XGBoost在卫星网络协调态势预测中的应用
2020-01-14王春梅
朱 明,王春梅,高 翔,王 静
1(中国科学院 国家空间科学中心,北京 100190)2(中国科学院大学,北京 100049)
1 引 言
随着航天事业的发展,在轨卫星的数量越来越多.据美国忧思科学家联盟(UCS)统计,截至2018年8月,全球在轨运行的卫星数量为1886颗.卫星的频率和轨道资源日趋紧张,各国争相抢占频率和轨道资源,致使卫星网络之间的协调难度不断加大,协调任务不断加重[1-5],实现卫星网络协调态势的预测可以有效降低成本,提高协调效率和成功率,然而经过中国知网、百度学术、必应学术和Web of Science核心合集的检索,目前尚缺乏卫星网络协调态势预测的相关研究.
机器学习算法在求解预测问题具有重要应用,而XGBoost算法作为机器学习算法中的一种,在电商销售预测、油价预测、用户行为预测、轴承故障预测、医疗诊断等领域均取得较好效果.文献[6]利用XGBoost模型对商业销售进行预测,在训练速度及评价标准上均具有明显的优势.文献[7]对国际原油价格进行预测研究,预测精度高、泛化能力强.文献[8-11]分别对用户行为、风机主轴承故障、节假日路网流量与骨质疏松性骨折进行预测,预测结果的效率和准确度方面均具有较好的优越性.
鉴于此,本文提出基于XGBoost的卫星网路协调态势预测方法,实现对卫星网络协调态势有效预测,达到降低协调成本、提高协调效率的目的,并通过对比实验,验证该方法的可行性与优越性.
2 数据描述
卫星网络协调数据主要包括:卫星所属国实力数据、需协调国家及其实力数据以及卫星适用频段及其相关属性数据.表1~表3分别列出上述三种数据的部分示例,其表中USA、KOR、CHN与UAE分别表示美国、韩国、中国与阿拉伯联合酋长国.
数据表中的卫星网络协调数据共有461条记录,每条记录含有3441列特征,数据维度极高,选择既能保证较好的泛化能力又能保证较高效率的模型极为重要.
3 XGBoost模型的优势
集成学习模型是按照某种规则将多个学习器的结果进行整合,从而获得比单学习模型学习效果更优的一种模型.其模型思想主要有两种:
1)Bagging思想,是采用多个并行的学习器进行预测,然后基于“少数服从多数”的策略来确定最终的结果,典型的算法如随机森林(Random Forests,RF)方法.RF算法在训练决策树的过程中进行特征的随机选择,虽然能够处理高维数据集,但当数据中某个特征含有较多特征值时,容易出现过拟合问题;
表1 卫星所属国实力数据示例
Table 1 Example of strength data of satellite country

卫星名称卫星所属国家该国投入使用量该国C资料同步轨道卫星网络数量该国N资料同步轨道卫星网络数量该国操作者数量…USNN-3USA76819435780…COMS-116.2EKOR517292615…CHINASAT-MSB5CHN54421017761……………………
表2 需协调国家及其实力数据示例
Table 2 Example of coordination of countries and their strength data

卫星名称卫星所属国家需协调国家-UAEUAE投入使用量UAE-C资料同步轨道卫星网络数量UAE-N资料同步轨道卫星网络数量…USNN-3USAYES15313043…COMS-116.2EKORNO15313043…CHINASAT-MSB5CHNYES15313043……………………
表3 卫星使用频段及其相关数据示例
Table 3 Examples of satellite frequency bands and related data
2)Boosting即将多个学习准确率低的弱学习器,集成一个学习准确率高的强学习器,典型的算法如Adaboost和GBDT(Gradient Boosting,梯度提升树).Adaboost算法通过调整样本权重将多个弱学习器集成为强学习器,擅长解决分类问题[12].GBDT算法的建树迭代过程是在前一次迭代的基础上完成本次迭代,比Adaboost性能更佳,但是GBDT算法的基础学习器仅能使用CART(Classification and Regression Tree)回归树模型,并且时间和空间复杂度较高.
XGBoost是华盛顿大学的陈天奇博士在2016年提出的一种GBDT算法的优化算法[13].主要有三方面的优势:
1)支持并行处理,一方面XGBoost模型采用按列存储的方式保存数据,可以并行的对同层级的所有特征进行分裂点的查找计算,另一方面,XGBoost在模型训练之前预先对数据进行排序并保存为block结构,在计算中重复使用这个结构使得它可以在特征粒度上利用CPU多线程实现并行计算,提高运行效率[14];
2)最优解收敛速度快.XGBoost模型相较于GBDT算法在代价函数上进行了二阶的泰勒展开,通过计算二次函数求出最优解,使算法的收敛速度更快;
3)避免过拟合.XGBoost模型在代价函数中加入正则项来控制模型的复杂度,进而降低模型的方差,避免过拟合现象的发生.
因此,采用XGBoost模型对卫星网路协调态势进行预测,可以有效提升运行效率,避免过拟合现象的发生.
4 基于XGBoost模型的预测方法
XGBoost模型预测过程如图1所示.预测模型主要包括两部分:数据预处理和模型构建.数据预处理主要任务是用于生成完整和可用的数据集,其包括数据集成与数据清洗两部分.模型构建的主要任务是训练各基学习器,通过参数调优降低模型误差,最后集成成为准确率较高的组合学习模型.
4.1 数据预处理
为了防止数据集冗余和不一致,提高预测模型的准确性与速度,因此,将多个数据表集成为具有统一属性及单位的数据集.数据集成示意图如图2所示.数据集成步骤如下:
①首先匹配卫星所属国家(即图2中标识[1]);
②匹配成功后,将卫星所属国实力属性插入到原始数据表中(即图2中标识[2]添加到标识[1]后面);
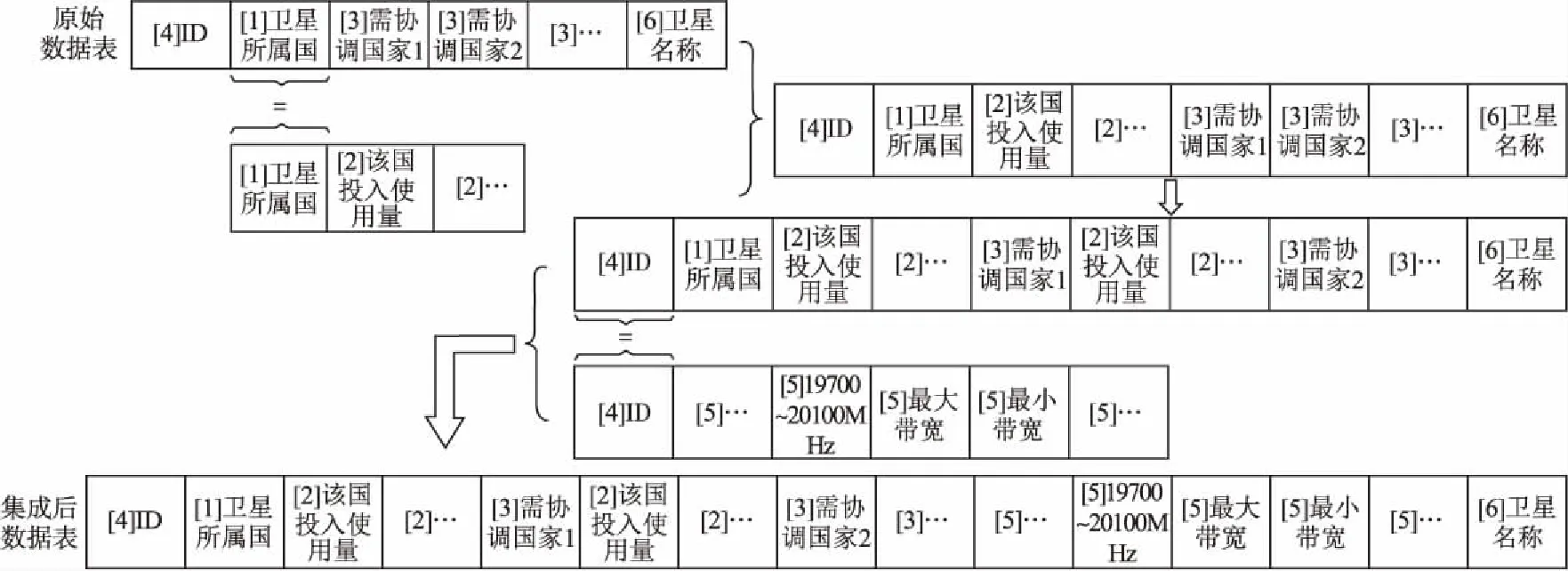
图2 数据集成示意图Fig.2 Data integration diagram
③根据国家名称,将需协调国家实力属性添加到原数据表中(即图2中标识[2]添加到标识[3]后面);
④根据ID值(即图2中标识[4]),将频段属性添加到原始数据表中(即图2中标识[5]添加到标识[6]前面),数据集成结束.
卫星网络协调数据的数据类型主要有两类:数值型与非数值型数据,而XGBoost的基学习器是一种回归树模型,只能处理数值型数据,因此,需要对其原始数据进行清洗,将非数值型数据转化为数值型.
数据清洗过程包含三部分:缺失值的填充、字符数据的量化及删除异常数据.数据清洗示意图如图3所示.数据清洗步骤如下:
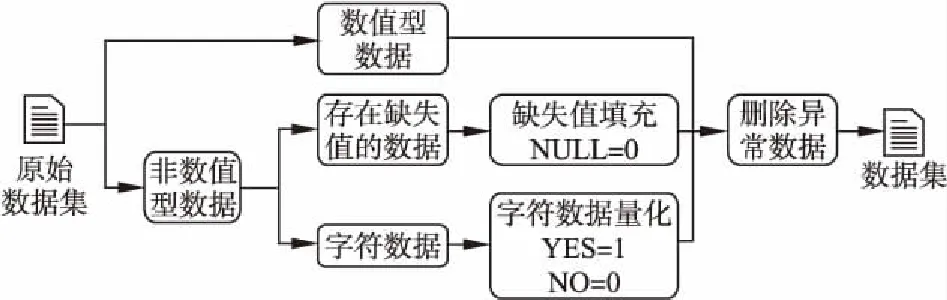
图3 数据清洗示意图Fig.3 Data cleaning diagram
①判断原始数据集中数据类型.若为数值型数据,转到步骤③.若为非数值型数据,转到下一步.
②判断非数值型数据类型.若为缺失值数据,进行缺失值填充.卫星网络协调数据中,缺失值说明该卫星不使用此频段范围,因此,将缺失值处填充为0.若为字符数据,进行字符型数据量化.字符型数据则主要有YES和NO,如表2所示,YES表示与该国存在协调关系,NO表示与该国不存在协调关系;如表3所示,YES表示该卫星使用此频段范围,NO表示该卫星不使用此频段范围.本文使用1和0分别对应表示YES和NO.
③删除异常数据.
④数据清洗完成,形成数据集.
数据划分如图4所示.数据集划分为训练集和测试集,数量分别为362条和100条数据.训练集按照7:3的比例划分为训练子集和验证集.训练子集用作训练回归预测模型,验证集用作确定回归预测模型参数,测试集用作模型验证及结果分析.
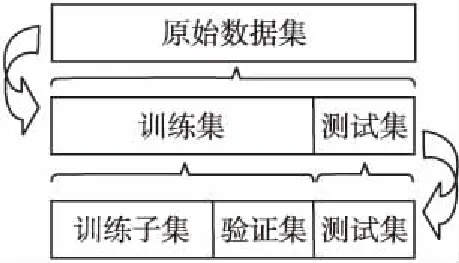
图4 数据划分示意图Fig.4 Data division diagram
4.2 参数调优
XGBoost参数[15]较多,其中以max_depth,min_child_weight,eta,gamma,subsample,colsample_bytree,lambda,alpha对模型的性能影响较大,因此构建预测模型时主要针对上述参数进行调优.XGBoost参数信息如表4所示.
参数选择采用遍历的方法,搜索步长从大变小.以max_depth参数为例,选择方法步骤如下:
①设定参数初始值为默认值6;
②设定参数遍历范围为[3,12];
③设定参数遍历步长为2,如图5所示,可以看出在max_depth的值为5时,平均绝对误差(MAE)最小,其值为0.2403;
④参数遍历范围缩小为[3,7];

图5 max_depth参数步长为2时的误差值Fig.5 Error value of max_depth step 2
⑤把参数遍历的步长调节为1,如图6所示,可以看出平均绝对误差(MAE)的最低点从0.2403变成为0.2392,参数max_depth的值从5变为4.综上所述,max_depth的参数值为4.

图6 max_depth参数步长为1时的误差值Fig.6 Error value of max_depth step 1
表4 XGBoost参数信息
Table 4 XGBoost parameter information
5 实验验证与分析
5.1 实验环境
操作系统:Windows10,64位.
开发平台:Pycharm,python3.6.3.
第三方库:Numpy,Pandas,scikit-learn,xgboost.
硬件环境:Inter(R)Core(TM)i7-7700HQ CPU @ 2.80GHz 2.81GHz.
5.2 实验过程及结果分析
本文实验分为两部分,第一部分实验是XGBoost模型参数调优.步骤及参数详细信息参见章节4.2 参数调优.为验证XGBoost模型的预测方法在解决卫星网络协调态势预测问题的优越性,第二部分实验是与其他预测模型对比实验.实验将XGBoost模型分别与平均回归的K邻近(UNI_KNR)、距离加权回归的K邻近(DIS_KNR)、径向基核函数的支持向量机(RBF_SVR)、回归树(DTR)、随机森林(RF)、极端随机森林(ETR)和弹性网络回归(ElasticNet)模型进行结果对比.
本实验采用均方误差(MSE)和平均绝对误差(MAE)作为预测模型的评价函数,误差数值越小说明预测的结果越好,其评价函数的计算公式分别如公式(1)和公式(2)所示:
(1)
(2)
表5 预测模型评价结果
Table 5 Evaluation results of prediction model
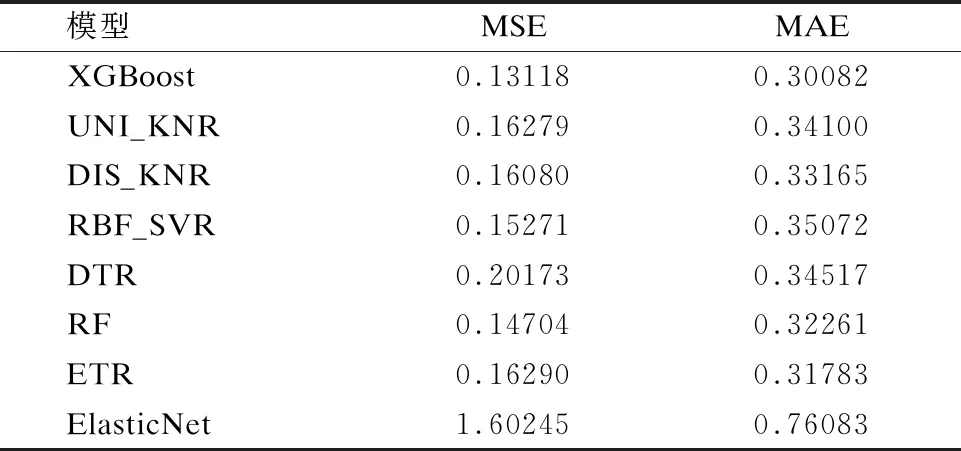
模型MSEMAEXGBoost0.131180.30082UNI_KNR0.162790.34100DIS_KNR0.160800.33165RBF_SVR0.152710.35072DTR0.201730.34517RF0.147040.32261ETR0.162900.31783ElasticNet1.602450.76083
第二部分实验中8种模型的预测评价结果如表5所示.比较表5 中各模型预测评价结果可以看出:
1)XGBoost回归模型、支持向量机回归模型、K邻近回归、随机森林回归等基于非线性的预测模型远好于基于线性模型的弹性网络回归模型,表明卫星网络协调数据为非线性关系,因此采用非线性回归预测模型优于线性回归预测模型;
2)在卫星网络协调态势预测方面,XGBoost模型和随机森林的集成学习方法预测效果好于弹性网络回归、支持向量机回归,K邻近回归等单学习模型;
3)XGBoost模型评价函数的均方误差(MSE)和绝对误差(MAE)均小于其他模型,且相较于次优模型(RF和ETR),其MSE降低了10.78%,MAE降低了5.35%,表明XGBoost模型具有较好的卫星网络协调态势预测精度和泛化能力.
7 结束语
为降低卫星网路协调难度,提高协调任务效率,本文研究基于卫星网络协调的高维数据进行网络协调态势预测方法.采用XGBoost的模型实现对卫星网络协调态势的有效预测.并实验对比平均回归的K邻近、距离加权回归的K邻近、径向基核函数的支持向量机等7种回归模型,结果表明XGBoost模型在卫星网路协调态势预测方面具有较好的预测精度和泛化能力.
