跨境电商系统用户数据库智能访问方法优化
2020-02-24刘彩霞
刘彩霞
(郑州工业应用技术学院信息工程学院,郑州 451150)
近年来,计算机科学逐渐发展,在社会需求的推动下,跨境电商在中国发展迅速,跨境电商为通过电子设备与网络进行的商业模式,在电子商务高速发展的今天,其涵盖范围非常广泛,是一种很好的发展方向[1-2]。现阶段,跨境电商系统中的用户量逐渐增多,跨境电商系统需从数据库中对数据进行提取,然后把读取的数据在网页中显示[3]。需研究一种有效的数据库智能访问方法,从海量跨境电商数据中获取有效信息特征,利用关键词查询与语义索引完成数据库智能访问优化,对增强数据库集成有重要价值[4-5]。
当前常用的数据库智能访问方法包括基于统计信息分析方法、基于信息流减法聚类的数据库访问方法和基于关键词的有向图模型建立的数据库访问方法[6]。基于统计信息分析方法通过信息子空间建模与数据关联属性采集,依据查询接口完成数据库优化访问,然而计算量大,在数据库访问中受关键词影响大,访问时查准性较差;基于信息流减法聚类的数据库访问方法通过聚类法完成对数据库中重要信息的聚类,依据语义调控目标函数实现数据库调度,增强访问性能,然而该方法在进行特征聚类时在很大程度上会陷入局部最优,造成数据库访问时收敛性能差。基于关键词的有向图模型建立的数据库访问方法,受到数据库知识存储单元耦合性的影响,数据库访问准确性低。
针对以上问题,通过语义关联指向性特征提取进行跨境电商系统用户数据库访问,为了解决其不适于大规模用户访问,结合多维索引树编码对其进行优化。
1 跨境电商系统用户数据库智能访问方法
1.1 跨境电商系统数据库模型
为了提高跨境电商系统用户数据库访问能力,对跨境电商数据库模型进行建立。跨境电商数据信息管理实体模型主要包括三个定量域[7],依次为客户端定量域V、V中控制定量域U,记模糊搜索集合为S(U),定量值u在定性概念S中随机实现时,u对S的信息分类聚类特度为稳定随机数,则u在定量域V中的分布称作模糊搜寻集合S(U)。不同模糊搜寻集合被称作有限数据集,以此建立跨境电商系统数据库模型[8]。
假设V是神经网络信任数据的拓扑定量域,S是V中的定性概念,在定量值u为定性概念的依次随机实现时,所有特征点u针对S的确定度ε(u)∈[0,1]均为稳定随机数。
按照随机线性映射完成数据格式转换,获取各跨境电商随机数序列分量,即
uk+1=4uk(1-uk)
(1)
式(1)中,k代表跨境电商数据库访问任务数量。
利用上述过程获取跨境电商数据库模型,为数据库智能访问提供模型依据。
1.2 数据库智能访问方法
1.2.1 语义指向性关联特征提取
依据模糊层次聚类提取语义指向性关联特征[9],在概念格中完成语义指向性相似度计算。假设跨境电商数据库语义指向性关联映射微分形式可描述为
(2)
(3)
式(3)中,a表示逻辑推理函数,在对语义指向性关联特征进行提取时,利用上下文本映射的方式完成约简[10],获取本体I和I′间的类间离散度泛函数关系式,即
a=F(a,t)
(4)
完成语义指向性关联特征提取,获取特征定位自变量:
t=[t1,t2,…,tn]
(5)
获取跨境电商系统数据库语义指向性关联特征,依据提取特征实现数据库智能访问。
1.2.2 数据库智能访问
完成语义关联指向性特征提取后,实现跨境电商系统用户数据库访问。假设访问过程中数据信息流用Q(t)进行描述,利用语义关联指向性特征对跨境电商系统中多源节点进行建立,在大规模数据存储空间中产生新映射[11]。在数据库中,数据存储节点空间轨迹矢量场用Q进行描述,通过特征值与特征向量匹配获取融合代价ci(t),假设数据库访问干扰项用bsi(t)进行描述,通过异步迭代法获取初始化访问融合中心离散度,则有:
Qi(t)=Q(t)ci(t)+bsi(t)
(6)
式(6)中,ci(t)用于描述规模为Q(t)数据库在跨境电商系统数据库语义本体加速分布融合函数,也就是数据库访问语义词频信息的响应函数[12]。为了增强访问准确性,需完成对冗余信息流的特征压缩,获取特征压缩控制函数:
Hi(t)=H(t)c′i(t)+bsi(t)
(7)
式(7)中,c′i(t)用于描述规模为H(t)数据库访问过程中多普勒频移估计[13],通过语义关联指向性特征遍历跨境电商系统存储节点,通过自相关解卷积法获取数据库访问模糊隶属函数:
l′i(t)=Hi(t)Qi(t)c′qi(t)ci(t)+bqi(t)
(8)
式(8)中:c′qi(t)用于描述逆向文档搜索传递函数;bqi(t)用于描述联合概率分布。通过上述过程产生语义相似度关系弧可描述为
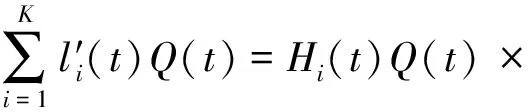
(9)
经处理,获取访问控制序列。将输入关联指向性特征聚集在一起,将其当成索引变量完成词频分类处理,访问数据的近邻点,输入查询关键词[14],执行输入的语义序列,获取的访问输出结果Z可描述为
Z=l(t)(keyword,g1)+l(t)(search,g2)
(10)
式(10)中:g1用于描述跨境电商系统数据库访问样本测试集;g2用于描述访问词频信息训练集。通过分析,可完成跨境电商系统用户数据库智能访问,但在用户规模较大的情况下,会影响访问准确性,针对该问题,采用多维索引树编码的方式对其进行优化[15]。
1.3 数据库智能访问方法优化
在上述数据库模型与语义指向性关联特征提取的基础上,对数据库智能访问方法进行优化。利用多普勒效应在跨境电商数据库节点竞争窗口值进行滑动评估,通过数据库模型分析数据结构,完成语义指向性检索。数据库节点多维索引树编码信息输入可描述为
(11)
完成对跨境电商系统数据库特征空间的全局效率寻优,在已知变量初始值的状态下,设计最小竞争滑动窗口特征向量,在系统节点中完成数据融合[16]。本节建立数据库索引控制特征函数,确定语义指向性信息流预测收敛需符合的条件为
J′[a(tk+1)]-J′[a(tk)]≤
(12)
式(12)中,Di()用于描述数据库索引控制特征函数。
在进行特征分区的过程中,利用数据库语义指向性特征匹配,完成数据库访问的信息采样。则通过自回归调控模型获取的数据库存储节点模型可描述为
(13)
式(13)中:hi(t)与pi(t)依次用于描述第i个节点访问数据库时的时域长度与控制长度;αi与γi用于描述缓冲区的数据调度速率;oi用于描述数据库访问响应速率;βi()用于描述第i个存储断开的调控函数;τ用于描述时延。
在上述分析的基础上,通过多维索引树编码获取用户访问数据库时关键数据回波相位误差E0的解析表达式:
(14)
式(14)中,μi与θi依次用于描述待查询关键数据的主动频谱与被动频谱。利用自适应匹配,获取关键数据的高阶累积量重构对角矩阵:
Φ4c=diag[φ4c1,φ4c2,…,φ4cn]
(15)
依据对角矩阵完成用户访问结果匹配,达到智能访问的目的,实现对跨境电商系统用户数据库智能访问方法的优化。
2 实验和结果分析
为了验证本文方法在实现跨境电商系统用户数据库访问中的性能,需要进行仿真实验分析。仿真实验环境是Windows 7与SQL Sever 2005,通过Java语言与SQL语言对数据库智能访问方法进行编写。针对跨境电商系统用户访问信息进行统计,完成数据库智能访问资源索引与调度。
2.1 特征提取性能测试
特征提取为跨境电商系统用户数据库智能访问的关键,本节采集数据的时域波形与时频,将文献[4]方法和文献[5]方法作为对比,对特征提取性能进行测试。
首先对跨境电商系统数据结构特征信息进行采样,采样时间长度是1 200,时间间隔是12 s,获取的数据库访问时间序列波形用图1进行描述。

图1 数据库访问时间序列波形Fig.1 The time seriesop database access
针对图1所示的数据测试集,采用本文方法、文献[4]方法和文献[5]方法对数据库访问语义指向性特征进行提取,获取特征提取结果用图2进行描述。

图2 三种方法对数据时域波形特征提取结果Fig.2 The extraction results of three methods in time domain
分析图2可以看出,通过本文方法对跨境电商系统数据语义指向性特征进行提取,能够完成数据语义本体特征指向性聚类,冗余干扰信息被滤除,特征分布聚类性较强,为数据库智能访问提供有效依据。而文献[4]方法和文献[5]方法提取结果指向性聚类效果不好,对数据库智能访问产生不好的影响,降低访问精度。
在同样的仿真环境下,获取跨境电商系统用户数据时频分布,用图3进行描述。
针对图3中的数据样本,对大数据语义关联特征进行提取,不同方法提取结果用图4进行描述。
由图4可以看出,采用本文方法进行特征提取,可获取样本数据中的有效数据,数据空间聚集性好。传统方法特征提取结果性能不佳,抗干扰能力不强,进一步验证了本文方法特征提取的有效性。

图3 跨境电商系统用户数据时频分布Fig.3 Time-frequency distribution of user data in cross border electricity supplier system
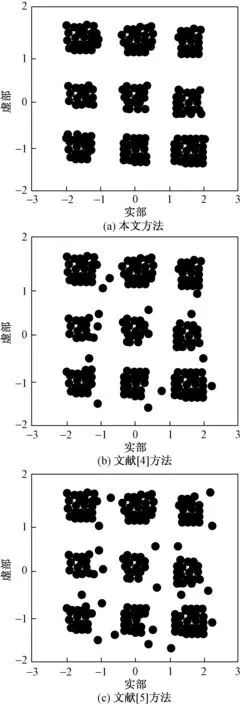
图4 三种方法对数据时频特征提取结果Fig.4 The results of three methods for extraction of time and frequency characteristics
2.2 访问性能测试
通过查全率与查准率对访问准确性进行测试,计算公式分别如下:
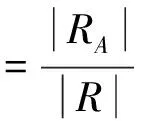
(16)
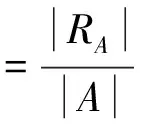
(17)
式中,|R|代表跨境电商数据数量;|RA|代表测试集中和初始访问相关的数据;|A|代表访问数据量。
在对跨境电商系统用户数据库进行智能访问时,通常把查全率和查准率当成两个矛盾指标,查准率会随查全率的升高而降低,即为了达到查全的目的,很可能会形成一些无用信息。而在查全率增加的情况下,查准率会相应降低。因此需针对不同查全率水平,对查准率进行测试。下面对不同查全率水平下查准率进行处理:
(18)
式(18)中,P(r)代表查全率是r情况下的平均查准率;Nq代表查询总量;Pi(r)代表查全率是r情况下第i次查询的查准率。
采用本文方法、文献[4]方法和文献[5]方法对跨境电商系统用户数据库进行智能访问,对查全率水平较高情况下的查准率进行比较,结果用表1进行描述。
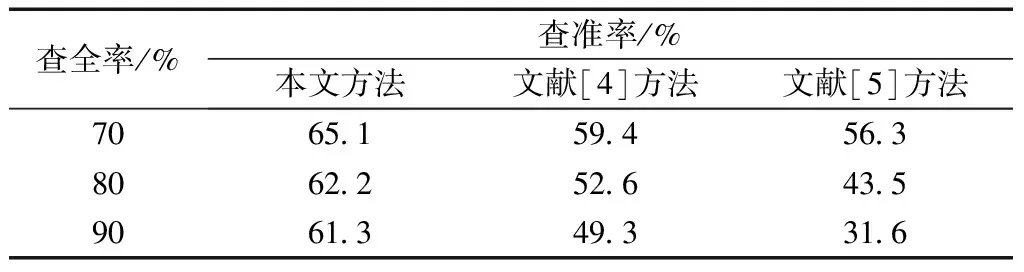
表1 不同查全率水平下三种方法查准率平均值比较结果Table 1 Comparison in average precision of different recall levelsby three methods
分析表1可以看出,在查全率相同的情况下,本文方法查准率明显高于其他两种方法,且在查全率升高时,本文方法可令查准率保持在较高的水平,未随查全率的升高有显著下降,说明本文方法访问准确性最高。
3 结论
提出跨境电商系统用户数据库智能访问方法,并对其进行优化。
(1)对跨境电商数据库模型进行建立,为数据库智能访问提供模型依据。
(2)依据模糊层次聚类提取语义指向性关联特征,在概念格中完成语义指向性相似度计算。
(3)依据提取特征,通过相似度计算匹配实现数据库智能访问。该在用户规模较大的情况下,会影响访问准确性,针对该问题,采用多维索引树编码的方式对其进行优化。利用多普勒效应在跨境电商数据库节点竞争窗口值进行滑动评估,通过数据库模型分析数据结构,完成语义指向性检索。依据对角矩阵完成用户访问结果匹配,达到智能访问的目的,实现对跨境电商系统用户数据库智能访问方法的优化。
(4)实验结果表明,所提方法访问准确性高。
