Digital Vision Based Concrete Compressive Strength Evaluating Model Using Deep Convolutional Neural Network
2019-12-19HyunKyuShinYongHanAhnSangHyoLeeandHaYoungKim
Hyun Kyu Shin,Yong Han Ahn,Sang Hyo Lee and Ha Young Kim
Abstract: Compressive strength of concrete is a significant factor to assess building structure health and safety.Therefore,various methods have been developed to evaluate the compressive strength of concrete structures.However,previous methods have several challenges in costly,time-consuming,and unsafety.To address these drawbacks,this paper proposed a digital vision based concrete compressive strength evaluating model using deep convolutional neural network (DCNN).The proposed model presented an alternative approach to evaluating the concrete strength and contributed to improving efficiency and accuracy.The model was developed with 4,000 digital images and 61,996 images extracted from video recordings collected from concrete samples.The experimental results indicated a root mean square error (RMSE) value of 3.56 (MPa),demonstrating a strong feasibility that the proposed model can be utilized to predict the concrete strength with digital images of their surfaces and advantages to overcome the previous limitations.This experiment contributed to provide the basis that could be extended to future research with image analysis technique and artificial neural network in the diagnosis of concrete building structures.
Keywords: Concrete compressive strength,deep learning,deep convolutional neural network,image-based evaluation,building maintenance and management.
1 Introduction
For the assessment of durability and performance of concrete based building,it is essential to acquire the various ingredients influence the performance of concrete.Compressive strength of concrete is a representative parameter to evaluate the performance of concrete structures [Beushausen and Luco (2016)].To obtain the compressive strength,various test methods are developed,such as destructive test and non-destructive test [Kaouther (2014)].In the past,the performance of concrete was generally assessed using destructive tests such as core drilling,to recognize their compressive strength [Bickley (1982);Denys (2010)].However,destructive tests not only destroy critical structural components but also lead to safety problems damaging during the drilling the sample from the structures [Denys (2010);Shih,Wang,Lin et al.(2015);Vona and Nigro (2015)]).In order to address these problems,non-destructive test (NDT) methods that minimize the damage caused to the structure have developed.Denys et al.[Denys (2010);Khoudja,Sbartaï,Breysse et al.(2017)].At present,the Schmidt Hammer test,the Ultrasonic Pulse Velocity (UPV) test and Electrical Resistivity measurement are the representative NDT methods to determine the compressive strength of concrete structures [Ju,Park and Oh (2017);Kaouther (2014)].However,although these methods are simple and effective,NDT produces different results depending on the formula applied [Breysse (2012);Elaty (2014)] and also suffers from low reliability [Yaseen,Deo,Hilal et al.(2018)].
Since it is important to measure the compressive strength accurately for assessment of building performance,many studies have sought to develop better compressive strength measurement methods [Bickley (1982);Chen,Fu,Yao et al.(2017b);Denys (2010);Elaty (2014);Ju,Park and Oh (2017);Kaouther (2014);Omar,Boukhatem,Ghrici et al.(2017);Park and Jung (2010);Shih,Wang,Lin et al.(2015);Yaseen,Deo,Hilal et al.(2018)]).Several researchers have developed advanced methods to evaluate the compressive strength of concrete using algorithms based on fuzzy logic,data mining,and machine learning techniques to boost the accuracy of concrete performance predictions [Chen,Fu,Yao et al.(2017b);Omar,Boukhatem,Ghrici et al.(2017);Yaseen,Deo,Hilal et al.(2018);Elaty (2014)]).The proposed methods present quite good results to evaluate the concrete strength producing reliable predictive values when the mixing ratio information is known.Although these methods improved the accuracy and effectiveness in evaluating concrete compressive strength,they still required specific information related to test specimen such as the mix ratio.Because it could be challenging to determine the composition ratio information for existing concrete structures,apparent limitations are restricting their utility.
Hence,a new method to overcoming the traditional approach is required to easily and simply evaluate the performance of concrete.To address these limitations,the effective methodologies based on image analysis in evaluating the strength of concrete have been proposed [Lange,Jennings and Shah (1994);Başyiğit,Çomak,Kilinçarslan et al.(2012);Dogan,Arslan and Ceylan (2017)].These studies were implemented with the assumption that the surface image of concrete provides a good correlation with concrete strength in accordance with a good correlation between the strength and characteristics of concrete (e.g.,pore properties,cement paste,aggregate,water/cement ratio).Researchers have reported a correlation between a digital image of the concrete and its compressive strength,indicating this is indeed a valid way to examine many of the parameters known to affect the strength of concrete such as pore properties,water/cement ratio and cement paste [Wong,Pappas and Zimmerman (2011);Hu and Li (2014);Akand Yang and Gao (2016);Shi,Wu,Lv et al.(2015);Dogan,Arslan and Ceylan (2017);Siregar,Rafiq and Mulheron (2017)].In this regard,many studies have conducted to improve the accuracy and effectiveness of concrete strength evaluating models using digital vison data.However,image-based analytic methods require to extract the appropriate thresholds for feature segmentations [Wong,Head and Buenfeld (2006)].Since the heterogeneous mixtures such as concrete are composed of a complex element,it is difficult to feature extract by hand-craft for analyzing digital vision data [Lin,Nie and Ma (2017)].To address these limitations of image analysis methods,a deep learning-based method was proposed for extracting features autonomously using deep convolutional neural networks (DCNN) [Russakovsky,Deng,Su et al.(2015)].The DCNN-based neural network has advantages its automatic computation as a feature extractor [Wang,Ma,Zhang et al.(2018);Cha,Choi and Büköztürk (2017)].Moreover,this approach is both fast and efficient,it could be contributed to reducing the cost and time required to solve problems using traditional analysis methods considerably.
Therefore,in this study,we proposed a digital vision based concrete compressive strength evaluation model using DCNN technologies.Since the characteristics of concrete with various surfaces depend heavily on the state of the surface particles,this method can evaluate the compressive strength of concrete structural based on a detailed examination of their surface features [Hilsdorf and Kropp (2004)].To verify the accuracy of the proposed method,we tested three different DCNN algorithms that are widely used for image classification because of their high accuracy.The algorithms were modified appropriately and then applied to improve the performance of the concrete compressive strength evaluation model.The experimental results obtained confirm the feasibility of using this new approach for assessing the compressive strength in concrete structures.
2 Methodology
Deep learning based convolutional neural network (CNN) methods are becoming very popular for computer vision field analyses [Cha,Choi and Büköztürk (2017);Krizhevsky,Sutskever and Hinton (2012);Schmidhuber (2015);Szegedy,Liu,Jia et al.(2015);Xu,Luo,Wang et al.(2016)] as they represent a close-to-human level of image recognition [Krizhevsky,Sutskever and Hinton (2012);Szegedy,Liu,Jia et al.(2015)].Such methods can solve highly complex problems through learning,and for applications where sufficient data is available,their analytical performance continues to increase.In the past,traditional methods have also proven to be useful when hand-crafted features must be defined.However,since some domain knowledge involves high-dimensional data such as images,speech,or text-hand-crafting features,the performance of older learning algorithms is severely limited.When the domain knowledge of the image data is undefined,an analysis based on CNNs will be more accurate because a CNN learns features from raw image pixels without the need for any further information about the application images.This state-of-the-art method trains itself autonomously to identify features in hidden layers of the deep neural networks,and because deep convolutional neural networks (DCNNs) represent a data-driven approach,algorithms can learn the relevant features by analyzing the data on their own.
In this study,deep learning techniques were applied to examine surface images of concrete specimens in order to predict the compressive strength of the concrete.Deep learning can understand and imitate complex and abstract concepts and to identify the characteristics of the input data and classify the data accordingly [Wang,Ma,Zhang et al.(2018)].This feature allows the algorithm to extract features from the algorithm itself and classify data as being similar to those characteristics,even if the characteristics of the object are not previously known [Wan,Wang,Hoi et al.(2014)].This methodology makes it a suitable approach for analyzing data with complex,high-dimensional data with few known features,even though it differs from existing methods for determining the properties of an object.It has become possible by applying deep learning to existing artificial intelligence algorithms.The concept of deep learning was introduced in 1998 by LeCun et al.,who developed the first deep neural network [LeCun,Bottou,Bengio et al.(1998)].It generally consists of three layers:a Convolution Layer,a Pooling Layer,and a Fully-Connected Layer [Ki and Cho (2017)] (Fig.1).Once the image is recognized,the convolution layer and the pooling layer are repeated multiple times until the features of the hierarchical structure have been extracted.These can then be input and classified into the target group [Krizhevsky,Sutskever and Hinton (2017)].

Figure 1:Architecture of the Alexnet [Krizhevsky,Sutskever and Hinton (2012)]
Most image recognition algorithms use filters to extract features [Chen,Su,Cao et al.(2017a);Soltani,Zhu and Hammad (2016)].The layer that serves as a filter in CNN is called the Convolution layer,and a feature-map is formed through learning in this layer.Pooling is used to reduce the size of the feature-map image obtained through the Convolution layer.At this point,features that represent the image are extracted.Finally,these global features are integrated into a fully connected network,capable of providing optimal recognition results through learning.For this study,appropriate data are collected to enable the algorithm to extract relevant features from images of the concrete surface that are then used to predict the material's compressive strength.The three algorithms,Concnet_A,Concnet_G,and Concnet_R,used to evaluate the concrete's compressive strength,are modified from Alexnet [Krizhevsky,Sutskever and Hinton (2012)],Googlenet [Szegedy,Liu,Jia et al.(2015)],and Resent [He,Zhang,Ren et al.(2016)],respectively.the characteristics of each algorithm (Tab.1) are as follows.
Concnet_A is a modified version of the neural network architecture proposed by Krizhevsky et al.(Fig.1) [Krizhevsky,Sutskever and Hinton (2012)].Its learning rate is improved by using the ReLU model instead of the Tanh and Sigmoid functions used in conventional neural networks,and the error rate is reduced by overlapping the pooling layers [Krizhevsky,Sutskever and Hinton (2012)].
Concnet_G is a modified version of the neural network introduced by Szegedy et al.[Szegedy,Liu,Jia et al.(2015)] which solves the problem of side effects such as overfitting and the increase in computation that can be caused by using 22 layers by applying the nine inception module concept (Fig.2).Concnet_G extracts various features locally by using Convolution in parallel with various kernel sizes,and the number of feature maps is reduced by using a 1×1 Convolution.Hence the amount of computation required is controlled.Besides,the auxiliary classifier is used to prevent the loss of gradients that can occur while learning [Szegedy,Liu,Jia et al.(2015)].

Table 1:Characteristics of DCNN algorithms
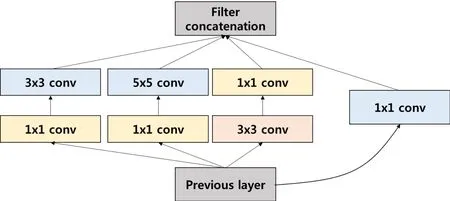
Figure 2:Inception module with dimension reductions [Szegedy,Liu,Jia et al.(2015)]
Concnet_R is a modified model of the Residual net (Resnet) initially proposed by Szegedy et al.[Szegedy,Liu,Jia et al.(2015)].It consists of a network with many layers,created by repeatedly stacking several residual blocks (Fig.3).The original Resnet architecture consisted of 152 layers,but in the Concnet_R model,this is reduced to 50 layers because the concrete image size for training is smaller at just 84×84 compared to the 224×224 image size in the original.Although the number of layers is higher than in either Alexnet or Googlenet,the difficulties frequently encountered in deep neural networks such as vanishing,exploding,the gradient problem and the increasing number of parameters,are solved through the skip connection.The Resnet architecture,therefore,presents higher accuracy by learning more complicated problems and can learn the depth of layers to predict the compressive strength of concrete by extracting the features [He,Zhang,Ren et al.(2016)].Therefore,this study explored three modified algorithms to analyze the characteristics of heterogeneous materials distributed on the concrete surface.The experimental results were identified and the accuracy of each algorithm was compared in chapter 4.
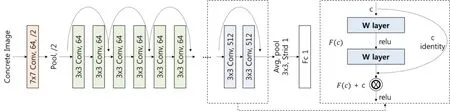
Figure 3:The residual network with 34 parameter layers [He,Zhang,Ren et al.(2016)]
3 Experimental procedure
In order to develop a DCNN algorithm for predicting concrete compressive strength,it is necessary to define the input,output and input/output parameters of the algorithm and design the detailed structure of the DCNN,including the layer type.It involves determining the optimum number of layers,defining the convolutional layer and the fully connected layer,and selecting the filter type,which involves determining the optimum number of filters and the filter size.The performance of the algorithm depends on precisely how the input and output of the DCNN are defined [Schmidhuber (2015)].When image data is used,the input data is typically defined by the input size,preprocessing,and augmentation of the image.The output type can be expressed in terms of the target value as it stands or can be transformed into various normalization or category forms.It means that a DCNN's input and output must be carefully defined in order to generate an accurate prediction algorithm.For this study,an image of a concrete surface was set as the input data,and the concrete compression strength was set as the output data.Since no existing data is linking compressive strength with images,data sets suitable for DCNN algorithm learning had to be collected.In order to develop a set of suitable concrete surface images covering a wide range of compressive strength data sets,concrete specimens were prepared to utilize various mix proportions.
3.1 Input data collection
Twenty-five concrete specimens (Φ100×200 mm) were prepared at three water/cement mixing ratios to collect a suitable set of concrete images showing various compressive strength performances.Samples with a water content of 68% (9 samples),50% (8 samples),or 33% (8 samples) were created and cured for periods ranging from 3 days to 4 weeks in order to obtain a broad range of compressive strengths based on the mix proportions indicated in Tab.2.The dataset for experiments was collected on concrete samples with a specific combination in the laboratory environments.The experimental conditions are shown in Fig.4.First,we prepared the concrete specimens to implement the performance test and repeatedly and randomly recorded several 25 mm×15 mm images of the surface of each to build an appropriate image dataset that could then be linked to their known compressive strength (subsequently measured as described below).Images of the surface of each specimen were captured from a distance of 15 mm with a digital camera;the original image pixel size of 4,096×2,160 was reduced to 224×224 to prevent overfitting of the algorithm.Each sample was photographed 300 times,with the camera moved between shots to ensure the image captured showed a different section of the surface each time.

Table 2:The mix proportion of experimental concrete specimens
If the size of the image is large,the amount of information it contains is also significant,which can lead to problems with high dimensionality and overlapping pixels interfering with the algorithm's learning process.However,if the size of the image is too small,the amount of information is significantly reduced,potentially to the point at which it becomes effectively worthless.Therefore,to achieve an excellent DCNN algorithm performance and learning capability,it is crucial to identify the optimal input image size.For this study,setting the image data size to 84×84 was found to be adequate for algorithm learning.As the accuracy of a deep learning algorithm increases as the amount of data available for learning increases,the data was amplified using random cropping and horizontal flipping as shown Fig.5.

Figure 4:Schematization about experimental conditions for building image dataset

Figure 5:Data augmentation using random cropping and horizontal flipping
Tab.3 shows the number of image datasets used as the input in this study.Data augmentation was performed on 65,996 datasets obtained from video images of the surface to secure sufficient data.The training,validation,and test data were utilized at a ratio of 7:2:1.The dataset was trained using 70% of the training data,and this was doubled by flipping.The resulting 112×112 images were then randomly cropped multiple times to create images that were 84×84 in size,and the data was amplified 28×28 times.As a result,the data used as input for the training algorithms consisted of about 72 million images.
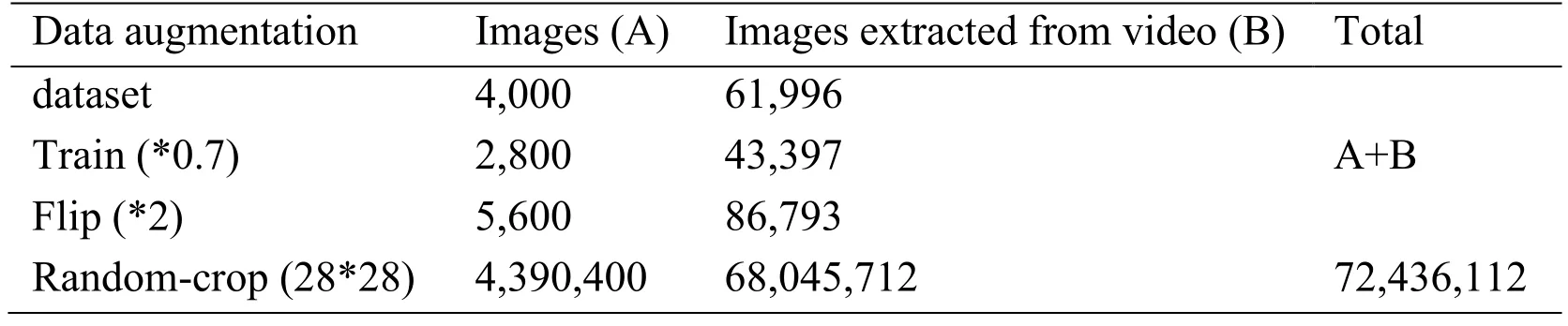
Table 3:The number of parameters of the derived algorithms
3.2 Output data collection
The specifications selected for the output information from the deep learning algorithm determine what can be obtained from the input information and algorithm analysis.Here,the output information was the compressive strength of the concrete,but since the compressive strength and the image data have not yet been linked in an existing database,the compressive strength of the specimens had to be measured experimentally and then compared with the images of the specimen surface taken immediately beforehand.The samples created for this experiment were therefore tested after the image capture process was completed using the procedure specified in KS F 2405 and found to have compressive strength values between 8.89 MPa and 41.48 MPa.
The performance of the new algorithm was measured in terms of the difference between the actual and predicted concrete performance values.Based on a range of compressive strengths corresponding to the measured values,namely 8.89 to 41.48 MPa,the Euclidean Loss Equation shown below in Eq.(1) was used as a loss function for the DCNN learning to predict this output value.Here,N is the total number of points in the dataset,oi is the output value of DCNN,and yiis the compressive strength measured.As the algorithm utilizes this loss function and applies a reversed wave algorithm,the weights of the DCNN are learned in such a direction that this error function becomes a minimum.

As the range of compressive strength test results obtained from the test was quite wide,a performance improvement test was performed via normalization,with the value changing from 0 to 1 through a min-max normalization of the type shown in Eq.(2).

4 Experiments and results
Data for the 4006 images collected by the digital camera,along with the training,verification,and test data,were classified,as shown in Fig.6.The image data collected for each sample was distributed as follows:70% training data,10% validation data,and 20% test data.A total of 2,804 images extracted from the 4,006 images collected were used for training.The images for all the compressive strengths were used equally for the three (training,validation,and test) algorithms.The algorithm learns by using the concrete specimen images distributed across the test set,and we monitored the performance of the algorithm by using the validation set and adjusting the amount of learning.Finally,the test set was used to examine the error rate of the algorithm.
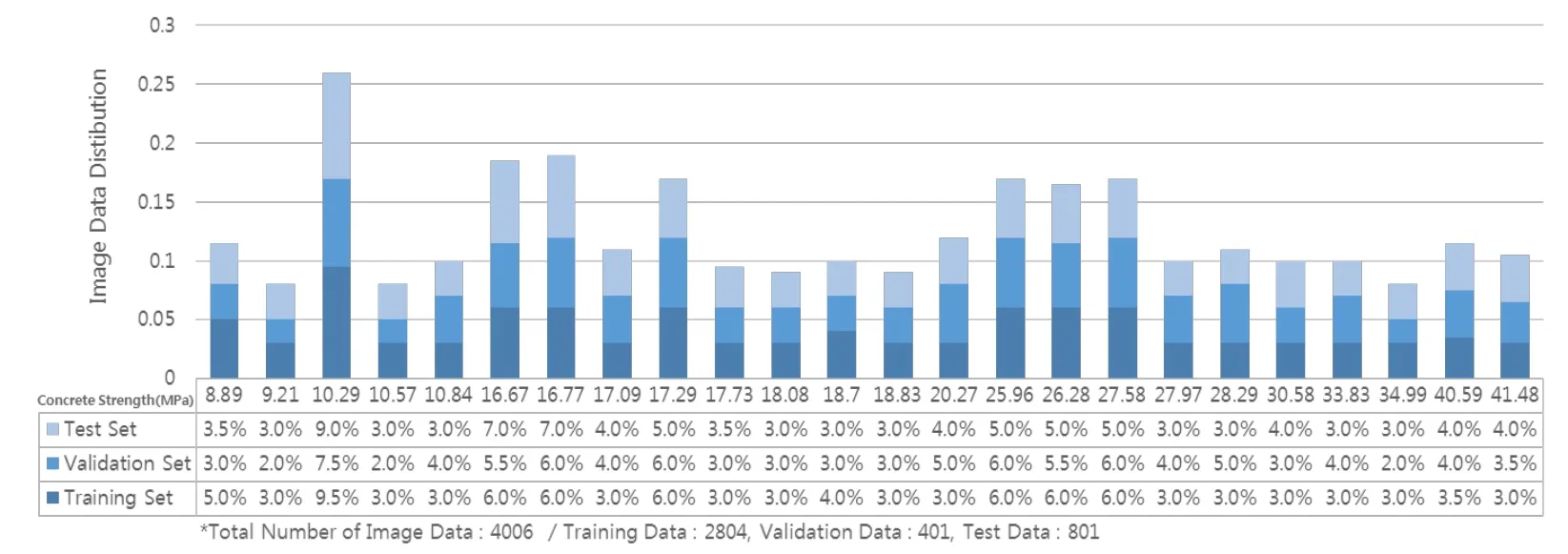
Figure 6:Concrete specimen surface image data distribution

Figure 7:Validation loss of proposed algorithms

Figure 8:Root mean square error according to the algorithm
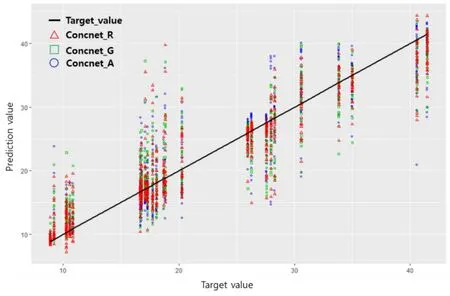
Figure 9:Prediction tendency achieved by the three algorithms
As the validation curve in Fig.7 shows,overfitting was not a problem.As explained earlier,more than 72 million concrete surface images from specimens with a range of compressive strengths were collected for this study by implementing data augmentation with random cropping and horizontal flipping.The validation loss flow can be interpreted as evidence that sufficient data sets have been collected for the training process.
Fig.8 indicates the accuracy of the RMSE for each concrete compressive strength value.The lowest root means square error (RMSE) of 3.56 is for Concnet_R,which is 0.08 lower than Concnet_G (3.64) and 0.26 lower than Concnet_A (3.82),corresponding to a prediction performance that is 2.0% and 6.8% better.RMSE values are distributed in various ways and represent the difference in the amount of learning data available for the target value.The results of the RMSE for each target are shown in Tab.4.
Fig.9 shows the distribution of the predicted values according to each algorithm.This graph demonstrates that the results for Concnet_R were distributed most closely to the target values.The RMSE for Concnet_R (3.56) demonstrates its superior performance compared to either of the other two algorithms.
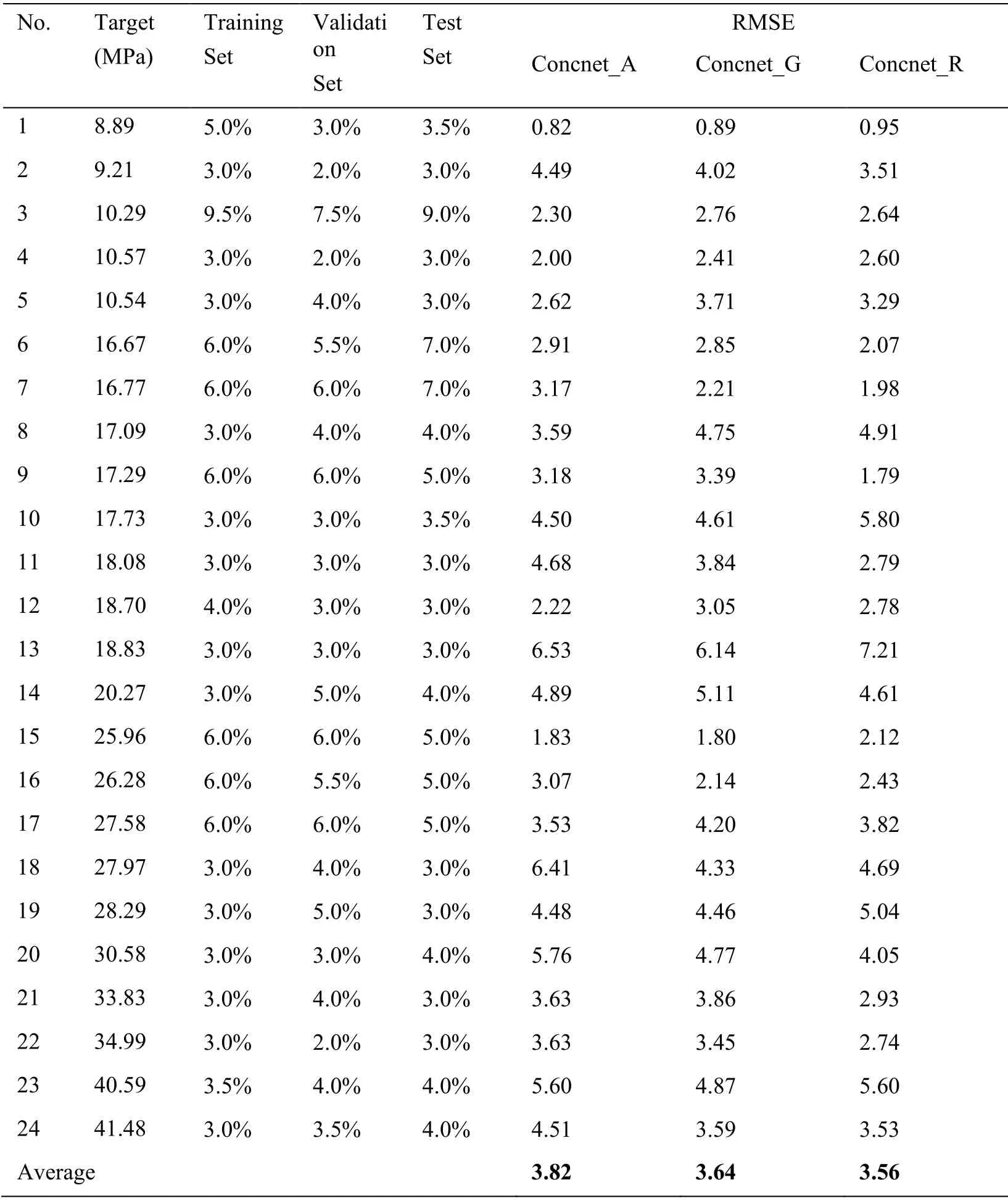
Table 4:Concrete surface digital camera image distribution and RMSE
The accuracy of the image-based DCNN method performed in this study was then compared with the accuracy achieved by conventional machine learning and NDT methods to determine the suitability of the new algorithm for estimating the compressive strength of concrete.
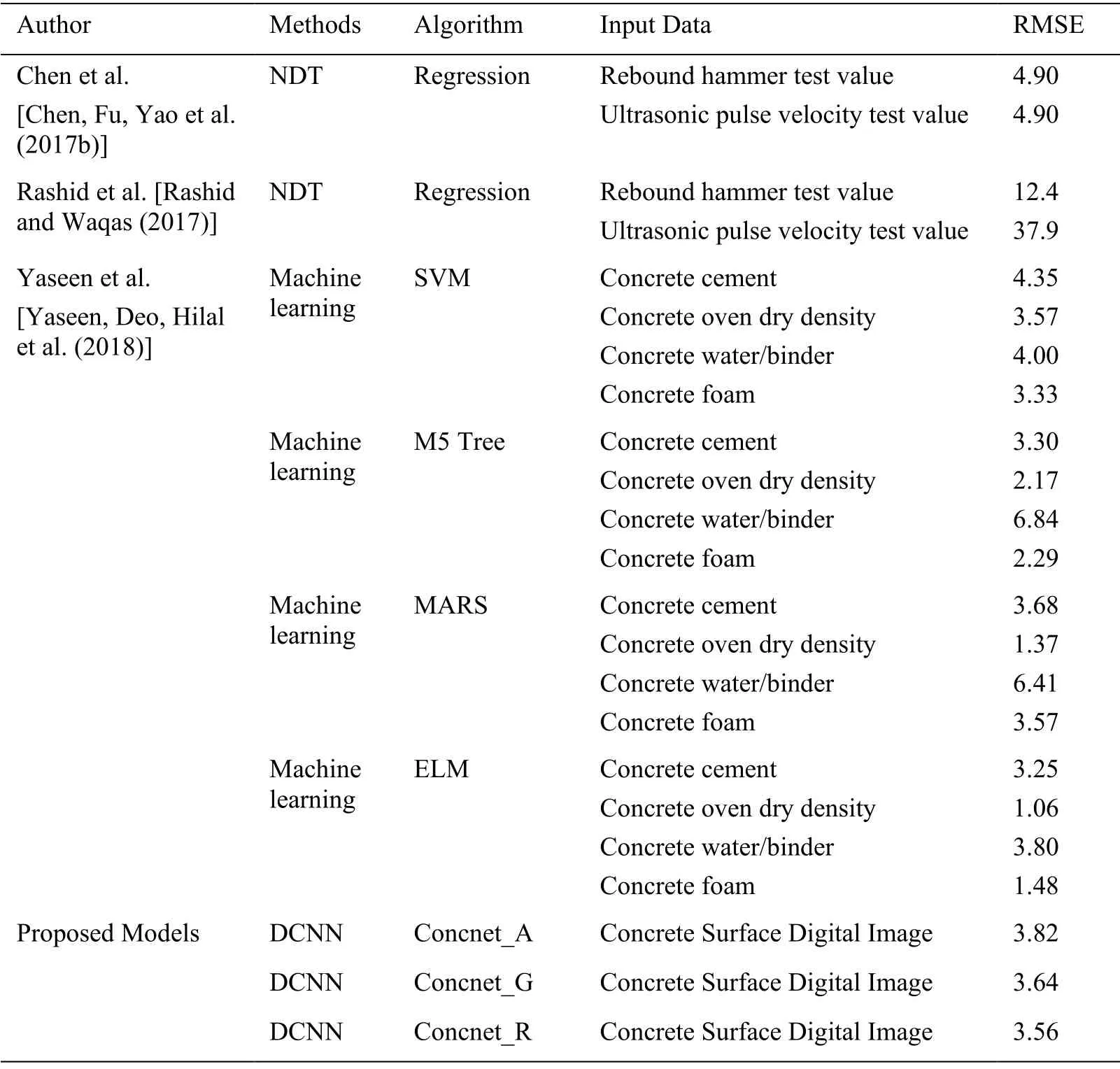
Table 5:Comparison with existing NDT prediction results
Tab.5 lists the existing RH and UPV test values collected by previous researchers.The accuracy of the compressive strength estimation formula analyzed by the regression has an RMSE of 4.9.In the SVM,M5 Tree,MARS,and ELM algorithms used by Yaseen [Yaseen,Deo,Hilal et al.(2018)],the distribution ranges from RMSE 1.06 to 6.84 using the information on the cement,oven dry density,water/binder,and foam.Our new approach based on Alexnet (Concnet_A),Googlenet (Concnet_G),and Resnet (Concnet_R) achieved RMSEs of 3.82,3.64,and 3.56,respectively.Of these,the prediction using Resnet achieved the highest accuracy.The mean error value of compressive strength was measured within 4 MPa using only surface image information for the concrete,which is a significant step forward.
5 Discussion and limitations
The DCNN algorithm developed in this study was designed to predict the compressive strength of concrete based on a digital vision data of the concrete's surface.The proposed model provides a new approach to support the efficient assessment of concrete building performance.In this study,an innovative image-based approach for measuring the compressive strength of concrete was developed.The results demonstrate that it is indeed possible to verify the performance of concrete facilities using digital camera equipment.The proposed method indicates that this has the potential to become an efficient and accurate way to evaluate compressive strength values using a digital image and deep neural network in samples with no structural defects.However,as the experiment was carried out using concrete specimens prepared in a laboratory environment,this study has only a limited range of data to draw on;concrete surface images exposed to real environments were not utilized.Under real-world conditions,where many parameters influence the surface properties of the concrete,as yet the best way to measure the compressive strength of concrete structures remains to test samples extracted from the structures to gain a real picture of a structure's concrete performance.Nevertheless,this study is a significant first step in verifying the potential effectiveness of an efficient new approach to evaluating concrete performance.
In future research,these limitations should be addressed by directly observing the current status of a wide range of concrete structures and predicting their compressive strength by analyzing their observed images.Deep learning algorithms represent a new and robust way to detect features from complex porous concrete surfaces.It is not unreasonable to assume that the DCNN technique can also learn to assess the compressive strength of concrete structures based on characteristics such as microcracks,pores,and transition shear features that appear on the surface of a concrete structure.
6 Conclusion
This paper proposed a digital vision-based evaluation approach for assessment building performance.By collecting over 4,000 single images and 61,996 video extracted images and measuring the associated concrete performance values,a DCNN model was proposed,and the optimum data file size determined.The performance of the proposed method was validated based on data collected in the laboratory,revealing an RMSE value of less than 3.56 for the Concnet_R algorithm.It signifies that the concrete compressive strength error value predicted by proposed model was within 3.56 MPa of the true value.The proposed model presented a great promise as a way to predict compressive strength through examining images of the surfaces of concrete structures.Moreover,the results demonstrate that the deep learning approach provides a valuable opportunity to contribute to improving the efficiency for assessment of concrete structures.As yet,however,this model was developed only to evaluate the compressive strength of concrete samples with specific proportions produced in the laboratory environment.More research is required to build a database that is capable of recognizing surface images of deteriorated concrete structures in various environments and then strengthening the algorithms to enable them to predict how concrete reacts to being exposed to different environments.Advanced models that can predict various performance indicators such as chloride diffusion coefficient,porosity,and compressive strength also need to be developed to achieve a comprehensive performance index for concrete structure and infrastructures.
Acknowledgement:This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (NRF-2018R1A2B6007333).
References
Akand,L.;Yang,M.;Gao,Z.(2016):Characterization of pervious concrete through image based micromechanical modeling.Construction and Building Materials,vol.114,pp.547-555.
Alshihri,M.M.;Azmy,A.M.;El-Bisy,M.S.(2009):Neural networks for predicting compressive strength of structural light weight concrete.Construction and Building Materials,vol.23,pp.2214-2219.
Başyiğit,C.;Çomak,B.;Kilinçarslan,S.;Üncü.I.S.(2012):Assessment of concrete compressive strength by image processing technique.Construction and Building Materials,vol.37,pp.526-532.
Beushausen,H.;Luco,L.F.(2016):Performance-Based Specifications and Control of Concrete Durability.Springer,Netherlands.
Bevilacqua,M.;Braglia,M.(2000):The analytic hierarchy process applied to maintenance strategy selection.Reliability Engineering & System Safety,vol.70,no.1,pp.71-83.
Bickley,H.A.(1982):The variability of pullout tests and In-Place concrete.Concrete International,vol.4,no.4,pp.44-51.
Breysse,D.(2012):Nondestructive evaluation of concrete strength:an historical review and a new perspective by combining NDT methods.Construction and Building Materials,vol.33,pp.139-163.
Cha,Y.J.;Choi,W.;Büyüköztürk,O.(2017):Deep learning-based crack damage detection using convolutional neural networks.Computer-Aided Civil and Infrastructure Engineering,vol.32,no.5,pp.361-378.
Chen,J.H.;Su,M.C.;Cao,R.;Hsu,S.C.;Lu,J.C.(2017a):A self organizing map optimization based image recognition and processing model for bridge crack inspection.Automation in Construction,vol.73,pp.58-66.
Chen,X.L.;Fu,J.P.;Yao,J.L.;Gan,J.F.(2017b):Prediction of shear strength for squat RC walls using a hybrid ANN-PSO model.Engineering with Computers,vol.34,no.2 pp.367-383.
Cusson,D.;Lounis,Z.;Daigle,L.(2011):Durability monitoring for improved service life predictions of concrete bridge decks in corrosive environments.Computer-Aided Civil and Infrastructure Engineering,vol.26,no.7,pp.524-541.
Denys,B.(2010):Chapter three.Deterioration Processes in Reinforced Concrete:An Overview.Woodhead Publishing Limited,UK.
Dogan,G.;Arslan,M.H.;Ceylan,M.(2017):Concrete compressive strength detection using image processing based new test method.Measurement,vol.109,pp.137-148.
Elaty,M.A.A.A.(2014):Compressive strength prediction of Portland cement concrete with age using a new model.HBRC Journal,vol.10,no.2,pp.145-155.
Ghodoosi,F.;Abu-Samra,S.;Zeynalian,M.;Zayed,T.(2018):Maintenance cost optimization for bridge structures using system reliability analysis and genetic algorithms.Journal of Construction Engineering and Management,vol.144,no.2,04017116.
He,K.;Zhang,X.;Ren,S.;Sun,J.(2016):Deep residual learning for image recognition.IEEE Conference on Computer Vision and Pattern Recognition,pp.770-778.Hilsdorf,H.;Kropp,J.(2004):Performance Criteria for Concrete Durability.CRC Press,USA.
Hu,C.;Li,Z.(2014):Micromechanical investigation of Portland cement paste.Construction and Building Materials,vol.71,pp.44-52.
Ju,M.;Park,K.;Oh,H.(2017):Estimation of compressive strength of high strength concrete using non-destructive technique and concrete core strength.Applied Sciences,vol.7,no.12,pp.1249.
Kaouther,J.M.A.M.(2014):Destructive and non-destructive testing of concrete structures.Jordan Journal of Civil Engineering,vol.8,no.4,pp.432-441.
Khoudja,A.B.;Sbartaï,Z.M.;Breysse,D.;Kenai,S.;Ghrici,M.(2017):Analysis of the single and combined non-destructive test approaches for on-site concrete strength assessment:general statements based on a real case-study.Case Studies in Construction Materials,vol.6,pp.109-119.
Krizhevsky,A.;Sutskever,I.;Hinton,G.E.(2012):ImageNet classification with deep convolutional neural networks.Proceedings of the 25th International Conference on Neural Information Processing Systems,vol.1,pp.1097-1105.
Krizhevsky,A.;Sutskever,I.;Hinton,G.E.(2017):ImageNet classification with deep convolutional neural networks.Communications of the ACM,vol.60,no.6,pp.84-90.
Ki,C.M.;Cho,T.H.(2017):Efficient implementation of convolutional neural network using CUDA.Journal of the Korea Institute of Information and Communication Engineering,vol.21,no.6,pp.1143-1148.
Kim,S.S.;Lee,J.Y.(2016):Present and future of concrete technology.Review of Architecture and Building Science,vol.60,no.2,pp.26-30.
Lange,D.A.;Jennings,H.M.;Shah,S.P.(1994):Image analysis techniques for characterization of pore structure of cement-based materials.Cement and Concrete Research,vol.24,no.5,pp.841-853.
LeCun,Y.;Bottou,L.;Bengio,Y.;Haffner,P.(1998):Gradient-based learning applied to document recognition.Proceedings of the IEEE,vol.86,no.11,pp.2278-2324.
Lee,S.H.;Park,W.J.;Lee,H.S.(2013):Life cycle CO2assessment method for concrete using CO2balance and suggestion to decrease LCCO2of concrete in South-Korean apartment.Energy and Building,vol.58,pp.93-102.
Lin,Y.Z.;Nie,Z.H.;Ma H.W.(2017):Structural damage detection with automatic feature-extraction through deep learning.Computer-Aided Civil and Infrastructure Engineering,vol.32,no.12,pp.1025-1046.
Marios,S.;Bungey,J.(2010):Chapter one.Introduction:Key Issues in the Non-Destructive Testing of Concrete Structures.Woodhead Publishing Limited,UK.
Omar,B.D.;Boukhatem,B.;Ghrici,M.;Tagnit-Hamou,A.(2017):Prediction of properties of self-compacting concrete containing fly ash using artificial neural network.Neural Computing and Applications,vol.28,no.1,pp.707-718.
Park,T.W.;Jung,L.(2010):Prediction of concrete compressive strength by neurofuzzy inference system.Journal of the Computational Structural Engineering Institute of Korea,vol.23,no.3,pp.61-68.
Rashid,K.;Waqas,R.(2017):Compressive strength evaluation by non-destructive techniques:an automated approach in construction industry.Journal of Building Engineering,vol.12,pp.147-154.
Russakovsky,O.;Deng,J.;Su,H.;Krause,J.;Satheesh,S.et al.(2015):ImageNet large scale visual recognition challenge.International Journal of Computer Vision,vol.115,no.3,pp.211-252.
Saand,A.;Keerio,M.A.;Bangwar,D.K.(2017):Effect of soorh metakaolin on concrete compressive strength and durability.Engineering,Technology & Applied Science Research,vol.7,no.6,pp.2210-2214.
Schmidhuber,J.(2015):Deep learning in neural networks:an overview.Neural Networks,vol.61,pp.85-117.
Shi,C.;Wu,Z.;Lv,K.;Wu,L.(2015):A review on mixture design methods for selfcompacting concrete.Construction and Building Materials,vol.84,pp.387-398.
Shih,Y.F.;Wang,Y.R.;Lin,K.L.;Chen,C.W.(2015):Improving non-destructive concrete strength tests using support vector machines.Materials,vol.8,no.10,pp.5368.
Siregar,A.P.N.;Rafiq,M.I.;Mulheron,M.(2017):Experimental investigation of the effects of aggregate size distribution on the fracture behaviour of high strength concrete.Construction and Building Materials,vol.150,pp.252-259.
Soltani,M.M.;Zhu,Z.;Hammad,A.(2016):Automated annotation for visual recognition of construction resources using synthetic images.Automation in Construction,vol.62,pp.14-23.
Suguru K.;Soichi.O.;Naoki,M.(2012):Detection of cracks in concrete structures from digital camera images.NTT Technical Review,vol.10,no.2,pp.1-5.
Szegedy,C.;Vanhoucke,V.;Ioffe,S.;Shlens,J.;Wojna,Z.(2016):Rethinking the inception architecture for computer vision.Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition,pp.2818-2826.
Szegedy,C.;Liu,W.;Jia,Y.;Sermanet,P.;Reed,S.et al.(2015):Going deeper with convolutions.Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition,pp.1-9.
Wan,J.;Wang,D.;Hoi,S.C.H.;Wu,P.;Zhu,J.et al.(2014):Deep learning for content-based image retrieval:a comprehensive study.Proceedings of the 22nd ACM International Conference on Multimedia,pp.157-166.
Wang,J.;Ma,Y.;Zhang,L.;Gao,R.X.;Wu,D.(2018):Deep learning for smart manufacturing:methods and applications.Journal of Manufacturing Systems,vol.48,pp.144-156.
Wong,H.S.;Head,N.R.;Buenfeld,N.R.(2006):Pore segmentation of cement-based materials from backscattered electron images.Cement and Concrete Research,vol.36,pp.1083-1090.
Wong,H.S.;Pappas,A.M.;Zimmerman,R.W.;Buenfeld,N.R.(2011):Effect of entrained air voids on the microstructure and mass transport.Cement and Concrete Research,vol.41,pp.1067-1077.
Wu,K.R.;Chen,B.;Yao,W.;Zhang,D.(2001):Effect of coarse aggregate type on mechanical properties of high-performance concrete.Cement and Concrete Research,vol.31,pp.1421-1425.
Xu,J.;Luo,X.;Wang,G.;Gilmore,H.;Madabhushi,A.(2016):A deep convolutional neural network for segmenting and classifying epithelial and stromal regions in histopathological images.Neurocomputing,vol.191,pp.214-223.
Yaseen,Z.M.;Deo,R.C.;Hilal,A.;Abd,A.M.;Bueno,L.C.et al.(2018):Predicting compressive strength of lightweight foamed concrete using extreme learning machine model.Advances in Engineering Software,vol.115,pp.112-125.
杂志排行

Computers Materials&Continua的其它文章
- XML-Based Information Fusion Architecture Based on Cloud Computing Ecosystem
- Forecasting Damage Mechanics By Deep Learning
- Reduced Differential Transform Method for Solving Nonlinear Biomathematics Models
- SVM Model Selection Using PSO for Learning Handwritten Arabic Characters
- Automated Negotiation in E Commerce:Protocol Relevance and Improvement Techniques
- A Stochastic Numerical Analysis for Computer Virus Model with Vertical Transmission Over the Internet