结合负载均衡与A*算法的多AGV路径规划
2020-03-11赖乙宗赵雨亭
袁 洋,叶 峰,赖乙宗,赵雨亭
华南理工大学 机械与汽车工程学院,广州510000
1 引言
随着物流仓储业、自动化制造业的快速发展。AGV 在仓储物料搬运系统中发挥着越来越重要的作用[1]。庞大且复杂是目前的大规模AGV 道路网络的显著特征,由此引发的AGV 交通拥堵问题表露得愈发明显。研究表明,路网的路径选择过程会影响其传输能力。因此,可以通过优化动态路由选择算法,使其趋于高效稳定,以促进路网整体吞吐量及降低交通拥堵程度[2]。
路径规划方法主要有三类:图形搜索法、人工智能法和势场规划法。人工智能法进行路径规划的方法主要是Q-learning 算法,Q-learning 算法在随机动态环境的路径规划中有较好的应用,但其算法的收敛速度较慢、空间复杂度较大[3]。势场规划法进行路径规划具有较好的精度[4],但需要引入人工势场的概念,进行复杂的势能计算增大了算法实现难度。图形搜索算法是目前比较成熟的路径规划算法,其算法原理易于实现,在机器人路径规划领域得以广泛应用[3]。本文主要针对基于图形搜索法的并且在机器人路径规划领域中广泛应用的A*算法进行改进,提供一种能有效均衡区域负载的多AGV路径规划算法。
图形搜索法第一步构造图结构,在此基础上采取图搜索方法实现路径规划。图搜索法包括广度优先遍历、深度优先遍历、启发式算法、最短路径搜索算法等。图论中的最短路径问题与AGV 路径规划问题相关,其中包括单源最短路径问题、点对点的最短路径问题、多源多汇点最短路径问题、全源最短路径问题[5]。最短路径问题解法可用于求解单AGV路径规划中只求最短运行路径的情况。如需另行考虑AGV 之间的冲突、死锁现象,则是多AGV路径规划中出现的情景。Dijkstra算法是目前图搜索算法里单源最短路径算法中最经典的一种,A*算法则属于启发式搜索算法,广泛应用于移动机器人的路径预先规划[6]。D*算法是基于这些图搜索算法的众多改进算法之一。张伟等[7]分析了AGV 调度系统中的Dijkstra 算法应用,解决了仓储配送任务中的AGV 与任务匹配问题。张紫辉等[8]对未知环境下的路径规划问题进行研究。在机器人碰到未知障碍物的情况下,采用A*机器人路径规划算法,结合二次路径规划策略重新规划路径,进一步拓宽原算法的应用范围。Dijkstra 算法、A*算法都是常用且性能较突出的全局路径规划算法[9]。
拥堵问题对AGV 整体运行效率有重大影响,是多AGV路径规划中需要重点研究的问题。路径规划问题是机器人导航应用中最基本、最重要的问题[10]。路网的宏观基本图是道路网络的固有属性,反映了路网的总交通量和路网运行水平的关系[11]。宏观基本图是研究大规模路网车流量与车辆的主要工具,路网中车辆数量超过允许的极限值时,路网局部区域会陷入拥堵状态,车辆运行效率会受到影响,因此均衡路网中的负载至关重要。
本文针对多AGV在规则路网的路径规划问题展开研究,研究多AGV 在运行时单个AGV 的路径规划问题。提出一种考虑局部拥塞程度的基于A*的AGV 路径规划算法,将路网负载引入到A*算法的评价函数中,避免多AGV 路径规划时产生局部车流量过大的情况,最后使用仿真实验说明了算法的有效性。
2 基于图搜索的A*算法
2.1 传统A*算法
在数学中,图定义为一个二元组(V,E),其中V 称为顶点集,E 为边集。E 中的每一个元素,即每个边,使用一对顶点表示,如果一个边连接了顶点a 和顶点b,则可以用a-b 表示这个边。在图中,路径是由边连接的一系列顶点。图的表示方法主要有邻接矩阵、邻接表数组两种方式。邻接矩阵适用于稠密图,邻接表适用于稀疏图。
A*算法是一种在图中的启发式搜索算法,引入了最优启发式函数,可以在搜索过程中避免盲目性[12],其表达式如式(1):

令x 表示某个节点,f*(x)为x 的最优评价函数;目的是使得f*(x)最小。g*(x)是从初始节点到x 节点的最小代价,h*(x)是从x 到目标节点的所有路径中的最小代价。
因为f*(x)无法预知,一般使用实际加估计的方式做近似如式(2):

在式(2)中,f(x)是近似处理后当前节点x 的评价函数;g(x)是起点到当前节点x 节点的实际路径代价,h(x)是从当前节点x 到目标节点的估计路径代价。
当使用f(x)代替f*(x)时,实际为使用g(x)代替g*(x),使用h(x)代替h*(x),需要满足的条件为h(x)<h*(x),即A*算法的启发函数值要始终小于等于实际最小路径代价。
当使用两点之间的距离作为代价时,便需要衡量点之间距离的算法。衡量点之间距离最常用的是闵可夫斯基距离。当有两点P 和Q,坐标如式(3)和式(4)时:

P 和Q 之间的闵可夫斯基距离L 可以由式(5)表示:

当p=2时,称距离L为欧几里德距离(Euclidean distance),当p=1时称距离L为曼哈顿距离(Manhattan distance)。
2.2 基于A*算法且考虑局部区域拥塞程度的路径规划算法
本节的目标是在已知的环境情况下,为待规划路径的AGV规划一条从AGV原始位置到目标位置的路径,以提高AGV 系统的效率。在目标的指导下,考虑了一种AGV 的局部拥塞下的判别方式,并在考虑局部拥塞程度的基础上,设计了基于A*的路径规划方法对AGV进行路径规划。
2.2.1 拥塞对AGV路网运行的影响
研究表明,在路由选择策略确定的情况下,当单位时间内产生的交通负载量超过该确定值时,网络交通流快速陷入拥塞状态[2]。局部拥塞最大的原因是交通流分布存在不均衡,某些路段已经达到瓶颈状态,而有些路段处于非饱和或车流稀少的状态[13]。因此避免单位节点出现过大负载是解决拥塞的关键。
在研究路网的宏观问题中,宏观基本图[14](Macroscopic Fundamental Diagram,MFD)是一个非常重要的工具,它用于描述路网交通流宏观变量间的关系模型[15]。体现一定区域内车辆流出量(车辆完成率)和车辆的累积数量的关系,如图1所示[16]。
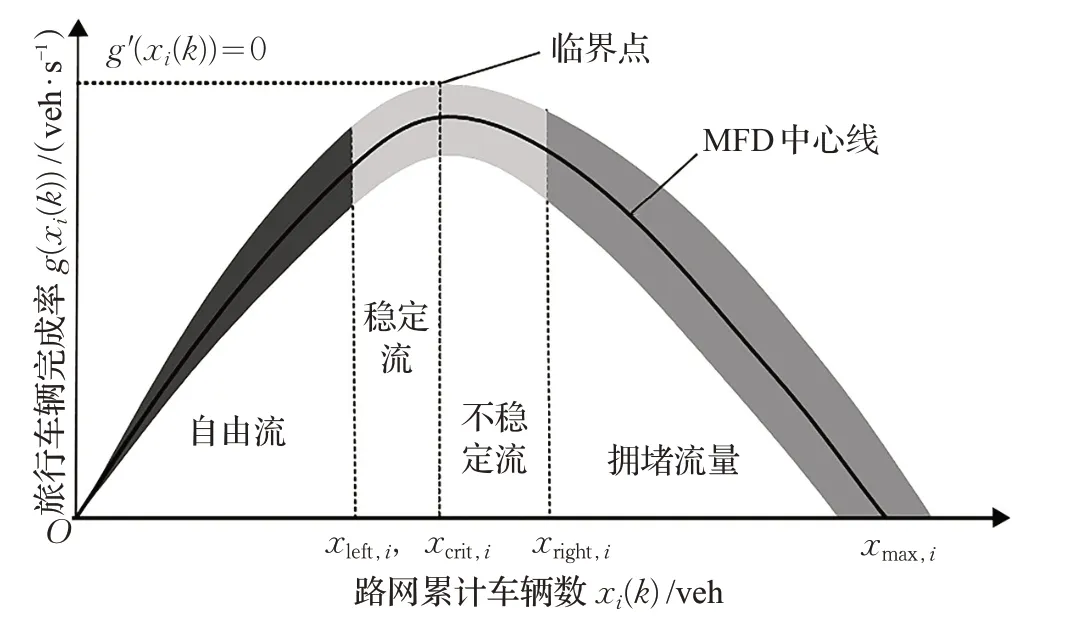
图1 宏观基本图
在MFD 中,横轴为路网中某区域一段时间内累计车辆数,即在某区域中存在的车辆数;纵轴为旅行车辆完成率,即车辆流出率,表达的是在区域边界上每秒流出的车辆数。根据局部区域路网中存在的车辆数,交通流可归为四类:自由流、稳定流、不稳定流、拥堵流量。
MFD 的图形如图1,其形状与抛物线类似,从其图形可以分析累计车辆数(横轴xi(k))与车辆完成率(纵轴g(xi(k)))之间的约束关系,当xi(k)=0 时,g(xi(k))=0;当xi(k)路逐渐增加,g(xi(k))也同步增加,并逐渐达到最大值,该最大值点是稳定流向不稳定流转变的临界点。该临界点过后,随着xi(k)不断增大直致超过不稳定流状态下的最大值,交通流由不稳定流状态转变为拥堵状态。当xi(k)增大至某一特定值xmax(k),道路进入完全拥堵状态,此时g(xi(k))=0,无车辆流出。
由MFD 可以看出,拥堵会严重影响路网内车辆的运行效率。
2.2.2 单向多入多出路网模型和双向多入多出路网模型
仿真是交通效率和安全性能评价的重要手段[17]。单向和双向的多入多出路网模型可用于对不同路径规划算法下路网负载情况进行仿真研究。n×n 路网模型包含了n×n 个子区域。单向多入多出路网模型和双向多入多出路网模型的区别在于车辆驶入方向不同,前者车辆从一侧的n 个子区域中之一驶入,后者车辆从随机一侧的n 个子区域中之一驶入,两者车辆都是从另一侧n 个子区域中之一驶出。
图2是单向多入多出路网示意图。该13×13路网示意图中,圆代表子区域,连通的子区域通过在两圆心之间连线表示,AGV在路网外部的运行方向采用箭头标识。
图3 为一个13×13 的双向多入多出路网示意图。示意图中圆、连线和箭头的涵义同单向多入多出路网示意图。

图2 13×13单向多入多出路网示意图
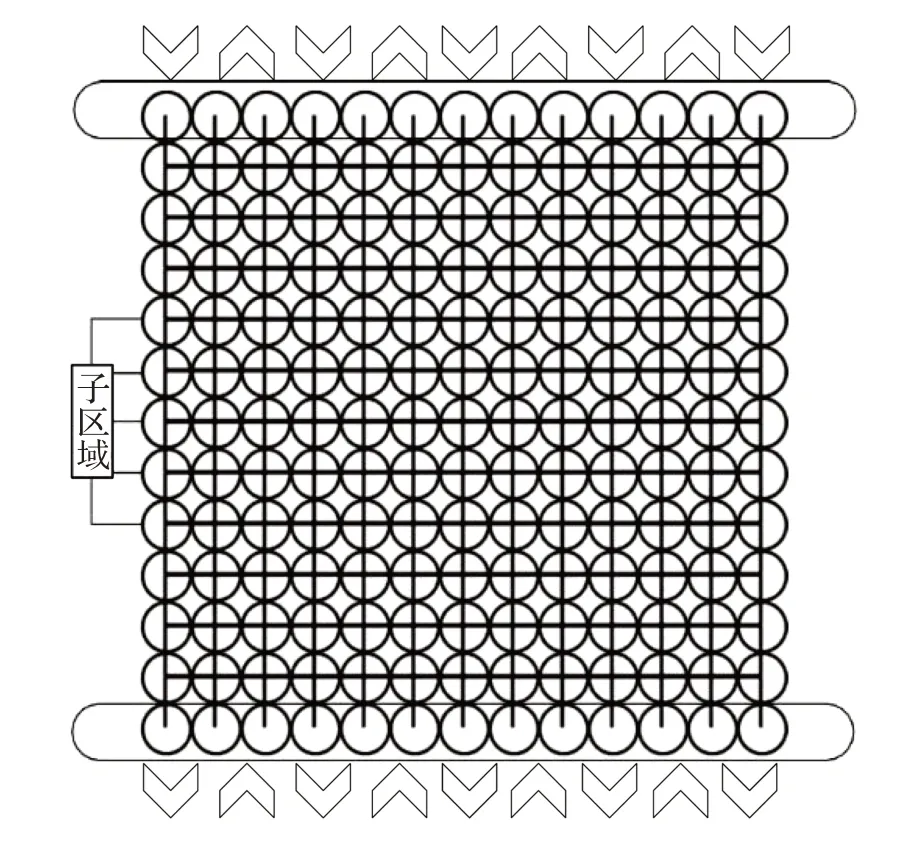
图3 13×13双向多入多出路网示意图
单向多入多出路网模型中,AGV执行任务时,从一侧(北侧)13个中选择一个作为入口驶入,从另一侧(南侧)13个中选择一个作为出口驶出。
双向多入多出路网模型中,AGV执行任务时,从随机一侧(南侧或北侧)随机一个口驶入,从对面出口中的随机一个口驶出。
在区域路网负载的研究中,通常按照如下的三个步骤展开:
(1)AGV 执行任务时的出入口位置采用随机生成的方法,生成多种组合方式。
(2)结合出入口位置进行路径规划。
(3)统计路网子区域内经过该区域的规划路径条数作为该子区域负载,然后统计所有子区域负载作为路网负载,观察路网负载规律。
2.2.3 A*路径规划算法下路网负载情况
如图4为经典的A*算法流程图,其核心思想为通过维护两个节点元素集合开集OpenSet和闭集CloseSet以及对于有关节点的松弛操作得到最终结果。

图4 A*算法流程图
测试中,A*算法采用距离作为评价函数,对多个AGV分别进行路径规划。g(x)表示从起点到当前x 节点的实际距离,h(x)表示从当前x 节点到终点的欧几里德距离。
测试中区域的负载统计包含了4 000个任务的路径规划结果。在单向多入多出路网模型中所有任务的起始位置在第一行随机选取,目标位置在最后一行随机选取。图5和图6分别是在5×5和13×13的单向多入多出路网模型下仿真实验得出的路网负载情况。

图5 5×5单向多入多出路网负载
由图5、图6可知,负载过高的区域集中在中部位置的出口行附近,而在入口行附近,负载比较均衡而且负载较低。
对多个AGV 分别在5×5 和17×17 单向多入多出路网模型中进行路径规划测试,其结果分别如图7 和图8所示。由图可得,传统A*算法在单向多入多出路网模型下进行规划路径时,会在接近出口区域时在左右方向上移动,从而更靠近出口,进而会导致靠近出口处区域的负载较大。
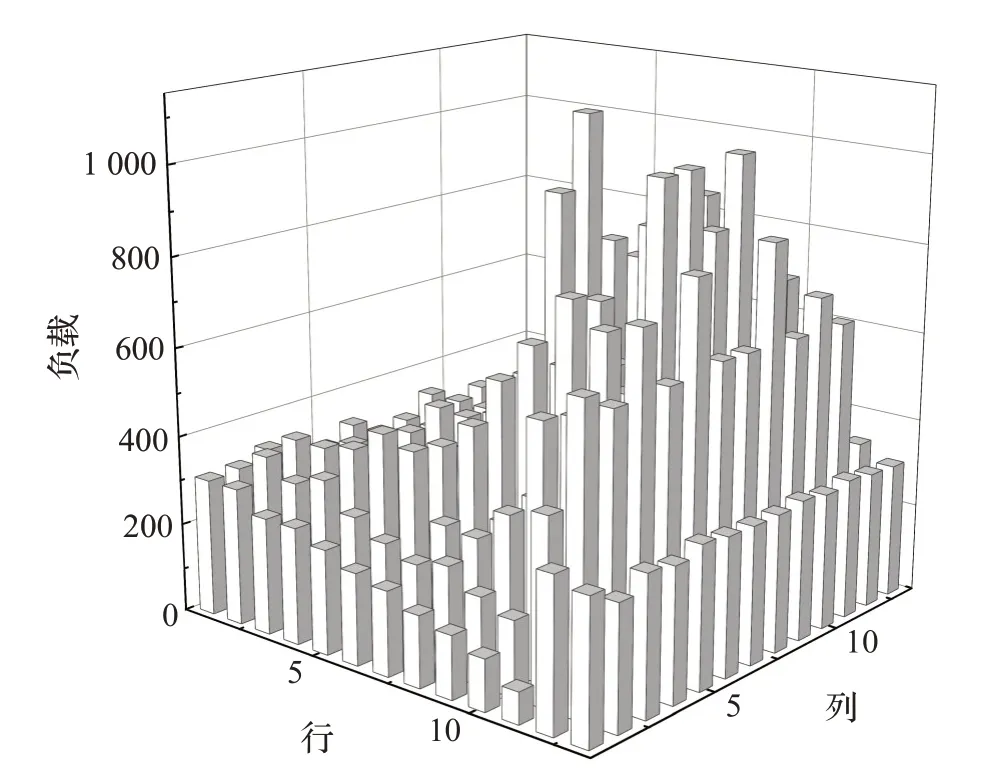
图6 13×13单向多入多出路网负载

图7 5×5路网下两个路径规划实例

图8 17×17路网下两个路径规划实例
综上,在使用传统的A*算法即未考虑负载均衡情况下,会出现负载过高区域集中在靠近出口处的情况,并且负载在靠近出口的行呈现类似钟形曲线分布,出口行左右方向上靠近中部的区域负载也会显著高于其他区域。负载高的区域发生拥堵的几率更大,从而会造成AGV系统运行效率低下,进而影响整体AGV系统运行。
3 考虑负载均衡下AGV路径规划方法及路网负载
考虑负载均衡下的AGV路径规划方法实质是在传统的A*算法基础上,将负载因素考虑到实际路径代价中,即对新的代价函数g(x)进行改进,引入负载因素,可由式(6)表示:

其中,l(x)表示从初始节点到节点x 的实际距离,load(x)表节点x 的负载。α 是将负载转换为负载代价的转换系数,后续实验中,测试不同的α 值,以求得最优α 值。当α=0 时即为不考虑负载均衡的情况。
仿真实验原理如下:保持4 000个AGV任务的起点和终点不变,对比考察考虑负载均衡情况下不同的负载系数的路网负载情况,当负载系数为0时是传统的A*算法,即为不考虑负载均衡。
在实现步骤上,首先对第一台AGV 使用考虑负载均衡改进的A*算法的路径规划方法进行路径规划,然后根据本次路径规划的结果对路网中的负载数据进行更新,在此更新后的路网负载基础上,对后续AGV依次使用相同方法进行路径规划并且更新路网负载,直至所有的AGV完成路径规划,并对路网更新为止。
在单向的多入多出路网模型进行实验。在式(6)中,令α=0 时即为不考虑负载均衡的情况。在10×10的单向多入多出路网模型中分别设置α 值为0、1 进行实验,以上两种路网模型下路网负载情况分别如图9、图10所示;在没有负载均衡的情况下,单向多入多出路网模型中的车辆负载会出现在靠近出口行中部集中的情况,而负载系数α 为1 的情况下,路网中的车辆负载明显均衡。负载均衡改进的A*算法在单向多入多出路网模型中具有较好的负载均衡效果。
在双向的多入多出路网模型进行实验。在20×20的双向多入多出路网模型中分别设置α 值为0、10 进行了同样的实验。两种路网模型下路网负载情况分别如图11、图12 所示。由图对比可知负载均衡改进的A*算法在双向多入多出路网模型中具有较好的负载均衡效果。
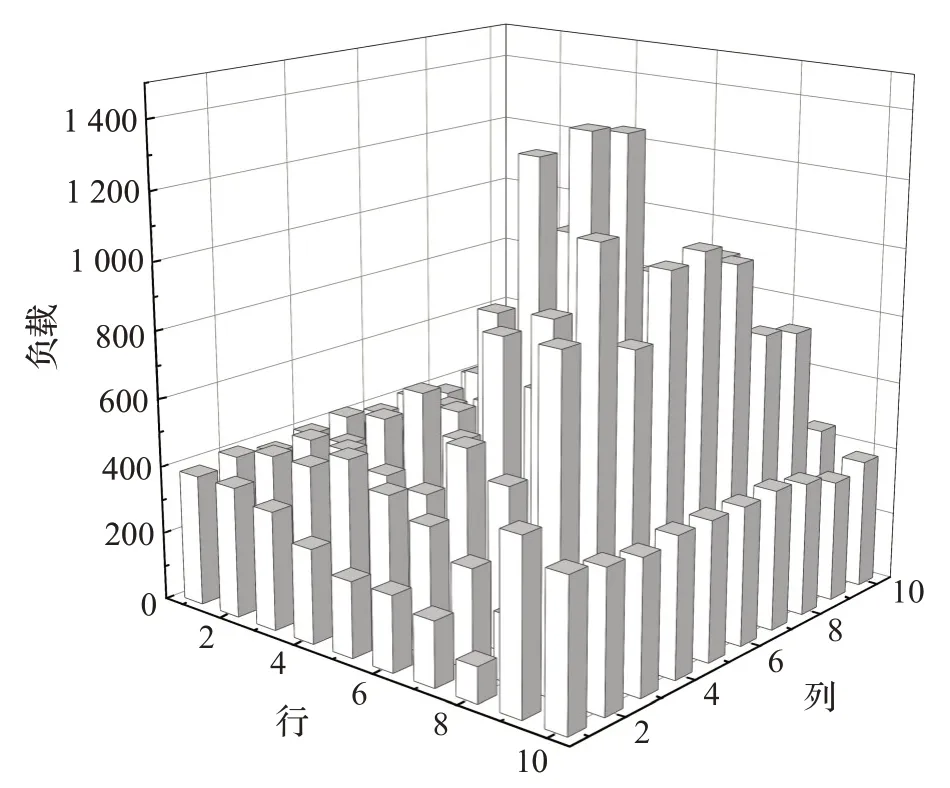
图9 α=0 下10×10单向多入多出路网区域负载

图10 α=1 下10×10单向多入多出路网区域负载
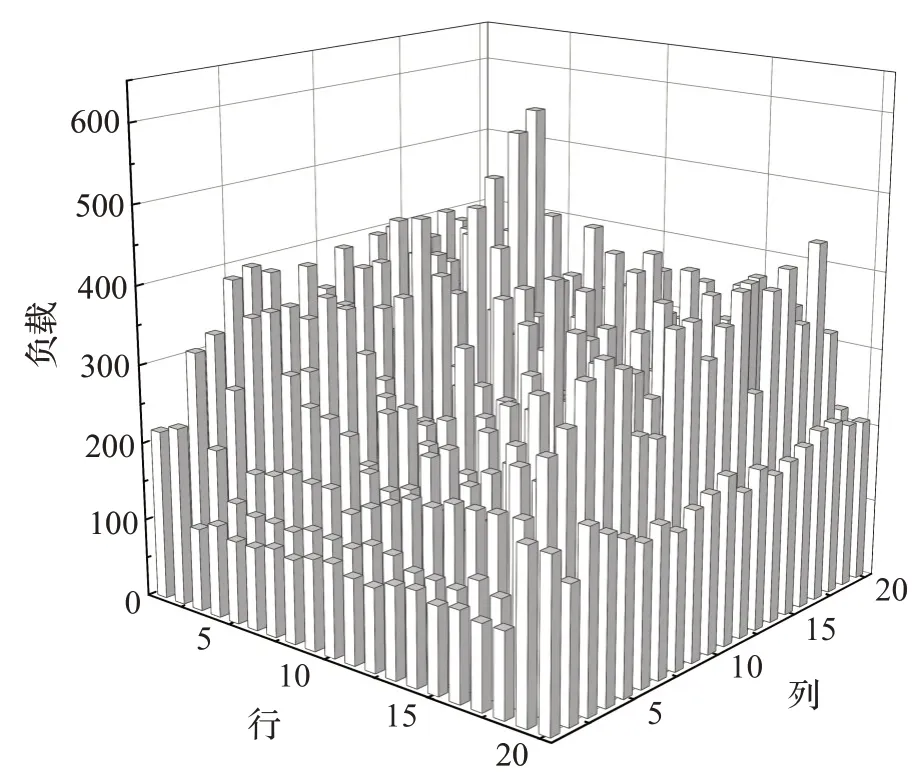
图11 α=0 下20×20双向多入多出路网区域负载

图12 α=10 下20×20双向多入多出路网区域负载
可以看出,在两种路网模型下,随着α 值的增大,路网区域负载逐渐趋于稳定。在α 值增大至某一特定值后,除处于入口行和出口行区域外,处于中间行的区域负载基本相同。由于入口行和出口行仅由随机生成的任务决定,考虑负载均衡与未考虑负载均衡情况下,近入口行和近出口行的区域路网负载是几乎没有变化的。由路网中间的区域负载情况可知,在单向或双向的路网模型下由负载均衡改进的A*算法均具有较好的负载均衡效果。
由于负载均衡的引入,有效地均衡了区域负载,但是可能会导致某些AGV在路径规划的时候避开最短路径从而导致路网整体的负载增加。为研究负载均衡的引入给路网整体负载带来的影响,针对单向多入多出和双向多入多出路网模型做了多次实验。得出路网负载标准差和路网区域平均负载在引入负载均衡前后的变化程度如表1~表4所示。

表1 单向多入多出路网下模型区域负载标准差
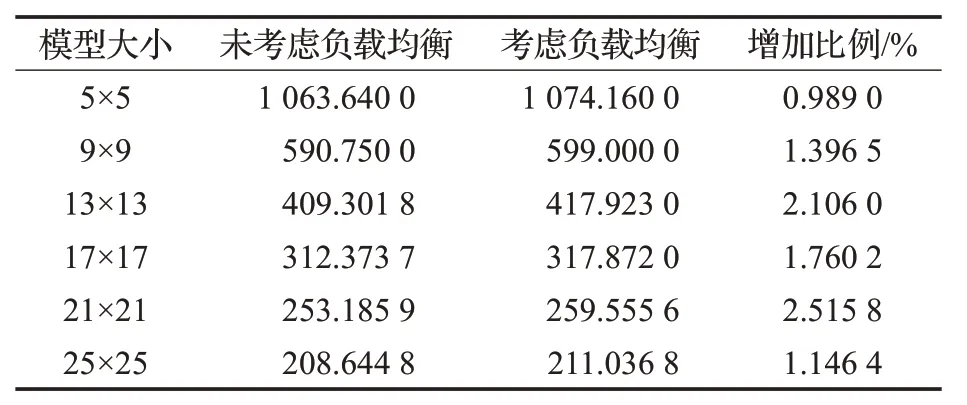
表2 单向多入多出路网下模型区域平均负载
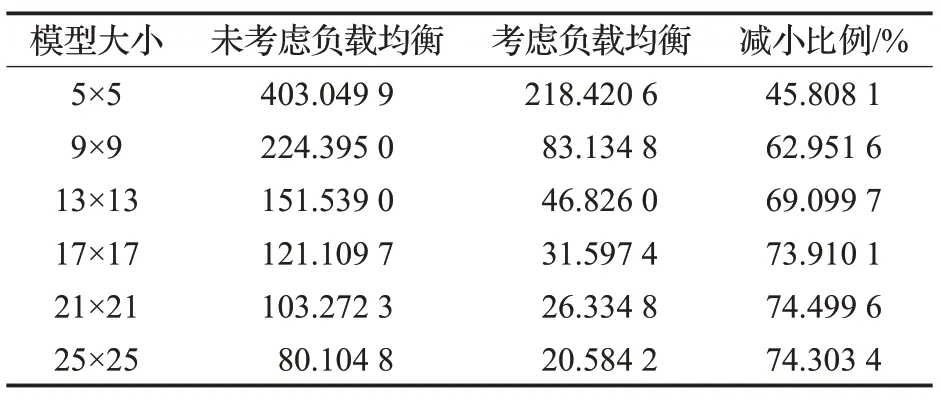
表3 双向多入多出路网下模型区域负载标准差

表4 双向多入多出路网下模型区域平均负载
对比表1与表2,在单向多入多出路网模型中,引入负载均衡后区域负载标准差大大减小,而平均负载增加的比例几乎可以忽略。对比表3 与表4,在双向的多入多出路网模型中情况一样。可以看出,在引入负载均衡后,路网平均负载有微量的增加,而路网负载的标准差明显下降。因此引入负载均衡后能够保证路网平均负载微量增加的情况有效地均衡路网负载。
4 结语
本文针对大规模AGV路网下区域负载不均衡以及造成的拥塞问题,提出了考虑负载均衡改进的A*算法,实验证明了所提方法在均衡路网区域负载上的有效性。通过将负载转化为A*算法中代价函数的一部分,在路网平均负载微量增加的情况下能够均衡负载,从而有效避免局部拥塞问题,大大提升了AGV的运行。
