用户相关反馈下的空间关键字语义查询方法
2020-01-14孟祥福赵路路张霄雁
孟祥福,赵路路,张霄雁,李 盼
(辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛 125105)
1 引 言
随着GPS等定位服务技术的出现,获得地理空间维度信息变得容易,Web上因此也出现了越来越多具位置信息的空间对象,如酒店、咖啡厅和旅游景点等,这些空间对象通常被称为兴趣点(Point of Interest,POI).一个空间对象o主要包含空间信息和文本信息两部分,空间信息通常由经纬度表示,文本信息是对空间对象的文本描述.空间关键字查询q是以地理位置和关键字作为参数,目的是从空间对象集合中获取位置相近和文本相似的空间对象.一个空间关键字查询q的形式为:q(loc,keywords,k,α),其中q.loc代表查询位置,q.keywords是查询关键字集合,k是指定返回的结果个数,α∈[0,1]是一个权重系数.
目前,普遍采用的空间对象o与查询q的相关度计算方法是将空间相近度和文本相似度加权组合.然而,该类方法存在两个方面的不足:
1)仅从文本形式上匹配查询关键字,而普通用户的查询意图通常是不明确的,因此需要语义层面的查询匹配;
2)查询关键字的权重仅根据关键字在空间对象文本信息中的出现频率评估,没有考虑用户对不同查询关键字的偏好程度,这很可能导致返回结果与用户期望之间的偏差较大,因此,需要依据用户的相关反馈来挖掘用户隐式偏好并以此来调整查询关键字的权重.
来看一个例子.图1给出了一个空间关键字查询和5个空间对象.空间关键字查询条件为:
q:(location,{beefsteak,music})
该查询表达的含义是:用户想要在其位置附近寻找提供beefsteak和music服务的餐厅.o1~o5是附近的餐厅和茶馆,每个对象包含了查询q与其之间的规范化欧式距离以及该对象包含的文本信息.如果按照目前普遍采用的相关度计算方法,o2、o5和o1将是查询结果(其中,α=0.5,k=3).然而,实际上并不一定所有的用户都对上述查询结果满意,或许某些用户为了方便不愿意到远地方而选择o3,即o3也可能是某个或某些用户的top-3选择之中.也就是说,上述方法并没有体现用户的个性化和语义查询需求.

图1 空间关键字查询的例子Fig.1 An example of spatial keyword query
针对上述问题,本文提出一种基于用户相关反馈的空间关键字个性化语义查询方法.该方法分为两个阶段:第一阶段,在离线处理过程中,采用Gibbs方法和LDA主题模型对空间对象的文本信息进行语义扩展,使得数据库中的每个空间对象都在原来文本信息基础上增加了语义相关的文本描述.第二阶段,对于一个给定的空间关键字查询,先采用IR-tree索引到语义扩展后的空间数据库中获取包含k个对象的候选查询结果集,并要求用户从中明确标注出自己感兴趣的空间对象(即相关反馈);然后,根据用户的反馈信息,采用改进的Rocchio算法对查询关键字的权重进行更新,形成新的查询条件;接下来,利用更新后的查询条件对数据库进行检索,重复执行上述过程,直到结果令用户满意为止.
2 相关工作
近年来,Internet上兴趣点的大量增加以及移动设备的普遍应用,网络上出现大量的空间对象,因此空间关键字查询的研究已成为当前数据库查询领域的研究热点.根据文献[1],空间关键字查询大致分为4类:(1)布尔范围查询(2)布尔KNN(k近邻)查询[20](3)top-k范围查询[3](4)top-kKNN(k近邻)查询[4].该查询通过兴趣点与查询点之间的空间距离以及兴趣点的文本描述和查询关键字之间的文本相似度的加权组合来度量.空间对象o与查询q的位置相近性计算方法使用欧式距离,文本相似度方法使用余弦相似度方法计算.
然而,需要指出的是,现有的空间关键字查询仅在形式上匹配关键字,只考虑文本相似度而未考虑查询与文本的语义相关度以及用户对不同查询关键字的偏好程度.
对于文本间的相似度研究已有很多工作,主要可分为2大类:一是余弦相似度,二是基于主题模型.
Salton等人提出的向量空间模型的计算方法,将文本信息转化为文本向量,然后使用余弦相似度计算文本间相似度.
Chris H.Q.Ding等人提出隐性语义标引(LSI)模型,将高维向量空间中的文本向量映射低维潜在语义空间中,再计算其文本间相似度[26].Blei,Ng,Jordan使用LDA模型,进行文本建模,通过文本中词项(term)的共现特征发现文本的主题结构.LDA比VSM增加了概率的信息,更侧重语义的挖掘.
与现有方法相比,为了理解空间对象文本信息反映的语义信息,本文使用Markov-Chain Monte Carlo算法中的一个特例Gibbs Sampling算法,同时为了快速有效的获得空间关键字查询结果,使用IR-tree进行检索.并且本文进一步研究用户相关反馈来了解用户查询的需求.
3 空间对象的语义扩展和候选集生成
本节主要描述基于LDA-Gibbs模型的空间数据库的语义扩展方法,以及基于IR-tree索引的候选查询结果集生成方法.
3.1 相关定义
给定一组空间对象集合O={o1,o2,...,on},空间对象o∈O包含了位置信息o.loc和文本信息o.doc.一个空间关键字查询q的形式为:q(loc,keywords,k,α),其中q.loc代表查询位置,q.keywords是查询关键字集合,k是指定返回的结果个数,α∈[0,1]是一个权重系数.目前,普遍使用的空间对象o与查询q的相关度计算方法为:
Score(o,q)=α·Sspatial(o.loc,q.loc)+(1-α)·
Stext(o.doc,q.keywords)
(1)
其中,Sspatial和Stext分别代表o与q之间归一化的位置接近度和文本相似度[4,14,19,21,23].
空间对象o与查询q的位置相近性计算方法如下:
(2)
其中,dist(o.loc,q.loc)表示o与q之间的欧式距离,MaxDist表示o与所有空间对象的最大距离.
空间对象o与查询q的文本相似度评估的基本思想是,先将空间对象文本和查询关键字进行向量化处理,分别用Vo和Vq表示(向量的维度是所有空间对象文本信息中包含的不同关键字总数),再利用余弦相似度方法计算文本相似性,计算方法如下:
(3)
3.2 利用 LDA-Gibbs模型对空间数据库进行语义扩展
对空间数据库进行语义扩展的基本思想是,(1)先将数据库中的所有空间对象文本信息集成到一个文档中(假设该文档包含了K个主题);(2)然后利用LDA模型生成该文档的主题分布,再针对某个主题生成相应的词分布,在某个主题的词分布中随机选择一个词,重复该过程,直到某个主题下拥有若干个词;(3)将空间对象o的文本信息o.doc中的关键字与生成的主题-词分布中的词进行比较,若相同,则将该词对应的主题下的词(该词的φk,t应大于给定的阈值)加入o.doc中,生成新的文本信息,从而使得新的文本信息体现了原有信息的语义.
3.2.1 LDA主题分布
图2为LDA概率模型图.其中,α是文档中主题的多项分布的Dirichlet先验参数;β为主题下的词的多项分布的Dirichlet先验参数;zn为文档第n个词的主题;wn为该文档第n个词;K是主题数;N为该文档中词的个数.θ和φk都是需要求解的未知隐含变量,θ表示该文档下的主题分布,φk为第k个主题的词分布.
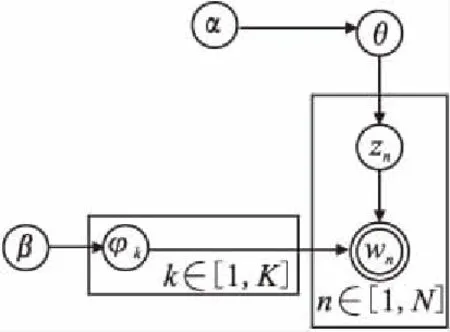
图2 LDA概率模型图Fig.2 LDA probability model diagram
假设空间数据库中所有空间对象的文本信息构成的文档为D,wn是可以观察到的已知变量,α和β是根据经验给定的先验概率,本文取α=0.5,β=0.1.根据图2的LDA的概率模型图,主题和单词的联合概率分布可表示为:
(4)
3.2.2 基于Gibbs Sampling的LDA学习过程
本文采用Gibbs Sampling算法来学习未知隐含变量是θ和φk.Gibbs Sampling的执行方法为每次选取概率向量中的一个维度,给定其他维度的变量值随机选取当前维度的值.不断迭代,直到收敛输出待估计的参数.图3给出了基于Gibbs Sampling的LDA学习过程.

图3 基于Gibbs Sampling算法的LDA学习过程Fig.3 LDA learning process based on Gibbs Sampling algorithm
该过程首先初始化文档D中的每个词,并且随机分配主题,然后统计每个主题z下出现词w的数量和该文档下出现主题z中的关键字的数量,即n(w|z)和n(z|D).每一轮计算p(zi|z-i,d,w),根据其他词的主题分配来估计当前词的主题属于各个主题的概率.根据当前词属于所有主题z的概率分布为该词随机选取一个新的主题.循环执行更新下一个词的主题,当θ和φk收敛时,算法停止,输出估计的参数θ和φk.其中p(zi|z-i,d,w)是Gibbs updating规则,计算公式如下:
(5)
当Gibbs sampling 收敛后,根据文档D中所有单词的主题分配来计算θ和φk.文档D上主题的后验分布和每个主题下的词后验分布计算方法如下:
p(θ|z,α)=Dir(θ|nDOC+α)
(6)
p(φk|z,w,β)=Dir(φk|nk+β)
(7)
然后,使用Dirichlet分布的期望计算公式
就可得到两个Multinomial分布的参数θ和φk的计算公式:
(8)
(9)
3.2.3 空间对象文本信息的语义扩展
将空间数据库中每个空间对象的文本信息根据LDA-Gibbs模型学习到主题-词分布进行隐式语义分析,将原空间数据集扩展成具有语义的新的空间数据集.即将空间对象o的文本信息o.doc中的关键字与主题-词分布中的词进行比较,若相同,则将该词对应的主题下的词(该词的(k,t大于0.07)加入o.doc,生成新的文本信息,使得新的文本信息更全面表达了原有文本信息的语义.
下面利用图1说明使用Gibbs Sampling算法对空间对象文本进行语义扩展.将图1中兴趣点的文本信息集成到一个文档,并且假设主题数为2,然后LDA模型得到主题-词分布,如下:
Topic0:beefsteak 0.25 pizza 0.745454
Topic1:tea 0.598125 music 0.396975
最后将o1~o5中关键字与主题-词分布中的词进行匹配,匹配相同且参数值大于0.5的加入o1~o5,扩展成新的空间对象集合为:
o1:(0.25,beefsteak,tea,pizza)
o2:(0.3,beefsteak,pizza)
o3:(0.1,pizza,tea)
o4:(0.3,tea,music)
o5:(0.2,beefsteak,music,pizza,tea)
3.3 候选集获取
本节主要研究基于IR-tree索引的空间关键字查询选取候选集.IR-tree 本质上是一棵 R-tree,每一个节点都参照一个倒置文件来丰富包含在该节点的子树中的对象.IR-tree是由R-tree空间索引和文本索引倒排列表Inverted file组成.R- tree将空间对象及索引空间用最小边界矩形(Minimum Bounding Rectangle)来近似表示,将空间相邻的对象组织到同一结点或同一分支, 并将一个结点对应成一个或者多个磁盘页.该索引策略大大减少了I/O 访问.倒排索引是一种简单高效的文本索引, 它列出了每个关键词以及包含该关键词的所有对象.
IR-tree的每个节点包含两种类型的信息,即子树的最小边界距离和包含关键字的倒排列表.图4和图5分别给出了根据图1中的空间对象构建的IR-tree.

图4 最小外接矩形Fig.4 Minimum external rectangle
图4为最小外接矩形,其中o1~o5对应图1中的5个空间对象,R1~R5对应为最小外接矩形.图5是根据图4构建的IR-tree结构,根节点是R5,中间节点是R3和R4,叶子节点是R2和R1.每个节点记录了以该节点为根的子树中所有对象的文本信息(关键字集合)及指针.并且每个节点的信息分为两个部分指针和条目集合(entries),指针指向包含该节点所有关键字的到排文件(InvFile).叶节点的每个条目包含一些形式为(oi,rectangle,oi.di)的条目,其中oi表示空间对象集合O中的对象,rectangle(矩形)是对象oi的边界矩形,oi.di是对象oi的文本信息的标识符.非叶节点包含多个形式的条目(cp,rectangle,cp.di),其中cp是非叶节点的子节点的地址,rectangle是子节点条目中所有矩形的最小边界矩形 ,并且cp.di是文本信息的标识符.
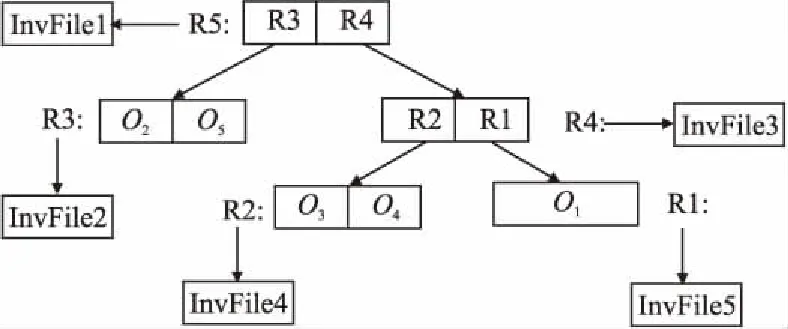
图5 IR-tree结构Fig.5 IR-tree structure
利用IR-tree索引获得位置文本匹配结果的过程为:
1)初始化优先队列U和一个列表V,U存储IR-tree中已访问的条目(entry),列表V用来存储候选集,e为带有关键字集合的倒排列表和矩阵的条目.
2)给定一个查询q,以迭代方式从U中删除顶部条目给e,若e为空间对象,则添加到V中,若e为非叶子节点,则判断查询q与节点矩形之间的最小距离是否小于e与查询q间的距离,若有小于,则判断查询q中的关键字集合和节点e的子条目中的关键字集合是否有交集,有交集则e的子条目添加到U中;否则,若e为叶子节点,那么获得查询q和空间对象之间距离,若该距离比e与查询点间的距离小,则判断查询q中的关键字集合和节点e包含的对象中的关键字集合是否有交集,若有交集则将e包含的对象添加到U中.如果U为空,则中止上面的进程.
3)根据score函数将检索到的结果集V进行top-k排序,获得得分最高的前k个对象作为用户反馈的候选集.
在图1所给的实例中,使用IR-tree检索到与查询相关的结果为o5和o1.
上述利用IR-tree索引进行空间关键字查询处理的过程如算法1所示.
算法1.生成候选集
输入:数据集D,查询q,k
输出:候选集S
1.初始化一个空列表V
2.初始化一个优先队列U
3.将tr的根节点加入U
4.whileU是否为空 do
5.e←U中顶部条目
6.ife是空间对象othen
7.e添加到V中
8. break;
9.else
10. ife为非叶子节点 then
11. for 每个子条目eiinedo
12.if(他们之间距离小于e与查询间的距离
13. and 每个子条目包含关查询键字)
14.ei添加到U中
15. else
16. for 每个空间对象oiinedo
17.if(他们之间距离小于e与查询间的距离
18. and每个空间对象包含关查询键字)
19.oi添加到U中
20.S←使用score函数从V中选出前k个空间对象
空间数据库中存在大量的空间对象.在反馈过程中,每个回合中通过整个空间数据库进行用户反馈是不现实的.因此这个阶段的目的是通过生成一个较小的候选集合,将其提供给用户来进行反馈.算法1为第4节相关反馈的个性化查询做准备.
算法1中第1、2行是初始化过程,3~19行是进行IR-tree的初始检索,第20行是使用score函数选出检索结果的前k个空间对象作为候选集.使用IR-tree进行初次检索获取候选集,其时间复杂度为O(|q.φ|·log|O|).其中|q.φ|为查询q中关键字数,|O|为空间数据库中空间对象数量,使用score函数的KNN的时间复杂度为log|O|.
4 基于用户相关反馈的个性化查询方法
4.1 相关反馈基本思想

图6 基于Rocchio算法的相关反馈过程Fig.6 Related feedback process based on Rocchio algorithm
通过用户的相关反馈,目的是增强语义相关文本信息中的出现的关键字的权重,降低在非相关文本信息中出现的关键字的权重,进而用户可以逐渐接近其实际需求,最终得到用户满意的结果.基于Rocchio算法的相关反馈过程如图6所示.
4.2 基于Rocchio算法评估关键字权重
现有方法通常采用式(3)衡量查询关键字与空间对象文本之间的相似度,其中Vo和Vq是维度相同的向量,令Vo={d1,d2,…,dn},Vq={q1,q2,…,qn}.其中,di和qi分别为空间对象和查询中包含的关键字权重,n代表空间对象集合的文本信息与查询条件中包含的所有不同关键字总数.
关键字的权重使用tf-idf方法计算,公式如下:
wti=tf(ti,o.doc)*idf(ti,O)
(10)
其中词频tf(ti,o.doc)为关键字ti出现在o.doc的频率,逆文档频率idf(ti,O)=log(1/f(ti,O)),f(ti,O)表示包含关键字ti的对象个数.
在进行基于用户相关反馈的查询扩展时,查询中的关键字的权重使用基于Rocchio算法进行重新计算,得到
(11)
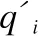
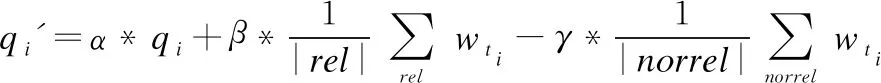
(12)
其中,β部分为正反馈,γ部分为负反馈,α、β、γ取值为了调整原查询、相关和不相关对象中文本信息之间的相对重要性.lton和Buckley的实验发现,一般取α=1,β=0.75,γ=0.25时,Rocchio算法实现的效果最好[11,24].其中wti权重使用公式(10)计算.
结合图1是空间关键字查询的例子,对于空间关键字查询q,假设认为o1、o2、o5是相关的,o3、o4是不相关的.利用Rocchio公式计算扩展后的查询q′:
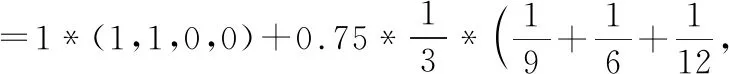
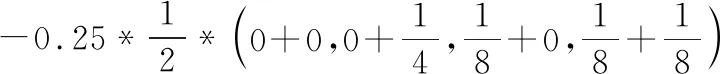
=(1.09028,1.00000,0.05208,0.00521)
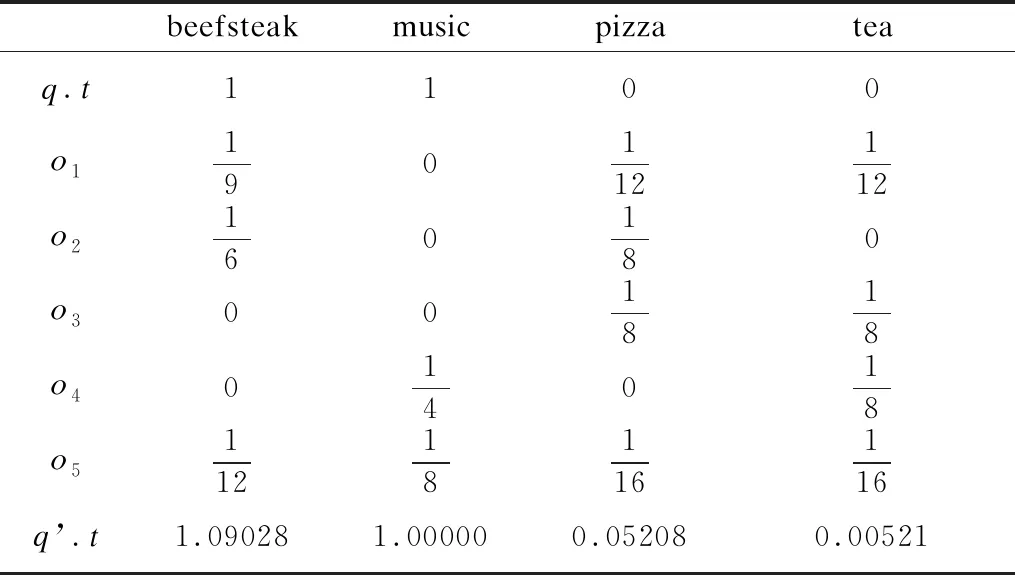
表1 查询和对象的文本信息中关键字权重Table 1 Keyword weights in query and object text information
根据表1和式(3)计算后,得到表2,如下:

表2 查询与对象间的文本相似度Table 2 Text similarity between queries and objects
由表2可以看出,尽管对象o3与查询无关,但反馈后的新查询与对象o3具有语义相关性,原因是与查询相关的对象o1、o2和o5包含对象o3文本信息中的关键字.在查询过程中,查询关键字出现的越少,越可能出现此情况.总体而言,基于Rocchio算法的相关反馈,提高了相关对象的语义相关度,提高了查询的用户满意度.
基于用户反馈的空间关键字查询的具体过程如算法2.
算法2.基于Rocchio算法的反馈过程
输入:候选集S,查询q
输出:结果集P
1.向量化候选集S中对象的文本信息d
2.向量化查询q的文本信息q.t
3.初始化空列表P,rel,norrel
4.whiletruedo
5. 将S中的对象呈现给用户
6.rel←用户从S中选择喜欢的对象oi
7.norrel←用户从S中选择不喜欢的对象oi
8. 基于Rocchio公式计算q′.t
9.S←利用IR-tree对查询条件q′.t检索
10. if terminate is true then
11.P←S
12. break;
13.returnP;
基于Rocchio算法的反馈过程中IR-tree检索的时间复杂度为O(|q.φ|·log|O|).其中|q.φ|为查询q中关键字数,|O|为空间数据库中空间对象数量.
4.3 用户反馈终止条件
用户相关反馈的中止方法有两种:一是用户自己判断最终结果是否满意;二是系统自动计算中止阈值.本节给出一种系统自动判断中止阈值的方法.
令fm和fm-1分别表示第m轮和m-1轮用户反馈得到的结果,两个集合相交,如果交集到达一定数量,则终止用户反馈,计算方法见公式(13):
(13)
terminate的取值越小用户反馈越容易终止,但查询的结果集不理想.最后将查询结果集中的对象与新查询的距离相近性和文本相似性用公式(1)将查询结果集进行排序,score越大与查询越相关.
5 效果与性能实验评价
5.1 实验设置
数据集:本文使用从Yelp商户点评网站上抓取的真实的POI数据集来进行实验研究.Yelp是美国著名商户点评网站,其网站包含了各地餐馆、购物中心、酒店等各个领域的商户信息以及用户评价和购物体验等.将这些真实POI数据进行处理174567个兴趣点,使得每个POI兴趣点都有一个ID、位置(以经纬度的形式表示)和用户评论.使用位置作为空间信息,用户评论作为文本信息.
查询集:在数据集中随机选择10个对象作为查询条件,将其空间位置作为查询位置,从文本信息中随机选择一定数量的单词作为查询关键字.在进行空间关键字查询过程中,将该对象从数据集中排除.查询关键字数量分别是2、4、6和8.
5.2 实验结果与分析
5.2.1 用户满意度调查实验
用户满意度分析:该实验目的是测试现有计算位置相近度和文本相似度方法(即公式(1),且α=0.5)与本文方法在用户满意度方面的差别.其方法使用如下公式:
(14)
其中,{relevant}表示用户标注的与给定查询相关的10个对象,{top-10retrieved}表示本文提出的空间关键字查询方法得到的前10个对象.
实验设置:参加测试的用户数量多少会对查询结果产生影响,用户测试数量在5~8个左右,就几乎能得到所有结果,更多的测试用户和使用5个用户的结果是相同的.
邀请5名用户,对于每一个测试查询条件q,每位用户使用本文方法获得前5个相关对象,然后再用文本相似度方法(公式(1))获得前5个对象,这样可以得到30个空间对象(如果有重复对象,则去重并从空间数据库随机选取对象加入,使其生成为30个空间对象的集合).
另外邀请1名用户,令其在每个查询对应的30个对象构成的测试集中,分别选取他认为与给定查询最相关的前10个对象,这10个对象作为评价查准率的标准.
然后分别利用文本相似度方法(公式(1))和本文方法获得前10个对象,进而利用公式(14)计算查询的准确性(即标准的10个对象与不同方法检索到的10个对象的重叠度).图7给出了同一个用户在不同查询条件下获得的查询结果的准确性.

图7 不同查询条件下文本相似度方法和使用用户反馈获得结果集的准确性Fig.7 Text similarity method under different query conditions and the accuracy of the result set obtained by user feedback
邀请10名用户(分别是导师、研究生同学和部分本科生),在测试集中选取与某个查询最相关的前10个对象.然后在利用文本相似度方法(公式(1))和本文方法分别获得与该查询相关的前10个对象,查看用户的满意程度.图8给出了不同用户在相同查询条件下获得的满意度对比.
根据图7、图8分别计算平均准确性,不同查询条件下,同一个用户使用文本相似度方法获得结果集的准确性为0.38,使用用户反馈方法的准确性为0.73.不同用户使用文本相似度方法获得结果集的准确性为0.41,使用用户反馈方法的准确性为0.79.由此可见,本文方法获得的查询结果的用户满意度较高,这是因为经过空间对象文本信息的语义扩展和用户相关反馈,本文方法能够获得更能满足用户语义需求和偏好的结果.
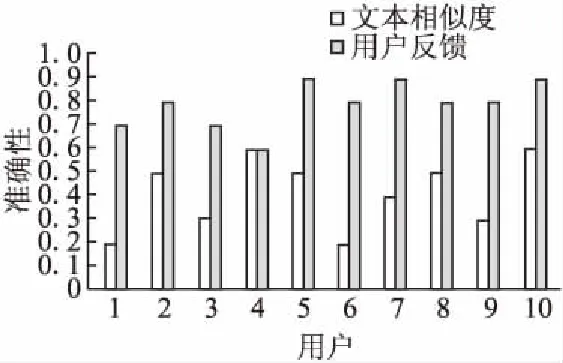
图8 不同用户使用文本相似度方法和使用用户反馈获得结果集的准确性Fig.8 Different users use text similarity method and use user feedback to obtain the accuracy of result set
5.2.2 反馈终止
该实验目的是评价终止阈值τ对基于Rocchio算法的用户反馈的收敛速度的影响.我们将最多的轮数限制为10,以避免很难达到的情况.其中,取候选集的数量k=10,20,关键字数量n=8,τ的取值为0.2,0.4,0.6,0.8.图9是终止阈值τ的影响.
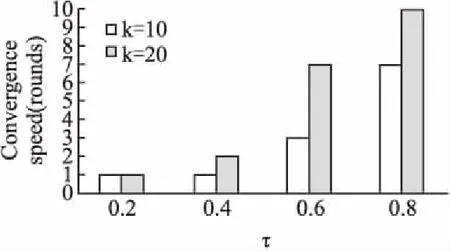
图9 终止阈值τ的影响Fig.9 Impact of the termination threshold
从图9可以看出随着k值得变大,其该轮得到的结果集和上一轮相交所得的交集越大,收敛速度变慢,反馈的轮数增加.当τ值设置过高时,用户反馈过程甚至不能终止.
一般情况下用户反馈7轮就能得到满意结果.
6 结 论
为了更好的理解用户的查询意图,本文提出基于用户相关反馈的空间关键字个性化语义查询方法.将空间数据集进行语义扩展,使得新生成的文本信息体现了原有信息的语义.然后进行相关反馈,得到最终的结果集,此结果集最接近用户查询,最能满足用户的查询需求.通过实验,可以看出使用用户反馈比文本相识的方法的准确率高,说明基于用户反馈的空间关键字查询获得的结果集更加接近查询,更符合用户的查询意图.
本文与现有方法的不同之处在于体现了原有信息的语义并且使用用户反馈体现了个性化查询,在空间关键字查询的检索实验中,发现本文提出的方法对于提高用户效率以及满足用户的查询需求是有效的.
