面向I/O密集型应用的分离执行模型的实现与优化
2020-01-14颜秉辉梁伟浩陈俊仕
颜秉辉,安 虹,梁伟浩,陈俊仕
(中国科学技术大学 计算机科学与技术学院,合肥 230026)
1 引 言
伴随着高性能计算(High Performance Computing,HPC)技术的发展,众多科学计算领域的应用(如气候预测、环境模拟等)模拟精度逐步提升,计算过程处理的数据量逐渐增多,I/O成为此类应用的性能瓶颈[1].例如公共地球系统模式(Community Earth System Model,CESM)在执行0.25°水平分辨率的计算模拟过程中会产生PB(petabytes)量级的数据,接近90%的应用执行时间耗费在I/O行为上[2].这类I/O密集型的科学大数据应用(简称I/O密集型应用)对HPC系统的I/O性能提出更高的要求.
随着处理器工艺的改进和多核与众核处理器的采用,HPC系统的计算性能获得极大提升,但系统的I/O性能增长却极其缓慢[3].系统计算性能与I/O性能之间的差距不断扩大,I/O性能成为制约系统计算性能发挥的重大阻碍.同时,在现有每秒千万亿次浮点计算能力的HPC系统上,以计算为中心的I/O机制无法高效满足应用扩展到大规模节点上的性能需求.并且许多传统科学计算应用采用的低级I/O管理模式也在限制应用的性能提升[4].因此随着系统计算能力的增强和体系结构的更新,用户必须兼顾系统结构资源特性和应用程序需求来获得最佳的I/O性能[5].用户需要一个高效、友好,并且便于移植的I/O优化方案来满足这些需求.
本文实现并优化一种基于消息传递模型(MPI)的新型执行模型——分离执行模型.在该执行模型的系统框架中引入新的数据处理节点,主要负责执行应用中与I/O相关的数据密集型操作,包括与计算节点的数据交互、对存储节点的I/O操作等.在商用平台和国产高性能系统神威太湖之光上的实验表明,该模型可以有效减少数据在计算节点与存储节点之间互连网络中的传输次数,加速计算进程对数据的获取,提升约10%至20%的I/O性能.
2 相关工作
2.1 硬件层面的研究
基于固态硬盘和相变存储器的FLASH存储技术等系统硬件层面的研究工作,这些工作致力于加快系统对存储介质的访问速度,减少访问延迟[6],加速数据获取,从而减少系统计算性能与I/O性能之间的差距.但这些工作无法有效减少数据在系统内部互连网络中的传输次数,不能从根本上解决系统I/O性能瓶颈问题.
2.2 编程模型层面的研究
当前HPC系统上的并行编程模型如:MPI,Unified Parallel C 和数据并行编程模型HPF 等,这些并行编程模型专门为计算密集型应用设计,实现进程访存和进程间通信机制的抽象描述,而对I/O操作的管理和优化较少.如MPI标准库采用MPI-I/O接口子集实现进程I/O操作的抽象描述[7].一些高级的I/O接口库,如HDF和PnetCDF,虽然提供进程I/O操作的高层抽象,并将这些抽象作为并行编程模型的一部分,但仅作为编程模型在管理I/O行为方面的补充.这些研究多数仅实现基本的I/O管理操作,缺少针对I/O密集型应用I/O性能需求的专门设计,I/O映射和管理能力较弱.
2.3 运行时系统层面的研究
优化运行时系统来提升I/O性能的研究工作,其技术策略是在I/O操作的客户端或服务端将小规模数据请求整合为大规模连续数据请求,以此提升系统的I/O性能[8].并行文件系统技术,致力于实现多个客户端对文件的并发I/O访问[9].I/O系统的高速缓存优化技术[10]和数据预取优化技术[11],致力于提升进程对数据的读写速度,降低I/O访问延迟.但对于I/O密集型应用的多个进程突发性大规模I/O读写请求,这些技术提升的性能有限.解耦范式[12]提供一种对I/O密集型应用的全新优化思路,通过在系统框架中引入双层中间节点负责管理I/O操作,从而减少应用在执行过程中数据迁移的成本.但解耦范式三段式的I/O路径仍可进一步优化,同时双层中间节点的引入使节点管理模式更为复杂.
2.4 软件层面的统计研究
在美国阿贡国家实验室(Argonne National Laboratory)统计的26个科学大数据计算应用中,有20个应用在执行过程中生成和存储TB(terabytes)量级的数据[13].这些应用在执行过程中产生大量的I/O请求成为此类应用性能的主要瓶颈.此类I/O密集型应用在多个HPC系统平台上的I/O行为统计结果表明,采用原始、低级的I/O接口(如POSIX-IO)去管理应用I/O行为将无法充分发挥HPC系统的计算性能[4].而许多经典的I/O密集型应用代码量大、逻辑复杂,重构困难.因此提供一个高效、便于应用调用、无需更改应用算法逻辑的I/O管理函数库是有必要的.
3 分离执行模型的实现及优化
3.1 系统架构
分离执行模型改变传统系统架构中计算节点与存储节点经内部互连网络直接相连的模式,将系统原计算节点划分为计算节点和数据处理节点两部分,计算节点通过数据处理节点与存储节点相连(见图1).在该模型中,计算节点可以迅速利用进程通讯从数据处理节点获得计算所需数据,无需经过慢速的互连网络从存储节点读取数据,减少计算节点的数据等待时间.同时经过数据处理节点的数据可以由数据处理节点在本地进行归约和缓存,减少系统内部互连网络中数据传输的数据量和传输次数.

图1 分离执行模型系统架构Fig.1 System architecture of the decoupled execution model
3.2 执行模型
传统的程序执行流程为“数据提取-模拟计算-数据存储”.本文将流程中“模拟计算”阶段包含的操作划分为计算密集型操作和与I/O相关的数据密集型操作两大类,并在流程中加入“数据规约”阶段,用以执行划分出的I/O密集型操作.以此形成“数据提取-数据归约-模拟计算-数据归约-数据存储”这种新型的程序执行模型——分离执行模型(见图2).模型在数据规约阶段可以利用数据处理节点的本地存储有效减少数据在内部互连网络中的传输次数,并在系统架构上增加互连网络带宽,加快数据的获取,从而解决I/O密集型应用由于大量数据在慢速互连网络中传输造成的I/O性能瓶颈问题.
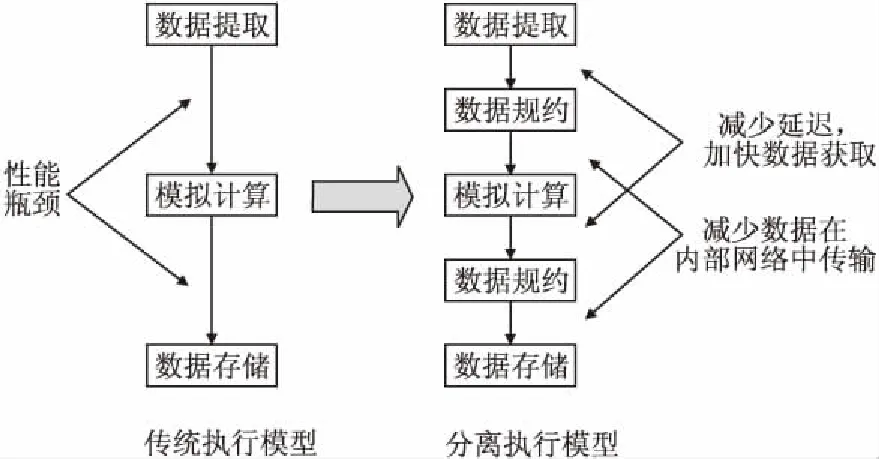
图2 执行模型的比较Fig.2 Comparison of execution model
在数据归约阶段,数据处理节点执行分离出的与I/O密切相关的数据密集型操作.数据处理节点主要负责接收计算节点的I/O读写请求,并将I/O请求分析整合,统一完成对文件的读写操作.在此执行模型下,用户可以根据需要将数据提取、数据归约、模拟计算、数据存储、数据使用等阶段做成软件流水,使应用的I/O、通信和计算时间高度重叠,减少应用的执行时间.
3.3 具体实现
分离执行模型仿照MPI-IO的相关I/O管理接口,定义新的I/O管理接口,并利用MPI进程调度管理函数进行计算节点和数据处理节点的任务分配与调度.为便于移植和使用,分离执行模型I/O管理接口在参数设置上与MPI-IO管理接口保持一致.
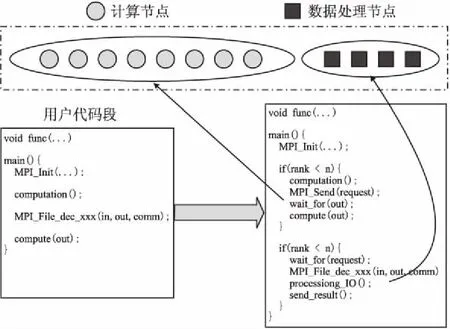
图3 分离执行模型实现Fig.3 Implement of the decoupled execution model
模型将数据规约阶段分为3步:I/O请求通讯阶段、I/O请求整合阶段和I/O操作阶段.在执行过程中,数据处理节点根据计算节点I/O读或写请求执行相应的任务调度.
1) 在计算节点发出I/O读请求后,数据处理节点接收并整合收到的请求,根据整合后的请求进行相应的文件读操作,然后将读取到的数据按照原请求散播到对应的计算节点;
2) 在计算节点发出I/O写请求后,数据处理节点接收计算节点发送的数据,然后将数据写入文件.
模型的任务调度实现如图3所示.
3.4 性能优化
根据分离执行模型数据规约阶段3步流程的特点,本文对模型进行I/O分级读写操作优化和数据处理节点的文件缓存优化,从而加快数据处理节点对I/O请求的响应速度,加速数据在数据处理节点和计算节点之间的传输,降低计算节点的数据等待时间.
3.4.1 分级读写优化
两阶段I/O(two-phase I/O)方案[14]是广泛用于提升I/O性能的经典优化方法.通过合并多个进程的非连续I/O请求,组成更长的连续I/O请求,从而减少I/O系统频繁响应I/O请求的等待开销和获取非连续数据的额外开销.在传统的两阶段I/O方案中,选取进程的一部分子集作为聚合器(aggregator),负责接收和整合其他进程的I/O请求.在第1阶段,所有进程通过调用MPI_Alltoall和MPI_Alltoallv函数交换I/O请求信息;在第2阶段,聚合器发起I/O读或写操作,并将获得的数据发送给对应进程或写入文件.相关的研究证明,在两阶段I/O方案中,第1阶段I/O请求的信息交换与整合为I/O行为的耗时热点.而第2阶段的I/O读写操作耗时受到系统硬件结构和网络结构的影响[15].
本文根据数据规约阶段I/O行为特点,基于两阶段I/O方案,设计新的分级读写策略——三阶段分级读写策略.数据处理节点作为聚合器,采用静态映射的方式,负责响应对应计算节点进程的I/O操作请求.策略流程分为3阶段(见图4),第1阶段,数据处理节点接收其所负责计算节点的I/O读或写请求;第2阶段,数据处理节点将接收到的I/O请求整合,将多次小规模I/O请求整合成单次大规模I/O请求;第3阶段,数据处理节点根据整合后的I/O读或写操作将数据散播给数据节点或写入文件.

图4 三阶段分级读写策略流程Fig.4 Process of the three-phase hierarchical read and write strategy
3.4.2 文件缓存优化
在分离执行模型的系统架构中,数据处理节点是数据的核心中转枢纽.为数据处理节点设计高效的文件缓存策略可以有效减少数据在计算节点与存储节点之间慢速互连网络上的传输次数[16].本文根据数据处理节点任务类别和I/O行为特点,为数据处理节点处理I/O读、写请求分别设计了不同的文件缓存策略.
在响应I/O读请求时,各数据处理节点在本地维护目标读取文件的完整拷贝作为读缓存.多节点的读缓存不会产生数据一致性问题,无需通过节点通讯进行缓存维护,因此没有额外的通讯开销.当数据处理节点收到计算节点的I/O读取请求后,从本地读缓存获取数据,然后将数据散播到对应的计算节点.
在响应I/O写请求时,各数据处理节点分别在本地按照进程序号顺序维护目标写入文件的部分数据.因此多节点的写缓存不存在数据交叉,不会产生数据一致性问题.当数据处理节点收到其所负责的计算节点的写入数据后,将写入数据维护到本地的写缓存,并在收到数据同步请求后将写缓存数据统一写入到文件.
经上述对分离执行模型的I/O分级读写操作优化和数据处理节点的文件缓存优化,数据处理节点的进程管理及I/O请求响应算法流程如下:
算法
while(!STOP_FLAG){
MPI_Probe();
switch(probe_status.MPI_TAG){
case READ_REQUEST_TAG:
MPI_Gather();// 获得读请求
Coalesce_read_request();// 整合读请求
Read_from_file_cache();// 从本地文件缓存读取
MPI_Scatter();// 将数据散播到计算节点
break;
case WRITE_REQUEST_TAG:
MPI_Gather();// 获得写请求的数据
Write_into_file_cache();// 将数据写入本地文件缓存
break;
Case SYNC_TAG;
MPI_Recv();// 获得同步请求
MPI_File_write();// 将本地写缓存写入到硬盘文件
break;
}
}
4 实验结果及分析
性能测试程序为经典的HPC系统I/O性能基准测试程序IOR.IOR基准测试程序包含多种编程模型的I/O管理接口,提供了多种配置I/O请求的参数选项.本文在IOR基准测试程序中嵌入分离执行模型的I/O管理接口,进行分离执行模型I/O接口的性能评测.实验通过多种配置选项去模拟I/O密集型应用多个进程进行文件I/O读写访问的请求.
实验平台选取曙光集群平台和国产HPC系统神威太湖之光.曙光平台为8节点集群,每个节点配备1个Intel(R) Xeon(R) CPU E5-2660处理器,内存126GB.系统采用容量为200GB的GPFS并行文件系统,节点之间通过4路QDR Infiniband网络相连,理论网络传输带宽为40Gb/s.神威太湖之光合计共有40960个节点,每个节点配备1个SW26010处理器,每个SW26010处理器包含4组计算核心,每个计算核心内存8G.系统采用GPFS并行文件系统,32个计算节点构成超节点,超节点与存储节点通过4路FDR Infiniband网络相连,理论网络传输带宽为56Gb/s,超节点内部节点通过PCIe3.O x8系统接口相连,理论传输带宽16GB/s.
实验记录在不同执行模型下,运行IOR基准测试程序进行文件I/O读写操作所能达到的有效数据传输带宽,并以此作为执行模型的I/O性能的评判标准.有效数据传输带宽为实际传输数据量与时间的比值.
实验测试数据采用6GB、12GB、18GB、24GB的文本数据文件,在IOR基准测试程序中分别调用传统执行模型的MPI-I/O接口和分离执行模型的I/O接口进行多节点进程的文件I/O读写请求对比实验.
第一组对比试验设置在曙光平台上,节点配置分别为传统执行模型下6个计算节点,分离执行模型下6个计算节点搭配1、2个数据处理节点.在实验中,I/O请求以16MB为单次传输数据量进行文件I/O读写测试.图5记录在曙光平台上利用不同模型进行I/O读操作和I/O写操作的实验对比结果.
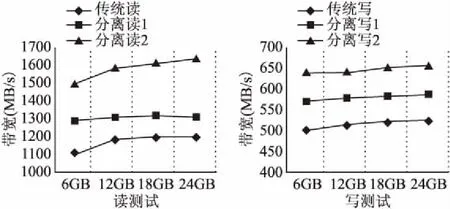
图5 曙光平台下优化前后带宽结果对比Fig.5 Bandwidth comparison on sugon cluster
上述在曙光平台的实验结果表明:
1) 在相同配置下,分离执行模型较传统执行模型可以获得10%至20%的I/O读写性能提升.
2) 在相同配置下,适当提高数据处理节点比例,可以提高分离执行模型的I/O性能.但随着数据节点数目的比例增加,数据处理节点之间的通讯开销会相应增加,使得整体的性能提升为非线性加速提升.
3) 分离执行模型对于I/O读请求的优化效果好于I/O写请求.因为分离执行模式中数据处理节点对本地读、写缓存的维护方案不同,数据处理节点无需根据计算节点的I/O读请求更新本地的读缓存.而对于计算节点的I/O写请求,数据处理节点获取计算节点传送的数据后,需更新本地写缓存,在响应频繁的I/O写请求时,其更新时间无法被其他过程隐藏.
第二组对比试验设置在国产HPC平台神威太湖之光上,节点配置分别为传统执行模型下12个计算节点和分离执行模型下12个计算节点搭配4、8个数据处理节点.在实验中,I/O请求以16MB为单次传输数据量进行文件I/O读写测试.图6记录在神威太湖之光上利用不同模型进行I/O读操作和I/O写操作的实验对比结果.
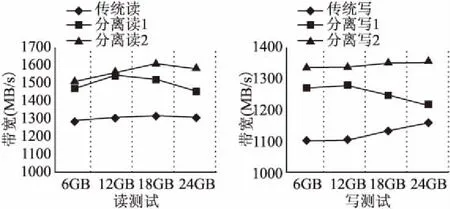
图6 神威太湖之光平台下优化前后带宽结果对比Fig.6 Bandwidth comparison on sunway TaihuLight
上述结果表明,在国产HPC系统神威太湖之光上,分离执行模型同样能够获得接近10%的I/O读写性能提升.相较于商用平台,分离执行模型在神威平台的性能提升有限.究其原因,神威系统架构下节点非统一内存访问的体系结构特点,导致节点内处理器进程通讯与节点间处理器进程通讯代价不一致.同时由于神威计算节点内单核心内存容量仅有8G,故当前的缓存方案在大文件情况下存在性能损耗.
基于目前的实验测试,通过对比商用平台与神威平台的实验结果,本文相信通过在系统架构中引入一层数据处理节点作为I/O传输数据的中转,并对数据处理节点进行多方面的优化,可以为解决当前HPC系统上I/O密集型应用的I/O性能瓶颈问题提供新的解决方案.
5 总 结
本论文面向I/O密集型科学大数据应用,实现并优化了一种基于消息传递模型的新的执行模型——分离执行模型.通过实验证明对I/O密集型应用的I/O性能有10%至20%的性能提升.本模型将应用的I/O操作和计算操作放在同等重要的位置,为解决HPC系统上I/O密集型应用的I/O性能问题提供了一种新的解决思路.与此同时,模型以数据为中心的设计思想,对我国下一代国产HPC计算机的体系架构设计和运行时系统研发具有重要的参考意义.未来,我们将在神威太湖之光平台上对模型进行强扩展性的优化与测试,同时对数据处理节点的文件缓存方案进行进一步优化.
