优化基于近红外光谱的联合间隔偏最小二乘法建模检测芝麻油掺伪含量
2020-02-26陈洪亮
陈洪亮,曾 山,王 斌
(1.南京财经大学 信息工程学院,南京 210046; 2.武汉轻工大学 数学与计算机学院,武汉 430040)
芝麻油是一种营养丰富的植物油,富含油酸和亚油酸,其特有的香味和出色的氧化稳定性使其成为备受青睐的调味品[1]。近年来,芝麻油的营养价值日益受到各行业的广泛关注[2]。由于芝麻油具有较高的营养价值,其售价远高于大豆油、菜籽油等常见食用油,因此一些不法生产者和经营者将低价格油掺入芝麻油中销售,这种做法严重损害了广大消费者和商家的利益。
目前,国内外学者对食用油掺伪检测方法的研究已取得了一定的进展,一些物理和化学方法被应用于食用油掺伪检测[3-4]。常规理化方法操作简便,不需要昂贵的仪器,但耗时长,测定过程往往要多名实验人员配合完成,无法满足快速检测油脂掺伪的要求[5]。色谱法与核磁共振波谱法分析快速,适合大批量油脂样本的掺伪检测,但所用仪器价格昂贵,且需要专业人员操作[6-7]。
近红外光谱(NIR)目前逐渐被应用到食用油的定性定量分析领域[8-9],相较传统的食用油分析方法,近红外光谱分析技术具有灵敏度高、稳定、能实现快速在线分析等优点。近红外技术在食用油掺伪检测方面已有研究。涂斌等[10]以激光近红外光谱分析技术结合化学计量学方法对稻米油掺伪进行定性-定量分析,对比了偏最小二乘法(PLS)和支持向量机回归(SVR)两种方法,二者均有较高的预测精确度。冼瑞仪等[11]采用可见和近红外透射光谱分析技术结合区间偏最小二乘法(iPLS)、联合间隔偏最小二乘法(SiPLS)和反向区间偏最小二乘法(BiPLS)对掺杂不同含量煎炸老油的橄榄油建模分析,SiPLS和BiPLS所建模型均取得了较好的预测效果,为合格植物油中掺杂其他不良油品的检测提供了参考。丁轻针等[12]采用标准正态变量变换(SNV)和偏最小二乘法(PLS)建立了芝麻油掺伪定量分析模型,当掺入量达到10%以上时,可以准确、可靠地实现快速检测。
虽然基于近红外光谱的食用油掺伪检测方法已有研究,但均未对预测食用油掺伪含量的最优特征波段进行探索,本研究应用近红外光谱分析技术结合无信息变量消除法、联合间隔偏最小二乘法和带极值扰动的简化粒子群优化算法优选特征波段建立芝麻油-大豆油掺伪含量分析模型,以期对波长变量做充分筛选后建立芝麻油掺伪含量预测模型取得相较单一SiPLS模型更好的预测效果。
1 材料与方法
1.1 试验材料
食用油掺伪定量鉴别试验样品:为配制具有代表性的掺伪样本,购买市售不同品牌、原料品种、加工工艺的芝麻油和大豆油,将大豆油以一定比例掺入芝麻油中,共配制32种掺伪含量。其中每种掺伪含量配制12份样品,共384个掺伪样品,每份样品约10 g,充分振荡混合均匀后,在实验室静置12 h待测。具体芝麻油掺伪样本中大豆油的掺伪含量见表1。
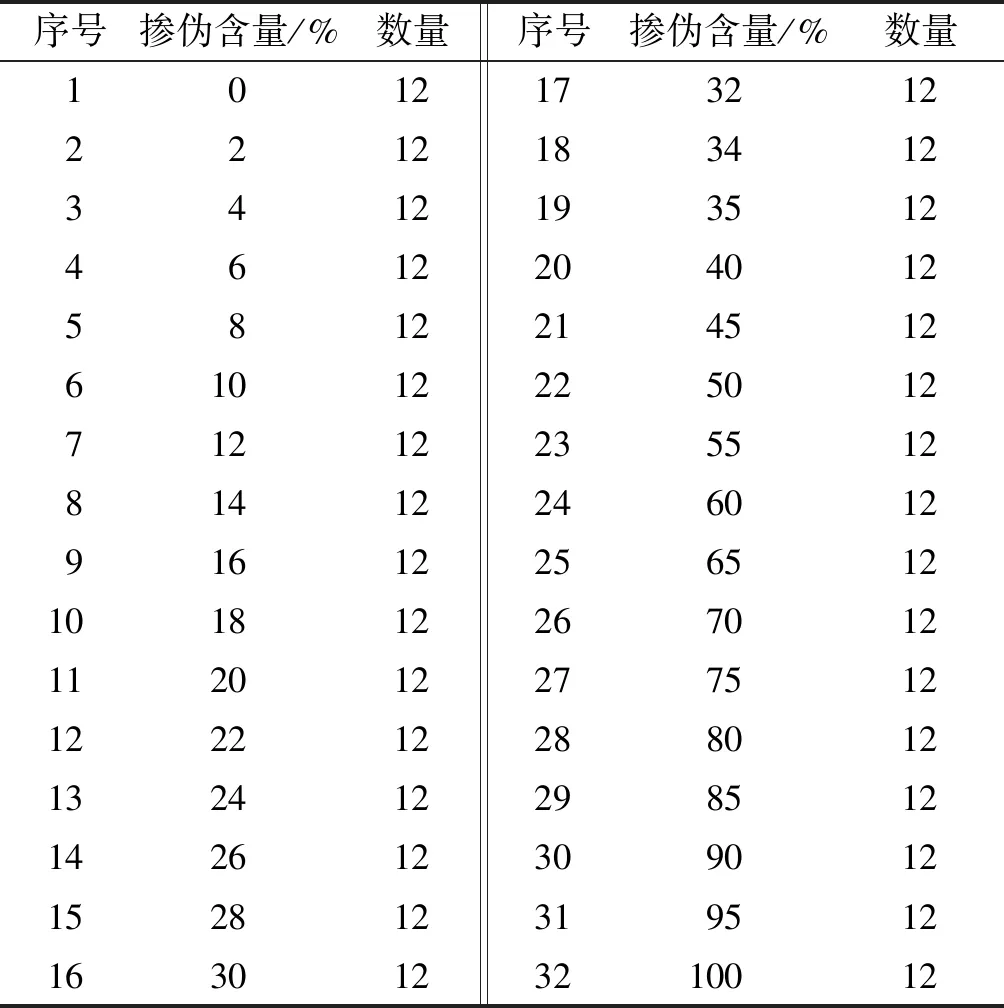
表1 芝麻油掺伪样本中大豆油的掺伪含量
1.2 试验方法
1.2.1 试验流程
基于近红外光谱的无信息变量消除法-联合间隔偏最小二乘法-带极值扰动的简化粒子群优化算法(UVE-SiPLS-tsPSO)对芝麻油掺伪含量定量分析的具体实现流程如图1所示。由图1可知,芝麻油掺伪含量快速检测方法的步骤主要可概括划分为近红外光谱数据采集、光谱预处理、波长变量初步筛选和选择最优特征波段建立掺伪含量预测模型。
1.2.2 光谱采集
掺伪油样品光谱的采集采用激光近红外植物油品质快速检测仪,其主机为Axsun XL410型激光近红外光谱仪。Axsun XL410型光谱仪以新型的超辐射发光二极管(SLED)作为光源,光谱测定范围1 350~1 800 nm,扫描次数32次,分辨率3.5 cm-1,波长重复性0.01 nm,信噪比(250 ms, RMS)大于5 500∶1,温控范围20~100℃。将光谱仪与工业电脑主板连接,方便待测样品光谱数据的采集和保存。试验中选用2 mm光程的比色皿,首先将油样滴在比色皿中,然后将比色皿放入光谱仪内便可开始采集光谱。
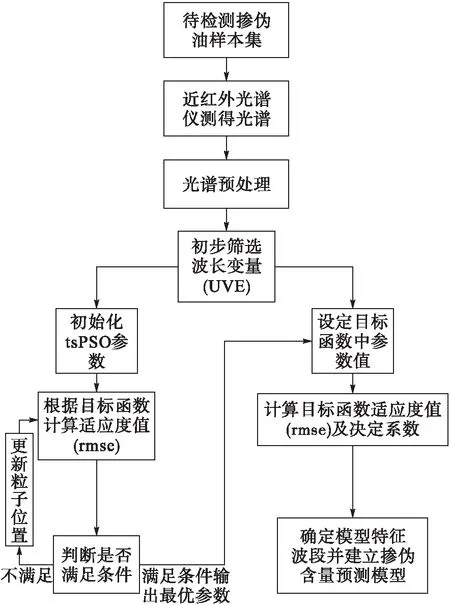
图1 芝麻油掺伪含量快速检测方法流程图
1.2.3 光谱预处理及样本划分
近红外光谱技术属于二次分析技术,采集的光谱含有丰富的信息,但存在影响模型预测效果的因素,如谱带重叠严重、光谱信息专属性差、信噪比低等,建立模型前,为了去除光谱信号的高频随机噪声、比色皿对光程的影响及光线散射和杂散光影响,首先需要对光谱数据进行预处理,确保基于近红外光谱建立的定量检测模型具有较好的性能。采用标准正态变量变换(SNV)进行光谱预处理[13]。此外,本试验对样本光谱数据采用SPXY样本划分法[14],按3∶1的比例划分训练集和测试集,该方法能够覆盖多维向量空间,从而提升模型的预测能力。
1.2.4 建模及参数优化
首先采用无信息变量消除法(UVE)[15]排除与被测组分浓度无关的波长变量,利用SPXY样本划分法划分训练集和测试集后,采用联合间隔偏最小二乘法(SiPLS)结合带极值扰动的简化粒子群优化算法(tsPSO)优选最佳波长区间组合建立掺伪含量预测模型。
间隔偏最小二乘法(iPLS)是由Norgaard等[16]提出的,其原理是将整个光谱分成若干等宽子区间,对每个区间进行偏最小二乘回归,比较全光谱模型和每个子区间模型的性能,最终选择误差最小的子区间。联合间隔偏最小二乘法(SiPLS)[17]是间隔偏最小二乘法的拓展,它通过若干子区间的组合使误差最小。
粒子群优化算法(PSO)由Kennedy和Eberhart在1995年提出[18],该算法通过模拟鸟群、鱼群等生物捕食行为中相互合作机制寻找问题最优解。但是粒子群优化算法在进化后期收敛速度变慢,同时算法收敛精度不高,在多极值的复杂优化问题中易陷入局部最优解。本文采用带极值扰动的简化粒子群优化算法(tsPSO)[19],首先去掉了PSO进化方程的粒子速度项,避免由粒子速度项引起的后期收敛速度慢和精度低的问题,同时增加极值扰动算子用于使粒子跳出局部极值点继续优化。
2 结果与讨论
2.1 光谱预处理及特征波长选择
采用标准正态变量变换(SNV)对32种芝麻油-大豆油掺伪样品的近红外光谱进行预处理,能够有效去除光谱噪声。芝麻油-大豆油掺伪样本的近红外光谱如图2所示。
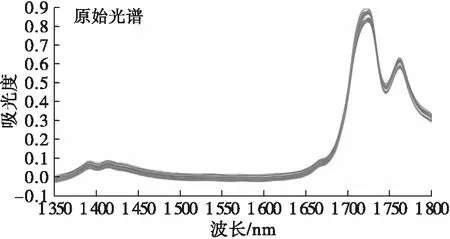
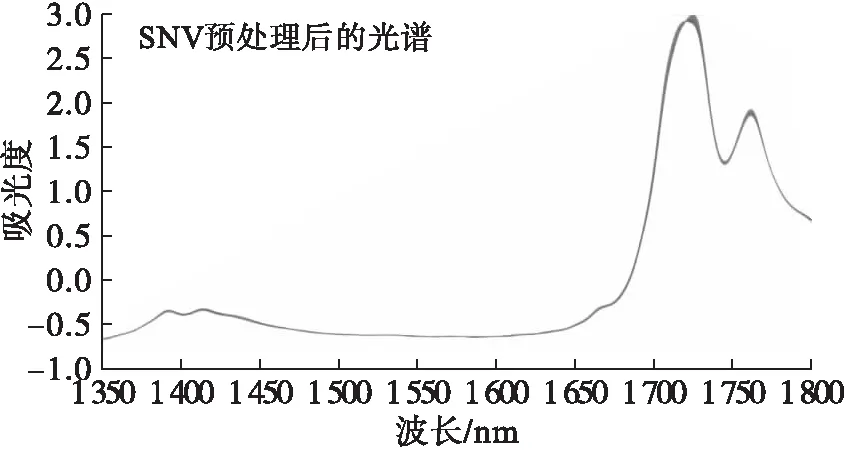
图2 芝麻油-大豆油掺伪样品近红外光谱图
分析图2,原始光谱和SNV预处理后光谱图中各有384条曲线,每条曲线代表一个样本在近红外波段各波长下的吸光度,对比可见原始光谱及经SNV预处理后的光谱,光谱的形状总体保持不变,只是排列更为紧凑。
对SNV预处理后的光谱数据采用UVE初步筛选特征波长,得到的光谱数据包含436个波长变量,经UVE筛选后的光谱图如图3所示。
图3中,横坐标表示经过UVE筛选后剩余波长变量由低到高排序,可见UVE在筛选掉经SNV预处理后的光谱中无信息波长变量的同时,没有破坏总体的光谱结构。
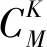
采用SiPLS方法建立模型时,波段的选择对模型的预测准确度存在一定的影响,波段分割过宽或选取波段数过多,会造成信息冗余;波段分割过窄或选取波段数过少,可能会丢失建模所需必要信息,因此选择合适的波段分割间隔和用于建模的波段数尤为重要。采用带极值扰动的简化粒子群优化算法(tsPSO)优化模型能很好地解决这一问题。
2.2 3种模型的建立
为证明本研究方法的优越性,首先建立全波段掺伪含量预测模型和UVE模型作为对比试验。利用SPXY样本划分法对光谱经SNV预处理后的掺伪样本划分为训练集和测试集,采用PLS方法,将训练集光谱数据和掺伪含量数据作为输入量,建立全波段芝麻油掺伪含量预测模型。采用UVE对经SNV预处理后的光谱筛选波长变量,对降维后的光谱数据和掺伪含量数据采用SPXY样本划分法划分为训练集和测试集,对所得训练集样本利用PLS方法建立芝麻油掺伪含量预测模型,3种模型预测结果见表2。

表2 3种模型测试结果
从表2可看出,所建全波段模型训练集和测试集相关系数(R2)均接近1,均方根误差(RMSE)分别为7.34E-2和6.69E-2,芝麻油掺伪含量预测精度一般。而利用UVE筛选后的光谱数据建立的PLS模型,均方根误差(RMSE)分别为7.32E-2和6.50E-2,相较全波段模型,略微降低了预测误差,此外参与建模的波长变量由451个降低到436个,缩短了建模时间。
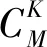
经过tsPSO优化得到参与芝麻油-大豆油掺伪定量分析模型建立的特征波段为1 350~1 353 nm、1 364~1 366 nm、1 368~1 391 nm、1 485~1 515 nm、1 581~1 611 nm、1 643~1 673 nm、1 705~1 718 nm、1 720~1 800 nm,如图4所示。模型测试结果如表2所示。

图4 芝麻油-大豆油掺伪样品近红外光谱特征波段
由表2可知,参与建模的变量锐减到219个,训练集和测试集均方根误差(RMSE)分别为4.39E-2和3.99E-2,并且相关系数(R2)均接近1,相较全波段和UVE模型,显著降低了预测误差,缩短了建模时间。图4中灰色区域即为所选用于预测的最优特征波段组合,可见所选特征波段大部分集中在波峰、波谷附近,说明波峰、波谷位置的吸光度比其他波段的差异更为显著,附近范围内的波段更适合用于掺伪含量定量分析模型的建立。
图5显示了试验建立的UVE-SiPLS-tsPSO芝麻油掺伪样本测试集预测结果与真实值的对比。由图5可知,此模型具有很高的预测准确度。
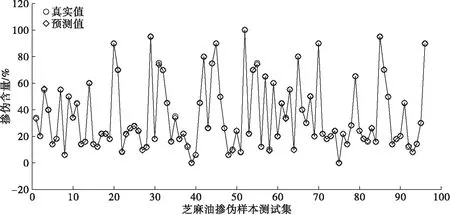
图5 芝麻油中大豆油掺伪含量预测结果
3 结 论
本文基于芝麻油中掺伪大豆油样本的近红外光谱,首先用SNV对光谱进行预处理,再采用无信息变量消除法(UVE)对掺伪芝麻油近红外光谱变量进行初步筛选,然后采用tsPSO选取SiPLS中的最优特征波段组合建立芝麻油中大豆油掺伪含量快速检测模型。所建模型通过特征波长变量的粗选与细选相结合的方式显著降低了芝麻油中大豆油掺伪含量预测误差,同时减少了建模变量和建模时间。此外,本研究为其他食用植物油的掺伪检测提供了一种可供借鉴的方法,在食用油掺伪研究领域体现出良好的可行性和参考价值。
