一种改进的基于孪生卷积神经网络的目标跟踪算法
2020-01-14任珈民宫宁生韩镇阳
任珈民,宫宁生,韩镇阳
(南京工业大学 计算机科学与技术学院,南京 211816)
1 引 言
目标跟踪技术是计算机领域的一项重要研究课题,在生活中也有广泛应用,如智能监控、视频分析、体感游戏等.目标跟踪通过在连续视频序列中估计跟踪目标状态,确定目标运动轨迹等信息,实现对跟踪目标的理解与分析[1].目标跟踪的难点主要有目标的外观变化或目标的快速移动等内部因素以及光照或遮挡等外部环境的影响等等.近年来,研究人员对此展开大量研究,提出了诸多算法,总体可以分为生成式方法和判别式方法,其中生成式方法运用生成模型来描述目标的表观特征,之后通过搜索候选目标来最小化重构误差,该方法一般采用传统机器学习算法,如CT[2]、STC[3]等等,可是一旦目标外观有较显著的变化,跟踪结果就会产生漂移,同时传统机器学习算法往往也存在特征提取不明显,跟踪效果不精确等问题;判别式方法一般通过训练分类器来区分目标和背景,该方法鲁棒性好,目前与深度学习相结合,取得了很好的效果.具体操作是利用深度学习构建一个跟踪模型,通过神经网络强大的特征提取能力和分类识别能力,进行精确跟踪,如FCNT[4]、MDNet[5]等.但这类模型存在两点不足:一是在线跟踪网络需要实时更新,因此在利用深度神经网络进行在线跟踪时存在网络更新不及时的问题,虽然利用更强大的深度特征进行实时跟踪也能解决该问题,但由于领域特定的细节未能使用,故性能往往得不到保障;二是由于待跟踪视频通常只给出第一帧图像,因此网络的训练样本往往十分缺乏,而利用前一帧的跟踪结果作为后一帧的跟踪依据则会产生累进误差,使跟踪结果不精确.
本文在深度学习框架的基础上,考虑到以上两点不足之处,故采用孪生卷积神经网络架构.利用模板分支保存先验信息,同时通过检测分支完成对待检测帧的特征提取,进行实时的比对和跟踪.这不仅解决了模型更新不及时的问题,而且由于使用的是模板图像作为训练参数,从而能隐式地解决跟踪误差逐渐增大的问题.
2 相关工作
孪生卷积神经网络含有两个相同的子结构,二者共享参数和权重,工作原理主要是利用多层卷积获得特征图后,再判断图像之间的相似性.该网络在单样本学习上表现优异,恰好能解决目标跟踪中训练样本不足的问题,且跟踪实时性更高,但其跟踪准确率有待提升.
为了更好地提取特征来提高跟踪准确率,文献[6]引入注意力机制,通过堆积注意力模型,生成一个注意力感知特征,不同模块的感知特征能够根据层数自适应地改变,从而提升特征的表达能力.而由Hu J等人提出的SE-Network子结构[7],则是通过对图像各通道之间的相关性进行建模,增强有效通道的特征,提高特征辨别力.该结构兼具泛化性和具象性,泛化性指在较低的卷积层上,可以学习去激励可信息化的特征,加强较低层次表征信息的共享质量;而具象性指在较高的卷积层上,其对不同输入具有高度的类别响应.因此,利用低层的激励学习,可以进一步提取有效特征;而利用高层的类别响应,可以进行目标的分类与识别.
CNNSVM[8]采用了大规模数据集,预先训练出卷积神经网络模型进行特征提取,再利用支持向量机作为分类器对跟踪目标的前景和背景进行分类,达到较好的跟踪效果.与CNNSVM方法不同,由Faster RCNN[9]提出的区域推荐网络(RPN)将文献[10,11]中的方法整合到一个网络,利用anchor机制和边框回归机制区分目标与背景.网络先利用anchor机制获得所有待筛选的目标(包括正例和负例),再利用损失函数及设定的重合度阈值对目标进行大致定位,筛选出目标区域;然后对比网络输出结果和真实目标的差距,如果差距小于某一设定的阈值,则利用边框回归机制进行线性微调.相比较而言,RPN由于添加了边框回归机制,其跟踪效果会更加精确.文献[12]将孪生卷积神经网络与RPN结合,提升了跟踪的效果.本文在SiamRPN网络结构上,将SE-Network加入到特征提取网络的卷积层,进一步提高网络表达能力和跟踪效果.
3 基于孪生神经网络的目标跟踪模型
3.1 网络模型构建
本文构建如图1所示的网络结构.

图1 网络总体结构Fig.1 Network architecture
如图1所示,该网络结构分为前后两部分,前半部分是孪生卷积神经网络的特征提取模块,进一步可以划分上支为模板分支,下支为检测分支,网络的训练主要是通过端对端的方式进行线下的图片训练.考虑到网络没有预先定义分类,即没有先验信息作为跟踪依据,所以本文将模板分支的输出结果作为一种训练参数,保存先验信息,然后通过与检测分支输出的特征图进行卷积,将其编码进RPN特征图来区分前景和背景,从而预测目标位置.实际上,模板分支主要是为了利用先验信息来加快检测速度的.
具体地,本文将特征提取模块两个分支中的卷积神经网络结构改为SE-CNN模块,使得该模块能够综合利用图像的空间信息和通道信息来增强特征图的表达能力.后半部分是区域推荐网络(RPN)模块,该模块分为分类网络和回归网络.首先利用anchor机制搜索卷积后特征图内的目标区域,同时使用softmax损失函数对网络进行优化,并通过计算目标区域与真实区域的重合面积来区分正例(即候选目标区域)和负例(即背景区域);然后将分类得到的正例输入回归网络,根据与真实边框的差距大小,对候选目标进行排序,选择差距最小的候选目标区域进行线性微调,最终输出跟踪结果.
3.2 改进之处
在原网络结构中,孪生卷积神经网络的特征提取部分采用的是AlexNet[13]结构,同时去掉了卷积层的第2层和第4层[12].故在结构上,原特征提取网络由3个卷积层和3个全连接层组成,前三个卷积核的大小分别为11×11、5×5和3×3,且前两个卷积层的池化步长为2,后一个卷积层的池化步长为1,然后接3个全连接层进行通道数的调整.经过一系列卷积核卷积,Relu函数激活,池化等操作,将3通道的原始图像变为256通道的特征图.最终特征提取网络通过多层卷积提取图像的空间信息特征,利用模板分支保存训练参数,并与检测分支输出的特征图进行卷积,将模板参数编码进待检特征图,然后输入区域推荐网络中进行后续的目标定位和范围框选.
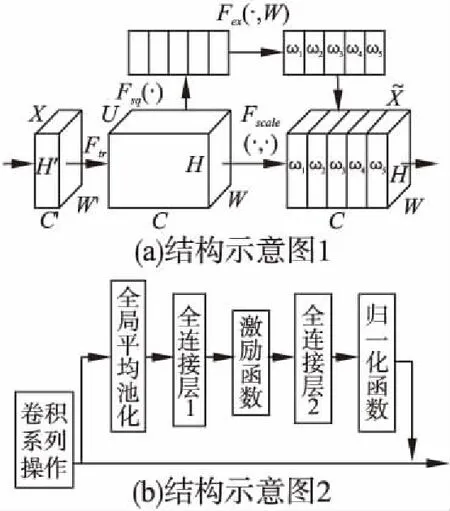
图2 SE-Network子模块Fig.2 Submodule of SE-Network
本文在原网络结构的基础上,将SE-Network加入到特征提取网络中.主要操作是将该网络结构添加到每个卷积层之后,构成SE-CNN结构.实际上,该结构的加入并未改变原有特征提取网络的卷积层数和输出层的通道数,而是在卷积层之间加入一个分支结构,对图像进行有效通道层面的强化,这样使得输入的图像帧不仅考虑空间上的特征信息,而且利用通道相关性进一步强化提取的有效特征.该结构的子模块如图2所示.
SE-Net网络的模型示意图如图2(a)所示,具体的方法及流程如图2(b)所示.如果设输入的图像帧尺寸为X∈RW′×H′×C′,通过卷积操作生成特征图U∈RW×H×C,如公式(1)所示:
(1)
其中vc表示卷积核,uc表示特征图在通道C处的感受野.
然后在全局平均池化层对图像尺寸进行降维,把每个二维特征通道变为一个实数,如公式(2)所示:
(2)
在获取通道信息后,需要保留有效通道并去除无效通道,而利用“瓶颈”结构(全连接层1—Relu激活函数—全连接层2)的目的是在处理数据时能够降低计算量.最后利用Sigmoid函数赋予权重,如公式(3)所示:
s=Fex(Z,W)=σ(W2δ(W1Z))
(3)
式中,Z表示上一步操作的结果,W1和W2分别表示两个全连接层的参数,δ(·)和σ(·)表示Relu函数和Sigmoid函数.这一步得到的结果为不同通道对应的权重值,设其为ωi(i=1,2,3,4,5).
最后将输出的权重以加权的方式在原图上进行重标定,如公式(4)所示:
(4)
其中sc是一个数,相当于权重.通过这种方式,网络可以强化有效通道,提高特征图的表征能力.
3.3 跟踪策略
在特征提取后,本文利用区域推荐网络进行目标定位和边框微调.该部分首先利用anchor机制在特征图上根据每个特征点生成k个边框,之后用softmax损失函数来优化分类层,并通过计算目标区域与真实边框的重合面积Scoi来区分正例M+和负例M-,设阈值为δ,若Scoi>δ,则判定为正例,否则为负例.
对于正例M+,设候选目标边框和真实边框为A和G,将A经映射f得到的一个与G更接近的回归窗口设为G′.则目标函数可利用公式(5)获得.
(5)
定义公式(6)为:
(6)

(7)
其中λ为超参数.最后将预测的输出结果A调整为G′,如公式(8)所示:
(8)
该操作的最终目的是使得目标边框和真实边框更接近.
另外,在进行实际目标跟踪时,为去除冗余边框,使处理过程更快速,在选择边框时,本文加入了相应的筛选条件:
1)在区分特征图中的前景目标和背景区域时,根据真实边框的位置,将面积为g×g的区域(略大于真实边框范围,但小于总特征图的面积)设定为分类特征区域,从而去除距离真实边框较远的候选目标区域,提高筛选的效率和精确度.
2)在选择用于线性回归的边框时,由于与真实边框差距较大的候选目标边框不满足线性回归的要求,因此考虑先将所有候选的目标边框根据与真实边框的差值大小进行排序,再选择差值最小的目标边框进行线性微调.
3.4 算法流程
本文的目标跟踪算法主要分为对孪生卷积神经网络的训练和目标跟踪两个部分.
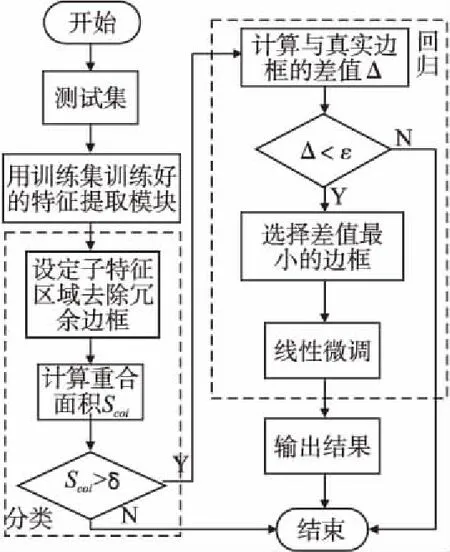
图3 算法流程图Fig.3 Algorithm flow chart
如图3所示,首先用训练数据集对孪生卷积神经网络的特征提取部分进行端对端的线下图片训练,再将测试集输入网络中进行特征提取.然后将两个分支输出的特征图卷积后输入到区域推荐网络中进行定位和微调.在定位阶段,首先设定某一个子特征区域,去除距离真实边框过远的噪声目标,并计算该子特征区域内的候选目标与真实边框的重合面积,再设定阈值,区分前景和背景.然后计算所有筛选出的正例与真实边框的差值,若差值小于阈值,则再对满足要求的候选边框根据差值大小进行排序,并选择差值最小的那个边框,进行线性边框微调,最终输出检测结果.
4 实 验
4.1 实验说明
本文采用OTB2015[14]数据集进行训练和测试,该数据集包含100个视频序列,共58897帧图像,视频的采集综合考虑了光照、遮挡、模糊等不同因素的影响.本文采用5折交叉验证法,其中4折作为训练集,1折作为测试集.
实验使用预训练的AlexNet网络初始化特征提取网络,并用随机梯度下降法(SGD)进行优化,学习率为0.001,迭代次数为100.实验环境为64位操作系统,内存16GB,CPU为4核4.2GHz Intel I7.
4.2 实验结果分析
为了更全面地评估本算法的跟踪效果,本文使用平均覆盖率和一次评估(OPE)方法作为跟踪效果的评价指标.平均覆盖率的计算如公式(9)所示.
(9)
其中ST和SG分别表示算法的跟踪结果区域和目标准确区域;∩和∪表示交集与并集运算,|·|表示计算图像区域内包含像素点的个数;number指序列的总帧数.通过对数据集的取样、分类与实验,得到的实验结果如表1所示.
表1 不同算法的平均覆盖率(%)
Table 1 Average coverage of different algorithms(%)

算法折数12345均值TLD52.454.453.955.151.353.4CNN57.658.559.157.356.857.9SiamR-PN67.867.568.264.361.265.8Ours68.268.168.865.662.466.6
从表1可以看出,TLD[15]使用传统机器学习的方法进行目标跟踪,其平均覆盖率较低,仅有53.4%;而CNN虽然利用卷积神经网络进行特征提取,但由于没有考虑边框调整问题,所以平均覆盖率有所提升,但仍旧不高,为57.9%;而文献[13]所提出的SiamRPN网络利用改进后的AlexNet作为特征提取网络,并加入了边框回归机制,因此其跟踪效果较前两个算法有很大的提升,平均覆盖率为65.8%.本算法在SiamRPN结构的基础上进行改进,加入SE-Net,提升了特征提取网络中通道的表达能力;同时利用RPN网络的目标定位及边框调整机制,所以其平均覆盖率较原网络有了一定的提升,平均覆盖率为66.6%.
一次评估(OPE)方法主要考虑中心位置误差和重叠率两方面的因素,以此为依据分别得到准确率图和成功率图.本文比较了本算法和其他不同算法的结果,利用Matlab绘制图像.如图4所示,FCNT和CNNSVM在目标定位上与本算法相差不大,但在范围的匹配上,由于本算法加入了RPN网络,因此效果更好;而对于SiamRPN,虽然其定位准确度及配准成功率和本算法很接近,但由于本算法加入了SE-Net加强特征提取,故最终的结果要更好一些.不过KCF[16]、Struck[17]、CXT[18]、IVT[19]、MIL[20]等传统机器学习算法在这两方面的表现均与本算法相差较大.总的来说,本算法的跟踪效果更好.
为了更直观地比较跟踪效果,本文将各算法在序列dog1部分帧上的跟踪效果绘制成如图5所示的图像.从第303帧中可以看出,使用SiamRPN框架基本能框定目标;部分使用深度学习框架的算法,如FCNT和CNNSVM,虽然在定位上基本精确,但不能很好地进行范围框定;此外,利用相关滤波器进行目标跟踪的KCF算法,其定位较真实边框偏左上角,且所框选的范围也较小;而使用传统机器学习的算法,如Struck、TLD和IVT等等,在定位和配准上都有一定误差,可以看出目标定位偏右下角且距离真实边框有更多的偏移,目标范围也未完全框定.在第1006帧中,由于目标较原图更加清晰可辨,故除了CT外,其余各算法都能较好地进行定位,但在范围框定方面,机器学习算法框定的范围明显不够,而SiamRPN、FCNT和CNNSVM的边框大小也和真实边框有一定差距.同样,在第1302帧中,上述这些算法在两方面的表现上也都存在一定的问题.
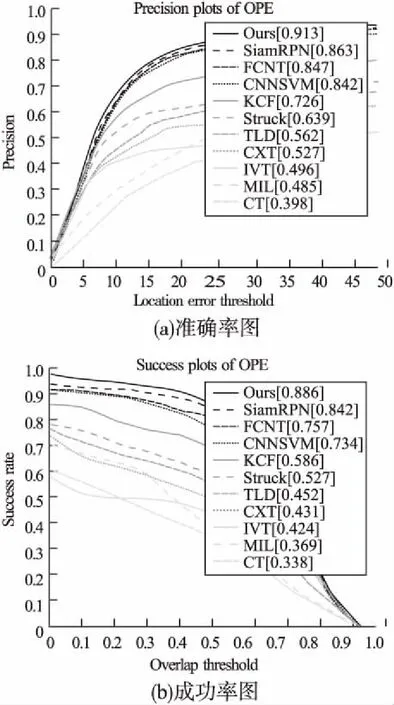
图4 OPE结果示意图Fig.4 Results of OPE

图5 不同算法跟踪效果Fig.5 Tracking results of different algorithms
本算法在孪生神经网络的基础上利用SE-Net提升特征表达能力综合考虑空间信息和通道信息两方面的特征,使网络的表达能力更强;并加入区域推荐网络RPN,使得目标定位和范围框选更加精确.最终根据仿真实验结果以及与其它算法的对比,可知本算法在目标定位和范围框定上更精准.
5 总结与展望
本文利用孪生卷积神经网络作为基础架构,不仅能够实时地进行图像比对与目标跟踪,而且预先利用模板分支保存先验知识,可以减少跟踪过程中误差的增加.同时在特征提取部分加入SE-Net,综合考虑图像的空间信息和通道信息,增强网络的特征表达能力.在目标定位阶段,本算法通过区域推荐网络,利用anchor机制和边框回归机制区分特征图中的目标和前景,并对输出结果进行线性微调,使跟踪结果更加准确.相较于之前的方法,该算法解决了网络模型更新不及时和训练数据集不足的问题,同时保证了跟踪的准确率.实验结果也表明该网络在单目标跟踪中取得了很好的效果.不过由表1可知,几种算法在第5折上的平均覆盖率都很低,经检验发现第5折数据集中遮挡和模糊的视频样本帧较多,针对这一问题的改进,是之后需要研究的地方.而且若是考虑到多目标的视频跟踪,由于其跟踪原理与单目标跟踪有较大的差别,因此对于多目标跟踪领域,也还需要做进一步的研究.
