基于改进深度学习算法的区域实时定位方法研究
2019-12-23江春
江 春
(南宁学院网络信息中心,广西 南宁 530200)
0 引 言
随着多媒体视频领域迅速发展,视频图像已成为人机交互的主要表现形式[1]。在视频图像在采集和传输等过程中常常会因为受到噪声污染而使视频图像质量下降,出现模糊、错位等情况,进而造成不同图像处理算法性能下降[2]。因此在图像处理前,需先对图像噪声污染位置实施检测,而视频图像区域实时定位则是图像检测领域内一个热点研究课题[3]。
当前,已有许多专家学者对视频图像定位方法进行了研究,取得了较好的研究成果。文献[4]提出了一种基于高程数据的无人机视频区域实时定位方法,该方法允许用户在无人机航拍过程中实时掌握视频拍摄区域,通过在视频中框选地面目标,能够实时计算出目标的经纬高,将改信息在Google卫星地图上显示,实现区域实时定位,但是该方法存在定位精度较低的问题。文献[5]提出一种基于GPS的立体视频移动目标实时定位方法。计算视频帧中目标的位置,将计算得到的目标位置输出与两个GPS接收机的相对位置进行了比较,并比较了所有时间点的视频测量计算坐标与基于GPS的相对距离,得到目标定位结果,但是该方法的稳定性较差。文献[6]提出一种基于特定视觉特征的视频图像区域实时定位方法。利用混合高斯函数构建视频监测区多态散布模型,对监测区域的视频图像进行去噪处理,获得视频图像颜色特征,利用颜色直方图Euler距离实现特定图像特征的跟踪匹配,进而实现对视觉检测区域的实时定位,但是该方法存在定位精度较低的问题,实际应用效果并不理想。
当前学习领域内进步最快的方法就是深度学习方法,该方法本质是对传统神经网络方法的改进。深度学习算法具有精度高、泛化能力强、适用范围广等诸多优势,在图像检测领域中具有较高的应用价值。本文将深度学习算法应用在视频图像区域实时定位中,提出一种基于改进深度学习算法的区域实时定位方法,实验结果表明该方法能够有效提高区域实时定位的准确性,具有较高的稳定性。
1 区域实时定位方法分析
1.1 基于改进深度学习算法的区域实时定位方法
1.1.1处理流程
在设计区域实时过程中采用深度算法,设计基于纹理特征的逐层增量深度学习算法,图1中描述的是算法处理流程。
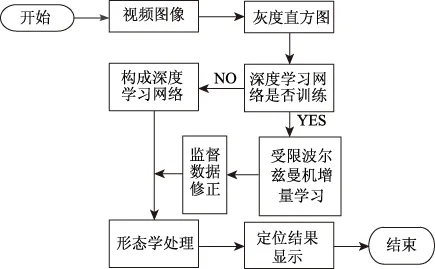
图1 算法处理流程
如图1所示,该方法利用图像灰度直方图采集图像区域的纹理特征,由于灰度直方图是获得图像纹理特征的最有效方法之一,因此提取图像纹理特征的准确性高;受限玻尔兹曼机具有强大的无监督学习能力,能够学习数据中复杂的规则,以获取的纹理特征为训练样本,通过受限玻尔兹曼机对训练样本逐层增量学习并对训练样本的权值进行判定,在学习过程中,将标记样本当成监督数据实施网络微调,组建深度学习网络训练获取区域图像,再通过标记区域的二值图像实现区域实时定位,通过上述过程能够有效提高视频图像区域实时定位精度。
1.1.2图像纹理特征提取
采用灰度直方图获取区域图像的纹理特征,该方法描述的是不同灰度级内图像区域灰度出现的概率,以函数f(x)代表,其中灰度值为x。
若x的均值是u,也就是:
(1)
那么u的n阶如下:
(2)
式(2)内,mn(x)受f(x)分布现象影响,用m1和m2分别描述图像灰度值分散情况和方差,其中m2为灰度对比度的量度,描述均值对比下的灰度值分布状况,主要体现的是直方图相对平滑程度和图像内纹理深浅状况。m3和m4分别表示偏度和峰度,偏度即直方图偏斜度,即灰度值与均值的对称性[7],可描述图像区域内纹理灰度起伏情况,峰度即直方图相对平坦度,也就是直方图分布聚集情况,能够体现图像区域内纹理灰度的反差。
基于灰度直方图的图像纹理特征提取算法包括三个步骤[8],分别是:彩色图像与灰度图像转换、提取灰度直方图、提取直方图均值和运算特征向量。
通常情况下,因为提取纹理特征的源图像区域多为不具备灰度项的BMP格式,所以需通过式(3)获取源图像区域的灰度值:
X=0.299R+0.587G+0.114B
(3)
式(3)内,X和R、G、B分别表示灰度值和红、绿、蓝分量值。
将彩色图像转换为灰度图像后,计算不同灰度级内灰度图像的灰度出现次数,获取灰度直方图,通过式(1)获取灰度值均值。得到灰度值均值后,通过式(2)获取直方图的n阶矩(n=1,2,3,4)得到4个特征向量,通过4个特征向量表示图像区域的纹理特征。
获取图像区域纹理特征后,将纹理特征作为训练样本,利用受限玻尔兹曼机逐层增量深度学习算法构建深度学习网络,采用学习网络对纹理特征训练样本进行训练,实现视频图像区域的实时定位。
1.1.3深度学习网络构建和训练
采用受限波尔兹曼机概率模型构建深度学习的网络[9]。1986年,生成式随机循环神经网络—受限玻尔兹曼机首次被提出,其本质为两层无向图模型,两层分别是可视层和隐藏层[10],用v和h表示,模型中同层节点间的连接受限,不同层间存在连接关系,详细描述如图2所示。

图2 受限波尔兹曼机概率模型
若受限波尔兹曼机概率模型内全部的节点均为随机二值(0,1)变量节点,且全概率分布W(v,h)为波尔兹曼分布,当v为已知时,全部隐藏节点间保持条件独立[11]。波尔兹曼机的联合组态能量表达式为:
(4)
式(4)内,参数集合用δ={P,a,b}表示,g和d分别为可视节点与隐藏节点的偏置向量,那么当状态为δ时,受限波尔兹曼机概率如下:
(5)
当隐藏层/可视层为给定情况时,可视层/隐藏层概率如下:
(6)
(7)
用D={v(1),v(2),…,v(N)}和δ={P,g,d}分别表示独立同分布的样本集和需要学习的模型参数,通过最大似然估计能够得到:
(8)
基于最大对数似然函数L(δ)求导Pij,能够获取L(δ)最大情况下对应的参数Pij为:
(9)
式(9)内,KWdgtg[vihj]和KWδ[vihj]分别表示观测数据训练集的期望和受限波尔兹曼机模型内定义的期望。由下而上构建深度学习网络过程中,以下层的输出为上层的输入,层层向上至输出层。
深度学习网络构建成功后,为获取最优权值需对其实施训练,一般情况下,深度学习网络训练由两个阶段组成,分别是由下而上的非监督学习阶段和由上而下的监督学习阶段[12]。训练过程如下:在利用受限波尔兹曼机对2.2章节获取的纹理图像特征实施逐层增量学习过程中,采用最大似然估计法持续修正深度学习网络内的权值,以满足受限波尔兹曼机能量稳定的要求;通过监督数据二次修正深度学习网络。
在进行由下而上的非监督学习时,深度学习网络内各状态值分别与一层结点相对应,确定的输入输出数据均与结点状态值为1的概率值相对应,不同区域的纹理样本以H0层的输入向量表示,经由轮流的吉布斯采样得到的结构为深度学习网络的输入。以n表示深度学习网络结构内的隐藏层个数,L1,L2,…,Ln表示各层中的节点数量,在深度学习网络的输入层H0层内加入纹理特征图像,对H0与H1间的权值P0持续修正,利用式(7)对按照式(8)、(9)将修正后的P0同初始数据进行运算,获取的新概率值作为H1层的输入数据。上述过程循环运算后得到P1,P2,…Pn-1,由此确定深度学习网络的初始权值为Pi={P0,P1,P2,…Pn-1}。深度学习网络由H0,H1,H2,…,Hn层与样本标签数据层组成,包含64个节点的H0层和标签样本层分别为输入层和输出层,L1,L2,…,Ln为中间n层的节点数。通过无标注的训练样本构建深度学习网络,通过H0与H1间的训练进行说明,两者构成了一个受限波尔兹曼机,H0和H1的节点数分别同可见层v和隐藏层h的节点数一致,通过轮流的吉布斯抽样修正权值P0,至受限波尔兹曼机收敛。
在进行由上而下的监督学习时,将受限波尔兹曼机修正获取的权值当做监督学习阶段的初始权值,原因在于经过受限波尔兹曼机修正获取的样本标注的权值准确性比为未修正的权值要高,不仅如此,将其作为监督学习阶段的初始权值能够降低二次权值修正的复杂性。利用梯度下降法对样本标注进行二次修正权值[13],能够有效提高区域定位的准确性。
经由深度学习网络对区域纹理图像特征实施训练输区域图像,利用形态学处理方法对区域图像空洞位置和孤立点实施填充、去噪、腐蚀和膨胀等操作过程,将获取的标记二值图像映射至原图像,实现清晰、准确的区域实时定位。
1.2 区域实时定位软件开发实现
上述过程采用改进深度学习算法实现区域实时定位,在此基础上在VS2008环境下,采用QT程序框架实现区域实时定位软件的开发。
开发的区域实时定位软件主要由图像地址获取模块、接口适配模块、空间分配模块、下采样模块、结构相似度模块、定位模块和结果存储模块等构成。区域实时定位软件在VS2008环境下,通过对话框MFC工程开发实现的[14]。对话框工程由数个按键组成,各按键与句柄相对应,经由句柄触发C函数。操作界面与信息交互界面的初始化通过程序启动是系统调用的函数“C噪声识别和定位Dlg::OnInitDialog” 初始化实现。
由于对话框工程的按键结构,仅需将处理功能代码录入相应的函数模块内即可完成核心算法功能[15]。软件将下采样模块和结构相似度模块等集成于按键“载入待识别图像”使应用过程更加简洁。“void C噪声识别与定位Dlg::OnBnClickedButton1()”为“载入待识别图像”应用对话框源程序内的函数,此函数模块内的代码为主程序。图3中描述的是主程序实现框架。
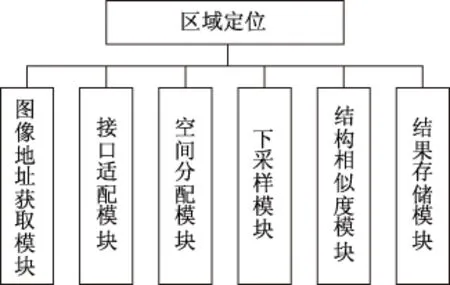
图3 主程序实现框架
数据类别转换、信息提取和管理存储图像的内存空间是接口适配模块和空间分配模块的主要功能;结构相似度模块能够计算子图像间的结构相似度,获取纹理特征的主要参数,并通过深度学习网络对其实施权值修正,利用形态学处理方法实现准确的区域实施定位。定位结果通过结果存储模块导出,写入硬盘。
2 实验分析
实验为验证本文基于改进深度学习算法的区域实时定位方法的定位性能,选用500张不同背景的视频图像作为实验对象,在相同实验环境下采用本文方法、文献[4]基于高程数据的无人机视频区域实时定位方法、文献[5]基于GPS的立体视频移动目标实时定位方法和文献[6]基于特定视觉特征的视频图像区域实时定位方法对实验对象进行区域定位,对比不同方法的准确性与稳定性,结果如表1所示。

表1 不同软件的区域定位性能对比
为了更清晰的体现不同方法的区域定位性能对比结果,将表1内的查全率、查准率和F系数用柱形图的形式进行描述,结果如图4所示。
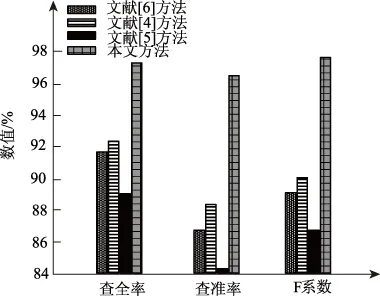
图4 不同软件的区域定位性能对比
分析上图可得,本文方法与其他区域实时定位方法的区域定位效果相比较,定位区域图像的查全率和查准率及F系数能显著高于其他方法,其中查全率高出5.21%以上,查准率高出8.19%以上,F系数高出7.50以上。实验结果表明本文方法的区域定位性能较好,其主要原因在于本文方法利用受限玻尔兹曼机逐层增量深度学习算法构建基于深度学习算法的深度学习网络,通过非监督学习阶段和监督学习阶段对视频图像纹理特征实施训练,输出区域图像,利用形态学处理方法进行区域图像后续处理,完成清晰、准确的区域实时定位,因此能够提高区域实时定位的准确性。
实验为测试本文方法中深度学习网络结构不同层数对本文方法区域实时定位结果的影响,将深度学习网络层数分别设置为2层、3层、4层、5层和6层,对比不同层数深度学习网络的区域实时定位性能,结果如表2所示。
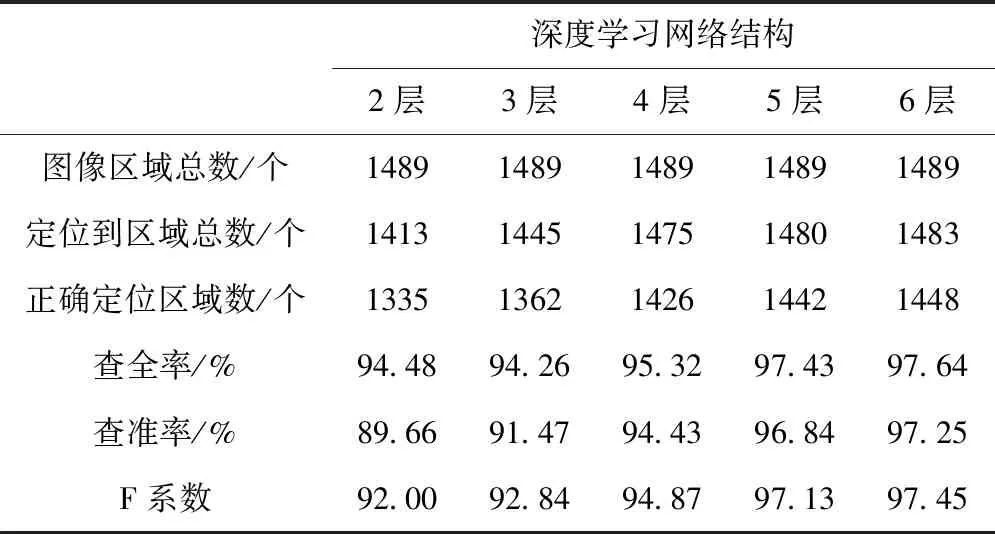
表2 不同深度学习网络结构性能对比
为了更清晰的体现深度学习网络结构不同层数对区域定位性能的影响,将表2内的查全率、查准率和F系数用柱形图的形式进行描述,结果如图5所示。
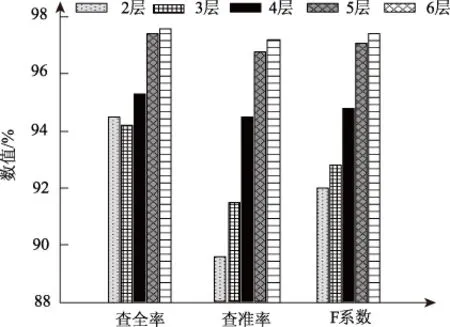
图5 不同深度学习网络结构性能对比
分析表2和图5能够得到,当深度学习网络结构层数低于4层时,本文方法的定位性能F系数低于93%;当深度学习网络结构层数为4层时,定位性能F系数低于97%;当深度学习网络结构层数高于4层时,定位性能F系数高于97%。也就是当深度学习网络层数逐渐提升时,本文方法的区域定位性能也随之提升。然而当深度学习网络结构层数提升时,随之提升的还有网络的复杂度,同时网络的泛化能力也有所下滑,因此深度学习网络结构并是不层数越多越好。实验结果表明,本文定位方法深度学习网络结构为5层,即可满足区域定位精度需求。
实验对本文方法的定位稳定性实施测试。针对不同大小的视频图像,使用本文方法、文献[4]方法和文献[5]分别进行区域定位,对比不同方法的定位结果,用表3、表4和表5描述。其中,Y值表示不同软件对区域实时定位水平的预测值[10]。
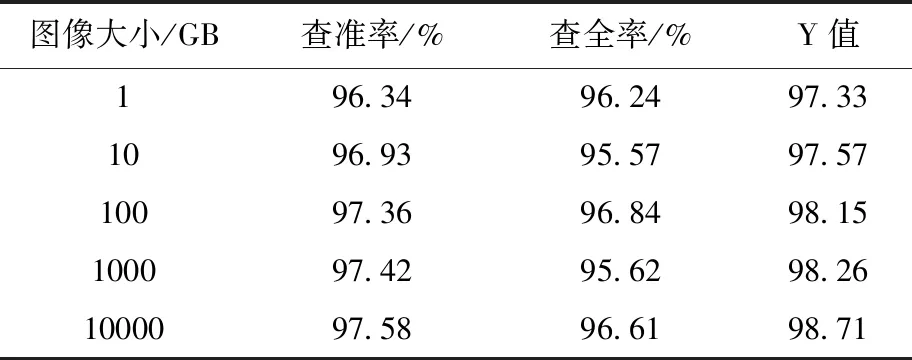
表3 本文方法稳定性测试

表4 文献[4]方法稳定性测试
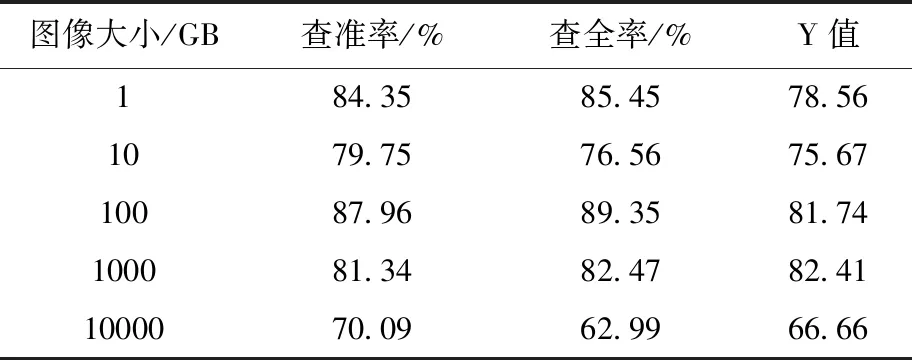
表5 文献[5]方法稳定性测试
分析上述三表可得,使用本文软件对不同大小的视频图像进行区域定位得到的查准率、查全率以及Y值,随着视频图像大小的持续提升均呈线性平缓上升趋势,同时各值均高于95%以上;文献[4]方法和文献[5]方法获取的结果随着视频图像大小的持续提升呈现出显著的波动状态,同时各值均低于95%。实验结果表明本文平台的定位稳定性较好,其主要原因在于本文方法将受限波尔兹曼机修正获取的权值当做监督学习阶段的初始权值,采用梯度下降法对样本标注进行二次修正权值,能够有效提高区域定位的稳定性。
3 结 语
本文设计基于改进深度学习的区域实时定位软件,将深度学习算法应用在视频图像区域定位当中,利用受限玻尔兹曼机逐层增量深度学习算法,依据图像纹理特征构建深度学习网络后,对深度学习网络实施训练获取区域图像,通告形态学处理方法对区域图像的空洞位置和孤立点实施填充、去噪、腐蚀和膨胀等操作过程,将获取的标记二值图像映射至原图像,实现高精度的区域定位,同时在VS2008环境下,采用对话框MFC工程实现区域实时定位软件的开发。
实验结果说明,本文方法进行图像区域定位过程中的查全率高出5.21%以上,查准率高出8.19%以上,F系数高出7.50以上,表明本文软件区域定位性能较好;当本文定位软件深度学习网络结构为5层时,可获取最佳的区域定位精度;本文软件定位不同大小视频图像区域的查准率、查全率以及Y值均高于95%,并且具有较高的稳定性,这些实验结果充分说明本文定位软件具有较高的图像区域定位性能,应用效果佳。
