基于双层Bi-LSTM-CRF模型的糖尿病领域命名实体识别
2020-02-28何春辉王梦贤何小波
何春辉,王梦贤,何小波
(1.湘潭大学 数学与计算科学学院,湖南 湘潭,411105; 2.湖南城市学院 管理学院,湖南 益阳,413000; 3.75841部队,湖南 长沙,410000)
从医学角度来看,糖尿病主要有1型糖尿病和2型糖尿病。据相关统计数据显示,在所有糖尿病患者中有超过90%的患者属于2型糖尿病[1]。无论是哪种类型,都会对患者的正常生活带来极大的影响。近年来,公开的研究数据表明中国糖尿病患者人数位居全球第一,且仍在快速增长。国际糖尿病联合会公布的调查数据显示,2040年中国糖尿病患者数预计会超过1.5亿[2]。对于这些糖尿病患者而言,大多数医院都会通过电子文档的形式对他们的病情进行记录和存档。针对这些电子文档,目前缺乏高效的自动识别方法对命名实体进行快速识别。为了改变这种现状,提升糖尿病领域的命名实体识别准确率,为人们做出辅助决策提供数据支撑,已成为糖尿病领域的一个重要的研究课题[3]。在其他领域中,命名实体识别已经取得了许多高质量研究成果[4]。但是国内外在糖尿病领域的命名实体识别方法研究还处于起步阶段。因此,提出高效的糖尿病领域命名实体识别方法,这对糖尿病领域电子病历的自动分析而言具有深远的意义。有研究成果表明,基于传统机器学习和规则[5-7]相结合的条件随机场CRF[8-9]和结合深度学习的条件随机场CRF[10-13]是中文命名实体识别领域性能非常高的两类方法[14]。下面引入某一段真实的糖尿病临床指南样例原文:“自从2005年国际上第一个肠促胰素药物上市以来,此类药物的研究和临床应用有了飞速的发展。目前在我国已经上市2种胰高血糖素样肽1(GLP-1)受体激动剂和5种二肽基肽酶Ⅳ(DPP-4)抑制剂。”上述样例包含了糖尿病领域中部分药物类实体名称。如何应用智能算法从类似的文本中自动识别糖尿病领域命名实体是本文的研究重点。为了将智能方法应用到糖尿病领域从而解决糖尿病领域的命名实体识别任务,分别对经典的CRF和基于深度学习的CRF这两类方法在公开的糖尿病领域标注数据集上开展实证研究。
1 双层Bi-LSTM-CRF模型
由于深度学习的框架可以对文本特征进行自动抽取,从而无需使用传统的特征工程来做特征筛选和建模。因此,在文本分类和序列标注问题中,深度学习模型通常会具有更好的性能。图1展示了基于字符嵌入的双层Bi-LSTM-CRF模型的体系结构。
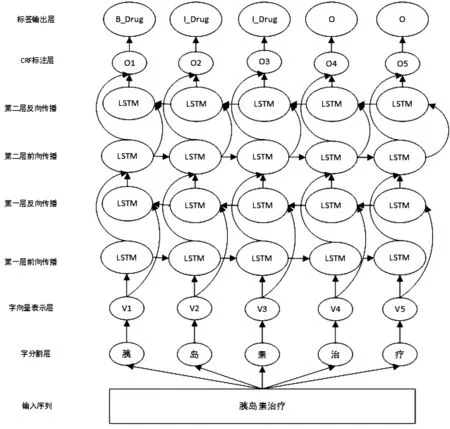
图1 基于字符嵌入的双层Bi-LSTM-CRF模型体系结构Fig.1 Double-layer Bi-LSTM-CRF model architecture based on character embedding
图1中的体系结构从下至上总共分为7个层次。首先是输入层,图中以[胰岛素治疗]这个中文字符串当作模型的输入序列;然后达到字分割层(按照字符进行切分),得到[胰][岛][素][治][疗]这5个不同的字符,这些字符分别调用预先训练好的字符嵌入向量映射成对应的向量形式;将相应的向量依次输入到第一层深度学习网络的前向传播和反向传播网络中进行参数训练;将计算结果继续依次输入到第二层深度学习网络的前向传播和反向传播网络中进行参数训练;将计算结果输入到条件随机场CRF层,完成相应的序列标注;最后,在输出层输出最终的序列标注结果。需注意的是,在深度学习网络中,采用双层Bi-LSTM网络结构。实验中,模型的主要超参数设置如表1所示。
表1 双层的Bi-LSTM-CRF模型核心超参数设置
Table 1 Core hyperparameters setting for the double-layer Bi-LSTM-CRF model

参数名称参数取值参数名称参数取值EMBED_DIM(向量维度)300第一层BiLSTM_UNITS500DROPOUT_RATE0.25第二层BiLSTM_UNITS250Batch_Size128Epoch15Loss_functioncrf_layer.loss_functionOptimizer functionAd-am
注:表中所列的超参数及取值情况,是指实验中性能最优的模型对应的参数取值。
2 数据集及预处理
为验证模型的性能,实验数据集由阿里云天池大赛平台提供的瑞金医院MMC人工智能辅助构建知识图谱大赛[15]所提供的糖尿病相关标注文档集构成,并按照80%训练和20%验证的方式来划分数据集。此外,选取竞赛第一轮test_B中公布的58份预测文档作为模型的独立测试集。所有的数据集标注工作都是基于brat[16]软件完成。标注信息包含了以T开头的实体标记,后接实体序号,实体类别,起始和结束位置以及实体在文档中所对应的原始内容五个部分。整个数据集总共包含了15种不同的实体类别,具体类别名称如表2所示。
表2 实体类别与对应的符号表示
Table 2 Entity categories and corresponding symbolic representations
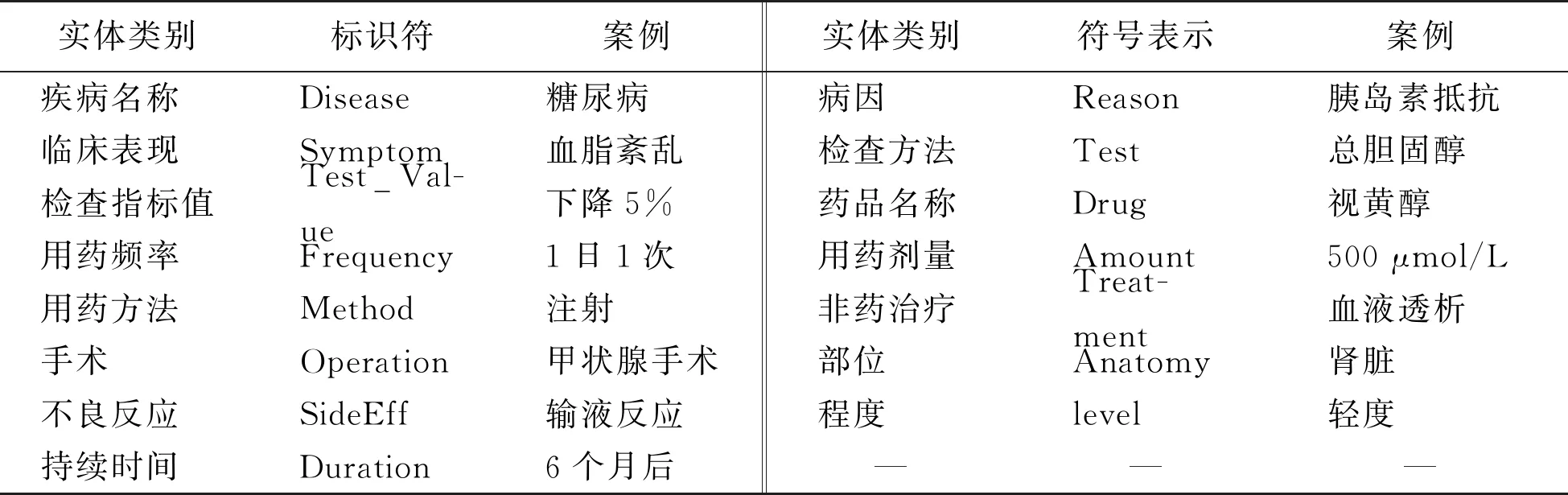
实体类别标识符案例实体类别符号表示案例疾病名称 Disease糖尿病病因Reason胰岛素抵抗临床表现 Symptom血脂紊乱检查方法Test总胆固醇检查指标值Test_Val-ue下降5%药品名称Drug视黄醇用药频率 Frequency1日1次用药剂量Amount500 μmol/L用药方法 Method注射非药治疗Treat-ment血液透析手术 Operation甲状腺手术部位Anatomy肾脏不良反应 SideEff输液反应程度level轻度持续时间 Duration6个月后———
所有实体对应的类别皆采用BIO三级标注体系按实体序列出现的先后顺序来完成实体标注(B表示实体的头部,I表示实体中间及尾部,O表示非实体),并以标点符号作为字符串切分边界。
为了减少中文分词所带来的误差,在训练数据集中采用频率大于2的字来构建相应的字向量,它可以减少因分词不准确而引起的误识别现象。为了进一步提升识别的准确性,在数据预处理阶段对文档内容中的特殊字符、空格等做了处理。
3 实验结果及分析
为验证和测试模型的性能,在第2节所述的数据集上,实现了多组不同模型的对比实验,从而完成模型的对比验证和对新数据的预测。在验证数据集上,采用所有类别的平均准确率来评估模型性能,在独立的测试数据集上,采用所有类别的平均F1值来作为评测指标。
在文本集合里,令D={d1,d2,…,dn},其中di= 采用F1值作为评测模型的指标。模型的输出结果集合记为S={s1,s2,…,sm},人工标注的结果集合记为G={g1,g2,…,gn}。集合元素为1个实体,表示为四元组 (1) (2) 在对应的数据集中,分别使用了传统的条件随机场CRF模型、结合了深度学习的单层Bi-LSTM-CRF、双层Bi-LSTM-CRF和双层GRU-CRF这4种不同的模型进行实验。相应的实验结果如图2所示。 图2 不同模型的实验结果Fig.2 Experimental results of different models 图2展示了4个不同的模型在验证集和独立测试集test_B上的实验结果。训练过程中,从结果中可以看出CRF模型效果一般,只有81.65%的平均准确率,双层Bi-LSTM-CRF模型取得了89.14%的平均准确率,单层Bi-LSTM-CRF和双层GRU-CRF模型平均准确率分别是88.12%和87.86%。在预测过程中,双层Bi-LSTM-CRF模型预测的F1值达到了72.89%,而其他模型的F1值处于69.38%到71.73%之间。由图2 结果可知:双层Bi-LSTM-CRF模型相对基线模型而言,在实验中的平均准确率和F1均属最高。此外,为了进一步验证模型的泛化能力,调用已经训练好的双层Bi-LSTM-CRF模型,对引言中所述的样例片段内容进行预测,得出的预测结果见表3。 表3 文中所述样例片段所对应的实体识别结果 实体编号实体类型开始下标结束下标实体内容T1Drug1317肠促胰素T2Drug5575胰高血糖素样肽1(GLP-1)受体激动剂T3Drug7894二肽基肽酶Ⅳ(DPP-4)抑制剂 表3所示的命名实体识别结果中共包含了3个不同的实体,分别标记为T1,T2和T3。其中每个实体对应5列,分别为实体标签、实体类别、实体在原始文档中的起始下标位置、结束下标位置、实体内容。根据表3的实验结果可以看出T1,T2和T3都是属于药物类的实体,这与真实的标注结果相吻合,这也进一步揭示了双层Bi-LSTM-CRF模型的优越性。 在糖尿病领域命名实体识别任务中,鉴于目前缺乏成熟的自动化技术来支撑实体识别任务;提出了基于双层Bi-LSTM-CRF模型来识别糖尿病领域的命名实体。该模型在实验数据集上取得了较好的效果,它的平均准确率达到了89.14%,在外部测试集上的F1值为72.89%。提出的双层Bi-LSTM-CRF命名实体识别模型,在公开的糖尿病领域实体识别数据集上已经取得了较高的识别准确率,未来会进一步提升模型的性能,并将改进后的双层Bi-LSTM-CRF模型应用于大规模糖尿病领域命名实体识别任务,从而形成结构化知识为辅助决策提供数据支持。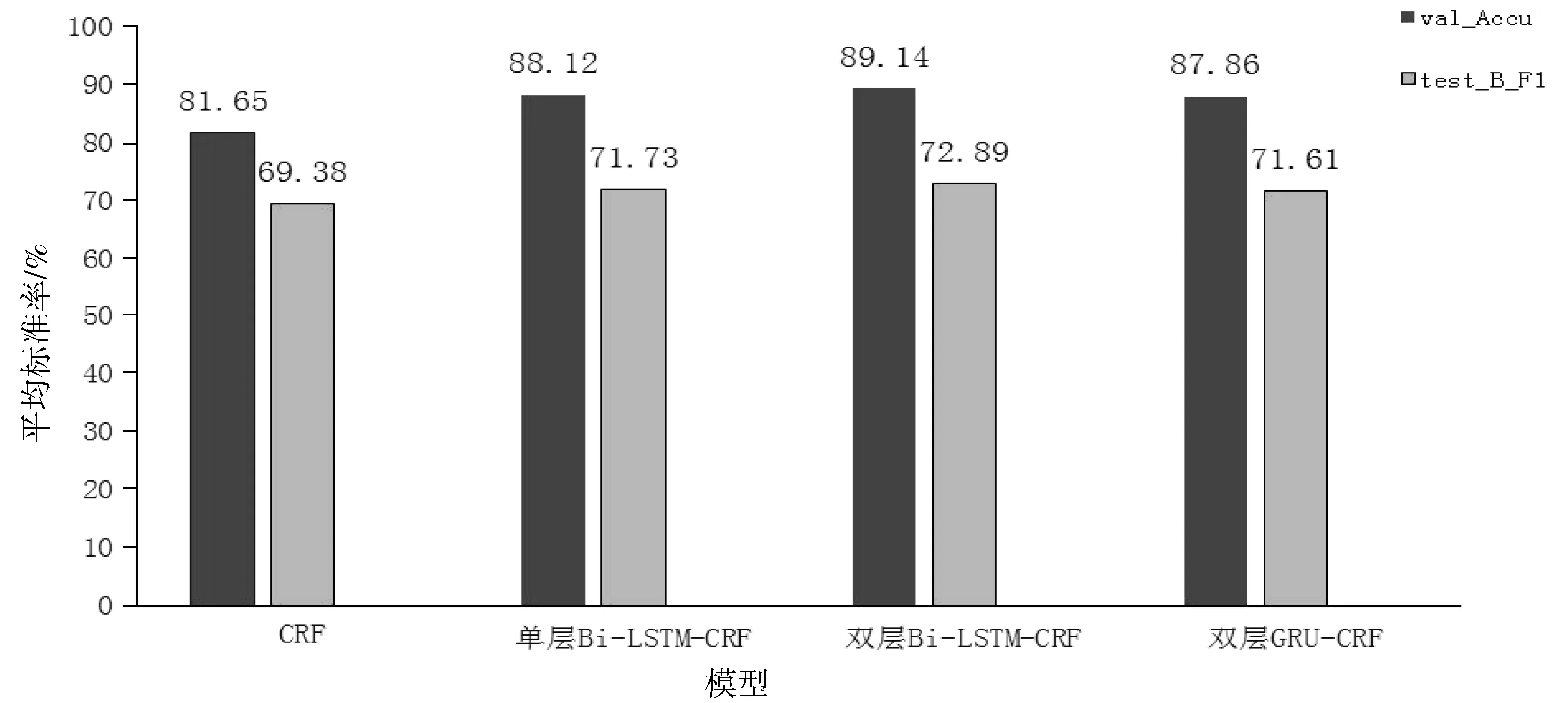
Table 3 Entity recognition results corresponding to the sample fragments described in this paper
4 结论与展望
