一种基于IABC-RF的ICU患者心衰死亡率预测模型
2020-01-14帅仁俊李文煜
郭 汉,帅仁俊,张 欣,李文煜,李 鑫
(南京工业大学 计算机科学与技术学院,南京 211816)
1 引 言
因为ICU患者的特殊性,医院在人员、设备及技术上都予以最佳保障,通过连续或接近连续的观察、诊疗和监护,以达到良好的医疗效果[1,2],同时医疗费用也比较昂贵.ICU患者通常病情危急、病情多变,仅通过有丰富经验医生的主观经验及医学手段来做出重大决策进行诊疗已经显露出一些局限性[3,4].尽管付出了巨大的努力,但每天仍然有很多生命逝去,因此迫切需要将大量重症监护数据库利用起来,通过建立数据与疾病之间的联系,来辅助医生决策[5],对ICU患者的死亡率做出更快、更准确的预测.
重症监护室数据集样本数量及复杂程度一直保持增长状态,同时ICU数据相比起普通的电子病历数据其维度更高、更密集,给机器学习方法提供了有利的条件[5].心力衰竭(heart failure)简称心衰,是各种心血管疾病的终末阶段,对机体多个重要脏器造成侵袭并影响其正常功能.有将近5%的ICU入院是与心力衰竭相关的,并且这是导致死亡的主要原因之一.据有关报道,对不同受试人群调查,心力衰竭患者在1年内全因死亡率达30%,其中重症心力衰竭患者在确诊后第1年内全因死亡率超过20%[6].因此,预测ICU心力衰竭患者死亡率是一个非常重要的问题.医生可以根据预测结果进行辅助医疗,对于高死亡率的病人,及时采取有针对性的诊治手段以避免错失最佳治疗时机;对于低死亡率的病人,减少药物的过度使用,也更有益于患者和卫生保健资源的合理分配.
随机森林[7]是通过集成学习的思想将多棵树集成的一种算法,其因具有极好的准确率、在生成过程中能够获取到内部生成误差的一种无偏估计等特点,有着广泛的应用前景,可用于市场营销模拟建模,统计客户来源,保留和流失,也可用来预测疾病的风险和患者的易感性等领域.由于许多合并症会导致心衰死亡率的加剧,研究不同合并症对ICU患者心衰死亡率的影响,能够找出更容易预测死亡率的患者群.蜂群算法在多变量函数问题中具有较强的优化能力,结合蜂群的觅食行为与随机森林思想在真实ICU病患数据集上构建模型实现对ICU病患的心衰死亡率预测.本文主要做出了如下贡献:
1)首次在ICU患者心衰死亡率预测研究中结合改进的迭代加深搜索蜂群算法和随机森林,改善优化性能的同时也极大地提高了模型的性能,有助于更准确、更快地预测心衰死亡率;
2)考虑到不同合并症会加剧心衰的死亡率,研究几种不同合并症下的心衰死亡率,更易找出死亡率较高的患者群;
3)在真实的ICU病患数据集上验证本文提出方法的有效性.
2 相关工作
在过去几十年中,大多数研究都集中在疾病的严重性评分系统或数据挖掘模型[4],这些模型设计用于 ICU入院后至少24或48 小时的风险评估.一些文章已经讨论并比较了依赖专家小组[8]或统计分析模型的ICU患者的死亡率预测模型.ICU 中最常见的危重症评分模型虽然都是基于逻辑回归,但在实际构建模型训练过程中采用的策略并不同.常用的APACHE[9]和SAPS[10]评估在实际建模过程中就采用不同策略对疾病严重程度加以预测.
但基于逻辑回归的传统ICU病人死亡风险预测模型更新十分缓慢.为了获得更优的预测性能,越来越多的研究从数据挖掘角度出发,开发机器学习模型.谢俊卿等[4]为基于本地电子病历数据预测ICU患者死亡风险的研究者提供必要的概念、步骤与方法,在临床医生最为熟知的逻辑回归模型的基础上,阐述了人工神经网络、决策树和支持向量机三种机器学习模型的基本框架以及优劣势.Awad等[1]强调了ICU患者早期死亡率预测的主要数据挑战并引入了新的机器学习基于重症监护病房患者早期死亡率预测的框架.所提出的方法在重症监护多参数智能监测II(MIMIC-II)数据库中进行评估.Baxt等人[11]认为神经网络特别适合对复杂临床场景进行建模,文献[12]使用C4.5来构建死亡风险预测模型.Wong等[13]采用基尼指数作为其节点分割规则生成分类回归树,但预测因素较多时,模型就会过于复杂.Moridani[14]利用SVM构建模型预测ICU患者中心血管病人的死亡风险,结果表明SVM优于人工神经网络的结论.任晓红等[15]探讨血清低白蛋白对老年心力衰竭(心衰)患者院内死亡的预测价值,实验证明血清低白蛋白是预测老年住院心衰患者院内死亡的强独立危险因素.刘艳玲[15]根据肝功能指标对于心衰的预后有关联,其中胆红素指标和死亡风险有独立关联性,通过对患者相关临床数据进行回顾性分析并了解胆红素系统检测手段在对此类疾病死亡风险预测的临床价值.
国内外学者已经提出了一些针对心力衰竭死亡率预测的机器学习方法,都具有其合理性并起到一定效果.可以发现对心力衰竭死亡率的研究,从单纯的医学问题,逐渐到开始利用并分析病人电子病历的海量数据,进行数据挖掘,从而采取一系列算法对心力衰竭死亡率进行预测.随着ICU数据密度更大、质量更高的趋势,以及当前急重症患者评分模型存在的局限性,利用先进的机器学习算法来对ICU患者死亡率进行预测越来越热门.但ICU重症电子病历中涉及到的信息众多,如临床观察记录、CT与胸透等扫描记录、医生诊断等,如何根据病历转化为标准格式,并分析、筛选出合适的特征来实现有效的预测是一大难点.目前研究的方法只能在一定程度上对死亡率进行预测,医护人员在大数据和人工智能算法的帮助下,结合自身的临床经验,能够更好地解决医学难题、提升服务效率.因此本文采用IABC-RF算法对ICU患者心衰死亡率进行预测,并根据不同合并症提出了新的预测模型,进一步提高对ICU患者心衰死亡率预测正确率.
3 基于IABC-RF的ICU患者心衰死亡率预测模型
本文从真实的ICU病患数据集出发,对数据进行整理、筛选、清洗、特征提取等一系列数据预处理过程后,结合随机森林和改进蜂群优化算法,提出了一种有效的ICU患者心衰死亡率预测模型(IABC-RF),预测系统框架图如图1所示.
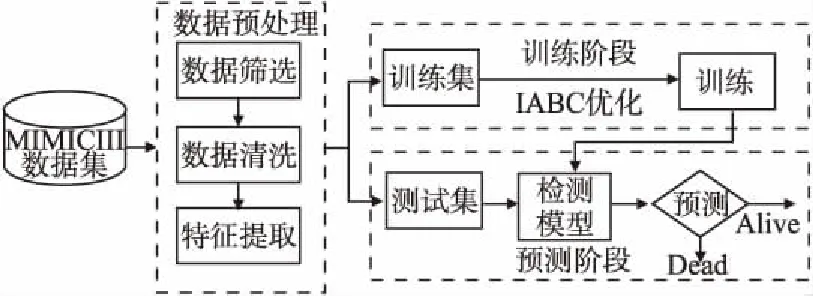
图1 系统框架图Fig.1 Scheme of the proposed detection system
3.1 改进蜂群算法(IABC)的基本原理及优点
Karaboga提出的人工蜂群算法(Artificial Bee Colony,ABC)通过模拟蜜蜂的觅食行为来解决优化问题[17].三类蜜蜂(雇佣蜂、观察蜂和侦察蜂)进行不同的活动,实现信息的共享和交流,从而找到最佳的解决方案,其优化过程为:
1)初始化阶段:种群规模为2N(雇佣蜂数量=观察蜂数量=N),与雇佣蜂对应随机产生N个解向量(蜜源).每个蜜源Si(i=1,2,…,n)是一个D维矢量,包含待优化的随机森林参数.

(1)
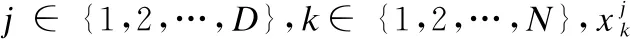
3)观察蜂阶段:雇佣蜂与观察蜂分享食物来源的信息.观察蜂重新计算蜜源的适用性,并计算被访问蜜源的概率.
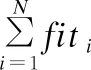
(2)
其中,fiti是Si的适应度.
4)侦查蜂阶段:如果经过一轮尝试后蜜源量没有提高,则雇佣蜂将变为侦查蜂.侦查蜂将放弃这个蜜源并生成一个新的解决方案来替换它.新蜜源中的每个参数都根据公式(3)创建.
(3)
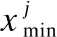
ABC可以有效地处理多模和多维优化问题,由于其结构简单,易于实现和出色的性能[18],已成功扩展到解决多目标优化问题、二进制优化问题、数据聚类问题以及许多现实世界的应用.但ABC在生成候选蜜源(新解决方案)时,相应原蜜源中只有一个参数随机改变,这种生成模式使得沿轴搜索以及新蜜源将位于相关原蜜源的邻域中,这使得扰动变小;另一方面,ABC中的“随机性”可能无法利用最佳解决方案或其他优越解决方案的信息,并且根本没有充分利用有希望的进化方向,而且与其他优化一样,ABC的收敛速度较慢.
1https://mimic.physionet. org/gettingstarted/access/
为了弥补原始ABC的缺陷并进一步改善其性能,本文提出了迭代加深搜索算法(ID-DFS)框架来改进ABC算法,迭代加深搜索算法是仿广度优先搜索的深度优先搜索,既能满足深度优先搜索的线性存储要求,又能保证发现一个最小深度的目标结点.在原始ABC的雇佣蜂阶段,每个蜜源通过其雇佣蜂产生候选食物来源,这意味着所有食物来源被分配相同的计算资源.而在观察蜂阶段,观察蜂根据雇佣蜂提供的信息搜索新的食物来源,这表明质量较好的食物来源将在观察蜂阶段分配更多的计算资源,该方法的计算资源分配强调广度优先搜索(BFS),从而导致ABC擅长探索但利用率较低.引入ABC的迭代加深搜索算法框架后,在雇佣蜂阶段,随机选择的食物来源将不断更新,直到它无法产生更好的食物来源;在观察蜂阶段,观察蜜蜂的数量不再是N,而是α·T(其中T=p·N,p∈(0,1),α∈{1,2,3,…,ceil(1 / p)},参数α可以控制计算策略资源分配),只有顶级T个精英解决方案吸引观察蜂搜索,利用随机选择的精英食物来源(具有高纯度值或小目标函数值)连续产生候选食物来源,直到不能产生更好的食物来源.可以发现经过改进后的蜂群算法(IABC),在雇佣蜂阶段和观察蜂阶段,食物来源容易得到改善,这将吸引更多的雇佣蜂和观察蜂,从而分配更多的计算资源,同时食物来源的质量(finess值)在每一代中可能有显著差异,与轮盘赌过程相比,观察蜂阶段的搜索过程时间大大缩短.
3.2 基于改进蜂群算法的随机森林预测模型(IABC-RF)
每个蜜源矢量Si包含待优化的随机森林参数,所以每一个蜜源对应一个随机森林,蜜源量由适应度决定,适应度越高表示蜜量越多,利用随机森林在测试集上正确分类的样本比例公式(4)来决定适应度fiti.
(4)
其中t为测试集中样本的数量,如果蜜源Si成功分类第j个样本则c(Si,j)=1,否则c(Si,j)=0,对于第j个样本,如果成功分类的决策树个数等于错误分类的决策树数量,则r(Si,j)=1,否则r(Si,j)=0.
为便于呈现,基于改进蜂群算法的随机森林预测模型(IABC-RF)伪代码如表1所示.在使用该算法时,需要确定几个控制参数的值:蜜源的数量(N)、放弃的条件(limt)、最大迭代次数(MCN)和搜索空间的上下界(Ub,Lb).在第四节中,将给出这些控制参数的实验值.
4 实验结果与分析
为了验证本文提出的方法的有效性,利用麻省理工学院计算生理学实验室开发的公开数据集MIMICIII数据集进行了一系列实验.
4.1 实验环境
本文的实验环境为Anaconda5.2,脚本语言使用Python3.6.5,硬件处理器为AMD Ryzen2700X,内存32G,运行Linux操作系统,同时配备GTX1080Ti显卡.
表1 基于改进蜂群算法的随机森林算法(IABC-RF)的伪代码流程
Table 1 Pseudocode of random forest algorithm based on improved bee colony(IABC-RF)

算法:基于改进蜂群算法的随机森林算法(IABC-RF)初始化:随机生成N个蜜源,每个蜜源对应一个随机森林,确定最大迭代次数(MCN)While 不符合结束条件 do 选择前T个蜜源作为精英解决方案 employed_flag=1 //雇佣蜂阶段 for i=1 to N if employed_flag=1 随机选取Si中的一个参数xji end if 利用公式(1)生成新参数vji if f(vji)≤f(xji) 将xji用vji代替 counter(s)=0,employed_flag=0 else counter(s)=counter(s)+1,employed_flag=1 end if end for //雇佣蜂阶段结束 onlooker_flag=1 //观察蜂阶段 for i=1 to α·T if onlooker_flag=1 随机从T个精英解决方案选取一个参数xji end if 利用公式(1)生成新参数vji if f(vji)≤f(xji) 将xji用vji代替 counter(e)=0,onlooker_flag=0 else counter(e)=counter(e)+1,onlooker_flag=1 end if end for //观察蜂阶段结束 if counter(max)>limt //侦查蜂阶段结束 雇佣蜂将变为侦查蜂,侦查蜂将放弃这个蜜源并利用公式(3)生成一个新的解决方案来替换它 counter(max)=0 end if //侦查蜂阶段结束end while
4.2 实验数据集
本文实验数据集采用麻省理工学院计算生理学实验室开发的公开数据集MIMICIII[19,20].可在链接1获取.原始数据集包含了2001-2012年60000多次住院相关的数据.包括人口统计学,生命体征,实验室测试、药物等.数据集由26个数据表组成.本次实验采用了其中6个表:PATIENTS,ADMISSIONS,ICUSTAYS,DIAGNOSES_I CD,D_LABITEMS,LABEVENTS.这6个表说明如表2所示.
表2 实验数据表说明
Table 2 Description of the experimental datas

数据表名称内容PATIENTS(病人登记表)病人的基本信息,包含病人的性别、出生及死亡日期ADMISSIONS(住院表)病人入院和出院信息,人口统计信息,入院来源等ICUSTAYS(ICU记录表)病人进出ICU出院和已经出院的相关信息DIAGNOSES_ICD(诊断信息表)根据ICD_9标准的病人确诊信息,包含病人编号等D_LABITEMS(门诊化验词典表)病人在ICU中实验室测试项目ID、名称、缩写等LABEVENTS(门诊检查记录表)病人在门诊测量的项目记录
本文研究的是重症监护患者心力衰竭的死亡率,所以用ICD_9代码从PostgreSQL数据库中查询PATIENTS表并筛选所有诊断为心力衰竭的患者.然后根据SUBJECT_ID和RAW_ID从其他表筛选出数据.筛选完成后共有10414名患者有心力衰竭诊断.其中6115名患者不再生存,4299名患者仍然存活.实验数据统计表如表3所示.
表3 实验数据统计表
Table 3 Statistics table of experimental data

总人数死亡人数存活人数训练集83324892(58.71%)3439(41.29%)测试集20821223(58.74%)860(41.26%)
4.3 数据预处理及特征选取
本次实验选用了MIMICIII数据集中的六个表.这些数据集通过SUBJECT_ID或者RAW_ID互相连接映射.本文死亡率预测为出院30后的死亡率,我们需要对患者出院后的存活时间进行计算,并给数据集增加标签完成监督学习,此外还需要对特征进行选取.
先给数据集增加标签,步骤如下:对患者的出院存活时间mortality_time进行了计算,计算方式为患者的死亡时间dod与患者的出院时间dischtime的差值(以天计),将出院存活时间大于30以及为空值的标记为为存活的.其他的标记为死亡的.
D_LABITEMS表列出了所有的化验项,LABEVENTS门诊检查记录LABEVENTS列出了每个可用临床测量的数值,日期和患者ID的信息,其中心力衰竭患者做过的实验室测试有345种.为了研究死亡的和存活的对每个实验室测试项目的差异性,对所有的实验室测试项目进行了Mann-Whitney检验,并将按p值进行排序,前五个项目p值排序表如表4所示.其中itemid为实验室检验项目标号.label为实验室检验项目名称,N为做了该实验室检验项目的患者人数,P-value为Mann-Whitney检验的p值.结果中有231种p值小于0.05,有统计学差异.
表4 p值排序表
Table 4 Sorted table of p-value
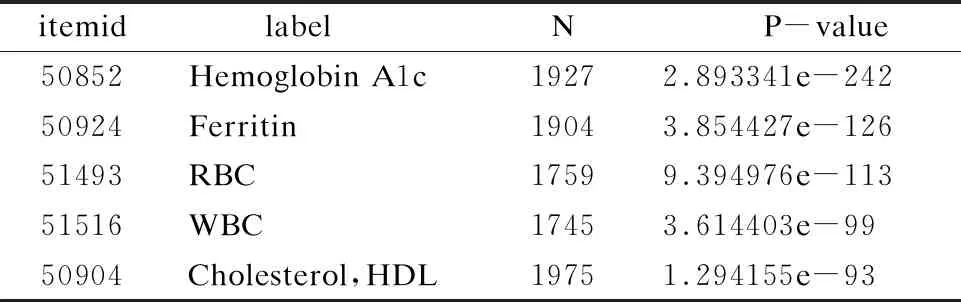
itemidlabel N P-value50852Hemoglobin A1c19272.893341e-24250924Ferritin19043.854427e-12651493RBC17599.394976e-11351516WBC17453.614403e-9950904Cholesterol,HDL19751.294155e-93
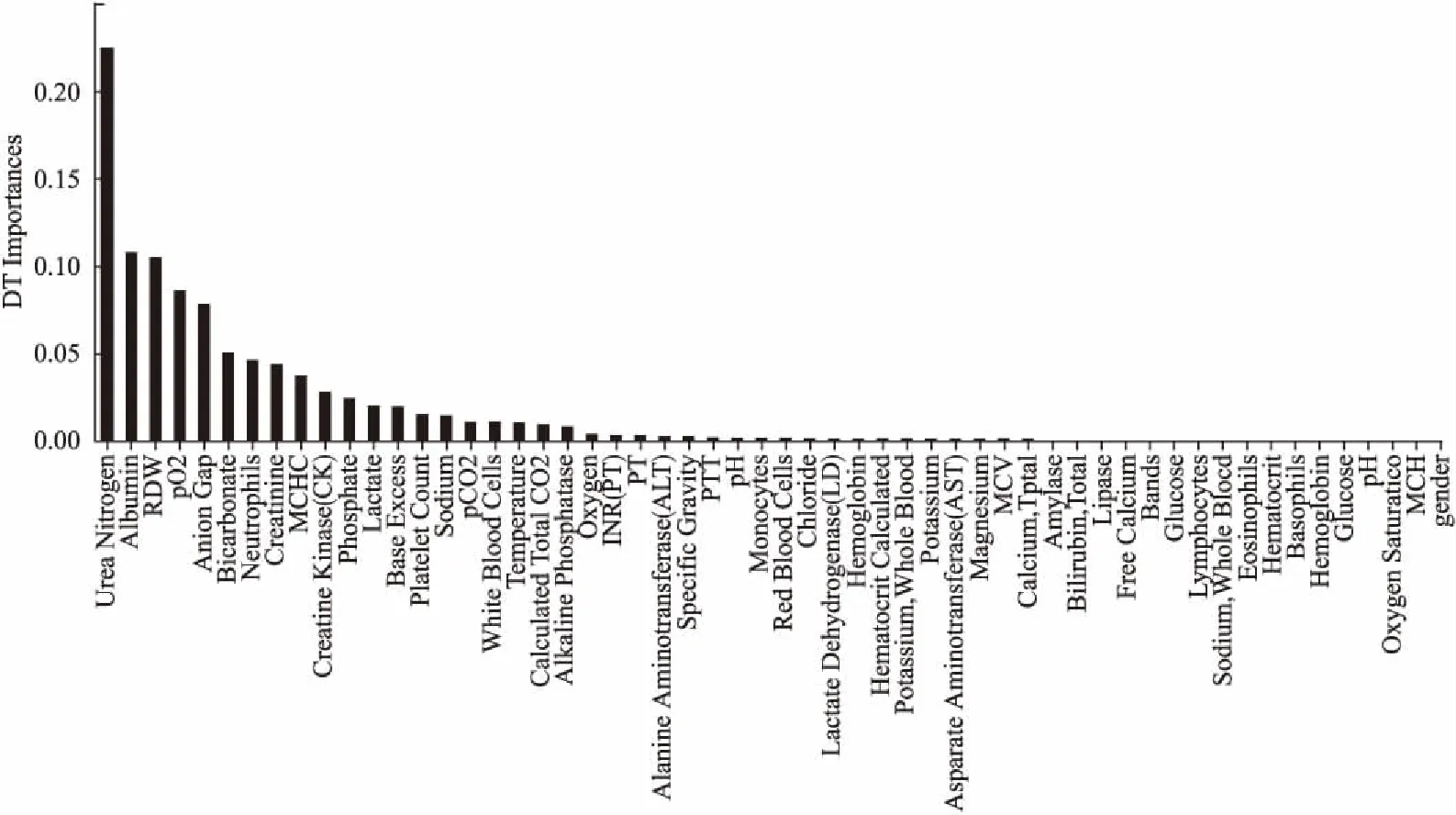
图2 特征重要性排序Fig.2 Ranking of feature importance
部分实验室测试项目只有少数患者进行检查,本实验将少于3000名患者接受检验的实验室检测项目删除,因为同一名患者在不同时间进行同一种实验室测试项目,所以对同一个实验室测试项目,同一患者会有多个值,本实验取多个检测结果的均值.最后对数据进行空值,数据标准化处理.预处理完成的数据集的维度为55维.
用随机森林特征选择算法对特征进行选取,按照特征的重要性对55个特征进行排序.特征重要性排序如图2所示.横轴为特征名,纵轴为重要性.
为了得到合适的特征数量m,分别选取了不同的m值进行实验,并使用决策树算法进行预测.结果表明当选取的特征数为12的时候,预测模型表现最好,因此本文选取前12个特征.
4.4 实验结果分析
根据表5所示的混淆矩阵,我们可以使用正确率,精确率(查准率)、召回率(查全率)、F值等评价指标对本文提出的方法进行评估.
表5 分类预测混淆矩阵
Table 5 Classification prediction confusion matrix

实际类预测类DeadAliveDeadTPFNAliveFPTN
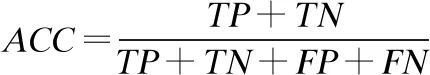
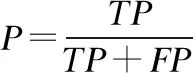


为了充分验证本文提出的ICU患者心力衰竭死亡率预测算法的有效性,本文实验从下面两个部分进行.
实验1.基于IABC-RF的ICU患者心衰死亡率预测实验
在本实验中为了验证本文提出的IABC-RF算法的有效性,我们选取了多种分类器模型进行比较,分别是C4.5,SVM,Adaboost、NN以及ABC-RF,其中本文提出IABC-RF算法的控制参数的值为:最大迭代次数为终止条件,设置为MCN=15000,N=50,Ub=100,Lb=-100,p=0.1,α=1.优化后的随机森林模型的最终参数分别为:决策树最大深度:7,投票前子树数量:87,内部节点再划分最小样本数274,叶子节点最小样本数85,RF划分时最大特征数7.
实验均采用10折交叉验证,每组进行5次实验,并记录五次实验结果的均值.实验结果如图3所示.
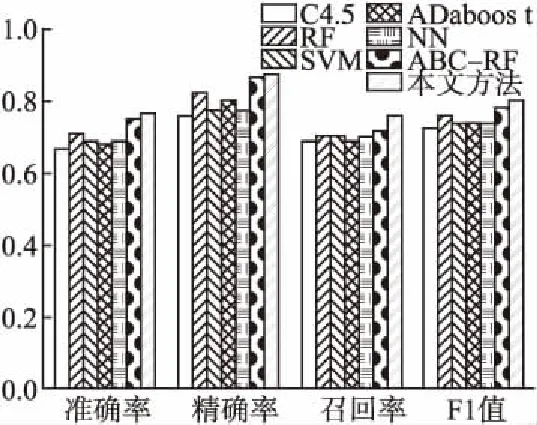
图3 实验1结果Fig.3 Results of experiment 1
实验结果表明,本文提出的IABC-RF算法在重症监护患者心力衰竭死亡率预测上的表现最好,预测准确率达到了76%.基于ABC-RF算法的重症监护患者心力衰竭死亡率预测准确率要低一点.其中,基于C4.5算法的预测模型准确率最低.
对随机森林算法,ABC-RF算法和本文提出的IABC-RF算法的运行速率进行对比,采取了5组数据量,分别为600、1200、2000、3500、6000,算法耗时对比如图4所示,随着数据量的增大,本文提出的IABC-RF算法的运行速率优势于其它两种算法.
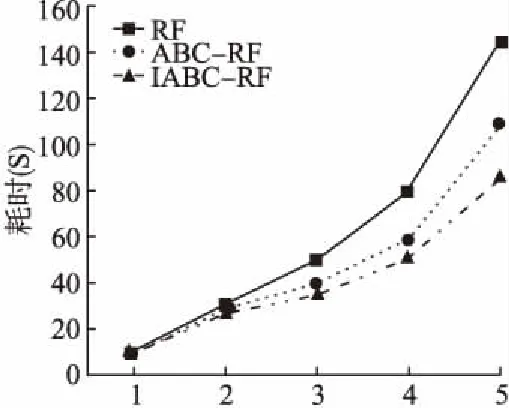
图4 算法耗时对比Fig.4 Algorithms time-consuming comparison
实验2.基于IABC-RF的针对不同合并症ICU患者心衰死亡率预测实验.
心力衰竭是一类广泛的心脏病,许多合并症会导致它的加剧,为了能够更好的研究不同合并症对ICU患者心衰死亡死亡率的影响,找出更容易预测死亡率的患者群,本文根据上述的12个特征进行聚类.聚类方法选用Kmeans,PCA以及t-SNE.实验结果表明,Kmeans和PCA并不能很好的将Dead与Alive两类进行分簇.通过t-SNE将12维映射到2维,如图5所示,图中XY轴均为坐标轴,图中可以看出,在x∈(-10,-5) 左边簇与x∈(0,5),y∈(0,5)右上簇两个区域中,Dead(方点)的密度明显远大于Alive(原点)的密度.对上述的两个区域内患者合并症进行筛选并排序,结果表明左边簇中的合并症主要为肾衰竭类,右上簇的为脓毒症类.因此,本文将合并症分为三类,分别为肾衰竭类、脓毒症类和其他合并症.

图5 2维映射图Fig.5 2D mapping
表6 实验2结果
Table 6 Results of experiment 2

模 型正确率精确率召回率F1值实验1最佳模型0.76210.86450.71540.7830实验2模型0.87420.91640.86130.8981
本文构建了针对不同合并症ICU患者心衰死亡率预测模型,该模型构建了三个基于IABC-RF的基分类器,分别对应于上述三类合并症.在测试前,先对病人的合并症进行分类,再使用本文的模型进行预测.实验采用10折交叉验证,每组进行5次实验,并记录五次实验结果的均值.实验结果如表6所示.
实验结果表明,使用本文提出的基于IABC-RF针对不同合并症的ICU患者心衰死亡率预测模型能够有效的对ICU患者心衰死亡率进行预测,其预测正确率达到了87%,能够用于辅助临床诊断.
5 结束语
近年来电子健康记录广泛应用,大量的临床数据得以完好保存,提高医院管理与服务水平的同时,也给医学研究提供了机会,其中重症监护室患者病情预测对帮助医生制定医疗方案、配置医疗资源、评估医疗效果具有重要意义.本文利用真实的重症监护数据库,将迭代加深搜索算法(ID-DFS)框架改进的ABC算法与随机森林相结合,提出了一种有效的ICU患者心衰死亡率预测模型(IABC-RF),并对原始数据进行预处理和特征筛选,实现了对ICU患者死亡率有效的预测.接下来的研究我们将尝试研究用时间序列表示的实验室测试项目作为深度网络输入的方法来实现对ICU心力衰竭患者的死亡率预测.
