基于情感词汇与机器学习的方面级情感分类
2020-02-08张璞,李逍,刘畅
张 璞,李 逍,刘 畅
(重庆邮电大学 计算机科学与技术学院,重庆 400065)
0 引 言
情感分类作为情感分析的一项关键研究任务[1],受到研究人员的广泛关注。已有研究中,多数学者的研究集中于文档级及句子级的情感分类[2-9]。作为细粒度情感分析领域的一项研究任务,方面级情感分类的目标是确定句子中所描述对象的特定方面的情感极性。已有的方面级情感分类研究中,不少学者采用基于情感词典的方法。王巍[10]通过构建修饰词表以及高频搭配库对评价单元进行情感分类。该类方法的核心思想是“词典+规则”,即根据情感词典匹配评价短语中的情感词,并考虑其中的否定词、修饰词以及搭配的评价对象,设计相应的规则进行情感分类,但由于网络词汇的不断更新、语言表达的方式也复杂多变,该类方法难以处理新领域特有的语言现象。还有学者使用机器学习和深度学习方法来进行方面级情感分类。Mohammad Al-Smadi等[11]利用朴素贝叶斯、贝叶斯网络、决策树、k-最近邻(kNN)、支持向量机(SVM)等机器学习方法来构建分类器,进行方面级情感分类。曾义夫等[12]提出一种基于双记忆注意力机制的方面级情感分类模型来判断评论中评价对象的情感倾向。总体而言,基于机器学习的方法一定程度上弥补了情感词典方法的不足,但需要大量时间和精力进行数据标注,且特征的提取和分类器的选取将直接影响到分类性能。
本文提出了一种基于情感词汇与机器学习的方面级情感分类方法,在数据集上的微平均值和宏平均值分别达到89.61%和89.27%,相比4种传统机器学习方法中表现最好的KNN方法分别提高了3.15%和3.66%。
1 相关介绍
1.1 评价搭配及情感类别
方面描述的是评价对象的某一侧面,通常表示为评价对象的属性,方面级情感分类任务主要针对由评价对象的某个特定方面与其评价词组成的评价搭配进行情感分类。例如“华为荣耀手机的做工好,颜色炫”这一评论语句中,评价对象为华为荣耀手机,所涉及方面为做工和颜色,评价搭配包括<做工,好>和<颜色,炫>,相应的方面级情感分类结果均为积极。通常,评价搭配可分为以下几种:第一种中,评价词的情感倾向与评价对象无关,如评价搭配<手感,好>和<信号,好>等,其中的评价词语“好”始终表达正向的情感;第二种评价搭配的情感倾向由评价对象和评价词语共同决定,如<性价比,高>的情感倾向为正向,<价格,高>的情感倾向为负向,评价词“高”对不同的评价对象表现出的情感倾向也不同;还有少部分评价搭配的评价词没有明显的情感词,多表现为动词或动词短语的形式,如<电池,每天需要充电>,这一类评价搭配需要对其进行深层次理解才能判断其情感倾向。本文的情感倾向类别包括正向、中性和负向这3类。
1.2 Word2Vec
Word2Vec是Google开源的一款词向量表示模型的学习工具,其基本思想是将文本中的每个词映射为一个固定维度的向量,将词与词之间的语义关系转化为它们对应的词向量之间的距离。Word2Vec主要有CBOW和Skip-Gram模型。对于某个词w(t),如取上下文窗口大小为k,CBOW模型根据w(t-k) 至w(t+k) 的词向量来预测当前词w(t) 的词向量;Skip-Gram模型则利用当前词w(t) 和上下文窗口k来预测w(t-k) 至w(t+k) 的词向量。本文使用Word2Vec训练词向量模型来获得文本的分布式表示。
1.3 互信息
互信息(MI)主要用来计算两个随机变量之间的相关性。对于某个特征项i和某个类别c,它们的互信息MI(i,c) 定义如式(1)所示

(1)
其中,N(i,c) 表示属于类别c的文档集合中出现特征项i的文档数量;N(i) 表示数据集中出现特征项i的文档数量;N(c) 表示属于类别c的文档数量;N为数据集中的文档总数量。
2 情感分类方法流程
本文的方面级情感分类方法的流程如图1所示。
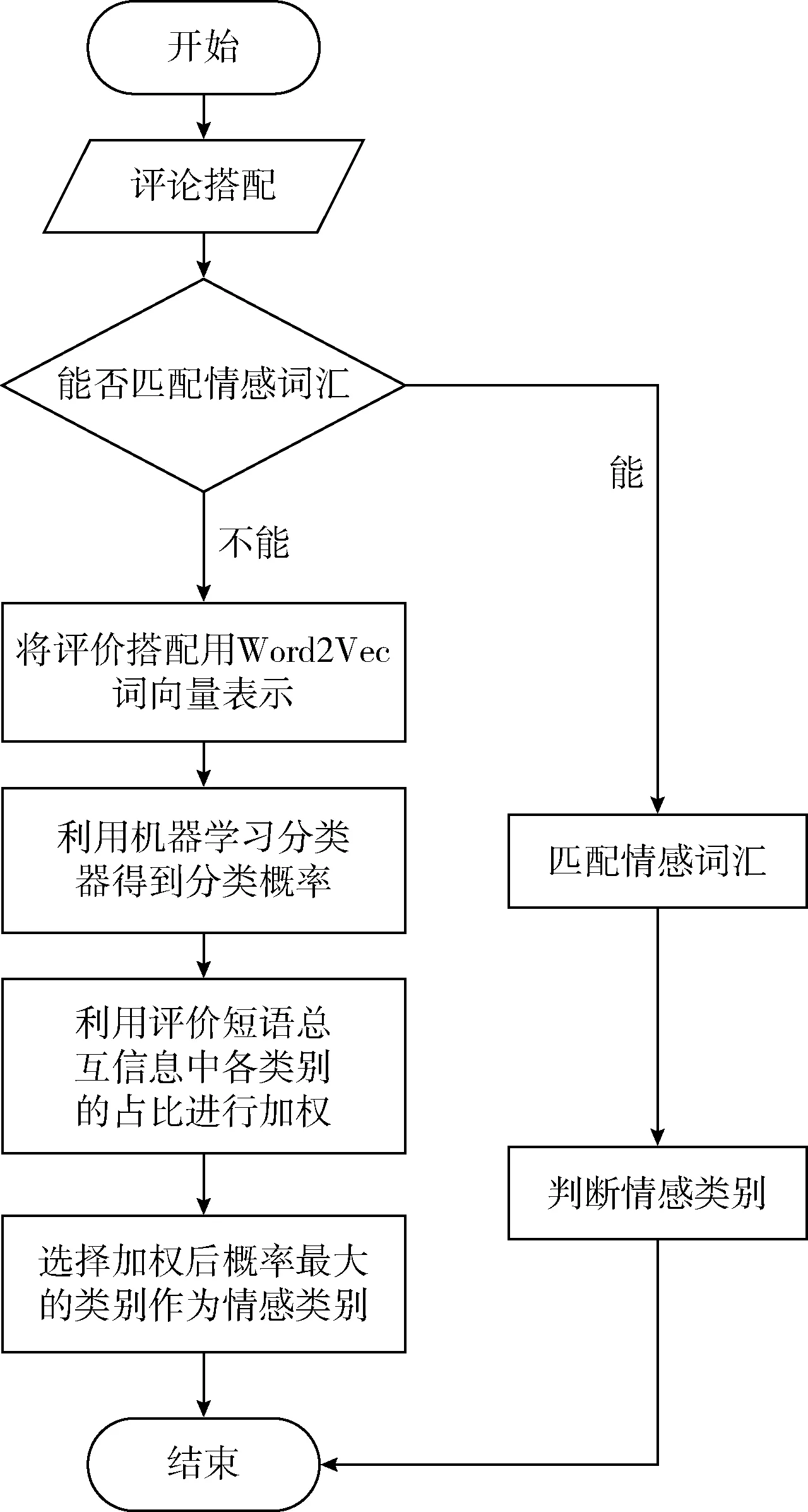
图1 本文方法的流程
2.1 基于情感词汇的分类方法
2.1.1 传统的情感词典分类方法
情感词典通常是指具有褒义或贬义倾向的词语集合,传统的基于情感词典的分类方法在构建和扩充情感词典之后,还需要考虑情感词周围的否定词、修饰词以及搭配的评价对象,对其制定相应的规则进情感分类,该方法分类效果的好坏取决于情感词典和规则是否足够完善。如产品的评价对象“电池”,与之搭配的评价词“耐用”属于褒义词,但评价搭配<电池,不耐用>的情感倾向为负向,这是由于包含了否定词“不”,使得该评价搭配表现的情感倾向与情感词典的判断结果完全相反;再如评价搭配<电池,不是特别耐用>和<电池,不是很耐用>的情感倾向均表现为中性,这是由于否定词“不是”与描述情感强度的修饰词“特别”或“很”组合之后,整体表达的负向情感没有那么强烈、肯定,但与正向情感又有较大差距,所以将这两个评价搭配的情感倾向判定为中性;而对于评价搭配<电池,特别不耐用>和<电池,很不耐用>,同样存在着否定词“不”、表示情感强度的修饰词“特别”和“很”,它们表现出来的情感倾向却都是负向的。
因此,仅通过情感词典和制定的相关规则对评价搭配进行正向、中性和负向的情感分类,由于自然语言表达的多样性导致规则的完整度难以达到理想状态。
2.1.2 本文的情感词汇分类方法
通过对已有标注的评价搭配进行观察,发现大部分情感倾向为中性的评价搭配中的评价短语往往包含了特定的评价词或修饰词。如评价搭配<屏幕,有点小>,<质量,还行>和<质量,一般>等都表现为中性情感,其中的评价短语包含了“有点”和“还”等特定的修饰词或“一般”等特定的评价词,这些特定的词与评价短语中的其它词或不同的评价对象进行搭配之后,表现的情感倾向为中性。对评价搭配中这些特定词进行单独考虑有利于提高情感分类效果。为方便叙述起见,本文将选取的极性评价词及修饰词统称为情感词汇。通过人工选取少量情感倾向与评价对象无关的正向、中性、负向情感词组成情感词汇,并根据以下策略判断评价搭配的情感倾向:正向和负向情感词与评价搭配中完整的评价短语进行完全匹配,如评价搭配<运行,流畅>可匹配为正向情感;对于情感词汇中的中性修饰词,则只需要情感词匹配部分评价短语即可,如评价搭配<外表,还不错>和<性能,还可以>,它们的评价短语中有部分词能够成功匹配情感词汇中的中性修饰词“还”,因而倾向性判定为中性。本文的部分情感词汇见表1。

表1 部分情感词汇
2.2 融入互信息的情感分类方法
对没有成功匹配2.1.2节中情感词汇的评价搭配,本文使用Word2Vec对其进行词向量表示,然后利用传统机器学习分类方法计算评价搭配属于各类别的概率,并通过计算每个词的互信息得到评价短语的总互信息,利用总互信息中各类别的占比对基础的机器学习分类器得到的各类别分类概率进行加权,然后选择加权后概率最大的类别作为该评价搭配的情感类别。
2.2.1 基础的机器学习分类器
传统的机器学习分类方法中,逻辑回归(LR)和支持向量机(SVM)分类器主要用于二分类,对于三分类问题通常需要使用一对一或一对多的方法对其进行改进,但这两种分类器在本文的测试数据中分类效果并不理想,没有正确判断情感倾向的评价搭配分别占总测试数据的16.51%和20.41%;而朴素贝叶斯(NB)分类器对测试数据分类错误的比例达到23.93%。
特别地,K-最邻近法(KNN)分类器在分类过程中选择最近的K个样本中投票最多的类别作为待预测样本所属类别的决策结果,在处理二分类问题时只要将K值选取为奇数就能保证其中一个类别的投票数多于另一个类别,从而达到分类目的,但在处理本文的三分类问题时,可能存在某两个或3个类别投票数相等的情况,这种情况下KNN分类器往往将第一个出现的类别作为决策结果,以至于对分类效果产生影响。通过分析结果得知,KNN中由于投票数相等导致的错误占所有分类错误的15.07%,而在测试数据中所有的出现两个类别投票数相等的评价搭配中,以第一个出现的类别作为决策结果导致分类错误的占47.83%,接近50%的随机选择结果。
本文将KNN分类器中各类别投票数占K值的比例作为该类别的分类概率,例如K值选取为5时对评价搭配<电池,不怎么好>和<包装,太简单>进行所属类别预测,得到的各类别分类概率见表2。

表2 KNN的分类概率
从表2中可以看出,KNN分类器将评价搭配<电池,不怎么好>的情感倾向预测为中性和负向的可能性相同,将评价搭配<包装,太简单>的情感倾向预测为正向和负向的概率也相等,这种在两个分类概率相同的类别中随机选择的情况必然会在一定程度上影响到分类结果的准确性。因此,需要进一步对基础分类器的分类概率进行一定的权重计算,以提升分类效果。
2.2.2 融入互信息的机器学习分类器
一方面,三分类过程中,LR、SVM、NB等分类器分类效果有待提高;另一方面,KNN分类器出现某两个或3个类别的分类概率相等而进行随机选择会导致分类效果降低。针对这些问题,本文将互信息中各类别的占比作为机器学习分类概率的权重进行情感分类。首先利用哈尔滨工业大学研发的语言技术平台(LTP)的分词模块对评价对象和评价短语进行分词处理,然后根据式(1)对评价短语中的每个词分别计算其与正向、中性和负向3个类别的互信息,然后通过式(2)得到整个评价短语分别对3个类别的总互信息。特别地,其中互信息值的负数本文将其设置为0
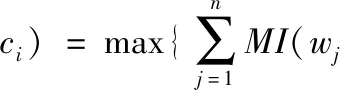
(2)
式中:评价短语s表示为 {w1,w2,…,wn},类别集合为C={-1,0,1}。 对于输入的测试数据,首先通过机器学习分类器得到该评价搭配分别属于正向、中性和负向的概率集合P={p1,p2,p3},然后根据评价短语的总互信息中各类别的占比分别对基础分类器得到的概率进行加权,如式(3)所示,最后选择加权计算之后概率最大的类别作为该评价搭配的情感倾向分类结果
(3)
式中:pi表示基础分类器预测评价搭配属于类别ci的概率值,MI(s,ci) 表示评价短语s对于类别ci的总互信息,若3个类别的总互信息都为0,则将3个类别的权重都分配为1,否则根据总互信息中各类别的占比进行权重分配。以KNN分类器为例,其加权前后的概率见表3。

表3 互信息加权前后的概率值
2.3 本文的情感分类算法
本文方法的完整算法如下:
输入:测试评价搭配集合D={d1,d2,…,dn};
输出:各评价搭配所属情感类别的集合R={r1,r2,…,rn},其中ri的取值为正向、中性或负向;
步骤1 构建情感词汇集合E;
步骤2 计算训练集中评价短语的每个词分别对于3个类别的互信息MI(w)={MI(w,c1),MI(w,c2),MI(w,c3)},得到所有词的互信息M={MI(w1),MI(w2),…,MI(wm)};
步骤3 若评价搭配能够匹配情感词汇E,则直接判断评价搭配的情感倾向,否则进入步骤4;
步骤4 将Word2Vec训练得到的评价搭配词向量输入到LR、SVM、NB和KNN等基础机器学习分类器中进行分类,得到评价搭配分别属于3个类别的概率集合P={p1,p2,p3},根据集合M和式(2)得到评价搭配中评价短语s对各类别的总互信息集合MI={MI(s,c1),MI(s,c2),MI(s,c3)},利用式(3)对集合P中的分类概率进行加权,选取加权后概率最大的类别作为情感倾向类别,加入到R集合中;
步骤5 对每个评价搭配进行步骤3和步骤4,直到测试数据全部处理完。
3 实验结果
3.1 实验设置及评价标准
3.1.1 实验数据
本文的实验数据集为自行爬取的3000条京东商城手机评论数据,利用gensim工具包中的Word2Vec模型使用默认参数对所有的评论数据进行训练得到100维的词向量。对其中的1027条评论中进行人工标注得到1800个评价搭配及其情感倾向,其中正向评价搭配682个,中性评价搭配500个,负向评价搭配618个。使用scikit-learn工具包中的LR、SVM、NB和KNN等作为基础的机器学习分类器,选取70%已有标注的评价搭配作为训练集,剩下的30%作为测试集。
3.1.2 评价标准
本文分别对正向、中性和负向情感的分类结果进行准确率、召回率和F1值计算,然后对3个类别分别计算宏平均值和微平均值作为分类器整体性能的评价标准。
3.2 对比实验
为了验证本文提出的针对评价搭配情感分类方法的有效性,选取了4种基础的机器学习分类器作为对比实验,将其直接对已有标注的评价搭配进行训练得到分类模型,包括LR、SVM、NB和KNN等分类器,其中KNN分类器的K值选取为5时的分类效果最好。
3.3 实验结果与分析
3.3.1 实验结果
本文实验所得到的正向、中性和负向情感分类的准确率、召回率和F1值的实验结果分别见表4~表6,整体分类效果的宏平均值和微平均值见表7。其中,LR、SVM、NB、KNN分别代表4个传统机器学习分类方法,“LR(EL&MI)”分类方法则表示本文方法以“LR”作为机器学习分类器,在此基础上结合了情感词汇与互信息(简称 EL&MI)而得到的方法,其它分类方法的表示类似。
3.3.2 实验分析
从表7的实验结果可以看出,对3类别情感分类问题,本文提出的方法和4种传统机器学习方法相比较,宏平均值和微平均值都取得了较好的提升效果,其中最高的宏平均值和微平均值分别达到89.27%和89.61%。
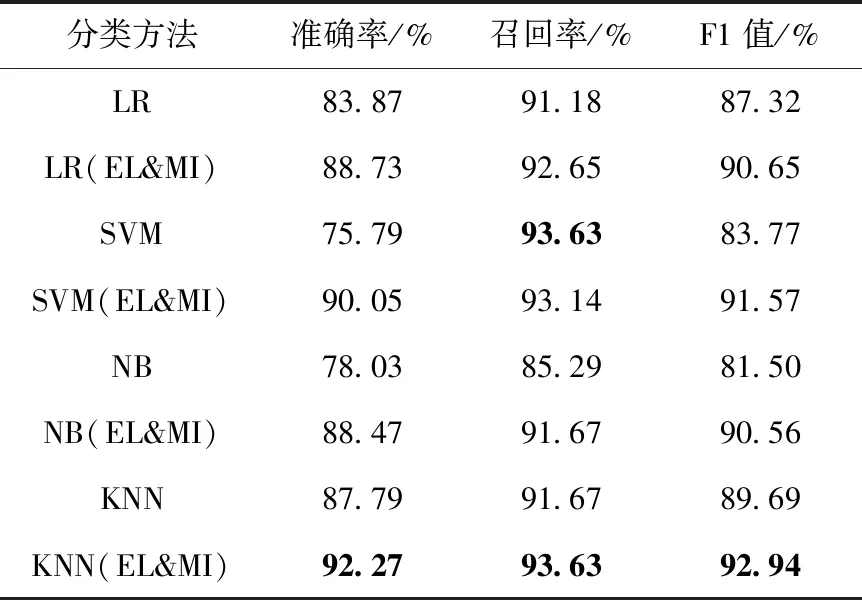
表4 正向情感的分类结果

表5 中性情感的分类结果
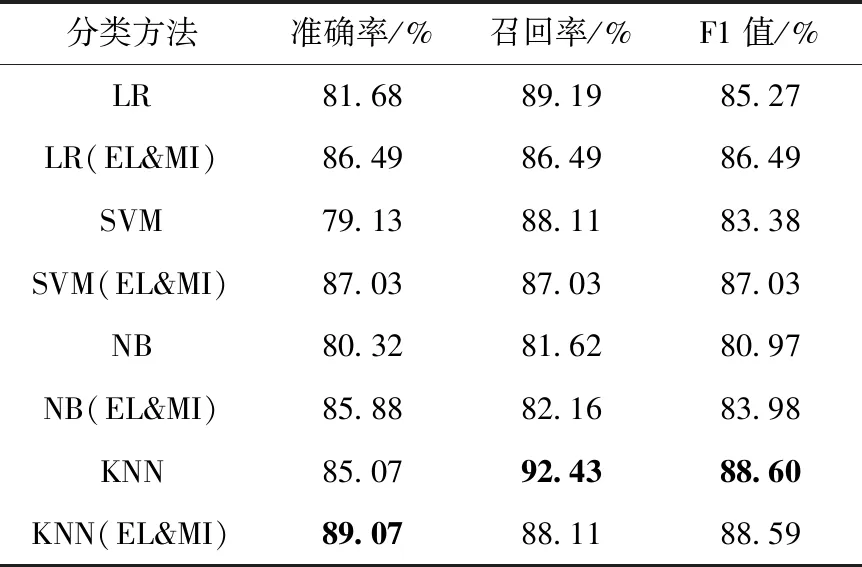
表6 负向情感的分类结果
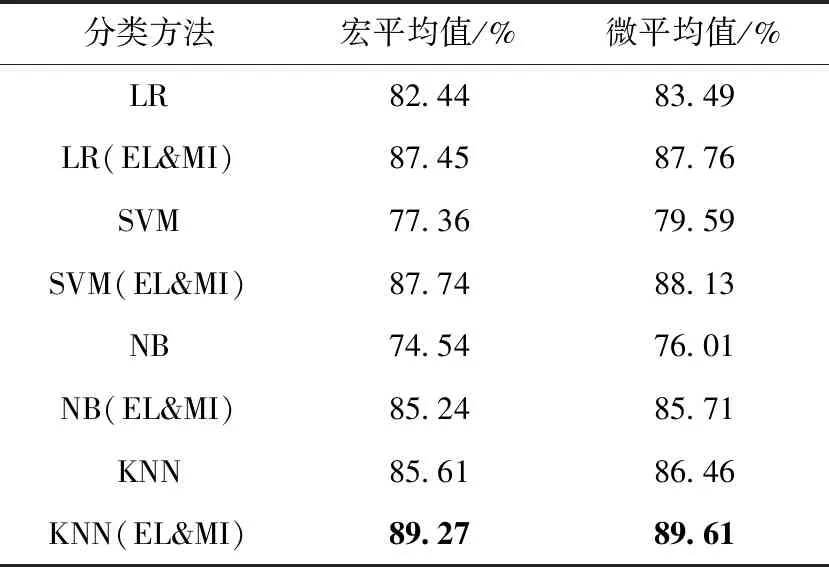
表7 宏平均值与微平均值实验结果
从表5的实验结果可以明显发现,4种基础的机器学习分类器对中性情感的分类效果都不太好,其中SVM分类器的召回率只有50%,NB分类器的准确率和F1值分别只有66.41%和61.15%,这个结果也验证了本文1.1节中提到的中性情感的判断与正向、负向样情感的区分度不够明显;而利用本文提出方法,SVM(EL&MI)分类器的准确率略有降低,但召回率提升了32.67%,F1值提升了19.7%,NB(EL&MI)分类器的准确率、召回率和F1值分别提升了13.98%、25.33%和20.02%,另外LR(EL&MI)和KNN(EL&MI)分类器的F1值分别提高了10.5%和7.74%。这个实验结果充分验证了本文所提出的方法对中性情感分类有显著的提升效果。
从表4和表6的实验结果能够看出,基础的机器学习分类器对正向和负向情感的分类结果都好于表5的中性情感分类结果。而基于4种分类器的本文方法则对正向情感分类的F1值分别提高了3.33%、7.8%、9.06%和3.25%,且都达到90%以上,说明了本文方法对正向情感分类的有效性;负向情感的实验结果中,除了KNN(EL&MI)分类器的F1值几乎保持不变外,LR(EL&MI)、SVM(EL&MI)、NB(EL&MI)等其它3个分类器的F1值分别提高了1.22%、3.65和3.01%,这也表明了本文方法对负向情感分类的有效性。
为了验证本文提出的情感词汇和利用互信息对基础分类器的分类概率进行加权的这两种方法各自的有效性,本文选取4种基础机器学习分类器中取得最好效果的KNN分类器来另外设计了两组对比实验:只加入情感词汇(简称EL)和只加入互信息进行加权(简称MI),其实验结果见表8。
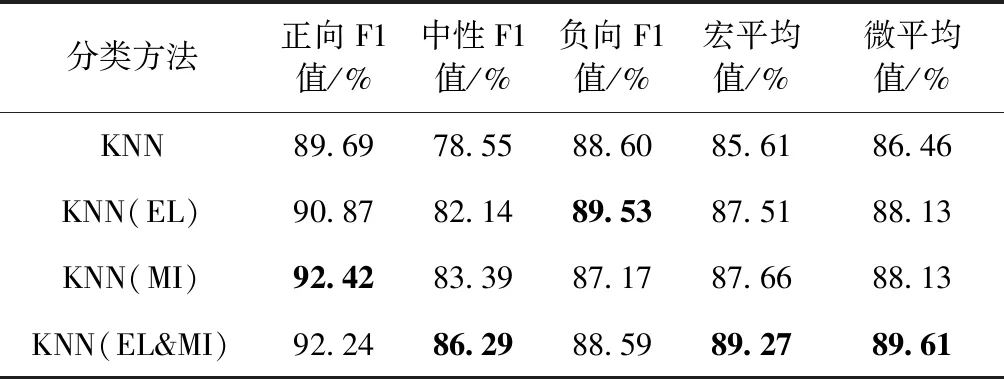
表8 KNN上分别加入EL和MI的分类结果
从表8中的实验结果可以看出,3种改进方法都提升了正向和中性情感的分类效果,加入情感词汇的方法KNN(EL)使负向情感分类的F1值提高了0.93%;方法KNN(EL)和KNN(MI)与KNN相比,在宏平均值上分别提升了1.9%和2.05%,而同时加入EL和MI之后,KNN(EL&MI)的宏平均值相比于KNN提高了3.66%,微平均值提高了3.15%。以上结果表明了本文方法对提升评价搭配情感分类性能的有效性。
4 结束语
本文提出一种基于情感词汇与机器学习的方法进行方面级情感分类,首先通过选取少量情感倾向不受评价对象影响的正向、中性和负向情感词汇,对于匹配到情感词汇的评价短语直接判断情感倾向,否则通过计算每个词的互信息得到评价短语的总互信息,然后利用总互信息值中各类别的占比来对基础的机器学习分类器得到的各类别分类概率进行加权,再选择加权后概率最大的类别作为该评价搭配的情感倾向,以此得到评论语句中每个评价搭配的情感类别,实验结果表明了本文方法的有效性。
近年来,深度学习技术在计算机视觉、自然语言处理等诸多领域内不断取得新的进展,越来越多的研究者开始应用长短时记忆网络、门限神经网络、递归神经网络、注意力机制等深度学习方法来构建方面级情感分类模型。因此,下一步工作中,将考虑利用更多的评价搭配上下文信息以及情感知识,构建深度学习模型来进一步提升方面级情感分类性能。
