自适应聚类的未知应用层协议识别方法
2020-03-11龚启缘冯文博李毅豪
洪 征,龚启缘,冯文博,李毅豪
中国人民解放军陆军工程大学 指挥控制工程学院,南京210042
1 引言
应用层协议识别是指从承载应用层协议数据的网络流量中提取出可以标识应用层协议的关键特征,并以这些关键特征为基础,将同一种类型的应用层协议数据划分在一起。
应用层协议识别是网络服务提供商和网络管理员提供差异性服务质量保障、实施入侵检测、流量监控等工作的重要基础[1]。举例来看,据统计目前互联网上超过60%的流量是由流媒体、P2P、网络游戏等新型网络应用所产生的,这些应用的流量占据了大量的网络带宽,使得其他网络服务运行异常甚至无法提供服务。使用应用层协议识别技术对这些应用层协议网络流量进行识别进而根据需要进行限制,是网络服务提供商提供服务质量保障的基础。此外,大量的计算机病毒、木马程序等恶意软件为了躲避安全软件和防火墙的防护,使用自定义的应用层协议、动态端口以及端口伪装技术,使得网络管理员对恶意入侵行为的检测越来越困难,应用层协议识别是将这些恶意流量从正常业务流量中区分出来的重要手段,是网络管理员及时发现并阻止攻击行为、保护网络安全的重要基础。
应用层协议识别方法主要包括基于端口号的识别方法、基于深度包检测(Deep Packet Inspection,DPI)的识别方法、基于主机行为的识别方法以及基于深度流检测(Deep Flow Inspection,DFI)的识别方法。
基于端口号的识别方法是以IANA 为HTTP、FTP、TELNET 等常用应用层协议分配的固定端口号为依据对应用层协议网络流量进行识别。根据IP 地址、端口号、协议号等信息,就可以粗略地确定哪些流量是由IANA 分配了固定端口号的应用层协议产生的,这种方法简单快捷,便于实现。但是,随着网络的发展,端口号的数量无法满足日益增长的网络应用需求,动态端口技术应运而生,同一种应用层协议使用的端口号不再固定,甚至有些应用层协议会使用熟知端口(well-known ports)进行通信,如P2P 应用KazaA 就会使用80 端口进行通信。基于协议端口号的流量识别方法无法识别这类应用层协议的网络流量。Moore等人[2]通过实验证明基于端口号的识别方法的准确率已经下降至20%以下。
基于深度包检测的识别方法通过提取应用层数据包的载荷特征,然后和已知库中的协议载荷特征比对完成协议识别分类[3]。一些研究人员提出使用应用层协议载荷特征识别P2P 等流量的方法[3-4]。很多P2P 协议具有较为明显的特征字段,如BitTorrent protocol 的特征字段为“13 42 69 74 54 6F 72 72 65 6E 74 20 70 72 6F 74 6F 63 6F 6C”。此类方法解决了协议端口号不固定的问题,可以识别采用动态端口的协议,对于P2P 流量的识别较为有效。但是该方法以应用层协议载荷特征为基础,因此只能识别数据库中存储了应用层载荷特征的应用层协议,不能识别未知协议和加密协议的网络流量,同时该方法需要维护庞大的载荷特征库,占用系统资源较多,匹配计算也较为复杂。尽管缺陷很多,但是这是当前识别准确率较高的一类方法,也是部署在高速网络环境中最好的方式[5]。
Karagiannis 在文献[6]中提出了基于主机行为的识别分类方法,该方法结合网络层、运输层和应用层的网络流量特征,通过分析主机行为来区分不同的协议数据,该方法在一定程度上提高了应用层协议识别的准确度,但是并没有解决基于深度包检测的识别分类方法无法识别未知协议和加密协议的网络流量的问题。
为了实现对未知协议和加密协议的网络流量的识别分类,研究者提出了基于深度流检测的识别方法。Moore等人[2]利用TCP连接过程产生的248种流特征进行应用层协议网络流量的识别。Moore 认为每一种应用层协议对应的网络流特征信息是唯一的,这些网络流特征包括网络流长度、网络流持续时间、网络流中数据包的数量,以及网络流中数据包的发送间隔等。通过提取网络交互过程中产生的流的统计特征区分不同协议的流量。该方法不需要读取解析应用层载荷,只提取流统计特征,计算复杂度低,可以识别加密流量和未知应用层协议流量,方法也不需要维护和更新一个庞大的特征库,消耗资源少。但是该方法的准确度完全取决于所选取特征的协议区分能力,不足以满足网络管理的需要。
面对复杂的网络环境,传统的应用层协议识别技术面临着识别效率低、准确率低等问题。同时,传统应用层协议识别分类技术无法识别协议规范未知的应用层协议的网络流量。快速、准确地对未知应用层协议的网络流量进行识别是协议识别领域的一个重要研究目标。为了解决现有网络流量识别分类方法在处理未知应用层协议网络流量识别效率低、识别准确度低的问题,本文提出一种基于自适应聚类的应用层协议识别方法,将聚类算法与传统的基于深度包检测的协议识别方法相结合,对未知应用层协议的网络流量进行识别。所提出的方法能够自动化地提取目标网络流量的应用层协议负载特征,自适应地确定目标簇的数量,高效准确地对未知应用层协议流量进行识别。
2 相关研究
近年来,研究者将机器学习方法引入网络流量识别领域。目前有较多基于有监督学习的应用层协议识别方法的研究。谭骏等人[7]提出了基于自适应BP 神经网络的流量识别算法,方法取得了较高的协议识别准确率。Wang W等人[8]将卷积神经网络应用到网络流量识别分类领域,通过流量清洗消除可能对特征提取造成影响的无用信息,提升了分类准确率。王勇等人[9]提出了基于LeNet-5 深度卷积神经网络的识别分类方法,通过循环调整相关参数得到最优分类模型。Wu D等人[10]提出一种基于距离的最近邻识别方法,能够改善其他方法对不平衡网络流量识别性能低的问题。Jain[11]研究了由不同优化器训练的卷积神经网络对协议识别的影响,实验结果表明,随机梯度下降(Stochastic Gradient Descent,SGD)优化器产生的识别效果最好。Ren J 等[12]提出了一种针对无线通信网络的协议识别方法,首先利用一维卷积神经网络进行自动化的特征提取,然后基于SVM对应用层协议进行分类。
上述研究利用神经网络等分类模型,采用有标记的协议数据进行模型训练,训练出的模型能够较为准确地对应用层协议网络流量进行识别。但是,如果应用层协议的协议规范未知,则相应的网络流量难以采用这类方法进行识别。
将无监督学习方法应用于网络流量识别领域是解决上述问题的一种可行方法。基于无监督学习的应用层协议识别目前尚处于起步阶段。无监督学习领域最典型的方法是聚类算法。对于任意的数据集,聚类算法能够依据相似性,将数据进行类别的划分。要将聚类算法应用于流量识别领域,需要研究分析如何将应用层协议数据转化为聚类算法的输入以及如何计算应用层协议数据之间的相似性。
聚类算法包括层次化聚类算法、划分式聚类算法、基于密度和网格的聚类算法等类型。目前在协议识别领域,研究者采用较多的是划分式聚类算法。李林林等人[13]在K 均值算法和K 近邻算法的基础上设计了一种分类器,采用K 均值算法对少量有标记样本和大量无标记样本组成的混合数据进行聚类,得到若干簇,而后利用K 近邻算法结合簇中有标记的样本对无标记样本进行识别,实验结果表明该分类器对于不平衡网络流能够取得较好的分类效果。Munz G 等人[14]使用K-Means聚类算法对未进行标注的异常流量进行检测,成功实现了异常流量的识别。Mcgregor A 等人[15]将EM算法应用于网络流量分类,但是其方法只能粗略地进行协议识别,准确率较低。Liu S等人[16]针对EM算法初值敏感性强和易收敛到局部最优解等缺点,提出了基于改进EM 的协议识别方法,该方法缩小了搜索范围,提高了协议识别的准确率。周文刚等人[17]针对网络流量的复杂性和动态性等特点,利用谱聚类将协议识别分类问题转化为无向图的多路划分问题,根据图论的思想构建分类器,最终基于图划分结果对协议进行识别分类。Wang 等[18]研究了基于先验知识的协议识别方法,该方法将标记数据集和未标记数据集作为输入,首先利用约束聚类算法提取未标记数据的新模式,且这些模式是标记数据未出现的,并以此模式代表未知协议,然后基于标记数据和未标记数据的新模式训练多个二元分类器,根据分类器的结果确定样本数据的协议类型。
总体上看,现有的基于聚类的网络流量方法虽然能够对未知协议网络流量进行分类,但是大部分方法需要输入目标类簇的数量,协议识别的准确率受目标类簇数量的影响较大,不能自动对未知协议流量进行分类,实际应用的局限性较大。
3 基于自适应聚类的未知应用层协议识别方法
3.1 算法概述
本文以网络通信中的应用层协议数据作为分析对象。同一种协议的网络数据存在一定的相似性,可以利用这种相似性来区分不同的应用层协议。本文方法首先从采集的原始网络数据中重组出网络流,提取出网络流的应用层协议数据,并对协议数据进行相似度计算,以应用层协议数据间的相似度作为协议识别的依据。而后,利用改进的层次聚类算法对网络流的应用层协议数据进行自适应地聚类,自动化地识别未知应用层协议。
具体来看,如图1 所示,所提出的应用层协议识别方法包括以下处理步骤:
(1)数据预处理:对采集的网络流量数据进行处理,通过数据过滤与排序、流重组、应用层协议数据提取等子步骤,将网络流量数据转化为字节流的形式。
(2)相似度计算:截取应用层协议数据前部固定长度的字节,计算获得不同应用层协议数据之间的相似度。
(3)未知应用层协议聚类:对应用层协议数据进行簇初始化,通过簇间相似度算法计算获得簇间相似度,利用改进的聚类算法迭代反复,直至达到聚类停止条件,将同种应用层协议数据聚集在一个簇中,最后输出簇集合,集合中每一个簇即为一种应用层协议所对应的网络流信息的集合。
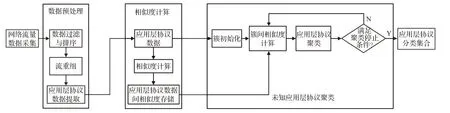
图1 基于自适应聚类的未知应用层协议识别的处理流程
3.2 数据预处理
数据预处理是进行未知应用层协议识别的基础,其目的是从采集的网络流量中提取出网络流,进而获得应用层协议数据。数据预处理可以细分为三个子步骤。第一个子步骤是进行数据过滤与排序,通过数据过滤获得具有应用层协议负载的网络流量,进而通过排序将可能属于同一个流的网络数据包聚集在一起。第二个子步骤是流重组,获得网络流的信息。第三个子步骤是应用层协议数据提取,在网络流的基础上提取出应用层协议数据。
数据预处理的第一个子步骤是过滤掉不需要考虑的通信数据包。本文关注的是包含应用层协议数据的网络数据包,所涉及的网络流可以是一个完整的TCP连接或者一次完整的UDP交互。可以通过读取数据链路层帧头中FrameType字段将非IP数据包过滤,而后通过读取网络层IP 数据包首部的Protocol 字段来确定TCP数据包和UDP 数据包,将非TCP 和非UDP 数据包过滤。对于一条单向的网络流,其中数据包的IP地址和端口号是固定的,因此可以按照IP数据包首部源IP、目的IP、源端口号、目的端口号等信息对网络数据包进行排序,将可能属于同一个流的数据包聚集在一起,以提升流重组的效率。
数据预处理的第二个子步骤是流重组。对于TCP流,根据TCP首部中的SYN和FIN标志位可以标识TCP流的开始和结束,而后利用TCP首部的序列号和负载数据长度关系将到达的数据包重新整合为一条有序流。
对于UDP 流,由于其没有连接建立和连接释放过程,无法通过UDP 首部标识UDP 流的开始和结束。本文通过设置流最大持续时间,依据数据包的发送时间判断UDP流的开始和结束。首先按序选择第一个UDP数据包,以该数据包的发送时间为流开始时间,每捕获一个数据包,就计算其发送时间与流开始时间之差,如果该差值小于流最大持续时间,则捕获的数据包属于该UDP 流;如果该差值大于流最大持续时间,则认为该UDP流已经结束,捕获的数据包属于下一条UDP流。
第三个子步骤是应用层协议数据提取。根据TCP流和UDP 流特征,将TCP 流和UDP 流中的应用层协议数据提取出来,保存用于后续分析。
3.3 相似度计算
聚类算法会依据相似度将数据集划分为多个不同的簇,簇内的数据具有较高的相似度,不同簇之间数据的相似度差距较大。
层次化聚类算法对给定的数据集进行层次的分解,直到达到某种条件才停止。具体可以分为凝聚的层次聚类算法和分裂的层次聚类算法。凝聚的层次聚类算法采用自底向上的策略,首先将每个对象作为一个簇,然后将相似的簇合并形成更大的簇,直到某个条件满足才终止算法。分裂的层次聚类算法则相反,这类算法首先将所有对象置于一个簇中,然后逐渐分裂为越来越小的簇,直到终止条件满足。层次化聚类算法适用范围广,可以得到高质量的聚类结果。
本文采用凝聚式的层次聚类算法,并选取该算法体系中使用广泛的AGNES算法作为相似度度量的基础。
在进行聚类时,首先对数据对象集进行簇初始化,将每一个数据对象标记为一个簇,而后计算簇与簇之间的相似度,通过将簇间相似度与设定的阈值进行比较来决定是否合并两个簇,迭代反复,自动完成数据对象集的聚类。但是,传统的AGNES 聚类算法在计算簇间相似度时,存在重复计算对象间相似度的情况。
举例来看,对于对象集{a1,a2,a3,b1},其中,a1,a2,a3为同一类型对象,b1为另一类型对象。聚类算法对其进行簇初始化后得到簇集合{{a1},{a2},{a3},{b1}}。执行第一次聚类循环,计算簇{a1},{a2},{a3},{b1}之间的簇间相似度,由于初始的每个簇中只有一个对象,初始簇间相似度即为对象a1,a2,a3,b1之间的相似度,需要计算对象a1,a2,a3,b1之间的相似度作为簇间相似度。假设第一次聚类循环后,簇{a1}与簇{a2}被合并为簇{a1,a2},则新的簇集合为{{a1,a2},{a3},{b1}}。第二次聚类循环需要计算簇{a1,a2},{a3},{b1}间的簇间相似度,对于簇{a1,a2}与簇{ }a3,计算其簇间相似度时,首先计算a1与a3、a2与a3的对象间相似度,然后取其平均值作为簇间相似度,以此类推。聚类过程如图2所示。在聚类循环的过程中,一些对象间的相似度被反复计算,例如,a1与a3间的相似度,a2与a3间的相似度。聚类算法改变的是对象在簇集合中的位置,并没有增加或删除对象,在计算簇间相似度时,存在重复计算对象间相似度的情况,重复性地计算降低了聚类效率。
本文方法对聚类流程进行了改进,将聚类方法中相似度的计算划分为两个部分,第一部分是数据对象间相似度的计算,第二部分是簇间相似度的计算。在聚类前通过对象间相似度的计算,获得所有对象之间的相似度。在计算簇间相似度时,当需要确定两个对象间的相似度时,只需要利用之前的相似度计算结果,不再重新计算,以此来提高聚类效率。
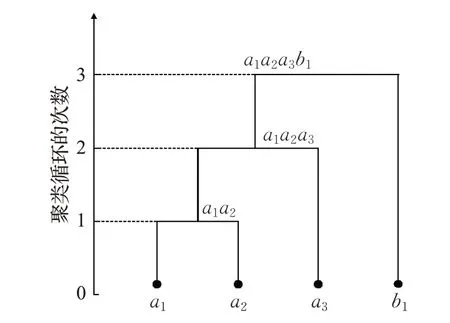
图2 聚类循环过程的示例
相似度计算阶段主要完成对象间相似度的计算,针对协议识别需求所设计的相似度计算流程如图3所示。
本文的应用层协议间相似度计算流程包括切片处理、选取切片集、计算相似度、存储相似度等子步骤。
应用层协议数据可以看作有序的字节流。应用层协议数据中,往往有一些具有明显协议特征的短序列。这些短序列主要集中在应用层协议数据的前部位置。本文通过截取应用层协议数据前部固定长度的字节,尽量保留包含协议特征短序列的数据,同时屏蔽与协议信息无关的用户数据。然而,在截取的应用层协议数据中依旧可能包含部分干扰判定的用户数据。
本文通过对文本型协议数据的研究发现,用户数据与协议特征序列之间往往会使用空格或特殊字符分隔。为了尽可能降低用户数据对协议分类的影响,提升相似度计算的准确度,本文针对文本型协议设计了切片方法。切片是以空格等特殊字符作为分隔符,对应用层协议数据进行切割,将用户数据与协议特征短序列分开来。
例如,一条典型的HTTP协议报文为如下形式:
“GET/HTTP/1.1
Host:127.0.0.1
User-Agent:Mozilla/5.0”
第一行为协议特征序列,其后每行数据左边为协议特征序列,右边为用户数据,中间以冒号分隔,通过切片处理后可以获得如下切片集:
{“GET”、“HTTP”、“1”、“1”、“HOST”、“127”、“0”、“0”、“1”、“User”、“Agent”、“Mozilla”、“5”、“0”}
可以看出每一个切片要么是能够标识应用层协议特征的短序列,要么是用户数据,协议特征序列和用户数据被区分开来。
在对截取的应用层协议数据进行切片处理后,以应用层协议数据的切片集作为相似度计算算法的输入。相似度计算的具体步骤为:
对于任选两个切片集:
A={a1,a2,…,an},B={b1,b2,…,bm}
计算第一个切片集中切片在第二个切片集中出现的个数,记为num,则切片集A 对B 的相似度为:
similar(A,B)=num/n n 为A 中切片总数。
循环执行此步骤,直至计算出所有切片集间的相似度。将得到的相似度保存在数组中,供下一步使用。
举例来看,对于切片集:
A={a1,a2,a3,a4},B={a1,a4}
A 中只有切片a1和a4在B 中出现,则num 为2,那么A 对B 的相似度为:
similar(A,B)=2/4=0.5
同理,B 对A 的相似度为:
similar(B,A)=1
3.4 未知应用层协议聚类
该步工作针对应用层协议识别分类的需求对网络流信息进行聚类。本文在层次聚类方法的基础上进行了改进,改进工作主要体现在相似度计算上。传统的层次聚类算法在计算簇间相似度时,会重复计算数据对象间相似度,本文通过将相似度计算拆分为聚类前应用层协议数据间相似度计算和聚类中簇间相似度计算两个部分。在聚类前完成复杂的应用层协议数据间相似度计算,而后将结果保存到数组中。在计算簇间相似度时,遇到需要计算应用层协议数据间相似度的地方,只需从数组中提取数值即可,简化了聚类中的相似度计算,提升了聚类效率。图4为本文所使用的改进的层次聚类方法的流程示意图。

图3 应用层协议间相似度计算流程
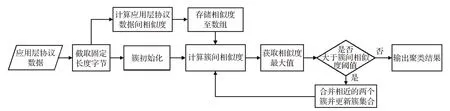
图4 改进的层次聚类算法流程
本文所使用的改进的层次聚类算法流程包括簇初始化、簇间相似度的计算、相似度阈值比对、簇的合并等子步骤。
以数据预处理获取的应用层协议数据作为算法的输入,对协议数据进行簇初始化。具体操作为,将每一条网络流的协议数据独立保存,并加上初始簇标记。每一条网络流的协议数据经过簇初始化后属于不同的簇。
以簇集合作为簇间相似度算法的输入,任选两个簇,首先计算簇中每一条协议数据与另一个簇中所有协议数据间相似度的均值,作为该条协议数据与另一个簇之间的相似度。而后计算簇中所有协议数据与另一个簇之间的相似度的均值,作为簇间相对相似度。最后,计算两个簇之间相对相似度的均值,得到簇间相似度。
举例来看,在聚类时任选两个簇:
C1={a1,a2,…,an},C2={b1,b2,…,bm}
首先计算簇C1 内协议数据ai(i=1,2,…,n) 与簇C2 的相似度:,记为similar(ai,C2),其中similar(ai,bj)表示应用层协议数据ai对应用层协议数据bj的相似度,m 为簇C2 中包含的应用层协议数据的总数。
如果簇间相似度大于相似度阈值,则合并两个簇类并更新簇集合。具体做法为选取相似的两个簇:
C1={a1,a2,…,an},C2={b1,b2,…,bm}
以其中任意一个簇为基础,将另一个簇中所有数据添加进来,如以C1 为基础,合并后为:
C1={a1,a2,…,an,b1,b2,…,bm}
进而在簇集合中删除簇C2,这就完成了合并簇集合的操作。
重复计算簇间相似度、相似度阈值比对、合并簇等步骤直到算法满足聚类终止条件。聚类的终止条件一般是簇集合中的簇间相似度小于相似度阈值,不能再进行簇的合并。而后输出簇集合,每一个簇包含了对应于一种应用层协议的所有网络流信息。
4 实验测试
4.1 应用层协议网络流量采集
应用层协议识别分类的第一步是数据的采集,本文实验使用的数据集分为公开数据集和本地数据集。
公开数据集使用的是林肯实验室发布的DARPA数据集[19],本文从其中的tcpdump 数据集中提取出HTTP、FTP、SMTP三种协议的通信数据,把它们作为未知协议进行测试。对3 种协议各抽取前500 个数据包,组成1 500个数据包的数据集作为原型系统的输入数据。
本地数据集为在实验环境中捕获的一种自定义协议的通信数据。该协议服务端通过21 号端口进行通信,在Wireshark 中这种自定义协议会被错误地识别为FTP的通信数据。
实验中将选取的DARPA公开数据集与本地数据集通过Wireshark混合生成了多协议混合数据集。协议交互过程是双向的,本文方法针对单向网络流,因此在实验时首先对每种协议进行流重组,以获得每种协议对应的请求网络流和响应网络流数量,如表1所示。因为数据从DARPA 数据集中按顺序选取,因此请求网络流和响应网络流数量基本是相等的。
4.2 算法中的参数分析
本文算法涉及两个重要参数,一是簇间相似度阈值,该参数是聚类算法中两个簇能合并为一个簇的最小簇间相似度;二是截取报文长度,该长度影响到算法自动提取出的特征短序列的完整性。本文通过控制变量法测试了两个参数对聚类效果的影响。
(1)簇间相似度阈值对聚类准确率的影响
本文使用从DARPA数据集提取出的协议流量进行测试。首先测试簇间相似度阈值对聚类准确率的影响。簇间相似度阈值是聚类中两个簇能合并为一个簇所需的最小簇间相似度,阈值的大小会影响聚类效果。实验设置的截取应用层协议数据的长度为60 Byte,测试结果如图5所示,从图中可以看出簇间相似度阈值为0.3 时,聚类准确率最高,聚类效果最好,三种协议的聚类准确率都达到了100%。在簇间相似度阈值大于0.3以后,三种协议的聚类准确率开始下降;当阈值接近1时,HTTP、FTP 协议的聚类准确度下降到接近0%,而FTP协议聚类准确度还能保持在50%以上。
经分析,测试数据虽然只截取了协议前部60 Byte数据,但是其中依旧包含了部分用户数据。在计算簇间相似度时,会对相似度结果产生一定影响,同类协议的相似度在0.3 左右,因此随着簇间相似度阈值接近0.3,聚类效果越来越好,随着相似度阈值接近1,聚类效果变差。
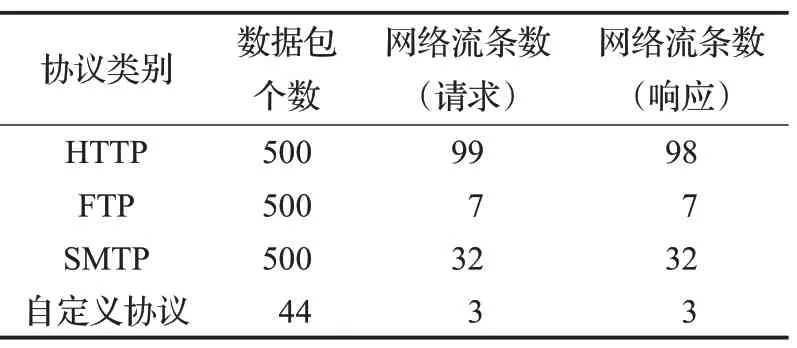
表1 网络流量数据集

图5 簇间相似度阈值对聚类准确率的影响
(2)截取的应用层协议数据长度对聚类准确率的影响
截取的应用层协议数据长度决定了截取的数据中包含的协议特征短序列的数量和用户数据的数量,影响着应用层协议数据间相似度计算的准确性。本文设置簇间相似度阈值为0.3,通过改变截取的应用层协议数据的长度,得到每一种长度下的聚类准确率。截取长度选取范围为(10,100),步幅为10,图6 为测试结果。从图中可以看出,在簇间相似度阈值为0.3时,聚类效果在截取的应用层协议数据长度等于10 Byte 或大于等于60 Byte时效果最好,SMTP协议受截取数据长度影响最大,FTP协议几乎不受截取数据长度影响。
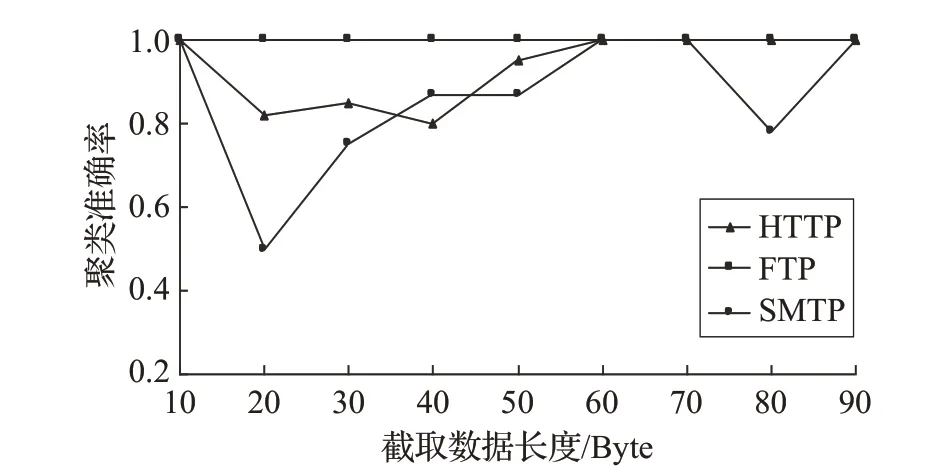
图6 截取报文长度对聚类准确率的影响
经分析认为,协议数据为协议特征短序列与用户数据的交替混合,虽然特征短序列都处在协议数据前部,但是其前部依旧包含一些用户数据,且用户数据比协议特征数据多出不少。当截取数据长度为10 Byte 时,截取的数据全部为协议特征短序列或者协议特征短序列明显多于用户数据,因此聚类结果准确率很高。随着截取数据长度的增加,用户数据在截取数据中的占比逐渐超过协议特征短序列,导致聚类准确率开始下降。同时,由于特征短序列与用户数据是交替排列的,因此当截取数据长度进一步提高时,协议特征短序列的占比又会逐渐提高,导致聚类准确率再次增长。
4.3 聚类准确率测试
本文通过Python 实现了算法,而后输入测试数据集。算法需要人工设置两个参数:簇间相似度阈值和截取的应用层协议数据长度,测试实验选取簇间相似度阈值为0.3,截取的应用层协议数据长度为60 Byte。最后得到聚类结果如表2所示。
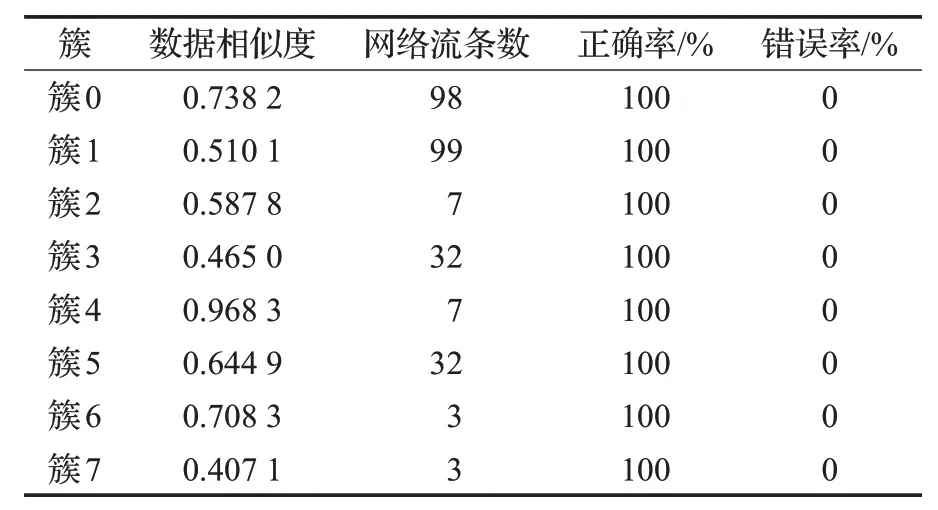
表2 聚类结果
本文通过将该结果与人工标记结果进行比较得到算法聚类的准确率,得到表3。

表3 聚类结果准确率
从结果可以看出,本文算法成功将HTTP、FTP、SMTP 和自定义协议的请求网络流和响应网络流区分开,聚成不同的簇,聚类准确率达100%。本文算法并没有使用端口信息进行协议区分,而是使用协议应用层数据负载特征进行协议聚类,因此本文可以成功将使用端口伪装技术的自定义协议与FTP协议区分开,实现未知协议识别的目标。
4.4 聚类效率测试
本文将改进后的AGNES 算法与原算法进行比较,测试数据集采用上文所采集的数据,具体信息如表4所示。在测试过程中,本文以程序运行时间作为聚类效率的度量标准,得到聚类效率对比结果如表5所示。
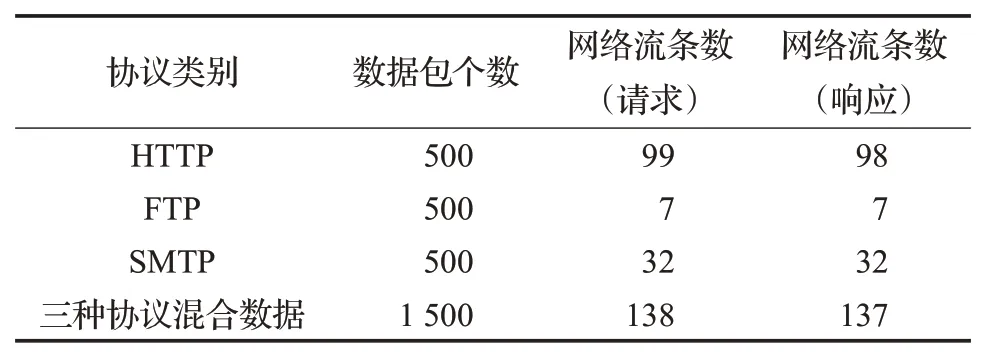
表4 测试数据集
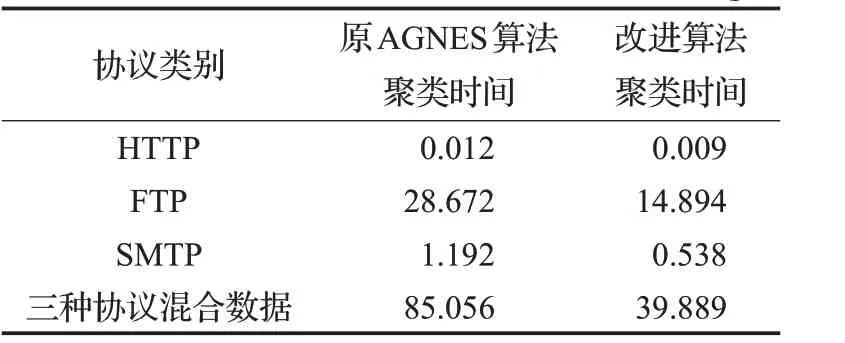
表5 聚类效率测试结果 s
从结果可以看出改进后的算法在聚类效率上明显优于改进前的原始算法,从数据上看,其效率可以提高一倍,时间上表现为算法运行所需时间减少一半。该结果说明通过将AGNES算法的相似度计算拆分为聚类前应用层协议数据间相似度计算和聚类中簇间相似度计算确实可以提升聚类算法的聚类效率。
4.5 与其他聚类算法的对比分析
本文使用Weka 平台中的SimpleKMeans、EM、MakeDensityBasedCluster 等聚类算法与本文算法进行对比测试,进一步验证本文方法的性能。
KMeans聚类、EM聚类和MakeDensityBasedCluster是三种典型的聚类方法。KMeans 聚类是划分聚类算法中最著名的算法,具有简洁高效的特点。Weka 平台中的SimpleKMeans 算法是KMeans 算法家族中使用最广泛的一种。对于一个数据集合,当用户指定聚类数目k 后,KMeans 算法会依据设定的距离函数把数据分为k 个簇中。KMeans聚类认为每一个数据对象完全隶属于某个簇。EM 算法假定每个数据对象是模糊隶属于某个簇的,每个簇都是一个高斯分布,该算法反复迭代,以确定数据对象存在于某个簇中的概率。当概率模型适合于数据该时,此算法终止这一过程。基于密度的聚类方法可以在有噪音的数据中发现各种形状和各种大小的簇。MakeDensityBasedCluster 是该类方法中最典型的代表算法。其核心思想就是先发现密度较高的点,然后把相近的高密度点逐步都连成一片,进而生成各种簇。
实验首先通过预处理,对从DARPA 数据集中提取的3 种协议数据进行处理,获得应用层协议数据,而后使用本文设计的切片方法对应用层协议数据进行截取和切片,并将切片数据保存采用csv 格式保存。该格式可以被Weka平台识别并处理。
对于SimpleKMeans 算法,本文设置聚类数目为6,随机种子为10 进行测试,其余参数为默认参数。测试结果如表6所示。
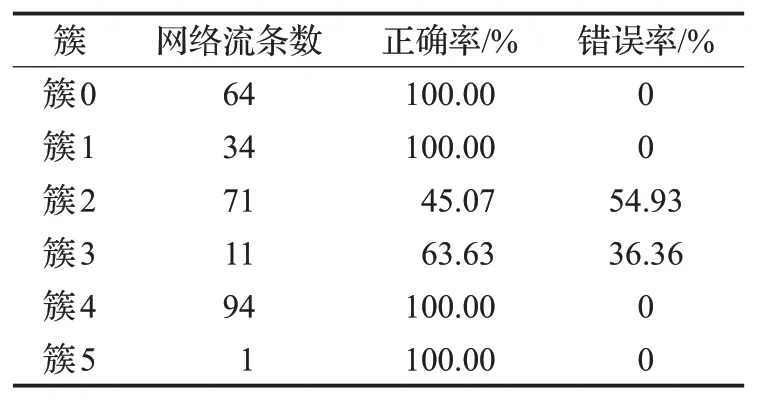
表6 SimpleKMeans聚类结果
对于EM算法,设置聚类数目为6,随机种子分别取100进行测试,其余参数默认。测试结果如表7所示。
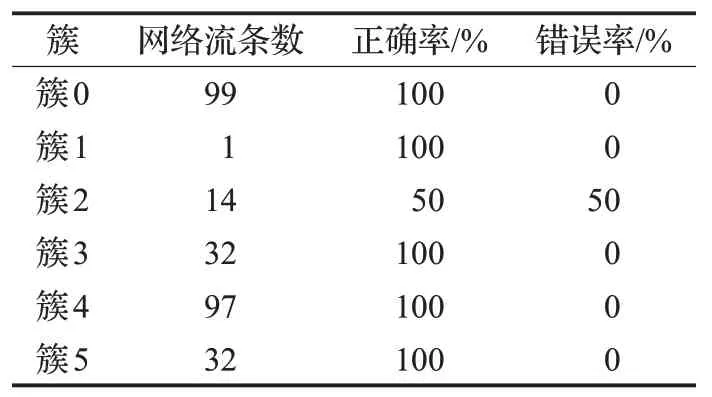
表7 EM聚类结果
对于MakeDensityBasedCluster算法,所有参数采用默认值。测试结果如表8所示。

表8 MakeDensityBasedCluster聚类结果
本文通过将结果与人工标记结果进行对比,得到四种聚类算法的聚类准确率,如表9。
实验结果表明本文方法在三种协议的聚类上明显优于SimpleKMeans 算法和MakeDensityBasedCluster 算法,在FTP协议的聚类上优于EM算法。
总体上看,通过实验结果可以看出,本文方法能够快速准确地将未知混合多协议分类为单协议数据,聚类准确率较高,并且无需训练,适合实际使用。
5 结束语
本文提出了一种基于自适应聚类的未知应用层协议识别分类方法,首先从采集的原始网络数据中重组出网络流,提取网络流的应用层协议数据载荷特征,进而计算应用层协议数据的相似度作为应用层协议识别分类的依据,利用聚类算法自动化地对网络流的应用层协议数据进行聚类,高效准确地实现未知应用层协议网络流量识别分类。方法充分利用了聚类算法的优势,避免了训练过程,高效准确,具有较高的实用价值。
本文方法存在的主要问题是无法对经过加密处理的网络流量进行识别分类。对于经过加密处理的应用层协议网络流量,由于其数据区域被加密处理过,其特征序列被打乱和隐藏,本文提出的方法并不能自动化提取出数据中的特征序列,无法计算其应用层协议间相似度。对于加密协议的识别,将是下一步研究的主要方向。
表9 四种聚类算法聚类准确率对比%
聚类算法SimpleKMeans EM MakeDensityBasedCluster本文算法HTTP 80.20 99.49 77.66 100.00 FTP 50 50 0 100 SMTP 50 100 0 100
[2] Moore A W,Zuev D.Internet traffic classification using Bayesian analysis techniques[J].ACM SIGMETRICS Performance Evaluation Review,2005,33(1):50.
[3] Bujlow T,Carela-Español V,Barlet-Ros P.Independent comparison of popular DPI tools for traffic classification[J].Computer Networks,2015,76:75-89.
[4] 汪立东,钱丽萍,王大伟,等.网络流量分类方法与实践[M].北京:人民邮电出版社,2013:122-126.
[5] Deri L,Martinelli M,Bujlow T,et al.nDPI:open-source high-speed deep packet inspection[C]//Proc of Wireless Communications and Mobile Computing Conference,2014:617-622.
[6] Karagiannis T.Blinc:multilevel traffic classification in the dark[C]//Proc of the 2005 Conference on Applications,Technologies,Architectures,and Protocols for Computer Communications.New York:ACM Press,2005:229-240.
[7] 谭骏,陈兴蜀,杜敏,等.基于自适应BP神经网络的网络流量识别算法[J].电子科技大学学报,2012(4):580-585.
[8] Wang W,Zhu M,Zeng X,et al.Malware traffic classification using convolutional neural network for representation learning[C]//Proc of the 2017 International Conference on Information Networking.Piscataway,NJ:IEEE Press,2017:712-717.
[9] 王勇,周慧怡,俸皓,等.基于深度卷积神经网络的网络流量分类方法[J].通信学报,2018,39(1):14-23.
[10] Wu D,Chen X,Chen C,et al.On addressing the imbalance problem:a correlated KNN approach for network traffic classification[C]//Proc of International Conference on Network and System Security.Cham:Springer International Publishing,2014:138-151.
[11] Jain A V.Network traffic identification with convolutional neural networks[C]//2018 IEEE 16th Intl Conf on Dependable,Autonomic and Secure Computing.Washington:IEEE Computer Society,2018:1001-1007.
[12] Ren J,Wang Z.A novel deep learning method for application identification in wireless network[J].China Communications,2018,15(10):73-83.
[13] 李林林,张效义,张霞,等.一种基于集成学习的流量分类算法[J].信息工程大学学报,2015(2):240-244.
[14] Munz G,Li S,Carle G.Traffic anomaly detection using K-means clustering[C]//GI/ITG Workshop MMBnet,2007:13-14.
[15] Mcgregor A,Hall M,Lorier P,et al.Flow Clustering Using Machine Learning Techniques[C]//Proc of the International Workshop on Passive and Active Network Measurement.Berlin,Heidelberg:Springer-Verlag,2004:205-214.
[16] Liu S,Hu J,Hao S,et al.Improved EM method for internet traffic classification[C]//Proc of the 8th International Conference on Knowledge and Smart Technology.Piscataway,NJ:IEEE Press,2016:13-17.
[17] 周文刚,陈雷霆,董仕.基于谱聚类的网络流量分类识别算法[J].电子测量与仪器学报,2013,27(12):1114-1119.
[18] Wang Y,Xue H,Liu Y,et al.Statistical network protocol identification with unknown pattern extraction[J].Annals of Telecommunications,2019,74(7):473-482.
[19] Lippmann R,Haines J W,Fried D J,et al.The 1999 DARPA off-line intrusion detection evaluation[J].Computer Networks,2000,34(4):579-595.
