面向人工林经营的模型库和方法库服务平台*
2020-03-04吴保国王姗姗苏晓慧陈玉玲李宜瑾
陈 栋 吴保国 王姗姗 苏晓慧 陈玉玲 李宜瑾
(1. 北京林业大学信息学院 北京100083; 2. 国家农业信息化工程技术研究中心 北京100097; 3. 中国联通网络技术研究院 北京100048)
近年来,人们对造林、抚育间伐、更新等阶段的人工林经营模型研究逐步深入,模型规整、推广和应用的方式方法也备受关注,随着信息技术不断发展,面向人工林经营的决策支持系统成为了模型应用的有力渠道。决策支持系统(decision support system,简称DSS)概念自提出以来,其基本结构不断发生变化: 早期的决策支持系统是由模型库、数据库和人机交互界面3个部件构成的两库结构; 随着研究的深入,将算法从模型库中独立出来构成方法库,扩展成三库结构; 在此基础上,学者们又引入知识库,形成四库结构。这种四库结构一直沿用至今,其中模型库和方法库是存储决策支持系统决策所需各种模型和决策方法的数据库。林业行业20世纪80年代末期开始了决策支持系统的探索(宋铁英, 1990; 李际平, 1991; 1994),进入21世纪,林业决策支持系统的相关研究如雨后春笋般涌现,国内外研究者相继构建了针对某一应用场景下的林业决策系统原型(吴保国等, 2006; 2009a; 2009b; 杨英奎, 2015; 沈立辉, 2015; 谢黎等, 2008; 谢小魁等, 2011; 李勇等, 2003; 李大伟等, 2010; 王琳等, 2006; 薛晶, 2008; 石磊等, 2007; 肖劲锋等, 2001; Wangetal., 2008),目前决策支持系统的应用范围已经扩展到林业各个领域。由于森林经营决策领域的模型众多,且对统计学方法依赖性较强,因此模型库和方法库对森林经营决策支持系统的作用显得尤为重要。Ren等(2014)构建南方人工林模型系统,存储了经营、效益等模型; 李勇等(2003)研究了一类DSS方法库的可重用体系结构; 李大伟等(2010)对决策支持系统的模型库和方法库进行了概要设计。随着计算机技术不断发展,基于Web Service以及SOA架构的B/S模型库系统相继出现(Richardsonetal., 2006; 陈砣等, 2009; Ayedetal., 2016; Rauscheretal., 2000; Soufietal., 2018; Zhuetal., 2007; Newton, 2015; 郑广成, 2011),大大提升了模型库系统的管理水平。森林经营领域,王琳等(2016)从树木生长模型分类入手,对模型的构建、存储、管理等流程进行了研究; 吴保国等(2009a; 2009b)为实现森林培育专家决策,构建了适用于单一树种的模型库。综上可见,现有森林经营决策系统中模型库的设计只考虑了数学公式型模型,没有涉及程序型模型(如基于人工神经网络的应用模型),且往往针对的是某一树种或特定决策过程,缺乏通用性; 而且,在森林经营决策系统中应用的方法多以嵌入程序的形式存在,大大增加了方法管理的复杂度; 此外,在模型与方法的统一管理、依托方法库的模型更新以及基于Web技术的面向大众和应用的模型与方法服务等方面鲜见研究报道。
针对以上现状,本研究在分析人工林经营模型结构和构建方法的基础上,为降低模型和方法存储与管理的复杂度,增强模型存储的通用性和方法管理的便捷性,结合森林经营模型和方法的特征,利用面向服务和数据耦合思想,将模型库和方法库与决策系统解耦,分别设计模型库和方法库关系模式,构建面向服务的模型库和方法库平台系统原型,以期为人工林经营过程提供模型和方法的计算、调用和共享服务。
1 人工林经营模型库研究
1.1 人工林经营模型分类
模型是人类认识自然、改造自然的强有力工具,几乎所有领域都在不约而同地应用模型来解决其领域问题。人工林经营领域积累了大量数学模型,涵盖造林、抚育、间伐、经营优化、更新等经营阶段,主要包括立地质量评价模型、生长收获模型、形态生长模型、效益评价模型等数学方程式模型,以及利用神经网络等机器学习方法构建的程序块模型,如表1所示。
1.2 人工林经营模型表达方式和存储模式
为解决模型库的通用性问题,本研究针对不同模型形式的存储和解析展开探索,设计适用于不同树种的数学方程型和程序块型的存储关系模式。为了方便存储、管理和调用人工林经营模型,采用“数据表示法”和“程序表示法”分别表示数学方程型和程序块型模型。
数据表示法将数学公式以字符串形式存储在关系数据库中,如内蒙古赤峰地区华北落叶松(Larixprincipis-rupprechtii)地位指数模型的表达方程(韩焱云, 2015):SI=Ht×{0.81÷[1-exp (-0.056t)]}1.36,在模型表“模型代数表达式”字段中存储的公式字符串为“HT*(0.81/[1-EXP(-0.056*T)])^1.36”,解析公式时首先需要通过词法分析识别字符串中的运算符,然后通过语义分析验证公式的语义正确性,验证通过后利用逆波兰式对公式进行计算。

表1 人工林经营决策支持模型分类Tab.1 The decision support model classification of artificial forest management
程序表示法将模型与计算机程序融为一体,每个模型对应一套完整程序,如人工神经网络构建的林分蓄积量模型等,模型实现基本使用统计程序语言进行编写,将模型整理为程序包文件,在模型表的“模型程序包存放地址”字段中存储程序包文件的路径,解析公式时通过路径获取程序包文件,经解析后得到模型结果。
针对以上2种模型表示方式,结合人工林经营模型特征,构建模型库关系模式(王珊等, 2006),并使用关系型数据库(本研究使用SQL Server2008数据库)存储2种方式表示的模型。关系模式如下:
模型表(模型编号、模型名称、模型分类、模型形式、树种名、适用地区、模型描述、模型代数表达式、模型程序包存放地址、模型变量名列表、模型作者姓名、所属国家、作者电子邮件、最后更新时间,备注);
模型调用记录表(模型编号、调用日期、调用用户编号、模型输出结果、备注)。
模型表用于对模型全方位表述,其中,模型分类: 模型分类的名称(按表1中模型分类名称进行分类); 模型形式: 包括“数据表示”和“程序表示”2种; 模型代数表达式: 若模型形式为“数据表示”,则填写模型由数学方程式公式改写的公式字符串表达式,否则为空; 模型程序包存放地址: 如果模型形式为“程序表示”,则存储模型程序包存放的相对路径,否则为空; 树种名: 代表此模型适用于具体哪种树种; 模型变量名列表: 模型中的变量英文字符,用逗号分隔; 备注: 说明模型适合条件。
模型调用记录表用于记录模型的使用记录,以方便对模型使用进行分析。表中调用用户编号为模型调用中系统用户编号,模型输出结果记录每次调用模型产生的结果。
表2所示为部分人工林经营所需要的模型具体存储示例,系统管理员可以根据需要修改、增加、删除模型。

表2 模型表中的存储示例Tab.2 Sample storage in a model table
1.3 模型解析方法
针对数据表示和程序表示2种模型,前者通过规定模型表达式的基本语法规则,使用词法分析、语法分析、语义分析和表达式计算实现解析过程; 后者使用R语言对模型进行实现,通过Rsession调用R程序包实现模型计算。设计模型解析流程如图1所示。在解析流程中,首先根据传入的模型ID去模型库中查询具体模型,然后调出模型信息,判断模型是数据表示模型还是程序表示模型,若为数据表示模型,则进入程序数据解析流程,反之进行程序模型解析流程。
1.3.1 “数据表示”模型解析 1) 词法分析 词法分析是读取字符串形式的模型表达式,并将其分成一个个独立的词法单元token,如数字、操作符或函数等,构成单词符号序列token流。以内蒙古赤峰市华北落叶松在立地质量为优时平均高模型表达方程20.597×[1-exp (-0.055t)]1.344为例(韩焱云, 2015),模型解析的词法分析过程如图2所示。

图1 模型解析流程Fig.1 Model analytic flow diagram
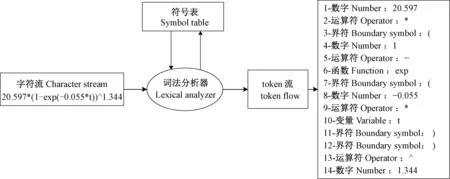
图2 模型表达式词法分析过程Fig.2 The lexical analysis process of model formula
2) 语法分析 语法分析是对词法分析获得的token流进行识别并判断其是否存在语法错误,如操作数个数是否符合、左右括号是否匹配等。本研究采用上下文无关(context free grammar,CFG)文法对其进行语法分析。
以华北落叶松在立地质量为优时平均高模型表达方程20.597*[1-exp(-0.055*t)]^1.344 为例,该模型的文法G1包含以下产生式:
G1: E->E-E|E*E|exp(E)|E^E|(E)|i
基于G1文法,采用最左推导,可以推导出i*((i-exp(i*i))^i),推导过程如下:
E->E*E->E*(E)->E*(E^E)->E*(E^i)—>E*((E)^i)->E*((E-E)^i)->E*((E-exp(E))^i)->E*((E-exp(E*E))^i)->E*((E-exp(E*i))^i)->E*((E-exp(i*i))^i)->E*((i-exp(i*i))^i)->i*((i-exp(i*i))^i)
E代表算数表达式,i为数字或变量标识符。
语法分析树如图3所示。语法树根节点为开始符E,叶节点为终结点。通过自顶向下的语法分析算法对语法树进行遍历,并最终判断语法的正确性,从而检验方程式表达式的正确性。

图3 语法分析树Fig.3 Parse tree
3) 语义分析与模型计算 语义分析是在语法分析基础上进一步对模型表达式的运算对象进行逻辑检查,如除数不能为0等; 同时利用逆波兰式进行模型表达式计算。通过构建存储器和符号栈,存储数据和操作符。存储器从左向右存储数据,而符号栈遵循先进后出的原则,从左向右扫描模型表达式生成逆波兰式,从而计算逆波兰表达式,完成模型计算。
4) 模型解析核心流程实现 基于以上研究,数据表示模型解析核心流程实现包括词法分析、语法分析和模型计算。具体实现如下:
①词法分析函数: LexicalAnalysis(String modelstring),输入的是模型公式字符串,返回的是单词符号序列Map;
②语法分析函数: GrammaAnalysis(Map tokenmap),输入的是单词符号序列Map,返回的是Boolean值(公式是否有语法错误,没有返回true,有返回false);
③ 步骤①、②是对模型公式正确性进行校验,如返回true,则使用Java的ExpressionEvaluator类的eval方法对模型公式进行计算; 如返回false,则提示错误信息。
1.3.2 “程序表示”模型解析 程序包式模型类似于黑盒模式,直接输入模型参数值,调用程序输出结果即可完成模型计算。本研究将此类模型封装在R语言程序包(王斌会, 2014)中,使用Rserver的Rsession对象调用封装好的程序包。程序表示模型解析核心流程实现如下:
① 从模型表的模型读取程序包存放地址字段,通过RserverConf对象连接Rserver服务器,获取存储在Rserver服务器上的模型程序包。
② 使用Rsession对象解析模型程序包,将参数代入。
③ 使用Rsession对象中的eval方法计算模型结果返回。
2 人工林经营方法库研究
2.1 方法库中的方法组成
方法是指在自然科学领域中所采用的基本算法和过程,如图4所示,包括基本数学方法、统计学习方法、优化方法和预测方法等。目前常用的做法是将方法嵌入业务程序中,但该做法会增加方法维护管理的复杂度。为了将方法代码和业务代码解耦,引入Rserver和Rsession将方法代码用R语言实现并封装。
2.2 方法库设计
为了方便对方法库的方法进行管理和调用,决策支持系统中的方法库由方法程序库和方法描述表组成。方法程序库以文件形式存储方法程序块,方法描述表存储方法描述信息,采用关系型数据库的关系存储。
2.2.1 基于R语言的方法程序库设计 统计学习方法是人工林经营模型生成和更新的常用方法,本研究以林业常用回归方法为例,采用R语言依次对方法进行程序包开发,并将方法程序以R执行文件形式保存。每种方法生成一个R语言程序包,存储在对应的文件夹下,具体如表3所示。
2.2.2 方法描述表设计 为了方便对方法库的方法进行管理和调用,方法描述表中需要存储方法的描述信息和方法程序包的调用地址。另外,为了记录方法库的使用情况,需设置一种方法调用记录表。具体表的关系模式如下:
方法描述表(方法编号、方法名、方法说明、参数组成、输出值类型、是否方法组合、组合方式、组合编号、组合方法执行顺序号、程序包路径、备注);
方法调用记录表(方法编号、调用日期、方法输入数据、方法输出结果、备注)。
在方法描述表中,程序包路径字段存放R语言程序包的路径,方法被调用时,系统会根据该路径去获取方法程序包运行。
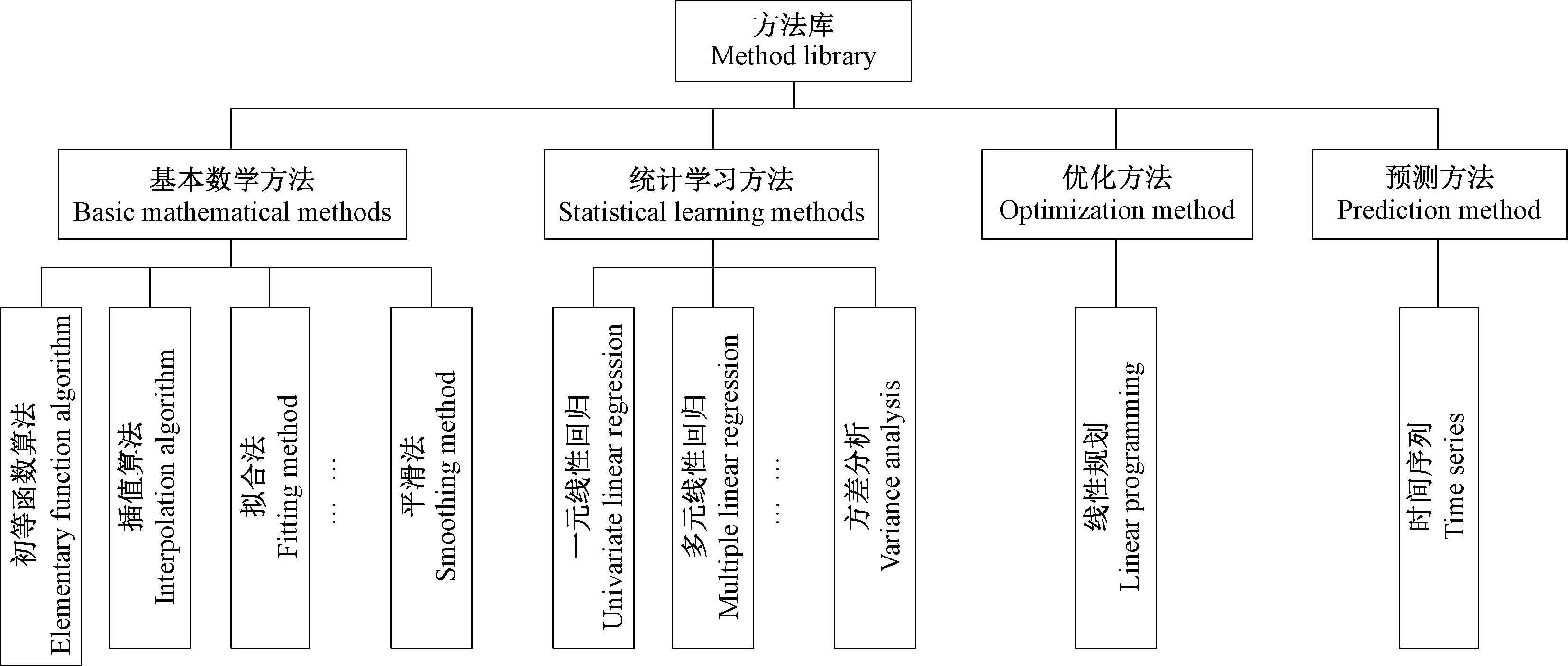
图4 方法库中的方法模块Fig.4 Method module diagram in method library

表3 基于R语言的方法程序①Tab.3 A list of methods programs based on the R language

续表3 Continued
① “—”表示此内容本研究暂未涉及。“—”indicates that this study is not yet relevant.
2.3 方法解析流程
方法库中各方法使用R语言程序进行封装,通过Rserver服务器进行发布,并将方法的描述存入关系型数据库中,调用通过Rsession完成,如图5所示。
方法解析流程是查找方法运行计算结果的过程。首先根据传入的方法ID去方法库中查询具体方法,然后调出方法信息,提出方法程序包,将实参输入,使用Rsession调用并执行程序包文件,计算出结果后将结果转化为标准数据传输格式输出。具体的方法解析流程如图6所示。

图5 方法库调用示意Fig.5 Method call diagrammatic sketch
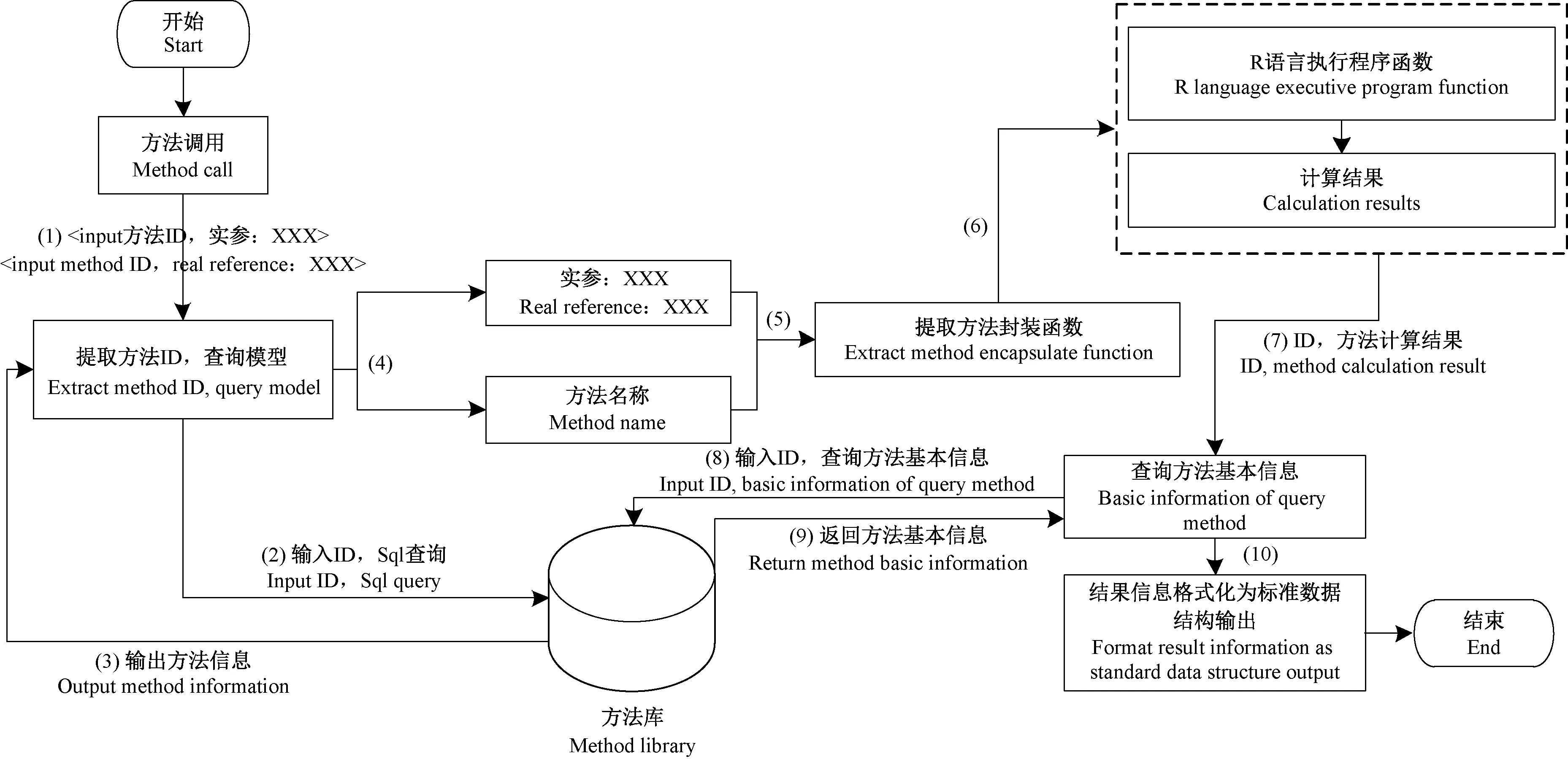
图6 方法解析流程Fig.6 Method call flow diagram
3 模型与方法库平台服务模式
3.1 面向服务的模型与方法库平台结构

图7 模型与方法库平台系统结构Fig.7 The model library and method library management system structure
为了满足模型与方法的统一管理,并实现面向大众和应用的模型与方法服务,设计模型与方法库平台的系统结构。如图7所示,模型库与方法库系统分别提供了基于API调用的接口服务和用户使用界面,前者为人工林经营决策支持系统提供模型管理、计算与方法管理、运算服务, 后者为系统使用者提供模型查询计算与方法查询计算功能。另外,模型库和方法库管理系统之间设计中间件,实现对模型库的更新。
模型与方法库平台系统原型的研建使用Java EE、Spring MVC、Hibernate、Jquery与Bootstrap等技术开发实现,模型与方法的调用使用基于HTTP协议构建的API。系统技术架构如图8所示。
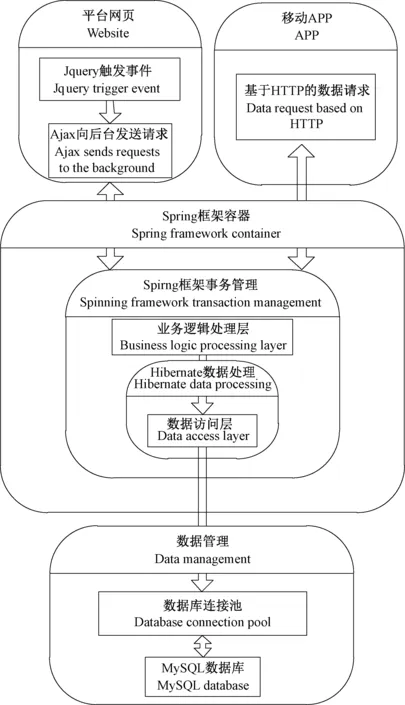
图8 系统技术架构Fig.8 Technical architecture of subsystem
3.2 面向服务的统一数据交互结构设计
模型与方法库平台系统结构采用独立的2种方式(API和界面)调用模型与方法,无论是以API方式还是以界面方式调用模型与方法,都需要提供查询和计算功能。实现这2种方式,必须有良好的数据交互结构,因此设计面向服务的统一数据交互结构是实现模型与方法服务模型的基础。本研究在模型与方法基本结构的基础上,利用符号化表达法以及标准数据传输结构,设计模型调用和方法调用过程中的数据传输格式。
1) 模型调用过程中数据传输格式 调用模型库中的模型时,数据传输格式采用符号化方法对模型进行表达,格式如下:
ForestryModel=(ModelDic,ModelDes,ModelResult,Time)。
式中:ModelDic是模型基本描述信息; ModelDes是模型具体信息; ModelResult是模型计算结果; Time是模型调用时间。
ModelDic=(ModelId,ModelName,ModelClassName,ModelForm,ModelTreeName,ModelArea,ModelExplain,ModelAuthors,Country,Email,Remark)。
式中:ModelId∈Integer是系统内部定义的模型编号;ModelName∈String是模型名称;ModelClassName∈String是模型类别名称;ModelForm∈String是模型形式(数据表示、程序表示);ModelTreeName∈String是模型适合的树种名称;ModelArea∈String是模型适合的地区名称;ModelExplain∈String是对模型的解释说明;ModelAuthors∈String是模型作者;Country∈String是模型作者所在国家;Email∈String是作者邮件地址;Remark∈String是模型表述的备注信息。
ModelDes=(ModelId,ModelAlgebraicExpression,ModelParams,Remark)。
式中:ModelId∈Integer是系统内部定义的模型编号;ModelAlgebraicExpression∈String是模型的代数表达式(如果模型使用的是程序包,则填“无”,并在Remark中填入“程序包”);ModelParams∈String是模型的自变量参数列表;Remark∈String是模型表述的备注信息。
ModelResult∈String,是模型调用后的结果。
Time∈Date,是模型调用时的时间戳。
基于以上分析,使用轻量级数据交换格式JSON(JavaScript Object Notation)作为数据传输格式。定义模型调用的数据传输格式如下:
{"ForestryModel":
"ModelDic":{ ∥模型基本描述信息
"ModelId":"XXX", ∥模型编号
"ModelName":"XXX", ∥模型名称
"ModelClassName":"XXX", ∥模型类别名称
"ModelTreeName":"XXX", ∥模型适用树种名称
"ModelArea":"XXX", ∥模型使用地区名称
"ModelExplain":"XXX", ∥模型解释说明
"ModelAuthors":"XXX”, ∥模型作者
"Country":"XXX", ∥作者所在国家
"Email":"XXX", ∥作者Email
"Remark":"XXX" ∥模型备注信息
},
"ModelDes":{ ∥模型具体信息
"ModelId":"XXX", ∥模型编号
"ModelAlgebraicExpression": "XXX", ∥模型代数表达式
"ModelParams":"XXX", ∥模型自变量参数列表
"Remark":"XXX" ∥模型具体信息备注
},
"ModelResult":"XXX", ∥模型计算结果
"Time":"XXX" ∥模型调用时间戳
}
2) 方法调用过程中数据传输格式 调用方法库中的方法时,数据传输格式采用采用符号化方法对方法进行表达,格式如下:
ForestryAlgorithm=(AlgorithmDic,AlgorithmDes,AlgorithmResult,Time)。
式中:AlgorithmDic是方法基本描述信息; AlgorithmDes是方法具体信息; AlgorithmResult是方法计算结果; Time是方法调用时间。
AlgorithmDic=(AlgorithmId,AlgorithmName,AlgorithmExplain,AlgorithmParams,AlgorithmOutputType,IsGroup,GroupType,Remark)。
式中:AlgorithmId∈Int是系统内部定义的方法编号;AlgorithmName∈String是方法名称;AlgorithmExplain∈String是对方法的解释说明;AlgorithmParams∈String是方法输入参数列表;AlgorithmOutputType∈String是方法输出结果说明(数值型/代数表达式型);IsGroup∈String说明方法是以组合形式运行还以单个方法运行;GroupType∈String代表方法的组合方式[串联: N1,N2…Nn/并联: N1,N2…Nn/(Ni代表方法编号)];Remark∈String是方法表述的备注信息。
AlgorithmDes=(AlgorithmId,Remark)。
式中:AlgorithmId∈Int是系统内部定义的方法编号;Remark∈String是方法表述的备注信息。
AlgorithmResult∈String,是方法调用后的结果。
Time∈Date,是方法调用时的时间戳。
方法库调用的数据传输格式参照模型调用的数据传输格式生成,具体如下:
{"ForestryAlgorithm":
"AlgorithmDic":{ ∥方法基本描述信息
"AlgorithmId":"XXX", ∥方法编号
"AlgorithmName":"XXX", ∥方法名称
"AlgorithmExplain":"XXX", ∥方法解释说明
"AlgorithmParams":"XXX", ∥方法参数说明
"AlgorithmOutputType":"XXX", ∥方法输出结果说明
"IsGroup":"XXX", ∥是否为组合方法
"GroupType":"XXX" ∥组合方式
"Remark":"XXX" ∥方法备注信息
},
"AlgorithmDes":{ ∥方法具体信息
"AlgorithmId":"XXX", ∥方法编号
"AlgorithmURL":"XXX", ∥方法程序包存放地址
"Remark":"XXX" ∥方法具体备注信息
},
"AlgorithmResult":"XXX", ∥方法运算结果
"Time":"XXX" ∥方法调用时间戳
}
当模型和方法库平台与其他应用系统或平台界面进行数据交互时,使用以上定义好的数据交互格式可以提高调用的规范化和便捷性。
4 系统运行实例
平台使用SQLServer2008数据库实现模型(图9)与方法(图10)的存储,目前存储了广西、福建等在内的人工林胸径、断面积、树高、蓄积、地位指数、林分密度指数等生长收获模型以及各种线性与非线性拟合方法等。平台可提供API调用和友好的用户使用界面功能2种服务方式: API接口是为人工林经营辅助决策等业务系统提供模型、方法调用服务的,业务系统通过HTTP请求的方式,用GET或POST方法向平台发送请求,平台计算出结果后将其转换为统一数据交互结构返回给业务系统; 友好的用户使用界面为用户提供模型、方法基本信息的查询、调用说明以及模型计算等功能。本研究以福建某国有林场人工林林分收获模拟过程为应用场景,说明模型的计算调用运行过程; 以地位指数方程的拟合构建为例,说明非线性拟合方法的计算调用运行过程。
4.1 模型库调用实例
以福建杉木(Cunninghamialanceolata)全林分平均胸径模型调用计算为例,分别通过API和页面2种调用方式给出模型库调用实例。
1) API调用 调用福建杉木全林分平均胸径模型,地位指数为18,林分密度为2 000株·hm-2,预估10、15、20、25、30林龄的林分平均胸径,模型调用说明如表4所示,整理计算机结果如表5所示。
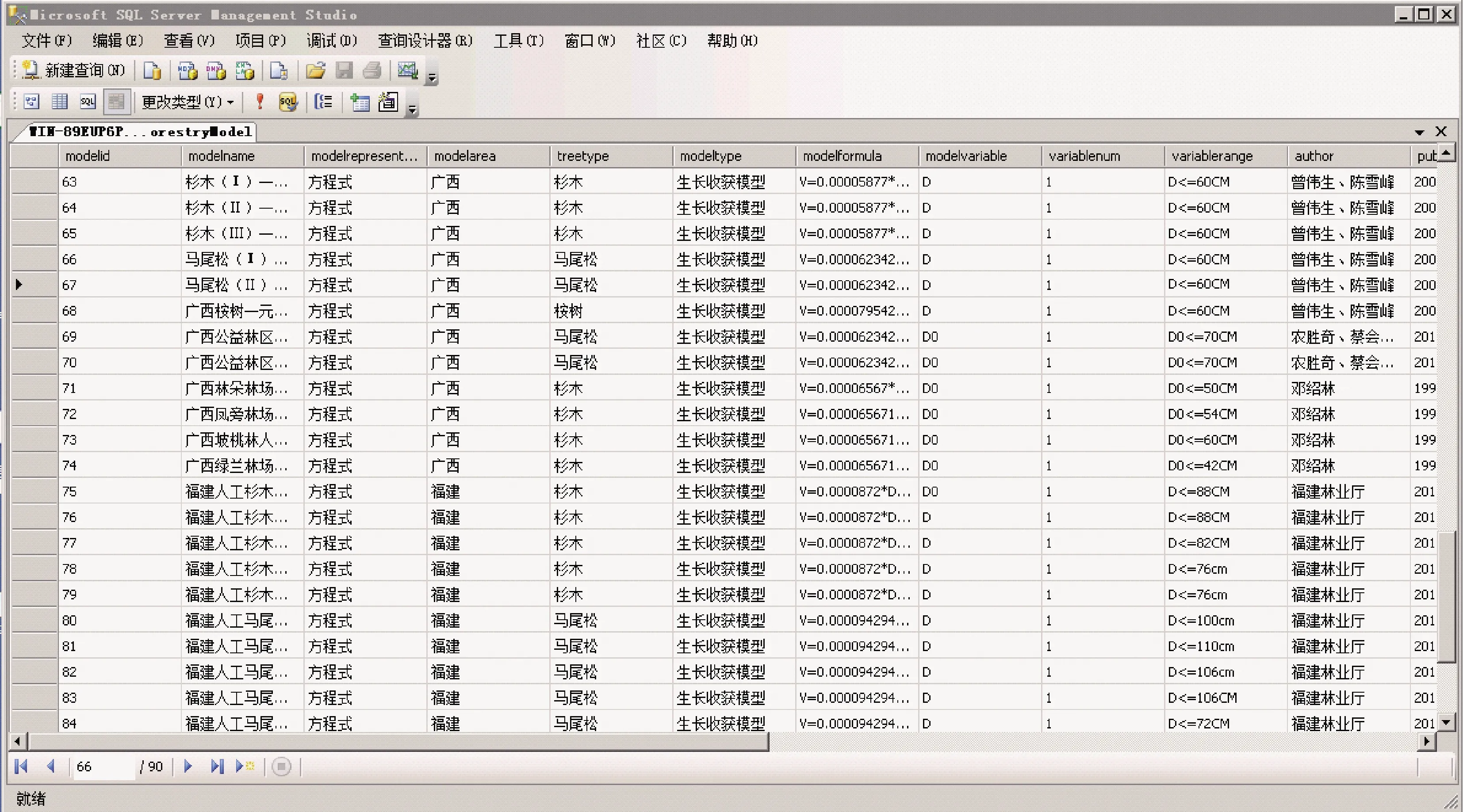
图9 模型表存储实例Fig.9 Model table storage

表4 模型API调用说明Tab.4 Model API call description

表5 杉木人工林林分平均胸径模拟(SI=18)Tab.5 Simulation of mean BDH of Chinese fir plantation(SI=18)
2) 页面调用 与API调用对应,使用页面调用福建杉木人工林全林分平均胸径模型,地位指数为18,林分密度为2 000株·hm-2,预估10、15、20、25、30林龄的林分平均胸径。调用时,进入如图11所示福建杉木人工林全林分平均胸径模型计算交互页面,在模型计算对话框中输入地位指数: 18,密度: 2 000,林龄: 10、15、20、25、30,点击“调用计算”按钮即可得到计算结果。
4.2 方法库调用实例
以福建杉木地位指数方程拟合为例,使用Richards理论生长方程作为原型,采用代数差分法构建地位指数方程。
1) API调用 选择以a为自由参数对Richards理论生长方程进行变换得到公式: HT2~HT1*{{[1-exp(-b*T2)]/[1-exp(-b*T1)]}^c},使用来自福建省两期固定复测样地(212块)数据对以上公式进行拟合,其中,T1为第1期的林龄,HT1为第1期的优势木高,T2为第2期的林龄,HT2为第2期的优势木高。数据示例如表6所示。
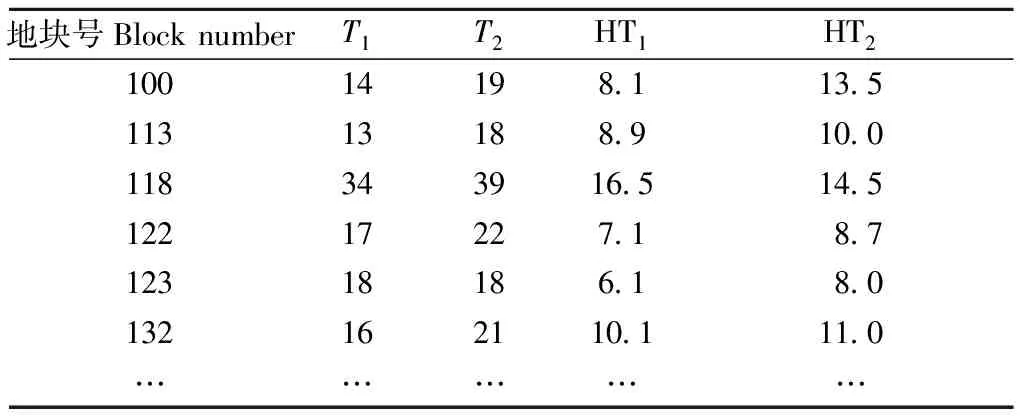
表6 固定复测样地林龄与优势木高数据示例Tab.6 Fixed re-test sample forest age and superior wood height data
调用非线性回归方法,参数分别为拟合公式formula=‘HT2~HT1*{{[1-exp(-b*T2)]/[1-exp(-b*T1)]}^c}’;b=0.105 636,c=1.139 241 (初始参数值);T1=14,16,18,20,14,…;T2=19,21,23,25,19,…; HT1=3.2,7.6,8.6,7.5,8.1,…; HT2=5.9,5,5,8.5,13.5,…; 不同参数之间以&符号隔开; 平台拟合后将结果返回。具体调用说明如表7所示。

表7 方法API调用说明Tab.7 Method API call description
其他非线性拟合方法调用与表7中的调用方式类似,用户可根据拟合的返回结果判断拟合效果,选择拟合效果好的模型补充到模型表中。
2) 页面调用 采用与API调用同样的应用场景,使用页面的方式调用非线性回归方法。 在方法库页面中选择非线性回归方法,将数据写入如图12所示的拟合数据文件(文件为Excel类型),然后点击“上传数据文件”按钮,将填写好的数据文件上传; 在图13的参数对话框中分别填写拟合公式和初始参数值。平台进行拟合,拟合结果返回,如图13的页面显示。
图12 方法调用拟合数据模板Fig.12 Method call fitting data template

图13 方法调用接口说明界面Fig.13 Method call interface description interface
5 结论
本研究应用关系型数据库结合R语言程序封装方法构建了通用性强的模型库和方法库,采用数据表示法和程序表示法分别表达人工林经营中数学公式型模型和程序块型模型,针对数据表达的模型,使用词法分析、语法分析、语义分析等方法实现模型的解析计算,针对程序表达的模型,利用Rsession实现程序模型的调用计算,同时利用Rsession实现对方法库中方法的管理和调用,实现了模型、方法的管理更新与业务代码的分离,降低了模型、方法的管理和使用复杂度。通过构建数据交互结构,为实现模型库与方法库的API调用奠定了基础,使模型库与方法库具备了面向用户的界面使用服务与程序级调用服务功能。
