核磁共振氢谱-PCA-SVM回归法用于稀奶油中植脂奶油掺假定量分析
2020-01-14杨红梅贾婧怡
李 玮,杨红梅,王 浩,贾婧怡,刘 琪
(北京市食品安全监控和风险评估中心,北京 100094)
稀奶油 (cream)是以动物乳为原料的乳制品,是制作裱花蛋糕等西式烘焙食品的重要原料[1]。植脂奶油(non-dairy whip topping)是以食用氢化油、甜味剂等为主要原料的人造奶油[2],与稀奶油在外观、特性与用途上都极为相似,但价格却远低于稀奶油。在实际烘焙制品应用中,不良商家常以植脂奶油掺假于稀奶油中来替代纯稀奶油。但目前国内有关烘焙制品中奶油种类及掺假定量的检测标准尚未出台,加之相关国家标准的缺失,给有效监管带来了难度,而且随着网络烘焙店的兴起和奶油蛋糕等西式烘焙食品消费的逐步增长,这些问题将会越来越突出。
目前,对乳脂掺假检测的传统方法有感观鉴别、气相色谱等方法,但是这些方法前处理烦琐、检测时间长,且测定结果受人为因素影响大[3-4]。近年来,亦有学者采用红外、拉曼、荧光等光谱技术结合化学计量学方法针对油脂含量在80%以上的黄油进行掺假定量鉴别研究[5-7]。但这些光谱技术受其检测原理所限,其图谱对乳脂等复杂混合物体系内各成分解释能力有限,难以实现对建模样本的真实性判断,具有引入不真实的样本造成校正模型的真实性降低或(和)将特殊真实样本排除在建模样本外造成校正模型的普适性减弱的风险。为有效解决烘焙市场上的问题,应以稀奶油和植脂奶油为基础,采用接近实际情况的方式配制掺假的混合奶油制品并开发适于稀奶油检测的前处理方法。
核磁共振(nuclear magnetic resonance, NMR)是有机物结构分析的强有力工具,与液相色谱、气相色谱法等传统分析方法相比,具有高通量、重现性好、操作简便、结构信息丰富等优点,对食品等复杂体系的整体分析具有优势[8-9],已被用于多种植物油及其他脂类成分的分析中[10-11]。由于通过NMR所得到的样品信息具有数据信息复杂、多维数据矩阵内各变量之间具有高度的相关性等特点,需要结合化学计量学等算法对数据进行分析。支持向量机(SVM)[12-13]是近年来机器学习研究的一项重大成果,其主要思想是建立一个分类超平面作为决策曲面,使得正例和反例之间的隔离边缘被最大化,错误概率的上界最小化。与传统的人工神经网络相比,支持向量机结构简单,且泛化能力明显提高。
本研究采用市售稀奶油、植脂奶油样本,建立了基于核磁共振氢谱-PCA(主成分分析)-SVM回归法的稀奶油中植脂奶油掺假含量测定模型,利用该模型可实现裱花奶油产品中稀奶油掺假植脂奶油的含量测定。与传统的PLS(偏最小二乘法)及单纯SVM回归算法建立的定量模型相比,基于PCA-SVM算法的定量模型的稳定性、准确性以及模型的预测能力均优于PLS、SVM算法,可为规范市场上奶油蛋糕等烘焙制品的质量监管提供技术支持。
1 材料与方法
1.1 实验材料
1.1.1 原料与试剂
市场上采集了25个不同品牌、产地的奶油样品(见表1),其中稀奶油(脂肪含量35.0%~38.0%)14个,植脂奶油(脂肪含量16.5%~37.5%)11个。稀奶油4℃存放;植脂奶油-20℃存放,使用前常温融化,避免反复冻融。所有样品均在保质期前使用。
氘代氯仿 (CDCl3,氘代度99.8%),美国CIL公司。

表1 用于 1H-NMR分析的25个奶油样品信息
1.1.2 仪器与设备
Bruker AVANCE 600 MHz超导傅里叶变换核磁共振仪(配有BBO探头和Topspin3.2处理软件),瑞士Bruker公司;Norell 5 mm核磁管,美国Norell公司;XS204电子天平,瑞士Mettler Toledo公司;Centrifuge 5424R离心机,德国Eppendorf公司;TARGIN多管涡旋振荡器,北京踏锦科技有限公司;Tissuelyser II均质器,德国Qiagen公司。
1.2 实验方法
1.2.1 掺假样品的制备
按稀奶油中掺假植脂奶油质量分数分别为0%、5%、15%、25%、35%、45%、55%、65%、75%、85%、95%、100%比例称取2种奶油,将称好的2种奶油分别置于12个15 mL的塑料瓶中,每个比例点称取的2种奶油的总质量为10 g。放入直径约为5 mm的不锈钢研磨珠,用盖子密封后放入多管涡旋振荡器中振荡1 min,使瓶中的两种奶油充分混合。
1.2.2 样品溶液的制备
称取约500 mg 1.2.1中制备的奶油样品于2 mL EP管中,加入1 mL CDCl3,置于均质器中均质40 s(30 Hz)后放入离心机中,4℃条件下离心10 min (8 000 r/min)。移取600 μL上清液于5 mm核磁管中,待测。
1.2.3 训练集与测试集样本的获得
在Matlab中用Randperm函数随机将14个稀奶油分为2组,每组7个样品;同样,将 11个植脂奶油分为2组,一组6个样品,一组5个样品。取稀奶油中第1组7个样品和植脂奶油中第1组6个样品,按照1.2.1 掺假样品制备方法制备样品,共213个样本作为训练集(training set)样本;取稀奶油中第2组7个样品和植脂奶油中第2组5个样品,按照1.2.1 掺假样品制备方法制备样品,共112个样本作为测试集(testing set)样本。
1.2.4 仪器条件
1H NMR测定条件:使用Bruker标准脉冲序列noesyig1d,检测温度为297 K,谱宽SWH为6 002.40 Hz,中心频率O1P为2 400.52 Hz,脉冲延迟时间D1为10 s,混合时间D8为0.01 s,扫描次数NS为32。
1.2.5 谱图处理
测得的1H-NMR谱使用Bruker Topspin3.2软件处理,变换点数为64 K,LB为1.00 Hz,用指数窗函数处理,基线和相位校正均采用手动方式进行,TMS为内标信号(δ0.00)。处理后的图谱以δ0.005积分段对化学位移区间δ0.40~7.00进行分段积分并进行面积归一化处理。
1.2.6 模型建立及评价
以图谱的分段积分值作为输入自变量,以掺假样本中所含稀奶油脂肪的相对含量作为拟合输出因变量,建立模型。按照下式计算因变量。
Y=aK/(aK+bJ)
式中:Y为掺假样本中所含稀奶油脂肪的相对含量;a为稀奶油样品商品标签标识的脂肪含量;b为植脂奶油样品商品标签标识的脂肪含量;K为掺假样本中稀奶油的质量分数;J为掺假样本中植脂奶油的质量分数。
PCA、PLS模型的建立:将上述所得数据进行PCA和PLS分析,分别选用中心化法(Ctr)、单位方差法(UV)的数据标度换算方式。PLS模型采用交叉验证(CV)Q2值、排列实验对所建立的拟合模型进行评判。
PCA-SVM回归模型的建立:首先用 PCA分析方法将训练集数据自变量降维,得到新的特征变量,交叉验证优化模型的c、g值,然后用最优参数训练SVM回归模型,模型类型为epsilon-SVR,核函数为径向基(RBF)函数。用得到的模型预测测试集。模型评价:采用训练集交互验证均方根误差(RMSECV)、测试集的判定系数(R2)、预测均方根误差(RMSEP)作为回归模型的评价指标。RMSECV用于评价建模方法的可行性及所得模型的预测能力,RMSEP用于评价所建模型对外部样本的预测能力,这两个值越小,表明模型的准确度越高,预测能力越好;R2越接近于1,说明期望值和预测值之间相关性越好。
2 结果与分析
2.1 稀奶油和植脂奶油1H-NMR图谱分析
图1为植脂奶油和稀奶油CDCl3提取物的1H-NMR图谱。根据文献[14-15]报道,图谱中δ0.75~0.99信号为脂肪链末端甲基质子信号,δ1.11~1.47信号为长链脂肪酸一般性亚甲基质子信号,δ1.57~1.68信号为脂肪链上与羰基相隔一个亚甲基的亚甲基上的质子信号,δ1.92~2.14信号为与脂肪链上双键相连的亚甲基质子信号,δ2.26~2.38信号为脂肪链上与羰基直接相连的亚甲基质子信号,δ2.75~2.85信号为脂肪链上两个双键之间亚甲基质子信号,δ4.10~4.38和δ5.24~5.29信号分别为甘油三酯中丙三醇的亚甲基和次甲基质子信号,δ5.30~5.43信号为非共轭脂肪酸不饱和质子信号。

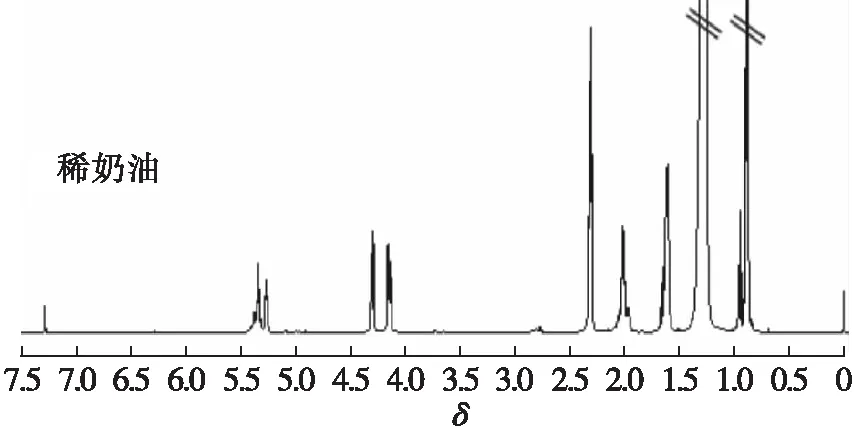
图1 稀奶油和植脂奶油CDCl3提取物的1H-NMR图谱
从图1可以看出,与稀奶油相比,植脂奶油的氢谱质子信号明显缺少δ0.99(甘油三酯丁酸脂肪链末端甲基质子信号)、δ1.92~2.14(与甘油三酯脂肪链上双键相连的亚甲基质子信号)、δ5.30~5.43(甘油三酯非共轭脂肪酸不饱和质子信号)这3组质子信号。这是因为,稀奶油来源于天然乳脂,其脂肪酸组成与牛乳类似,含有牛乳中所特有的脂肪酸(丁酸)和较多的饱和脂肪酸;而植脂奶油现多以氢化棕榈仁油为原料,所以其中的脂肪酸以饱和脂肪酸为主。
2.2 PCA分析
为检查定量掺假实验所用奶油样品是否存在异常样品,对25个奶油样品CDCl3提取物NMR 谱图进行PCA分析,结果见图2。
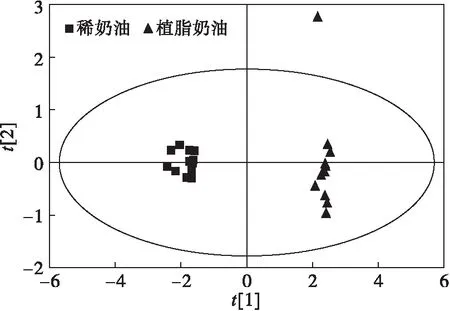
图2 稀奶油、植脂奶油CDCl3提取物1H-NMR图谱PCA分析PC1/PC2得分图
由图2可见,植脂奶油组出现了一个明显远离其他样品的异常样品,代表该样品的化学成分与其他植脂奶油样品具有显著性差异。通过查阅原始1H-NMR图谱并结合多种2D-NMR图谱发现,与其他植脂奶油样品相比,此样品中含有香兰素,因而在PCA得分图上会表现出异常偏离的趋势。香兰素是一种具有奶香气息的可食用香料,在奶油、糖果等食品中使用广泛,因此此样品虽然在PCA得分图中远离其他植脂奶油样品,但其却代表了一类含有香兰素的植脂奶油样本的特征,因此后续的定量掺假实验中应保留此样品,不应当做异常样本剔除。
2.3 PLS掺假定量模型
以采用训练集数据建立PLS稀奶油中植脂奶油掺假定量分析模型,并经内部交叉验证和排列实验对所建立的拟合模型进行评判。在潜在变量为4时,交叉验证Q2为0.977。在此之后,通过排列实验随机多次(n=200)改变分类变量(y)的排列顺序得到相应不同的随机Q2和R2值对模型有效性做进一步的检验,结果如图3所示。
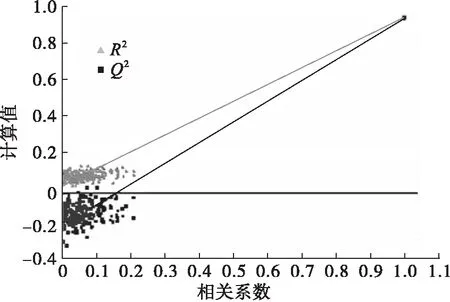
图3 PLS掺假定量模型排列实验
由图3可知,图中所有的Q2均在R2之下,且Q2的回归直线与y轴的交点在负半轴,说明该模型未过度拟合。以模型可预测指标Q2并结合排列实验验证结果说明建立的定量模型成立。
2.4 PCA-SVM、SVM掺假定量模型
PCA-SVM掺假定量模型:在本研究中,采用了径向基函数作为SVM的核函数,以降维得到的新的特征变量作为输入自变量,以掺假样本中所含稀奶油脂肪的相对含量作为拟合输出因变量,通过交叉验证的方法优化c、g值,优化后的最佳c值为256,最佳g值为0.062 5,此时的RMSECV为3.69。以优化得到的c、g值作为模型参数,采用svmtrain函数训练降维后的训练集数据,建立PCA-SVM掺假定量模型。
SVM掺假定量模型:SVM掺假定量模型的建立过程与PCA-SVM模型相似,只是不进行自变量数据的降维。
2.5 PLS、SVM与PCA-SVM模型建模效果、预测结果对比
分别采用建立的PLS、SVM与PCA-SVM掺假定量模型对112个测试集样本进行预测,模型预测值和实际值相关性见图4~图6。从图4~图6可以看出,SVM模型的预测性要优于PLS模型。
模型相关参数结果见表2。由表2可知:SVM模型的RMSECV小于PLS模型,而训练集R2大于PLS模型,说明SVM模型的拟合精度优于PLS模型;同时,SVM模型的RMSEP小于PLS模型,而测试集R2大于PLS模型,说明SVM模型对外部样本的预测能力高于PLS模型。同是SVM模型,经过PCA降维的SVM模型RMSECV、RMSEP、测试集R2均优于没有降维的SVM模型,说明PCA降维能够在保证原变量信息不变的前提下,将数据降维,使原来的多维问题大大简化,有效缩短运行时间,提高预测精度。
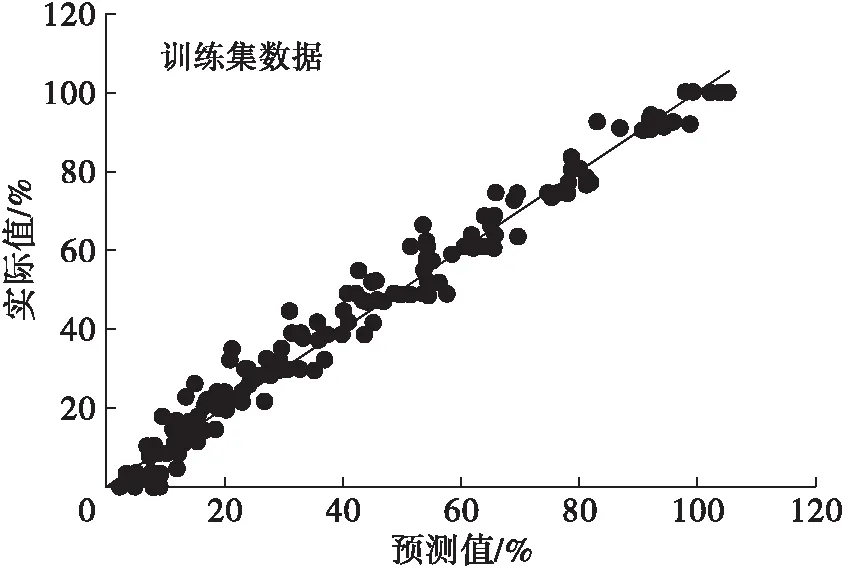
图4 PLS掺假定量模型预测值和实际值相关性
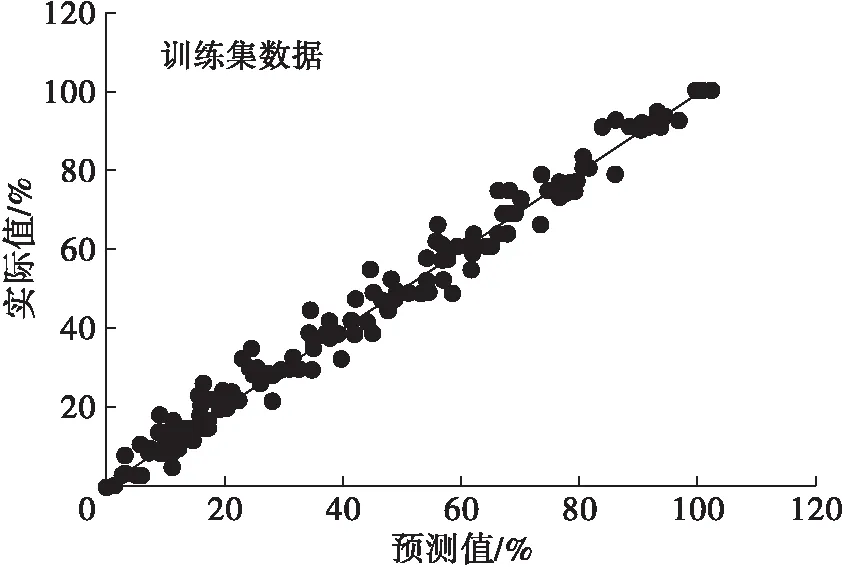
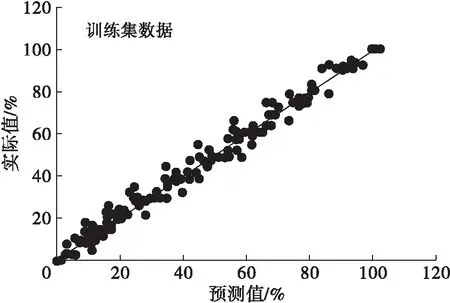
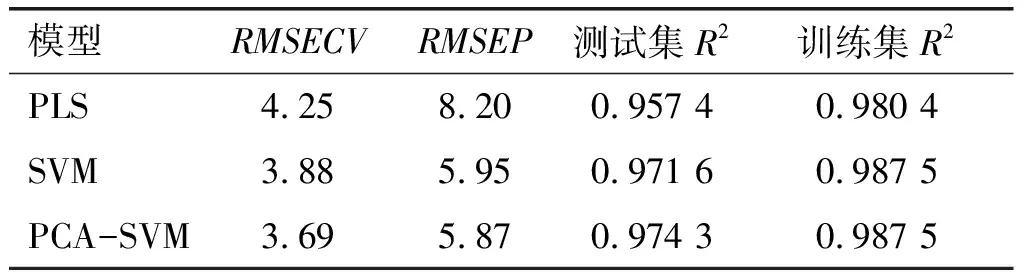
表2 PLS、SVM与PCA-SVM模型相关参数
3 结 论
本研究将PCA-SVM回归法与核磁共振技术相结合,利用PCA法对数据进行降维处理,建立稀奶油中植脂奶油掺假定量分析模型,并与PLS及SVM建模结果进行对比。结果表明,PCA-SVM模型具有稳定性好、预测准确度高、外推能力强及不存在过度学习现象等优点。
