应用于小样本的差异字典人脸识别
2020-02-08邓佳璐贾玉洁
邓佳璐,贾玉洁,卫 祥,杨 波,阎 石+
(1.兰州大学 信息科学与工程学院,甘肃 兰州 730000;2.国网甘肃省电力公司 信息通信公司,甘肃 兰州 730000)
0 引 言
在实际应用中,人脸识别用于训练的样本数量通常有限[1]。一是由于训练样本存储空间的有限性所致,二是因为在较短的时间内难以取得大量的训练样本。测试人脸具有难以预测的光照、面部表情和姿势变换,使得人脸识别的准确度仍需提高。因此,为了应对这些挑战,许多研究人员将注意力集中在小样本问题上,并且设计了许多相应的方法。其中大多数研究者使用生成虚拟样本的方法以解决样本不足的问题。如Hao Zhang等使用正脸和非正脸的角度变化来生成虚拟训练样本[2],Yong Xu等提出的生成镜像脸以扩充训练样本的算法[3],和Ningbo Zhu等提出的对测试样本生成虚拟样本的方法[4],这些方法虽然增加了样本数量,但由于虚拟样本生成方法的单一性问题,使其只能解决光照变换或姿态变换其中的一种问题,而不适用于同时具有光照、姿态变化的小样本问题。于是Pengfei Zhu等提出了基于分块思想的局部通用表示的单样本识别方法(local generic representation,LGR)[5]用来解决同时具有光照、姿态变换的小样本问题。但LGR的通用字典都具有局限性,其训练样本只有为基准样本时才有较好的结果。基于以上讨论,本文提出了一种应用于小样本情况,使用基于表示分类的差异字典克服姿态、表情、光照变换的情况,并应用灰度对称脸使训练样本中的非基准脸转换近似基准脸的人脸识别方法。
1 基于表示分类的差异字典
1.1 基于表示的分类
在人脸识别分类方法中,基于表示的分类(RBC)方法由于其简单性和较高的识别精度而受到了广泛的关注。传统的RBC方法也被称为稀疏表示分类(sparse representation classification,SRC)方法[6]。包括SRC在内的基本所有的RBC方法都假设测试样本可由所有训练样本的线性组合来表示。SRC利用1范数极小化约束求出它的解。换句话说,SRC是在稀疏条件下求解的,该约束即假定线性组合的多个稀疏系数等于或接近于零。因此,我们还可以认为SRC使用了所有训练样本的稀疏线性组合来表示测试样本。除了SRC,RBC方法中还有利用2范数最小化约束来实现分类的方法[7],该方法称为协同表示分类(collaborative representation classification,CRC)。用2范数最小化约束的CRC算法比SRC更简单、更易于实现、效率更高。
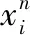
z=XB+e
(1)
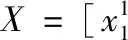
B=(XTX+λI)-1×XTz
(2)
其中,λ为标量,I为单位矩阵。根据求解出来的B与式(3)计算每类的残差并确认最终分类结果
(3)
其中,ei为第i类的残差,k为测试样本所属类别。残差越小则越接近正确的分类,当残差最小时所归属的类别为测试样本所属类别。
1.2 差异字典
在小样本情况下,测试样本与训练样本会具有姿态、表情和光照等变化。训练样本的有限使得基于表示的分类方法会产生较大的误差。即训练样本集的线性组合无法近似地表示测试样本,残差变大,识别率降低。所以提前用训练样本无关类的基准样本(即无表情、光照适中、无姿态变化的正脸)与该类具有表情、姿态和光照变换的差异样本,构成差异字典。然后使用训练样本与差异字典的线性组合,降低或抵消测试样本的姿态表情变化,使测试样本更加易于被训练样本线性表示。换句话说,用差异字典填补训练样本,使训练样本具有与测试样本相同的姿态表情变化,可增加分类的正确率。
现在,将差异字典代入基于表示的分类方法中,假设选取G个无关类,每类具有M个具有光照或姿态变换的差异样本和1个该类的基准样本,使其构成差异字典,即
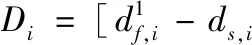
(4)
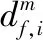
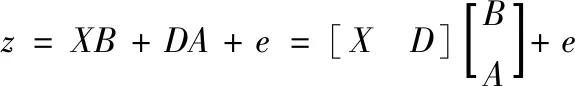
(5)
其中,B为系数,A为差异字典系数,e为残差。可通过以下式(6)求解式(5)中的B和A
[BA]=([XD]T[XD]+λI)-1×[XD]Tz
(6)
利用求解出来的B和A与式(7)可得到每类的残差
(7)
如图1所示的ORL人脸库中的第1类的第1个样本作为样本集(图1中第1行第1幅图为样本集),第1类的第10个样本作为测试样本(图1中第1行第2幅图为测试样本),将其代入到基于表示的分类方法中。如图2所示式(1)中的残差e向量重构为残差矩阵的图像,即测试样本减去训练样本集线性组合后重构图像的残差。并用图1所示的GT库的第1类的第1个样本为基准样本(图1中第2行第1幅图为基准样本),第1类的第2、3、4、5、6、8个样本为差异样本(图1中第2行除第一幅图外的图为差异样本)。根据式(4)构成差异字典,将差异字典加入到基于表示的分类方法中得到其残差矩阵,即式(5)中的残差e向量重构为残差矩阵的图像,如图3所示,即测试样本减去训练样本集与差异字典线性组合后重构图像的残差。对比图2与图3,可以看出图3中的残差要比图2小,图3中部区域的有很多残差数值趋近于0,而图2中部区域的残差数值仍然较大。由此可以得出基于表示的分类方法加入差异字典后的分类效果要比不加的效果要好很多。

图1 ORL库中部分样本与GT库中部分样本
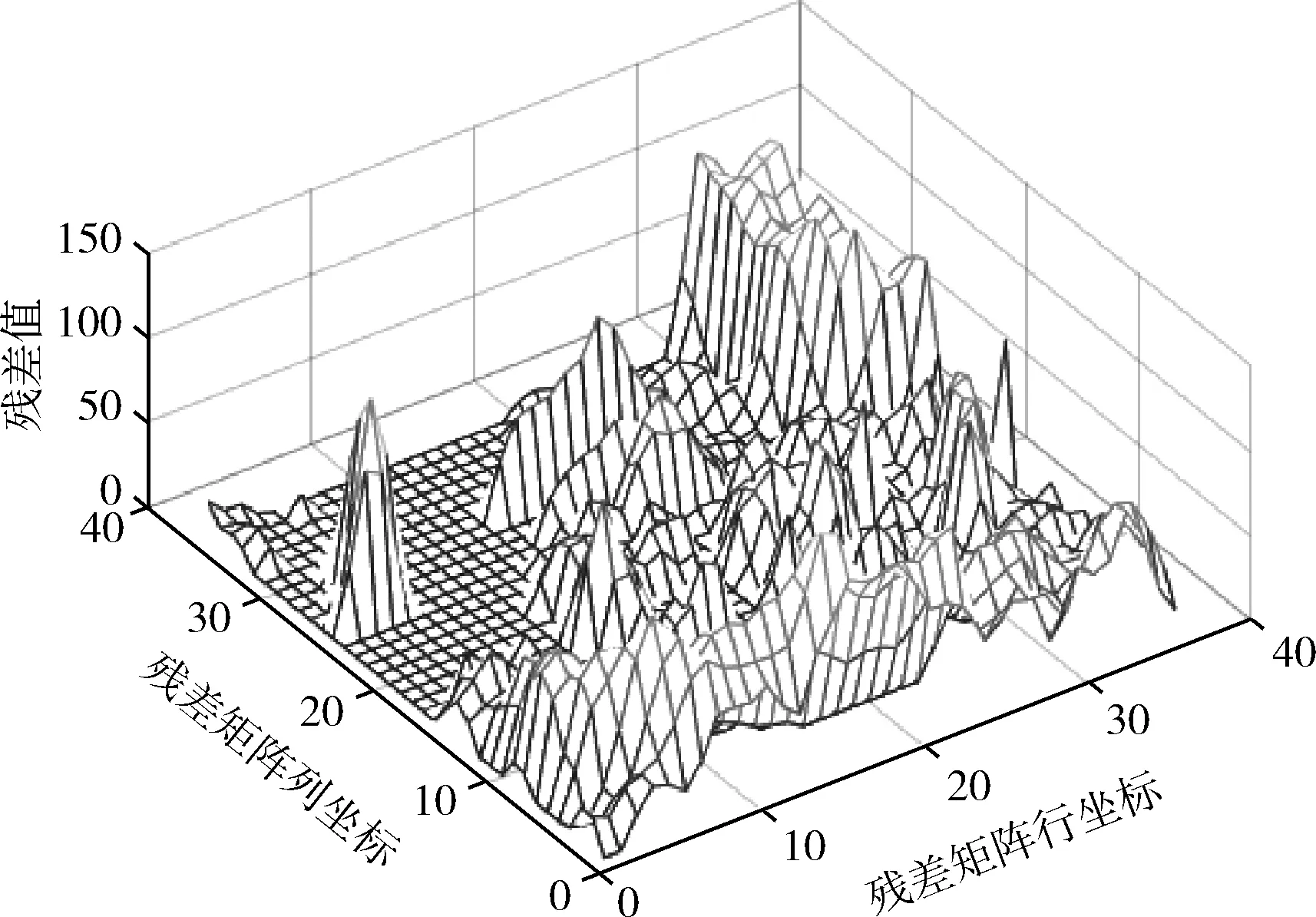
图2 RBC残差矩阵
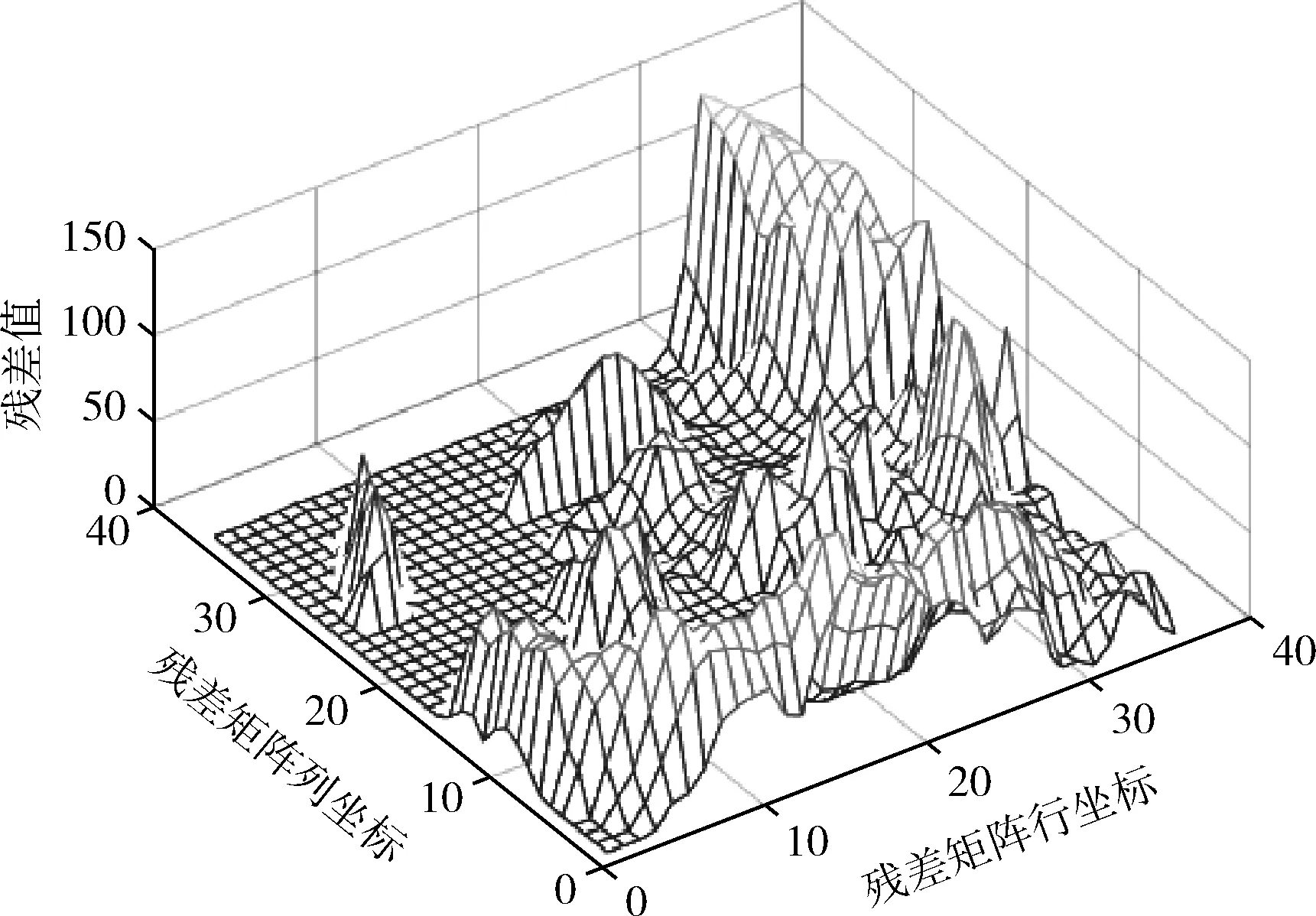
图3 RBC加入差异字典后的残差矩阵
1.3 灰度对称脸的提出
差异字典由于其可以弥补测试样本与训练样本之间的姿态、表情差距,所以对于小样本人脸识别有较好的效果。根据式(4)可以看出差异字典是由差异样本减去基准样本所构成的,这导致只有当训练样本为基准样本时,才能使训练样本与差异字典更好地线性表示测试样本。即如果训练样本不为基准样本,则分类结果将有较大的误差。但是对于小样本来说,一般使用1~3个训练样本,难以保证所有的训练样本全为基准样本。基准样本一般为无姿态无表情变换的正脸,正脸一般都具有对称性。所以这里使用灰度对称脸把不是基准样本的图像转变为具有对称性的样本,也就是所谓的近似基准样本。
人脸具有对称性,根据人脸的对称性提出了对称脸[8],即把原始人脸根据图像中轴线及其对称性生成新的虚拟样本,生成的新虚拟样本具有对称性,即为近似基准样本。但这种对称脸的生成方式,只考虑了图像位置的对称性,所以根据图像中轴线生成的对称脸并不一定是最好的方法。
图4中的虚线是将人脸图像的灰度值矩阵压缩为一行(即图像灰度值按列求平均值后得到的一行灰度值)所得到的数据图像,由上图可以看出数据的起伏与人脸的姿态与位置有很大的关系。灰度值均值的分布可以很明显地看出具有近似对称性。灰度值的对称轴(如图4中的三角标记线为灰度值的对称轴)不一定为图像的中轴线(如图4中的方块标记线为图像的中轴线)。当人脸为正脸时,灰度值的对称轴与图像的中轴线重合。但是当人脸为侧脸时,灰度值的对称轴与图像的中轴线并不相同。根据灰度值均值具有的近似对称性,我们提出了灰度对称脸。
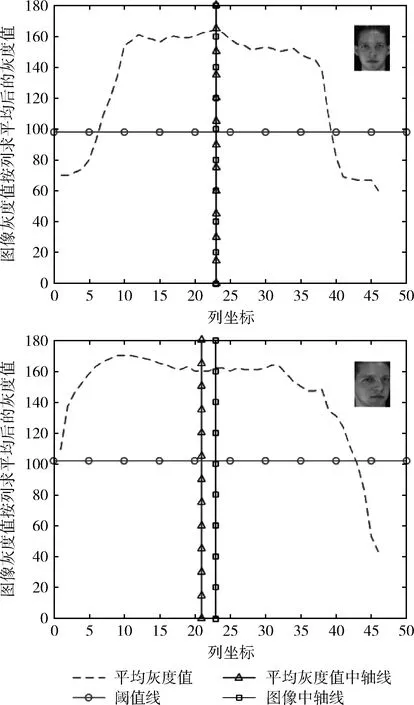
图4 将人脸图像压缩为一行后的数据图像
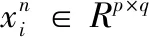
α=β*u
(8)
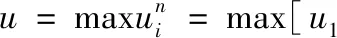
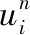

图5 原始图像与灰度对称脸
根据图5,可以看出灰度对称脸可以把非基准脸转变为近似基准脸。
为了比较灰度对称脸和对称脸,谁对于差异字典有更好的提升。于是以图6所示的ORL库的第37类的10幅人脸图像作为实验对象,以第1~9幅人脸图像中第n幅作为原始训练样本,对其分别进行灰度对称脸或对称脸生成虚拟样本组成训练样本集,以第37类的第10幅图像为测试样本。以GT库的前25类的第1个样本为基准样本,前25类的第2、3、4、5、6、8个样本为差异样本构成差异字典。最后代入到式(7)中求出残差值ei。ei的数值如图7所示,其中方块标记虚线表示用灰度对称脸生成虚拟样本组成训练样本集代入到式(7)中的残差值曲线,圆圈标记虚线表示用对称脸生成虚拟样本组成训练样本集代入到式(7)中的残差值曲线。根据图7,可以看出灰度对称脸结合差异字典大多数情况下比对称脸的残差值更小,对于差异字典有更好的提升效果。于是本文提出了根据图像灰度均值分布,用以确定对称轴所在位置的灰度对称脸生成方法。

图6 ORL库的第37类的人脸图像
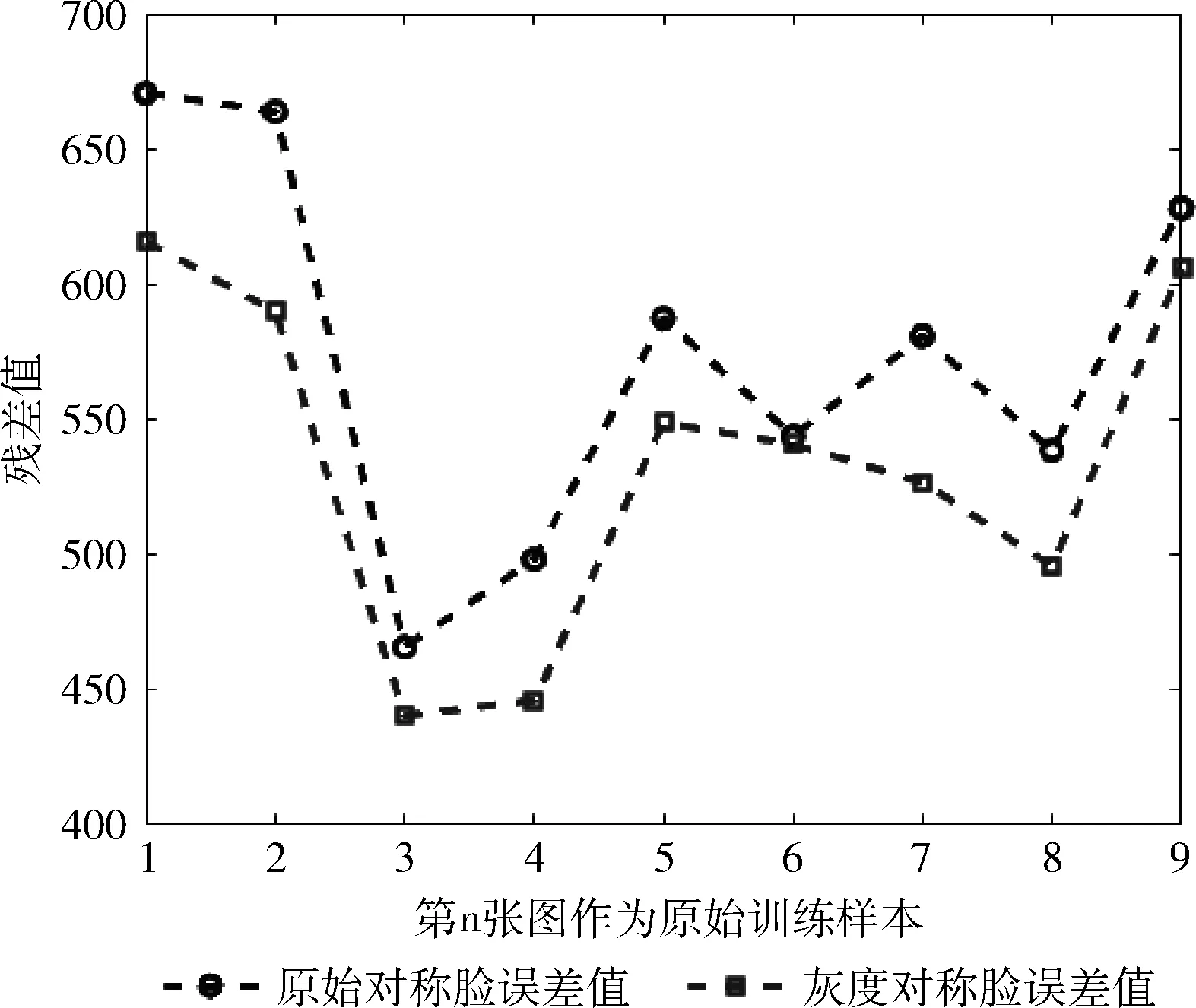
图7 加入灰度对称脸或对称脸的差异字典残差对比
1.4 算法流程
为了在小样本情况下使人脸识别效果较好,我们加入差异字典的基于表示的分类方法。因为差异字典只有在训练样本为基准样本时效果较好,于是又进一步加入了灰度对称脸来提高识别率。本文所提出方法的具体步骤如下:
步骤1 每类取1、2或3个训练样本初步构建训练样本集,并应用灰度对称脸方法生成左、右灰度对称脸。并将训练样本与左、右灰度对称脸结合构成新的训练样本集X。之后选取与训练样本无关的类用于生成差异字典,取无关类中的基准样本(基准样本一般为每类的第一个样本)和差异样本根据式(4)生成无关类的差异字典D;
步骤2 将训练样本集X与差异字典D分别进行归一化,即每列除以列平均值。将归一化后的训练样本集X与差异字典D代入到式(6)中,求出系数矩阵B与差异字典系数矩阵A;
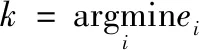
本文算法的具体流程如图8所示。
2 实验数据及分析
我们在ORL、GT和FERET人脸库分别进行了所提人脸识别算法的测试。根据测试数据,不仅可以验证该算法在处理小样本训练方面是否有效,而且还可以验证该算法对姿态、表情变化是否具有鲁棒性。此外,为了验证我们提出算法的性能,这里将本文算法与多重表示和稀疏表示算法(multiple representations and sparse representation algorithm,MRSR)[9],基于常规和逆表示的线性回归分类(conventional and inverse representation-based linear regression classification,CIRLRC)[10],基于无噪声表示的分类(noise-free representation based classification,NFRBC)[11],局部通用表示(LGR),集成稀疏和协同表示分类(integrating sparse and collaborative representation classifications,ISCRC)[12],判别稀疏表示法(discriminative sparse representation method,DSRM)[13],以及原始对称脸结合差异字典基于表示的分类算法和差异字典基于分类表示的算法进行了比对。
图8 本文算法流程
2.1 ORL人脸库
ORL库共有400张人脸图像,包含40名受试者的人脸图像,每人各有10幅图像。这些人脸图像由不同的光照,不同的面部表情,以及不同的姿态组成。每幅图像的大小为56×46的像素矩阵,为了方便后续差异字典的图像提取,我们在实验中将训练样本、测试样本以及差异样本全都缩放为36×36的灰度像素矩阵。实验中,以ORL库每人前1、2、3幅图像及其灰度对称脸为训练样本,ORL库中除训练样本以外的图像为测试样本。取GT库的前25类构成差异字典,每类的第1张图像为差异字典的基准样本,第2、3、4、5、6、8张图像为差异字典的差异样本,λ=0.12,β=0.6。图9展示了部分ORL库和GT库的图像,第一行为ORL库部分图像,第二行为GT库部分图像。表1是对比算法和本文算法在ORL库上的实验结果,以错误率的形式表示。

图9 ORL库部分图像与GT库部分图像
根据表1可看出与现有算法相比,所提算法在处理ORL数据库小样本情况中光照、姿态、表情变化方面具有更好的性能和更好的识别精度。对比差异字典和原始对称脸差异字典的识别率,可得出灰度对称脸可以更好发挥差异字典的作用,并改善训练样本为非基准脸情况的识别效果。
2.2 GT人脸库
GT数据库包含50个人的面部图像,每个人都有15幅背景复杂的彩色图像。图像由不同表情、不同光照条件和不同角度的正面人脸构成。我们移动每个图像的背景,并将它们转换成灰度图像。为了方便后续差异字典的图像提取,在实验中将训练样本、测试样本以及差异样本全都缩放为34×34的灰度像素矩阵。实验中,以GT库每人前1、2、3幅图像及其灰度对称脸为训练样本,GT库中除训练样本以外的图像为测试样本。取ORL库的前25类构成差异字典,每类的第1张图像为差异字典的基准样本,第2、4、5、8张图像为差异字典的差异样本,λ=0.3,β=0.5。表2是对比算法和本文算法在GT库上的实验结果,以错误率的形式表示。
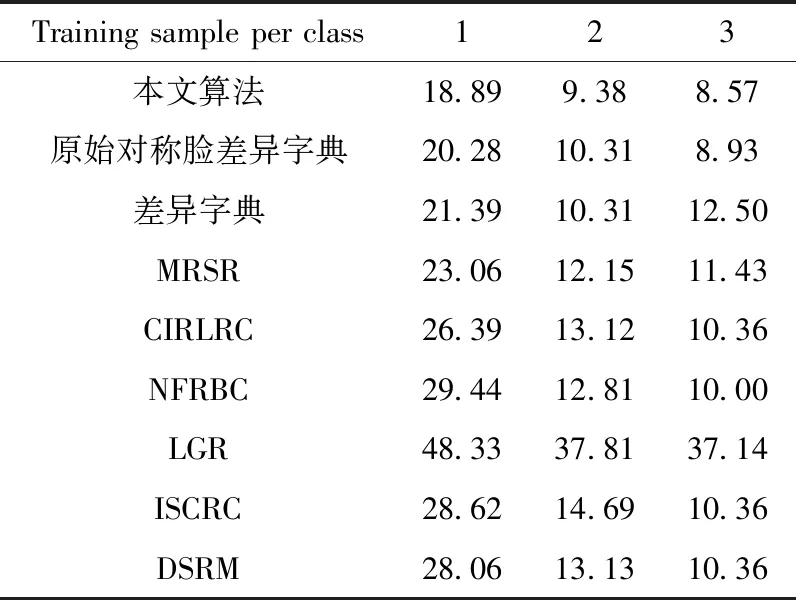
表1 算法在ORL库上的实验结果(错误率/%)
根据表2可以看出,所提出的算法对于GT库的表情变化、光照变化和角度偏转等方面具有较好的鲁棒性。因为GT数据库中的人脸背景是复杂的,使其不利于基于表示的分类算法。但灰度对称脸和差异字典对于基于表示分类的分类方法具有很好的提升效果。
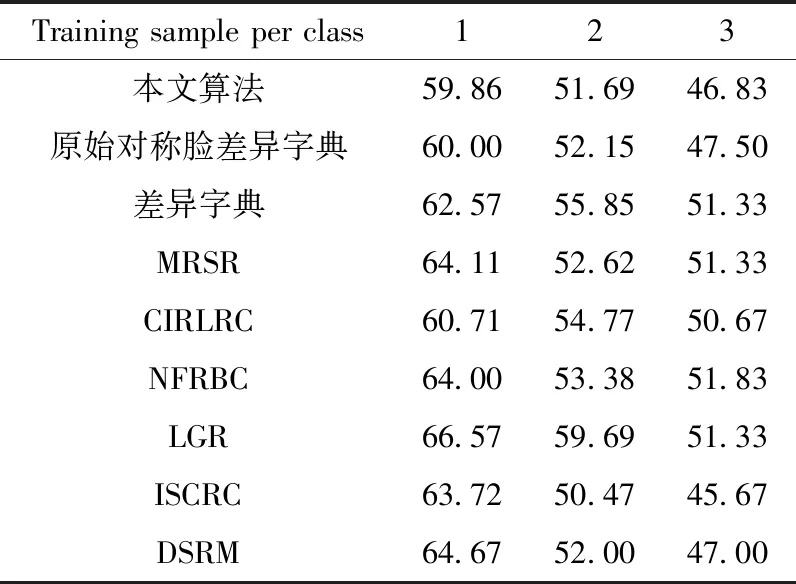
表2 算法在GT库上的实验结果(错误率/%)
2.3 FERET人脸库
我们使用FERET数据库的一个子集来测试我们的方法。该子集由来自200个人的1400张图像组成,每个人提供7幅图像,图像显示了不同表情、和不同角度的人脸。我们使用其中前100类的第1、2、3幅图像组成训练样本集,每类的其余图片作为测试样本。取后100类的每类第1幅图像作为差异字典的基准样本集,其余样本为差异字典的差异样本集,并将全部图像的大小调整为40×40的灰度图像。λ=0.04,β=0.56。其它对照算法也使用前100类做训练样本集和测试样本集,以便进行算法比较。图10展示了部分FERET库的部分图像。表3是对比算法和本文算法在FERET库上的实验结果,以错误率的形式表示。

图10 FERET库部分图像
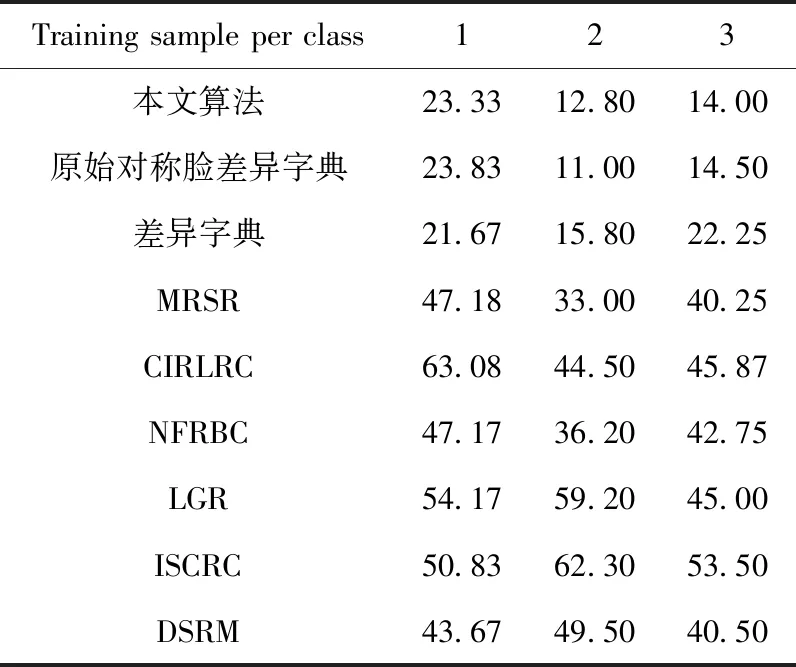
表3 算法在FERET库上的实验结果(错误率/%)
根据表3可看出本文的算法在姿态以及表情变换的小样本问题,得到了较好的实验结果。虽然在第1张图片作为训练样本时,本文算法不如差异字典,是因为FERET库的大多数类的第1张样本具有左右脸不对称性,例如左右眉毛的起伏不同,左右脸的表情不同,头部的摇摆角度偏转等。所以FERET库的第1张样本不适合做对称变换。但本文算法在小样本的大多数情况下,效果要比其它算法好。
3 结束语
为了应对在小样本情况下,测试样本与训练样本具有很大差异的情况,本文引入了差异字典,使其可以根据无关类的差异变化而缩小测试样本与训练样本之间的差异,改善分类结果。但差异字典只有在训练样本为基准样本时,才能有较好的效果。于是本文提出灰度对称脸,即根据人脸图像灰度值均值分布具有对称性而将非基准脸转换为近似基准脸,以提高基于表示分类的差异字典的性能。实验结果表明,灰度对称脸与差异字典结合的基于表示的分类算法在小样本情况下的人脸识别有很好的效果。
