基于邻节点和关系模型优化的网络表示学习
2019-12-18冶忠林赵海兴肖玉芝
冶忠林 赵海兴 张 科 朱 宇 肖玉芝
1(青海师范大学计算机学院 西宁 810008)2(陕西师范大学计算机科学学院 西安 710119)3(藏文信息处理教育部重点实验室(青海师范大学)西宁 810008)(zhonglin_ye@foxmail.com)
随着计算机处理性能的提升和网络数据规模的不断增长,对网络数据挖掘的重视程度也越来越高.网络数据挖掘不仅可以挖掘出隐藏在数据之下的真实价值,更可以推动改变现实生活的进程.网络数据挖掘主要面向对象为各类现实生活中的数据网络,例如:社交网络、引文网络、博客网络和通信网络等.这些网络统称为信息网络,且具有规模大、数据杂、噪音多等特点[1].目前,信息网络的数据挖掘是研究的热点和前沿,而深度学习、终生学习、强化学习等技术的提出更是将信息网络的数据挖掘引入了更深层次的研究范畴.网络数据挖掘具有重要的意义.例如在社交网络中,通过挖掘好友出行记录和文本内容可以预测游客未来出行安排,该预测结果可帮助旅游公司更加精准地推荐旅游服务信息.而信息网络与自然语言处理结合进行产品和服务的推荐是目前挖掘数据挖掘最有价值的应用.单纯地使用网络结构数据或者使用文本信息进行数据挖掘,则难以完全反映出真实网络的特征.因此,将网络结构特征和文本特征进行联合的学习和预测是数据挖掘致力于解决的难题.
信息网络数据挖掘首先需要面对的难题是如何恰当地表示网络数据.如果仅考虑网络的结构特征,则可以使用网络的邻接矩阵.如果仅考虑网络节点的文本特征,则可以将文本转化为共现矩阵.如果同时考虑网络的结构特征和网络节点的文本特征,则可以将2个矩阵进行列拼接或者降维后再拼接.这种简单的矩阵拼接虽然包含了2种不同数据的特征,但是却没有充分地考虑2种数据之间的关系,即关系被忽略.不论何种处理方式,矩阵的运算会导致模型的训练产生较高的计算复杂度,另外,在大规模的网络数据挖掘任务中也不具有可行性.
网络表示学习算法对上述任务提出了可行的解决方案.网络表示学习通过神经网络对网络节点之间的结构进行编码,能够处理大规模网络结构特征编码任务.其中最经典的算法为DeepWalk[2]算法,之后基于DeepWalk算法和思路提出了各种改进算法.然而现有的基于神经网络的表示学习算法将当前节点的所有上下文节点平等对待,使得在上下文窗口中的节点对当前中心节点具有同等地位的影响,即忽略了上下文节点的位置信息.例如在神经网络模型中当前窗口大小设置为5时,则当前节点前后的各2个节点作为其上下文节点.在神经网络训练过程中,上下文节点对(n-2,n0),(n-1,n0),(n0,n1),(n0,n2)被输入到神经网络模型中通过节点对共现不断地调整其向量中的元素值.该过程使得常出现于节点对中的节点在向量表示空间中拥有更近的空间表示距离,未出现于节点对中的节点在向量表示空间中具有更远的空间表示距离.但是,该训练过程并未考虑n-2,n-1,n1,n2与n0之间的距离.此时模型采用的是上下文结构无关性假设,采用这个假设的目的是为了加速模型训练速度.在文献[3-4]中已经验证了当窗口大小设置为5时,上下文对当前元素的影响达到最大.过大的窗口和过小的窗口都会影响模型的泛化和学习能力.因此,本文在采用神经网络模型训练网络表示的过程中,首次对网络采样的上下文节点对进行深入的优化,即在上下文窗口内对当前节点的邻居节点进行优化.本文同样设置神经网络采样上下文节点的窗口大小为5,此时n0的上下文节点为n-2,n-1,n1和n2.n-1,n1与n0之间的距离大于n-2和n2与n0之间的距离.因此,训练所得的网络表示中,n-1和n1的网络表示比n-2和n2的网络表示在向量空间中与n0的网络表示具有更近的空间距离.为了实现该目标,本文优化了当前节点的1阶邻节点,即优化了n-1,n1对n0的学习过程.2阶邻居节点n-2,n2并未做任何处理.因为,优化了n-1,n1与n0之间的学习强度,则同时自然地降低了n-2,n2与n0之间学习强度.对于n0,最终的结果是n-1和n1被训练出了更近的位置关系,n-2和n2被训练出了较远的位置关系.本文对1阶邻节点所采用的优化过程不同于node2Vec[5]和Walklets[6],这2类算法采用通过改变随机游走策略的方法改变神经网络的输入.而本文并未改变神经网络的输入,而是在神经网络训练的过程中优化随机游走序列中1阶邻节点对当前节点的贡献.
另外,现有的网络表示学习算法通常将节点文本作为特殊的节点或使用另外一个神经网络训练文本向量.例如TADW[7](text-associated deep walk)将网络节点的文本内容转化为词共现矩阵,之后使用降维方法得到文本的低维度特征.为了将文本特征和网络结构特征有效地融合,TADW引入了诱导矩阵补全算法[8],该算法将网络结构特征作为待分解的目标特征矩阵,同时将文本特征作为目标矩阵的辅助分解矩阵.TriDNR[9]使用第1个3层神经网络建模节点与节点之间的关系,并使用第2个3层的神经网络建模节点与其文本中的词语之间的关系.TriDNR同样使用第2个3层神经网络建模标签类别与文本中词语之间的关系.CENE[10]仍然采用DeepWalk[2,11-12]建模节点与节点之间的关系,并使用循环神经网络(recurrent neural network,RNN)和双向循环神经网络(bidirectional recurrent neural network,BiRNN)建模节点与文本内容之间的关系.TADW和CENE方法在构建文本特征时均采用了独立于建模节点关系之外的策略,TriDNR采用了将文本中的词语作为特殊的网络节点的策略.这3类方法在网络表示学习过程中采用了不同的策略建模节点与节点、节点与文本内容之间的关系.因此,本文在以上网络表示学习融入文本特征的研究基础上,引入了知识表示学习中的关系模型.利用关系模型可以在建模节点与节点关系的同时考虑节点文本之间的关系类型.为了实现该目标,本文引入了节点三元组的概念.而知识三元组(subject,predict,object)[13]常被用来表示知识及其关系,并在知识库中被大量应用.在关系模型中,知识被定义为关系三元组(h,r,t)[14]的形式.本文采用关系三元组(h,r,t)定义节点与节点关于文本的关系.h项和t项表示头节点和尾节点,r表示节点与节点之间在文本上拥有的共现词语,即2个节点的文本特征中含有共同的词语则表示2个节点之间具有了文本关联性.本文并不采用单独的关系模型建模节点与文本之间的关系,而是采用统一的目标函数将节点关系建模与节点与文本关系建模融合在一起进行训练,这样处理既可以保留节点关系建模过程,又可以引入节点与文本内容建模对节点关系建模的指导和影响.
以上过程详细讨论了优化邻节点对网络表示学习过程的影响,又讨论了引入关系模型建模对建模节点与文本之间的关联关系的意义,从而强化网络表示学习过程.这2个部分可单独建模和学习,验证其对网络表示学习的影响.为了学习得到更加稳健的网络表示,这2个部分可进行联合学习,从而提出了一个统一的联合学习框架.而本文提出的NRNR算法正是为了解决以上3个问题而提出.本文通过3个真实的引文网络数据集验证了其有效性和鲁棒性.
1 相关工作
表示学习又被称为嵌入学习,而Bengio等人[15]于2003年首次提出了“Word Embedding”一词.随后,Bengio等人[16]在2013年提出了一种基于深度神经网络的表示学习算法,但是该算法受限于计算机计算能力的限制并没有得到重视.而表示学习真正地受到科研人员的重视是在Mikolov 等人[3-4]与2013年提出了Word2Vec算法之后.Word2Vec使用窗口获取当前词语的上下文节点对,然后将节点对输入到一个浅层的3层神经网络中,基于节点对的共现不断地调整词语之间的表示向量.Word2Vec算法被广泛地应用于各类自然语言处理任务[17-20].2014年Perozzi 等人[2]基于Word2Vec算法提出了DeepWalk算法.DeepWalk在语言模型中引入了随机游走的采样方法,通过随机游走粒子在网络上的游走模拟语言模型中的句子,底层同样采用Word2Vec所采用的3层神经网络模型.DeepWalk被广泛应用于网络节点分类[11-12]、链路预测[21-22]、推荐系统[23]和可视化[24]等任务中.
DeepWalk为大规模网络表示学习任务提供了一种高效的解决方法,但是因其模型简单,在某些任务中效果并没有传统的方法好,因此基于DeepWalk提出了各类网络表示学习的改进模型.例如node2Vec[5]和Walklets[6]改进了网络表示学习中的随机游走过程.LINE[25]引入1阶相似度和高阶相似度对大规模网络进行表示学习.NEU[26](net-work embedding update)和GraRep[27]提出了高阶逼近的网络表示学习.TADW[7]仅引入诱导矩阵补全算法[8]将网络节点的文本特征嵌入到网络表示学习中.DDRW[28](discriminative deep random walk),MMDW[29](max-margin deepwalk),TLINE[30],GENE[31](group enhanced network embedding)和SemiNE[32](semi-supervised network embedding)引入了网络节点的标签类别信息约束网络表示学习模型.TriDNR[9](tri-party deep network represen-tation),LDE[33](linked document embedding),DMF[34](discriminative matrix factorization),Planetoid[35](predicting labels and neighbors with embeddings transductively or inductively from data),LANE[36](label informed attributed network embedding)同时引入了网络节点的文本内容和节点的标签类别约束网络表示学习模型.针对动态网络和超网络等特殊的网络结构,也提出了相应的网络表示学习算法,例如DynamicTriad[37](dynamic triadic),DepthLG[38],DHNE[39](deep hyper-network embedding)等.另外,生成对抗网络(generative adversarial network,GAN)[40]也被引入到网络表示学习中,例如ANE[41](adversarial network embedding),GraphGAN[42],NetGAN[43]等.
以上内容详细地讨论了网络表示学习的起源,描述和解释了网络表示学习中的经典算法,并介绍了最新的一些网络表示学习算法,例如特殊结构的网络表示学习和生成对抗式的网络表示学习算法等.但是,以上部分算法在基于神经网络训练表示学习模型时,并未考虑不同位置的上下文节点对中心节点的影响,也未考虑使用关系模型构建节点对之间的关系.因此,本文提出的NRNR算法正是为了优化以上2个目标而提出.因为,在上下文窗口中,不同位置的节点对中心节点的影响力是不相同的.应该使中心节点的1阶邻居节点比2阶邻居节点拥有更大的影响力.另外,通过矩阵分解或者异构网络将文本特征嵌入到网络表示具有较大的计算开销,而本文首次采用关系模型机制将及节点之间的多元关系嵌入到网络表示,其计算开销较小且拥有统一的目标函数,且在多元关系向量建模过程中优化具有相同关系节点对之间的表示向量学习过程.
2 算法设计
2.1 定 义

2.2 关系模型
关系模型最经典的算法为TransE(translating embeddings),该算法于2013年被Bordes等人[14]在NIPS(neural information processing systems)会议上提出.TransE被提出主要是用来解决大规模知识库中知识的表征学习[44],即研究如何将知识嵌入到一个低维度的向量空间中,其目的是建模多关系数据.现有的知识库有OpenCyc(open cycorp),WordNet,Freebase,Dbpedia[13]等.这些知识库中已有大量的知识,但是这些知识都是基于现有的知识抽取而得,而研究基于知识库的知识推理就需要研究如何对知识进行表征,进而从现有的知识中推导出大量的未知知识.
TransE是基于翻译机制的知识嵌入模型,其将关系三元组(h,r,t)中的关系r作为实体h到实体t的翻译,并通过关系三元组的不断涌现从而持续地调整实体h、关系r和实体t的表示向量,使实体h与关系r的和向量xh+xr尽可能与实体t的向量xt具有更近的空间距离,即模型训练的目标为xh+xr≈xt基于该目标,TransE的目标函数为

(1)
其中:
S′(h,r,t)={(h′,r,t)|h′∈E}∪
{(h,r,t′)|t′∈E},
(2)

(3)
S为三元组(h,r,t)的集合,S′为三元组(h,r,t)的负采样集合,即存在于知识库中的(h,r,t)为正样本,不存在于知识库中的(h,r,t)为负样本.λ>0为间隔距离超参;x>0时[x]+=x,x≤0时[x]+=0.
本文使用节点关系三元组作为关系模型的输入.在构建节点关系三元组时,本文仅考虑了一元关系.一元关系是2个节点的文本中含有一个共同词语时,则将该词语作为2个节点的关系.例如,节点1的文本标题为“Neural Network for Pattern Recog-nition”,节点2的文本标题为“Neural Network:A Comprehensive Foundation”.则可以构建的节点三元组为(Node1,neural,Node2)和(Node1,network,Node2).这种类型的节点三元组被称为含一元关系的节点三元组.
2.3 使用负采样的CBOW模型
Word2Vec提供了2种模型:CBOW和Skip-Gram,并提供了2种优化方法:负采样和层次化的Softmax[3-4].DeepWalk是基于Word2Vec模型提出的大规模网络表示学习算法[2],因此,DeepWalk完全继承了Word2Vec提供的训练模型和优化方法.CBOW模型训练速度快,但是精度略劣于Skip-Gram.负采样优化方法由于不用构建huffman树,故优化速度也优于层次化的Softmax.因此,本文采用负采样优化的CBOW训练DeepWalk模型,并将1阶邻节点优化的目标函数和关系模型的目标函数融入到DeepWalk的目标函数中.
对于当前中心节点v,其上下文定义为Context(v).负采样集合定义为NEG(v),且NEG(v)≠∅.对于∀u∈D,D表示节点集合.定义节点u的标签为

(4)
即正样本的标签为1,负样本的标签为0.
在负采样的过程中,当前中心节点为正样本,其他所有节点为负样本,然后将所有概率相乘使其最大化.对于单个样本(v,Context(v))有:

(5)
则所有样本的概率之和为

(6)
xv是上下文Context(v)中每个节点的向量之和,θξ是节点ξ的待训练向量,式(6)可被简化为

(7)
因此,函数g(v)通过式(5)和式(7)生成为

(8)
综上,基于语料C,负采样优化的CBOW的整体优化目标函数可定义为

(9)
对式(9)取对数操作,则整体的目标函数可修改为

(10)
在神经网络模型中,目标函数一般取对数似然函数,且对数的底通常省略,因为在最终的参数更新公式中,对数形式会被转化为非对数形式.从式(10)抽取出基于负采样优化的CBOW模型的目标函数最常用的形式为

(11)
其中:
(12)
式(11)中,C为节点序列语料,使用随机梯度上升法获得式(10)中变量θξ的更新公式为
θξ
(13)
c(v)c(v)+
(14)
式(13)中μ表示学习率,xv为Context(v)中每个节点的表示向量之和.通过xv可以获得Context(v)中每个节点的表示向量更新方式,如式(14)所示.
2.4 NRNR建模
本文提出的NRNR算法旨在于解决如何使用1阶邻节点优化网络表示学习过程,同时解决如何采用网络节点的文本内容优化网络表示学习过程,为了适应大规模网络表示学习任务要求,需要提出一种简单高效的联合学习模型.为了实现该方案,本文提出了一种基于神经网络的网络表示联合学习框架,该框架由3个部分构成,分别为1阶邻节点优化部分、网络节点关系建模部分和节点与文本关系模型构建部分.具体如图1所示:

Fig.1 NRNR algorithm framework图1 NRNR 算法框架
如图1所示,Nvi表示当前中心节点vi的1阶邻节点集合,Rvi表示当前中心节点vi的节点三元组集合.在Word2Vec中,CBOW模型是通过上下文词语出现的概率去预测当前中心词出现的概率.而DeepWalk算法是基于Word2Vec算法的改进,因此,底层同样可以采用CBOW模型学习节点与节点之间的关系.例如对于当前中心节点vi,CBOW模型通过其在随机游走序列中的前面2个节点vi-2和vi-1以及其后面2个节点vi+1和vi+2来预测当前中心节点vi出现的概率.CBOW模型通过不断地调整网络表示向量中的值,使得具有连边的节点对之间具有更近的表示向量空间距离,使得具有多跳边或者没有边的节点对之间具有较远的表示向量空间距离.本文提出的NRNR算法在该调节的过程中添加了一些约束,即使得当前中心节点vi的1阶邻居节点vi-1和vi+1比2阶邻居节点vi-2和vi+2在向量表示空间中与vi具有较近的空间距离.在图1中,vj∈Nvi=(vi-1,vi+1).另外,NRNR算法添加了文本特征,该文本特征是将具有共同出现词语的节点对之间转化为节点三元组关系.NRNR算法采用多源关系建模思想优化了网络表示向量学习过程,即使得具有三元组关系约束的节点对比没有三元组关系约束的节点对在网络表示向量空间中具有更近的空间距离.
在NRNR算法中,以上过程可被认为是3个CBOW模型的叠加.另外,CBOW模型与1阶邻节点优化过程共享一份节点向量,同时,与关系模型优化过程也共享1份节点向量.因此,本文提出的NRNR通过共享向量来获得和交换彼此的特征信息,使得NRNR算法在建模学习过程中能够从1阶邻居节点和节点三元组中获取有价值的特征信息,从而使获得的网络表示能够在各类任务中具有更强的泛化能力.另外,共享节点向量为联合学习模型提供了解决思路.
为了将1阶邻节点信息融入到网络表示学习模型中,本文提出的目标函数为
(15)
本文中,NRNR_N算法的学习目标是最大化式(15),因此,本文采用了类似于Word2Vec[3-4]所采用的随机梯度上升法获得每个参数的更新公式.其中,gCv(v)与gNv(v)的具有相同的形式.式(15)的v即为图1中的vi,因为我们在式(15)中最外层的求和符号下标设定为v∈C,如果将此下标设置为1≤i≤|C|,则式(15)中的v全部应替换为vi.式(15)的左边项为CBOW的目标函数,其参数更新见式(13)(14).式(15)右边项为本文添加的约束项,其本质为一个CBOW模型,即再一次使用1阶邻居节点优化网络表示学习模型,故优化求解方法与CBOW完全相同.首先我们设求偏导的表达式为
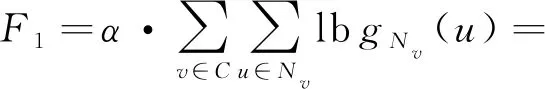
(16)
令:

(17)
式(16)中,对于当前节点的1阶邻居节点集合而言,目标节点是正样本,而该集合之外的所有节点均为负样本.然后采用f1分别对θξ和xu求偏导.最终求得式(17)中θξ和1阶邻居节点n(u)的更新公式为
θξ
(18)
n(u)n(u)+μ·
(19)
本文中通过权重α控制1阶邻居的权重,因此权重α需要乘到式(18)(19)中的μ之前.另外,xu为当前节点的1阶邻居节点的表示向量之和,n(u)为其中每个1阶邻居节点的表示向量.
NRNR然引入了关系模型,但是并未使用TransE[14]算法建模节点三元组,如果使用TransE模型,需要将TransE的目标函数融入到DeepWalk算法的目标函数中.在TransE算法中,三元组(h,r,v)满足xh+xr≈xv.该式子是TransE算法的训练目标,即如果节点v和节点h之间存在关系r,则让节点h和节点r的向量之和尽量靠近节点v的表示向量,否则应该远离v的表示向量.本文将关系模型的思想引入到NRNR算法中,实现了在建模网络节点对之间关系的同时建模了节点三元组之间的关系.基于此,本文提出了一种基于CBOW的关系模型构建方法NRNR_R.其目标函数为

(20)
在式(20)中,Rv表示构成v的关系三元组(h,r,v)的集合.式(20)中gh+r(v)可被认为是通过节点h之间的关系r来预测节点v出现的概率.式(20)类似于式(15),均可被认为是2个CBOW模型的叠加,左边的第1个CBOW模型的更新公式可见式(13)(14).右边第2项我们设:

(21)
令:
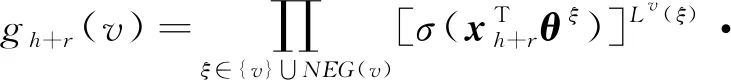
(22)
又令:

(23)
NEG(v)进行负采样时,客观存在的三元组设置为正样本,而非客观存在的三元组设置为负样本.然后用函数f2对θξ求偏导数,最终得到θξ的更新公式为
θξ
(24)
由于xh+r=xh+xr,因此,需要单独对xh和xr求偏导,得到最终的更新公式为
xhxh+μ·
(25)
xrxr+μ·
(26)
本文中通过权重β控制三元组的权重,因此,权重β需要乘到式(24)~(26)中的μ之前.


(27)
式(27)可被认为是3个CBOW模型的叠加,因此,每个部分的参数更新即为整个表达式的参数更新公式.故式(27)的参数更新公式由式(13)(14)(18)(19)(24)~(26)组成.另外,也需要在参数更新公式中添加权重α和β.为了更加详尽地介绍本文提出的NRNR算法的具体流程,我们给出了算法伪代码:
算法1.NRNR.
输入:图G(V,E)、节点向量大小d、每个节点的随机游走数量wp、随机游走长度wl、节点三元组R、节点三元组权重β,1阶邻居节点权重α;
输出:节点向量V.
/*获取所有节点的随机游走序列*/
① fori=0 towpdo
②O←Shuffle(V);
③ forv∈Odo
④C←WalkSeqAppend(G,v,wl);
⑤ end for
⑥ end for
/*初始化所有参数*/
⑦vertex_size←GetVocabSize(C);
⑧relation_num←GetRelationNum(R);
⑨V←InitVector(vertex_size,d);
⑩θ←InitVector(vertex_size,d);
/*对每一个节点作如下训练和优化*/
/*训练原始的负采样优化的CBOW模型*/
/*根据式(13)(14)更新CBOW模型的参数*/
/*更新上下文节点的表示向量*/
/*采用1阶邻居节点优化网络表示学习模型*/
/*根据式(18)(19)更新模型参数*/
/*采用节点三元组优化网络表示学习模型*/
/*获取所有的节点三元组*/
/*根据式(24)~(16)更新模型参数*/
3 实验与分析
3.1 数据集描述
本文使用Citeseer(M10),DBLP(V4)数据集验证本文提出算法的可行性.为了验证在稠密网络中的可行性,本文基于DBLP(V4)构造了一个高平均度的网络Shifted DBLP(SDBLP).在SDBLP中删除了所有孤立节点,并且删除了节点连边数少于或等于2的所有节点及其连边.3个数据集的具体属性描述如表1所示:

Table 1 Property Description on Citeseer,DBLP and SDBLP Datasets表1 Citeseer,DBLP和SDBLP数据集属性描述
如表1所示,列2和列3分别为原始数据集中的节点数量和连边数量.列4为网络中孤立节点的数量.经过删除孤立节点等操作,剩余的节点数量和连边数量如列5和列6所示.最终删除后的网络中,Citeseer,DBLP,SDBLP数据集中节点个数分别为4610,17725,3119,网络平均度分别为2.57,11.936,25.339.可以发现,网络的密度越来越高.本文使用Citeseer,DBLP,SDBLP模拟3类属性不同的网络数据集,从而验证本文提出算法的泛化能力.
3.2 对比算法
1)DeepWalk.DeepWalk算法是基于神经网络的最经典的网络表示学习算法,后续的诸多网络表示学习算法均是基于DeepWalk算法而提出.DeepWalk起源于Word2Vec算法.DeepWalk可使用CBOW和Skip-Gram两种模型训练基于神经网络的表示学习模型,另可采用负采样和层次化的Softmax加速网络训练过程,CBOW具有训练速度快的特点,Skip-Gram具有精度高的特点.在本文中,使用CBOW和负采样训练DeepWalk.
2)LINE.Tang等人[25]提出了一种大规模网络表示学习算法,该算法通过部分舍弃精度的方式追求在超大规模网络中编码网络结构成为低维度的网络表示.因此,LINE的训练速度非常快,但是精度不高,尤其在稀疏网络中网络节点分类性能较差.这种速度的提升主要来自于LINE仅考虑网络的1阶相似度1st LINE或者2阶相似度2nd LINE.本文中使用2nd LINE训练网络表示.
3)node2Vec.node2Vec是基于DeepWalk算法而提出的一种网络表示学习算法.DeepWalk的随机游走策略是完全的随机,而node2Vec改进了Deep-Walk的随机游走策略,即采用了图论中的广度优先搜索策略和深度优先搜索策略来采样节点,广度优先搜索控制网络的全局宏观视图特征,深度优先搜索控制网络的局部微观视图特征.
4)GraRep.GraRep是一种基于矩阵分解的高阶网络表示学习算法,在该算法中,定义1阶的概率转移矩阵为A=D-1S,其中S为邻接矩阵,D为对角矩阵,则第k阶的网络结构特征定义为Ak.然后使用SVD去分解每一阶的网络结构特征,最后拼接所有阶的表示向量.在本文中,设置k=3.
6)DeepWalk+TF.将DeepWalk和TF生成的网络表示向量通过列向量扩充的形式拼接在一起.
7)MFDW.网络表示学习算法DeepWalk被证明是分解矩阵M=(A+A2)/2,本文使用SVD算法去分解矩阵M,并使用W=U·S0.5作为网络的表示向量.
8)TADW.网络表示学习算法DeepWalk被证明是分解矩阵M=(A+A2)/2,其中A为邻接矩阵.TADW并非使用SVD去分解矩阵M,而是引入了诱导矩阵补全算法去分解矩阵M.因为诱导矩阵补全算法可提供一个外部矩阵辅助分解矩阵M的功能.
9)STADW.该算法是TADW算法的简化形式,在TADW算法中删除了对文本特征的优化处理.
3.3 实验设置
本文使用网络节点分类任务评估本文提出的算法与本文引入的对比算法.本文使用Liblinear[45]作为基线分类器.为了验证算法的泛化能力,本文将训练集设置为0.1~0.9,共9个比例的训练集,将剩余的网络节点作为测试集.网络表示学习算法得到的网络表示向量统一设置为100维.另外,设置随机游走长度为40,随机游走个数为10条,窗口大小为5,负采样为5,最小节点频度为5,神经网络的学习率为0.05,1阶邻居节点的权重为0.7,节点三元组的权重为0.3.本文中所有实验均重复10次取平均值作为最终的结果.
3.4 实验结果分析
本文使用Citeseer,DBLP,SDBLP等真实的网络数据集作为评估数据集.并从数据集中抽取10%~90%的数据作为训练集,剩余的数据作为测试集.表2~4列出了本文引入的对比算法和本文提出的算法在3个数据集和9种训练集比例下的网络节点分类准确率.

Table 2 Accuracy of Vertex Classification on Citeseer表2 Citeseer数据集上的节点分类准确率

Table 3 Accuracy of Vertex Classification on DBLP表3 DBLP数据集上的节点分类准确率

Table 4 Accuracy of Vertex Classification on SDBLP表4 SDBLP数据集上的节点分类准确率
如表2所示,LINE算法的网络节点分类性能最差.MFDW为DeepWalk的矩阵分解形式,其在各比例的训练集条件下获得的网络节点分类性能均优于DeepWalk算法.DeepWalk和node2Vec算法的底层均为一个3层的浅层神经网络算法,不同的是上层的随机游走序列获取方式不同.从实验结果可知,node2Vec算法的网络节点分类性能优于DeepWalk算法.在Citeseer数据集上,网络节点的文本特征在节点分类任务中其性能优于DeepWalk算法.因此通过简单地拼接策略和类似于TADW算法融入文本特征进入网络表示,其获得的网络节点分类性能均得到了极大地改善.STADW中删除了对文本特征的优化,因此其性能劣于TADW.本文提出的NRNR_N优化了随机游走过程中的1阶邻居节点,其性能优于DeepWalk算法.本文提出的NRNR_R通过节点三元组的形式将文本特征融入到网络表示中,其性能优于TADW算法.本文提出的NRNR_NR将NRNR_N和NRNR_R的思路融合在一起,即同时将1阶邻居节点的优化和文本特征融入到网络表示中,其获得的性能优于NRNR_N和NRNR_R,也均优于本文中提出的其他对比算法.
如表3所示,在DBLP稠密网络上,DeepWalk的网络节点分类性能略劣于LINE和GraRep.由于稠密网络中存在大量的连边,因此,网络节点之间的结构关系可得到充分地挖掘,node2Vec,DeepWalk等基于神经网络的网络表示学习算法能够得到充分地训练.在该数据集中,同样存在基于DeepWalk的矩阵分解MFDW算法其分类性能优于DeepWalk的现象.随着训练集比例的提高,文本特征TF的网络节点分类性能越来越优于DeepWalk.但是通将TF的特征向量与DeepWalk的表示向量进行简单拼接,其获得的性能却劣于文本特征的性能.通过矩阵分解思想融入文本特征(TADW),其网络表示分类性能远优于DeepWalk,node2Vec,GraRep等网络表示学习算法.由于是稠密网络,因此优化1阶邻节点得到的NRNR_N算法其分类性能略优于DeepWalk.NRNR_R引入知识表示的思想进入网络表示,从而将文本特征以三元组约束的形式融入到网络表示中,其分类性能优于TADW.NRNR_NR融合了NRNR_N与NRNR_R的学习过程,因此与本文引入的对比算法相比,NRNR_NR获得了最好的性能.
如表4所示,在SDBLP数据集上,基于矩阵分解的网络表示取得了很好的节点分类性能,例如,DeepWalk的矩阵分解算法MFDW,在各训练集比例下,其性能均优于基于神经网络的DeepWalk算法.基于矩阵分解的高阶表示学习GraRep算法同样也获得了优于DeepWalk的性能.基于本文提出的NRNR_N算法优化了DeepWalk算法在随机游走过程中的1阶邻居节点,因此,其节点分类性能优于DeepWalk.SDBLP数据集上,文本特征的节点分类性能是最差的,因此,将DeepWalk和文本特征的向量简单拼接后,其性能的提升是非常有限的.TADW通过诱导矩阵补全融入文本特征到网络表示,NRNR_R通过神经网络融入文本特征到网络表示,STADW删除了TADW中对文本特征的优化.通过实验发现,在SDBLP数据集上,TADW,STADW,NRNR_N在节点分类任务上的性能几乎相同.相较于NRNR_N和NRNR_R,NRNR_NR的性能得到了显著的提升.
在Citeseer和DBLP数据集上,NRNR_N算法的网络节点分类性能不如NRNR_R和NRNR_NR算法.在Citeseer数据集上,NRNR_N算法的平均分类准确率为0.626 3,DeepWalk算法的平均分类准确率为0.612 2.在DBLP数据集上,NRNR_N算法的平均分类准确率为0.669 7,DeepWalk算法的平均分类准确率为0.656 5.因此,在Citeseer和DBLP数据集上,DeepWalk和NRNR_N算法之间的平均分类准确率提升为2.32%和2.02%.而NRNR_R和NRNR_NR的提升率远大于该值.主要原因是虽然NRNR_N在网络表示学习过程中优化了1阶邻居节点,使得1阶邻居节点与中心节点之间的关联度大于2阶邻居节点与中心节点之间的关联度.但是使用Citeseer,DBLP,SDBLP数据集和网络节点分类准确率衡量算法性能时,NRNR_N和DeepWalk算法均能够较好地识别不同类别节点内部节点的标签,而NRNR_N算法能够优化不同类别之间的边界节点被错误分类的过程.例如在边界节点中2阶邻居节点是另外一个类别的节点时,DeepWalk算法会使得该不同类别的节点与中心节点之间具有较近的表示向量空间距离,而NRNR_N算法仅优化1阶邻居节点,因此能够增进1阶邻居节点与中心节点之间的表示向量空间距离,从而疏远了中心节点与2阶邻居节点之间的表示向量空间距离,进而避免将不同类别的节点分类到同一个类别中.在Citeseer和DBLP数据集上,仅使用文本特征进行网络节点分类,则文本特征的网络节点分类性能优于DeepWalk算法,因此,NRNR_R引入了外部文本特征后能够优化网络节点分类性能,使得NRNR_R的网络节点分类性能优于NRNR_N和DeepWalk等算法.
本文主要提出了3种网络表示学习框架:NRNR_N,NRNR_R,NRNR_NR.NRNR_N是对DeepWalk中随机游走序列中的1阶邻居节点进行优化,NRNR_R基于DeepWalk模型引入文本特征,NRNR_NR是NRNR_N与NRNR_R的融合,TADW通过矩阵分解思想引入网络节点的文本特征.因此,为了直观地展示本文引入的3种模型是否有效,本文图示化了NRNR_N,NRNR_R,NRNR_NR,DeepWalk,TADW在Citeseer,DBLP,SDBLP上的网络节点分类性能,具体结果如图2所示.
Fig.2 Performance comparisons of five algorithms on three datasets图2 3种数据集上5种算法性能对比图
如图2所示,5种算法在Citeseer和DBLP数据集上的网络节点分类准确率值跨度大于其在SDBLP数据集上的值.在SDBLP数据集上,5类对比算法的网络节点分类准确率呈现出了显著的上升趋势.但在Citeseer和DBLP数据集上,准确率曲线表现出了比较缓慢的上升趋势.另外,在这2类数据集上,DeepWalk和NRNR_N的准确率曲线与NRNR_R,NRNR_NR,TADW这3条准确率权限之间有着明显的大跨度.出现这种现象的主要原因是在稀疏网络上,不同算法之间的获取的特征差异性较大,如果某种算法能够获取较为充分地反映网络结构的特征,则其网络分类性能变得越好.且在这类稀疏网络上,基于联合学习的网络表示学习算法能够弥补因为边稀疏而带来的训练不充分问题.而在稠密网络上,不同算法均能从充分地边连接中获得有效的网络结构特征,因此表现出来的分类性能之间的差异性就越小.
基于表2~4和图2的结果,本文得到4点结论:
1)在Citeseer稀疏网络上,基于高阶表示的GraRep其网络节点分类性能不如DeepWalk优异,但是在DBLP和SDBLP等稠密网络数据集上,GraRep的网络节点分类性能优于DeepWalk.该结果表明,在稀疏网络上,高阶的网络表示学习算法倾向于获得较差的分类效果.主要是由于网络稀疏,通过矩阵多次相乘获得的高阶特征无法准确地反映出网络结构特征.
2)在DBLP和SDBLP等稠密网络数据集上,基于矩阵分解的网络表示学习算法比基于浅层神经模型的网络表示学习算法更有效,前者在网络节点分类任务中性能稍优于后者.但由于矩阵分解效率和复杂度的限制,基于矩阵分解的网络表示学习算法在大规模网络表示学习任务中不可行.主要的原因是,在稠密网络中,网络节点之间的连边数较多,基于纯结构的随机游走算法能够充分地挖掘出节点所蕴含的网络结构,因此不同网络表示学习算法之间的差异性不明显.假如引入的外部特征噪音较多,反而会使得网络表示学习的性能受到影响.
3)网络节点的文本特征融入方式较多.本文实验对比了拼接方法、诱导矩阵补全和类知识表示的节点三元组约束等方法.其中,简单的向量拼接方法并不能带来网络表示性能大幅度的提升.诱导矩阵补全是一种非常有效的文本特征融入框架,在3类真实数据集上均获得了优异的网络表示性能.本文提出的文本特征融入框架克服了矩阵分解的计算限制,采用节点三元组对DeepWalk训练过程进行约束,从而使得到的网络表示中含有语义信息,也使得网络表示含有更多的信息.
4)在Citeseer等稀疏网络上,通过优化随机游走过程中一阶邻居节点,NRNR_N的分类性能优于DeepWalk,但是随着网络节点的平均度的增大,这种差异会变得越来越小.例如在DBLP和SDBLP数据集上,NRNR_N和DeepWalk之间的分类性能差异变得很小.通过将2种优异的网络表示学习算法融合学习,得到的算法在网络节点分类任务中其性能优于其中的一种算法,例如本文使用NRNR_NR融合了NRNR_N和NRNR_R这2种算法的改过程,其性能在3类数据集上均获得了优于其中一种算法的效果.
3.5 网络表示可视化
网络表示可视化的主要目的是查看训练得到的表示向量能否出现明显的聚类现象,如果出现了聚类现象,则在网络节点分类和链路预测等任务中可发挥出优异的性能.聚类现象可被认为是网络表示是否学习得到了网络的社团信息.基于网络表示得到的社团划分越准确,则在网络节点分类任务中具有更好的可靠性.在此实验中,本文从Citeseer数据集中随机选取了4类节点,每个类别随机选取150个节点.本文使用 t-SNE算法可视化学习得到的网络表示.具体结果如图3所示:
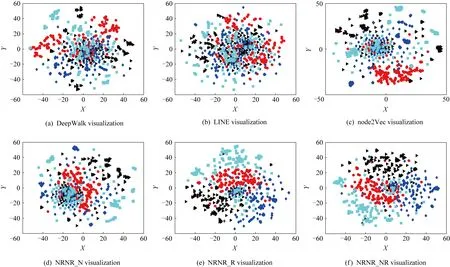
Different shapes and colors represent different types of verticesFig.3 The network visualization results of the partial vertices on the Citeseer dataset图3 网络部分节点表示在Citeseer数据集上可视化结果
从图3可以发现,本文可视化了DeepWalk,LINE,node2Vec与本文提出的3类模型训练得到的部分网络表示向量.从表2~4可知,DeepWalk和LINE的网络表示分类性能较差,因此,这2种算法学习得到的网络表示向量在可视化任务中也同样表现出了较差的结果.node2Vec和NRNR_N可视化结果中,仅有2类节点表现出凌乱的分布,其余2类颜色的节点具有明显的聚类边界.本文提出的NRNR_R和NRNR_NR的可视化结果中,4类节点的表示向量均展现出了明显的聚类现象和聚类边界.该可视化实验说明,在网络表示学习任务中,网络1阶邻居节点优化、网络节点文本优化或者2种优化联合学习的策略均能提高网络表示学习的性能.
3.6 案例研究
在该案例研究中,首先使用“An Evolutionary Algorithm That Constructs Recurrent Neural Networks”作为目标节点的文本,然后返回与该目标节点最相似的3个节点.本实验通过余弦相似度计算节点之间的相似度值.
如表5所示,DeepWalk算法基于网络的结构特征学习网络表示,未考虑节点的文本相似性,因此返回的相似节点中最相关的节点文本中不含有目标节点文本中的词语.TADW和NRNR_NR均考虑了节点的文本特征和结构特征,因此,返回的相似节点中,其节点文本与目标节点的文本之间均有相同的词语共现.由于不同的算法挖掘网络节点之间的不同结构特征,因此返回的最相似节点的文本可能并不相同.

Table 5 Case Study on Citeseer表5 Citeseer数据集上的案例分析
4 总 结
本文首次引入了邻节点优化策略提升网络表示学习性能,在窗口大小为5时,当前节点的1阶邻节点被优化,自然地与2阶邻节点产生了不同,进而导致一阶邻节点和2阶邻节点对当前中心节点的影响不同.该1阶邻节点的优化过程被认为是为窗口内的上下文节点赋予不同的位置信息.本文首次引入了关系模型进入网络表示学习,该方法是一种新颖的文本嵌入网络表示的方法.不同与TADW和CENE等单独训练文本特征的方式,本文提出的NRNR方法在训练网络表示学习模型的同时建模了节点与文本之间的关联关系.为了实现该过程,本文进而引入了节点关系三元组概念,使得节点之间含有共同词语的节点对在向量表示空间中具有更近的网络表示.本文提出了3个目标函数,分别讨论了1阶邻节点、节点三元组与其2者联合学习对网络表示学习性能的影响.实验结果表明,添加了1阶优化的网络表示学习NRNR_N算法在网络节点分类任务中其性能优于原始的DeepWalk算法.使用关系模型建模节点与文本内容的NRNR_R算法在网络节点分类任务中其性能优于TADW算法.如果将NRNR_N和NRNR_R相结合学习,则得到的NRNR_NR算法在网络节点分类任务中其性能均优于本文提出的各类对比算法.在网络可视化测试中,本文提出的NRNR_R和NRNR_NR均展示出了明显的聚类现象,其聚类边界明显.因此,本文所做的实验地验证了本文提出的NRNR算法具有可行性.在未来研究中将研究如何增大不同社区或类别的节点在向量表示空间中的距离.
