人脸表情识别综述
2020-03-13叶继华祝锦泰江爱文李汉曦左家莉
叶继华,祝锦泰,江爱文,李汉曦,左家莉
(江西师范大学计算机信息工程学院,南昌,330022)
引 言
人脸表情是一种非常重要的语言交往方式,也是人与人之间进行沟通的重要手段。1971年,Ekman等[1]第一次将表情划分为 6种基本形式,包括悲伤(Sad)、高兴(Happy)、恐惧(Fear)、厌恶(Disgust)、惊讶(Surprise)和愤怒(Angry)。随着面部表情研究的发展与深入,基于运动单元(Action unit,AU)的面部动作编码系统(Facial action coding system,FACS)被提出,其通过分析运动单元的运动特征及其对应区域来说明与之联系的相关表情。
人脸表情识别(Facial expression recognition,FER)技术是将生理学、心理学、图像处理、机器视觉与模式识别等研究领域进行交叉与融合,是近年来模式识别与人工智能领域研究的一个热点问题。人脸表情识别在计算机视觉、社会情感分析、刑事案件侦破与医疗诊断等方面有着广泛的应用。
人脸表情识别是人脸识别[2]的进一步发展,主要包括了3个基本步骤,即人脸图像预处理、面部特征提取与表情分类,如图1所示。图像预处理主要是对原始图像进行检测与分割[3]。本文主要对传统的面部表情特征提取与表情分类方法以及基于深度学习的表情识别方法进行归纳与总结。表情数据集是表情识别研究中重要的一部分,本文对各表情数据集进行了介绍与分析,总结了各数据集普遍存在的问题,并针对这些问题,介绍了几种数据增强的方法。最后,总结了目前表情识别研究中存在的问题,并对其未来的发展作出了展望。

图1 人脸表情识别主要步骤Fig.1 Main steps of facial expression recognition
1 传统的表情识别方法
传统的表情识别方法主要分为人脸面部特征提取与表情分类两部分,分步进行操作。
1.1 表情特征提取
一张人脸图片拥有大量的信息,而且在视频序列中一个人在不同时刻所做出的表情也不完全相同[4],因此表情识别时需要提取出图像的纹理特征、五官特征等有效信息。这些有效信息的提取对识别速度与准确率的提升具有重要意义。表情特征提取是表情识别研究过程中最重要的部分,所提取特征的鲁棒性与完整性将对最终识别结果产生决定性影响[5]。传统的表情特征提取方法主要分为基于全局的提取方法、基于局部的提取方法以及混合提取方法[6]。
1.1.1 基于全局的提取方法
人脸表情的表现依赖于人脸肌肉的运动。人脸表情图像可以直观表现出人脸做出表情时肌肉运动所带来的相应的人脸纹理与外观的变化,而这些变化对人脸图像产生全局信息的影响,从而提出了基于全局的特征提取方法。
基于全局的特征提取方法是指将人脸作为一个完整的部分对其进行特征提取,然后将提取出的特征进行降维处理,从而获得表情特征。主成分分析(Principal component analysis,PCA)[7]方法是图像处理中常用的方法,其通过线性方法从原始变量中导出主成分,这些主成分可以尽量保留原始信息,从而节约处理时间,并从全局提取特征。但PCA方法有以下缺点:面对二维人脸图像矩阵必须将其先转化为一维向量,计算量很大;训练为无监督训练,不能利用训练样本中的类别信息;识别率有待提高。因此PCA方法需要解决二维图像降维的问题,文献[8-9]开始使用二维PCA来提取图像的二维特征信息,其优化目标变为将矩阵Sx转换为对角矩阵,然后取前n个特征向量。在PCA的基础上,Niu等[8]利用加权主成分分析(Weighted principal component analysis,WPCA)进行特征提取并使用改进的支持向量机(Support vector machine,SVM)进行表情分类,提高了识别效率但整体识别准确率较低;Zhu等[9]提出了利用均值主元分析(Equable principal component analysis,EPCA)方法进行表情特征提取,该方法能够大幅提高表情特征提取的鲁棒性;周书仁等[10]在对PCA进行改进后,提出了独立成分分析(Independent component analysis,ICA),并将其与隐马尔科夫模型(Hidden Markov model,HMM)结合,在保持识别效率的同时提升了识别准确率。ICA将数据划分为独立分量的线性组合从而获得数据的独立成分,所以具备较好的可分性,但面对复杂图像会导致识别率下降。
此外,局部线性嵌入(Locally linear embedding,LLE)与线性判断分析(Linear discriminant analysis,LDA)也广泛应用于表情特征提取部分。Roweos等[11]首次提出了使用LLE方法进行图像降维处理;Meng等[12]将LLE与神经网络进行结合,提出了一种LLENET进行特征提取,并取得了不错的效果。Siddiqi等[13]提出了一种逐步线性判断分析(Stepwise linear discriminant analysis,SWLDA)方法用于提取表情特征,得到了较高的识别率。朱明旱等[14]提出一种二维Fisher线性判别分析(Two-dimensional Fisher linear discriminant analysis,2DFLA)与局部保持投影相结合的表情识别方法,较大地提升了识别效率。
基于全局的特征提取方法在受控制的环境中取得了不错的成绩,但在样本量小、环境复杂的情况下不能达到很好的效果,而且性能普遍较差。
1.1.2 基于局部的提取方法
基于局部的特征提取方法主要是针对人脸的表情易变区域进行编码与表征。常见的局部提取方法主要包括基于几何特征的提取方法和基于纹理的特征提取方法。
(1)基于几何特征的提取方法
几何特征的提取主要是通过图像中人脸表情的显著特征,如眼睛、嘴巴、鼻子、眉毛等部位进行定位,从而得到丰富的空间几何信息,通过这些信息进行表情识别。
在基于几何特征的提取方法中,AU[15]是一种比较经典的特征提取方法,许多研究者开始从图像中提取AU特征再进行分类。Zhao等[16]使用多标签学习和联合小块的方式提取AU特征。Han等[17]提出了一种用于提高AU特征提取效果的面部网格变换法。Coots等[18]提出的主动形状模型(Active shape models,ASM)可以更好地提取人脸轮廓以及眼睛、鼻子、嘴的位置。在ASM的基础上,Matthews等[19]提出了主动外观模型(Acitve appearance models,AAM),能够更加精确地提取人脸轮廓以及五官的位置。Barmana等[20]提出了一种快速Sic主动外观模型(Fast-Sic active appearance model,Fast-Sic AAM),通过选择人脸的特征点(眉毛上的3个点,眼睛上的4个点,鼻子上的3个点以及嘴巴上的4个点)形成一个由特征点之间的欧式距离组成的网格,以更有效率地提取面部特征。
基于几何的特征提取方法可以有效地提取人脸面部表情的显著特征,但是当图像出现人脸五官不完整,或角度、光照强度及人脸尺寸等关键识别分类信息丢失时,会导致提取出的特征出现偏差,从而使得识别精度下降。
(2)基于纹理特征的提取方法
纹理特征是指图像像素周围空间邻域的灰度分布,最常用的提取方法是局部二值模式(Local binary pattern,LBP)[21]与 Gabor变换[22]。
传统的LBP算法定义了一个3×3的LBP算子,设置其中央像素点灰度值作为阈值,然后对阈值与中央像素点附近8个方向的灰度值进行比较,如果相邻像素点的灰度值大于中心像素的灰度值,则将其值设为1,否则设置为0,然后按照一定顺序形成8位二进制码,对应的十进制数则为LBP值。
传统的LBP方法将中心像素与单个邻域像素的灰度值进行比较,忽略了中心像素的作用以及一定范围内相邻像素之间的关系,从而导致部分局部特征丢失。面部表情图像特征复杂、细节丰富、类内差异大,使得传统的LBP方法难以详细描述像素在邻域方向上的灰度值变化。所以在LBP的基础上,Sheng等[23]针对LBP算子的覆盖区域难以满足不同尺寸图像纹理的问题,提出了一种多尺度局部二值模式,Kabir等[24]提出了一种基于局部方向模式(Local directional pattern,LDP)方差的人脸描述符用于人脸表情识别,Jabid等[25]提出了基于LDP的方法,提升了表情识别的鲁棒性,Li等[26]通过研究中心像素与相邻像素的定量关系,提出了一种多方向LBP编码方式(Multi-directional LBP,MDLBP),识别准确率较传统LBP方法提升了1.5%。Nagaraja等[27]提出了完全局部二值模式(Complete local binary pattern,CLBP),引入了一种新的包含边缘特征的完整性概念,用于提取面部表情更重要的特征。此外,Wu等[28]提出了一种自适应鲁棒二值模式(Adaptive robust binary pattern,ARBP),通过融合平均强度、最小强度和最大强度对阈值方案进行改进。Rubel等[29]提出了一种基于外观特征描述的自适应鲁棒局部完备模式(Adaptive robust local complete pattern,ARLCP),克服了现有局部算子的局限性。表1给出了JAFFE数据集下几种特征提取方法的识别准确率。
此外,基于Gabor小波变换的方法也常用于表情特征提取。2008年,Bashyal等[30]提出基于Gabor小波变换的表情特征提取方法,证明了Gabor小波在表情特征提取中具有巨大优势。此后,Abboud等[31]继续使用Gabor小波作为滤波器进行表情特征提取,取得了较好的识别效果,但冗余特征较多且提取时间过长。针对以上问题,邓洪波等[32]提出了一种基于局部Gabor滤波器组,其算法对Gabor进行了特征优化与降维,从而使得识别性能得到了提升。姚伟等[33]提出了一种二层Gabor特征选择方法,其对高维向量做过滤处理,再对过滤产生的特征子集进行AdaBoost选择,挑选出最具区分度的特征,从而降低Gabor特征的维度。
1.1.3 混合提取方法
混合提取方法是指将基于全局的特征提取方法和基于局部的特征提取方法进行融合,共同提取人脸表情的多种特征。Chao等[34]提出使用特定表情的局部二值模式(ES-LBP)来提取特征,此方法先使用ASM提取人脸的标记点,然后在标记点附近提取LBP特征组成ES-LBP特征。Agarwal等[35]在提取特征时采用流光法和图像梯度相结合的方法。Wang等[36]将几何特征与纹理特征进行融合从而提取表情特征,取得了较好的识别效果。Liu等[37]提出了一种基于局部Gabor滤波器组和分数次幂多项式核函数PCA的人脸表情识别方法,既克服了传统Gabor滤波器组的缺点,还可以削弱光照影响,使得识别率得到了大幅提高。
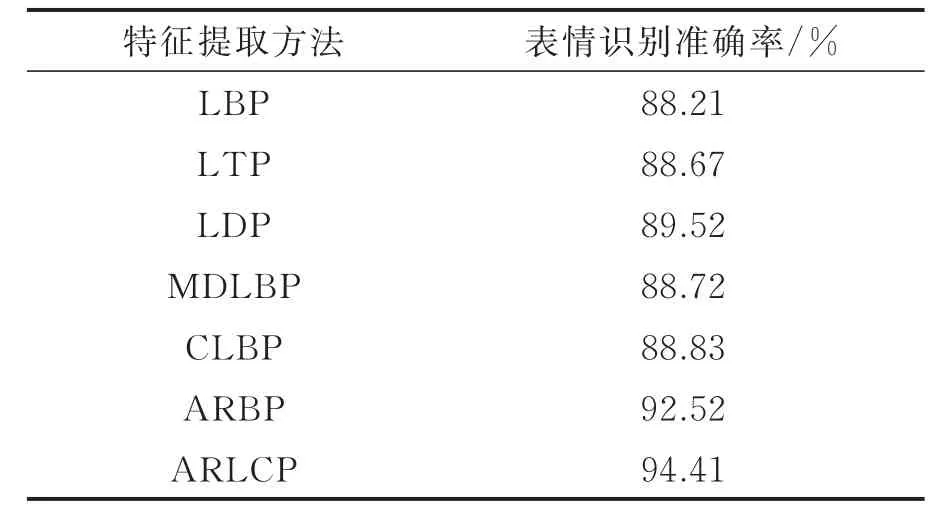
表1 不同特征提取方法在JAFFE数据集上的识别准确率Table 1 Identification accuracy of different feature extraction methods on JAFFE dataset
1.2 表情分类
在特征提取工作完成后,需要根据提取出的特征对表情进行分类处理。传统的表情分类方法主要分为机器学习方法与非机器学习方法。
1.2.1 非机器学习方法
非机器学习方法主要包括了HMM模型、模糊数学(Fuzzy mathemtics)以及贝叶斯分类器(Naive Bayes classifier)等。Filntisis等[38]提出将HMM模型与ASM模型相结合的方法,证明了HMM插值可以有效地实现表情地分类。Devi等[39]对HMM的时间复杂度与参数进行了优化,使其可以并行处理图像,从而提升了分类效率。Halder等[40]使用模糊数学使分类准确度达到了87.8%。Sebe等[41]提出了一种通过Cauchy贝叶斯分类器进行表情分类的方法,此方法使用Cauchy分布替代高斯分布,得到了更为出色的分类效果。
1.2.2 机器学习方法
随着机器学习的深入发展,研究者开始使用机器学习方法对表情进行分类。常用的机器学习方法有SVM、K近邻算法(K-NearestNeighbor,KNN)以及神经网络等。Liu等[42]将提取到的特征分为某一种表情的特有特征与两种表情的共有特征,再用稀疏支持向量机算法对其进行表情识别,提高了识别精确度。孙晓等[43]将面部结构作为先验知识,将KNN与感兴趣区域(Region of interest,ROI)进行结合,用于深度学习训练后表情分类的部分,提升了深度学习在表情分类中的鲁棒性,同时极大地降低了识别错误率。Hivi等[44]提出了一种基于方向梯度直方图(Histograms of oriented gradients,HOG),并对SVM、KNN与初级神经网络等分类器进行对照试验,在使用相同表情库与特征提取方式的条件下,SVM效果最佳,准确率达到93.53%;其次是神经网络,准确率为82.57%;KNN效果最差,识别率为79.97%。经过实验证明,采用机器学习方法进行表情分类的识别率较非机器学习方法有极大的提升。
2 基于深度学习的表情识别方法
2006年,Hinton等[45]提出深度信念网络(Deep belief networks,DBNs),使得深度学习重新引起重视。2012年,Krizhevsky等[46]提出的AlexNet将卷积神经网络用于图像分类,在ImageNet计算机视觉比赛中位列第一位。2014年,Simonyan等[47]提出一个19层VGGNet模型,由尺寸小、数量多的卷积核组成卷积组,在ILSVRC大赛中将Top-5错误率降至7.32%。随后,谷歌团队提出的GoogLeNet模型[48]及其后续改进模型[49-51],进一步将ImageNet数据集上的Top-5错误率降到了4.8%。随着神经网络深度的增加,对网络进行训练时经常会出现梯度消失或梯度爆炸的问题。针对这些问题,何凯明及其团队提出了深度残差网络ResNet[50],通过多个带参数的网络层来学习输入输出之间的残差表示,在可以增加深度的同时避免了梯度爆炸与梯度消失的问题。在ResNet出现后,Google团队借鉴了ResNet的思想,推出了Inception-ResNet-V2以及InceptionV4两种模型[51],并对两种模型进行融合,将ILSSVRC比赛的TOP-5错误量降到了3.08%。
深度学习在图像识别领域取得的巨大成绩为表情识别提供了新的思路[52]。许多研究者开始将深度神经网络(Deep neural network,DNN)用于表情识别。深度学习的出现打破了表情识别中传统的先特征提取后模式识别的固定模式,可以同时进行特征提取与表情分类,而且深度学习对特征的提取是通过反向传播算法与误差优化对权值进行迭代更新,所以能够提取出人类预想不到的关键点和特征。
深度学习在表情识别中的应用,大多基于VGGNet、GooGleNet与ResNet网络模型,其核心结构均为深度卷积神经网络(Deep convolution neural networks,DCNN)。在此基础上,Mollahosseini等[53]将AlexNet与GoogleNet模型结合,构建了一个7层CNN用于人脸表情识别,得到了较好的识别效果。Jung等[54]提出利用彩色图像与人脸特征点联合训练CNN网络,其网络包括3个卷积层与2个隐藏层,但这使得其表情特征学习不够精确。Lopes等[55]将部分特定特征提取方法与卷积神经网络进行组合,先采用预处理技术提取部分特定表情特征,但这会导致未知环境下正确率不高、鲁棒性不足。Verma等[56]提出了一个具有视觉和面部标识分支的网络,其视觉分支负责图像序列的输入,并引入从低层到高层的跳转连接,以此考虑到底层特征的重要性;面部标识分支研究面部标记轨迹,考虑到因面部大动作造成的面部特征的变化,如眼睛、鼻子、嘴唇的动作变化等,该方法在CK+数据集上取得了较高的识别率。表2对几种深度模型在CK+数据集上的识别准确率进行了比较。
除了对基础模型及网络结构进行改进外,有些研究者还对损失函数进行了研究与改进。Sun等[57]将contrastive loss损失函数用于表情识别。Schroff等[58]提出triplet loss损失函数,因其可以训练差异性较小样本的优势从而可以更好地训练表情识别网络,但其计算量较大,会导致网络性能下降。Wen等[59]提出了一种center loss损失函数,其目的是关注类内分布均匀性,让其绕类内中心均匀分布,以实现类内差异最小化。Cai等[60]在传统softmax损失函数的基础上,提出了island loss损失函数,可以在减少类内变化的同时,扩大类间差异,从而进一步增强深度特征的辨别力。Wang等[61]提出了一种AM-softmax损失函数,以softmax loss损失函数作为基础,引入角度间距,加入余弦余量项,使学习到的特征在特征空间中的决策边缘最大化,从而在获得更大类间距的同时极大地减少类内距离。吴慧华等[62]对AM-softmax损失函数与island loss损失函数进行结合,提出了一种基于余弦距离的损失函数cosine distance loss,用于对CNN学习强区分度表情特征进行监督,取得了较高的识别准确率。Qiang等[63]提出了一种全新的损失函数Knot magnify(KM)loss,通过自适应的方式对训练过程中的每个样本添加一个权重,从而提升强样本在DCNNs中训练的效果。表3对比了不同损失函数下表情识别的准确率。

表2 深度模型在CK+数据集识别准确率Table 2 Recognition accuracy of deep model in CK+dataset
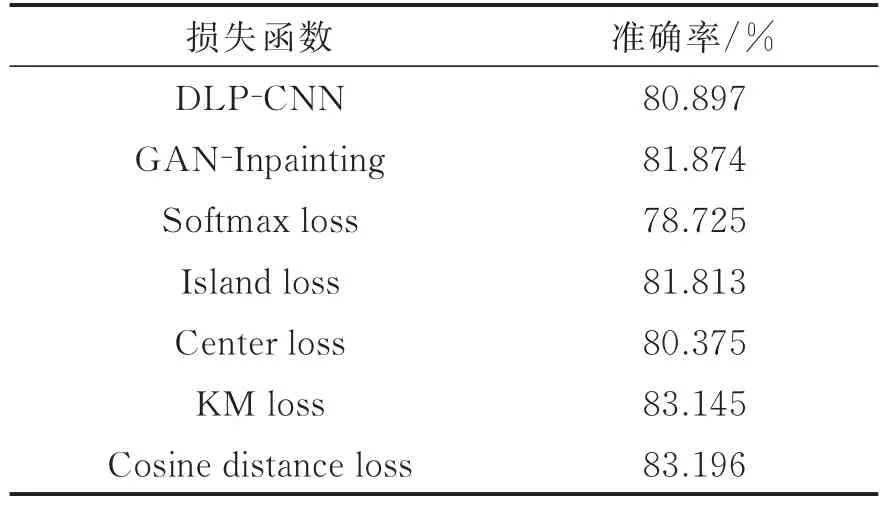
表3 不同损失函数下表情识别准确率对比Table 3 Comparison of facial expression recognition accuracy under different loss functions
3 表情数据集与数据增强
3.1 表情数据集比较与分析
表情识别起步相对较晚,发展还不够成熟,因此当前公开的数据集也较少。完善的表情数据集需要人脸图片包括各种表情以及五官信息,常用的表情数据集如下:
(1)The Japanese Female Facial Expression Database(JAFFE)。1998年,Lyons等[64]建立了一个日本女性表情数据集。该数据集共213张图像,包含了10名日本女性在相同背景下做出的高兴、悲伤、中性、厌恶、生气、害怕以及惊讶这7种表情,每一种表情拥有30~31张图像。图像拥有相同的尺寸,只是光照强度有些差异。
(2)The Extended Cohn-Kanade Dataset(CK+)。2010年,Lucey等[65]建立了目前应用较为广泛的CK+数据集。该数据集拥有更多的数量,还包括了表情的标记以及运动单元的标记。这个数据集包含123位参与人员,生成了593个图像序列,是目前公开的表情数据集中较为完善的数据集。JAFFE与CK+数据集部分图像对比如图2所示。
(3)Natural Visible and Infrared Facial Expression(USTC-NVIE)。2010年,Wang等[66]建立一个包含自发与诱发6种基本表情的静态数据集,成为目前世界上较为全面的人脸数据集。

图2 JAFFE与CK+数据集部分图像对比Fig.2 Comparison of JAFFE and CK+datasets
(4)Acted Facial Expression in the Wild(AFEW)。2012年,Dhall等[67]建立了一个野外动态面部表情数据集。该数据集从电影中获取表情数据,被用于视频情感识别大赛系列感情识别挑战赛。
(5)GENKI-4K。该数据集共4 000张图像,包含了两种表情:笑与不笑,被专门用来进行笑脸识别。此数据集姿势随意,图像大小不一,光照变化较多,导致此数据集比较复杂。
(6)Bimodal Face and Body Gesture Database(FABO)。该数据集在人脸表情的基础上,添加了身体姿态信息,目的在于利用表情与姿态进行表情分析与情感分析。FABO数据集包含23名参与者9种不同的表情。
(7)Beihang University(BHU)。2007年,毛峡等[68]建立了一个由18种单一表情、3种混合表情以及4种复杂表情组成的数据集。该数据集在实验室拍摄,含有部分在其他表情数据集中未曾出现过的情感表情,使得已有的表情数据集得到了极大的补充。
(8)The Facial Expression Datasets with Label in the Wild(FELW)。2019年,叶继华等[69]创建了一个自然场景下带标签的人脸表情数据集,如图3所示。该数据集由网络收集的不同性别、种族、年龄的人脸表情图像组成,对每张图像标注带有人脸部件的表情标签与状态标签,并引入了Kappa一致性检验。FELW数据集包含了26 848张图像以及10种表情,图像数量与表情丰富度都得到了不错的提升。

图3 FELW数据集部分表情图像Fig.3 Partial expression images of FELW
3.2 表情数据增强
虽然近年来越来越多的表情数据集得到公开,但人脸表情数据集普遍存在数据规模较小、数据量不足以及数据种类不平衡的问题。随着深度学习更广泛地应用于表情识别,训练神经网络需要更丰富、平衡的数据集。针对这一问题,研究者开始使用数据增强的方法扩充原始数据集。
最初,对原始图像进行几何变换成为一种普遍的做法。Simard等[70]提出使用平移、旋转以及倾斜图像等方式增加样本数量。Lopes等[71]通过使用二维高斯分布在原始图像眼睛附近加入随机噪声的方法,生成新的两眼位置,再通过旋转操作将两眼位置保持平衡,从而得到新的样本图像。Krizhevsky等[72]对原始图像进行随机裁剪,形成固定大小的子样本,然后再对每个子样本进行水平翻转,从而将训练集扩充了2 048倍。
针对图像的亮度、对比度等色彩空间属性进行调节,也是一种常见的数据增强方法。通过对原始图像的亮度进行调节,在扩大样本数量的同时,可以在一定程度上削弱光照问题对表情识别产生的影响。
除了通过几何变换与调整色彩属性的方法,对局部区域进行特殊处理也产生了不错的效果。Sun等[73]提出了一种基于感兴趣区域的表情数据增强方法,将人脸五官与下巴等在表情识别研究中特征更显著的区域设定为感兴趣区域,通过对不同图像感兴趣区域的替换来生成新的人脸图像。
2014年,Goodfellow提出了生成对抗网络(Generative adversarial network,GAN)[74],对图像数据增强产生了重要意义。GAN网络是一种深度生成模型,如图4所示,包含了生成器与判别器两个部分。生成器通过接收一个随机噪声并根据这个噪声生成假样本,即生成图像;而判别器用于对生成样本与原始样本进行区分,判断此图像是否属于真实图像样本。经过不断地生成与判别,最终生成与原始图像同风格的图像。
随着GAN网络的发展,越来越多的表情识别研究者开始将GAN网络用于人脸表情数据集增强。Arjovsky等[75]提出的WGAN-GP网络可以通过惩罚梯度以及Earth-MoverhL来增加网络学习的稳定性。Zhu等[76]提出了一个CycleGAN网络,该模型可以利用未配对的训练数据学习从一个域到另一个域的映射函数,从而实现图像的风格迁移。Mirza等[77]提出的CGAN在模型中加入了类别信息,从而可以生成具有特定标签的图像。Choi等[78]对CGAN与CycleGAN进行结合,提出了一种StarGAN网络,将生成器简化为1个,同时可以生成多种不同风格的图像。此方法完成了表情图像风格迁移的一步跨越,使得多邻域图像生成成为可能,使表情种类更为丰富,一定程度上解决了大部分表情数据集风格单一、数据不平衡的问题。Tang等[79]提出了一种EC-GAN网络,适用于各种不同的表情生成任务,可以通过条件属性标签轻松地控制其中特定的面部表情,增加了生成图像的丰富性。图5展示了StatGan网络在CelebA数据集上的效果。

图4 GAN网络模型结构Fig.4 GAN network model structure

图5 StarGAN在CelebA数据集上效果图Fig.5 Effect of StarGAN on the CelebA dataset
4 人脸表情识别存在的问题与未来的发展
4.1 存在的问题
目前人脸表情识别研究已经有了很大进展,部分技术也已经得到了应用。但是当前表情识别依然存在着一些问题,主要有以下几个方面:
(1)表情种类不够丰富,人脸表情并不是局限于6种基本表情,这也导致人脸表情识别对复杂表情识别效果不佳。
(2)目前传统的特征提取和分类方法一般都是通过标准人脸表情数据集来验证识别率,对于复杂环境与多变环境考虑不足,削弱了表情识别系统的适用性。
(3)传统的特征提取方法难以提取出人脸表情中隐藏较深的特征,而CNN等深度学习算法虽然可以提取出人工难以想到的特征,但训练复杂神经网络需要大量的计算成本与训练时间。
4.2 发展方向
在机器学习与人工智能迅速发展的今天,对人脸表情进行实时识别与分析的需求越来越显著,表情识别获得了更为广阔的研究前景。表情识别未来的发展应当在技术创新与新应用方向两方面进行探索。
4.2.1 技术创新
(1)进一步解决光照、遮挡等复杂环境下表情识别率下降的问题,提升表情识别系统的鲁棒性。当前,自然环境下的数据集并不丰富,导致很多模型对于复杂环境下的表情识别效果不佳,构造一个丰富的自然环境下3D人脸表情数据集,对于表情识别未来的研究会产生重要的影响。
(2)在提取表情特征时,考虑更多的边缘信息。随着边缘计算的兴起与发展,利用边缘信息进行人脸识别与图像识别的技术正变得越来越成熟,利用边缘信息分析人脸表情也更加重要。
(3)改进深度模型。当前的深度模型可以得到不错的预测准确率,但训练中因高复杂度模型产生的过多参数会导致模型训练成本急剧增加,同时深度模型对于提取到的特征的解释性较差。如何增强深度模型的解释性,以及如何通过技术对深度模型进行精简,在降低训练成本的情况下保持并增加模型预测的准确率,是未来表情识别发展的重要环节。
(4)提高GAN网络对表情数据增强的影响,通过融入非视觉形式,如对语义特征等更深层次的特征的关注,来提升模型的泛化能力。此外,通过生成对抗网络解决表情数据量不平衡,也是值得关注的问题。
4.2.2 新应用方向
(1)在计算机中训练好的模型虽然可以得到不错的预测效果,但巨大的计算成本导致其难以使用到轻便设备中。如何更好地将模型运用到移动端与嵌入式设备中,增加表情识别的实用性,还有待于进一步研究。
(2)随着微表情在心理学领域的发展,将表情识别的方法用于对人脸微表情进行识别已经得到了一部分研究者的关注。微表情作为一种自发性的表情,具有动作幅度小、持续时间短的特点,所以制作微表情数据集、提取微表情特征是未来的研究重点。
(3)人的表情与动作在很大程度上能够体现一个人的情感状态。在表情识别的基础上,与姿态分析技术进行结合,通过实时人脸表情与姿态动作进行情感识别与分析,是未来研究的重要方向。
5 结束语
本文重点总结了表情识别中传统的特征提取方法、表情分类方法与基于深度学习的表情识别方法。介绍了表情数据集,并针对表情数据集出现的数据量不足以及数据不丰富等问题,总结了GAN等用于表情数据增强的方法。最后总结了表情识别目前存在的问题并对未来的发展方向做出了展望。
随着心理学的不断发展,对于人内心情绪的判断变得更为重要,通过表情识别对心理健康状况进行分析与判断是人们当前显著的诉求,因此通过机器进行表情识别与心理状况分析显得更为重要。未来的表情识别应当朝着效率更高、适用性更强的方向进行发展。
