多层梯度提升树在药品鉴别中的应用*
2020-02-20杜师帅李灵巧胡锦泉郑安兵冯艳春胡昌勤杨辉华
杜师帅,邱 天,李灵巧,胡锦泉,郑安兵,冯艳春,胡昌勤,杨辉华,+
1.北京邮电大学 自动化学院,北京 100876
2.北京理工大学 光电学院,北京 100081
3.桂林电子科技大学 电子工程与自动化学院,广西 桂林 541004
4.中国食品药品检定研究院,北京 100050
1 引言
假药或劣质药品大约占据世界药品贸易10%的份额,在全球范围内摧残人民群众的身体健康,同时扰乱市场经济秩序,是世界各国共同面临的挑战。2006年,世界卫生组织在罗马召开“打击假药建立有效的国际合作”国际研讨会议,促进国际合作打击假劣药制售。我国建设的药品快速识别系统,针对不同企业生产的药品中的活性成分进行定性分析或定量鉴别,以确保药品在市场流通过程中的质量。因此,为了建立更加完善的药品监督系统及维护市场稳定,发展创造性的和有效的药品鉴别方法具有重大意义。
近红外(near-infrared,NIR)光谱分析技术能够对样品进行快速、无损及无污染检测,实现对待测样本的定性或定量分析,且可以通过光纤实现远程测量,这些优势使其在石油分析[1]、食品检测[2]、药品监督[3]等领域有广阔的应用前景。直到现在,基于NIR分析技术的药品鉴别算法仍得到广泛的研究。Scafi等[4]提出NIR光谱能够有效区分相似药物,并通过构建多变量模型验证了NIR在快速、现场和无损鉴别假药方面的潜力。文献[5]采用NIR相关系数法,通过药品检测车对药品在流通领域中的变化进行跟踪,并快速筛查药品的真伪。Feng等[6]建立一种NIR光谱检测算法,可快速鉴别非法掺入合成药物的草药。但由于NIR光谱具有谱带宽、重叠严重及信息解析困难等缺点,传统的药品鉴别技术有着一定的局限性。随着信息时代的来临,基于机器学习的NIR光谱分析技术被提出,能够有效解决NIR光谱的缺陷,并在药品分析领域有突破性的进展。Deconinck等[7]运用决策树在Viagra和Cialis药品数据集上建立分类模型,在二义性数据上表现良好。Xin等[8]利用偏最小二乘和随机森林构建分类器模型,改进决策树在多分类问题上的不足。文献[9]针对药品二类别不平衡问题,提出平衡级联稀疏的分类方法。但随着产业界数据的复杂多样化,机器学习算法的特征学习遇到瓶颈,使得这类药品鉴别算法对多类、高维且非线性的近红外数据有较差的适应性。
近年来,信息科学与技术的爆炸式发展导致人工智能逐渐成熟,而深度神经网络(deep neural network,DNN)是其最成功的产物[10-11]。无论在监督学习还是在无监督学习环境下,DNN都有优秀的特征表示学习能力,并在计算机视觉、自然语言处理等领域[12-13]表现出极佳的性能。目前,NIR光谱分析技术与DNN紧密结合,在药品鉴别任务中也取得一定的成果。文献[14]采用主成分分析和反向传播(back propagation,BP)神经网络结合的方法,有效提高多类别药物的分类准确率。Yang等[15]将dropout技术引入深度信念网络,克服药品精细分类领域中小样本带来的过拟合问题。文献[16]提出一种基于堆栈压缩自编码的NIR药品鉴别方法,将高维光谱数据进行特征映射,以低维特征进行定性分析并大幅度提升分类效果。然而,神经网络模型的训练,主要采用BP算法迭代更新网络参数及最小化目标函数。因此对于难以获取大量样本的小规模药品光谱数据,DNN的BP复杂性导致模型容易陷入局部最优解,在一定程度上限制了其强大的特征学习能力。
BP算法的弊端使得很多领域遇到瓶颈,甚至Hinton曾提出“抛弃反向传播,重起炉灶”。因此,探索神经网络以外的方法具有重要的研究价值和开拓意义[17-18]。Feng等[19]提出的多层梯度提升决策树(multi-layered gradient Boosting decision trees,MGBDT)算法,通过构建“深层”的非可微梯度提升决策树(gradient Boosting decision trees,GBDT)模块,以目标传播的变体联合优化训练过程,探索其特征表示能力。目前尚未检索到MGBDT在NIR分析领域的应用,本文尝试将MGBDT算法应用于NIR药品鉴别的实例分析,同时引入自适应特征选择和代价敏感学习以解决MGBDT模型内存需求过大、样本不均衡及特征冗余问题,并分别在胶囊和药片两种药剂数据集上进行验证。
2 基于特征选择和代价敏感学习的多层梯度提升树
2.1 自适应特征选择
特征选择一直是模式识别领域的研究热点。该领域的高维复杂性数据往往包含大量的冗余特征或噪声信息,特征选择的作用就是从原始特征集中选择能够最大化有效的数据信息及最优化模型性能的特征子集。相关算法主要分为Filter[20]、Wrapper[21]和Embedded[22]三大类。其中,基于Embedded的特征选择方法与模型本身紧密结合,在模型训练过程中优先选择对性能增益最大的特征,也是目前主流的特征提取思想。随机森林[23]具有准确率高、速度快、鲁棒性好等优点,能够应用于特征选择问题,可作为一种高效的Embedded特征选择方法[24]。
然而,针对不同任务,要耗费大量人工成本对特征选择过程进行不同的研究和调整。为解决以上问题,在特征选择的基础上引入自动调节比例因子λ,根据具体任务或数据自适应选择最优特征,该方法目前广泛应用于各领域[25-26]。
本文将λ引入基于随机森林的特征选择,旨在高效且自适应地选取最优分类特征。具体来说,随机森林首先计算原始数据每个特征的重要性并进行排序,再根据某种规则选择最小且最有效的特征子集。假设原始训练集为D,Bootstrap取样后的训练子集为B,决策树为T,决策树个数为N,则特征X的重要程度计算及自适应特征选择的流程如下:
(1)从D中Bootstrap采样N个子数据集Bi(i=1,2,…,N) 且分别对应N个袋外数据OOBi(out of bag)。用子集Bi训练决策树模型Ti,之后测试数据OOBi,计算袋外误差errOOBi1,并记录所有决策树的袋外误差之和errOOB1。

(2)对袋外数据OOBi所有样本的特征X随机加入噪声干扰ε再次测试Ti模型,计算袋外误差errOOBi2

(3)如果X加入随机噪声ε后,袋外数据准确率大幅度下降,即errOOBi2远大于errOOBi1,说明X对于样本的分类有很大影响,即重要度较高。则计算特征X的重要程度如下:
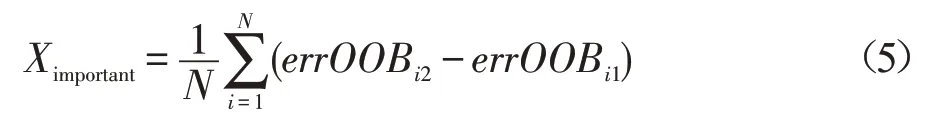
(4)将特征按照其重要度进行降序排序,并根据自适应比例因子λ,提取新的特征集。
(5)用新的特征集重复(1)~(4)步骤,直至特征数小于设置的最低特征维度停止。
(6)根据上述步骤得到各个特征子集及对应的袋外误差errOOB1,选取最低误差的特征子集作为自适应特征选择的最终特征集。
2.2 自适应特征的多层梯度提升决策树
强大的特征学习能力是DNN成功的关键[27],例如自编码系列网络[28-30]在监督或无监督学习中具有极佳的性能,广泛应用于图像识别、语音识别等领域。Feng等[19]提出多层梯度提升决策树算法,由多层非可微GBDT模块构成,汲取DNN的特征分层表示能力和梯度提升树的集成能力两大优势,将原始数据映射至表征能力更强的特征空间。同时,基础构建块的非可微性,一定程度上避免了BP的弊端。
然而MGBDT也存在缺陷。经实验研究发现,该模型第一层构建块将原始数据进行前向映射,其输出往往存在较多冗余特征,进而影响深层模型的特征学习。另外,每层构建块由与该层特征维度有相同数量的GBDT组成,高维数据的输入会增加该模型的GBDT数量,从而消耗大量内存及运行时间。针对高维度的药品近红外光谱数据,本文提出一种基于特征选择的多层梯度提升决策树(multi-layered gradient Boosting decision trees based on feature selection,FGBDT),即用自适应特征选择模块替换MGBDT第一层的GBDT模块,旨在减少原始数据的冗余特征,同时降低MGBDT的空间复杂度对高维数据的敏感性,增强分层分布式表征能力。

Fig.1 Illustration of FGBDT structure图1 FGBDT结构示意图
FGBDT具有一个原始特征输入层、M个中间层以及一个最终输出层,如图1所示。其中,oi,i∈{0,1,…,M} 分别作为输入层和中间层的前向输出,zj,j∈{1,2,…,M}分别是中间层的逆向伪标签。中间层的第一层是特征选择器,对原始数据特征按重要程度排序,在最小化特征信息损失的基础上,选择有益特征,提升深层模型的特征表示学习能力。之后的M-1个中间层来自MGBDT结构,每层结构包含两个GBDT模块:F和G构建块。F用于特征的前向映射,G用于特征的逆向映射。学习任务是指学习每层的映射模块,使得最终输出在训练集上最小化经验损失。
具体来说,算法流程分为三个阶段。首先,初始化阶段。产生一些高斯噪声作为中间层的输出,并训练一些非常小的树结构以获得,其中索引0表示在该初始化阶段中获得的树结构,从而训练过程可以继续进行迭代更新前向映射和逆向映射。其次,Gi,i∈{2,3,…,M}更新阶段。在迭代t过程,假设给出前一次迭代的前向映射,获取与对应的“伪逆”映射,使得式(6)成立:

其中,oi-1是第i-1层Fi-1的输出;是第t-1次迭代过程的第i层的前向映射构建块;是第t次迭代过程的第i层的逆向映射构建块。可通过最小化重建损失函数的期望值来实现,如式(7):
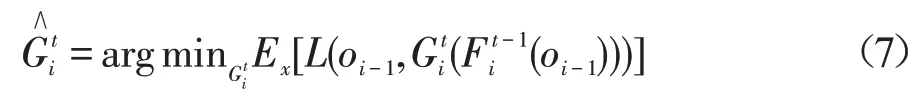
其中,L是重建损失函数;Ex是L的期望。从而更新,进一步更新前一层。最后,Fi,i∈{2,3,…,M}更新阶段。在迭代t过程,关键在于为分配伪标签,且每层的伪标签被定义如式(8):


那么,只要设置好第M层的伪标签,就可以使整个结构进行更新。这里使用真实标签y定义M层的伪标签,如式(10):

其中,α是残差梯度系数;y是真实标签。用计算该层伪标签,如式(11):

一般的分类任务,将最终输出层设置为线性分类器。主要有两个原因:首先,浅层将被迫学习一个尽可能线性可分的特征重新表示,这是一个有用的属性。其次,输出层和前层之间的维度的差异通常很大,因此可能难以学习准确的逆映射。当使用线性分类器作为顶层的前向映射时,不需要计算该特定的对应逆映射,因为可以通过关于最后一个隐藏层的输出的全局损失的梯度来计算下面层的伪标签。本文最终输出层用的是Softmax层,如式(12)。

其中,C是类别个数;xi是第i个Softmax神经元的输入;y(xi)是第i类别的预测概率。
2.3 代价敏感
现实任务的数据大多都存在样本不均衡的缺陷,往往是样本的类别不平衡或样本的难分易分问题。在类别失衡的分类任务中,少数类样本对分类器的影响较小,容易降低其泛化能力,尤其少数类样本可能更为重要。另外,不同样本可能有不同的区分难度,而简单样本与困难样本在训练中所占的权重相同,会导致较难学习样本很难被挖掘分析。药品鉴别是典型的类别不均衡问题,相比于真药,假劣药的样本往往较少且较难学习,但其被误判的损失会更加严重,故针对样本不均衡问题进行研究很有必要。
样本不均衡问题的研究日益成熟[31-33],其中代价敏感学习[34]表现最为突出。目前Lin等[35]提出一种新的损失函数Focal Loss,解决了目标检测中正负样本的不平衡问题及样本的难训练问题。本文将Focal Loss引入NIR光谱的药品鉴别任务,并结合FGBDT算法,旨在抑制药品样本不均衡的学习敏感性。
Focal Loss是基于交叉熵函数的一种损失函数,故本文首先以二分类为例,介绍说明交叉熵损失函数(cross entropy loss),如式(13)所示:

其中,y是类别的真实标签;y'是类别的预测概率。交叉熵损失函数根据正负样本相应的概率输出,以调整损失值大小,即预测输出越接近真实值,损失越小;反之越大。然而,该函数收敛缓慢,优化困难。更重要的是,它无法解决正负样本的平衡问题及简单与困难样本的区分问题。
而Focal Loss是在交叉熵损失函数基础上进行的修改,期望少数样本及困难样本对损失的贡献变大,使模型更倾向于从这些样本上学习,如式(14):

其中,α对类别不均衡问题的损失函数进行控制,以平衡正负样本本身的比例不均。γ对易分/难分样本问题的损失函数进行调节,以调整简单样本权重降低或困难样本权重增加的速率。
对于多类样本的情况,原理相同。如果某一类或某几类样本较多,模型肯定也会偏向于数目多或者易训练的样本类别,进而影响模型的泛化能力,在药品鉴别领域是很常见且很重要的问题。基于FGBDT算法引入Focal Loss,利用平衡因子α和γ对类别不平衡及易分难分的样本进行控制,使样本在训练集所占的学习权重达到一定程度的平衡,相应损失函数可以快速收敛。
3 实验结果分析
3.1 数据
该数据由中国食品药品检定研究院提供,且所有样品均通过了法定方法检验。本文选取胶囊、药片两种类型药剂的NIR数据为实验数据,尝试用新算法对主成分相同且仅辅料或生产工艺有差异的药品NIR光谱进行区分。
实验数据A,是哈药集团三精制药诺捷有限责任公司及其他制药公司生产的铝塑包装罗红霉素胶囊,总计337个样本;实验数据B,是北京中惠药业、上海信谊药厂、深圳市中联制药等10家药厂生产的非铝塑包装盐酸二甲双胍片,共计691个样本,如表1所示。

Table 1 Profile of experimental data A and B表1 实验数据A和B简介

Fig.2 NIR spectrum curves of dataset A and B图2 数据集A和B的近红外光谱曲线

Fig.3 NIR spectrum curves of dataset A and B after preprocessing图3 预处理后数据集A和B的近红外光谱曲线
使用Bruker Matrix光谱仪测定每个样本在不同NIR波长下的吸光度值得到相应光谱曲线,如图2所示。NIR光谱曲线的横坐标表示波数(波数=1/波长),范围约为11 995~4 000 cm-1,间隔4 cm-1,共2 074个波数;纵坐标表示不同波数对应的吸光度值,共2 074个吸光点。因此,每个样本的NIR光谱数据是不同波数下的一组吸光度值,具有一维的数据表示形式,包含2 074个特征。
3.2 数据预处理
为消除原始数据的噪声干扰,且维持光谱的形状、宽度不变,对数据A和B均采用Savitsky-Golay平滑求导方法进行预处理,其窗口大小取9,多项式阶数取2,求导次数取1。
预处理后的光谱数据具有一维表示形式,包含2 074维特征,对应的NIR光谱曲线如图3所示。
3.3 评价指标
本文应用的度量方法有分类准确率(Accuracy,Acc)、准确率标准差(standard deviation of accuracy,Std)、F1值及算法运行时间(Time)。以二分类为例,设定TP、FN、TN、FP分别表示分类正确的正类、分类错误的正类、分类正确的负类、分类错误的负类。
分类准确率是模型正确分类的样本数与总样本数之比,最能直观反映分类模型性能的好坏,定义如下:

分类准确率标准差是多次准确率与其平均值偏差的算术平均数的平方根,用来衡量模型预测的稳定性。其计算公式如下:

其中,N表示交叉验证的折数;ai是第i折交叉验证的分类准确率是N折交叉验证的准确率均值。
但分类准确率不能很好地反映各类的具体分类情况,尤其是处理类别不均衡问题,该指标并不能充分验证算法的有效性。因此,为了更好地评估分类性能,增加F1值作为评价指标。F1值是以每个类别为基础进行定义的,包括精确率(Precision)和召回率(Recall)。精确率是指正确预测为正类样本占全部预测为正类样本的比例;召回率是指正确预测为正类样本占全部实际为正类样本的比例。而F1值为两者的调和平均数。相关定义如下:
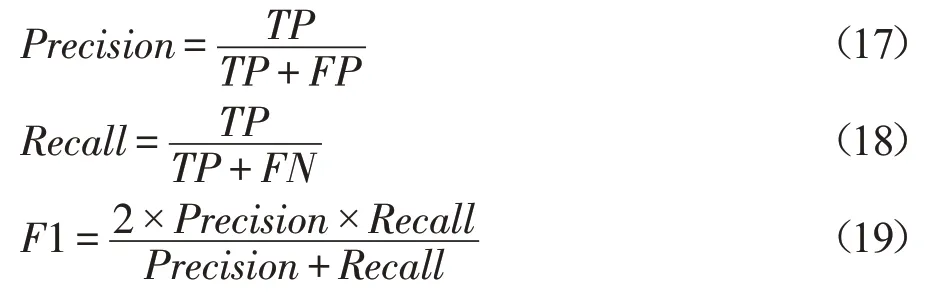
为验证改进MGBDT的特征重表示能力以及代价敏感学习的有效性,除以上评价指标之外,本文引入特征表示图及训练、测试状态图进行分析。
3.4 实验过程及配置
本实验基于Linux操作系统、i7-6700 CPU和32 GB安装内存等环境,使用Python编程语言及PyCharm软件开发平台进行设计与实现。针对药品精细分类任务,对近红外光谱数据进行预处理,并实现模型的训练、测试及对比研究。具体过程如下:
(1)预处理阶段
为了消除噪声干扰且保护光谱数据形状、宽度不变,利用Savitsky-Golay平滑求导算法对两个样本集进行预处理,详细信息见3.2节。
(2)训练阶段
将预处理后的光谱数据,送入到各模型中训练。其中,支持向量机(support vector machines,SVM)选择线性核函数。极限梯度提升树(extreme gradient Boosting trees,XGBoost)包含100个树分类器。多层感知机(multi-layer perceptron,MLP)有两层隐藏层,分别包含1 024、256个神经元,激活函数为ReLU,权重优化器为Adam,损失函数为Cross Entropy。堆栈自编码(stacked auto encoder,SAE)包含预训练和微调阶段。预训练阶段,分别训练具有input-1 024、1 024-256、256-output网络结构的3个编码器,优化器为Adam,损失函数为均方误差(mean square error,MSE);微调阶段,训练具有input-1 024-256-output网络结构的预训练模型,优化器为Adam,损失函数为Cross Entropy。FGBDT结构input-f-f/2-output(f表示模型自适应的特征维度,自适应比例因子为0.6,最低特征维数为256),优化器为Adam,损失函数为Cross Entropy,目标学习率为0.1。CS_FGBDT相比于FGBDT,损失函数为Focal Loss,经实验证明平衡因子α取0.21,γ取0.2为最佳,其余配置不变。
(3)测试阶段
用训练好的模型对测试样本进行测试。模型的最后一层分类器计算出测试样本属于每个类别的“概率”,概率最大的类别即为样本的预测类别。将所有测试样本的预测值与真实值进行对比,计算测试准确率、标准差及F1值等评价指标。
(4)对比阶段
经初步分析,MGBDT算法在本文实验环境(CPU,32 GB)下易内存溢出且时间复杂度过高,并不适于实际应用下的高维NIR光谱药品鉴别,因此该算法的实验意义不大,不用于模型对比。
本文选用经典商业软件算法(SVM)、梯度提升树算法(XGBoost)、神经网络算法(MLP、SAE)作为对比方法,旨在以实际应用和学术理论等角度综合评估FGBDT、CS_FGBDT的性能。为验证各算法在不同大小训练集上的分类能力,以2∶8、3∶7、4∶6、5∶5、6∶4、7∶3、8∶2等7种不同比例选取训练集/测试集,并在每个比例数据集下进行十折交叉验证。同时,将分类准确率及F1值作为模型分类指标;将准确率标准差作为模型稳定性指标;将运行时间作为模型速度指标。
3.5 实验细节分析
本节对SVM、XGBoost、MLP、SAE、FGBDT等对比算法的实验细节进行分析说明。
对于高维小样本数据,尤其特征维数远远大于样本维数,SVM一般选取线性核函数。研究表明,多项式核、径向基核等SVM的药品分类性能确实劣于线性核SVM。
MLP、SAE的网络结构为input-1 024-256-output,该配置主要参考文献[16]。针对小规模NIR数据,若加深神经网络结构,不仅会增加模型的时间复杂度,还易导致模型过拟合。另外,在具有不同规模训练集的实验中,可适当调节输入数据的批量大小(一般小比例训练集取32,大比例训练集取128),有效地提升不同阶段模型的拟合能力、稳定性和速度。
XGBoost是梯度提升树算法,而FGBDT是基于多层梯度提升树的分类方法,前者是后者构建块(block)的组成部分。两者进行对比,以突出多层非可微梯度提升树对特征分层表示的有效性。经广泛实验验证,本实验FGBDT的最优模型结构设计为input-f-f/2-output(f为自适应的特征维数),而过于深层的模型会导致特征信息丢失或过拟合,且时间代价较大。表2给出实验数据B的训练和测试集为3∶2时,不同FGBDT模型结构间的性能对比。

Table 2 Performance comparison of different FGBDT model structures表2 不同FGBDT模型结构的性能对比
3.6 实验结果
3.6.1 特征重表示
多层梯度提升树算法的主体结构由深层非可微模块组成,避免了BP算法的缺陷,同时具有特征分布式学习的可探索性。针对药品数据的高维复杂特性,本文将自适应特征选择与多层梯度提升树方法结合,以消除内存占用率过大及噪声信息的影响,并在数据集A和B上分别对FGBDT的特征学习能力进行验证,如图4(a)、图4(b)所示。左图是原始数据的空间分布图,可以看出部分不同类别的样本之间的类间距离较小,而类内距离较大。用FGBDT算法对原始数据进行特征重表示,映射到新的特征空间,极大增加了类间距离并降低了类内距离,如右图所示。由此,可初步推论,FGBDT算法具备优秀的特征学习能力及特征重表示能力,对后续非线性分类器的性能有较大的增益效果。
3.6.2 模型预测能力

Fig.4 Feature visualization of experimental data图4 实验数据的特征可视化
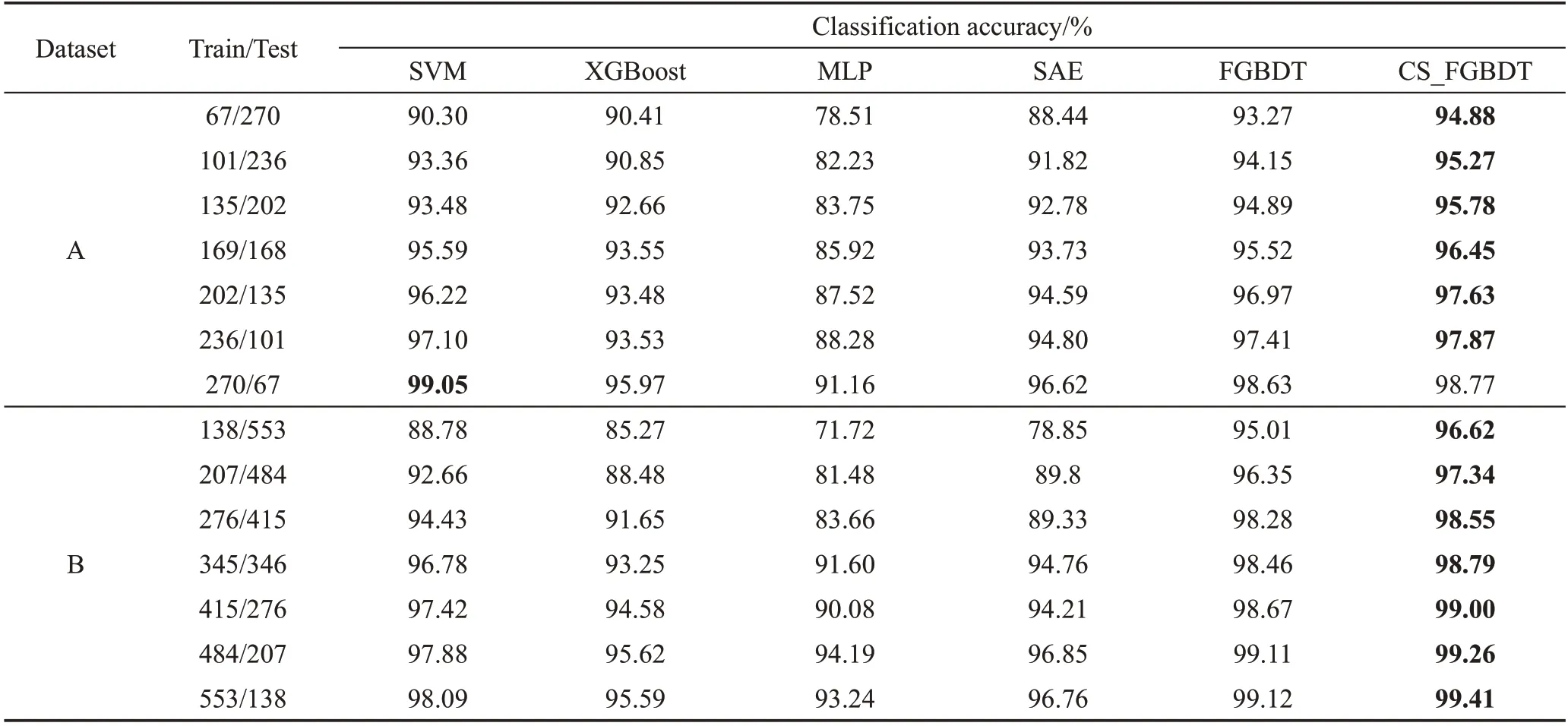
Table 3 Classification accuracy of each algorithm on dataset A and B表3 各算法在数据集A和B上的分类准确率

Fig.5 F1-score of each algorithm on dataset A and B图5 各算法在数据集A和B上的F1值
在分类准确率方面,如表3所示。MLP算法总体表现一般,尤其数据量较小时,其分类准确率明显较低,说明模型没有学到有效信息或者陷入局部最优。而SAE算法解决了神经网络的参数初始化问题,使模型加速收敛,且避开局部最优解,故其类性能优于MLP,同时表明特征分层表示有益于分类。XGBoost算法的准确率与SAE的相似,可知梯度提升树算法对NIR光谱数据有一定的分析能力,但性能劣于SVM。随着训练集增大,SVM的模型优势愈加明显,特别是在二分类实验下,其预测精度达到最高。相比其他模型,FGBDT结合特征分层表示和决策树集成思想,能有效学习数据特征,在各个规模数据下表现十分优越,尤其在小数据量上具有明显的分类优势。在此基础上,FGBDT结合代价敏感学习机制,以提升其分类性能,使得CS_FGBDT的预测精度更优。
在F1值方面,如图5所示。随着训练数据集的增加,各模型的F1值也逐渐增大,说明大数据量有利于提升模型的综合分类性能。在各个比例的训练集/测试集下,FGBDT的F1值达到最优,表明该算法在各类别数据上的分类性能表现优越。而CS_FGBDT的代价敏感学习进一步降低不均衡数据对各类别预测能力的不利影响,相比FGBDT,其F1值得到提升。
综合考虑模型的分类准确率和F1值,FGBDT和CS_FGBDT在各个规模训练集下具有最佳的预测能力。
3.6.3 算法稳定性

Fig.6 Standard deviation of accuracy of each algorithm on dataset A and B图6 各算法在数据集A和B上的精度标准差
在算法稳定性方面,如图6所示。MLP的总体鲁棒性较差,但随着数据量增大,该模型逐渐稳定,说明小数据量不适用于神经网络方法。由于逐层贪婪学习的SAE有预训练阶段,其稳定性能明显优于MLP,但不如XGBoost算法,表明梯度提升决策树算法更适合NIR数据的稳定分析。相比之下,SVM算法在二分类实验中表现十分稳定,但在多分类实验中稍逊于FGBDT。而CS_FGBDT在各个比例训练集下表现出更加优越的鲁棒性,可以推断多层梯度提升树模型在多类复杂性的数据下适应性良好。
3.6.4 时间复杂度
模型的时间复杂度(此实验仅在CPU环境下)如表4所示。SVM的运行速度具有最为明显的优势,可快速地处理二分类或多分类问题。MLP的训练时间高于SVM,但稍低于XGBoost,主要因为XGBoost是多决策树集成的串行结构,相对耗时。SAE包含预训练阶段,导致其时间复杂度最高。FGBDT是多层的梯度提升决策树,每层构建块由XGBoost构成,因此训练速度低于XGBoost,但高于结构较为复杂的SAE。而CS_FGBDT与FGBDT的模型结构一致且配置类似,因此两者时间复杂度相似。
由以上分析可知,FGBDT的训练速度仅高于SAE,但远低于SVM等算法,表明其时间复杂度相对较高。在模型具备优秀的分类性能和稳定性的前提下,提升运行速度对实际应用有重大意义,是未来的探索点。在算法结构层面,可考虑FGBDT构建块的多线程设计;在硬件层面,由于该模型由决策树和线性分类器构成,可使用GPU进行加速。

Fig.7 Learning curves of FGBDT and CS_FGBDT图7 FGBDT与CS_FGBDT的学习曲线
3.6.5 代价敏感学习的影响
上文提出的FGBDT算法在分类准确率及模型稳定性方面,相比其他算法有更优越的性能,是一种有效的药品鉴别方法。但药品NIR数据存在样本不均衡问题,故本文在FGBDT算法的基础上引入代价敏感学习,期望缓解样本不平衡对收敛速度及模型不稳定等问题造成的影响,以提高模型分类效果。下面以评价指标、训练及测试状态来分析FGBDT与CS_FGBDT的性能。
评价指标方面,如表3、图5及图6所示。CS_FGBDT的性能稍优于FGBDT,特别是在样本不均衡问题相对突出的小数据上,其分类准确率、模型稳定性及F1值都有较大提升。这表明代价敏感学习对FGBDT模型的性能有一定的提升作用,且适用于样本不平衡的药品数据。
训练及测试状态方面,如图7(a)、图7(b)所示。相比FGBDT模型,CS_FGBDT的初始准确率较高,随着迭代次数逐步增加直至稳定。同时,CS_FGBDT损失收敛更快且更低。进一步说明该模型有更优秀的鲁棒性,且更快地达到全局最优点。
4 结束语
针对主流算法在鉴别药品数据时存在的缺陷以及多层梯度提升树算法的不足,提出一种新的药品鉴别算法CS_FGBDT,用于处理样本类别多、不均衡且高维非线性的药品数据。所提出的模型在MGBDT基础上引入特征选择器,并替换第一层GBDT模块,以降低原始数据的冗余特征及噪声信息,同时保证模型的内存低消耗;并引入代价敏感学习,将Focal Loss用于最终输出层,提升模型性能。将改进的算法在样本不均衡的罗红霉素胶囊、盐酸二甲双胍药片数据集上进行分类鉴别。实验结果证明,与SVM、MLP、SAE、XGBoost等相比,其模型的分类精度及稳定性表现优越,且适用于不同规模数据。另外,引入代价敏感学习机制的CS_FGBDT在处理样本不均衡问题的能力更优于FGBDT,且模型学习状态更加稳定。综合而言,该方法对于相似度较高、重叠严重、信息解析困难的药品NIR光谱有更好的辨识能力,即使处理小规模数据的能力也十分突出。但是,如何有效地优化模型速度及自适应模型复杂度是今后研究的重点。
