模拟低碳烯烃生产工艺的智能算法
2020-01-03刘兴旺竺伟俊
侯 旭, 刘兴旺, 竺伟俊
(1.长春工业大学 化学工程学院, 吉林 长春 130012;2.长春工业大学 材料科学高等研究院, 吉林 长春 130012)
0 引 言
低碳烯烃生产工艺模拟是当前化工领域的研究热点问题之一。低碳烯烃是橡胶、塑料和纤维等化学工业及相关合成工业的关键原料[1-4]。传统的热裂解工艺一直是低碳烯烃的主要生产来源[5-6]。近些年,为了满足日益增长的乙烯和丙烯需求,科研人员开发了石脑油/重油催化裂解等新型的低碳烯烃制备技术,引起了广泛关注[7-10]。碳氢化合物裂解往往受反应温度和催化剂用量的影响[11-13]。精确地解析系统特性对裂解反应的影响,对于开发新型的低碳烯烃生产工艺具有重要的指导意义[14-19]。
现阶段通常采用详细动力学模型、集总动力学模型和全局动力学模型描述碳氢化合物的裂解过程。详细动力学模型是以反应网络为基础,采用热力学参数描述关键的基元反应,适用于不同的操作条件[20-22]。集总动力学模型通过将产物分为若干组,减少了模型对反应机理的依赖[23-26]。在缺少反应机理的情况下,可以建立全局动力学模型,对于模拟复杂的化工过程具有积极的指导作用[27-28]。除了上述传统的建模方法外,机器学习技术正逐渐被应用于处理各类化学、化工领域的相关问题。机器学习具有准确、简单和灵活等优势,在函数逼近、数值预测、数据关联、过程仿真、设计优化等方面显示出潜力。神经网络算法作为一种深入的机器学习原型,已被用于物理化学性质及典型化工过程的模拟分析,引起了广泛关注[29]。
目前,尚未有研究报道智能模型应用于低碳烯烃制备工艺,这启发我们探索智能模型在低碳烯烃制备及相关烃类裂解过程模拟中的应用前景。文中对基于神经网络的智能模型开发过程做了简要说明,建立了正戊烷裂解制备低碳烯烃工艺的ANNs模型,并采用MSE和R2指标对其性能进行评价,考察了训练算法和拓扑结构对模型性能的影响,通过匹配训练算法与拓扑结构,建立了性能最优的ANNs模型,并进一步考察了该模型性能的稳定性,拓展了智能模型的适用范围。
1 智能模型简介
ANNs模型通过多层感知神经网络关联自变量和因变量,实现数据分类、再现等功能。神经网络是由相互连接的处理节点构成,这些节点分为输入层、隐藏层和输出层。反向传播算法用于确定神经网络模型的参数,已被证明是高效的,其数学表达式为:
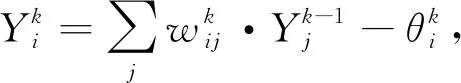
(1)

(2)
式中:k——ANNs拓扑结构中第k层,k≥2;
i——第k层中的第i节点;
j——第k-1层中的第j节点;
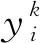

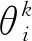

Xi——输入值。
总的来说,ANNs模型的建立遵循一个系统的过程:
1)数据预处理。通过下式将基础数据归一化,然后将其划分为训练数据和测试数据
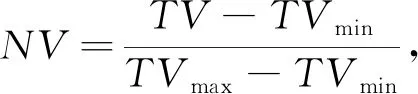
(3)
式中:NV——基础数据的归一化值;
TV——基础数据的真实值;
TVmin——基础数据的最小真实值;
TVmax——基础数据的最大真实值。
2)模型设计。采用经验法或启发法确定神经网络的拓扑结构,即隐藏层的层数和节点数,以及训练算法。
3)训练过程。在这一阶段调节模型的权值和阈值,使自变量和因变量相互关联,最终的模型参数应使计算数据和训练数据之间的偏差最小。
4)测试过程。确定了权值和阈值就完成了ANNs模型的建立,并能执行运算功能。此时,将测试数据的变量值输入,将得到的计算结果与实际值比较。
计算均方误差(MSE)和拟合度(R2),对ANNs模型性能进行评价:

(4)

(5)
式中:N——样本数据的总数;


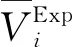
如果MSE值接近0,且R2值接近1,证明ANNs模型具有良好的计算精度;相反,如果MSE值偏离0或R2值偏离1,证明ANNs模型的计算精度较差,需要调整拓扑结构或者训练算法,完成又一轮训练过程,得到崭新的ANNs模型,重新进行测试。重复设计、训练和测试过程,可以改善ANNs模型的计算精度。
采用Matlab R2018a软件完成智能模型的相关运算任务,电脑配置包括i5-8600K CPU(4.0~4.4 GHz)、DDR4-3000 RAM(8 GB)及Windows10操作系统。
2 实验数据

3 结果与讨论
3.1 ANNs模型设计与优化
选用的训练数据占实验数据的90%,且均匀分布其中。分别将GD、CGB和LM三种训练算法应用于“2423”拓扑结构,建立GD2423、CGB2423和LM2423三种ANNs模型,同时,计算模型的MSE和R2值,训练算法对ANNs模型性能影响显著,见表1。

表1 训练算法对ANNs模型性能的影响
三种ANNs模型的训练MSE值均为10-4量级,正戊烷转化率、乙烯收率和丙烯收率的R2值均高于或者接近于0.9,证明计算数据与实验数据吻合度较好。进一步计算了测试MSE值,发现LM2423模型的测试MSE值最小。通过对MSE和R2值的比较分析,可以推测出LM2423模型具有较好的计算精度,因此选用LM算法训练ANNs模型。
为了探索隐藏层对ANNs模型性能的影响,设计了“243”、“2423”和“24223”三种拓扑结构,采用LM算法进行训练,建立LM243、LM2423和LM24223三种ANNs模型,计算相应的MSE和R2值,见表2。

表2 隐藏层对ANNs模型性能的影响
随着隐藏层增加,MSE值先增大后减小,R2值先减小后增大,LM24223模型表现出较好的性能。综合考虑隐藏层的影响,ANNs模型的隐藏层设定为3个。
通过调节第1个隐藏层的节点数,设计了“22223”、“24223”和“28223”三种拓扑结构,采用LM算法进行训练,建立LM22223、LM24223和LM28223三种ANNs模型,计算相应的MSE和R2值,见表3。

表3 隐藏层节点对ANNs模型性能的影响
随着节点数增加,MSE值先减小后增大,R2值先增大后几乎不变,LM24223模型表现出优异的计算精度。
综上所述,ANNs模型性能依赖于训练算法和拓扑结构,二者的最佳匹配有助于提高模型计算精度。与其它ANNs模型相比较,LM24223模型的拓扑结构为“24223”,选用LM算法进行训练,表现出最佳的计算精度,其MSE值接近实验误差(1.47×10-5)。
3.2 低碳烯烃生产模拟
通过模拟正戊烷裂解制备低碳烯烃,进一步考察LM24223模型性能,其计算结果与实验数据对比如图1所示。
图1中45°的实线(y=x)代表了计算结果和实验数据理想吻合,其偏差为0;虚线表示正戊烷转化率误差为±2%的边界线(见图1(a)),以及乙烯和丙烯收率误差为±1 wt.%的边界线(见图1(b)和图1(c))。研究发现,图1(a)、(b)和(c)中虚线之间点的比例分别为92%、98%和100%,说明92%正戊烷转化率的计算数据偏差小于2%,98%乙烯收率的计算数据偏差小于1 wt.%,100%丙烯收率的计算数据偏差小于1 wt.%。

(a) 正戊烷转化率
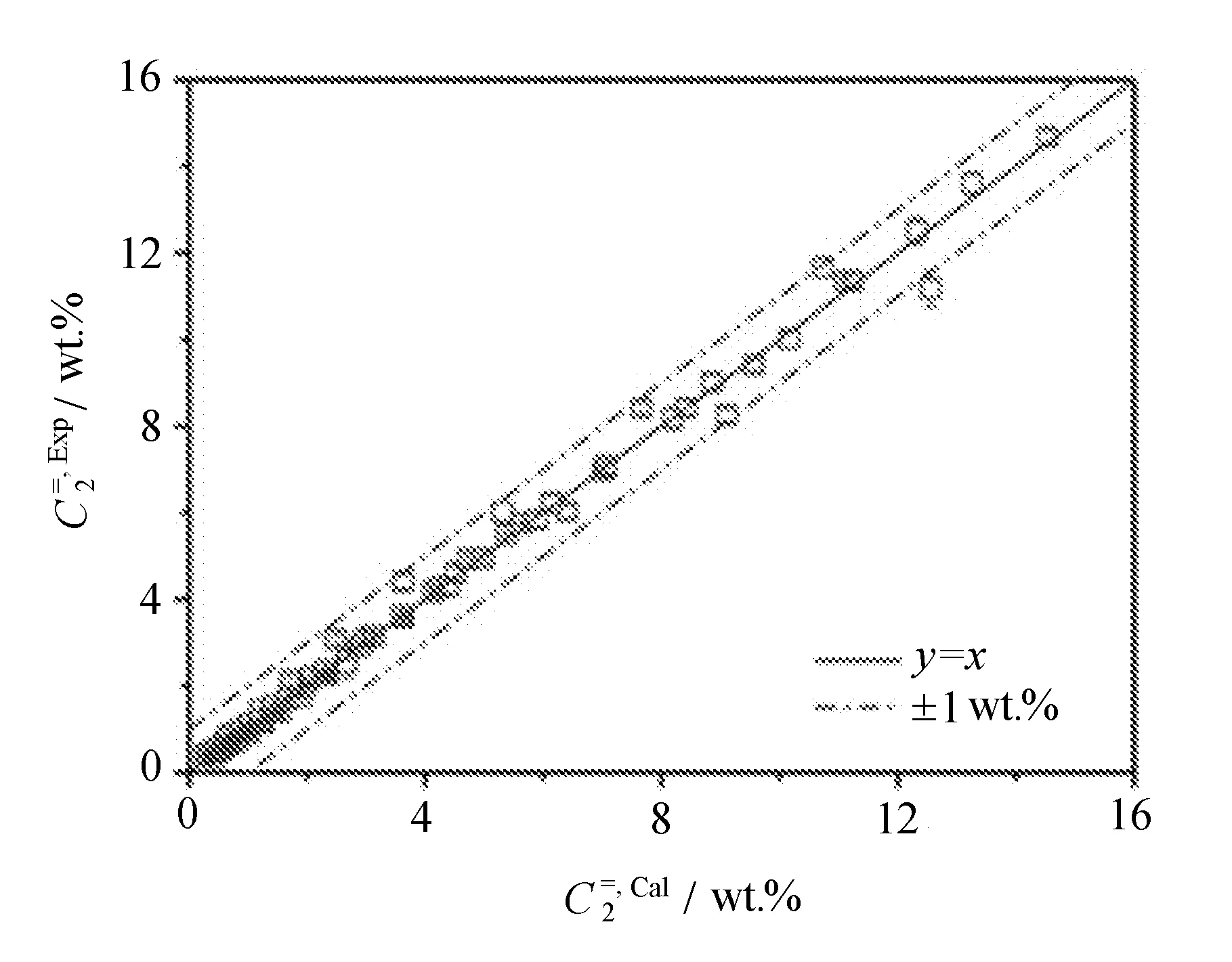
(b) 乙烯收率

(c) 丙烯收率图1 LM24223模型计算结果与实验数据对比
由此可以推断,LM24223模型很好地模拟了正戊烷裂解制备低碳烯烃过程,表现出极佳的准确性。
3.3 模型适用性
通过选取50%~90%实验数据用于训练过程,建立了一系列LM24223模型,并计算相应的MSE和R2值,考察训练数据量对LM24223模型性能的影响,如图2所示。
随着训练数据比例从90%降到50%,MSE值略有升高,R2值略有下降,但是,始终在可以接受的范围内,MSE值总是在10-3~ 10-5范围内,并且R2值接近于1。由此可以推断,随着训练数据的减少,LM24223模型性能略有波动,但是始终保持在较高水平。
基于不同训练数据的LM24223模型计算结果与实验数据对比如图3所示。
训练数据比例为90%~50%的LM24223模型的平均计算精度为:86%正戊烷转化率的计算数据偏差小于2%,92%乙烯收率的计算数据偏差小于1 wt.%,96%丙烯收率的计算数据偏差小于1 wt.%。虽然计算误差随着训练数据的减少而增加,但是LM24223模型始终保持较低的计算误差。由此可以推断,减少训练数据对LM24223模型计算精度的影响并不显著,验证了该模型模拟正戊烷裂解制备低碳烯烃的适用性。

(a) 正戊烷转化率

(b) 乙烯收率

(c) 丙烯收率图3 基于不同训练数据的LM24223 模型计算结果与实验数据对比
4 结 语
围绕智能模型的建立及其应用于模拟低碳烯烃制备工艺展开了系统研究。以正戊烷裂解制备乙烯、丙烯为研究对象,按照数据预处理、模型设计、模型训练和模型测试的过程,建立了多种ANNs模型,并以MSE和R2值评价其性能,考察了训练算法和拓扑结构对ANNs模型性能的影响,通过优化训练算法和拓扑结构的匹配建立的LM24223模型展示出令人满意的计算精度。进一步考察了训练数据对LM24223模型性能的影响,研究发现,LM24223模型的MSE值总是在10-3~10-5范围内,并且R2值接近于1,验证了该模型模拟正戊烷裂解制备低碳烯烃工艺的适用性。
