基于分层学习的易混淆法条预测
2020-02-08赵红燕谭红叶
程 豪,张 虎,崔 军+,赵红燕,3,谭红叶,李 茹,2
(1.山西大学 计算机与信息技术学院,山西 太原 030006;2.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006;3.太原科技大学计算机科学与技术学院,山西 太原 030024)
0 引 言
随着人工智能的兴起,司法智能化已成为目前司法领域的研究热点之一,相关人员提出“智慧法院”的观点。法条预测作为法律判决预测的子任务,是构成“智慧法院”的重要部分。目前大多数现有工作采用文本分类方法完成法条预测,但未能较好解决易混淆法条预测问题。
本文以刑法类文书作为实验数据,输入刑事案件的事实描述预测该案件所引用的法条。通过分析案情描述部分内容,发现较多法条区分性大,易于准确预测,但存在部分法条间内容较为相似,在法条预测时极易混淆。据此针对易混淆法条预测问题,采用分层学习的方法解决。首先按照各法条预测效果将其分为易区分法条和易混淆法条两类;其次结合法条含义与相应事实描述两部分内容将易混淆法条组合为不同的易混淆法条集,并单独训练各易混淆法条集的分类模型。依据易混淆法条集的类别情况与易区分法条类别数,构建基于分层学习的易混淆法条预测数据集。根据分层预测思想,完成对两类法条的预测。本文的研究主要贡献有:
(1)通过分析刑事文书的事实描述与法条内容,将183个刑事法条整理组合为136个易区分法条和11个易混淆法条集,其中11个易混淆法条集总共包括47个易混淆法条;
(2)针对法条预测中易混淆法条问题,构建基于分层学习的易混淆法条预测模型。
1 相关工作
早期研究通常采用简单数学模型进行法律判决结果预测,研究人员根据案情事实描述部分进行定量分析,提出法律判决计算公式;利用相关性分析预测案例判决结果;在法律判决预测中引入数学模型,这些方法仅适用于很少类别的小数据集。由于机器学习在许多领域的成功应用,研究人员开始将法律判决预测作为文本分类问题并利用机器学习的方法来解决。通过提取了法律因素标签用于案件分类任务;Sulea等[1]提出了基于支持向量机的罪名预测模型,模型以案情事实描述和时间跨度信息作为输入,输出罪名信息。
随着深度学习在语音[2-4]、计算机视觉[5-8]上的成功应用,研究人员提出许多基于深度学习的文本分类模型,为法律判决预测奠定良好的基础。Yoon Kim等[9]最早提出将卷积神经网络(convolutional neural network,CNN)用于文本分类任务,其中卷积层滤波器具有局部特征提取的功能,能够捕捉文本上下文局部相关性;Xiang Zhang等[10]提出基于字符集的卷积神经网络文本分类模型,该模型不需要使用预训练好的词向量和语法句法结构等信息,并且可很容易的推广到所有语言;Pengfei Liu等[11]提出将多个任务联合起来,用来直接对网络进行改善,基于RNN(recurrent neural network)设计了3种不同的信息共享机制进行训练,并在4个基准的文本分类任务中获得了较好的效果;Joulin A等[12]提出快速文本分类模型,该模型结构简单高效,在保持分类效果的同时,大大缩短了训练时间;Zichao Yang等[13]提出了层次注意力网络模型(hiera-rchical attention networks,HAN),该模型针对文本分类问题采用层级注意力与双向循环神经网络相结合的方法;Conneau A等[14]关注卷积神经网络的层数对分类效果的影响,通过增加层数抽取更加准确的文本特征信息。
在参照深度学习文本分类的基础上,罗等[15]提出基于注意力机制的刑事罪名预测模型,在统一的框架中对罪名预测任务和相关法条提取任务进行建模,以提取的法条信息作为罪名预测的依据;胡等[16]针对法条预测任务中低频罪名问题,引入了法律区分性属性来增加罪名预测的可解释性。
现有研究中针对法条预测问题大多采用基于深度学习的分类模型,对易混淆法条的预测效果普遍不太理想。
2 基于分层学习的易混淆法条预测模型
2.1 问题描述
表1是易混淆法条实例,表中法条第347条是走私、贩卖、运输、制造毒品法条,法条第348条是非法持有毒品的法条,通过分析两个法条的案情事实描述部分,发现其中包含许多与毒品相关的词语,文本语义较为相似,在进行法条预测时容易相互混淆。

表1 易混淆法条实例
注:加粗字体为与“毒品”相关的相似或相同词语。
2.2 筛选与组合
本文提出的模型首先根据法条预测中各法条的预测结果将法条划分为易区分法条和易混淆法条,表2显示了各法条的预测实验结果。当法条预测的准确率、召回率、F1值高于法条平均指标值,实验认为该法条为易区分法条,相反低于法条平均指标值,则认为该法条为易混淆法条。
对于易混淆法条,分析相关的法条内容与对应事实描述,将法条内容、相应事实描述相近的组合为易混淆法条

表2 各法条预测结果
集。我们将47个易混淆法条整理组合为11个易混淆法条集,对11个易混淆法条集进行编号。每个易混淆法条集包含法条预测时相互间容易混淆的多个法条,见表3。
2.3 模型构建
实验数据集中共涉及183个刑事法条,筛选组合整理为147个法条类别,其中包括11个易混淆法条集类别与136个易区分法条类别。易混淆法条预测模型可通过两层学习机制实现。该模型的整体架构如图1所示,第一层分类学习中在易区分法条和易混淆集法条组建的147个新法条类别上训练分类器模型,第二层分类学习中分别训练11个易混淆法条集的分类器模型。我们利用新类别分类器模型完成第一层预测,预测结果为易混淆法条集或易区分法条。如果结果为易区分法条,则完成预测;如果结果为易混淆法条集,则调用相应易混淆法条集模型完成第二层预测,输出易混淆法条预测结果。模型中分类器采用卷积神经网络文本分类器。

表3 易混淆法条集

图1 基于分层学习的易混淆法条预测模型
2.4 分类器
2.4.1 编码
易混淆法条预测模型中分类器模型包含有输入层、卷积层、池化层、全连接层、Softmax层。其中卷积层负责抽取文本的特征,最大池化层负责选择最主要的特征值,Softmax用于预测在各个类别上的概率。在输入层对文本进行向量化表示,通过将文本序列中对应位置词典元素的词向量拼接起来,就得到整个文本序列的词向量表示矩阵
x1∶n=x1⊕x2⊕…⊕xn
(1)
其中,⊕是词向量连接运算符。xi是句子中第i个单词的词向量,xi∶i+j指的是xi,xi+1,…,xi+j共j+1个词的词向量。卷积操作涉及滤波器w,其应用于h个词的窗口以产生新特征。例如,在单词xi∶i+h-1Xi∶i+h-1上一个窗口生成特征Ci
ci=f(w·xi∶i+h-1+b)
(2)
其中,b是一个偏置项,f是一个非线性函数。这个滤波器用于句子 {x1∶h,x2∶h+1,…,xn-h+1∶n} 中,产生一个特征集
c=[c1,c2,…,cn-h+1]
(3)
2.4.2 正则化

y=w·(z∘r)+b
(4)
其中,z表示m个滤波器组成的特征集,∘表示按元素逐个相乘操作,r表示掩模向量。
2.4.3 优化
模型采用交叉熵作为损失函数。法条预测损失可以形式化为
(5)

3 实 验
为了验证本模型在刑事案件预测中的有效性,本文基于中国裁判文书网的刑事数据构建了不同规模的数据集,并利用SVM模型、CNN模型与RNN模型和本文的模型(hierarchical learning confusing law prediction model,HLCLPM)进行了比较实验。
3.1 数据集
本文基于“中国裁判文书网”公开的刑事法律文书构建Small和Large两组数据集,其中每份数据由法律文书中的案情事实部分与引用法条两部分组成。两组数据集中涉及183个刑事法条,Small包括19.6万条文书样例,Large数据集包括150万条文书样例。在实验中两组数据集的划分情况见表4。
3.2 基 线
本文采用3种典型的文本分类模型作为实验基线:
TFIDF+SVM模型:实现了(TFIDF)来提取输入的文本特征,并采用SVM(support vector machine)作为分类。
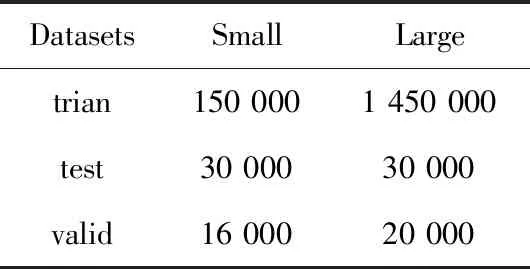
表4 两个数据集数量统计/条
RNN模型:采用循环神经网络(RNN)作为文本分类器。
CNN模型:采用卷积神经网络(CNN)文本分类器。本文HLCLPM模型的基础模型,选用该模型作为对比,可以更好地体现出分层学习的思想可以帮助易混淆法条的预测。
3.3 实验设置和评价指标
本实验卷积神经网络模型滤波窗口大小设置为3,4,5,词向量维度大小为264维,全连接层神经元为128,dropout保留比例为0.5,学习率为0.0001,bath_size大小为264。
实验采用精确率(Precision,P)、召回率(Recall,R)、F1值(F-measure,F)作为评价指标。计算方式如下
(6)
(7)
(8)
其中,TP是模型将正例预测成正例的数目,FP是模型将负例预测成正例的个数,FN是模型将正例预测成负例的个数。
4 结果及分析
(1)实验一:不同模型下法条预测
实验对比了在两组数据集下本文提出的模型与其它基线模型的预测结果。见表5。

表5 两组数据集下各个模型法条预测的结果
其中加粗数据表示最优结果。表5显示:各模型在Large数据集下评价指标均优于Small数据集的评价指标,表明数据越大越有利于易混淆法条预测模型的训练。在相同数据集下本模型的评价指标均取得最优,表明基于分层学习的易混淆法条预测模型能较好完成易混淆法条预测。
(2)实验二:验证本模型在易混淆法条预测的有效性
为进一步验证本模型能较好解决法条预测中易混淆法条预测问题,我们构建了两个易混淆法条数据集,Data1和Data2。Data1包括走私类法条、合同诈骗类法条、逃税漏税类法条11个易混淆的法条,Data2包括走私类法条、合同诈骗类法条、逃税漏税类法条、毒品类法条17个易混淆的法条。见表6。

表6 Data1和Data2统计/条
我们将本模型与在TFIDF+SVM、RNN、CNN这3个分类模型在数据集1与数据集2上的预测结果进行对比,见表7。

表7 模型在Data1和Data2上的预测结果
表7显示,在数据集Data1和Data2上本模型的预测结果都取得最优,表明本模型在处理易混淆法条预测上的有效性。
5 结束语
本文根据刑事案件的案情描述,专注于易混淆法条预测问题。我们通过分析各个法条预测结果并结合文书案情描述与法条内容的相似度,将常用的183个刑事法条分为136个易区分法条与47个易混淆法条,易混淆法条进一步组合为11个易混淆法条集。针对法条预测中易混淆法条问题,我们构建基于分层学习的易混淆法条预测模型,通过对易混淆法条集单独训练分类模型,增强对易混淆法条相应案情描述特征的学习能力。本文没有将法条内容用于易混淆法条预测之中,同时没有考虑一个案件引用多个法条的情况。因此接下来我们的研究重点为:如何将法条内容运用到法条预测之中,增加法条预测的司法可解释性;如何解决易混淆法条中的一对多问题。
