基于Q-learning的定制公交跨区域路径规划研究
2020-02-28彭理群罗明波柏跃龙
彭理群,罗明波,卢 赫,柏跃龙
(华东交通大学交通运输与物流学院,南昌330013)
0 引 言
学者围绕定制公交自适应路径规划方法展开了研究.雷永巍等[1]针对互联网定制公交线路规划问题提出了最大需求、最小费用双层规划模型,采用并行遗传算法对定制公交调度模型进行求解.Cao 等[2]综合考虑定制公交线路通行时间、等待时间、延误惩罚和票价的组合人均成本最小化,结合乘客出行需求对定制公交乘客分配方案进行优化.Ma 等[3]针对定制公交线网资源分配率低的问题,提出基于旅客OD 出行需求划分的区域聚类线网规划方法,通过选择社会效益最大化和运营成本最小化的OD对进行匹配计算,提高了定制公交的经济效益.Lyu 等[4]应用多种出行数据对公交车站位置、公交线路、时刻表、乘客选择定制公交的概率等问题进行优化.以上规划方法须通过训练数据来拟合模型参数,通过权重参数反映路网状态的随机性,根据相应的算法求解规划线路.这类参数模型的训练常因数据存在异常值而导致模型参数存在偏差,在实际模型中需要增设假设条件才能达到合理的结果,实际问题难以得到验证.例如,Gao 等[5]通过分析离散路径分布数量的多项式算法,指出参数数量与路段数量成指数关系,部分参数模型因为参数维度高求解效果不理想.另有学者基于非参数模型对线网优化展开研究,Mao等[6]设计了一种非参数强化学习模型解决随机时变网络中的自适应路径问题.研究表明,在需求高峰期Q学习与基于树的函数逼近相结合的性能优于传统随机动态规划方法.Q学习是一类高效的非参数模型[7],通过智能体在未知环境下采取动作去探索状态空间,并通过环境奖励做出判断,以解决维度高、数据需求大等问题.传统的Qlearning 算法因奖励稀疏会导致求解速度慢,效率低等问题.
本文基于改进Q-learning 算法提出了一种基于势能场的非参数强化学习路径规划方法,有效解决了城市复杂路网条件下路径求解速度慢、时间长的问题.针对现有公交系统大客流跨区域出行需求及实际道路环境,提高了跨区域定制公交路径的通行效率,通过减小乘客步行需求和出行时间,改善定制公交线路的搭乘舒适度.
1 问题描述
大客流跨区域通勤出行在中大型城市非常常见,城市通勤者每天需要换乘不同交通工具才能到达目的地,若搭乘线路发生拥堵会导致通勤者的时间不确定性.定义跨区域定制公交路线具有以下特征:①在出发区域和目的地区域设置多个公交停靠站,有助于乘客短距离步行得到定制公交服务;②为乘客提供直达式服务;③定制公交路线只安排少量或无中间停靠站,如图1中虚线所示.
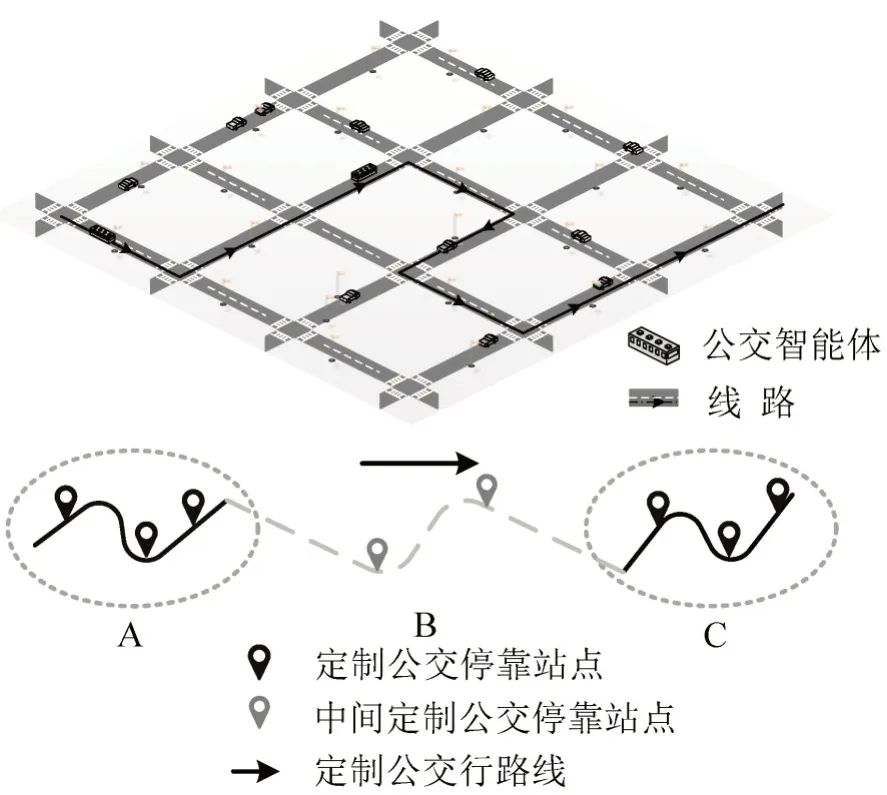
图1 典型的公交线路示意图Fig.1 Schematic diagram of a typical bus line
图1中,A区域和C区域为定制公交线路上下车需求区,B 区域中存在少量乘客搭乘,通过减少中间区域乘客需求,解决因中途站点请求数量多引起的频繁停车、等待、再次启动等问题.传统公交因无法准确估计沿线乘客数量,在高峰时期难以保障出行者的需求,而定制公交可以根据城市客流规律有效地提供定制化服务,解决公交服务配套设施供给不足问题.本文通过改进Q-learning算法对区域公交搭乘路径进行搜寻,通过乘客与定制公交平台的信息交互获取乘客上下车需求,进而优化定制公交跨区域通勤的承载率.并结合区域道路环境,乘客数量,道路拥堵状态等因素设置Q-learning的奖惩函数,解决实际交通路网环境下路径搜寻不合理,计算效率低等问题.
2 基于Q-learning强化学习的定制公交路径优化
2.1 Q-learning规划方法
Q-learning 为马尔可夫决策过程(S,A,P,γ,R),其中,S为所有环境状态,A是智能体适应环境所能采取的动作集,P为系统动态过程,P(s′|s,a)表示状态s过度到s′采取动作a的概率,奖励R为采取动作a时所获得的回报,γ为折扣系数,表示历史经验对将来估计的重要程度.如图2所示,Q-learning算法通过搜索动作获得最大奖励,并基于奖励的反馈为智能体提供决策依据.首先,智能体在当前状态s下从可用动作列表中选择一个动作a.然后,执行或评估所选择的动作,并将所选行动中获得的奖励R在Q 表中更新.智能体将识别环境模型中的下一个状态s′,并采取下一个动作a′.最后,智能体将检查目标完成情况.
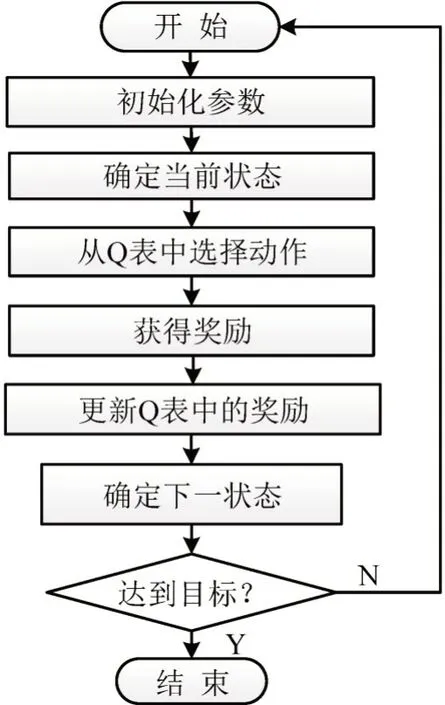
图2 Q-learning 算法流程图Fig.2 Q-learning algorithm flow chart
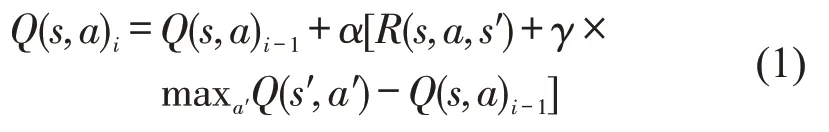
式(1)为Q-learning 迭代更新公式,根据maxa′Q(s′,a′),即下一个状态s′中选取最大的Q(s′,a′)i值乘以折扣因子γ加上真实回报值为Q现实,而根据过往Q 表中的Q(s′,a′)i-1作为Q估计.i为迭代数,通过更新其估计值来逼近真实Q现实值.其中,学习率α是新学习经验的权重,α∈(0,1),折扣因子γ是决定未来状态重要性的变量.高折扣因素将更多关注可能的未来奖励并忽略当前经验的重要性,并使得Q-learning 算法能够以更快的速率收敛.在选择动作的执行过程中,Q-learning 将搜索具有最大奖励的动作,即为贪婪选择,由贪婪概率触发.贪婪概率过高会促使智能体在环境中继续探索,智能体将面临难以收敛的问题.
下面我通过比喻、夸张、对比和反问四种修辞手法,分别阐述在《哈利·波特》小说的翻译过程中,修辞法准确的翻译与我们的习俗与文化相互结合帮助读者真正理解《哈利·波特》的内容,地道准确的融合提高读者对《哈利·波特》的理解力。
2.2 状态行为对矩阵
智能体的状态表示为公交在城市区域中所处的位置,本研究将城市区域分为交叉口、路段和居民小区,分别代表一个状态.车辆在开始进入区域后启动初始化参数并识别当前状态,从Q 表中选择一个动作确定下一个状态获得的奖励是否达到目标,如果达到目标则结束,未达到目标则更新Q表中的奖励值.通过Q-learning算法动作列表引导智能体进入下一个状态,直至智能体在整个过程中获得最优解.
定制公交智能体在城市区域内寻找路径时会在每一个状态空间进行探索,因此将区域内的路段及交叉口作为Q-learning算法动作选择依据.如图3所示,在交叉口和路段的状态位置时智能体有4 种动作可以选择,分别为前进、左转、右转和掉头,智能体将依次在路段和交叉口的状态位置之间选择,所选择的动作将会被存储在路径时序计划管理中,并输出每个时间段所经历的路段和交叉口,直到达到Q-learning算法最优的路径方案.

图3 智能体动作选择过程Fig.3 Agent action selection process
2.3 奖励和惩罚函数设置
如图4所示,综合考虑定制公交的路段行程时间、乘客搭乘便利性、公交线路可达性等因素设置了Q-learning算法的奖励和惩罚函数.
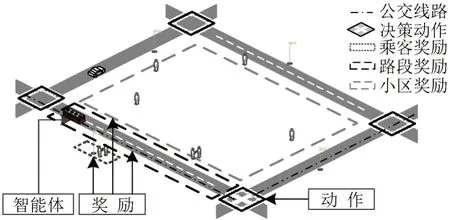
图4 Q-learning 环境示意图Fig.4 Schematic diagram of Q-learning environment
(1)乘客的奖励函数设定.
根据乘客提交的出行需求,将出行的起讫点记入数据集中,把有相似OD需求通过k-means方法进行聚类分组,以公交站点位置u(xk,yk)为聚类中心,k为聚类中心数.有n位乘客请求位置坐标数据集为X={(x1,y1),…,(xj,yj),…,(xn,yn)} ,其中dk∈Rd,Rd≤500 m,将集合中的相似数据划分为k类,对于每一组样本数据中的数据采用欧式距离计算每类数据点到聚类中心u(xk,yk)的距离平方和,即
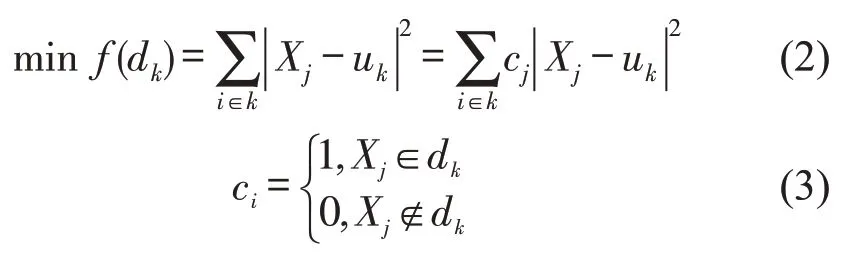
式中:dk为聚类中心约束半径;cj取值为0或1,表示判断该点是否在约束内;uk为聚类中心位置坐标;Xj为乘客请求位置坐标;f(dk)为乘客位置距聚类中心距离累计函数.
基于小区边缘街道的公交站点设置定制公交乘车奖励,本文将乘客数量作为Q-learning的奖励值,将每一位乘客的奖励值设置为1,每一个公交站台的乘客人数N,即为该站点的奖励值.
(2)道路拥堵惩罚.
实际车辆在路段行驶过程中存在部分路段拥堵,根据拥堵的程度不同,加入拥堵系数T作为奖励函数的一部分.乘客奖励和路段惩罚后的奖励函数为

式中:T为城市道路拥堵指数,根据道路等级和交通车辆行驶速度将拥堵指数分为5 级,分别为“畅通(0,2]”“基本畅通(2,4]”“轻度拥堵(4,6]”“中度拥堵(6,8]”“严重拥堵(8,10]”,数值越高表明交通拥堵状况越严重.N为乘客需求请求数,φ,θ为道路拥堵指数和乘客需求权重系数.
(3)小区位置惩罚.
为防止定制公交线路搜寻过程中通过居民小区,本文将其状态设置为Q-learning 算法的惩罚项,奖励值设置为-10,使其学习有用经验达到最大累计奖励值.
2.4 奖励函数塑形
稀疏的奖励函数导致算法收敛缓慢,通过改进Q-learning 算法的奖励函数,增加额外的奖励F(s,a,s′)可以丰富稀疏的奖励信号,为智能体提供奖励梯度信息.将额外奖励添加到环境奖励中,以创建一个合成奖励信号R′(s,a,s′),用于算法学习,可以解决奖励稀疏性问题.将出口设定为大目标,奖励值为20,其他乘客和道路状态设为道路额外奖励.改进后的奖励回报函数如为

式中:Φ(⋅)是返回状态s的电势函数;λ是更新值函数估计值使用的折扣因子.通过定义势能函数,并结合先验知识,使智能体在探索开始时不是均匀随机的,而是偏向探索具有高潜力的状态,当智能体从一个低势能状态转移到高势能状态转移时,它将获得额外地奖励,使用两个状态的势能差值作为额外奖励可以保证不改变MDP的最优解[7].
3 实验与结果分析
本文对江西省南昌市高新区的定制公交路线进行了实验分析.图5为高新区的城市道路结构示意图,其中,横向有艾溪湖北路、民强路和火炬大街3条主干道,纵向有青山湖大道、高新大道、京东大道和高新七路4条主干道.共有68个路段、43个交叉口和28个小区.该区域的功能主要以企业、工业园和学校为主,从高新区通往南昌县、新建中心和昌北开发区日常通勤需求量较大,且该区域离南昌市地铁1号线有一定距离,对于远距离通勤的工作者们下班极为不便,适合定制公交在该地区应用.经过实际调查发现该地区的公共交通系统较为落后,公交站台设置不完善,部分采用临时站台,甚至在部分道路上不设置公交停靠站点.本次实验中,模拟包括乘客OD需求点对55个,合计的服务乘客数量200人次,车辆核载人数为35人,乘客需求与发车时间误差不超过20 min.
如图5所示,建立一个15×11 的小型网络方格,其中图5(b)白色方格代表区域中的路段,灰色部分代表交通小区,黑色虚线代表智能体行驶线路,其中每一个方格代表一个状态—行为对.智能体将根据需求奖励,搜寻出口目标及中途乘客奖励目标,完成线路搜寻.本次实验平台基于python3.6,电脑配置为4 核CPU,七彩虹显卡GTX1060 3 G,固态硬盘240 G,设置Q-learning 学习率从0.5~1.0,按每0.1 个单位取值,折扣因子同理取值计算,训练次数为700次.学习率α=0.9,折扣因子γ=0.9时,智能体能最有效地获取奖励值.
(1)高新区定制公交路径分析.
图6~图8为计算所得区域路径结果,图6为高新区至南昌县1、2 和3 号线定制公交线路图,图7为高新至昌北开发区定制公交4和5号路线图,图8为高新区至新建中心定制公交6 号和7 号路线图,具体参数如表1所示.定制公交车区域线路直线系数均大于1.4,比传统公交直线系数大25%左右,定制公交在区域内承载率达到90%,保证定制公交在区域范围内接送更多的乘客.还能服务少部分在定制区域外上车的乘客.
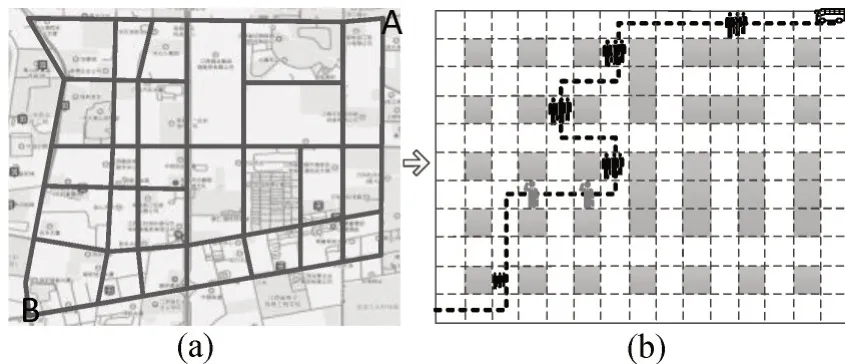
图5 区域交通街区示意图Fig.5 Schematic diagram of regional traffic block

图6 定制公交1、2 和3 号线路区域轨迹图Fig.6 Customized bus line 1,2 and 3 area trajectory

图7 定制公交4 和5 号线路区域轨迹图Fig.7 Customized bus line 4 and 5 area trajectory

图8 定制公交6 和7 号线路区域轨迹图Fig.8 Customized bus line 6 and 7 area trajectory

表1 高新区定制公交线路信息Table1 Basic information of customized bus in high-tech zone
(2)算法性能分析.
从表2中可以看出,通过奖励重塑的方法有效提升了Q-learning算法的计算效率.改进Q-learning算法相比传统算法的迭代次数平均下降了11.64%,计算时间平均缩短了19.76%.通过增加势能函数对奖励函数的重塑,能有效引导智能体获得目标奖励,相比传统的Q-learning 算法盲目搜索,改进的算法更容易完成路径搜寻.针对实验中7条公交路径进行优化的计算效率波动较大,迭代次数最高下降了22.83%,最低下降了6.1%.提升效率最为明显的是线路6,迭代次数和计算时间均下降22%以上,这可能与状态的位置及奖励函数大小有关.改进后的迭代次数线路1 比线路6 相差179 次(40%),在相同的环境下设定不同的奖励对算法的求解性能影响很大,说明合理设置奖励函数可以提高Q-learning算法效率.

表2 改进Q-learning 算法计算效率对比Table2 Improved Q-learning algorithm calculation efficiency comparison table
(3)定制公交线网分析.
如图9所示,为定制公交线网3条路径规划示意图,中间定制公交停靠站点较少,线路较为固定,以保证定制公交在服务过程中能够有效抵达目的地区域.减少中途停车需求,有效缩短乘客的通行时间,提高乘客舒适满意度.

图9 区域定制公交线网示意图Fig.9 Schematic diagram of regional custom bus network
定制公交全线数据如表3所示,直线系数在1.4 左右,部分略低于1.4,而在表1中区域内的定制公交直线系数均大于1.63,是由于区域内路径曲折,导致总程公交线路系数增大,相比传统公交在直线系数的优化上不存在明显优势.
与表1中的行程速度和满载率相比,定制公交因中途停站少,停靠时间短,实际定制公交的行程速度比区域内的行程速度要快很多,满足了公交1 h 内通行时间的要求.区域定制公交在通行效率、可达性等方面有明显的优势,且基本保证乘客一人一座,在乘坐舒适度上相比普通公交有较好改善.

表3 区域通行线路基本信息Table3 Basic information on regional access routes
4 结 论
本文研究了城市区域定制化公共交通的搭乘方案,基于改进的Q-learning强化学习算法为定制公交系统提供有效的区域路径规划,解决了区域乘客通行需求问题,并优化了乘客步行距离、通行时间及乘客搭乘站点位置.通过对高新区路段、交叉口及居民小区位置设定奖惩函数,采用奖励重塑的奖励改进优化方法,提高了智能体在环境中探索效率,通过小奖励的诱导以获得最大的奖励值.结果表明,改进的Q-learning 学习算法在求解定制公交通行路径上有所提升.并为跨区域定制公交区域路径寻找提供了新的解决方案.改善了传统公交服务不能直达目的地、换乘等待时间过长及低峰时段公交运力浪费等问题,是对传统公交运营模式的一种创新.
