基于深度学习的视频编码单元选择算法研究
2020-01-16温洁杨帆潘旭冉王晓宇范海瑞
温洁 杨帆 潘旭冉 王晓宇 范海瑞
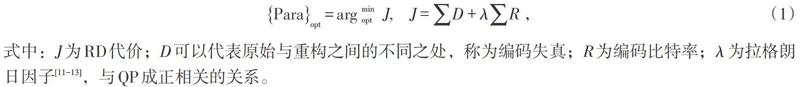
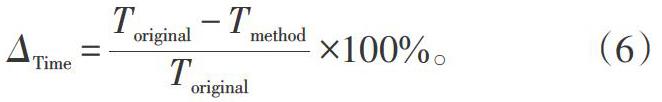
摘要 新一代视频编码标准VP9与上一代标准VP8相比性能提升了近1倍,且它的开源特性使得其在视频编码领域取得了广泛应用,但是编码性能提高的同时带来了编码复杂度的增加,从而对一些实时的视频应用产生很大影响。因此本文通过对编码单元模式划分复杂度过高问题的影响因素进行分析,提出基于深度学习的视频编码单元选择算法,该算法首先选择对编码复杂度很高的块划分进行研究,主要针对超级块划分模式的选择进行了优化。应用深度学习中的全连接神经网络模型作为划分模型,输入特征向量为36个,输出是具体的块划分模式,训练方式选择离线训练。其次,为了进一步的简化模型结构同时提升分类器的性能,将对复杂度很高的四叉树递归划分方式进行优化,并根据具体的量化参数(QP)值和块大小得到不同的结构,以便得到1个4层二分类模型。最后,通过对不同复杂视频图像应用简化版的四叉树进行测试,测试结果与原四叉树递归算法相比编码复杂度降低很多,编码复杂度平均降低比例高达77.84%,编码效率得到了很大的提升。
关 键 词 视频图像编码;VP9;编码单元划分;深度学习;SAD值
中图分类号 TN919.81 文献标志码 A
Abstract The performance of the new generation video coding standard VP9 is nearly double that of the previous generation VP8, and its open source characteristics make it widely used in the field of video coding. However, the improvement of coding performance brings about an increase in coding complexity, which has a great impact on some real-time video applications. Therefore, this paper proposes a video coding unit selection algorithm based on deep learning after analyzing the influencing factors of the problem of excessively high coding unit mode partitioning. The algorithm selects the block partition with high coding complexity, mainly for super block partitioning. The choice of mode is optimized. The fully connected neural network model in deep learning is applied as the partition model, and the input feature vector is 36. The output is a specific block partition mode, and the training mode selects offline training. Secondly, in order to further simplify the model structure and improve the performance of the classifier, the recursive partitioning method of the highly complex quadtree is optimized, and different structures are obtained according to the specific QP value and block size, so as to obtain a four-layer-two-classification model. Finally, by applying a simplified version of the quadtree to different complex video images, the test results are much simpler than the original quadtree recursive algorithm. The average coding complexity is reduced by 77.84%, and the coding efficiency has been greatly improved.
Key words video image coding; VP9; coding unit partition; deep learning; SAD value
0 引言
VP9[1-3]是Google针对上一代视频编码标准VP8[4]进行优化新推出的新一代编码标准,主要涉及的改进技术包括:引入超大块概念可对更大的编码区域进行处理;对一些参考帧采用了动态的方式进行选择;对熵编码也进行了相关的优化等。这些新技术确实带来了压缩效率的提高,但也引入了其他的问题,比如超级块技术的引入,可以在同等质量的视频下,降低近一半的码率,但是会出现编码复杂度的大幅度提高的现象,这种编码性能的提高以编码复杂度为代价的方式,使其在实时的编码应用场景下效果不太理想。针对上述问题已有大量的研究文献出现,文献[5]提出了编码单元模式判别与预测单元(PU)模式判别的优化算法,利用了率失真(RD)代价相关度、空域相近塊与父块之间的预测模式相关度来获取当前块的划分方式。文献[6]提出了利用父块和子块之间RD代价的差异性来进行判断是否进行四叉树递归划分的终止动作。文献[7]利用了SVM作为分类器进行模式划分的预测,对RD代价性能的影响进行了考量。文献[8]利用了聚类算法进行帧间模式预测,输入主要涉及时空域、相关的RD代价值。上述算法优化基本上采用的方式是机器学习加上RD代价及时空域相关性的方式,这类优化方式可以对简单的视频内容进行很高效的处理,误判率也很低,但是存在的问题主要是,对于视频内容多变且编码复杂结构多的情况,编码效率下降很严重,误判率也增加很多。
综上,本文采用的优化方式是通过对编码单元模式划分复杂度过高问题的影响因素进行分析,选择编码复杂度很高的块划分进行研究,主要针对超级块划分模式的选择进行了优化。本文应用深度学习中的全连接神经网络模型作为划分模型,输入特征向量为36个,输出是具体的块划分模式,训练方式选择离线训练。为了进一步的简化模型结构同时提升分类器的性能,本文将对复杂度很高的四叉树递归划分方式进行优化,并根据具体的量化参数(QP)值和块大小来得到不同的结构,最终可以得到1个三层二分类模型。最终通过对不同复杂视频图像应用简化版的四叉树进行测试,测试结果与原四叉树递归算法相比编码复杂度降低很多,编码效率得到了很大的提升。
1 编码块特征向量提取
1.1 编码单元模式划分影响因素分析
在分类任务中,特征工程是影响分类结果非常重要的因素。所以首先需要对编码单元模式划分影响因素进行分析。VP9是针对率失真优化(RDO)[9-10]理论进行编码块选择优化的,块的大小有很多,主要针对大于8×8的块大小,对于每个块应用划分及不划分两种模式的率失真代价来选择每个编码块的划分模式。具体的率失真优化({Para}opt)求取公式如式(1)所示。
式中:J为RD代价;D可以代表原始与重构之间的不同之处,称为编码失真;R为编码比特率;λ为拉格朗日因子[11-13],与QP成正相关的关系。
由式(1)可以看出率失真代价的计算是很复杂的过程,但是根据不同的视频内容可以找到基于RDO块划分的规律性。一般规律为:对于色彩单一、条纹简单的图像块主要采用大块方式划分,而对于色彩复杂、条纹丰富的图像块则主要采用小块的划分方式;同理对于含有运动信息的图像块主要采用小块划分方式,纯背景或不含运动信息的图像块则主要采用大块划分的方式等。
除了上述视频本身的特性外,如图1所示,采用不同量化参数(QP)进行编码所得划分深度分布图。由图1可得,QP与最终的编码块划分成正相关的关系。
综上所述,编码参数及视频内容特性与编码块划分模式有很大的相关度,这里编码参数主要考虑影响因素较大的QP,视频内容特性主要涉及条纹、色彩复杂度及时空域信息等。因此,编码参数及视频内容特性是在后续特征工程中要充分考虑的两个影响因素。
1.2 输入特征向量的选择和提取
本文主要的目的就是对编码块递归划分的过程进行优化,优化的同时还要保证原编码的性能。对于一个M[×]N的图像区域块,残差信号绝对值之和(SAD)的公式如式(2)所示,其中SAD主要是对运动图像进行估计的,用来衡量残差时域的差异性。
一般纹理简单或运动较小的图像序列精确匹配更容易,对应的SAD值会偏小一些;相反的,则精确匹配变得复杂一些,相应的SAD值会偏大一些。因此,本文采用前一帧在9个不同点的SAD值及当前待编码帧中的4个子块作为特征向量。如图2所示,选取的9个搜索点及相应子块的位置分布图。其中,9个点是等间隔分布的,每两个点相距2个像素的距离,图中最中心的点表示当前子块在上一帧中的对应位置。
从图2可以看出中心位置点及对应该点的9个方向是用9个搜索点来表示的,所以1个图像区块在9个搜索点的SAD在某种程度上可以代表区块的运动趋势。然后选取1个区块中的4个子块来分析当前区块的运动趋势,如图3所示,a)为不含局部运动的区块对应其中的4个子块的SAD变化曲线图,b)为含局部运动趋势的区块对应其中的4个子块的SAD变化曲线图。
由图3可以看出,9个搜索点由于纹理复杂度的差异性,不同点的SAD值变化很大,但是同1个子块的SAD值的变化趋势基本是一致的。含有运动信息的4个子块之间的差异还是很清晰的。所以可以用不同子块的SAD值来表示含有运动信息的视频图像。
综上所述,本文选取36个SAD值(4个子块,每个9点SAD值)来作为全连接网络的特征进行输入,这样对视频区域块的可区分度较高。
2 样本的预处理
由于神经网络的各个节点的权值是通过训练得到的,为了缩短训练时间,提高分类器的预测准确率,本文会选用典型的样本进行网络的训练,所以就要在离线训练前进行训练样本的筛选。
本网络输入为36个SAD值,输出为编码块划分模式,对于分类器结果好坏一般采用预判准确率来判断网络性能的优劣,但是对于本文的应用还需要考虑判别结果与RDCOST性能之间的关联。比如:4个子块与其父块的RDCOST值差异很小时,则划分模式误判决的影响结果较小;但是当差异较大时,一旦出现误判决,则对RDCOST性能影响很大。所以训练网络时就要寻找这种“典型的样本”,即:特征值与划分模式之间的映射关系。对于划分与不划分RDCOST差异较小的样本称为“奇异样本”,反之称为“典型样本”。我们选择样本就是要选择典型样本,去掉奇异样本。对于划分与不划分RDCOST差异[ΔRDCOST]是否显著的衡量公式为
式中,[Rspilt]和[Rnonsplit]分别表示划分与不划分的率失真代价。这样在进行典型样本的选择时,当[ΔRDCOST]大于1个给定的阈值时,则该样本被挑选出来,不同的阈值对应的网络泛化能力的实验结果是不同的,通过大量的实验得出,阈值取值大概为0.012时,测试准确率处于最高点位置附近。典型样本筛选完成后,还要选择样本的数量,太多则训练时间过长同时容易出现过拟合;反之,则容易出现欠拟合的问题。本实验选择400 000個样本集合,同时划分与不划分模式样本各占50%。
3 全连接网络模型及设计
人工神经网络(ANN)[14-15]是对人类大脑神经元系统建立的一种数学模型,具有强大的自学习及非线性拟合能力。对于全连接网络模型,即BP神经网络,在1985年被Rumelhart等[16]提出。
其中,神经元数学模型如式(4)所示。其中XW是对输入和权重的向量表示形式,[f(x)]为激活函数。一般的全连接网络层级分为输入、输出及隐含层,当隐含层层数增加到一定数目时即为深度学习。
本文的分类过程属于监督式学习,采用的思想是通过对比预测输出与实际输出的值,来不断优化网络,缩小最终的错误代价函数,最终训练出合适的网络参数。全连接网络的参数迭代过程包括正向和反向两个过程。一般在初始时,给各个权重1个初始值,然后正向逐层的计算,一直到输出结果,这个过程没有参数修正的过程,然后反向由输出层到输入层的过程应用BP算法[17-19]进行权重的修正。这样不断的迭代最终得到合适的网络参数值。这里面主要要考虑的影响训练时间及结果的关键点包括:网络初始权值的设定,激活函数的选择,误差损失函数的选择和学习步长[η]的选取等。
模型结构的建立主要涉及网络结构的搭建及神经元参数的给定2个部分。其中网络拓扑结构的建立主要是神经元个数的确定和网络层数的设计;神经元相关属性设定则为上面所叙述的关键点。实际建模的过程主要是根据具体的问题,通过经验和实验来确定的。由于本实验应用MATLAB开发工具进行训练,全连接网络训练采用的是开源库代码Deeplearning来实现,这样很多初始化参数,如权值的初始化值已经给定。因此,下面仅对网络建模过程中需要设定的相关参数进行说明。
3.1 网络节点及层数设计
网络节点个数及网络层数的设计是和具体任务紧密相关的,由于网络的输入特征是36个,所以网络的输入层节点数为36。网络的功能是判断是否划分为该类型编码单元,所以网络的输出节点数为2。为了更充分地提取输入特征,本文使用2个隐藏层的BP神经网络。因为增加网络的深度比增加网络的广度对特征提取的贡献更大,使得深度学习在多种图像处理任务中取得显著优势。但增加网络深度会增加计算量,层数不能增加太多,因此,这里选择包含两个隐藏层的4层BP神经网络。由于输入特征和输出特征数量相差较大,设计神经网络每层的神经元个数逐步减小,用于逐步提取更准确的特征。经过多次测试选择最终的网络节点数,表1列举了最终测试中几对不同隐藏层神经元个数的性能。
表1测试了几种常见隐层节点数的性能,通常情况下隐层1的节点数要比隐层2的节点数多,隐层1的节点用于提取输入节点中的特征,隐层2的节点用于判别结果,经过试验,最优的隐藏层节点配置为:隐层1节点数为18,隐层2节点数为8。
3.2 网络及神经元几个关键点的确定
本文采用全连接网络结构,由于输出结果为0到1,所以激活函数选择常用的单极性的sigmoid函数;学习步长[η]代表的是权值的修正步长,[η]过大则网络训练不易收敛;[η]过小则网络收敛速度很慢,训练时间过长,一般为了得到稳定的结果会选择0.03~0.75之间偏小一点的[η]值。在实践中一般根据学习的情况来随时调整学习步长,最终选择1个合适的学习步长来训练出网络权值;本实验误差损失函数选择均方误差损失函数;动量因子[α]和学习步长一样都需要根据实验情况,实践中去最终确定,最终[α]确定的区间为0.06~0.22;迭代次数就是网络中权重的更新次数,一般的迭代次数与测试准确率之间的关系为:一开始网络迭代次数小于某个限定值时,网络处于欠拟合状态,最终的测试准确度很低,随着迭代次数的增加,测试准确率达到最高,这时的网络权值时最优的权值结果,之后测试准确率开始下降,网络出现过拟合,所以需要根据具体的问题设置合适的迭代次数,这样网络性能才能达到最优,本实验通过测试,本实验的迭代次数通常确定在3 500到5 200之间。
4 基于全连接网络的编码单元模式选择优化
4.1 编码模型的简化
VP9支持的编码块大小有4种,包括:8[×]8、16[×]16、32[×]32和64[×]64,这导致最终需要预测的结果有83 522种。所以使用正常的分类器模式进行划分是不符合需求的。因此,本文采用的是如图4所示的优化模型,即:超级块划分全连接网络分类器的分布图,建立1个3层二分类模型,这样可以取代原来复杂的四叉树模型。图4中的分类器递归为3层,对于不同的64[×]64、32[×]32和16[×]16层分类器个数分别为1个,4个和16个。因此,分类递归过程分别进行1次,4次和16次的判决。把三层划分深度(cuDepth)从0到2进行编号,每层的命名如图4所示。最后,对所有不同的分类器输出结果进行整合即可得到超级块的1组预判决划分模式。具体编码过程的流程如图5所示。描述过程是逐层的对当前块是否划分进行标记,划分则对4个子块进行標记,然后进行预判决处理;不划分则对当前块进行标记,停止对4个子块进行进一步的预判决。这样就可以应用简化后的四叉树来进行编码处理。
4.2 编码单元划分结果预测
根据上述的理论分析方法,各个网络模型的输入、输出向量及模型结构几乎都一致,也就是输入、输出向量分别为36和2,最优的隐藏层节点配置为:隐层1节点数为18,隐层2节点数为8。实验中为进一步简化网络模型结构,通过设置不同的QP值得到不同的模型结构。
各层分类器进行模式分类的过程主要为3步骤:1)进行典型样本的筛选,然后分为测试样本和训练样本;2)应用离线的方式训练出各层的网络模型并进行简单测试;3)将训练后的网络模型移植到编码器,然后对各个块划分模型进行预测。具体的编码单元划分模式预判决算法各处理模块流程图如图6所示。
5 实验结果与分析
对于一个算法性能的评估,需要选择合适的评估方式及参数进行评估,本实验根据实际的需求情况,选择从算法的预判决准确率及对编码复杂度和编码性能影响等方面对本实验算法进行评估。本实验不使用BPNN进行预测,都是以原始编码算法的结果进行评估的。全连接网络的训练和测试都是采用MATLAB工具进行的,视频编码VP9使用的软件版本号是libvpx-v1.30。具体的主要参数设置为:Frame类型是IPPP,对应的Frame Rate为30 fps,GOP设置为200,划分深度为0到3,进行帧间预测时的参考帧数为单位帧数,对应编码块的非对称划分方式采用关闭处理的方式。
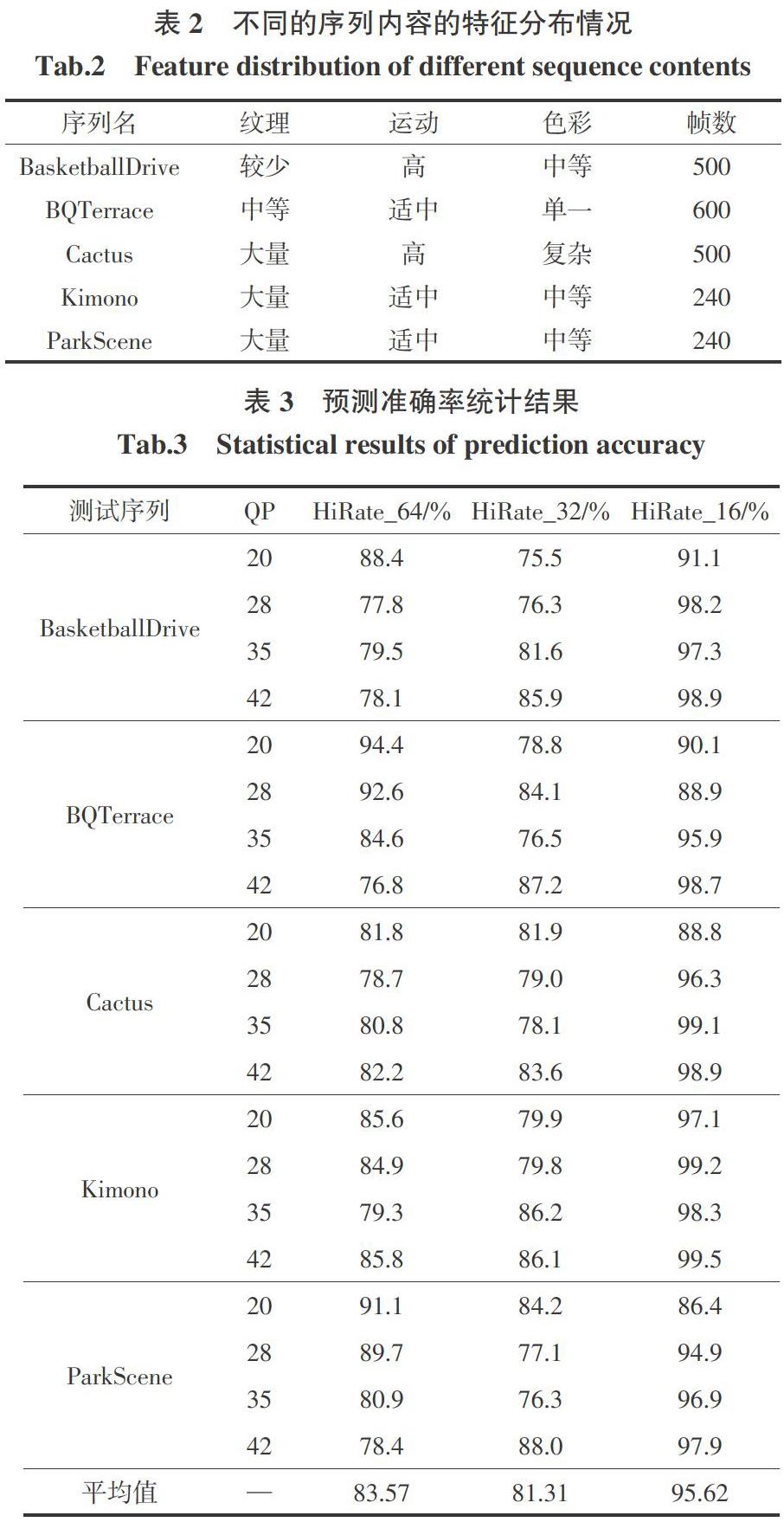
具體内容特征属性的统计情况如表2所示,其中前3个为训练样本,后2个为测试样本。从表中可以看到所选的5个1 080p序列在各自不同特征分布上的差异情况。
下面分别从各层网络命中率测试结果及优化后的算法性能测试结果进行分析。
1)各层模型结构命中率测试结果。各层模型结构命中率就是对上面3层的预判决命数进行统计,用HitRate_xx来表示,具体计算公式如式(5)所示。具体的测试结果准确率如表3所示。
HitRate = 当前层预判定模式与RDO模式相同的块个数/当前层总的块个数×100%。 (5)
2)优化后的算法性能测试结果。对于算法性能的衡量,则选用了5个参数来测试衡量,针对不同QP和序列得到的测试结果如表4所示。其中[ΔTime]计算公式如式(6)所示。式中变量分别对应原始编码器([Toriginal])和优化后算法编码器([Tmethod])的编码复杂度。
由上述测试后的统计结果如表3所示,可以看出针对不同序列、不同层的编码块,分类器进行预判后的准确率是不同的,整体预测准确率范围分布为76.3%~99.5%,3层的HitRate_xx平均命中率分别为83.57%, 81.31%和95.62%。从表4可以看出,虽然比特率([ΔBitrate]平均上升了25.01%,YUV三分量的PSNR(峰值信噪比)即:[ΔPSNR-Y],[ΔPSNR-U], [ΔPSNR-V]分别平均下降了-0.459,-0.196, -0.294(下降幅度很小),但是优化后的算法的编码复杂度得到了很大的降低,与正常编码预测相比,本文优化后模型的编码复杂度[(ΔTime)]平均降低比例高达77.84%。
由实验结果可以得出,对不同复杂视频图像应用简化版的四叉树进行测试,测试结果与原四叉树递归算法相比编码复杂度降低很多,编码效率得到了很大的提升。与之前相关的研究文献结果相比,本文针对ParkScene,Cactus等这种复杂度很高的视频图像内容进行测试,测试结果可以看出编码效率没有大幅度降低,而是得到了很大的提升。
6 结论
本文通过对编码单元模式划分复杂度过高问题的影响因素进行分析,选择编码复杂度很高的块划分进行研究,主要针对超级块划分模式的选择进行了优化。使用了基于全连接网络的编码块划分算法,将提出的算法应用到编码器中的1个预处理模块。通过最终的测试结果的对比,可以看出编码复杂度得到了很好地降低,但是当直接使用网络输出结果时,与之前相关文献出现的问题一样,就是整体的预测精度会有所降低。后续继续优化的方向是针对神经网络输出结果的规律性来对该算法进行优化处理,以此来提升预测精度。
参考文献:
[1] UHRINA M,BIENIK J,VACULIK M. Coding efficiency of VP8 and VP9 compression standards for high resolutions[C]//2016 ELEKTRO. Strbske Pleso,High Tatras,Slovakia,IEEE,2016:100-103.
[2] SRINIVASAN M. VP9 encoder and decoders for next generation online video platforms and services[C]//SMPTE 2016 Annual Technical Conference and Exhibition. Los Angeles,CA,IEEE,2016:1-14.
[3] 袁星范. 最新一代视频压缩标准VP9综述[J]. 电视技术,2016,40(5):18-21.
[4] FELLER C,WUENSCHMANN J,ROLL T,et al. The VP8 video codec-overview and comparison to H.264/AVC[C]//2011 IEEE International Conference on Consumer Electronics-Berlin (ICCE-Berlin). Berlin,Germany,IEEE,2011:57-61.
[5] SHEN L Q,ZHANG Z Y,AN P. Fast CU size decision and mode decision algorithm for HEVC intra coding[J]. IEEE Transactions on Consumer Electronics,2013,59(1):207-213.
[6] GOSWAMI K,KIM B G,JUN D S,et al. Early coding unit-splitting termination algorithm for high efficiency video coding (HEVC)[J]. ETRI Journal,2014,36(3):407-417.
[7] SHEN X L,YU L. CU splitting early termination based on weighted SVM[J]. EURASIP Journal on Image and Video Processing,2013,2013(1):4.
[8] SUNG Y H,WANG J C. Fast mode decision for H.264/AVC based on rate-distortion clustering[J]. IEEE Transactions on Multimedia,2012,14(3):693-702.
[9] SULLIVAN G J,WIEGAND T. Rate-distortion optimization for video compression[J]. IEEE Signal Processing Magazine,1998,15(6):74-90.
[10] ORTEGO A,RAMCHANDRAN K. Rate-distortion methods for image and video compression[J]. IEEE Signal Processing Magazine,1998,15(6):23-50.
[11] ORTEGA A,RAMCHANDRAN K,VETTERLI M. Optimal trellis-based buffered compression and fast approximations[J]. IEEE Transactions on Image Processing,1994,3(1):26-40.
[12] 王雙龙. 快速 AVS 帧内预测算法[J]. 计算机应用与软件,2015,32(6):185-187.
[13] 佘航飞,郁梅,蒋刚毅,等. 基于对比敏感度函数的高动态范围视频编码[J]. 光电子·激光,2018,29(10):73-80.
[14] AGATONOVIC-KUSTRIN S,BERESFORD R. Basic concepts of artificial neural network (ANN) modeling and its application in pharmaceutical research[J]. Journal of Pharmaceutical and Biomedical Analysis,2000,22(5):717-727.
[15] 李英玉,陈刚. 基于人工神经网络的RSSI测距的牛顿定位算法[J]. 仪表技术与传感器,2017(8). 1002-1841.
[16] RUMELHART D E,HINTON G E,WILLIAMS R J. Learning representations by back-propagating errors[J]. Nature,1986,323(6088):533-536.
[17] LI J,CHENG J H,SHI J Y,et al. Brief introduction of back propagation (BP) neural network algorithm and its improvement[J]. Advances in Computer Science and Information Engineering,2012:553-558.
[18] 严邓涛,霍智勇,戴伟达,等. 基于全连接神经网络和边缘感知视差传播的立体匹配算法研究[J]. 南京邮电大学学报(自然科学版),2018,38(3):83-88.
[19] WANG X G,TANG Z,TAMURA H,et al. A modified error function for the backpropagation algorithm[J]. Neurocomputing,2004,57:477-484.
[责任编辑 田 丰]
