卷积自编码融合网络的红外可见光图像融合
2020-01-14刘家祥黄淑英张迎梅吴嘉骅李露奕
杨 勇,刘家祥,黄淑英,张迎梅,吴嘉骅,李露奕
1(江西财经大学 信息管理学院,南昌 330032)2(江西财经大学 软件与通信工程学院,南昌 330032)
1 引 言
红外图像的目标轮廓清晰,热度信息丰富,但是存在视觉性不强、清晰度不高、细节信息少等缺点.可见光图像的对比度和分辨率都比较高,具有光谱信息丰富、细节信息多、视觉性好等优点,但是可见光图像抗干扰能力差.红外与可见光图像融合是将不同类型的传感器获得的红外图像与可见光图像进行融合,提取源图像中的显著特征,然后将这些特征通过适当的融合方法使其集成到单个图像中.融合算法广泛应用于许多应用中,如公共安全和军事应用等领域.
近些年来,图像融合领域得到广泛的关注.在变换域,有多尺度变换[1],基于显著性的方法[2]、稀疏表示[3,4]和定向梯度直方图[5]融合方法.在空间域,有基于引导滤波[6]和基于稠密尺度不变特征变换[7]的方法,这些方法大多数要经过复杂的图像像素点活跃度系数的测量以及复杂融合规则的制定,其实施难度与计算成本较高.
深度学习能够让计算机自动学习模式特征,并将特征学习融入到建立模型的过程中.目前,许多融合方法都以此为基础来进行研究.刘等人[8]提出了一种基于卷积神经网络(Convolutional Neural Network,CNN)的方法,CNN能够有效提取源图像的特征,但是其方法计算复杂度高,时间较长,并且忽略了许多在中间层获得的有用信息.马等人[9]提出了一种基于生成对抗网络模型的方法FusionGAN,它是一种端到端的网络模型,不用设计复杂的融合规则,但是由于GAN网络的不稳定性,其训练与测试过程都相对不稳定.李等人[10]提出了一种基于CNN的融合网络DenseFuse,可以得到较好的融合效果,但是其网络相对复杂,计算复杂度较高.
为了克服以上缺点,本文基于CNN和编解码结构,构建出一种简单、高效、泛化能力强的卷积自编码网络,并考虑到融合中需要保留图像结构信息的要求,在传统损失函数的基础上,提出了一种基于图像梯度纹理信息保留的损失函数来指导网络的训练,提高融合结果的质量.本文提出的基于卷积自编码融合网络的红外与可见光图像融合方法,是使用编码网络提取两类源图像的特征,通过融合规则来实现特征图的融合,再通过重建的解码网络获得融合图像.自编码融合网络是由卷积层构造,其中每层的输出用来作为下一层的输入.在提出的深度学习架构中,编码网络由三个卷积编码层构成,用于提取特征图,解码网络由三个卷积解码层构成.
本文融合方法首先训练卷积自编码网络,再利用训练好的卷积编码网络提取源图像相应的特征,得到多张特征图,特征图在不同维度上包含了源图像的各项信息;接着对多张图像特征图利用融合规则将其融合,得到包含所有源图像信息的特征图,然后利用卷积解码网络对其进行重建的操作,最终输出一张包含多张源图像信息的融合结果.图1给出了一个代表例子,左边两幅图像是待融合的红外和可见光图像,其中红外图像突出了目标,而可见光图像包含丰富的背景细节和纹理信息,但是关键目标信息丢失,而本文的融合结果很好地包含了红外图像的目标信息与可见光图像的纹理背景信息.

图1 基于卷积自编码融合网络的红外与可见光图像融合结果Fig.1 Infrared and visible image fusion result based on convolutional auto-encoding fusion network
论文结构如下:在第2节中,简要介绍自编码器与卷积神经网络的基础知识;在第3节中,给出了本文融合方法的详细介绍;在第4节中,将本文方法与现有的多种融合方法进行主观与客观实验对比分析;在第5节中,对本文工作进行总结.
2 自编码器与卷积神经网络
2.1 自编码器
自编码器[11]主要用于降维和特征学习的任务,对提取的高阶特征信息进行编码与解码,是一种无监督学习的非线性特征提取方法,其输出与输入具有相同的维度,隐藏层被用来对原始数据的特征进行编码.自动编码器是指保持输入与输出尽可能一致(通过信息损失来判定)的情形下,实现无监督方式下的隐层特征提取与参数学习[12].目的是让神经网络的输出能和原始输入一致.相当于在特征空间上学习一个恒等式 y=x.将原始图像作为输入,对图像进行编码解码,使提取到的特征保持输入与输出接近一致.本文将利用自编码器的结构思想,利用两个并行的编码网络分别对两类图像进行特征提取,然后对两类特征图进行融合,最后对融合后的特征图重建出与输入图像大小相同的融合结果.传统的自编码器因其无监督特征提取方法的特点,其虽可快速提取特征,但特征提取准确性与还原性却无法保证.
2.2 卷积神经网络
卷积神经网络(CNN)[13]是一种特殊的可训练权重和偏置的前馈神经网络,是深度学习中最经典的算法之一,诞生于上世纪80年代,当时只是应用于支票数字的识别,随着计算机硬件的发展和算法的创新,CNN已经在计算机视觉领域发挥了巨大的作用.CNN因为具有深度结构,以及局部感受野与共享权重的特点,使其可以提取更加完整的特征信息.以二维图像为例,CNN可以直接处理二维图像数据,通过卷积核和池化操作对原始输入进行特征提取,对输入数据进行特征表示,然后通过反向传播算法(Back Propagation,BP)进行参数的更新.CNN仿造生物的视觉感知机制构建,可以进行监督学习和非监督学习,其隐含层内的卷积核参数共享和层间连接的稀疏性使得CNN能够以较小的计算量对像素点提取特征.因此本文将利用CNN的优点,与自编码结构结合,提出一种卷积自编解码融合网络.
3 本文融合方法
本文提出的基于卷积自编码融合(Convolutional Auto-encoding Fusion,CAEFuse)网络的红外与可见光图像融合的过程,可以概括为如下四个步骤:
1)利用公共数据集训练CAEFuse网络模型的参数,选择所提出的损失函数来调整整个网络的参数训练;
2)分别对源图像A、B利用CAEFuse编码层进行深层特征图的提取;
3)对两类源图像提取的特征图采取等权重相加的融合策略,得到融合后的卷积特征图;
4)利用CAEFuse解码网络对卷积特征图进行重建,得到最终的融合图像.
3.1 卷积自编码融合网络
由于自编码网络提取信息准确率较低,单一的卷积神经网络忽略浅层特征,本文将卷积神经网络与自动编码器相结合,构建出CAEFuse网络.根据红外与可见光图像融合的特性设置卷积核的参数、调整网络框架,并根据融合特性提出一种基于图像纹理梯度信息的损失函数来指导网络训练.所提出的CAEFuse的网络框架如图2所示.该网络分为三个部分,第一部分是提取特征图的卷积编码层,第二部分为融合过程,将提取的两类图像的卷积特征图进行融合,第三部分是对于融合后的卷积特征图进行重建的解码层.第一、三部分构成一个自编码网络,需要利用数据集提前被训练,自编码网络的结构包含了三个3×3卷积核的卷积层,其步长为1,其参数设置如表1所示;在自编码网络训练好的基础上,利用第二部分的融合策略来实现编码网络中特征图的融合,再由解码网络重建融合图像.
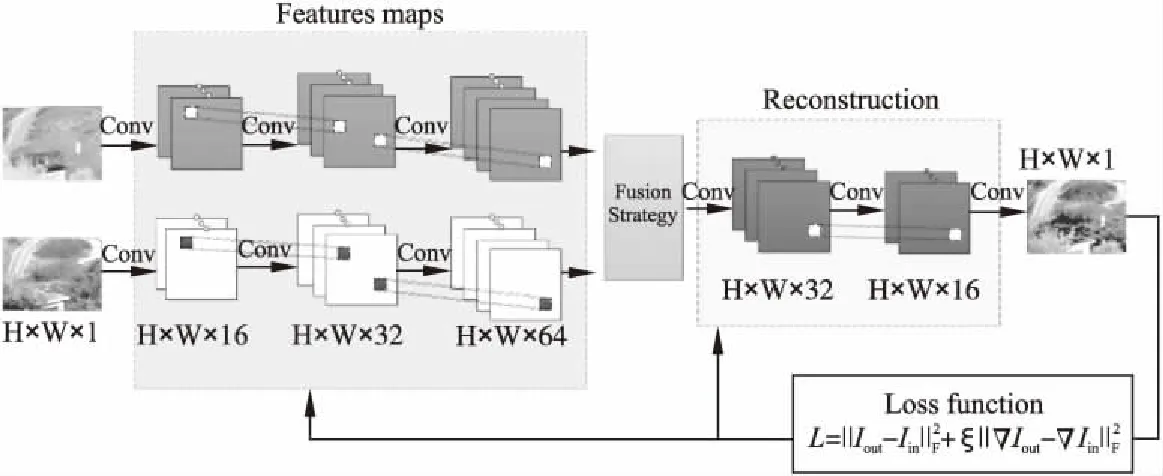
图2 本文的融合框架Fig.2 Proposed fusion framework
表1 CAEFuse结构
Table 1 Structure of CAEFuse
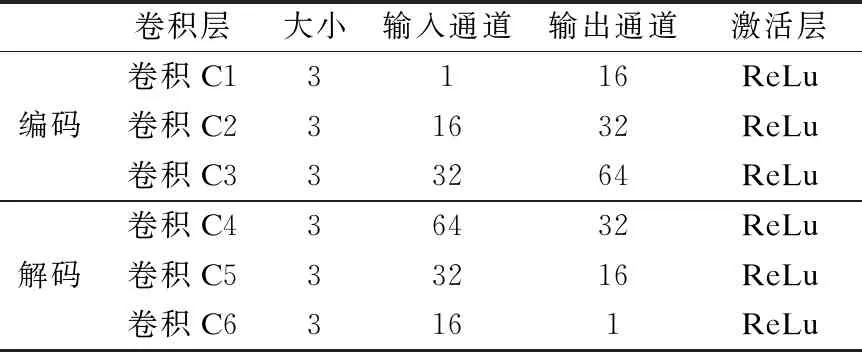
卷积层大小输入通道输出通道激活层卷积C13116ReLu编码卷积C231632ReLu卷积C333264ReLu卷积C436432ReLu解码卷积C533216ReLu卷积C63161ReLu
CAEFuse网络结构中的卷积编码层用来提取源图像的深层特征,使用卷积计算的方式,利用卷积的平移不变性,对图像上的每个像素进行卷积运算.在训练过程中,每层的卷积核会根据损失函数进行训练修正,以此降低损失.卷积计算公式如下表示:
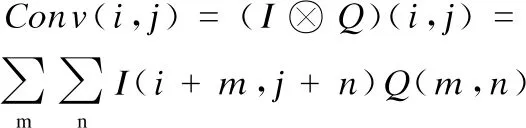
(1)
其中,⊗表示卷积运算,这个公式表示卷积核Q在输入图像I上的空间滑动,Conv(i,j)表示卷积核Q对应的输出矩阵所对应位置的元素值,Q(m,n)表示卷积核的参数,经过多层的卷积编码网络得到源图像的卷积特征图.
3.2 基于图像纹理梯度信息的损失函数
损失函数是深度学习优化中至关重要的一部分,没有一个适合所有深度学习任务的损失函数,常见的损失函数有L1损失、L2损失等,这些损失函数在分类任务中表现良好,但是在融合任务中表现不足.为了更加精准地重建源图像中包含的纹理结构,本文改进了传统的损失函数,提出一种针对于红外与可见光图像融合任务的损失函数,CAEFuse网络将通过最小化该损失函数训练得到.
CAEFuse的损失函数由两部分构成,如公式(2)所示:第一项的目的是将输入图像的全局显著性信息保留在融合图像中;第二项的目的是将输入图像的梯度纹理信息保留在融合图像中:
(2)
Iin代表输入卷积编码网络的图像,Iout代表卷积解码网络输出的图像,代表梯度算子,‖·‖F代表矩阵Frobenius范数,ξ为经过实验设置的权重参数,在本文实验中,设置为5.
为了说明本文损失函数的优势,图3选取了一组图像在不同损失函数训练网络得到的主观实验对比,从图中可以看出通过本文损失函数所得到的树枝在细节提取上更丰富,并且对比度更强.表2给出了不同损失函数训练网络所得到的8组图像(源图像见图6)的客观平均结果.其中,边缘保持度(QAB/F)[20]能够反映融合图像中纹理信息的保留程度,差异的相关系数之和(SCD)[21]代表了融合图像从源图像中获得的信息量.从表2可以看出,本文提出的损失函数在边缘保持度等指标上均优于传统损失函数,说明本文所提出的损失函数在纹理梯度信息上的提取更为丰富,获得的信息量更多.

图3 不同损失函数的融合结果对比Fig.3 Comparison of fusion results obtained by different los
表2 不同损失函数训练网络结果客观指标的对比
Table 2 Comparison of objective indicators of fusion resultsobtained by different loss functions

QAB/FSCDL2损失函数0.46901.8895本文损失函数0.48461.9037
3.3 融合策略
融合策略是图像融合中重要的一部分,本文经过大量对融合策略的对比实验,选择了特征图等权重相加的融合策略.
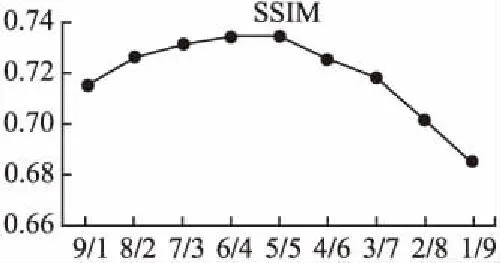
图4 加权融合策略下的不同融合权重的SSIM曲线Fig.4 SSIM curve with different fusion weights under weighted fusion strategy
图4给出了融合图像的平均SSIM[23]指标随融合权重变化曲线.从图4中可以看出,在等权重策略或6/4(红外图像/可见光图像)融合权重下SSIM达到峰值;图5给出了L1-norm〗融合策略以及加权融合策略下不同权重的融合图像,图5(a)为L1-norm融合策略下的融合图像,图5(b)-图5(j)为加权融合策略下的不同权重值的融合图像,右上角的矩形框为左下角的矩形框的放大图.从人物框处可以看出,图5(g)-图5(i)中严重丢失红外的目标信息;从树枝放大框处可以看出,图5(a)-图5(d)中严重丢失树枝的纹理信息;在图5(e)-图5(j)中,等权重策略(j)的红外信息与可见光信息保持得最完整.综上,在L1-norm融合策略下以及在加权融合策略下红外特征图的融合权重较大时,融合图像中树枝的纹理细节丢失严重;在加权融合策略下可见光特征图的融合权重较大时,融合图像中红外图像目标信息丢失严重,因此本文选择等权重相加的融合策略,其定义如下:
(3)

图5 L1-norm融合策略与加权融合策略下不同权重的融合图像Fig.5 Fused images of L1-norm fusion strategy and weighted fusion strategy with different fusion weights
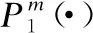
3.4 训练过程与测试过程
在训练过程中,只考虑CAEFuse网络的第一部分提取特征的编码层和第三部分重建解码层.选取多个公共数据集作为训练数据,其中包括公共数据集OSU[14](选取80组红外与可见光图像)、TNO[15](选取了40组红外与可见光图像)和MS-COCO[16](包含82700张灰度图像).训练过程是将单张图像作为输入送进网络,通过特征提取重建等过程得到输出图像,利用Adam[17]优化算法对损失函数进行最小值优化,调整整个网络参数,本文的方法是在NVIDIA GTX 1070 GPU上进行训练.通过对数据集的对比实验发现,提出的CAEFuse网络的泛化能力高,该部分将会在第三节数据集部分进行实验说明.
在测试过程中,将红外与可见光图像分别作为网络的输入图像,通过三层的卷积编码网络提取两类图像的特征图,将特征图送入融合策略进行等权重的加权融合,最后通过三层的卷积解码网络对融合的特征图进行重建,得到最终的融合结果.

图6 八组红外与可见光源图像Fig.6 Eight groups of infrared and visible source images
4 实验结果及分析
为了验证本文所提出方法的有效性,本文选择了8组被广泛用于实验研究的红外与可见光图像进行对比,其中包括people、house、plane、lake、mailbox、car、window、bridge,如图6所示.本文方法与五种当前主流的融合方法进行了比较,包括交叉双边滤波(CBF)[18]、梯度转移和总变异最小化法(GFT)[19]、卷积神经网络(CNN)[8]、融合对抗生成网络(FusionGAN)[9]、DenseFuse[10].五种方法的代码均是作者发布的,它们的参数选择均与各文献中保持一致,所有的实验均是在python3.6上实现的,实验配置是AMD Ryzen 7 2700X的CPU和NVIDIA GTX 1070 GPU.
4.1 融合图像质量客观评价指标
融合图像的质量评价主要包括主观评价和客观评价两部分.由于融合技术的不断提升,主观评价的标准已经很难发现不同融合方法得到的效果的差异.在本文中,将同时考虑融合图像的主观视觉效果和客观定量评价,其中客观定量评价通过四种常用的图像融合质量评价指标来衡量.
4.1.1 边缘信息保持度
边缘信息保持度(QAB/F)[20]使用Sobel边缘检测算子计算源图像与融合图像像素的强度和方向信息,以此衡量源图像传递到融合图像的边缘信息的多少.QAB/F的值越大说明融合图像保留了越多源图像的边缘信息.其定义为:
(4)
式中:
(5)
(6)
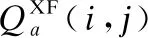
4.1.2 差异的相关系数之和
差异的相关系数之和(SCD)[21],是基于输入图像传输的最大的互补信息设计的,计算融合图像与输入图像的信息相关度.输入图像(S2)与融合图像(F)之间的差值图像可以得到从另一个输入图像(S1)的信息.反之亦然.F和S1之间的差实际上产生了从S2收集到的信息.这些差分图像(D1和D2)可以表示为:
(7)
在图像融合应用中,要求融合后的图像尽可能多地包含输入图像的信息.将D1与S1、D2与S2关联得到的值表示这些图像之间的相似性.换句话说,这些值表示从每个输入图像传输到融合图像的信息量.SCD指标利用这些相关值的和作为融合图像的质量度量.它的表达式如下:

图7 五组典型的红外与可见光图像融合结果Fig.7 Five typical fusion results of infrared and visible images
SCD=r(D1,S1)+r(D2,S2)
(8)
其中r函数计算S1与D1、S2与D2的相关关系:
r(Dk,Sk)=
(9)

4.1.3 离散余弦变换的互信息
离散余弦变换的互信息(FMIdct)[22]用来计算经过离散余弦变换的互信息.互信息是一个随机变量,其包含另一个随机变量的信息量的度量,它通过测量联合分布p(x, y)与完全独立情况下的分布p(x)·p(y)之间的Kullback-Leibler分布来衡量两个变量X和Y之间的依赖程度.
4.1.4 改进的无参考图像的结构相似度
结构相似度(SSIM)[23]通过计算图像结构的信息改变量来衡量图像的失真程度,改进的无参考图像的结构相似度定义如下:
SSIMa(F)=(SSIM(F,I1)+SSIM(F,I2))×0.5
(10)
其中,F表示融合图像,I1和I2表示输入的源图像.
4.2 图像融合实验
4.2.1 主观视觉效果
由于篇幅的限制,图7给出源图像以及六种方法的融合图像:从上到下分别是红外图像、可见光图像、CBF[18]、GFT[19]、CNN[8]、FusionGAN[9]、DenseFuse[10]以及本文方法的融合结果,从左到右分别是people、plane、lake、mailbox、car.从图7可以看出,CBF[18]方法引入噪声严重,图像严重失真,GFT[19]与CNN[8],FusionGAN[9]方法在保留纹理信息方面存在不足,造成了图像边缘处的模糊现象,相对来说,Dense-Fuse[10]的结果较好.本文提出的方法很好地融合了红外图像的整体目标信息以及可见光图像的纹理细节信息,相对于CBF[18]、GFT[19]、CNN[8]和FusionGAN[9]方法,本文方法的细节信息明显增多,原因在于用梯度算子作为损失函数的一项,更好的保留了梯度纹理信息.本文方法相对于DenseFuse[10]方法得到的结果在视觉上虽然很难看出差异,但后续的进一步分析可知本文提出的网络在训练时间与测试时间上都有较为明显的优势,具有更为简单、高效的优点,得到的融合图像在客观定量指标上表现也更好.
表3 不同融合方法得到的客观指标对比
Table 3 Comparison of objective indicators obtained by different fusion methods
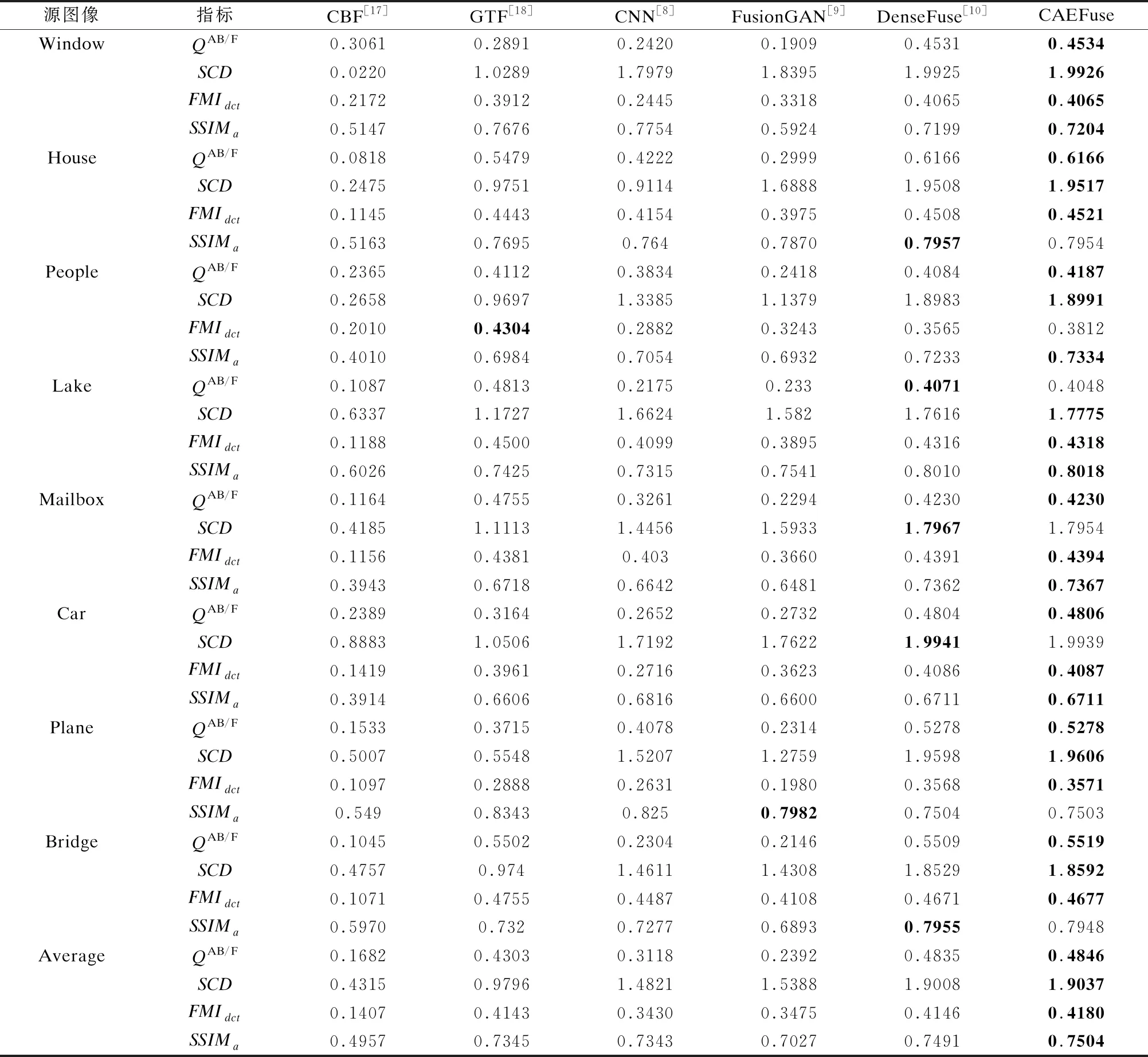
源图像指标CBF[17]GTF[18]CNN[8]FusionGAN[9]DenseFuse[10]CAEFuseWindowQAB/F0.30610.28910.24200.19090.45310.4534SCD0.02201.02891.79791.83951.99251.9926FMIdct0.21720.39120.24450.33180.40650.4065SSIMa0.51470.76760.77540.59240.71990.7204HouseQAB/F0.08180.54790.42220.29990.61660.6166SCD0.24750.97510.91141.68881.95081.9517FMIdct0.11450.44430.41540.39750.45080.4521SSIMa0.51630.76950.7640.78700.79570.7954PeopleQAB/F0.23650.41120.38340.24180.40840.4187SCD0.26580.96971.33851.13791.89831.8991FMIdct0.20100.43040.28820.32430.35650.3812SSIMa0.40100.69840.70540.69320.72330.7334LakeQAB/F0.10870.48130.21750.2330.40710.4048SCD0.63371.17271.66241.5821.76161.7775FMIdct0.11880.45000.40990.38950.43160.4318SSIMa0.60260.74250.73150.75410.80100.8018MailboxQAB/F0.11640.47550.32610.22940.42300.4230SCD0.41851.11131.44561.59331.79671.7954FMIdct0.11560.43810.4030.36600.43910.4394SSIMa0.39430.67180.66420.64810.73620.7367CarQAB/F0.23890.31640.26520.27320.48040.4806SCD0.88831.05061.71921.76221.99411.9939FMIdct0.14190.39610.27160.36230.40860.4087SSIMa0.39140.66060.68160.66000.67110.6711PlaneQAB/F0.15330.37150.40780.23140.52780.5278SCD0.50070.55481.52071.27591.95981.9606FMIdct0.10970.28880.26310.19800.35680.3571SSIMa0.5490.83430.8250.79820.75040.7503BridgeQAB/F0.10450.55020.23040.21460.55090.5519SCD0.47570.9741.46111.43081.85291.8592FMIdct0.10710.47550.44870.41080.46710.4677SSIMa0.59700.7320.72770.68930.79550.7948AverageQAB/F0.16820.43030.31180.23920.48350.4846SCD0.43150.97961.48211.53881.90081.9037FMIdct0.14070.41430.34300.34750.41460.4180SSIMa0.49570.73450.73430.70270.74910.7504
4.2.2 客观定量评价
为了进一步验证本文方法的性能,本文对六种方法的结果进行了客观质量评价.利用QAB/F[20]和SCD[21]、FMIdct[22]、SSIMa[23]对融合结果进行定量分析,评价结果如表3所示,其中黑色加粗为所有方法中的最大值.
从表3中可以看出,本文方法的四种定量指标大部分都能得到最大值,少数指标是第二大值,所提出方法的客观指标明显优于传统融合方法CBF[18]和GTF[19],也优于CNN[8]、FusionGAN[9]、DenseFuse[10]等深度学习融合方法.从平均定量指标来看,本文方法的结果都是最优的.因此,综合全部评价指标的结果来看,本文方法在有效信息提取上优于其它五种主流方法.
4.2.3 算法效率分析
在时间上,表4给出了不同红外与可见光图像融合的方法在八组融合实验中的平均耗时.从表4可以看出,在对比方法中,GTF[18]和DenseFuse[10]是效率较高的两种方法,分别需要4.88秒和3.53秒.CNN[8]是最耗时的方法,这是由于CNN[8]方法中结合了传统方法,计算复杂度较高,本文提出的方法是所有对比方法中效率最高的方法,可以达到准实时任务的响应需求.因此,可以证明本文方法与其他方法相比,性能优越.
表4 不同融合方法的耗时对比
Table 4 Comparison of time-consuming of different fusion methods

融合方法耗时/sCBF17.27GTF4.88CNN132.15FusionGAN8.52DenseFuse3.53CAEFuse3.14
表5 不同网络模型的模型大小与训练时间的对比
Table 5 Comparison of model size and training time of different network models

模型模型大小(kb)训练时间(s)CAEFuse5462.55DenseFuse87023.15
在模型和训练成本上,表5给出了DenseFuse[10]与本文方法的模型大小与训练时间对比,可以看出本文提出的模型训练时间(该训练时间指的是在TNO[15]数据集上迭代一次的时间)上优于DenseFuse模型,CAEFuse网络模型更为简单、高效.
4.3 数据集
本文利用了不同数据集来训练CAEFuse网络模型,接下来将讨论不同数据集对于网络的影响,说明网络的泛化能力.
本文对三组数据集OSU[14]、TNO[15]和MS-COCO[16]训练得到的模型分别进行了实验.选取八组红外与可见光进行融合测试,得到的客观指标的平均值如表6所示.
表6 MS-COCO与TNO、OSU数据集训练网络结果客观指标的对比
Table 6 Comparison of objective indicators of training network results on MS-COCO, TNO and OSU datasets
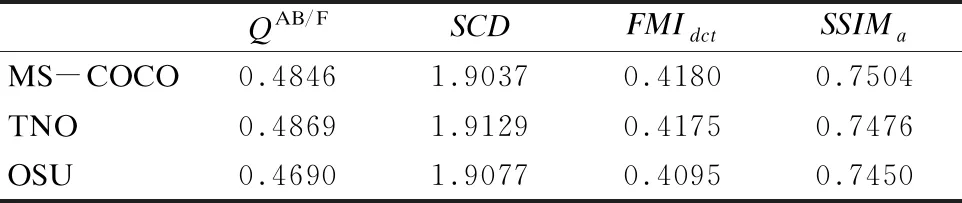
QAB/FSCDFMIdctSSIMaMS-COCO0.48461.90370.41800.7504TNO0.48691.91290.41750.7476OSU0.46901.90770.40950.7450
从表6中,可以看出利用三种训练集训练得到的网络模型进行融合,其客观结果基本接近,说明我们构建的网络模型对于训练集有着很强的泛化能力,可以通过小数据集迅速调整网络参数,提高训练的效率.
5 结 论
本文针对红外与可见光图像融合中纹理信息保留不全的问题,基于CNN和自编码结构的优点,提出了一种基于卷积自编码融合网络的红外与可见光图像融合方法.该方法首先利用训练集训练卷积自编码网络,然后利用等权重相加的融合策略对编码网络得到的特征图进行融合,最后利用解码网络得到融合后的图像.实验证明,所提出网络模型在不同大小的公共数据集上,网络收敛较快,具有很强的泛化能力.该融合方法用于红外与可见光图像融合时,能同时保持红外图像的整体目标信息以及可见光图像的纹理细节信息,融合后图像能够清晰地突出目标与丰富细节信息.本文同时使用主观评价与客观指标来评估提出的方法,与五种主流的融合方法进行了实验对比,实验表明本文的结果无论在视觉效果还是客观指标上皆优于其它主流方法,并且无论从网络训练时间、测试时间上,其效率也都优于其它方法.
本文提出的CAEFuse网络由于对数据集的低依赖性,同样也是处理其它融合任务的通用框架,下一步将考虑将其应用在其它融合任务,希望同样能够得到好的融合性能.
