基于多源轨迹数据的城市交通状态精细划分与识别
2020-02-28邬群勇胡振华
邬群勇,胡振华,张 红
(1.福州大学空间数据挖掘与信息共享教育部重点实验室,福州350108;2.卫星空间信息技术综合应用国家地方联合工程研究中心,福州350108;3.数字中国研究院(福建),福州350003)
0 引 言
随着经济社会的快速发展,机动车的拥有量急剧增加,交通拥堵已经成为大中城市一个亟待解决的问题[1].交通状态的精细划分和识别是改善交通拥堵的重要前提,对城市交通管理具有重要意义.近年来,随着定位技术和无线通信的发展,装载定位设备的浮动车可以实时产生城市交通流信息的轨迹数据,这些数据覆盖广、成本低,被广泛地用于城市交通状态识别[2-4].
在单一数据源研究的基础上,韦伟等[5]运用时空Moran 散点图结合层次聚类方法分析各路段交通状态的时空特性;邬群勇等[6]结合出租车轨迹数据,提出了基于拥堵指标的异常判别方法.随着大数据时代的到来,基于多源大数据融合挖掘将解决目前单一数据源覆盖范围和数据质量不足的问题,大大提高交通运行评估的精度和可靠性[7-8].出租车和公交车数据作为两种不同的数据源,数据互补且获取容易,为新时期城市交通状态识别提供了可靠的数据基础.
以往对道路交通状态的划分主要基于整条路段[9]或者定长划分路段[10].路段不同局部位置的交通状态存在一定的差异,基于整条路段的研究将整条路段视为一种交通状态,没有进行划分,难以区分路段各局部位置的交通状态.基于定长划分路段的研究通过对路段进行等间隔划分,在一定程度上实现了交通状态划分,但存在划分粒度过粗或者过细的可能,没有真正将路面交通状态相同、相近的段合在一起,难以灵活、精细地反映道路交通状况的实际区别.为了实现交通状态的合理划分,付子圣[11]等研究了基于单一GPS轨迹的二次聚类的方法.
本文利用出租车和公交车轨迹数据,研究一种基于多源轨迹数据的城市交通状态精细划分和识别方法,通过对道路交通状态的精细划分实现精细识别和分析,以厦门市公交和出租车轨迹数据为例进行验证和分析.
1 研究方法
研究流程如图1所示.首先,对研究数据进行处理;接着,对各路段上的轨迹点归一化后的速度值和空间位置值分别进行聚类;然后,对类簇进行二次处理,得到各路段交通状态精细划分的分割点以划分各交通状态范围;最后,分别统计各交通状态包括的轨迹点速度归一化值的均值,依据划分的4个交通流状态层级,精细识别路段局部位置的交通状态.
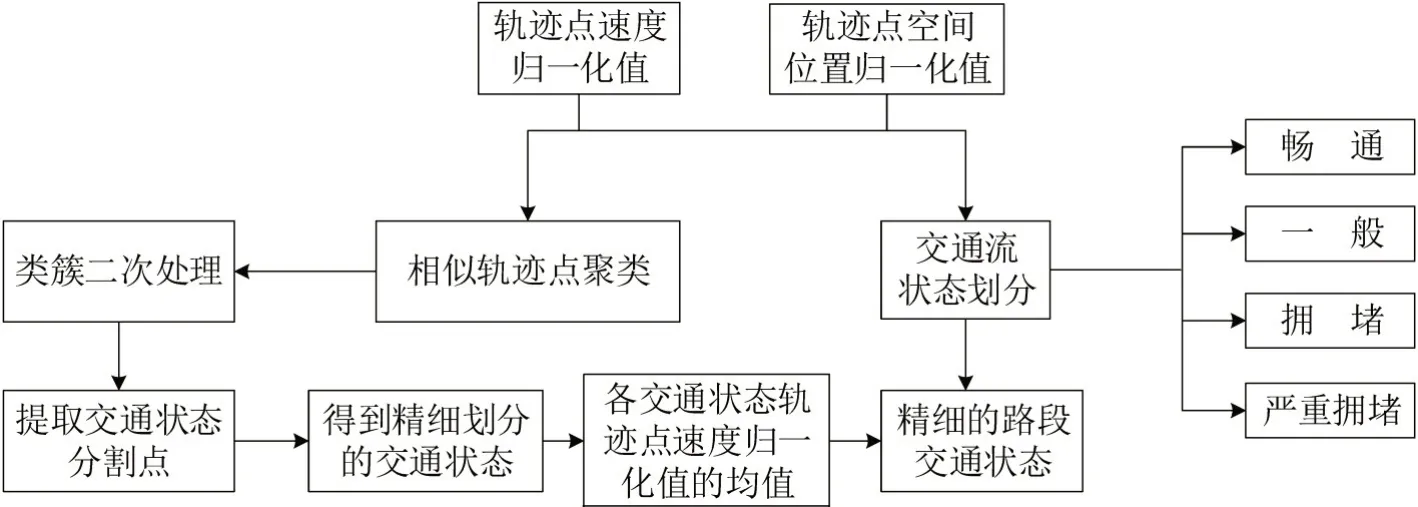
图1 基于多源轨迹数据的城市交通状态精细划分和识别流程Fig.1 Urban traffic status fine division and recognition process based on multi-source trajectory data
1.1 数据处理
本文所用数据包括厦门市出租车和公交车轨迹数据,以及OpenStreetMap 的路网数据.轨迹数据主要包括车辆编号、时间、位置、速度、出租车载客状态、公交车所属线路等基本信息,路网数据主要包括路段编号、路段长度等基本信息.以轨迹点的速度值和空间位置值为属性数据对轨迹点进行聚类,需要先计算每个轨迹点的空间位置值,由轨迹点距离相应路段起点的距离表示,单位为m.
轨迹点的空间位置值为坐标值,能够达到成百上千,与速度值单位和量纲都不一样.直接使用这两种参数会对聚类的结果产生较大的影响.将各个轨迹点的速度值及其空间位置值进行归一化处理,转化为无量纲的纯数值,使得它们能够用于聚类和融合.归一化处理的计算公式为
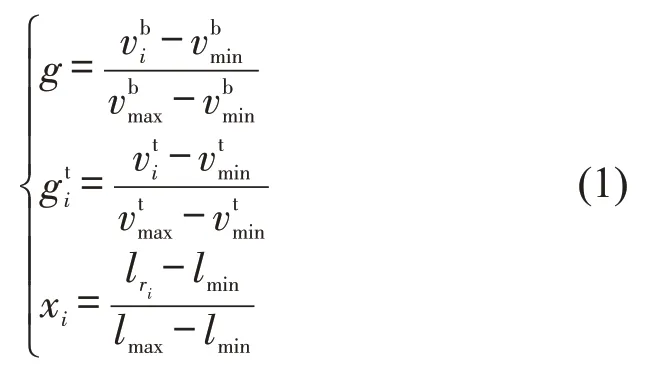
式中:gbi、gti分别表示公交车、出租车轨迹点i速度归一化后的值;vbi、vti分别表示公交车、出租车轨迹点i的实际速度值;分别表示在一个时间段Δt内的所有公交轨迹点中的最大、最小车速值和出租轨迹点中的最大、最小车速值;xi表示轨迹点i在路段上ri的位置;lri表示路段ri的长度;lmax、lmin分别表示路网中各路段的最大和最小长度.
1.2 基于相似轨迹点聚类和二次处理的交通状态精细划分方法
为尽可能对路网上不同路段的局部位置的交通状态进行分析,通过对路段上的交通状态进行动态精细划分实现精细分析.“动态”主要指:①同一时间不同路段的交通状态划分结果不同,②同一路段的交通状态在不同时间段划分结果不同.交通状态动态精细划分主要包括相似轨迹点聚类、类簇二次处理和各交通状态速度值计算等3个步骤.
1.2.1 相似轨迹点聚类
以5 min为时间间隔,在每条路段上进行轨迹点聚类,通过轨迹点聚类得到路段不同位置的轨迹点簇.相同簇内轨迹点的空间位置邻近,且速度相近;不同簇的轨迹点空间位置相距较远,且速度具有一定的差异.不同簇可表征路段不同位置的交通状态,进而实现交通状态的划分.
设城市中共有q条路段{r1,r2,r3,…,}rq,一条路段由m个轨迹点{p1,p2,p3,…,}pm组成,每个轨迹点的聚类特征参数为归一化后的速度值和空间位置值,构成的样本矩阵P为
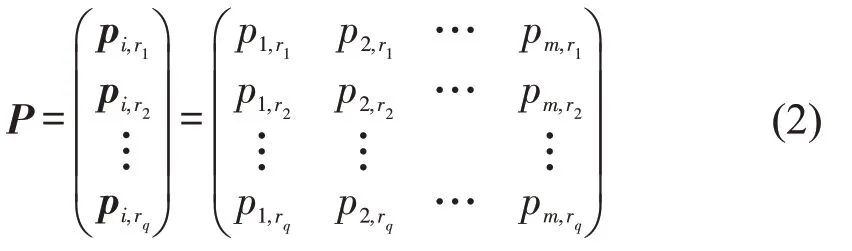
式中:pi,rq表示第rq路段的第i个轨迹点.
将样本矩阵P带入聚类过程中,具体步骤如下:
Step 1输入数据,选取样本矩阵P中的一行作为数据集,每行代表一条路段上的所有轨迹点.
Step 2从数据集中随机选取一个轨迹数据作为初始聚类中心c1.
Step 3计算每个轨迹点与当前聚类中心的最短距离di,j,计算每个轨迹点被选为下一个聚类中心的概率,依据概率选择新的聚类中心.最短距离采用欧式距离,计算公式为
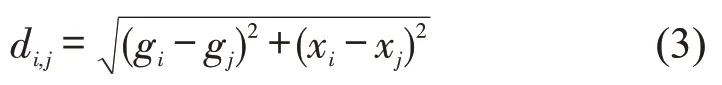
式中:di,j表示轨迹点i和聚类中心j之间的距离;gi和gj分别表示表示轨迹点i和聚类中心j的速度归一化值;xi和xj分别表示轨迹点i和聚类中心j的空间位置归一化值.
Step 4重复Step 3直到选出k个聚类中心.
Step 6设置不同的k值,重复Step 1~Step 5,得到不同聚类结果的轮廓系数,选取轮廓系数最大时的k值作为最终的聚类中心数.
Step 7遍历矩阵P中所有行,重复Step 1~Step 6,完成城市中所有路段上的轨迹点的聚类并输出.
1.2.2 相邻类簇的二次处理
设一条路段上的轨迹点经过初步聚类得到n个类簇{ }Cy1,Cy2,Cy3,…,Cyn,每相邻两个类簇构成相邻类簇集Cx={(Cy1,Cy2),(Cy2,Cy3),…,(Cy(n-1),Cyn)},任意相邻类簇(Cy(n-1),Cyn)之间可能存在如图2所示的3种分布情况.部分重叠和完全覆盖情形中的相邻类簇存在交叉使得类簇分割点无法提取,进而无法以类簇分割点精细划分路段上的交通状态.针对该问题,通过对类簇进行拆分和融合,得到各个分离的类簇,进而提取出类簇的分割点进行路段上交通状态精细划分.
以任意相邻类簇(Cy(n-1),Cyn)的临界点为初始分割点将(Cy(n-1),Cyn)拆分为i个类簇,2 ≤i≤3,拆分后的类簇集C={C1,C2} 或C={C1,C2,C3} ,如图3所示,构造最终的结果集Cf如下.

图2 相邻类簇位置关系示意图Fig.2 Schematic diagram of location relationship of adjacent clusters
(1)统计各类Ci包含的轨迹点数Ni.
(2)从C1开始处理,判断N1>5?路段上的轨迹点数达到一定的数目才能有效进行交通状态评估,文献[9]取3个以上,为提高准确度并结合实验效果,本文取5 个.若是,则将C1从结果集C移至结果集Cf;否则,将C1与相邻的下一个类C2融合,即C1=C1+C2,N1=N1+N2,更新类簇集C,令C中各元素Ci编号始终从1开始.
(8)五河尾闾区水系复杂,地势平坦,泥沙淤塞河道、水流不畅现象依然存在。除信江尾闾貊皮岭分洪道已实施,其他已纳入规划的尾闾河道和湖区洪道整治一直未进行更深的研究,五河尾闾疏浚工程也于2005年后停止实施。
(3)依次遍历类簇集C直至C中最后一个类C1,更新Cyn=C1,结束(Cy(n-1),Cyn)的二次处理.
(4)遍历相邻类簇集Cx={(Cy1,Cy2),(Cy2,Cy3),…,(Cy(n-1),Cyn)},完成所有类簇的二次处理,得到最终结果集Cf ={Cf1,Cf2,…,Cfk} ,k≤n.
(5)以Cf ={Cf1,Cf2,…,Cfk} 中任意两相邻类中前一个类的右边界与后一个类的左边界的中间点作为分割点对路段交通状态进行精细划分.

图3 相邻类簇处理示意图Fig.3 Schematic diagram of adjacent cluster processing
1.2.3 交通状态速度计算
采用特征级融合的策略对路段上的各交通状态ri包含的公交车和出租车轨迹点速度归一化值gbi、gti进行融合,利用两者的均值Gri代表交通状态ri的速度,公式为

式中:nb、nt分别为交通状态ri上公交车、出租车的轨迹点数目.
1.3 基于模糊聚类的交通流状态层级划分
结合《交通工程学》《城市道路交通管理评价指标体系》和文献[12],将交通状态分为畅通、一般、拥堵、严重拥堵4 个层级,依次对应自由流、稳定流、拥挤流及堵塞流.
设样本空间中共存在m个早高峰轨迹点{p1,p2,p3,…,pm} ,任意轨迹点pi以速度归一化值作为唯一特征,记为pi1.本文通过模糊聚类对聚类中心vk和隶属度矩阵U进行迭代,直至目标函数最小,以此将样本分为4个类,即C=4,分别对应4个城市交通状态层级.目标函数为

式中:uk,i介于0~1,为第i个轨迹点属于第k类的隶属度;V是聚类中心矩阵;l为加权指数,用于调整聚类的模糊性,一般取2;di,k是第i个轨迹点与第k个聚类中心的欧氏距离.
2 实例分析
实验采用厦门岛2015年6月15日(星期一)早高峰(07:00-09:00)的公交车和出租车轨迹数据,经过预处理后轨迹数据集达到511 401条,其中公交数据147 331 条,出租数据364 070 条.以5 min 为统计间隔划分为24 个时间段.以镇海路口和同安路口交界处的6 条路段作为实验路段,依次编号,如图4所示.实验分别给出了以路段1为例的单一路段和路口多路段的交通状态精细分析.
2.1 单一路段交通状态精细分析
路段1 上的轨迹点经聚类分为4 类,如图5(a)所示,类Ⅰ和类Ⅱ完全分离,类Ⅱ被类Ⅲ完全覆盖,类Ⅱ与类Ⅳ部分重叠.利用类簇二次处理方法,将4 个类簇融合成为3 个,如图5(b)所示,表明该路段上的交通状态被精细划分成3种,分别对应路段上不同范围内的交通流速度情况.类Ⅰ的总体速度相对最高,类Ⅱ区间内既有高速车流也有低速车流,总体速度值处于中间,类Ⅲ总体速度相对最低.该方法能够较好地对路段上交通状态进行精细划分,进而实现路段不同位置的交通状态的识别.

图4 镇海路和同安路路口路段分布Fig.4 Distribution of road sections of Zhenhai Road and Tong'an Road
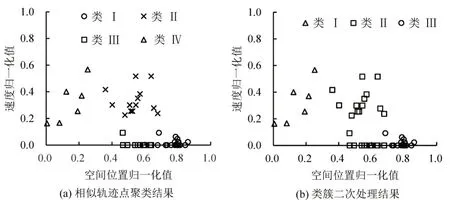
图5 相似轨迹点聚类及二次处理结果Fig.5 Results of similar trajectory point clustering and secondary processing
计算得出早高峰期间每5 min 交通状态的局部演化情况,由图6可知:
(1)路段1 在早高峰期各个位置基本完全处于拥堵或者严重拥堵状态.经查询,该路段附近分布有两家大医院、两所中学和两所小学,人流和车流都非常密集,是厦门市拥堵最严重的几个路段之一.
(2)在07:00-08:00期间,路段的后半段的拥堵更严重;08:00-09:00期间,严重拥堵更多的集中在路段的前半段.结合POI 分布发现,路段的后半段紧邻厦门群惠小学和镇海菜市场,07:00-08:00 正是学生上学及菜市场最繁忙的时间段,集中大量人流和车流,导致后半段的拥堵极为严重;随着时间的推移,08:00 以后,学生全部到校,以及菜市场人流的逐渐下降,路段后半段的拥堵情况有所缓解;随着路段前半段紧邻的银行、厦门市公安局出入境部门开始上班,08:00以后,路段的前半段的拥堵开始加重.
2.2 路口多路段交通状态精细分析
镇海路和同安路路口路段早高峰交通状态如图7所示,由图7可知:
(1)从拥堵的空间分布上来看,路段2~6 拥堵情况较为严重,路段3基本较为畅通.路段2和4的后半段拥堵相对于前半段更为严重,路段5的前半段拥堵会较为严重,而路段6 基本处于拥堵状态.结合POI发现,路段2后半段分布的厦门市第一医院,路段4后半段有地铁站、大同中学及中山公园,而路段5 与路段6 夹着厦门实验小学.这些POI 的分布对路段上的局部交通状态具有较大的影响.
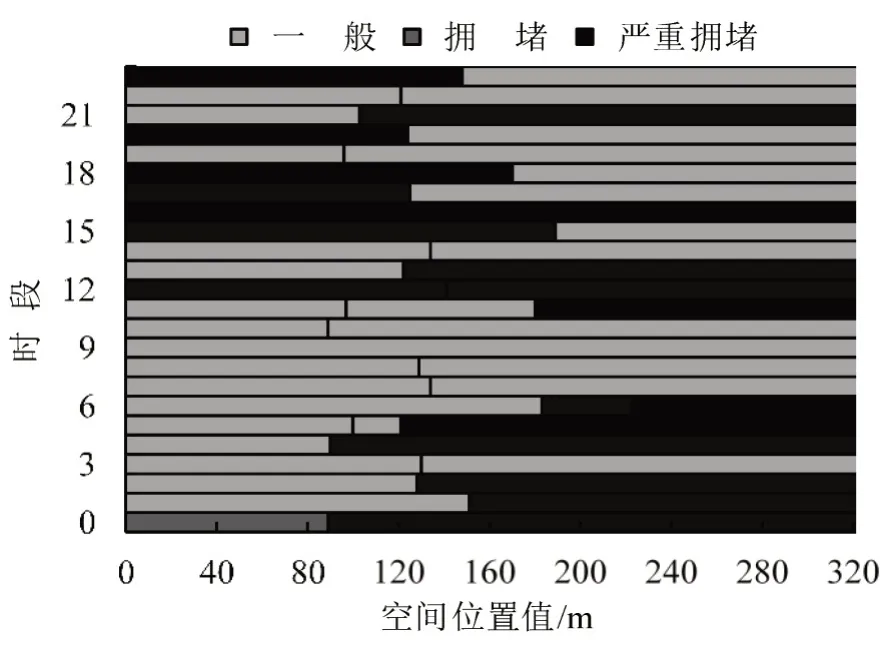
图6 早高峰路段1 交通状态图Fig.6 Early peak traffic status map of section 1
(2)从拥堵的时间分布来看,基本集中在08:00左右,整体上随着时间接近08:00 拥堵开始加重,08:00过后,随着早高峰的逐渐结束,拥堵开始相对缓解.
3 结 论
通过对出租和公交轨迹数据进行融合挖掘,提出一种全新的城市交通状态精细划分和识别方法,对道路上交通状态进行了动态精细划分,进而实现城市交通状态的精细识别和分析.研究结论为:针对当前单一FCD 数据质量和数据量不足的问题,本文基于归一化处理,在特征级建立了多源数据融合方法,实现出租和公交轨迹数据融合挖掘,有效地扩充了数据量,实现数据互补,提高了结果的可信度;相比于传统基于路段或者定长划分路段的城市交通状态识别方法,本文通过构建相似性聚类算法,并结合类簇二次处理,对城市道路上交通状态进行了动态精细划分,进而实现了道路局部位置交通状态的精细识别和分析,有效揭示了道路上交通状态的演化情况,为城市交通拥堵改善和治理提供决策支持.
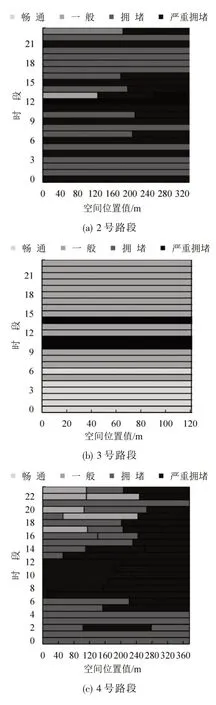

图7 镇海路和同安路路口路段早高峰交通状态图Fig.7 Early peak traffic status map of Zhenhai Road and Tong'an Road intersection
本文对城市道路交通状态进行了精细划分和识别,但尚未对路口处进行详细研究.后续的研究将着重于交叉路口处的拥堵演化分析.
