基于Hadoop的分布式集群大数据动态存储系统设计
2019-12-23吴晓晖
陈 磊,吴晓晖
(1.武汉工程大学,湖北 武汉 430000;2.嘉兴职业技术学院,浙江 嘉兴 314000)
0 引 言
大数据也称巨量资料,是必须使用新处理方法才可拥有强大决策力、洞察力与流程优化能力的大量、高增长率与多样性的信息资产[1]。大数据具有大量(Volume)、高速(Velocity)、多样(Variety)、价值(Value)的4V特征[2]。随着数据量爆炸式的增长,高效率、低成本的存储数据逐渐受到人们关注,将分布式文件系统作为大数据存储载体,是当前大数据存储领域相关技术人员重点关注方向[3]。
针对大数据存储效率低、容量大问题,采用分布式集群存储方式,减少单个存储任务存储时间,增加单位时间存储数据量,提高大数据动态存储效率。目前已有一些研究成果。如文献[4]提出了一种动态负载均衡的分布Name Node算法,通过元数据多副本异构节点的动态适应性备份,使元数据在考虑节点性能及负载的情况下实现了动态分布,提高了元数据的读写性及可用性。文献[5]针对电力企业数据,提出了一种分布式数据质量管理解决方案。利用Hadoop分布式处理框架的解决方案,把缺陷数据从Oracle中抽离,分散存储在集群里多台服务器上,有效地提高了磁盘I/O性能和数据分析性能。文献[6]提出了一个Hadoop生态系统的数据感知模块,以及用于遗传算法的分布式编码技术,框架允许Hadoop基于数据本身的集群分析来管理数据的分布和存储。具有较好的存储和响应性能。
本文的大数据冬天存储系统也是基于Hadoop生态系统,其特点和创新之处是融合分布式存储和集群两者方式,设计了大数据动态存储系统,实现高效率大数据动态存储。
1 分布式集群大数据动态存储系统
1.1 系统硬件设计
大数据本身对数据采集、存储与检索都有较高需求。通常情况下大数据采集效率高达MB/s和GB/s,大数据存储量高达TB或PB量级。以往关系类数据库因为一致性约束不能提供大数据要求的高强度采集和存储需求[5]。Hadoop是由Apache基金会设计的分布式系统基础结构,相关技术人员能够在不清楚分布式底层细节前提下,设计分布式程序,通过集群的高性能优势快速运算和存储大数据。Hadoop可存储TB或PB量级的大数据,在集群环境里检测并快速处理硬件故障。除了Hadoop生态系统,还有Flink和Spark。其中,Flink通过使用内存处理技术,改善了Hadoop的性能。Spark提供了用户数据转换的多样性。但这些生态系统在大数据系统中的具体应用还处于初始阶段。没有Hadoop生态系统的应用率高。
基于Hadoop的分布式集群大数据动态存储系统整体结构用图1描述,由中央控制集群、大数据采集集群、大数据永久存储集群和高速以太网连接模块构成,中央控制集群获取用户需求通过高速以太网连接模块下达采集指令至大数据采集集群,大数据采集集群受中央控制集群的调度,快速采集动态数据并定期把缓存数据导入永久存储集群存储。
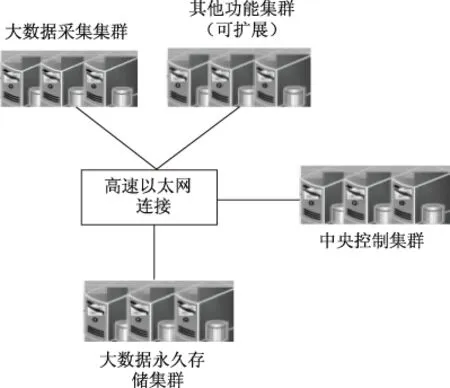
图1 系统整体结构图
1.1.1中央控制集群
中央控制集群是系统运行时的管理控制模块,通过中央控制集群获取用户需求后,通过高速以太网连接模块下达采集指令至大数据采集集群。中央控制集群的主要作用是提高单位时间内执行的任务数,可以控制多个分布式系统的时钟和操作,将不同指令准确下达到各分系统中,是整个系统的大脑。具体来说,中央控制集群实时监控数据状态解决异常状况,开启、关闭和更新制定集群任务,该模块主要用于控制整个系统稳定、快速、安全运行[6]。中央控制集群中主要包含主控单元与信令/调度单元,主控单元可指示信令信道。中央控制集群中主控单元电路结构用图2描述。

图2 中央控制集群主控单元电路结构图
1.1.2大数据采集集群
大数据采集集群是系统的内部入口,在多台机器上设定多个并发数据采集子模块,提升系统数据采集速度[7];且在各个机器中触发缓存功能,受中央控制集群的调度,快速采集动态数据后,定期把缓存数据导入永久存储集群中存储。大数据采集集群由用户层、管理节点以及数据接收器组成[8]。大数据采集集群整体结构用图3描述:
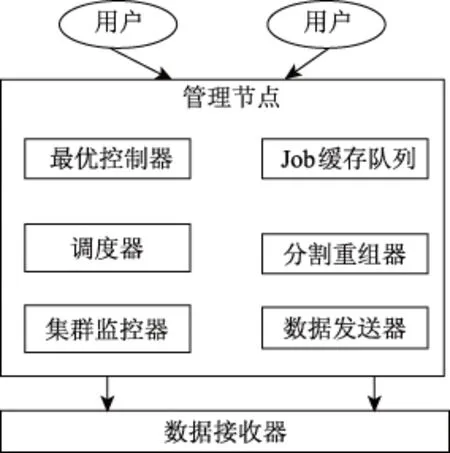
图3 大数据采集集群结构图
1.1.3大数据永久存储集群
大数据永久存储集群是系统的数据“仓库”,根据数据采集集群定期转入的数据实现数据定期存储更新,如图4所示,大数据永久存储集群的整体结构是分布式结构,其中包含元数据服务器、存储节点与各类大数据应用等构成的客户端。大数据永久存储集群通过分布式结构将大数据分成小数据,平均分布在多个数据存储节点中,将数据规模减少至单个节点能够处理的程度[9]。
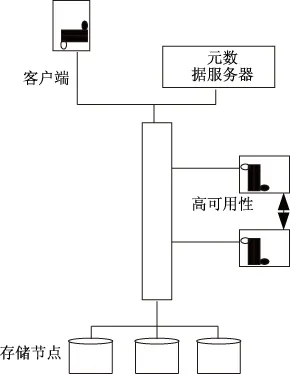
图4 大数据永久存储集群结构图
1.2 系统软件设计
基于Hadoop的分布式集群大数据动态存储系统,将多台存储服务器整合为一个集群系统后,均衡存储服务器负载情况,能够稳定安全完成用户存储指令,降低系统运行时间,避免系统出现崩盘死机情况[10-11]。
系统使用改进动态负载均衡算法均衡系统存储器负载情况。每次调度中,负载均衡调度器必须掌握集群里各存储服务器性能与负载状态[12],获取综合指标参数。依据性能指标和负载指标的比值,运算存储服务器综合指标值,该比值即为负载均衡器的调度凭据[13]。
1.2.1综合性能指标
设大数据永久存储集群里共有m台存储服务器,m台服务器以集合形式描述为R={R1,R2,…,Rm}。计算存储服务器的综合性能指标流程是:
a.获取存储服务器输出的性能指标;
b.统计每台存储服务器里每个性能指标,获取每个性能指标里数据达最大值;
c.对比各服务器性能指标值和相应的最大值,获取性能指标的比例值。
通过上述三个步骤,便可获取性能指标的比例值。再使用加权公式获取综合性能参数,过程如下:
定义1:大数据永久存储集群中存储服务器的CPU处理速率比值CPa为:
(1)
式中,第a台存服务器CPU处理速率为Aa,大数据永久存储集群中存储服务器CPU处理最大速率用max(A1,A2,…,Am)描述。
定义2:大数据永久存储集群中存储服务器的内存比值NPa为:
(2)
式中,第a台存储服务器的内存容量用Na描述,大数据永久存储集群里服务器内存最大容量用max(N1,N2,…,Nm)描述。
定义3:大数据永久存储集群的磁盘读写速率比值SPa为:
(3)
式中,第a台存储服务器的磁盘读写速率用Sa描述,大数据永久存储集群里磁盘读写最大速率用max(S1,S2,…,Sm)描述。
定义4:大数据永久存储集群的网络带宽比值DPa
(4)
式中,第a台存储服务器的网络带宽用DPa描述,大数据永久存储集群里网络最大带宽用max(D1,D2,…,Dm)。
上述分析的几类比值值域为[0,1],各比例值的大小体现了存储服务器的性能好坏,结合这些指标评判存储服务器的综合性能,并分配权重值,通过计算获取某台服务器的综合性能指标,依次给上述4类比值设置加权系数VC、VN、VS、VD,各加权系数的值域是[0,1],值的大小与性能指标在集群中的关键度息息相关,则大数据永久存储集群中第a台存储服务器的综合性能参数ZP(Ba)是:
ZP(Ba)=VC*CPa+VN*NPa+
VS*SPa+VD*DPa
(5)
1.2.2综合负载指标
设在任一时刻,大数据永久存储集群里第a台存储服务器的实时用户连接数量是Ya,此服务器负载最大值用FYa描述,那么二者的比值就是k时刻此服务器负载参数EP(Ba):
(6)
1.2.3服务器综合指标参数
通过上述获取的综合性能指标与综合负载指标,得到第a台存储服务器综合指标参数G(Ba):
(7)
通过公式(7),负载均衡调度器获取大数据永久存储集群里各台服务器的综合指标参数,选取综合指标参数值最大的存储服务器保存动态数据。指标参数变大,综合性能指标也变大或者综合负载指标变小,那么此台服务器则是最佳存储服务器。
2 实验分析
实验采用本文系统、高速数据存储系统[14]和网络编码云存储系统[15]进行对比实验,其中,高速数据存储系统采用大量flash存储器,偏于硬件的优化处理。网络编码云存储系统每个源符号只参与它所在行的编码,其缺点是通信开销很大,更新响应慢。设定不同大数据包数量用于存储,测试三种系统的存储响应时间,结果用图5描述:

图5 三种系统存储响应时间对比结果
分析图5可知,随着数据包数量的增多,本文系统的存储响应时间最大值为40 ms,相比高速数据存储系统和网络编码云存储系统,节省时间是50 ms和60 ms,说明本文系统存储大数据响应时间短。
采用持续性测试方法,在指定时间里用户使用特定强度向三种系统发送大数据动态存储指令,统计三种系统存储大数据时服务器实时负载情况,结果用图6描述:
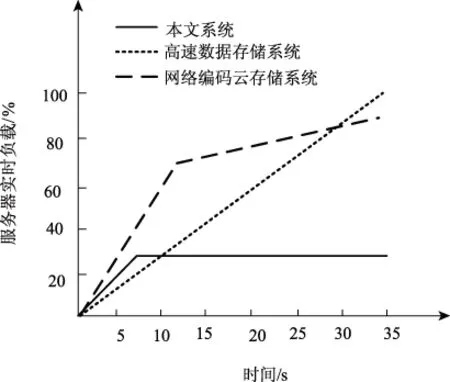
图6 三种系统服务器实时负载对比结果
分析图6可知,本文系统服务器实时负载最大值是30%,其它两种系统的实时负载最大值是100%和90%,本文系统服务器负载最小;本文系统服务器实时负载在7 s后逐渐趋于平稳,始终保持30%,而其它两种系统服务器实时负载随着时间的增加而大幅度提升,说明本文系统负载均衡性能优于另外两种系统。本文系统是基于Hadoop生态系统,组件包括Hadoop分布式文件系统(HDFS)和MapReduce引擎,其操作符都得到了增强,引擎更优化,因此负载处理更优秀。
在设定不同数据量的前提下,使用三种系统进行7次大数据动态存储实验,统计三种系统存储耗时数据,结果分别用表1、表2和表3描述。
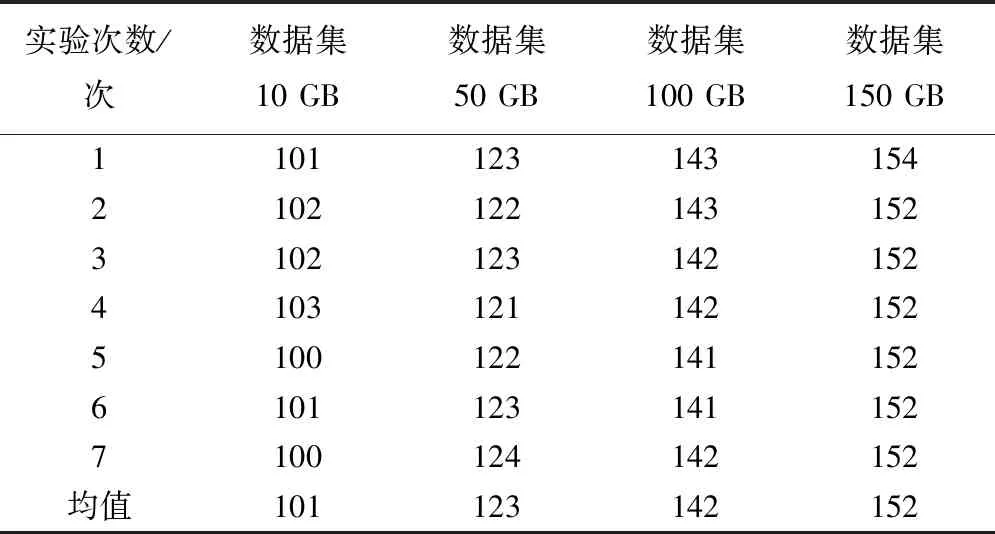
表1 本文系统存储耗时(ms)

表2 高速数据存储系统存储耗时(ms)

表3 网络编码云存储系统存储耗时(ms)
对比分析上述三个表可得,不同大数据存储量下,本文系统的耗时均值是(101 ms+123 ms+142 ms+152 ms)/4=130 ms,同理采用该运算方法获取高速数据存储系统的耗时均值是160 ms,网络编码云存储系统的的耗时均值是253 ms,经对比,本文系统进行大数据动态存储耗时最短,存储效率最快。这主要得益于Hadoop的分布式文件系统,HDFS的读取得到了更多的优化。网络编码云存储系统每个源符号只参与它所在行的编码,通信开销很大,耗时更长。高速数据存储系统随着数据量的增加,其偏重于硬件的缺点会被逐渐放大。
在设定不同大数据量的前提下,使用三种系统进行7次大数据动态存储实验,测试实验中三种系统的鲁棒性情况并进行对比,结果分别用表4、表5和表6描述:
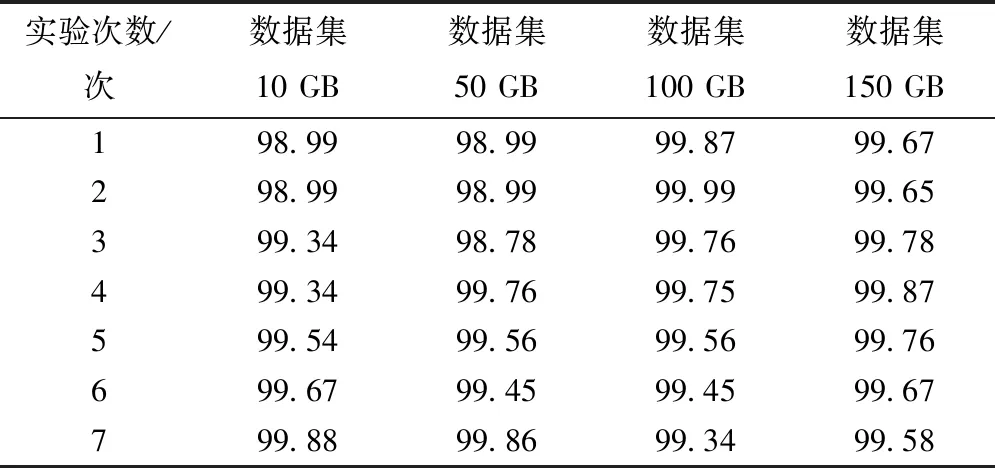
表4 本文系统鲁棒性测试结果(%)
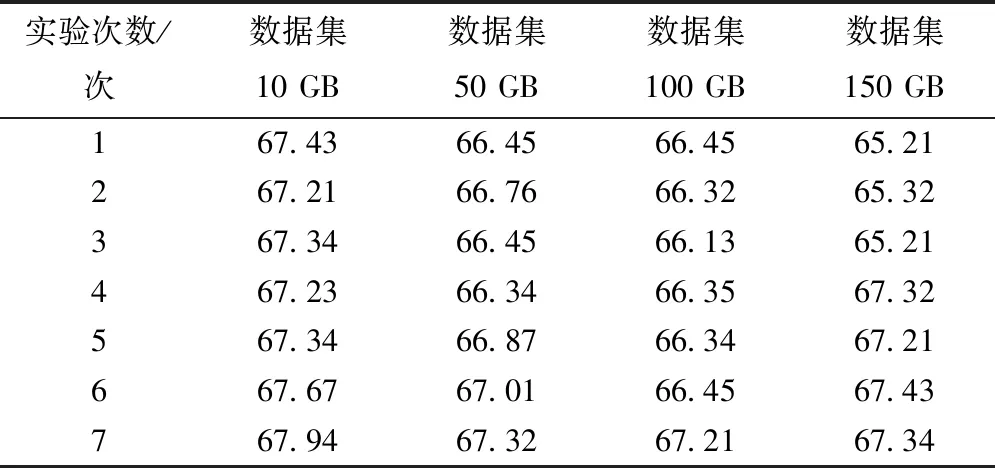
表5 高速数据存储系统鲁棒性测试结果(%)
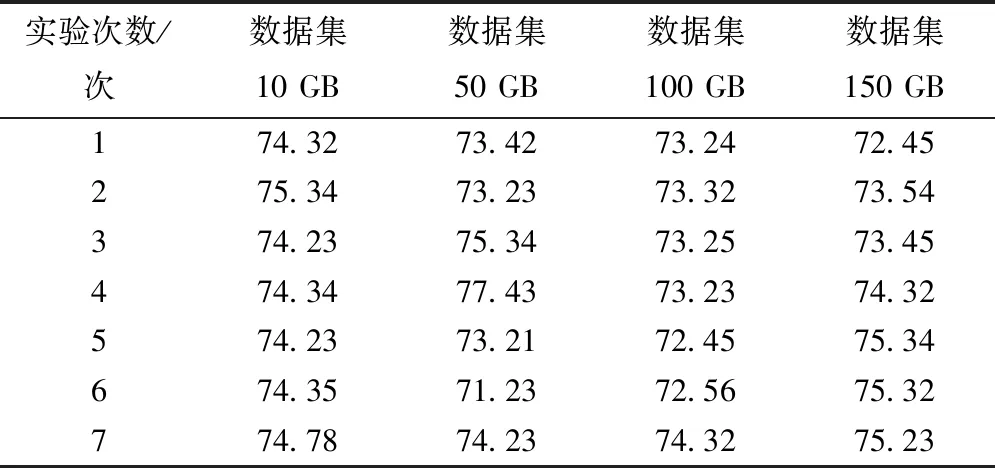
表6 网络编码云存储系统鲁棒性测试结果(%)
分析表4、表5和表6数据可知,存储数据量是10GB时,本文系统鲁棒性最大值是99.88%,比高速数据存储系统高出31.94%,比网络编码云存储系统高出25.10%;存储数据量是50GB时,本文系统鲁棒性最大值是99.86%,分别比其它两种系统高出32.54%和22.43%;存储数据集是100GB和150GB时,本文系统的鲁棒性最大值是99.99%和99.87%,同样也比其它两种系统的最大鲁棒性高,且随着存储数据量的不断增加,本文系统鲁棒性始终高于99%,具有较高存储稳定性,不会出现过载问题。
3 结 语
伴随信息化时代的到来,信息数据规模与复杂度的增长趋势对已有数据存储系统而言是个巨大挑战。高性能数据存储系统同大数据快速处理间具有较高关联性,为了提高大数据动态存储性能,本文设计基于Hadoop的分布式集群大数据动态存储系统,系统硬件由中央控制集群、大数据采集集群、大数据永久存储集群和高速以太网连接模块构成,中央控制集群获取用户存储需求通过高速以太网连接模块下达采集指令至大数据采集集群,大数据采集集群受中央控制集群的调度,快速采集动态数据并定期把缓存数据导入永久存储集群存储。系统软件采用改进动态负载均衡算法合理均衡存储服务器负载情况,减轻系统运行时间,避免系统出现崩盘死机情况。实验将本文系统、高速数据存储系统和网络编码云存储系统进行对比,得出了本文系统响应时间最大值仅有40 ms,实时负载最大仅占30%,且系统服务器实时负载在7 s后逐渐趋于平稳;随着大数据存储量的提升,本文系统对大数据动态存储耗时最短,稳定性最佳。
未来,本文将进一步研究配置参数对系统的性能影响(如网络缓冲等)。还将利用新的平台如Spark和Flink进行实验分析。
