大权值抑制策略用于训练卷积神经网络
2020-01-17范纯龙何宇峰王翼新
范纯龙,何宇峰,王翼新
沈阳航空航天大学 计算机学院,沈阳110136
1 引言
近年来,随着与深度学习相关技术的不断成熟和发展,计算机视觉[1-3]领域方面的相关研究和应用也得到了巨大的提升。卷积神经网络(Convolutional Neural Network,CNN)因其在图像分类和特征提取等方面相较于其他神经网络具有独特的优势,所以在学术界和工业界都受到了广泛的关注。
CNN 作为深度学习领域中的重要研究方向,目前众多学者和研究人员已经提出了多种基于CNN 的模型,如Lecun等提出用于手写字符识别和图像分类领域的LeNet[4]、Krizhevsky 等提出在2012 年大型图像数据库ImageNet[5]的图像分类竞赛中获得冠军的AlexNet[6]、Google 提出的2014 年ILSVRC 挑战赛冠军GoogleNet[7]以及微软提出的2015 年ImageNet 图像分类竞赛冠军ResNet[1]等等。
CNN模型有比传统神经网络更好的特征学习和表达能力,但其缺点在于CNN 提取的训练数据特征容易受噪声影响,会出现学习模型在训练过程中参数过度拟合训练数据集的现象,从而导致在测试数据集上损失函数不收敛,进而影响了模型在测试数据集的泛化能力。训练数据特征中隐藏的噪声对于结果的影响程度往往与训练方法、目标函数等密切相关。
为降低这些噪声的影响,研究了连接权值对网络性能的影响,通过对比不同的训练过程和训练结果,验证了CNN模型参数存在较大的冗余性,发现CNN连接权值大小对模型性能的贡献存在很大差异,权值越大的连接对模型性能的影响也越大。据此,提出了一种基于CNN大权值抑制(Weight Restrain of CNN,WR-CNN)的训练优化方法。在训练过程中抑制大权值连接的增长速度,控制连接权值分布,降低个别大权值连接对模型的负面影响,分散单独的较大权值对训练结果的影响,提升CNN模型的鲁棒性和泛化能力。另外,本文的训练方法还可以对已训练好的模型进行再优化,进一步提升模型的泛化能力和鲁棒性。
在CIFAR-10和CIFAR-100数据集对LeNet和AlexNet网络应用WR-CNN 方法训练,结果表明经过WR-CNN方法训练后,模型的泛化能力和鲁棒性得到普遍提升,Top1错误率下降1.8%~5.0%。
2 相关工作
CNN 基本训练过程中,首先通过训练样本计算当前网络模型下的误差或目标函数,然后利用反向传播算法逐层从后向前更新多层网络的连接参数权值,参数调整策略一般采用梯度下降方法,如此经过多次迭代,直到获得相对稳定CNN 模型。因为CNN 模型的参数数量多、迭代计算量大使训练成本较高且容易产生过拟合,所以相关学者从噪声抑制、网络设计和训练策略等方面提出多种优化方法[8-9]。
Krizhevsky和Wan分别提出Dropout[10]和DropConnect[11]方法,通过随机丢弃网络中的卷积核或连接参数,减少卷积核间的互相依赖,在提高网络准确率的同时,也使网络更具鲁棒性。但这些训练方法,在随机删除卷积核或连接参数的时候,没有考虑删除内容对模型结果的正面或负面影响,删除过程缺乏对删除内容必要的选择机制和策略,这样的删除过程主要通过增加卷积核或连接参数之间的独立性,可理解为将大网络训练转化为多个小规模网络训练,以达到抑制大网络公共噪声和过拟合的目的。
2016 年Iandola 等人提出SqueezeNet[12],通过设计网络结构和采用模型压缩技术,将网络参数数量减少到AlexNet 的1/50,而精确度基本与AlexNet 相近。SqueezeNet选用的网络结构,其参数数量较常规网络大幅减少,其寻求的网络设计不是为了获取最优识别结果,而是在网络设计和识别结果之间的一种平衡,另外,模型压缩技术在小模型上又进一步通过降低精度减小模型规模。Han等人提出DSD[13]训练方法,通过删除网络中小绝对值的连接参数提升网络稀疏性,再通过重新训练提升精度,是从优化参数训练方法的角度改进训练结果。这些方法为降低网络复杂性提供方案,同时也证实了CNN 网络中连接参数具有较大的冗余性,即对于常规CNN网络模型,存在冗余度更低的替代模型,但直接简化网络结构或批量删除连接参数,对网络训练效果带来较大的不确定性,并且对删除连接参数后训练效果改善的原因没有深入说明。
3 CNN大权值抑制优化训练
3.1 算法思想
针对现有方法的不足,主要在优化连接参数的更新策略方面改进网络训练方法。网络中的不同连接参数对于网络性能的影响也各不相同,采取了两组实验方案检测连接权值的绝对值大小对网络性能的影响。(1)选择删除网络中4%的连接参数,具体过程是选择训练好的CNN 模型,然后在各层内依据连接权值绝对值的大小对连接进行排序,接着从低到高依次删除4%的连接参数,测试集错误率作为网络性能变化的指标。实验数据集为CIFAR-10和CIFAR-100,选择基准网络为LeNet,实验重复三次后取平均结果,实验结果如图1(a)所示。(2)采用大端剪枝和小端剪枝对网络性能进行测试,从而探寻不同连接的贡献度。大端剪枝是指删除网络中绝对值最大的部分连接;小端剪枝是指删除网络中绝对值最小的部分连接。实验中,分批删除了LeNet中的不同连接,即首先删除网络中绝对值较大或较小前5%的连接,随后将删除比例逐渐增长至40%得到不同的网络,接着观察不同模型对于测试集的错误率来比较不同连接的贡献度,实验结果如图1(b)所示。
从错误率变化情况可以看出,删除连接会造成错误率上升,且这种影响呈现清晰的特点,删除权值绝对值越大的连接对错误率增高的影响越大。当删除绝对值最小的4%连接,两个测试集上的错误率基本没有变化,但删除绝对值最大的4%连接,CIFAR-10 和CIFAR-100测试集的Top1错误率分别迅速提升至70%和90%。这说明删除连接会影响错误率,但因为权值绝对值大的连接对网络性能影响过大,所以通过逐步删除大绝对值连接调整其影响的方法是不可行的。因此采用对大绝对值连接在反向传播过程中权值增大的幅度进行抑制的策略,达到由更多的连接权值决定CNN模型性能,而不是高度地集中在极少数大绝对值连接上,进而抑制某些强噪声干扰,提高网络性能。
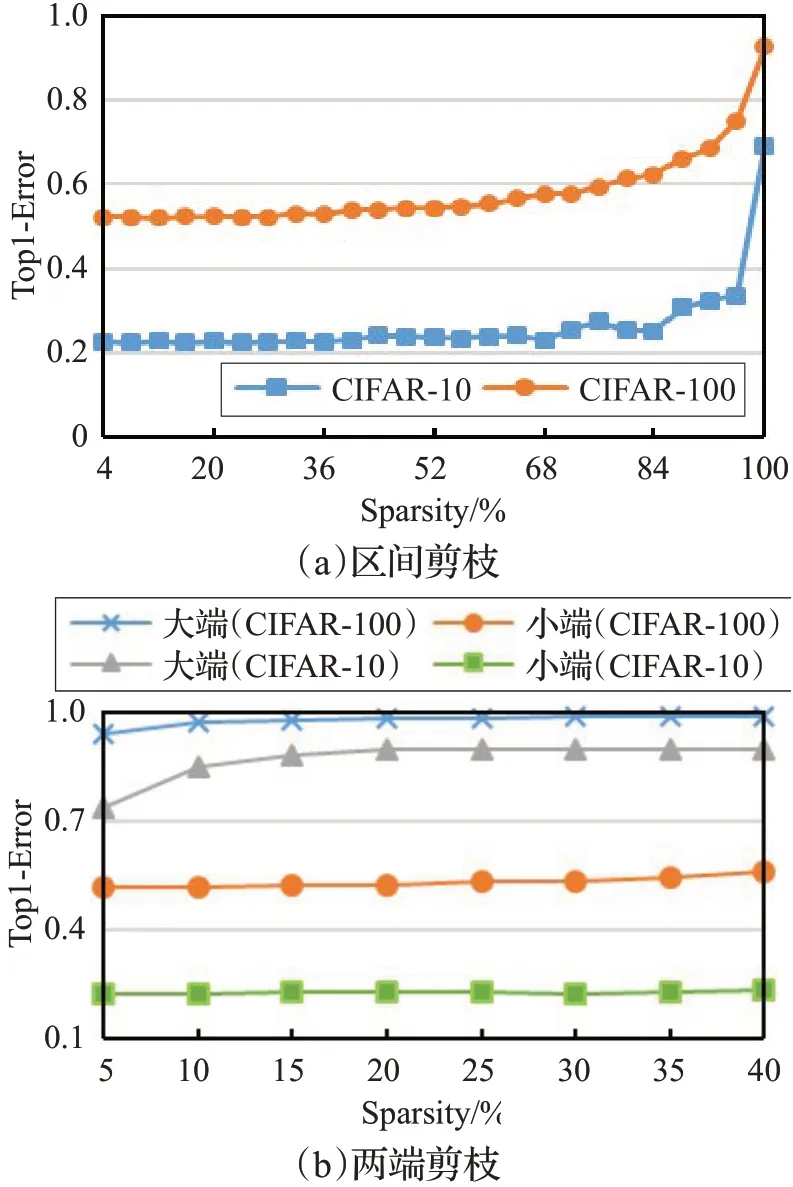
图1 在LeNet上删除不同连接
基于上述分析,提出CNN 大权值抑制策略(Weight Restrain of CNN,WR-CNN)训练方法。WR-CNN方法针对传统训练过程中的权值更新部分进行优化,在经过一定次数的训练后,每次反向传播过程中进行连接权值调整时,根据连接权值的绝对值从小到大排序,然后根据给定需要抑制的绝对值大的连接比例(抑制率)选择待抑制连接,并通过让这些连接的梯度值与一个小于1的抑制系数相乘来达到抑制连接更新幅度的目标。WR-CNN优化训练方法通过抑制对网络性能影响较大的连接权值变化速度来增加较大影响力连接数量,可以有效增强网络的泛化能力和鲁棒性。
3.2 算法分析
绝对值较大的连接权值使网络能够更好地支持样本数据,同时也限制了其他较小连接权值对于网络性能的贡献。WR-CNN方法通过控制绝对值较大的连接权值更新幅度,使网络中的权值参数趋于均衡,提升参与决策的参数权值数量,从而提高模型的泛化能力和鲁棒性。
抑制操作是对网络中贡献度较大连接(记为wb)的权值更新幅度加以控制,即对反向传播过程中计算出的Δw 乘以抑制系数p(0 <p <1),其中p 与连接的贡献度成反比,即贡献度越大的连接,权值更新幅度越小。设抑制方式为线性抑制,网络中最大连接权值为wmax,λ为线性抑制率(λ >1),则:

反向传播算法中网络参数的迭代调整普遍采用随机梯度下降法,该方法中参数的更新方向是网络对多个样本损失值的平均梯度方向,而非最优调整方向,这使网络容易被某些特定的样本影响。抑制对网络性能贡献度较大的连接权值的增长速度会使网络参数更趋于平均,同时使网络损失值E 的变化更加稳定,避免网络向某一参数的梯度方向大幅调整,提高了网络的鲁棒性和泛化能力。
算法1 WR-CNN算法的工作流程如下所示:
输入:训练集D;抑制率r
输出:连接值确定的神经网络模型
1. w(0)~N(0,1) /*随机初始化网络中所有连接*/
2. While 网络不收敛do
3. Δw=∂E/∂w /*计算神经元的梯度值*/
4. Sort(w) /*根据贡献度对连接进行排序*/
5. f(wb)=wb+Δw·p /*根据r 抑制贡献度较大神经元的更新速率*/
6. end
另外,针对已经用传统方法训练好的CNN模型,可以利用WR-CNN方法对上述模型进行再优化训练。首先,对于一个已经用传统方法训练完成的CNN 模型A进行大权值压缩处理。设计了一个大权值压缩函数,用于将模型A 中的绝对值较大的连接权值压缩到绝对值较小的连接权值区间中。记模型A 中绝对值较大的连接权值为wb,其中绝对值最大的连接权值为wmax,需要压缩的较大连接权值区间中最小的连接权值为wm,则大权值压缩函数如下:

由上式可知连接权值的绝对值大于wm的这部分连接权值都将被压缩到wm值以下,并且绝对值越大的连接权值被压缩的比例越大。模型A 经过大权值压缩处理后得到模型B,模型B中的连接权值将会集中分布在较小区间,连接权值的影响被强制趋于均衡。然后将模型B 作为初始化的输入网络,运用WR-CNN 方法进行优化训练适当的轮数(一般在20 轮以内),最后将得到再优化的目标网络模型C,通过实验表明模型C相较于模型A的泛化能力和鲁棒性都得到了明显的提升。
4 实验结果与分析
为验证WR-CNN 方法的有效性,使用基于Matlab平台的MatConvNet[14]工具包,在LeNet 和AlexNet 模型上对CIFAR-10、CIFAR-100以及SVHN数据集进行了多次实验。首先,将WR-CNN 方法与Dropout、DSD 方法进行了综合对比,其中DSD方法的稀疏率采用文献[13]中对于多种卷积神经网络的推荐设置值30%,具体实验结果见表1。
由表1 数据可知DSD 方法对于网络模型性能的提升效果不如WR-CNN优化方法明显。DSD方法在LeNet上对于CIFAR-10 的提升效果为4.22%,而WR-CNN 方法的提升效果为5.02%。而且该方法中稠密训练步骤使网络中的参数数量与原模型相同,即并未减少训练网络所需成本。WR-CNN方法对网络性能的提升程度明显优于其他优化方法,在同等级的训练数据集情况下,测试集的准确率进一步得到了提升,说明该优化方法增强了模型的泛化能力。
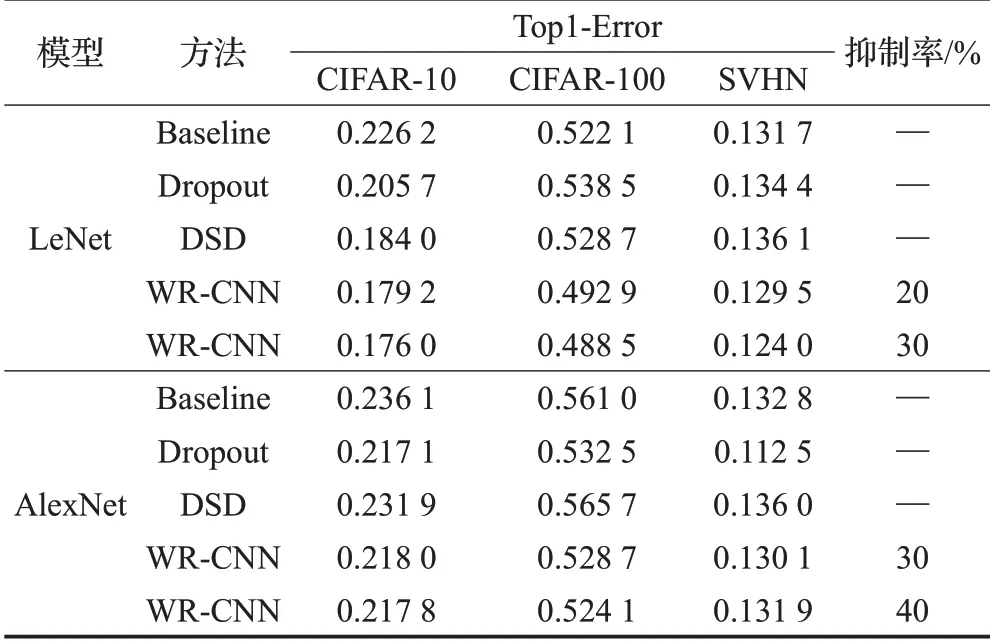
表1 CIFAR和SVHN数据集实验结果
其次,将WR-CNN方法的抑制率设置为30%,观察了不同稀疏率下多种优化方法的Top1 错误率,Dropout方法中,对于CIFAR-10和CIFAR-100数据集,当稀疏率大于50%,其识别效果较差,故不在图中展现,具体结果见图2、图3。

图2 不同方法下AlexNet错误率对比(CIFAR-10)
结合图2、图3 可以看出,Dropout 方法对于网络性能的影响与稀疏度密切相关。对于CIFAR-10 数据集,当AlexNet 稀疏率大于50%,网络的识别错误率开始出现明显的上升;对于CIFAR-100 数据集,当稀疏率大于30%之后,网络性能就受到了明显的影响。而WR-CNN方法对稀疏率的敏感性明显要低于其他方法,同时保持了较好的准确率。这说明用WR-CNN方法优化训练好的网络模型具有很强的鲁棒性。

图3 不同方法下AlexNet错误率对比(CIFAR-100)
然后,测试了上述几种优化方法训练好的网络模型的鲁棒性。将这些模型删去部分大权值后在CIFAR-10数据集上的Top1错误率变化。具体结果见图4。
图4所示的结果再次验证了本文的分析,用传统训练方法训练好的网络模型,其性能很大程度上依赖于网络中少量的大权值连接参数。图4中直观地显示出仅仅删除了0.4%左右的大权值连接参数,其网络性能就会急剧下降,Top1错误率接近未删除大权值连接参数前的一倍,达到40%左右,体现了传统训练方法训练好的网络模型鲁棒性较弱的特点。用Dropout方法优化训练好的网络模型在删除了1.3%左右的大权值连接参数时,Top1错误率才达到40%左右,说明该方法对于分散网络模型中大权值连接参数的贡献起到了作用,其优化训练好的网络模型鲁棒性也得到了增强。而WR-CNN方法优化训练好的网络模型直到删除了约2.3%的大权值连接参数,其Top1错误率才达到了40%,可见通过WR-CNN方法对于分散网络模型大权值连接参数作用的能力明显要高于其他方法,进一步增强了网络模型的鲁棒性。
最后,在CIFAR-10 数据集上实现了对已经训练好的LeNet 使用WR-CNN 方法再次优化训练。该模型进行权值压缩前的权值分布如图5(a)所示,压缩后的权值分布如图5(b)所示。对比两图中的权值分布可以发现,在经过压缩前的LeNet 少部分大权值绝对值分布在0.2左右,而在经过前述压缩函数进行压缩后,这部分大权值绝对值被压缩到了0.05左右。经过17轮再优化训练后的网络模型在测试集上Top1 错误率达到了17.45%,进一步增强了模型的泛化能力,验证了WR-CNN 方法对于已训练好的CNN模型再优化能力。
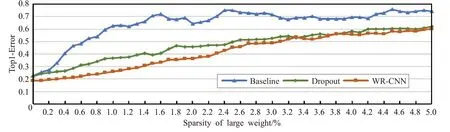
图4 在LeNet上删去大权值连接后的错误率变化(CIFAR-10)

图5 LeNet对权值压缩前后的权值分布
优化深度神经网络模型的难点之一在于鞍点的扩散[15],WR-CNN方法通过对大权值连接参数更新策略的调整,打破隐藏层中神经元的对称结构,使神经元不依赖于其他特定神经元,在网络的优化过程中摆脱局部最小值,跳离鞍点并收敛于全局最小值。网络训练过程中分散大权值作用的思想将网络的优化转移到对噪声更具鲁棒性的低维空间,从而减小方差并降低网络的错误率。权值绝对值较大的连接体现了网络的整体需求,但它们限制了剩余权值绝对值较小的连接对于网络的影响,最终使网络依赖于少量参数。其过快的变化速率打破了初始化时的参数分布[16],破坏了网络训练的平衡性和稳定性。因为抑制操作只增加一个超参数(抑制系数)用于调整权值更新策略,并没有增加反向传播过程中的计算资源,所以WR-CNN 方法对于网络的训练效率并没有明显降低。
5 总结
本文提出了针对卷积神经网络训练过程的WR-CNN优化训练方法,WR-CNN 方法通过对网络中贡献度较高连接的权值更新幅度进行限制,最终提高了网络的准确率,抑制训练过程中过拟合现象的产生,优化了传统卷积神经网络的训练过程。综合多项实验结果,WR-CNN方法对于CIFAR-10和CIFAR-100数据集,在LeNet模型上的Top1 精度分别提升5.02%和3.36%,在AlexNet 分别提升1.81%和3.69%。实验结果表明了传统训练方法的不足,验证了现有卷积神经网络模型中广泛存在泛化能力弱和鲁棒性不足的事实。WR-CNN优化训练方法可以将网络模型的大权值连接参数作用分散到较小权值连接参数上,使网络降低对于极少数大权值连接参数的依赖,增强了网络的泛化能力和鲁棒性。
