基于代表作制度的z指数学者评价方法改进研究*
2020-01-08张学梅
张学梅
(苏州市职业大学图书馆 江苏苏州 215011)
1 引言
学者是科学研究过程中最具活力的因素,学者评价是学术评价的重要组成部分。对学者开展科学、合理、公正的评价,不仅有助于科研单位、大学、机构的聘任、评奖等工作,还可以充分调动学者的科研积极性,激励他们持续从事科研活动,从而产生更多高质量的研究成果,由此促进科学发展。许多对学者进行评价的方法也可以直接或改造后推广到大学、科研单位、科技期刊等多种对象的评价中。
对学者的评价离不开对其科研成果的评价,无论是同行评议法还是基于科学计量学原理的定量评价方法,均是以学者科研成果为基础来开展。随着科学技术的飞速发展,产生了越来越多的作为科研成果的科技论文,科技论文是体现学者科研成果最重要的载体,是学者之间进行学术交流最重要的媒介,也是开展学术评价最重要的依据。目前同行评议法在学术评价中的应用范围还很广,如论文发表前的专家评审阶段、各种科技评奖、职称评审等。以定性评价为主要特点的同行评议法存在一些难以克服的缺陷,如实施成本高、不公开性、评价结果受专家知识结构和主观局限大、人为因素影响大等,从而使得评价结果不够真实公正。基于科学计量学的定量评价主要是在论文发表之后开展,借助于论文发表的数量及被引量等数据而得出,具有实施成本低、更加公正客观的特点,越来越受到相关学者的重视,学者们从多种角度开展研究并产生了大量研究成果。
近年来新出现的科学计量学学者评价指标中,影响力最大的是2005年由Hirsch提出的h指数[1],其创造性地将发文量与被引量结合到一个数字中,从而实现同时反映论文数量与质量的效果。在h指数出现之前,能够同时考虑到发文量和被引量的指标主要是平均被引率,即用学者全部论文的被引量总和除以发文量,以此反映出学者的学术水平。尽管具有一定意义,但是其存在的缺陷也很明显。它的计算方法非常粗犷,并且惩罚高产者奖励低产者,所以可能得到很不合理的结果,而h指数计算过程更加精细,在一定程度上克服了平均被引率的诸多缺陷,可以说h指数体现了一种科研质量的价值取向,是微观科研评价中的一项革命性的指标[2]。正因如此,h指数一经提出便引起广泛关注,产生了大量相关研究,主要包括利用h指数法开展学术评价[3-4]、h指数应用范围的推广研究[5-6]、h指数与其他评价方法的比较研究[7]、h指数原理研究[8-9]、针对h指数不足提出改进策略的研究[10-12]等。这些研究不断推动着h指数的发展,特别是各种改进策略的尝试,从不同角度着手设计出不少新指标,为学术评价提供了更多思路。但是这些指标绝大多数与h指数一样属于二维复合指标,也即主要是考虑发文量和被引量两个层面,而Prathap于2014年提出的Z指数[13],将作者引文分布特征引入评价指标中,所以可称为三维评价指标,为h指数的发展提供了新的研究视角,目前已引起部分学者兴趣,出现一些相关研究。
另一方面,在以论文为基础的学者评价中,从对评价结果产生影响的论文选取方法的角度,可以把评价方法分成两类:一种是全部论文均进入计算,在这类方法的框架下,作者的每一篇论文都对评价结果产生影响;另一种是部分有代表性的论文进入计算,在这种框架下,作者的一部分论文对评价结果产生影响,而另一部分论文对评价结果完全没有影响。前者如总发文量、总被引量、篇均被引量、EM指数[14]、hm指数[15]等,后者如高被引论文数、h指数、g指数[16]、e指数[11]等。它们实际也代表了两种学术评价的理论基础:在开展学者个人评价中,应该以学者全部论文的总体水平为依据,还是以其质量最高的部分论文为依据,后者是目前引起人们兴趣的代表作制度。
一般来说,在科研生涯中的不同阶段,一名科研人员在各项研究中投入的时间和精力不可能完全相等,所以作为科研成果的相关论文质量也会有所差异,那些集中全力而产生的论文可能质量更高从而成为其代表作[17-18]。在求职、晋升、评奖、基金申请等多个场合,科研人员都需要选择他们的代表作。迄今为止,如何选择代表作在学界仍然没有定论。例如,一名科研人员可以选择自己被引量最高的论文或者发表在顶级期刊上的论文作为自己的代表作[19]。Niu等人提出一种自避免最优扩散程序来确定个人的代表作[20]。Bao等人考虑到合作者对一篇论文的贡献差异,以分值分配为基础来确定科研人员的代表作[21]。周建林等人提出一种以被引量为基础选择学者代表作的方法(为下文叙述方便,暂称其为representative方法):首先将学者的全部论文(共N篇)按被引量从高到低排序,论文编号记为正整数n(1≤n≤N),每篇论文的被引量记为Cn,有Cn>Cn+1,然后依次计算相邻2篇论文被引量的差值C1—C2、C2—C3、……、Cn—Cn+1、……、CN-1—CN,并找到所有差值中的最大值max(Cn—Cn+1),那么此时的前n篇论文就是该作者的代表作,作者通过实证研究证实了该方法的有效性[22]。此外,h指数的实质是在对学者进行评价时,只选择其发表的论文中被引量最高的若干篇(也即h核心论文)作为代表进入h指数的计算,而忽略非h核心论文的影响。这种思想与代表作制度的原理不谋而合,可以认为h指数核心论文即是该作者的代表作,无论其他论文数量多少、质量如何,均不对学者的学术水平分值产生影响。
推行代表作制度是当前学术评价改革的一项重要内容,考虑到h指数应用的广泛性和representative方法的理论新颖性与实践简便性,结合目前国内外已出现一些针对Z指数的研究,本研究尝试从对其评价原理加以探讨为出发点,试图将该指标与以代表作制度为特征的评价方法相结合,从而对Z指数的计算原理进行改进和探讨,并通过定量研究分析采用不同的评价原理对评价结果影响的异同,目的在于对Z指数的设计原理进行探索,为相关研究者提供更多的理论与方法上的参考,为学术评价实施者实施不同目的的学术评价提供更多的选择,同时激发相关学者的思考,共同讨论究竟哪种评价原理更加合理。
2 Z指数发展过程及原理
为了更加清晰地厘清思路,首先对Z指数的发展脉络作一简要回顾。
2005年,加州大学Hirsch提出一种新的评价科学家个人学术水平的指标h指数,定义为某一学者所发表的全部论文中至少有h篇的被引量不少于h次。用数学公式表示为:

式(1)中k是将论文按被引量降序排列后的序号,k是正整数且满足1≤k≤N,N表示该学者的发文量,Ck是第k篇论文的被引量。
在h指数基础之上,学者们不断提出大量新的评价指标,p指数(performance index)是由Prathap在2010年通过模拟h指数而设计的一个综合指标,计算公式为:

式(2)中C表示学者的总被引量,p指数提出后已经被用于评价学者[23]、国家[24]、期刊[25-26]和论文[27]等,产生了一定的影响。Prathap使用该指标对100位最多产的经济学家进行排序,认为p指数相对于h指数的效果更好,因为它能够反映出学者科研成果总被引量和平均被引率之间的最佳平衡[23],从而弥补h指数灵敏度不高与区分度较低的缺点。该指数的缺陷在于它将学者的总被引量作为一个整体来进行计算,不能反映各篇论文被引量的分布情况,针对这一点,Prathap在2013年对p指数进一步改进,引入被引集中度指标η(consistency),从而提出Z指数。

那么,Z指数的计算公式为:
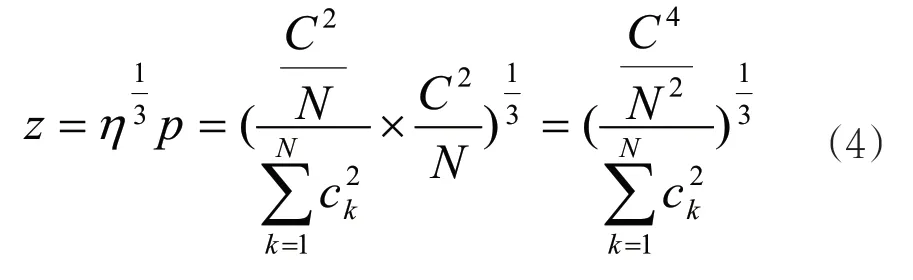
与p指数相比,Z指数在反映数量因素的总发文量和反映质量因素的平均被引率之外,又引入描述被引集中程度的η,通过计算每篇论文被引量的平方和,将三者有机地融合在一个指数中,从而使得论文被引量的分布状况在评价结果中得到一定程度上的体现。因此Prathap认为,Z指数是一种数量—质量—连续性(Quantity-Quality-Consistency)的3D效能评价指标。在p指数一定的情况下,论文被引量的平方和越大,说明被引集中度η越高,也即大量引用都集中在一篇或少数几篇论文上,评价对象之间的差距较大,Z指数越低;论文被引量的平方和越小,说明被引集中度越低,也即各篇论文被引量相对来说更接近,评价对象之间的差距更小,Z指数越高。俞立平认为,无论是团队、机构还是学术期刊,在水平较高的情况下,个体差距越小越好[28],这时Z指数反映的是一个集合中多个对象的总体水平,所以被引集中度越低,总体水平越高,Z指数就越高。但是对于单个学者来说,情况可能有所不同:被引集中度高,说明该学者可能拥有1篇或几篇被引量极其突出的论文。对于一名学者来说,在整个学术生涯中,也许就是这1篇或几篇高水准的论文奠定了其在学术界的地位,但是这时Z指数得分却可能比较低,所以Z指数在进行学者评价时的计算原理与应用范围,需要更进一步探讨。
3 基于代表作制度的Z指数改进方法设计与实证分析
3.1 基于代表作制度的Z指数改进方法原理
本文对Z指数改进的原理具体就是:在Z指数的计算过程中,不是学者的全部论文都进入计算,而是选择其中部分代表作来参加计算,具体是以h指数核心法和representative方法为例进行探讨。为方便讨论,分别用Zh和Zr表示使用h指数核心法和representative方法改进后所得到的指标,计算公式为:
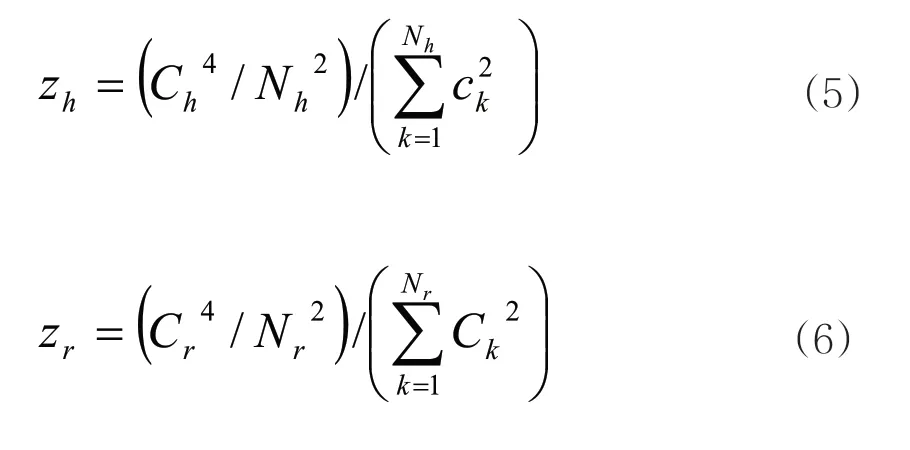
(5)和(6)式中Ch表示用h指数核心法选择出的学者代表作总被引量,也就是h核心论文总被引量,Nh表示h核心论文篇数,数值上等于h指数;Nr和Cr分别表示用representative方法选择出来的学者代表作篇数和这些代表作的总被引量。
3.2 实证分析
3.2.1 数据来源与获取
选择国内图书情报学领域60名知名学者为研究样本,以中国知网(CNKI)的中国引文数据库为数据统计源,检索这些学者2009—2018年间论文发表及引用情况。选择这一引文窗是考虑到学者撰写、发表论文及积累一定量的引用是一个需要较长时间的过程,通常10年的时间基本可以保障一名持续从事科研活动的学者能够发表一定量的论文并获取相当数量的引用。为尽量减少由于数据库更新给研究带来的误差,全部数据在2019年3月1日—7日检索完毕。由于本次研究主要目的为探索不同的评价原理对Z指数评价结果的影响,为降低复杂度,并未对合著论文的作者排序进行区分,如果有必要,可以在后续的研究中进一步专门分析作者署名顺序对评价结果的影响。
3.2.2 各指标总体分布情况
利用获取到的数据计算出每一名学者的排序与表1同。表1是各指标的描述性统计,对于非整数值,精度保留到小数点后4位数字。从表1可以看出,4种指标的极差(最大值—最小值)是Zr指数>Zh指数>h指数>Z指数,所以相比Z指数,Zr指数和Zh指数各值之间相差更大,在进行比较时可能更加直观地显示出学者之间的差距。
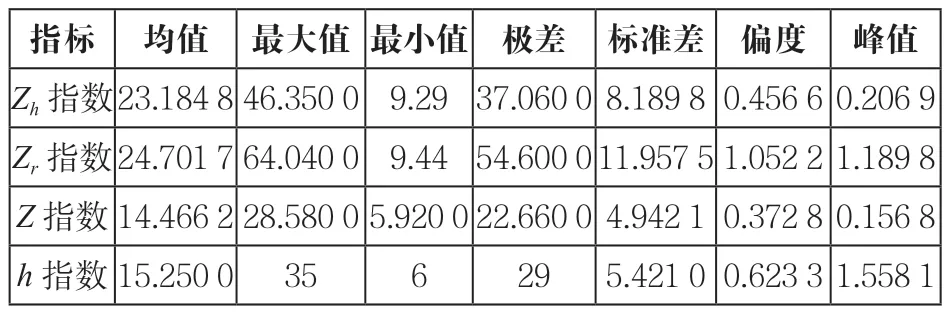
表1 各指标描述性统计
鉴于所使用的4种指标计算原理的不同,对各指标排序结果产生影响的论文篇数有所差异。总体上看,学者全部论文——无论是否获得过引用、无论被引用过多少次——对其Z指数的计算结果都产生影响,从14篇到345篇不等;只有h指数核心的论文对其Zh指数和h指数产生影响,从6篇至35篇不等;对学者Zr指数产生贡献的论文篇数最少,从1篇到7篇不等,其中只有1篇代表作的学者有38人,所以,representative方法对学者代表作的遴选机制更加严格。
3.2.3 各指标之间的相关性分析
Zh指数、Zr指数、Z指数和h指数之间的相关性分析如表2所示。从表2容易看出它们两两之间都存在相关性,且都通过了统计检验,这是因为这几种指标都来源于h指数,具有同源性。其中Zr指数与Z指数、Zh指数与Z指数、Zh指数与Zr指数的相关系数最高,分别为0.904、0.869、0.867,达到高水平相关,主要是因为这几种指数的计算方法相似,只是参加计算的论文选取方法有异;Z指数与h指数的相关系数是0.744,属于中高水平;Zr指数和Zh指数与h指数的相关系数分别是0.579和0.516,属于中等水平。
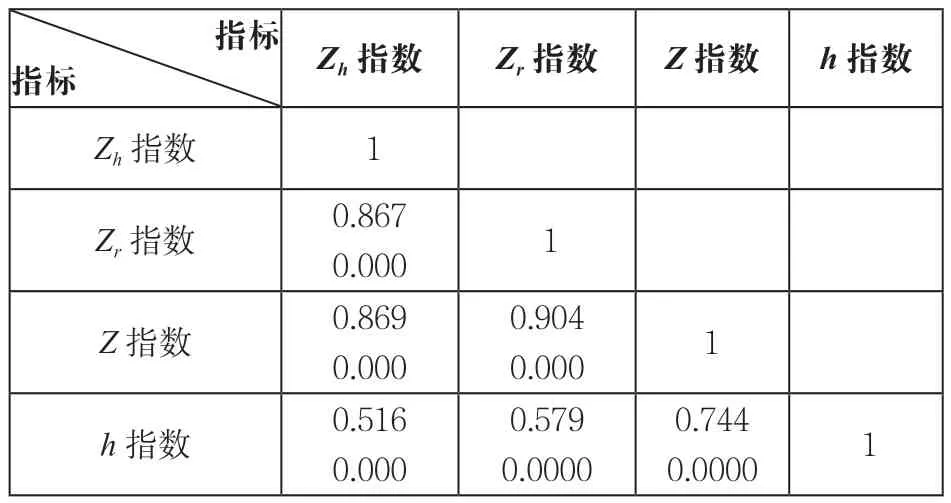
表2 各指标之间的相关性分析
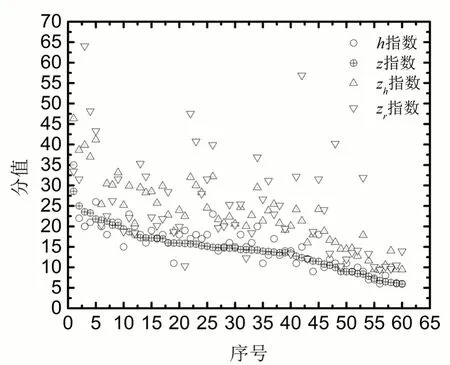
图1 样本作者各指标的散点图
3.2.4 样本作者各指数分布情况
图1是60名样本学者的各指标散点图,横坐标表示学者序号,纵坐标表示该学者各指标分值的大小,为便于观察,按照各学者Z指数大小降序排列的名次作为其序号,故图中Z指数的分值随横坐标递减。从图1中可看出,其他三种指数的得分,总体上与Z指数变化趋势保持一致,即随着横坐标的上升而呈不同程度的下降趋势,主要原因是由于这几种指数具有同源性,而各指数的变化趋势又有差异,Zr指数的最高点和次高点偏离横坐标原点非常明显,显示出其对高影响力学者的界定原理与其他三种指数的差异相对更大。
3.2.5 学者名次变化情况分析
表3给出4种指标分别位于前10名的学者数据,共涉及到17名学者。
从表3中的数值可以发现,邱均平的Zh指数、Z指数和h指数均排名第1,而Zr指数排名第11,与其他三个指标相差10名,主要原因在于他被引量最高的1篇论文与其他论文被引量相差较大,所以他的representative代表作只有1篇,被引量193次,而这篇论文的被引量却不是全部学者中最高的,导致他的Zr指数排名下降。
样本学者中Zr指数最高的是范并思,达到64.04,而他的Zh指数与Z指数排名第3,也是名列前茅,h指数排名第9。他的两篇representative代表作共被引726次,占其总被引量的37.46%,每篇论文被引量比第3篇论文高出近200次。被引量在前2篇论文上的集中程度较高,所以获得了很好的Zr指数排名。
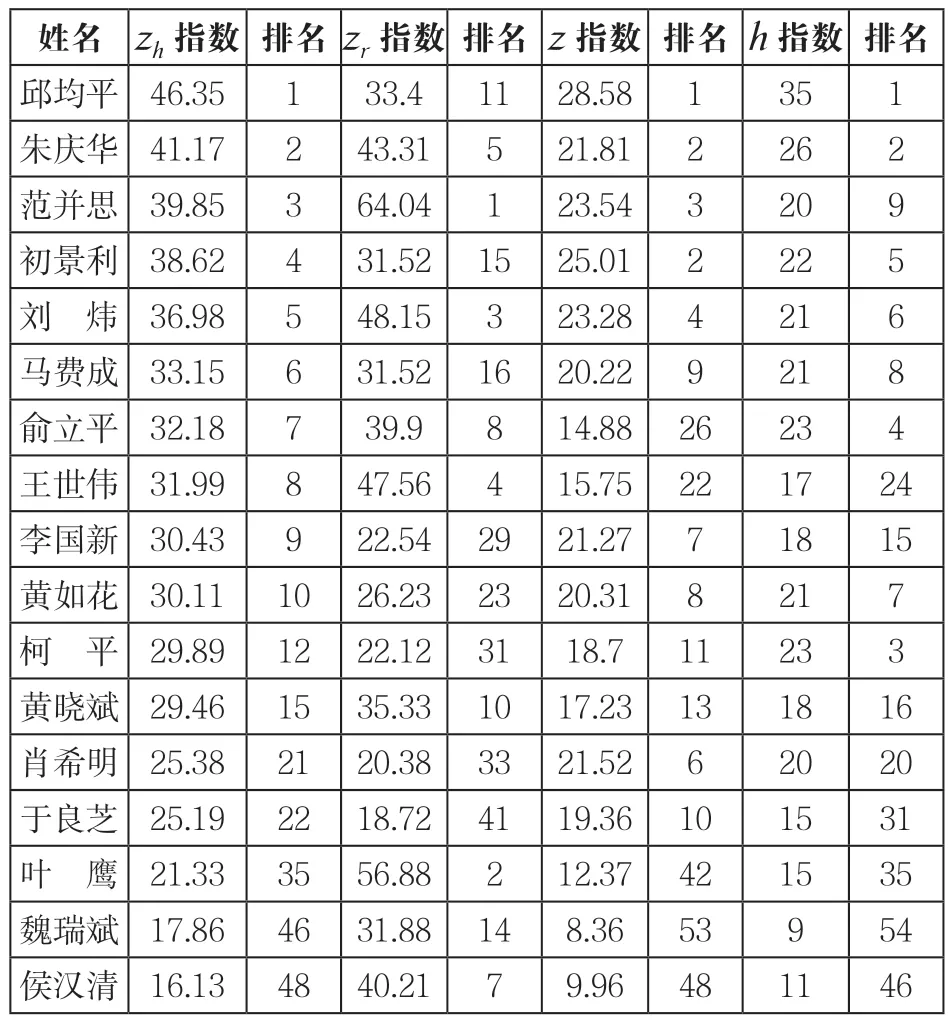
表3 4种指标排名前10的学者数据一览表
Zr指数与Z指数相比,共有3名学者名次没有发生变化,名次上升最多的是侯汉清和叶鹰。侯汉清Zr指数排名7,Z指数排名48,名次上升41名;叶鹰Zr指数排名2,Z指数排名42,名次上升40名。叶鹰被引量最高的1篇论文(也是其representative代表作)被引量达到429次,侯汉清被引量最高的1篇论文被引量为255次,所以他们的Zr指数分值较高,而从他们的论文被引量分布情况来看,他们各自的representative代表作论文被引量分别约占总被引量的45.1%和50.4%,整体上论文被引集中程度较高,所以Z指数较小,导致他们的Zr指数排名大大高于Z指数排名。总被引量名次下降最多的是王知津,Zr指数排名55,Z指数排名21,下降了34名。他的representative代表作论文也是1篇,被引量85次,在全部样本作者中并不算多,所以他的Zr指数较低;另一方面,从他的论文被引总体情况来看,他的各篇论文被引量相差不是很悬殊,论文被引集中程度较低,所以Z指数较大,故而他的Z指数排名大大高于Zr指数排名。另一位Zr指数比Z指数名次下降较多的学者毕强,其论文被引情况与之相似。Zr指数与Z指数排名变化情况最大的4名学者如表4所示。
Zh指数与Z指数相比,共有5名学者名次没有发生变化,而名次上升最大的是赵蓉英和袁勤俭。如表5所示,袁勤俭Zh指数排名25,Z指数排名45;赵蓉英Zh指数排名14,Z指数排名34,分别上升了20名。这两名学者的总发文量较高,分别是176篇和159篇,而且他们的h指数核心论文与其他论文被引情况差距比较显著,使得使用Z指数进行排名时,总发文量出现在分母的位置,便出现了这类计算方法固有的“惩罚高发文者,奖励低发文量”的缺陷,而Zh指数计算过程只有h指数核心论文发生作用,规避了这一缺陷。名次下降最大的是毕强,Zh指数排名38,Z指数排名12,下降了26名;任树怀Zh指数排名44,Z指数排名19,下降了25名。名次下降幅度明显的作者与全部样本相比,毕强总发文量149篇,与赵蓉英和袁勤俭相差不大,但是总被引量与前2名学者相差较大,但Z指数是最高的。任树怀的发文量和总被引量与前2名学者相比也是相差悬殊,同样Z指数是高于这2名学者。从这些指标来看,Z指数对学者的评价不够合理,而从Zh指数评价结果看,更加符合实际情况。
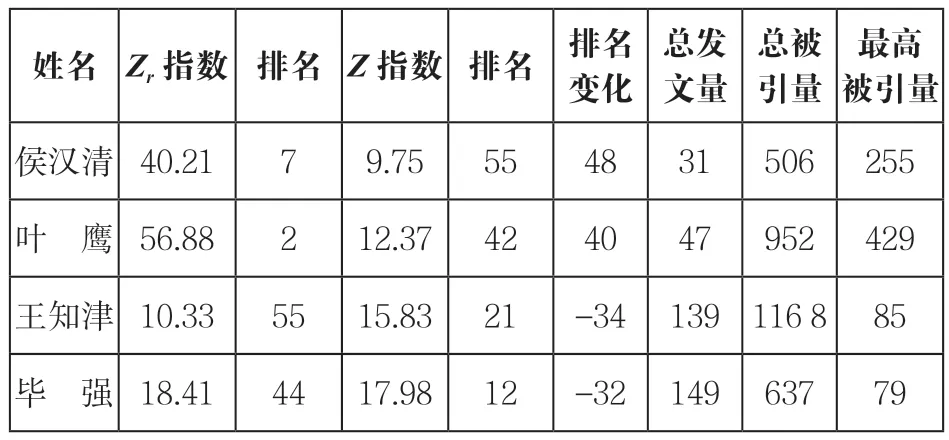
表4 Zr指数与Z指数排名变化情况最大的4名学者
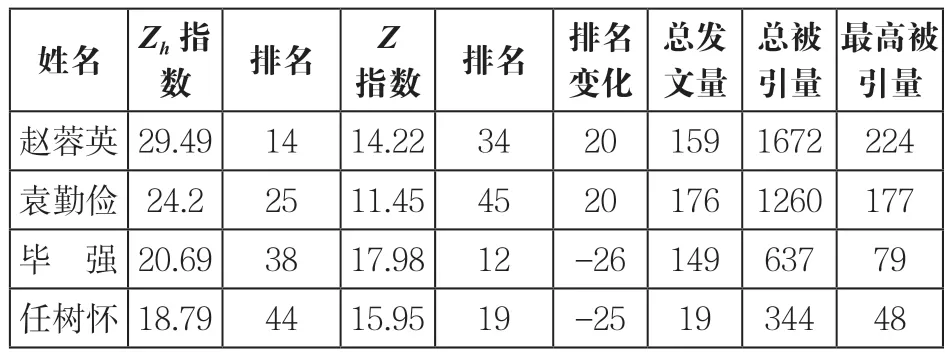
表5 Zh指数与Z指数排名变化情况最大的4名学者
4 结语
从以上分析可以看出,Zr指数和Zh指数汲取了Z指数的计算原理并加以改进得来,而Z指数是在p指数基础之上引入反映被引用集中程度的η而提出,p指数又来源于h指数,所以这些指标是一脉相承又各有特点。使用Z指数对学者开展学术评价时,学者全部论文与被引量都参加计算,即使是1次引用,也会对评价结果产生影响。而参加Zr指数和Zh指数计算的论文需要通过一定的方法遴选出来,所以只有部分论文对计算结果产生影响。
所选样本对象都是图书情报学领域的著名学者,他们为我国图书情报学研究的发展作出了不懈的努力,其发文和被引情况也各具特点。通过对他们各指数的实证研究,发现如果学者的1篇或几篇论文被引量显著高于其他论文及样本集合中其他学者的最高论文被引量,则有可能获得更好的的Zr指数排名;如果学者的h指数核心论文的总被引量较高,则有可能获得较好的Zh指数排名;如果学者的论文总被引量在样本集合中不算太低且相对来说比较平均,则有可能获得较好的Z指数排名。
学术评价是当今学术界的未解难题,至今没有一种公认的尽善尽美的学术评价方法或代表作选取方法,但是无论如何,一名科研人员代表作的质量应该优于其其他作品[22]。使用其他代表作选取方法对Z指数进行改进也有可能得到其他不同的评价结果,在实际工作中需要根据具体的评价目的,选择适合的方法开展评价工作,才能达到评价目的,并发挥出学术评价本身的意义。
