基于BBS-LDA的论坛主题挖掘
2020-01-15
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
如今,互联网正飞速地发展,网络已成为网民接收和传播信息的主要途径。通过网络,每个网民都可以在极短的时间内了解到全国各地最新的事件,并实时地对这些事件发表自己的感想,也可以把自己了解到的事件分享给其他人。在这种形势下,网络文本的挖掘成了如今科学研究的一大热点。如何从海量文本中提取出有价值的信息一直是一件很有挑战的事情。文本不同于一般的数值型数据,表示和处理都比较复杂。空间向量模型(Vector space model)把文本中的每个词语映射到向量空间,这使得文本可以通过传统的数值型数据挖掘算法来处理,不过对于海量数据,会面临维度灾难。TF-IDF[1]等方法利用了词的词频信息和逆文档频信息,能够快速提取文章的关键字,不过单纯以词频度量词的重要性不够全面,而且不能够处理同义词的情况。近年来,主题模型在文本挖掘中得到了不错的运用,其中最具有代表性的就是潜在狄利克雷分配(Latent Dirichlet allocation,LDA)。如今,已经有许多针对不同语料特点改进的LDA模型被用在了情感分析、舆情控制和个性化推荐上。
对于论坛文本,因为其本身具有一些结构化信息,使用原始的LDA模型并不能够最大化地利用文本信息来挖掘主题。论坛里面可能会存在大量的短回复和水帖,短回复会造成词的稀疏性,水帖会给主题挖掘带来很多噪音,这些因素都极大地影响了LDA在论坛上的建模效果。针对论坛的这些特点,对LDA作出了改进。经真实文本数据试验证明,改进后的主题模型能够提升在论坛语料上的主题挖掘能力。
1 相关工作
论坛文本因为有着天然的版块区分,很适合针对性地挖掘一些信息。目前针对论坛文本的研究比较少,不过文本挖掘是一个比较经典的研究问题,许多学者的研究都能够很方便地应用到论坛文本上。
文本摘要是文本挖掘中一个热门的研究方向。通过多文档摘要,可以从大量的文本中获取相对比较重要的文本,这使得读者能够更加快捷地消化这些文本数据。Slamet等[2]通过TF-IDF获取关键词和词权重,之后借助空间向量模型获取文本之间的关系,以实现文本的自动摘要。刘端阳等[3]在TF-IDF的基础上引入了语义词典和词汇链,能够缓解自动摘要中同义词冗余表达的缺点。余珊珊等[4]结合了中文的结构特点,提出了iTextRank算法,在中文新闻的摘要上取得了不错的效果。
对论坛进行文本摘要往往只能从大量论坛文本中抽取重要的内容,并不能对主题进行区分。论坛的主题挖掘相对而言更加困难。潜在语义索引(Latent semantic indexing, LSI)[5]是一个可以挖掘文档主题的方法,它是主题模型的雏形,LSI通过奇异值分解(SVD)的方法对文档进行降维,把单词空间映射到主题空间,通过它可以获取最有可能代表文章主题的词语,不过LSI计算比较复杂,而且不易针对文章的特点进行修改。Hofmann[6]提出了概率潜在语义分析(Probabilistic latent semantic analysis,PLSA),通过概率统计来获取代表文档主题的词语,不过PLSA比较容易过拟合,泛化能力比较差。
Blei等[7]在PLSA的基础上加上了先验,提出了潜在狄利克雷分布模型(Latent Dirichlet allocation, LDA),一定程度上克服了PLSA泛化能力差的问题。LDA是一种针对离散数据的概率生成模型,也是一种由文档、主题、词组成的3 层贝叶斯概率模型。LDA采用了词袋(Bag of words)的方式来描述文本,这种方式把独立的文档转化成了一个个词频向量,从而使文本信息便于建模。词袋法没有考虑文档中词的顺序信息,大大降低了问题的复杂性。
对某些语料直接应用LDA效果不是很好,比如短文本,其原因是短文本中每个文本所含的信息量太少,词袋间词共现数太少,模型生成会遇到数据稀疏问题。有人提出了一些有效的解决方案。最简单的方式就是把短文本拼接成长文本,Hong等[8]发现,通过把短的Tweet文本拼接成长的文本,以长文本来训练主题模型能够获取更高质量的主题。Zhao等[9]在分析Twitter的时候,认为在大多数情况下,一条Tweet只包含一个主题,以此提出了Twitter-LDA,经过测试,Twitter-LDA在挖掘主题的准确性上比原始的LDA提升了31%。Balikas等[10]在分析文本的时候采用了和Twitter-LDA类似的方法,在提出的Sentense LDA中,把同一个句子中的词语归到同一个主题。结果表明用词袋来表示文本会丢失词在文本段(句子或者词组)的共现信息。Yan等[11]用一个新的主题模型BTM(Biterm topic model)来处理短文本,BTM直接对共现词对(biterms)进行建模,通过汇聚语料中的共现词实现对短语建模的目的,解决了词在文档层面共现的稀疏性问题。BTM被广泛用在短信、微博等短文本主题挖掘上[12]。
根据语料的结构和特点对主题模型进行合理改进,不仅能够让主题模型学习新的东西,也能够提升主题模型的挖掘效果。Rosen-zvi等[13]提出的ATM(Author topic model)把作者信息加入到LDA,这使得模型不仅能够从文本中挖掘主题,也能够学习某个作者经常写哪些主题的文章。Lin等[14]提出了JST(Joint sentiment/Topic model)模型,JST模型在LDA模型的基础上加了一层情感层,通过新增的情感层,JST能够同时挖掘文本的主题信息和情感信息。JST被用在了电影评论上,对文本的情感分类取得了不错的效果。Xiong等[15]提出的WSTM(Word-pair sentiment-topic model)在BTM上加入了情感层,克服了JST面对短文本效果不佳的问题。Lim等[16]通过把好友关系、主题标签、关注和被关注信息整合到LDA中,构建出TN(Twitter-network topic model)模型。TN模型被实验证实能够更有效地挖掘主题和用户信息,被用于用户推荐。
结合文本特点对主题建模已经成了主流的趋势。论坛语料最大的特点就是存在很多水帖。如果直接对论坛文本进行建模,可能达不到比较理想的效果。笔者利用论坛帖子的用户特征,在对主题建模的同时,能够发现论坛语料的无意义回复以及回复中的背景词,更加有效地挖掘论坛主题。
2 论坛主题挖掘
2.1 论坛主题挖掘难点分析
论坛一般分版块,每个版块有一个大主题,比如经济、体育等。用户发帖时,一般会先根据自己想发的内容,选择一个版块进行发帖。帖子的主题和版块的主题相关。对于论坛的主题挖掘,主要研究的是同一个版块内的主题挖掘,这样不可避免会遇到主题相似的问题。
论坛的每个帖子包含正文和别人对帖子的一系列回复。对于一个帖子的正文和所有回复,其主题分布一致,通用的主题模型并不会考虑论坛的这些特征。
论坛文本的更新非常迅速,用户一般喜欢用比较简单的语言描述一件事情,很少有长篇大论,所以论坛的回复一般都比较短。直接使用LDA对短文本进行分析会遇到数据稀疏的问题,导致挖掘效果不好。
论坛的口语化现象比较严重,文本中滥用标点、错别字现象比较普遍,而且有些板块(比如金融)会存在很多专有名词,所以对于不同的论坛版块,应该做不同的预处理。可以把一些常用的表达整理出来,加入到分词工具的词典里,提高分词准确性,这一步很难做到无监督。
论坛中存在着部分的水帖和推广贴,这会给主题的挖掘带来很大的噪声。如果有一个人经常发无意义的帖子,那么这个人新发的帖子极有可能也是无意义的。可以在主题模型中引入用户的信息,提高主题挖掘的准确性。
2.2 BBS-LDA
根据2.1节的分析,笔者提出了BBS-LDA模型。BBS-LDA的图模型见图1,图模型中所用到的符号含义见表1。
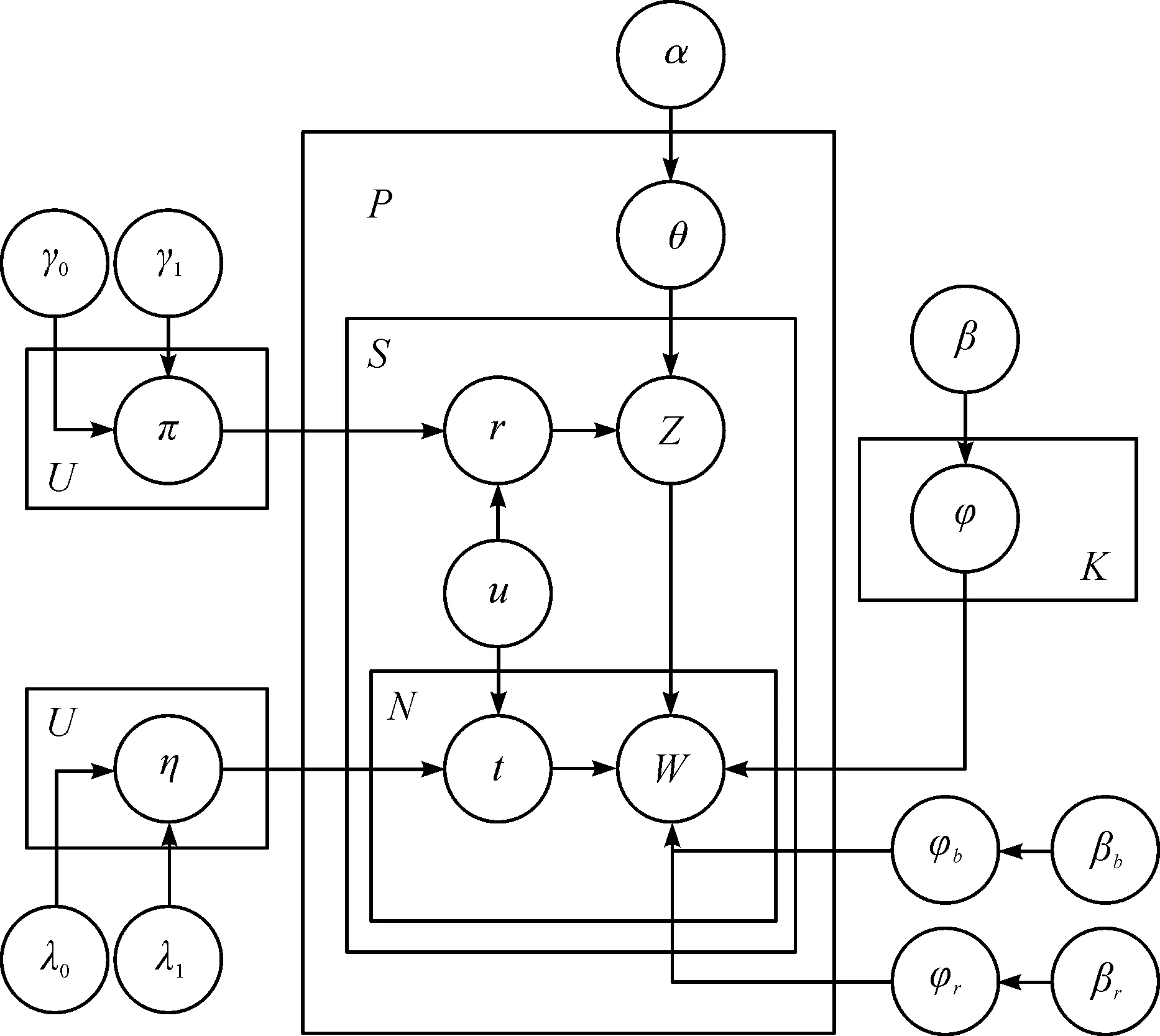
图1 BBS-LDA的图模型Fig.1 BBS-LDA graphical model

表1 BBS-LDA的参数含义Table 1 Parameter meaning of BBS-LDA
该模型和LDA模型一样属于生成模型,它假设语料是根据一定的概率分布生成的,可以据此对文本数据进行建模,得到变量之间的条件概率分布,这在此模型中具体指每个词属于不同主题的概率分布。图模型表示的语料的生成过程为
1) 对于每个主题k∈[1,K]
采样其词分布φk~Dirichlet (β)
2) 采样无意义的词分布φr~Dirichlet (βr)
3) 采样背景词分布φb~Dirichlet (βb)
4) 对于每个用户u∈[1,U]
采样标记变量分布πu~Beta (γ)
采样标记变量分布ηu~Beta (λ)
5) 对于每个帖子p∈[1,P]
采样其主题分布θp~Dirichlet (α)
对于帖子中的每个句子s∈[1,Sp]
采样标记变量rp,s~Bernoulli (πu)
如果rp,s=1
采样该句子的主题zp,s~Multinomial (θp)
对于每个词w∈[1,Ns]
采样标记变量tp,s,w~Bernoulli (ηu)
如果tp,s,w=0
采样词w~Multinomial (φb)
否则如果rp,s=0
采样词w~Multinomial (φr)
否则
采样词w~Multinomial (φzp,s)
对比原始LDA,BBS-LDA主要有3点与之不同。第1点是以句子为单位,每个句子的主题只采样一次,每个帖子中的句子具有相同的主题分布,这样的做法考虑了论坛文本的结构特性,并且可以缓解单条回复字数少导致的稀疏性问题。第2点是句子中的词分为两部分,一部分属于背景词,一部分属于主题词。这个做法与Twitter-LDA的做法差不多,唯一的不同是在Twitter-LDA中,η对于所有文本都是相同的,而在BBS-LDA中,对于每个用户,η都是不同的,因为不同的人,写作习惯是不同的。通过这样的做法,可以对文本中的背景词进行建模,增加模型在相同版块不同主题的区分能力。第3点是增加了一个标记变量r来识别句子是否有主题,这个想法是受文献[17]启发得到的,同样的,对于每个不同的用户,π的值是不同的,因为有的用户可能会经常回水帖,而有的用户发的回复可能基本上都是和主题相关的。
2.3 BBS-LDA的参数估计
LDA主题模型的参数都比较复杂,不能够被精确算出,一般使用一些近似的方法估计得到。最常用的方法有变分推理(Variational inference)和塌陷吉布斯采样(Collapsed Gibbs sampling)[18]。笔者使用塌陷吉布斯采样估计模型中的参数。
1) 首先,需要推导每个句子属于对应主题的概率。为了简化这个问题,可以先忽略句子中的背景词,因为背景词与主题无关。根据模型的生成过程,整个文本集的生成概率为
(1)
展开式(1)第3项,即
(2)

(3)
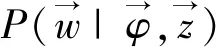
(4)

把式(3,4)代入式(2)之后,可以得到
(5)

同理,可以得到
(6)
(7)
(8)
在采样过程中,对于一个句子,先采样r,然后根据r判断句子是不是有意义的,如果有意义,则从以α为参数的Dirichlet分布中再采样z,否则句子直接属于无意义主题,无意义主题记为zr,则此时P(zr|r=0)=1,则有
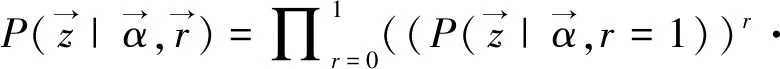
(9)
所以,整个文本集生成的概率为
(10)
由此,可以开始采样第p个帖子中第s个句子所对应的标记变量rp,s和句子的主题zp,s。当rp,s=1时,句子主题为k的概率计算为
(11)

rp,s=0的概率计算为
(12)
式中:C表示当前采样句子中无意义词的个数;C(v)表示当前采样句子中的词v属于无意义词的个数。
之后,对句子中的每个词进行采样(单词计为x,单词的序号为i)。
2) 现在考虑文本集的时候不忽略背景词,则文本集的生成概率为
(13)
因为此时句子的主题已采样,所以式(13)中的前两项与单词是否是背景词的概率无关,把它记为(*)。
与式(5)的推导相同,可以得到
(14)
(15)

将式(5,8,14,15)代入式(13),可得
(16)
词x属于背景词的概率为
(17)
如果该单词所在的句子对应的标志变量rp,s=1,且zp,s=k,同理可得
(18)
如果该单词所在的句子对应的标志变量rp,s=0,同理可得
(19)
等采样收敛之后,因为Dirichlet分布和多项分布共轭,各个隐藏变量的估计值为
(20)
(21)
(22)
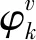
2.4 垃圾回复识别
直接使用模型对文档进行建模,在辨别回复是否为有意义的回复上准确度不是很高。识别部分比较明显的垃圾回复能够为模型提供部分监督信息,有利于更好地对文本进行建模。在模型参数估计的过程中,如果该条回复已经根据监督信息被标记为无意义的回复,则直接把该条回复对应的标记变量r赋值为1。如果该条回复没有被标记,则需要通过采样算法来决定r的值。根据观察发现,论坛的垃圾回复主要有两种:第一种是一些过短回复,基本不包含什么语义,只是为了顶贴或者水帖而发表的回复;第二种是推广。
对于第一种垃圾回复,其文本中一般会包含一些高频率词,比如说“顶”“紫薯补丁”。所以筛选了字数小于10的一些回复,经分词之后统计高频词,经筛选形成一份词典。对于新的文本数据,可以通过以下方式判断是否为这一类垃圾回复:首先对文本进行分词,根据回复的词数筛选出过短回复;之后判断该回复中是否包含词典中的高频词,如果是,则该条回复为垃圾回复。
对于第二种推广类型的回复,也有一个特点,就是不经过大幅度修改直接重复粘贴,且多为同一个人发出。对于这些水帖,可以在数据库中对每个用户的回复进行遍历(爬取语料的时候保留用户信息),查找文本中相似度比较高的回复,并对这些回复进行标记。计算语句的相似度主要有基于相同词的方法、基于向量空间的方法和基于局部敏感哈希(LSH)的方法[19]。笔者使用Simhash[20]来查找重复回复,它是一种典型的基于局部敏感哈希的算法,计算效率较高,更适合处理大规模文本。对于每个用户的所有发言,使用Simhash计算它们的哈希值,然后遍历,寻找相似度高于一定阈值的发言,如果这些彼此相似的发言数量大于这个阈值,则标记为垃圾回复。需要注意的是,在这里寻找相似回复的范围是一个用户的所有回复,而不是所有用户,因为在一个帖子中,可能会出现多个用户因为共鸣等原因发出相似的发言,而这些发言并不一定是垃圾回复。
3 实验与分析
3.1 数据准备
3.1.1 数据采集
为了验证BBS-LDA的主题挖掘能力,笔者爬取了天涯论坛的百姓声音版块的帖子作为实验数据。同一个版块的不同主题可能会含有很多共用词语,这样的数据能够很好地区分不同主题模型对于挖掘相同版块近似主题的能力。笔者爬取了2018年1—6月的所有帖子,爬取的内容见表2。

表2 爬虫爬取的内容Table 2 Content we crawl through the crawler
3.1.2 数据预处理
首先,对文本进行分词。中文分词主要有基于词典匹配[21]的方法和基于统计的方法。笔者使用了开源的Jieba分词,它结合了词典和隐马尔科夫模型,分词准确度较高。分词后根据词的词性保留动词、名词、形容词等重要词性的词,删除了数词、介词、量词等不包含语义信息的词。
分词后对词语进行去停用词操作。停用词是一些对语义没帮助的词。对于中文,现在已经有比较全的停用词库,比如“哈工大停用词词库”“百度停用词表”,笔者对这些停用词库进行了整合,并做了去重的工作。
之后,使用2.4节的方法进行垃圾回复的标记。对长度低于10的回复分词之后进行了统计,高频词见表3(只列出前8项)。

表3 短回复高频词列表Table 3 High frequency word list of short response
从表3中可以凭经验分辨出哪些词大概率是水贴,哪些词和板块的大背景切合。经过筛选,把腐败、贪官等词移除,构建出一个词典,根据这个词典把所有大概率可能是水帖的短回复做好标记。随后,通过Simhash找到每个用户发表的相似帖子,把重复数高于5的重复帖子标记为无意义回复。最后,统计各个词语的词频,把低于5的低频词删除,去除低频词有助于提高主题模型的效率。预处理之后数据的统计信息见表4,以下实验都是基于这些数据完成的。

表4 数据的统计信息Table 4 Data statistics
3.2 实验结果
本次实验将BBS-LDA和下面两种主题模型进行对比。模型所用的语料相同,均为上述处理后的语料。不过不同模型对应的输入不同,所以对于不同模型,需要在语料格式上做一些改动。
1) LDA:原始的LDA,因为LDA对于短文本效果不太好,这里把每个帖子的正文和回复拼成一起,当成一个单独的文档来进行实验。
2) Twitter-LDA:原始的Twitter-LDA是以用户作为聚簇,把每个用户的发言作为一个文档,用户发的每条Tweet中的所有词主题相同。这里以帖子作为聚簇,每个帖子的所有回复作为一个文档,每条回复中的所有词主题相同。

主题模型的效果一般可以使用困惑度(Perplexity)来进行评估。困惑度常用来度量概率图模型的性能,它的值代表着预测数据时的不确定度。困惑度越小,就代表着模型的效果越好。困惑度的计算公式为
(23)
式中:Nd代表第d个文档所包含的词数;p(wd)代表文档d生成的概率。
随着迭代次数的增加,不同主题模型在同一个测试数据集上的困惑度变化如图2所示。

图2 不同模型困惑度随迭代次数的变化Fig.2 The perplexity of different models changes with the number of iterations
从图2中可以看到:3 个模型随着迭代次数的增加,困惑度都逐渐降低,迭代500 次之后模型已经收敛,BBS-LDA的困惑度比Twitter-LDA和原始LDA的困惑度都低,说明BBS-LDA有更好的泛化能力。
主题相似度可以度量主题模型对于不同主题的区分能力,它也是主题模型的一个常用的评估手段。一般用KL散度来度量主题间的相似程度。KL距离越大,代表两个主题间的相似度越小,不同主题间的区分度更加好。
主题k1和k2的KL距离的计算公式为
(24)
因为KL距离不是对称的,所以这里计算两个主题之间距离的时候对两者的KL距离取平均,即
Distance (k1,k2)=(KL(k1,k2)+
KL(k2,k1))/2
(25)
在模型收敛之后分别计算模型的两两主题间的平均距离,结果如表5所示。

表5 不同模型主题间的平均距离Table 5 Average distance between different model topics
最后,直观地对3 个主题模型挖掘的主题进行对比(随机抽取了5 个主题),结果如表6所示。

表6 不同主题模型关键字对比Table 6 Keyword comparison between different topic models
从表6可以看到:3 个模型都能够比较好地挖掘文章的主题。其中,BBS-LDA因为综合考虑了论坛的结构特性和用户的信息,关键词质量最高。同时,BBS-LDA还在一定程度上识别了背景词和一些无意义的回复,这个是很有意义的。
4 结 论
论坛是人们获取和发布信息的主要途径之一,挖掘论坛的文本信息对于舆情监控、市场调研等有着重要的意义。根据论坛的一系列特点,基于LDA提出了新的BBS-LDA主题模型,并通过Gibbs sampling对模型进行推导。经过实际论坛语料试验表明:BBS-LDA不仅具有良好的主题挖掘能力,还能够在一定程度上识别文章的无意义回复和背景词。下一步工作将研究如何把时间和BBS-LDA结合在一起,让该主题模型能挖掘出更多信息,更实用。
