基于Logistics的中小微企业信用评价研究
2019-12-23李日扬

摘 要:中小企业是国民经济的重要组成部分,是推动中国经济增长的重要因素。但中小企业的融资仍然是制约其发展的难题。对于中小企业来说,企业经营者的信用状况很大程度上决定了中小企业贷款未来的偿还情况,中小企业主的个人维度信息将作为构建信用评价的不可或缺的变量。基于此,本研究在前人研究的基础上,建立了Logistics回归模型,并运用SPSS软件对90家中小企业数据进行实证分析。研究结果表明,信用评价模型在预测和准确性上取得了较好的结果。
关键词:中小微企业;信用预测;Logistics模型
中图分类号:F830 文献标识码:A 文章编号:1008-4428(2019)11-0133-02
一、 引言
自從1978年以来,我国中小微企业发展迅猛。截至2017年底2018年初,全国各类企业总数达到了1527.84万户。小型微型企业1169.87万户,占比76.57%。
从中可以看到,中小微企业在国民经济里占了非常重要的地位,是我国经济增长的强劲动力,然而目前中小微企业的资金支持远远不能满足其发展的需要,中小微企业的信用担保不稳定、融资存在高风险是银行等商业机构不愿意贷款的主要原因。上述问题的本质在于当前的中小微企业信用评价体系不能够很好地反映其信用水平,这是中小微企业融资困难的一个重要原因。故,当前需要建立一个合理的中小微企业信用评价体系。
本文对中小微企业信用评价模型进行研究,分析中小微企业信用评价的指标,加入了企业主个人维度指标,构建一个评价指标更加完善的中小微企业Logistics信用评价模型,最后运用SPSS软件对数据进行实证分析,进而完善信用评价体系的相关研究。
二、 相关企业信用评价技术
在1950之前,主要通过专家自身的经验去评价企业信用,专家通过阅读材料结合经验做出最后的信用评价,这种方式带有极强的主观性,造成误判的也无法避免。到了1960年之后,人们开始采用定性的方法去研究企业信用评价,特别是统计方法的研究。
从以往的公司经营成败经验发现,公司的财务信息至关重要。最早采用公司财务比率进行信用分析的是威廉·H·比弗(1967),他通过将经营失败(failure)定义为一个公司无法偿付到期债务,根据这一定义搜集了158 家公司(79 家失败和79 家非失败公司)的配对样本,运用了两分法检验单一财务比率对财务失败的预测能力。之后,Altman(1968)通过对财务比率等变量采用统计方法进行筛选,建立了多元线性判别式分析模型,即Z-score模型,Z-score模型在预测公司成败的问题上取得了较好的效果。迈耶和皮弗(1970)首先采用线性概率模型对公司运营失败进行预测,但是后面发现该模型在应用上有较大的统计问题。到了1970年后期,学者的研究方向从线性回归转移到非线性回归,在预测公司失败的研究上多采用多元条件概率模型,到20世纪90年代后期出现了一批综合性的信用评价方法。决策支持系统和多目标决策相继被提出用于解决有关定性变量方面的问题。随着计算机技术的发展,专家评估系统和人工神经网络也被逐渐应用到企业信用评价当中来。
根据具体状况不同,采用构建中小微企业信用评价模型的方法也有所不同。国内学者也对中小企业信用评分模型进行了比较和分析,发现Logistics回归模型相对于其他方法比较优秀。但是在对中小微企业的信用指标选择上,学者们多数集中在企业的财务信息上,而中小微企业中有很大一部分是企业主个人企业,企业的信用与企业主个人相关性较大,中小微企业所有者的信用状况在很大程度上决定了企业贷款的偿还。
综上,本文在基于公司财务指标的前提下,加入部分企业主个人的财务指标,运用Logistics模型,评价中小微企业的信用,这能很好地反映企业真实的信用状况。
三、 建模分析
(一)数据准备及特征变量选取
根据我国2011年7月发布的新的中小企业划分标准,报告中将中小企业划分为中型、小型和微型三大类。
基于此,本文通过企业调查的数据得到了90份样本数据,既包含了上市公司,又包含了个体经营企业等。根据企业是否拖欠工人工资、客户贷款和其他债务,以及是否履行合同不力等行为将企业定义为坏客户,反之则定义为好客户。如此,可将得到的数据划分为60个好客户、30个坏客户。
本文综合考虑三大报表,将各报表的数据互相结合、对比。以偿债水平、盈利水平、营运水平以及成长水平四个方面维度作为基础,来构建中小微企业信用评价指标体系。在此基础上将中小企业主的收支情况、信用记录等信息作为变量纳入模型,最终我们将38个特征变量作为初选变量选入。其中包括4个企业特征变量,16个体现企业内部财务状况的特征变量,18个企业主特征变量。
通过设定相关系数阈值为0.65,对变量进行相关性检验。变量间相关系数大于0.8,可以作为判断变量间是否具有多种共线性的临界点。根据隶属度以及设定的阈值,删除了6个变量,最终结果保留32个变量进入下一步的Logistics回归模型。
(二)Logistics结果
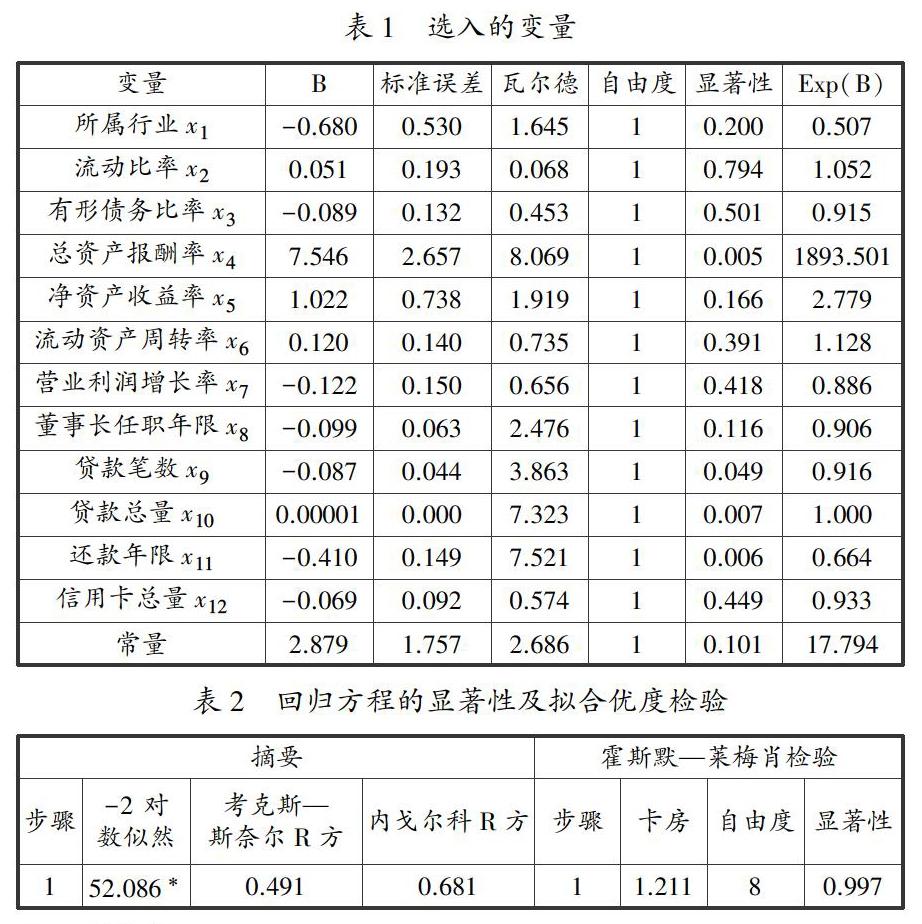
在经过上述变量的筛选以及多重共线性处理后,将选入的变量数据导入SPSS软件中做Logistics回归分析。分别通过向前和向后逐步筛选对选入的变量做进一步的分析和剔除,反复多次之后再运用enter 方法进行再次回归分析,得到最终的模型结果。经过多种方法尝试和回归结果比较,发现向前(有条件)方法的回归结果较好,但是筛选出来的变量较少,有些较为理想的变量未被选入,故采用enter方法将部分变量强制进入回归,得到了较好的结果,如表1所示。
从表1看到部分方程中的变量显著大于0.05,但从表2可以看到方程的-2对数似然值为52.086,内戈尔科R方的值为0.681大于0.5小于1,可以认为回归模型的显著性水平和拟合优度良好,霍斯默-莱梅肖检验显著性水平P值为0.997,接近于1,故不应该拒绝原假设。可以认为样本实际值得到的分布与预测值得到的分布没有显著差异,回归模型的拟合度较好。
将最终得到的变量及模型回归系数带入LogitP=ln (P1-P)得到Logistic回归方程:
(三)ROC曲线、AUC值与临界值的确定
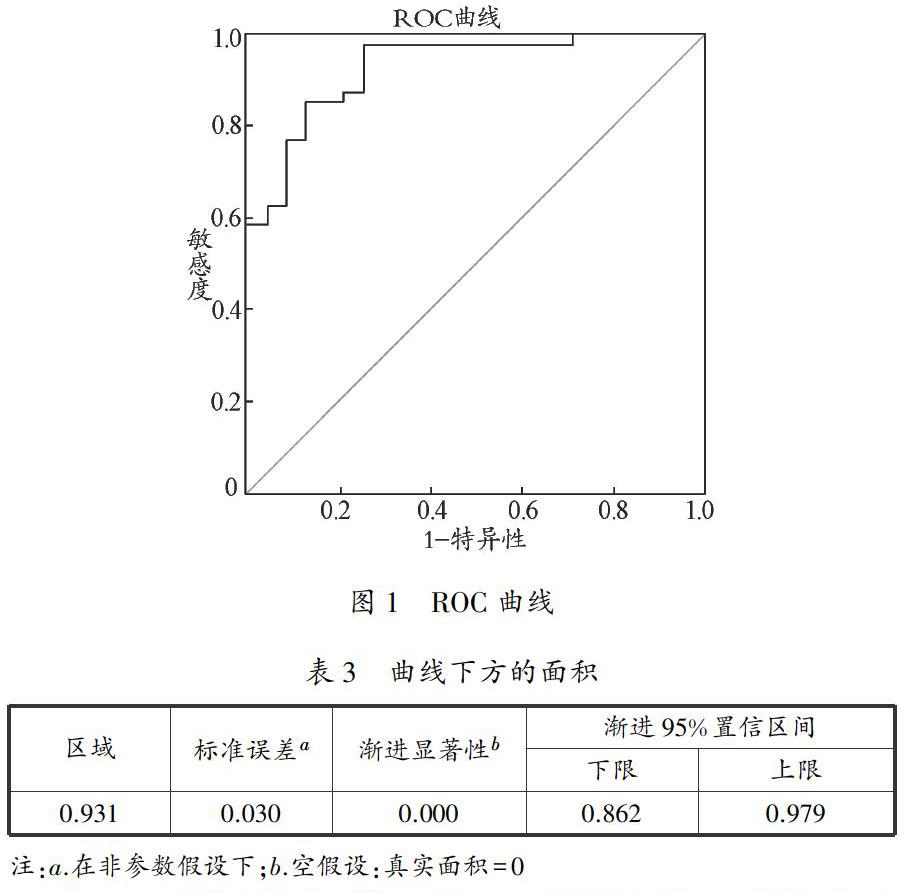
如图1所示,ROC曲线接近图的左上角,与对角线的距离较远,可以判断该Logistics信用评价模型在区分好坏客户上结果较好。并且可以从表3看到AUC(Area Under the Curve)的值为0.931,接近于1,同样说明了模型有较强的辨识好坏客户的能力。
SPSS軟件的默认截断值是0.5,即若是模型预测值如果大于0.5,则判断为好客户;否则判断为坏客户。默认的截断值设置得过小容易导致较大的误判,即将会违约的客户判断为好客户的概率变大,这在实际应用中会带来本金的损失。可以从模型的预测分类表4中看出,本文能够正确识别坏客户的比率只有73.3%,但是模型的整体准确率却能达到84.7%,所以需要ROC曲线来重新确定临界值。
如表5所示,当预测好客户的概率为0.4200时,尤登指数的最大值为0.729,那么该点所对应的尤登指数值即为临界值。即在实际应用中模型预测值大于0.729,则判断为好客户,反之则为坏客户。
四、 研究结果
对于中小微企业来说,中小微企业经营者的信用状况很大程度上决定了中小微企业贷款未来的偿还情况,将中小微企业主的收支状况、信用记录等信息作为构建企业信用评价模型不可或缺的变量。基于此,本文在借鉴前人的基础上,引入了企业维度变量同时加入了企业主个人维度的变量,运用SPSS软件,利用90家中小企业数据构建了Logistics回归模型,比起以往的信用模型在准确性和易用性上有很大的提升。研究结果表明,模型在主要关注的目标即识别好坏客户以及预测方面取得较好的结果。将来可以将模型进一步拓展,将其开发成信用评分卡,使得模型在使用上具有更好的简便性和操作性。
参考文献:
[1]胡航.企业信用评价模型的研究与实现[D].西安:西安电子科技大学,2012:121-130.
[2]张金贵,侯宇.基于Logit 模型的中小企业信贷风险实证分析[J].会计之友,2014(30):41-45.
[3]刘小龙.基于Logistic 模型的中小企业财务危机预警研究[D].上海:东华大学,2014:135-139.
[4]郑玉华,崔晓东.公司财务预警Logit模型指标选择与实证分析[J].财会月刊,2013(24):15-18.
[5]王千红,张敏.我国中小企业信用违约风险识别的实证研究[J].上海经济, 2017(1): 91-100.
[6]Miyamoto.M.Credit Risk Assessment for a Small Bank by Using a Multinomial Logistic Regression Model[J].International Journal of Finance & Accounting,2014,3(5):327-334.
[7]邓爱民,王珂.中小企业在供应链金融业务中信用风险评估的实证研究[J].征信,2015(9):23.
[8]施林丽,李晨宇,季琛.基于Logistic 回归模型的中小企业信用评价[J].高师理科刊,2018,38(5):10-17.
[9]朱艳敏.基于信用评分模型的小微企业贷款的可获得性研究[D].苏州:苏州大学,2014.
[10]李战江.微型企业信用评价指标体系的构建[J].技术经济,2017,36(2):109-116.
[11]朱艳敏,陈超. Z_score模型最优分割点的确定方法比较:基于违约风险预测能力的分析[J].南方金融,2013(8):74-77.
作者简介:
李日扬,男,海南澄迈人,北京邮电大学经济管理学院研究生。
