一种统计分类方法的学习
2017-06-12辛夷
高中生学习·高三版 2017年6期
辛夷
1. 基于统计学习理论的机器学习方法
数据序列是一组按照某种顺序排列的随机数据,采用统计的方法可以有效分析数据的统计特征。机器学习方法的重要理论基础是统计学,现代人工智能是基于大量数据的机器学习理论,机器学习的主要目的是对新的样本尽可能给出精确的估计。
2.提升方法
随机猜测一个是或否的问题,将会有50%的正确率。如果一个假设能够稍微地提高猜测正确的概率,那么这个假设就是弱学习算法,如果一个假设能够显著地提高猜测正确的概率,那么这个假设就称为强学习算法。提升方法是统计学习方法中常用的一种。提升方法就是从弱学习算法出发,改变训练数据的权值分布,反复学习,得到一系列弱分类器,然后组合这些分类器,构成一个强分类器。
提升方法的基本思路:
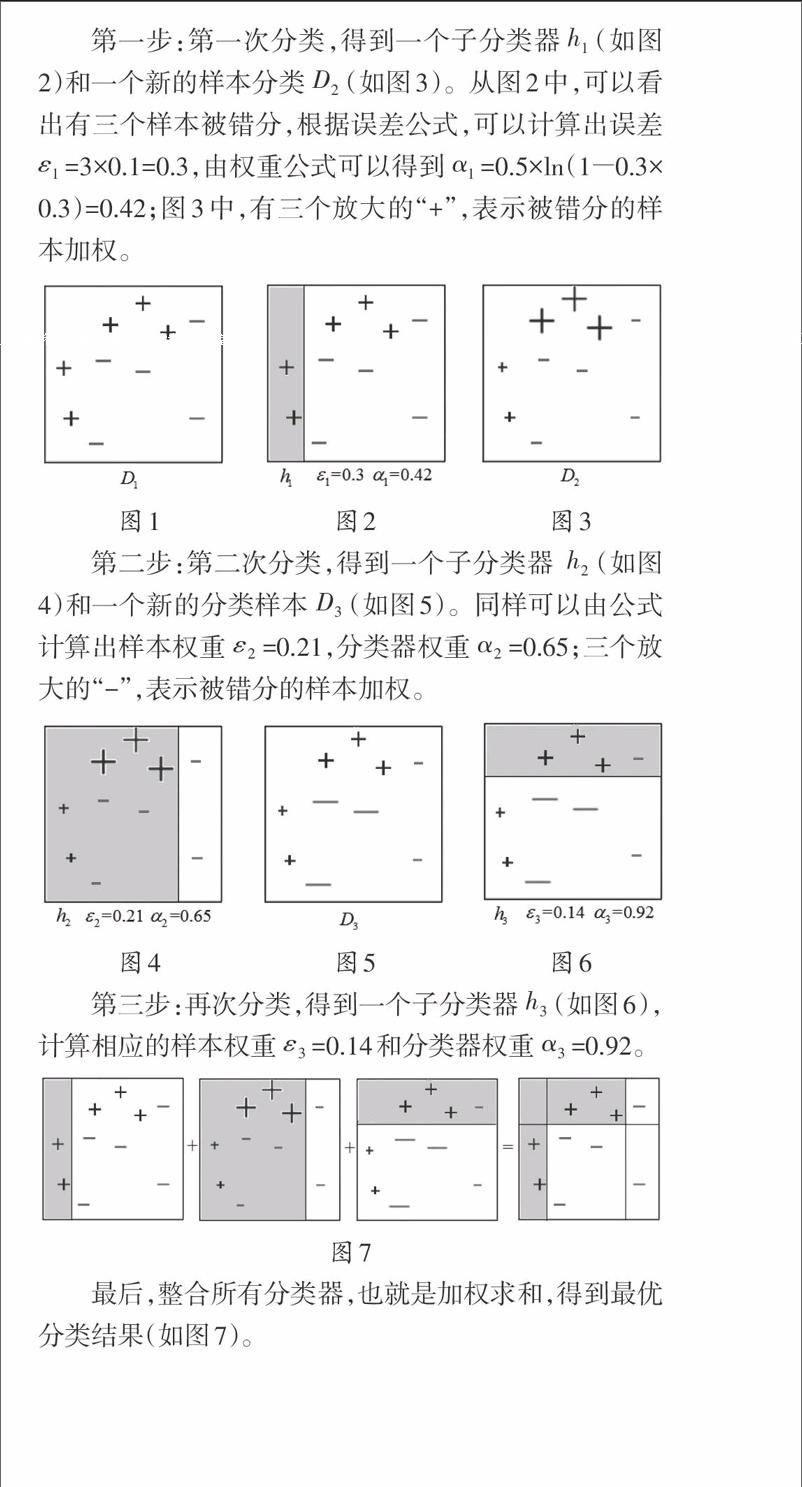
(1)刚开始训练数据中的每个样本被赋予一个相等的权重,这些权重构成分类样本[D];
(2)在训练集上训练出一个弱分类器并计算该分类器的错误率[ε],根据分类器的错误率可以计算出该分类器的权重[α=1/2ln(1-εε)];
(3)根據上一次分类器的权重调整每个训练样本的权重,分对的样本权重降低,分错的样本权重升高,然后在同一训练集上再次训练弱分类器;反复训练,直到错误率达到要求为止。
3.实例解析
假设现有“+”与“-”两种类别的数据,共10个数据点构成的数据集,我们用水平或垂直线作为分类器进行分类。初始情况下,每个样本的权重[D1](如图1)是相等的,为0.1。
<img src="http://img1.qikan.com.cn/qkimages/gzss/gzss201706/gzss20170633-1-l.jpg" alt="" />
