基于sequence to sequence的神经机器翻译模型研究
2019-12-20侯悦文
侯悦文


摘要:深度学习是机器学习的技术和研究领域之一,通过创设具有阶层结构的人工神经网络,在计算机系统中实现人工智能,近几年越来越为人们所关注。机器翻译也可以使用神经网络中的循环神经网络中sequence to sequence架构[3]进行实验。本文使用基于循环神经网络的编码器-解码器模型将一个语言的句子编码成固定长度向量,并使用一个语言模型来解码为另一个语言的句子。我基于这个模型构建了一个英法的机器翻译模型,经过评估能实现机器翻译的效果。
Abstract: Deep learning is one of the techniques and research fields of machine learning. Artificial intelligence has been realized in computer systems by creating artificial neural networks with hierarchical structure, which has attracted more and more attention in recent years. Machine translation can also use the sequence to sequence architecture[3] in the recurrent neural network in neural networks for test. In this paper, a cyclic neural network based encoder-decoder model is used to encode a language sentence into a fixed length vector and a language model is used to decode a sentence into another language. Based on this model, the author built an English-French machine translation model that was evaluated to achieve machine translation.
关键词:机器翻译;sequence to sequence;深度学习
Key words: machine translation;sequence to sequence;deep learning
中图分类号:TP18 文献标识码:A 文章編号:1006-4311(2019)33-0294-03
1 定义
1.1 深度学习
深度学习是一种特殊的机器学习,性能十分高而且非常灵活,能够表示高阶抽象概念的复杂函数,解决目标识别、语音感知和语言理解等人工智能相关的任务。相较于传统的机器学习,深度学习可以实现无监督学习[1]。而且相较于传统的机器学习在面对大量数据时性能有限的问题,深度学习可以通过输入数据量的增加或是训练一个规模更加大的神经网络来使性能随之不断提高,因此在数据量巨大的数字化时代,深度学习也得以快速兴起。深度学习的典型模型有:深度信念网络、深度玻尔兹曼机、自动编码器、卷积神经网络、循环神经网络等。[4]
1.2 机器翻译
机器翻译是指利用计算机将一种自然源语言转变为另一种自然目标语言的过程。法国科学家G.B.阿尔楚尼最早提出了机器翻译的设想。机器翻译发展至今,从一开始的基于规则到后来的基于语料库,即基于统计学和概率学[4]翻译效率和准确率均有了明显的提升。
2 模型
2.1 循环神经网络(RNN)
循环神经网络是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络。图1为一个单向循环神经网络。
要开始整个流程,首先要在零时刻构造一个激活值a<0>,a<0>通常为零向量。激活值a<0>通过前向传播输出
a<1>。同时将第一个单词x<1>输入在第一层神经网络中计算后将结果y<1>输出。在每次当它读到句中的第二个单词时,假设是x<2>,循环神经网络不是仅用x<2>就预测出y<2>,它也会输入一些来自时间步 1 的信息。具体而言,时间步 1 的激活值就会传递到时间步 2。然后,在下一个时间步,循环神经网络输入了单词x<3>,然后它尝试预测输出了预测结果y<3>等等,一直到最后一个时间步,输入了x
这些等式定义了循环神经网络的前向传播,通过构造a<0>,并输入x<1.2.3...t>来完成循环神经网络从左到右的前向传播。
2.2 Sequence to sequence模型架构
最简单的sequence to sequence模型由encoder和decoder组成。
2.2.1 Encoder
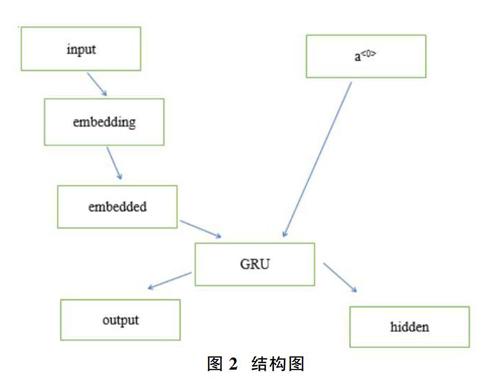
Encoder实际上是一个RNN,接受输入句子的每一个单词作为输入并产生一个向量作为输出。对于每个输入的单词,encoder都会输出一个向量和一个隐藏态(实际上隐藏态也是一个向量),并用于下一个时间步的计算。如图2所示。
其中GRU为门控制单元,GRU有两个门,分别为更新门和遗忘门。其作用是通过门来决定当从左到右扫描一个句子的时候,这个时机是要更新某个记忆细胞,还是不更新。GRU单元输入c
2.2.2 Decoder
Decoder实际上是另一个RNN,用于接收向量并输出单词的序列。对于最简单形式的Seq2Seq的decoder仅仅使用encoder的最后一个时间步的隐藏态作为输入。最后一個时间步的输出向量有时候被称为上下文向量,因为它代表整个输入序列的上下文。上下文向量被用于decoder的第一个时间步的输入。
解码的每一个时间步,decoder接收一个输入的token和隐藏态,初始的输入token是特殊单词start-of-sentence--
3 实验
本次实验基于sequence to sequence架构构建了法语-英语的平行句对的翻译模型并对之进行了训练和评估。本次实验使用的编程语言为Python。Python通过附加的工具可以转换成可以适合科学和工程代码的高级语言,速度通常足够快且灵活。[2]实现模型使用的深度学习框架是PyTorch。PyTorch是作为一个Python包提供如下两个优点:①具有强GPU加速度的张量计算(如numpy);②定义的网络结构简单。
3.1 数据预处理
用于训练机器翻译模型的数据是许多英语-法语的平行句对。训练数据保存在文件中,其中每一行是一个英语-法语的平行句对。英语与法语句子之间使用tab键分割,例如:I am cold. J'ai froid.
本次实验对语料进行了如下的数据预处理工作:首先我将语言中的单词使用one-hot编码进行表示,即除了单词索引位为1其他位全为0的向量表示并在开头添加
3.2 训练
3.2.1 训练数据的准备
为了进行训练,我会将句对转化为输入tensor(源语言句子单词的索引列表)和输入tensor(目标语言句子单词的索引列表),句子的末尾还会加上特殊的token标记句子的结尾
3.2.2 训练模型
训练时,我将源语言句子作为序列输入给encoder,并维护encoder每个时间步的隐藏态。之后,decoder使用
在训练时,decoder的输入token实际上是正确的目标语言单词,而不是像训练完成后进行翻译是使用的是上一个时间步decoder输出的单词。其中本次实验调用的损失函数为nn.L1Loss。nn.L1Loss函数的计算方法为取预测值和真实值的绝对误差的平均值在本次实验中预测值和平均值分别为模型预测的单词和正确的单词,函数的公式如下。(学习率为0.5)。同时我使用了一个辅助函数来显示进度。整个训练的过程可以简单的分为如下几步:①启动计时器;②初始化优化器和训练目标;③生成训练数据(句对);④保持loss到列表并绘图。在最后绘制结果时我使用了matplotlib库来绘图,使用之前保持的损失列表,绘图函数为plot_losses。
3.2.3 评估
评估的过程和训练非常像,但是由于模型不知道正确的翻译结果是什么,所以解码的每个时间步使用上一个时间步输出的token作为该时间步的输入token。每个时间步都会预测一个单词输出,将这个单词加入到最终要输出的源语言句子,当预测到特殊token--
4 实验过程及结果
本文模型使用的隐藏态hidden_size为256,在正式实验中一共训练了75000次,花费了48m22s,loss=0.5797。
本文随机输入句子对模型进行评估,结果如图3。
可以看出该模型在翻译时仍有较多的错误,其错误类型主要为译文选词错误,译文和原文意思相反以及词序不对。原因可能在于在翻译较短句子时由于模型难以得到所有的词,而翻译较长的句子时由于句子太复杂导致模型在翻译短句和长句时都会出现错误。
5 总结与展望
本文首先介绍了机器翻译常用的工具和模型,并使用基于循环神经网络的编码器-解码器模型实现了法语-英语的翻译。证明了神经网络对于自然语言的强大学习能力。其优点在于成本低、效率高。但是翻译的结果中还有一些问题,之后为了解决这些问题我会尝试引入注意力机制(attention model)。
参考文献:
[1]刘建伟,刘媛,罗雄麟.深度学习研究进展[J].计算机应用研究,2014,31(7):1921-1930.
[2]Oliphant, Travis E . Python for Scientific Computing[J]. Computing in Science & Engineering, 2007, 9(3):10-20.
[3]Sutskever I , Vinyals O , Le Q V . Sequence to Sequence Learning with Neural Networks[J]. 2014.
[4]周志华.机器学习[M].北京:清华大学出版社,2016.
[5]潘登.CNKI翻译助手和Wordnet分析中国政治词汇的英译[J].价值工程,2013,32(04):322-324.
