基于灰色系统建模技术的人体疾病早期预测预警研究
2020-03-03刘思峰
曾 波,刘思峰,白 云,周 猛
(1.重庆工商大学商务策划学院,重庆 400067;2.南京航空航天大学经济与管理学院,江苏 南京 210016; 3.重庆工商大学国家智能制造服务国际科技合作基地,重庆 400067)
1 引言
肾衰、癌症、猝死等重大健康问题在我们身边发生的频率越来越高,人们开始越来越重视常规体检在及时发现疾病隐患、保障人体健康中的重要作用。目前,健康体检已成为预防身体疾病隐患的一种重要途径,并受到政府和社会的普遍关注和广泛重视。
通常,专家通过体检结果各项指标,分析体检者身体健康状况及可能存在的疾病隐患。然而,这种诊断是基于一次体检结果的静态分析,难以发现指标在不同阶段的动态发展趋势;同时,由于不同个体体质不同,导致他们的某项体检指标在“量”上可能存在较大差异。因此仅仅通过某人单次体检指标进行横向比较和静态分析,纯粹从指标高低来判断体检者健康状况与身体状态,而缺乏对体检者指标变化趋势的动态比较和纵向分析,有可能得到不合理的体检结论。因此,合理运用数学方法科学描述身体指标发展变化规律,准确预测身体指标变化特征及其变化范围,在此基础上对人体健康实施预警管理,从而及时发现人体健康隐患,有效采取控制或治疗措施,对保障人体健康具有积极意义。
国内外围绕疾病预防筛查、指标预测与预警方面做了大量研究,定量预测建模方法不断涌现。归纳起来,这些方法主要包括:灰色系统预测模型、自回归移动平均模型、马尔柯夫预测模型、BP神经网络预测模型、多元回归预测模型、移动平均法(MA)和指数加权移动平均法(EWMA)等等。下面简要对各类模型的建模特点进行介绍。
(1)灰色系统预测模型[1-2]。该模型主要以“部分信息已知、部分信息未知”的小数据不确定性系统为研究对象,通过对部分已知信息的挖掘,寻找系统演化的客观规律,在此基础上实现对系统未来运行行为与发展趋势的预测。目前,灰色系统预测模型已被广泛应用于新老血管死亡率预测[3]、食源性疾病发病率预测[4]等。
(2)自回归移动平均模型(ARIMA)[5-6],该模型将预测对象随时间推移而形成的数据序列视为一个随机序列,并用一定的数学模型来近似描述这个序列。ARIMA模型一旦被识别后即可根据时间序列的过去值及现在值去预测系统的未来值。华来庆等应用ARIMA模型、ARIMA(2,2,0)模型来预测黄瓜霜霉病疾病指数。
(3)马尔柯夫预测模型[7-9],该模型应用概率论中的马尔柯夫链理论和方法来研究随机事件变化规律,并借此来分析和预测系统未来的可能状态的一种方法。简单说来,该模型的基本思想就是根据系统现在所处的状态,推测系统未来的变化趋势。臧春鹏应用马尔柯夫模型预测徐州市1998年伤寒发病率,预测结果与实际完全吻合。
(4)BP神经网络预测模型[10-13],其全称叫误差反向传播多层前馈神经网络模型。该模型的学习规则是最速下降法,通过误差的反向传播调整内部连接的权值和阈值,以达到减小误差的目的,在此基础上实现对系统未来趋势的预测。侯木舟等利用BP神经网络模型对大脑的病理状态进行分析,为脑疾病如癫痫病的诊断、预测和治疗提供依据。
(5)多元回归预测模型[14-17]。回归模型预测传染病发病及流行趋势通常是应用直线或曲线拟合原始发病数据,用数字和等式来表达传染病的流行规律,从而找到控制疾病的有效方法。但是回归预测不能任意外推,如果任意外推,预测远期目标的误差就大。美国2002年建立的疾病爆发与实时监控系统使用了动态自回归线性回归模型,采用递回最小平方算法,利用各地区症状历史资料的消长趋势,预测现阶段所研究症状数据的上限,模型相关系数是利用预测误差校正的。该系统在美国之外的地区也得到了广泛的运用,而且在中国台湾等地对该系统在突发传染病的预测预警上所具有的优势也给予了充分的肯定。
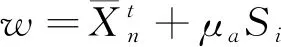
(7)指数加权移动平均法(EWMA)[19]。指数加权移动平均法是在简单移动平均的基础上引入了权重的思想,随着时间的推移,对历史数据赋予不同的权重。社区疾病流行早期电子报告系统(ESSENCE II)目前所使用的时间聚集探测模型就是指数加权移动平均模型。EWMA的缺点是由于其是对过去样本数据波动进行累计,因此它不能很好发现过程中的突发变化。其优势在于其对微小变化的灵敏性高,能更快速地识别爆发,从而达到早期预警的效果。
(8)组合预测法[20]。不同的模型有着不同的适用范围和优势,而组合的模型可以综合利用各种方法所提供的信息,提高预测精度。王永斌,李向文等,将灰色模型与广义回归神经网络组合成 [GM(1,1)-GRNN]模型,并应用于我国尘肺病发病人数的预测;张明华将GM(1,1)模型和最小二乘法模型优化组合成一新模型对门急诊量进行预测;严薇荣等对伤寒副伤寒发病率进行预测的研究中,将灰色模型和Markov模型进行互补组合,结果显示,组合模型对传染病发病率进行预测可以提高预测精度。
任何一种模型都有自己的建模特点与适用范围,模型的选择与建模对象数据特征息息相关。因此,在选择体检指标预测模型之前,首先对个体体检指标的信息特征进行分析和归纳。
2 个体体检指标的信息特征
体检者在不同时点的指标数据构成了该指标的时序数据,指标m在体检时间1~n的时序数据记为Xm=(xm(t1),xm(t2),…,xm(tn)),Xm具有如下特征:
(1)样本量小。人正常情况下每年体检1-2次,而且体检指标和年龄结构、生活状态、工作环境等因素密切相关,具有较强的阶段性和时效性,换言之,早期体检的指标数据对分析当前身体状况的参考价值微乎其微。通常,最近6-8年的体检指标数据能够比较系统地反映身体机能的演变过程和发展趋势。因此,构成体检指标的时序数据Xm,其元素个数n在6-16之间,考虑到某些年份未进行体检等具体情况,实际的有效样本量可能更小,因此Xm具有小样本特征。
(2)信息不确定。体检指标受到身体及精神状态、饮食结构、仪器设备、测量误差、技术水平等多种因素的影响,通常情况下难以获得准确的指标数据,这就是体检之后对“异常指标”需再次“复查”的主要原因。然而,尽管无法确定指标的具体数据,但是可以根据多次体检结果确定指标的“可能取值”或大概范围,从而形成了体检指标的区间不确定性及离散不确定性现象,在系统科学中,前者称为“区间灰数”,后者称为“离散灰数”。
(3)数据间隔不统一。设时序数据Xm=(xm(t1),xm(t2),…,xm(tn)),Δtk为序列Xm中相邻数据间的时间间隔,即Δtk=tk-tk-1(k=2,3,…,n),若Δtk≠常数,则称Xm为非等时距序列。非等时距序列在体检数据采集过程中经常遇到,如体检者在某些年份体检未正常进行,那么在一定时域内该体检者的指标数据即为某些年份数据缺失的非等时距序列。
(4)数据类型异构。所谓数据类型异构,是指时序数据Xm=(xm(t1),xm(t2),…,xm(tn))中元素之间具有不完全相同的数据类型,比如元素xm(tw)是具有一定取值范围的区间灰数,元素xm(tu)可能是无法确定具体取哪一个数值的离散灰数,而元素xm(tv)又是实数。根据前面的分析可知,由于体检指标数据的信息不确定性,进而导致了体检时序数据Xm“类型异构”现象的产生。
(5)指标影响因素构成情况复杂。身体指标是反映身体某项机能健康状况的重要参数,如医学上常用肌酐等指标来评价体检者肾功能的好坏。由于身体指标受到许多因素的影响,如环境因素(空气、水质、食物)、遗传因素、心理因素(焦虑、烦躁、恐惧)、生活方式因素(生活习惯、健康意识)及保健服务因素等,这些影响因素构成极其复杂且难以量化。
(6)指标时序数据具有振荡特征。由于反映身体健康状况的各项指标总是受到内在因素及外部环境等多种不确定性因素的影响,导致即使对某一特定的健康个体而言,其身体指标也非恒定不变或满足某种单调性变化规律,而常常表现为在一定范围内增加或下降的振荡特征。
体检指标时序数据Xm的六大特征,如图1所示。
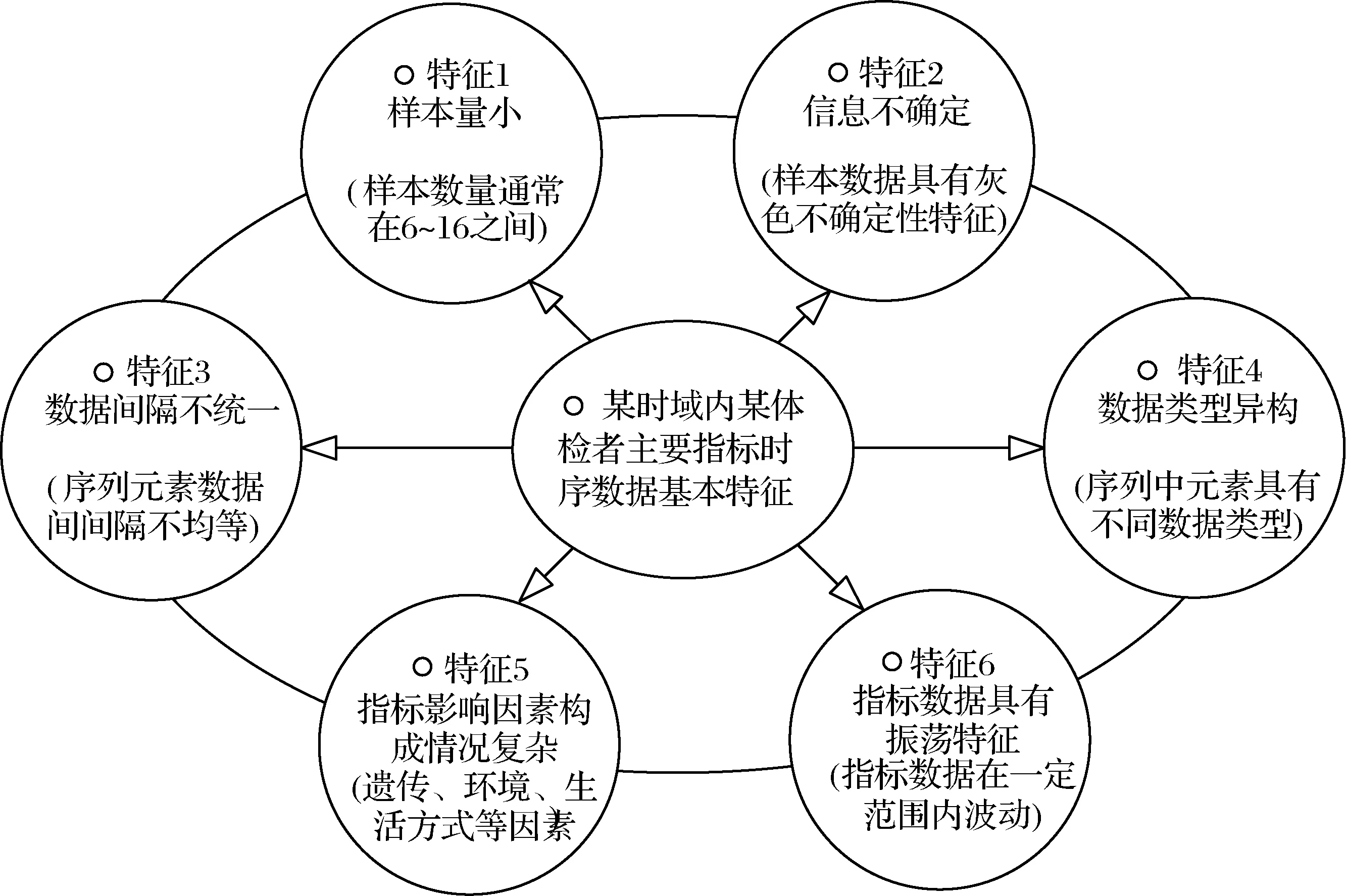
图1 某时域内某体检者主要指标时序数据基本特征
3 面向指标预测的灰色系统建模方法
以数理统计为基础的回归模型和结构方程模型是两类常用的预测方法,这两类模型均通过构建因变量和自变量的函数关系来实现对因变量的预测,由于它们都以数理统计为基础,因此必须以大样本数据为建模条件;同时由于因变量的预测值依赖于自变量,而自变量也是预测的,具有不确定性,这必然导致因变量预测值具有更大的不确定性。因此,对于建模样本量小、统计规律不明显、序列元素“数据类型异构”的不确定性系统而言,回归模型和结构方程模型均无能为力。另外,马尔科夫预测模型对过程的状态预测效果良好,但是不适合系统的中长期预测;神经网络模型实现了一个从输入到输出的映射功能,但“过拟合”现象常常导致其预测性能低下。
另外,上述模型主要以“大样本数据”为建模对象,无法解决具有图1所示数据特征的人体主要健康指标的模拟与预测问题。而“灰色系统预测模型”具有“小数据、贫信息”建模的优点,对异构信息、振荡数据、非等间隔数据都具有相对成熟的研究方法与建模手段。因此,本文拟应用灰色预测模型来解决人体主要健康指标的建模与预测问题。
GM(1,1)是最早建立的一阶导数单变量灰色预测模型,其最终还原式表现为齐次指数。因此,当建模序列具有近齐次指数增长特征时,该模型具有较好的模拟及预测性能。然而现实世界充满复杂性和不确定性,具有近齐次指数增长特征的序列只是一种理想状态下的特殊情况,而更多的系统行为序列呈现出近似非齐次指数增长特征[21-23]。在这样的情况下,若使用GM(1,1)模型对近似非齐次指数增长序列进行建模,其固有的建模机理与模型结构将导致我们很难获得一个满意的模拟及预测精度。另一方面,GM(1,1)模型通过差分方程估计模型参数,通过微分方程推导模型时间响应式,因此该模型兼具部分微分(光滑)部分差分(跳变)的性质。然而,这种参数估计与模型表达式来源的“非统一性”,导致即使面对严格齐次指数序列,GM(1,1)模型依然存在模拟误差。
为了解决人体主要健康指标的预测问题,本文构建了一个新的灰色预测模型。该模型解决了经典GM(1,1)模型参数估计与模型表达式之间“非同源性”的缺陷,能实现对齐次指数序列、非齐次指数序列及线性函数序列的无偏模拟。
定义3.1 设序列X(0)=(x(0)(1),x(0)(2),…,x(0)(n)),其中x(0)(k)≥0,k=1,2,…,n;则称X(1)=(x(1)(1),x(1)(2),…,x(1)(n))为序列X(0)的一次累加生成序列,其中:
定义3.2 设序列X(0)及X(1)如定义3.1所示,则称
(1)
现求解白化微分方程的时间响应式,根据公式(3.1)可知,其对应的齐次方程为:
(2)
则有:
ln|x(1)|=-at+ln|C1|
齐次方程(3.2)的通解为:
x(1)(t)=C1e-at
(3)
用常数变易法,把(3.3)式C1换成u(t),并令
x(1)(t)=u(t)e-at
(4)
对(3.4)两端对t求导得:
(5)
将(3.5)代入(3.1)得:
u′(t)e-at-au(t)e-at=bt+c-ax(1)
因为u′(t)=(bt+d)eat,故:
即:
(6)
把(3.6)代入(3.4)得:
(7)
整理,得:
(8)
当t=1时,可得:
(9)
解得:
(10)
把公式(3.10)代入公式(3.8),得:
(11)
公式(3.11)的最终还原式为:
(12)
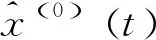
令:
则由(3.12)式可得:
即:
(13)
令:
则(13)式可表示为:
x(1)(t+1)=αx(1)(t)+βt+γ
(14)
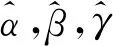
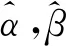
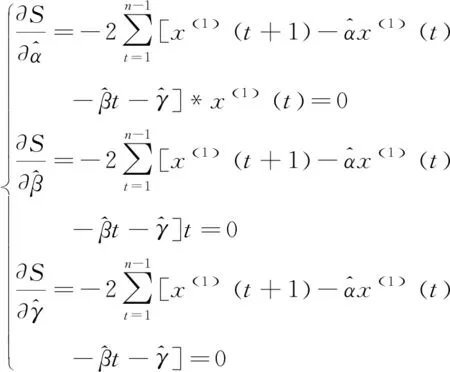
化简后得:
(15)
根据克莱姆法则解非齐次方程组(15),令:
B
则非齐次方程组的解为:
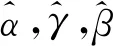
得参数a,b,c的估计值为:
再将参数估计值代入还原式(12),得到原始序列的模拟和预测值。
公式(12)称为人体主要健康指标的无偏灰色预测模型,简称为HIGM(1,1)。相对于经典的GM(1,1)模型,HIGM(1,1)模型确保了模型参数估计与模型时间响应式来源的一致性,能实现齐次指数序列、非齐次指数序列及线性函数序列的无偏模拟(具体证明过程略),具有较好的模拟及预测性能。
4 案例分析:基于HIGM(1,1)模型的肾功能预测
血肌酐是检测肾功能的最常用指标,也是健康体检的必检项目。在肌肉中,肌酸主要通过不可逆的非酶脱水反应缓缓地形成肌酐,再释放到血液中,随尿排泄。因此血肌酐与体内肌肉总量关系密切,不易受饮食影响。肌酐是小分子物质,可通过肾小球滤过,在肾小管内很少吸收,每日体内产生的肌酐,几乎全部随尿排出,一般不受尿量影响。临床上检测血肌酐是常用的了解肾功能的主要方法之一。通常,血肌酐正常值标准为:男53~106微摩/升;女44~97微摩/升;小儿:24.9~69.7μmol/L。某体检者2009-2016年血肌酐指标数据如表1所示。
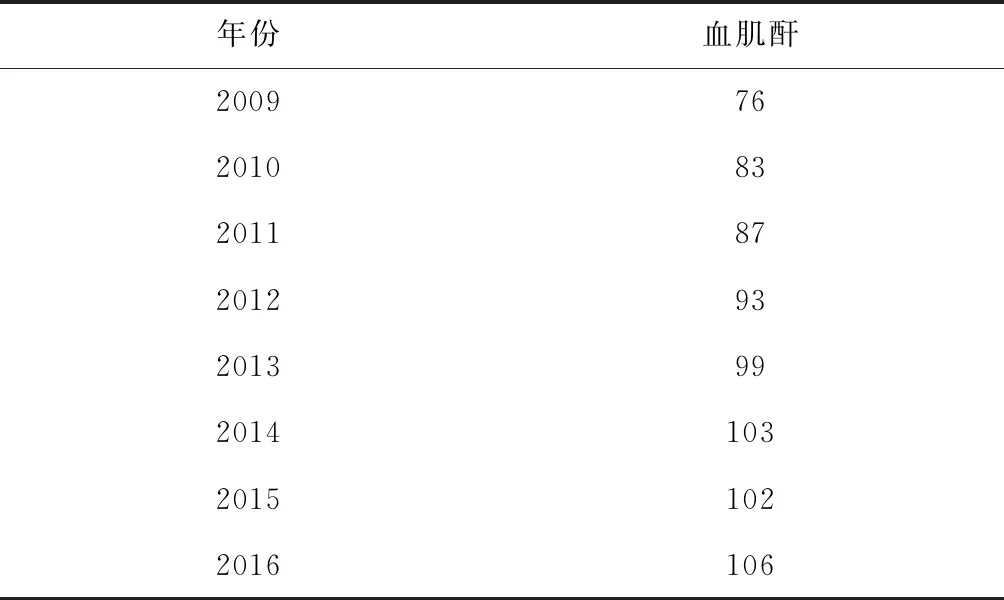
表1 某体检者2009-2016年血肌酐指标数据(单位:微摩/升)
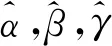
表2 序列X(0)的HIGM(1,1)模型参数值
根据表2,当t=2,3,…,n,…时,可以建立血肌酐的HIGM(1,1)模型,如下,
+113.3920
(16)
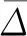
为了直观显示HIGM(1,1)及GM(1,1)模型对血肌酐的拟合性能,我们应用MATLAB分别绘制了HIGM(1,1)及GM(1,1)模型模拟值与实际值的对比图,见图2。
应用HIGM(1,1)模型预测该体检者2017-2020年血肌酐数据,结果如表4所示:
根据表1、3、4及图1,我们可以得到如下结论:
(1)由于成年男子血肌酐正常值标准为 53~106微摩/升。根据表1,该体检者在2016年血肌酐为106微摩/升,体检结果显示其“肾功能正常”。
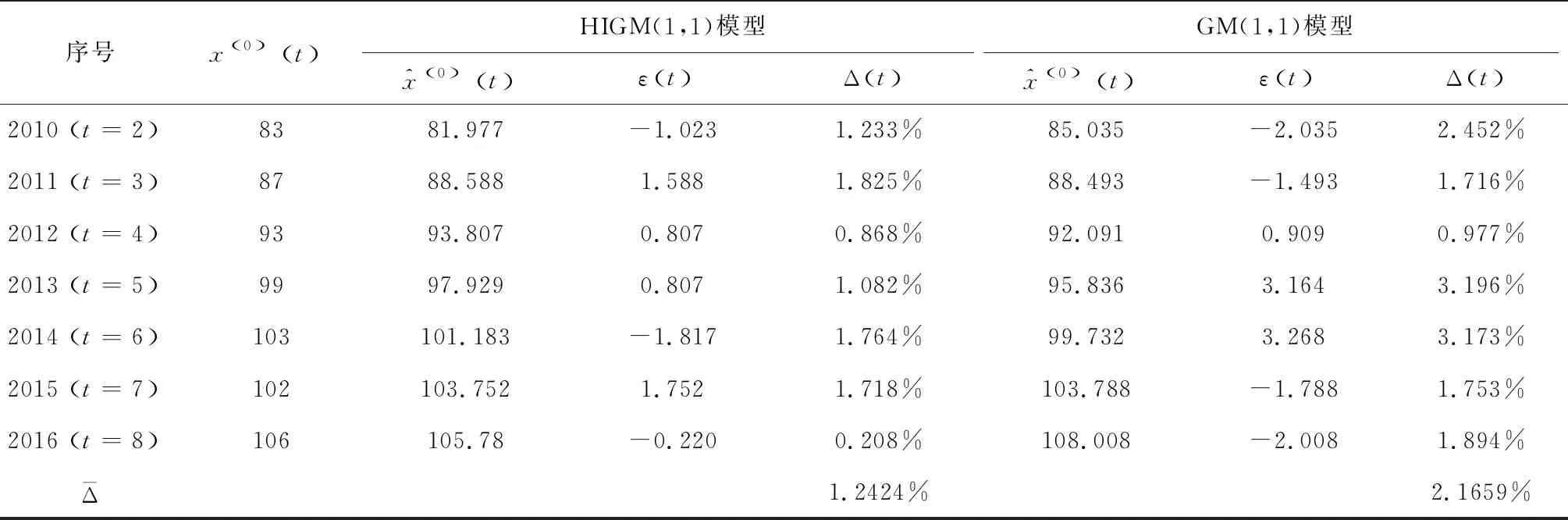
表3 序列X(0)的模拟值、残差、相对模拟百分误差与平均相对模拟百分误差
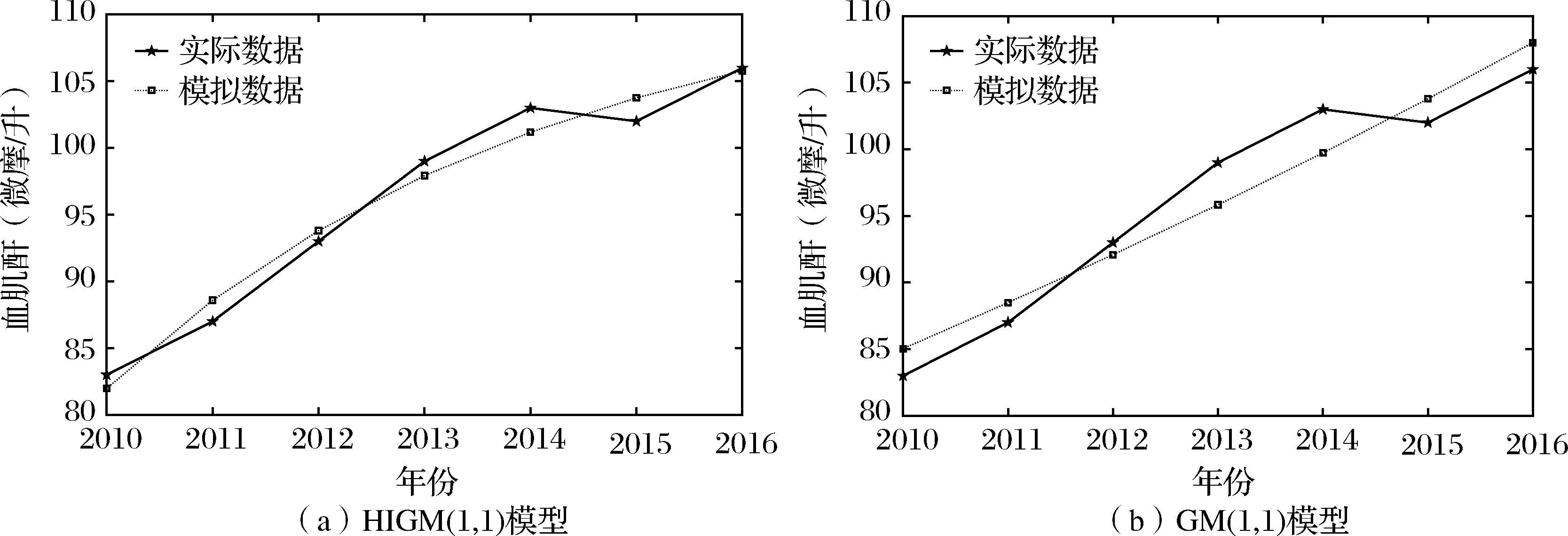
图2 血肌酐的HIGM(1,1)及GM(1,1)模型模拟数据对比图

表4 该体检者血肌酐指标2017-2025年预测值(单位:微摩/升)
(2)该体检者血肌酐指标尽管2015年比2014年略有下降,但总体上呈现上升趋势。
(3)到2020年,该体检者血肌酐预计将达到110.434微摩/升,已超过血肌酐的正常范围;换言之,该体检者的肾脏已经出现病变。
(4)该体检者2018年到国内某三甲医院做穿刺活检,结果显示其已患慢性肾小球肾炎(IGA第II期),需要施以药物治疗。而该体检者2014年血肌酐为103微摩/升,体检结果显示肾功能正常。
(5)本文构建的HIGM(1,1)模型比GM(1,1)模型具有更高的模拟精度。
可见,通过对体检者身体指标时序数据进行建模,能够发现体检者在未来一段时间该指标的发展趋势与演变规律,进而发现体检者的身体健康隐患,在此基础上有针对性地采取控制或治疗措施,做到防患以未然。
5 结语
传统健康体检主要通过对个体单次体检指标进行横向比较和静态分析,忽略个体差异,纯粹从指标高低来判断体检者健康状况与身体状态,而缺乏对体检者指标变化趋势的动态比较和纵向分析,有可能得到不合理的体检结论。因此,合理运用数学方法科学描述身体指标发展变化规律,准确预测身体指标变化特征及其变化范围,在此基础上对人体健康实施预警管理,从而及时发现人体健康隐患,有效采取控制或治疗措施,对保障人体健康具有积极意义。由于个体体检指标具有样本量小、信息不确定、数据类型异构、影响因素构成复杂等特征,传统以大样本为基础的数学模型均难以适应此类小数据系统的建模要求。为此,本文建立了适用于人体主要指标趋势预测的HIGM(1,1)模型,并将该模型应用于表征肾功能健康指标的血肌酐的模拟,同时对结果进行了分析。
本文所构建HIGM(1,1)模型目前仅能对等时距的实数序列建立预测模型,如何根据指标数据实际需要,构建面向非等时距的异构数据序列灰色预测模型,以及如何开发人体健康的智能预警系统,是项目团队下一步的研究目标。
