融合对抗训练的端到端知识三元组联合抽取
2019-12-18黄培馨朱慧明肖卫东
黄培馨 赵 翔,2 方 阳 朱慧明,3 肖卫东,2
1(国防科技大学信息系统工程重点实验室 长沙 410073)2(地球空间信息技术协同创新中心(武汉大学)武汉 430079)3(长沙商贸旅游职业技术学院经济贸易学院 长沙 410073)(huangpeixin15@nudt.edu.cn)
知识图谱描述现实世界中客观存在的实体以及实体之间的关系[1].在知识图谱中,一般用节点表示实体(entities),如人名、物品、地名等,用边即实体之间的连线表示关系(relations),如位于、拥有等.知识由1个实体关系的三元组(triplets),即(头实体,关系,尾实体)来表示,它是知识图谱的基本单元.
诸如WordNet[2]等的大型知识图谱为存储、分析和利用海量的网页文本信息提供了崭新思路,支撑机器理解自然语言,被广泛应用于智慧搜索、自动问答等智能信息服务.然而,现有知识图谱虽已包含数以万计的事实知识实例,却仍无法满足现实世界的需要.补全现有的知识图谱以及构建新的知识图谱都是当前需要解决的关键问题.工程上构建知识图谱,往往有2种方式:自顶向下——先构建本体(通过本体编辑器);自底向上——直接从信息(结构化Freebase或半结构化Wikipedia)中抽取知识[3].本文所研究的知识三元组抽取属于自底向上来构建知识图谱.其基本思路是从非结构化文本中抽取实体关系实例,处理抽取出的知识三元组以符合知识库(1)本文不区分“知识图谱”和“知识库”2个概念,“知识图谱”本质是“知识库”的一种呈现方式.规范,然后将其添加到知识库中.具体而言,给定网页新闻文本“美国总统特朗普将访问史蒂夫保罗乔布斯创办的苹果公司”,知识三元组抽取技术可以自动抽取出(美国,国家—总统,特朗普)和(苹果公司,公司—创办者,史蒂夫保罗乔布斯)这2个三元组.其中,“国家—总统”和“公司—创办者”这2个关系属于预先定义好的关系标签[4].
现有的知识三元组抽取方法可以分为两大类:流水线式方法和联合抽取方法.其中,传统的流水线式方法先进行命名实体识别(Nadeau等人[5])然后进行关系分类(Rink等人[6]).但这种方法存在错误传播、信息冗余、忽视了2个子任务之间的联系等问题.而现有的联合抽取方法中,基于语法分析的方法依赖专家知识且工作量大,基于特征工程的方法依赖外部NLP工具且需要复杂的特征设计,基于神经网络的方法虽克服了以上问题却没有充分利用实体与关系之间的联系而做到真正的联合.
本文的研究针对现有方法存在的问题建立联合模型.首先提出一种标注策略,以往常用的方法如BILOU(Li和Ji[7];Miwa和Bansal[8])只对实体进行标注,没有将实体和关系进行关联,而本文提出的策略通过3段式的标注可以同时暗示分词的实体和关系属性,将联合抽取问题完全转化为端到端的序列标注问题.为实现输入文本的标注,本文搭建了基于长短时记忆网络LSTM的端到端模型框架,充分挖掘LSTM神经网络处理长序依赖问题的优势.编码层采用双向LSTM(bidirectional LSTM,Bi-LSTM)循环处理文本,充分考虑序列的上下文关联,可以对历史信息与未来信息进行平等处理,从而对长句更具有鲁棒性;解码层采用LSTM产生标签表示.在编码层与解码层之间,添加自注意力层为实体标签赋予更大的权重,同时对输入序列的远距离依赖关系建模,辅助模型对文本特征的综合性建模.此外,在端到端模型中,增加了1个带有偏置项的损失函数,该偏置项用于捕捉相关实体之间的联系.
尽管深度学习在很多计算机领域的任务上表现出色,Szegedy等人[9]发现深度神经网络存在的弱点,他们证明了对模型的输入做1个刻意的微小扰动就可能导致具有高置信度的错误决策,对模型的实际应用造成威胁.Goodfellow等人[10]提出了一种用于图像识别的对抗训练(adversarial training,AT)作为正则化方法,该方法将原样本与对抗样本混合输入模型,以增强模型的鲁棒性.本文尝试在模型训练时加入扰动作为对抗样本,将对抗样本和原有数据一起进行训练,产生正则化的效果,增强模型的鲁棒性,进而提高模型整体性能.
模型在远程监督产生的数据集NYT[11]上进行综合性的实验,实验结果表明本文的基于端到端标注的模型在诸多性能指标上优于现有的知识三元组抽取模型,从而验证了所提方法的有效性和优越性.
本文的主要贡献有3个方面:
1)设计了一种标注策略.通过模型标注输入序列得到分词标签,将标签组合能够直接得到三元组抽取结果.通过这种策略,知识三元组抽取问题能够被完全转化为端到端的序列标注问题,从而做到了真正的联合抽取.
2)搭建了基于LSTM的端到端框架用于输入文本的标注.采用双向LSTM编码、LSTM解码的架构处理文本,综合句子的上下文信息对句子进行标注,组合标注结果得到三元组信息.同时,在框架中增加自注意力层提高建模长文本的能力,并设计带偏置项的损失函数以充分利用相关联实体之间的联系.
3)引入对抗训练作为模型训练的拓展.通过在网络底层添加扰动生成对抗样本,与原样本混合训练模型以提高模型对输入扰动的鲁棒性.
1 相关工作
知识三元组抽取是从纯文本中得到三元组形式的知识.本文用S表示句子文本,将三元组表示为(h,r,t),其中,h表示头实体,t表示尾实体,而r表示h和t之间的关系[12].定义关系集合R={r1,r2,…},知识三元组抽取就是根据S和已定义的关系集合R,得到(h,r,t)的过程.知识三元组抽取的2个子任务是命名实体识别与关系分类,其研究有两大主流方法:流水线式方法、联合学习方法.
流水线式方法首先进行命名实体识别(named entity recognition,NER),然后基于所识别的命名实体进行实体之间的关系学习,即关系抽取(relation extraction,RE).传统的命名实体识别模型是基于统计的,如隐Markov模型(HMM)和条件随机场模型(CRF)(Passos 等人[13]和Luo等人[14]).最近,一些深度学习模型(Lample等人[15]和Xu等人[16])被应用到NER任务上,这些模型通常将实体识别任务视为对分词的序列标注任务.对于实体关系学习,现有方法可分为基于人工特征的方法(Hasegawa等人[17]和Kambhatla等人[18])和基于神经网络的方法(Xu等人[19-20]、Zheng等人[21]和Santos等人[22]).流水线式方法往往存在误差传播、实体对冗余和忽视2个子任务间联系等弊端.
为克服以上弊端,联合抽取方法被提出,它用1个模型同时抽取实体和关系.目前主流的联合模型分为基于语法分析的模型(Roth等人[23]、Kate等人[24]和Finkel等人[25])、基于特征工程的模型(Li,Ji[7]和Ren等人[26])和基于神经网络的模型.与前两种模型相比,基于神经网络的模型不依赖外部NLP工具,自动进行特征学习从而避免复杂的人工特征设计,不仅模型复杂度降低,抽取效果也有所提升.目前,基于神经网络的联合抽取方法主要分为基于参数共享的方法和基于标注策略的方法.Zheng等人[27]提出了混合神经网络模型(hybrid neural network,HNN),HNN模型通过共享神经网络的底层表示来进行联合学习.Miwa和Bansal[8]提出的SPTree模型也是类似的思想.但参数共享的方法本质上还是分别进行2个子任务,仍会产生不存在确切关系的实体对这样的冗余信息.针对此,Arzoo等人[28]提出了一种Gold standard标注方案,并利用多层双向循环网络(multi-layer Bi-RNN)进行知识三元组抽取.Zheng等人[29]则利用标注策略将抽取问题转化为序列标注任务,并设计了神经网络框架用于序列标注,取得了更优的效果.但是,与本文策略不同,上述标注策略只关注实体标注,忽视了实体与关系之间的关联,也就无法实现真正的实体关系联合抽取.
对抗训练.尽管在知识三元组抽取任务上神经网络表现出色,但Szegedy等人[9]发现其存在弱点.他们将刻意的微小扰动输入模型,导致模型产生了高置信度的错误决策.Goodfellow等人[10]将这个微小的扰动定义为对抗样本,并提出了对抗训练(AT)作为正则化方法.与其他正则化方法如dropout(Srivastava等人[30])产生随机噪声不同,AT产生的扰动是容易被模型误分类的样例的变种形式.最近对抗训练越来越多地被应用于自然语言处理(NLP)任务如文本分类(Miyato等人[31])、关系抽取(Wu等人[32])、POS标注(Yasunaga等人[33])等任务.在知识三元组抽取任务上,Bekoulis等人[34]曾将对抗训练加入到他们的联合学习模型中.实验表明,对抗训练的加入极大提升了模型的抽取效果.但本文是第1次将对抗训练用于端到端的序列标注模型.
2 方法描述
本节介绍提出的端到端知识三元组联合抽取的网络模型,整体结构如图1所示.模型包括5层,分别是表示层、双向LSTM编码层、自注意力层、LSTM解码层(也称LSTMd层)、softmax分类层.
端到端知识三元组联合抽取模型首先利用表示层将输入文本转换成句子序列的向量表示,然后通过双向LSTM编码层和自注意力层充分提取文本的上下文信息,之后上下文特征经过LSTM解码层产生标签的向量表示序列,最后softmax分类层根据向量对分词进行标签分类得到文本的标签序列.下面首先介绍本文采取的标注策略,接着阐述模型细节.
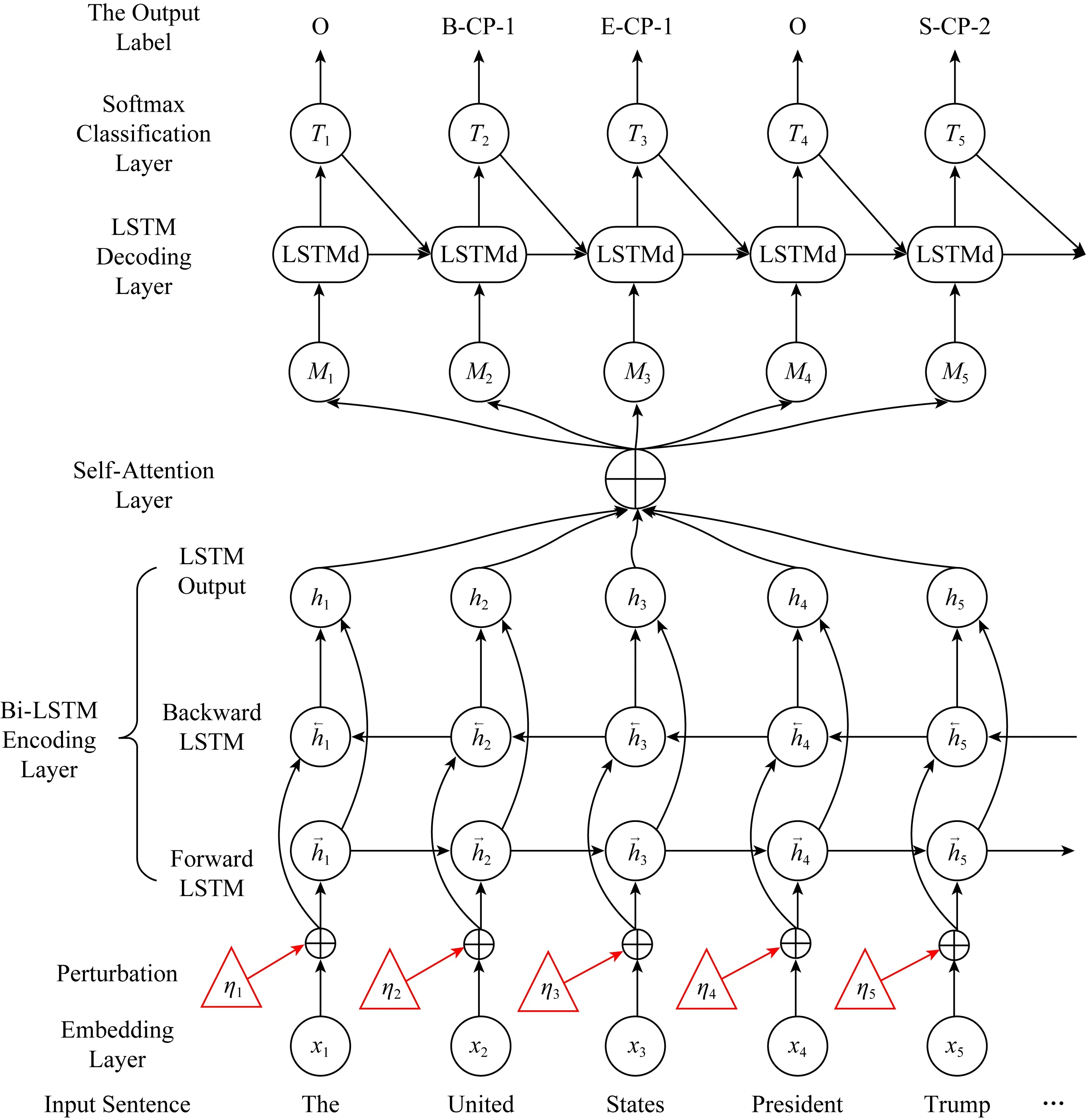
Fig.1 The structure of our end-to-end knowledge triplet extraction method combined with adversarial training图1 融合对抗训练的端到端知识三元组联合抽取模型结构图
2.1 标注策略
本节介绍标注策略以及如何通过标注策略将知识三元组抽取问题转化为序列标注问题.如图2展示了1个句子按照本文标注策略被标注的结果.
本文的每1个分词都被赋予1个标签,这些标签暗示此分词与要抽取的知识三元组的关系.
其中,标签“O”代表“其他(other)”,表示此分词与被抽取的结果无关,不是头/尾实体.除了标签“O”,其他的标签都由3个分标签(如B-CP-2)组成,接下来分别对3个分标签进行说明:
1)分词在实体中的位置.本文考虑实体由1个或1个以上分词构成,使用“BIES”(开头,内部,结尾,单独)标签方案来表示1个分词在实体中的位置信息.其中“B”即“开始(begin)”,表示此分词是实体成分且位于实体的开头位置;“I”即“内部(inside)”,表示此分词位于实体内部;“E”即“结尾(end)”,表示分词位于实体结尾;“S”即“单独(single)”,表示此分词单独就是1个实体指称.

Fig.2 Annotation of sample sentence based on our annotation strategy图2 基于标注策略对样句的标注
2)关系类型.分词构成的实体所属的关系类型信息是预先定义好的.本文做实验时使用NYT数据集[11],数据集中关系集[4]是预定义的.
3)关系角色.分词在关系中的角色信息由2个数字“1”和“2”表示.其中,“1”表示该分词在此关系类型中属于关系的头实体,“2”则表示尾实体.
抽取结果由三元组(实体1,关系类型,实体2)表示,“1”表示此实体是三元组的头实体,“2”是尾实体.因此总标签数是Nt=2×4×|R|+1,其中,|R|是预定义关系集规模.
图2是1个展示了本文标记策略的例子.输入句包含三元组:(United States,Country-President,Franklin Delano Roosevelt),其中“Country-President”是预定义的关系类型.分词“United”,“States”,“Franklin”,“Delano”,“Roosevelt”都与最终的抽取结果相关,因此它们都基于特殊的标记策略来标记.例如,词“United”是与关系“Country-President”相关的头实体“United States”的第1个词,因此被标记为“B-CP-1”.与最终抽取结果无关的词都被标记为“O”.
与现有较常见的标注策略BILOU(Li和Ji[7];Miwa和Bansal[8])不同,本文提出的三段式标签同时指示分词所属的实体属性以及关系类型,在通过标注模型标注文本得到标签后,将有相同关系类型的2个实体标签与关系类型结合成1个三元组,再根据关系角色标签可知实体的位置(头或者尾),从而可以得到抽取结果.通过上述步骤,知识三元组抽取问题能够完全被转化为端到端的序列标注问题.
需要强调的是,如果1个句子包含2个或者多个具有相同关系类型的三元组,本文按照最邻近原则将每2个实体结合,构成1个三元组.同时,本文仅考虑1个实体属于1个三元组的情况.
下面讲解模型如何实现上述标注.
2.2 表示层
表示层的输入是原始句子序列,通过词向量表将其转换成表示句子信息的低维向量输入到下一层.

(1)
将S输出到下一层作为输入.
2.3 双向LSTM编码层
双向LSTM编码层由2个平行的LSTM层组成,即前向LSTM层和反向LSTM层.每层都是由1系列循环连接的子神经网络组成,称为神经元,对应每个时间步长.双向LSTM中前向网络的神经元结构如图3所示:
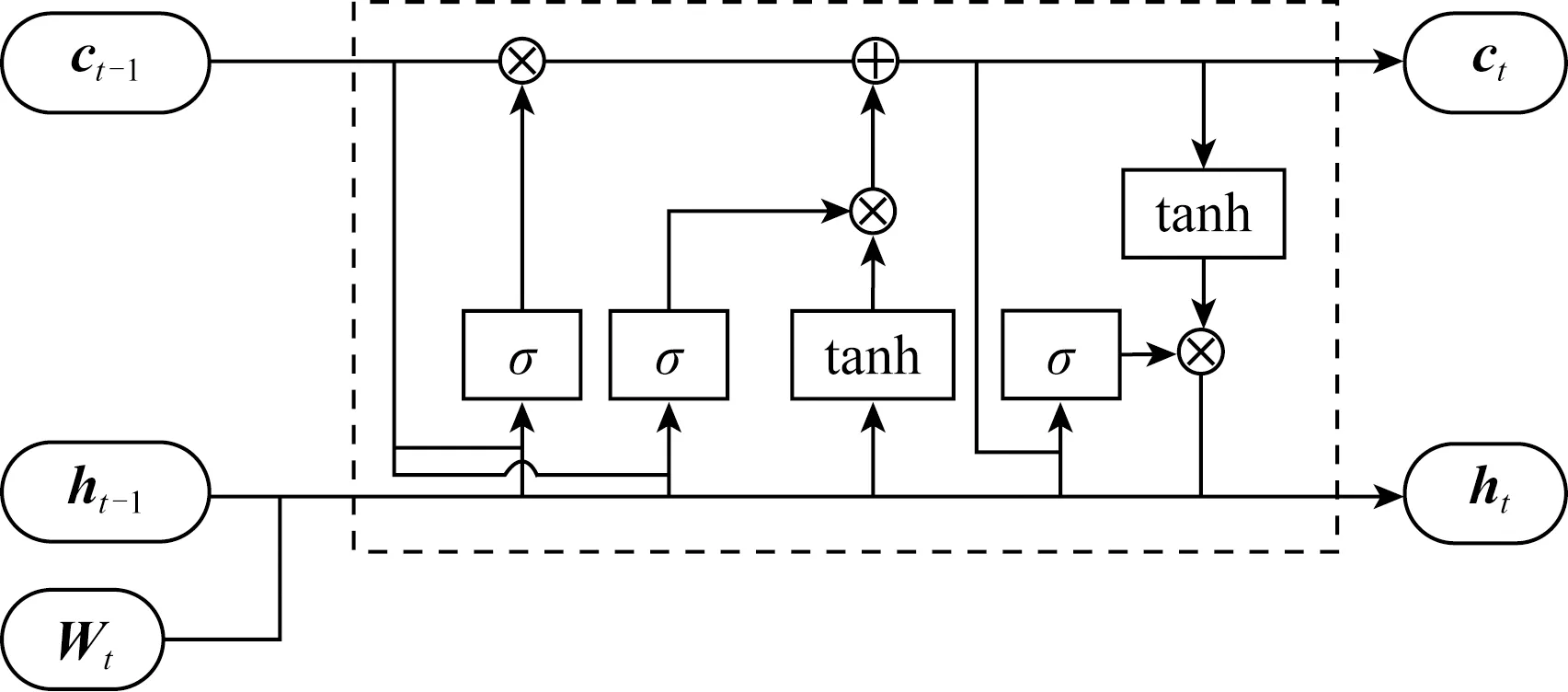
Fig.3 The structure of forward LSTM neuron图3 前向LSTM神经元结构图
LSTM通过遗忘门、输入门和输出门来对输入信息进行保护和控制.前向网络中,每次新输入1个分词特征向量xt,并与上一时刻状态ht-1共同产生下一时刻的状态ht,其中t代表时间步长.隐藏状态ht的计算:
it=δ(Wxixt+Whiht-1+Wcict-1+bi),
(2)
ft=δ(Wxfxt+Whfht-1+Wcfct-1+bf),
(3)
zt=tanh(Wxcxt+Whcht-1+bc),
(4)
ct=ftct-1+itzt,
(5)
ot=δ(Wxoxt+Whoht-1+Wcoct+bo),
(6)
ht=ottanh(ct),
(7)
其中,i,f,o分别为输入门、遗忘门、输出门,b是偏置项,W(·)为参数矩阵.
前向LSTM层通过从分词向量x1到xt考虑xt的前文信息来编码xt,输出记为ht.类似地,反向LSTM层从分词向量xn到xt考虑xt的后文信息来编码xt,输出记为ht.最后,联结ht和ht来表示第t个分词编码后的信息,表示为
(8)
其中,⊕表示向量联结,de为单向LSTM网络维度.对于输入的S,该层的输出为
(9)
将h输出到下一层作为输入.
2.4 自注意力层
双向LSTM神经网络,由于信息传递的容量以及梯度消失问题,只能够建模输入信息的局部依赖关系.为了能够增强模型建模长句的能力,本文增加自注意力层进一步编码输入文本.自注意力机制能够减少模型对外部信息的依赖,有助于捕捉文本内部信息的相互关联.
f(h)=tanh(hWa1hT+ba1),
(10)
A=softmax(f(h)),
(11)
(12)
其中,Wa1为权重矩阵,ba1为偏置项,f(h)表示输入文本各个分词之间的相关性分数,A代表分词之间的注意力权重,M则是输入文本的综合编码向量集合.接着将M输入解码层进行标签解码.
2.5 LSTM解码层
得到综合编码了上下文信息的序列后,本文也采用LSTM结构来产生标签序列,称为解码.解码层采用1个单向的LSTM层,称为LSTMd层,其结构如图4所示.
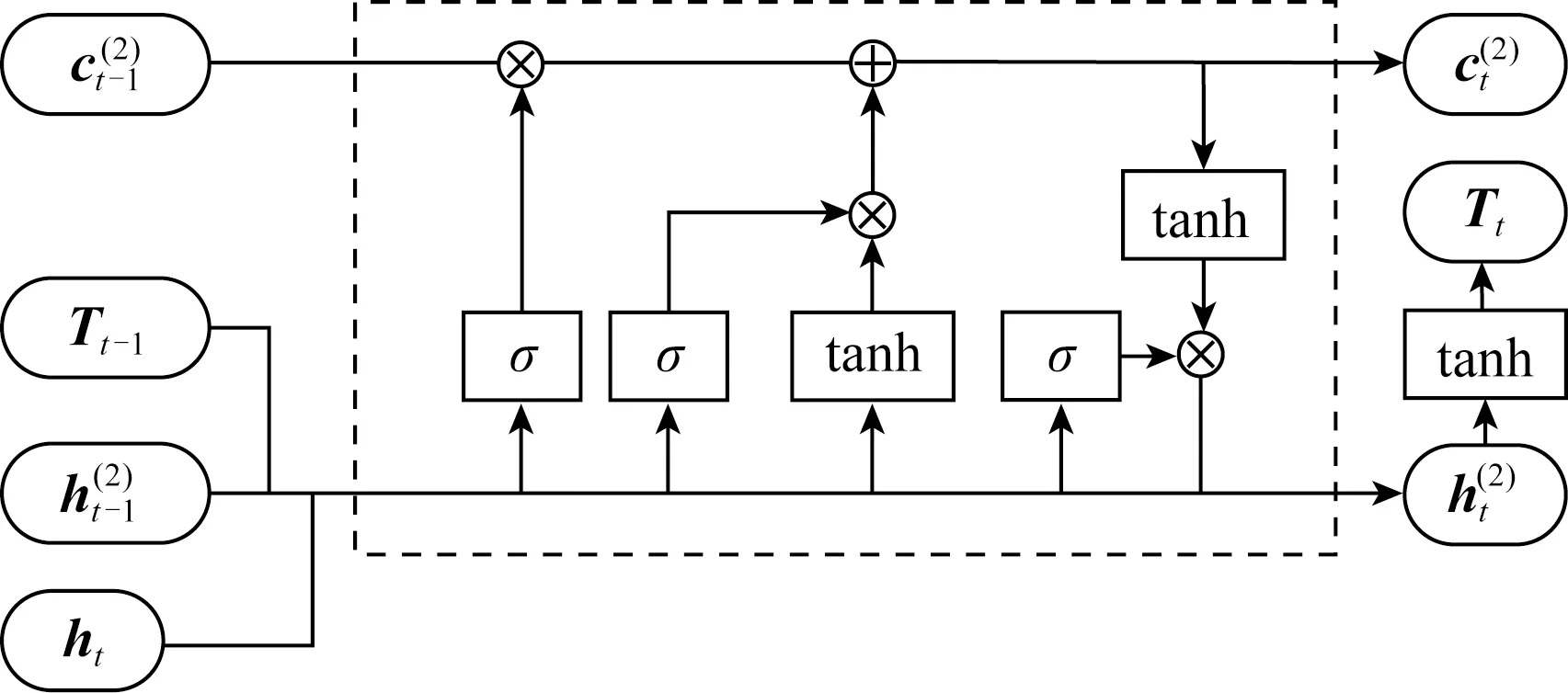
Fig.4 The structure of LSTMd neuron图4 LSTMd层神经元结构图
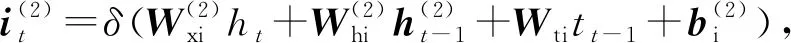
(13)
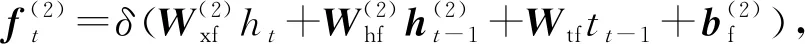
(14)
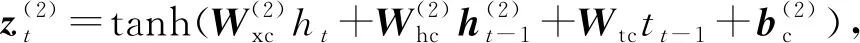
(15)
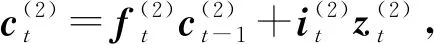
(16)
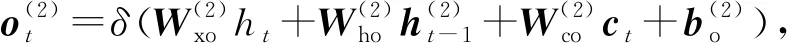
(17)
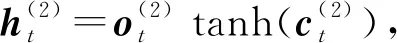
(18)
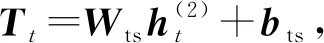
(19)
其中,i,f,o分别为输入门、遗忘门、输出门,b是偏置项,W(·)均为参数矩阵.
对于输入的M,该层的输出为预测标签的向量序列
(20)
其中,dd为LSTMd网络维度.
2.6 softmax分类层
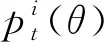
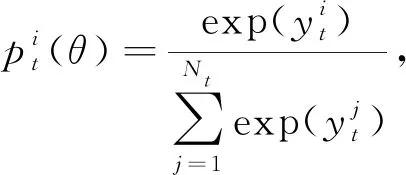
(21)
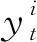
yt=WyTt+by,
(22)
在测试阶段,所学习到的标签特征Tt乘以概率p得到Tt=pTt,用Tt进行标签预测.
最终,得到分词t具有标签:
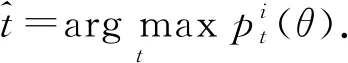
(23)
训练时,本文最大化对数似然函数:
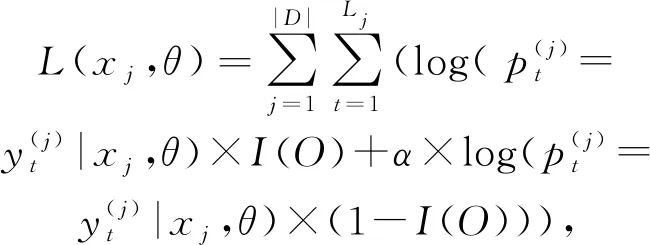
(24)
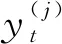
I(O)是1个门,用于区别“O”标签和其他标签的损失函数
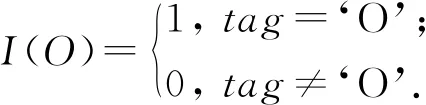
(25)
α为损失函数的偏置权重,偏置权重越大,关系标签对模型的影响越大,即模型将具有确定关系的实体对进行组合的能力越强,从而充分利用相关联实体之间的联系.
2.7 对抗训练
在模型训练时,本文融合了对抗训练(AT)的思想.在这里,对抗训练用作一种正则化方法,使模型对输入扰动更具有鲁棒性.
AT首先要生成对抗样本,本文通过将扰动ηAT添加到初始句子表示x来生成对抗样本.通过最小化对数似然函数,可以生成最差情况下的扰动ηAT:
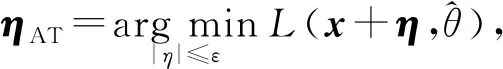
(26)

ηAT=εg/‖g‖,
(27)

(28)
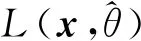
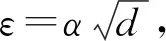
(29)
其中,d为输入表示的维度.
进行对抗训练时,将对抗样本和原样本混合.因此,最终要最大化的似然函数为

(30)
本文3.3节将对以上自注意力机制、偏置项、对抗训练3个部分进行消融分析以量化说明各个部分在模型构建中的作用.
3 实 验
本节介绍融合对抗训练的端到端知识三元组联合抽取方法的先进性实验验证.
3.1 实验准备与实验背景
实验使用Riedel等人[11]基于远程监督的假设构造的NYT数据集(3)数据集可下载于:https://github.com/shanzhenren/CoType.有3个公共数据集可以选择,本文选择使用NYT数据集.本文使用的数据集的细节见Ren等人[26]的文章.,数据集划分为训练集和测试集两部分.训练集包含353×103个三元组,通过远程监督方法获得;测试集包含3 880个三元组,通过人工标注获得.数据集的关系集合中定义了24个关系,其中包括1个特殊关系“None”,表示2实体间不存在关系.对关系在集合中的顺序依次编号,其中,“None”的编号为0,其余的关系编号为1~23.
在训练好的向量词典中,有114 042个词向量,囊括了NYT数据集中的所有词汇.词典中还包含一些特殊的分词,例如:“〈**END**〉”,“〈UNK〉”,“.”和“,”等.〈**END**〉表示句子结束的符号,〈UNK〉表示未识别出的词,“.”和“,”等是句子中常用的标点符号.
参考目前联合抽取模型的评价指标,对模型抽取出的整个知识三元组结果进行评价,本文实验使用准确率(Precision,P)、召回率(Recall,R)和F1值(F1)三个指标,F1是综合性的评价指标.
模型需要设置的所有超参数如下.n为输入网络的最大句长,设置为50,若句子长度不够,则使用空字符填充;本文使用Word2Vec算法训练词向量,词向量维度设为dw=300;每进行1次训练或测试,输入的句子集合数量为50;LSTM编码层的神经元数量设置为300,即该层维度de=300;LSTM解码层维度dd=600;本文采用随机梯度下降法迭代更新模型参数,直至模型参数稳定,学习率控制模型参数更新的速度,本文中设为η=0.001.
另外,模型引入偏置参数α来增强实体之间的联系.本文通过实验确定参数α,α∈{1,5,10,15,20}.将除α参数外的其余超参数调整至最优,调整参数α的值,模型准确率、召回率以及F1值的变化如图5所示.当α过大,会影响预测准确率;α过小则召回率会降低.当α=10时,模型能够获得准确率和召回率之间的平衡,从而得到最高的F1值.因此设置超参数α=10.
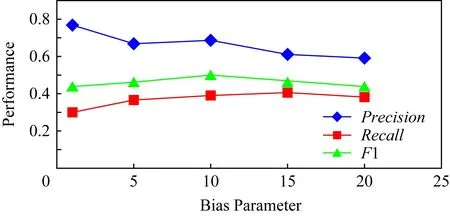
Fig.5 The results predicted by our model on different bias parameter α图5 调整偏置参数α时的模型预测结果
3.2 与其他三元组抽取方法的比较
其他典型的三元组抽取模型可以分为两大类:流水线方法和联合抽取方法.
对于流水线方法,本文遵循了Ren等人[26]的设置,即通过CoType进行命名实体识别,获得实体;然后应用了3种典型的关系分类方法来检测实体间关系:
1)DS-logistic是Mintz等人[36]提出的一种基于特征的远程监督的方法,它同时结合有监督IE特征和无监督IE特征的优势;
2)LINE是Tang等人[37]提出的一种基于网络表示的关系抽取方法,可被用于任何类型的信息网络;
3)FCM是Gormley等人[38]提出的将词汇化语言上下文和词向量结合用于关系抽取的复合模型.
对于联合抽取方法,本文将模型与其他3种典型的联合抽取方法进行比较:
1)DS-Joint是Li和Ji[7]提出的监督学习方法.它使用结构化感知器联合抽取人工标注的数据语料上的实体和关系;
2)MultiR是Hoffmann等人[39]提出的远程监督方法,它基于多实例学习算法,可以应对嘈杂的训练数据;
3)CoType是Ren等人[26]提出的通过将实体、关系、文本特征和类型标签进行联合表示来构建域独立的框架.
为进一步说明本文端到端模型的优势,将3种典型的但未被用于端到端的实体关系联合抽取模型,应用在本文所提标注策略上,进行三元组抽取任务.这3种端到端模型分别为:
1)LSTM-CRF是Lample等人[15]提出的通过使用双向LSTM编码输入语句,CRF预测实体标签序列进行命名实体识别的框架;
2)LSTM-LSTM是Vaswani等人[40]提出,与LSTM-CRF不同,它使用LSTM层来解码标签序列而不是CRF;
3)LSTM-LSTM-Bias是Zheng等人[29]所提出,在LSTM-LSTM的基础上,使用了带偏置项的损失函数.
表1展示了不同模型在知识三元组抽取任务上的表现.其中,行1~3是流水线式模型;行4~6是联合抽取模型;基于本文标注策略的端到端模型在行7~10,在这个部分不仅计算了准确率、召回率和F1值,还分别计算了它们的标准差.分析表中数据可以得到3个结论:
1)本文的模型LSTM-LSTM-2AT-Bias在联合抽取任务上的F1值为0.521±0.006,优于其他较先进的模型在此任务上的表现.并且,它相较于之前效果最优的模型CoType(Ren等人[26]),F1值有5.8%的提升,这也表明了本文所提方法的有效性.此外,从表1中还可以看出在三元组抽取任务上,联合抽取方法优于流水线式方法,而基于本文标注策略的方法优于大多数联合抽取方法.这也证实了本文提出的标注策略应用于联合抽取知识三元组任务的有效性.
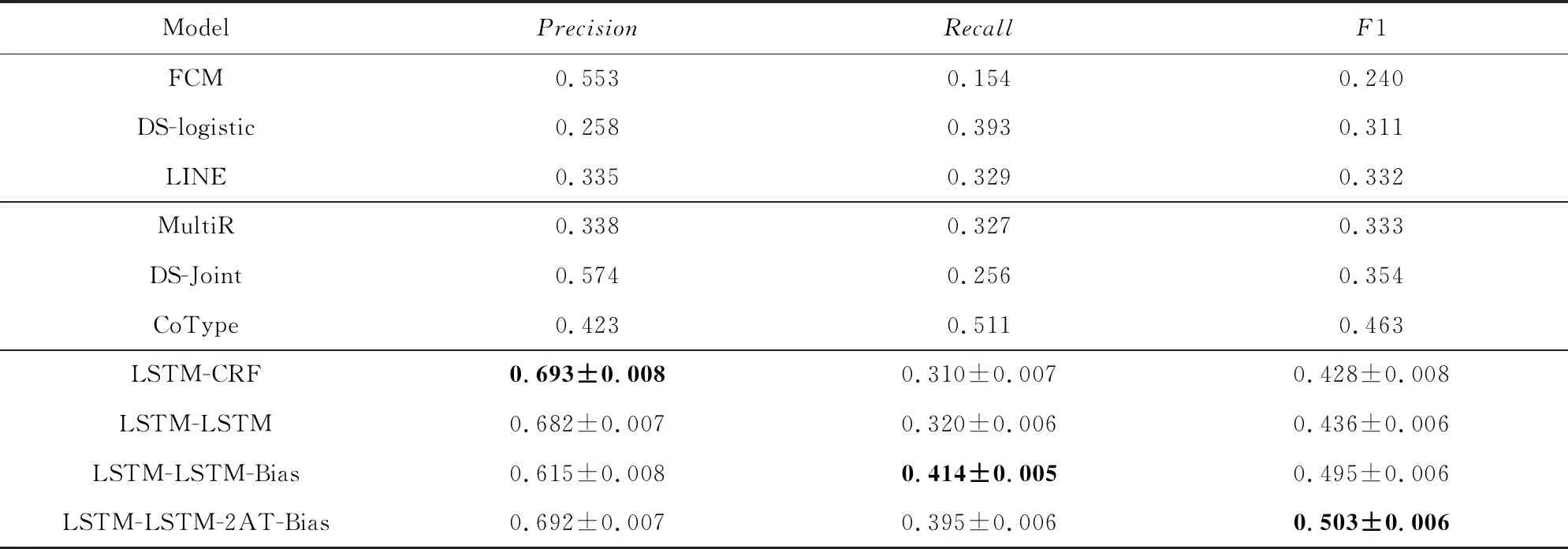
Table 1 The Predicted Results of Different Methods on Extracting Both Entities and Their Relations表1 不同模型在知识三元组抽取任务上的结果
Note:The bold numbers represent the highest performance among all models.
2)从准确率数据可以看出,与传统方法(流水线方法和传统联合抽取方法)相比,端到端模型的准确率有了显著提升.原因可能是端到端模型均使用双向LSTM来编码输入文本,提升了对文本的处理与表示能力,然后使用不同的神经网络来解码得到结果.然而,在所有端到端模型中,只有LSTM-LSTM-2AT-Bias能获得更高的准确率和召回率,得到最高的F1值.这说明其采取的添加自注意力层的网络架构对数据的适应性较好,能够很好地学习训练集的特征表示,采取对抗训练能够获得更高的准确率,最终获得了总体的F1值提升.
3)基于本文提出的标注方案,LSTM-LSTM模型比LSTM-CRF模型在三元组抽取任务上表现更好.分析原因,LSTM神经网络能够学习长距离依赖而CRF擅长捕捉整个标签序列的联合概率.而输入文本中,相关的实体标签互相之间可能距离很长.因此,LSTM解码方式比CRF更优.通过与LSTM-LSTM模型的比较,LSTM-LSTM-Bias模型通过增加1个偏置权重可以加强实体标签的影响权重,减弱无关标签的影响权重,更有利于区分出实体标签.
3.3 消融学习
在本文模型中,核心部分是基于LSTM的编码解码层,加入了自注意力层和对抗训练,并且在目标函数中添加了偏置项.为保证这些辅助部分加入模型的必要性,将进行这些部分的消融学习,观察其对模型抽取效果的改善作用.
原模型(LSTM-LSTM-2AT-Bias).原模型通过双向LSTM编码、LSTM解码实现对文本的端到端标注;使用带偏置项(Bias)的目标函数增加模型对相关联实体的注意力;加入自注意力层(self-atten-tion)提高模型建模文本信息的能力;采用对抗训练(AT)增强模型对输入扰动的鲁棒性,因此模型简写为LSTM-LSTM-2AT-Bias,2AT代表自注意力机制和对抗训练.
变种1.LSTM-LSTM-2AT.与很多现有端到端模型不同,针对知识三元组抽取任务,本文的模型额外在目标函数中添加了偏置权重,使得模型能够更好地组合相关实体构成三元组,是模型中很重要的一部分.变种1将Bias偏置项去掉,观察模型性能的变化,因此变种1简写为LSTM-LSTM-2AT.
变种2.LSTM-LSTM-ATT-Bias.对抗训练在Bekoulis等人[34]的文章中被用来在BiLSTM-CRF框架上进行联合抽取任务,实验证明,加入对抗训练使得模型在3个普遍使用的数据集上的抽取效果较现有模型均有一定幅度的提升.本文将对抗训练迁移至设计的特定目标函数上,为验证对抗训练在本文模型中的作用,变种2不采用对抗训练,简写为LSTM-LSTM-ATT-Bias.
变种3.LSTM-LSTM-AT-Bias.自注意力机制在Tan等人[41]的文章中被应用到了序列标注任务中,将自注意力层嵌入到神经网络框架,实验证明,加入自注意力机制提升了模型学习文本语义的能力,使得标注结果更好.本文在编码文本序列后加入自注意力层充分表示文本,为验证自注意力层在本文模型中的作用,变种3将自注意力层去掉与原模型比较,因此变种3简写为LSTM-LSTM-AT-Bias.
上述4个模型的超参数以及实验数据集均按照3.1节中的设定,使用的词向量编码也均相同.
表2展示了本文模型与3个变种在本文任务上的抽取结果.从实验结果看,本文模型的F1值比3个变种的F1值分别高出了2.6%,1.7%和1.2%,说明每一部分的加入都对模型性能的提升有所贡献.
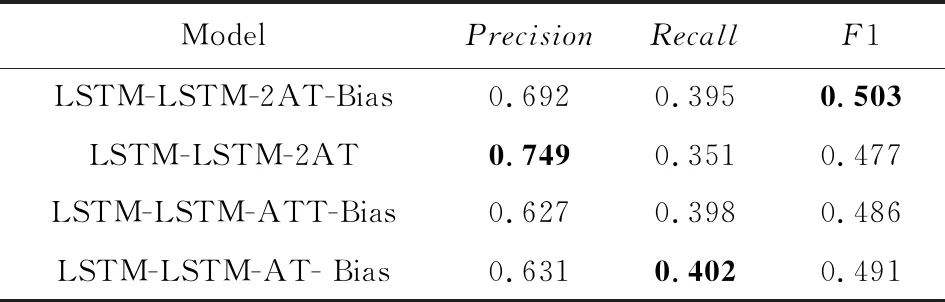
Table 2 The Predicted Results of our Model and Its Variants on the Knowledge Triplet Extraction Task表2 原模型与各变种在知识三元组抽取任务上的结果
Note:The bold numbers represent the highest performance among all models.
对于变种1,删除了偏置项,该变种在4个模型中表现最差,说明在3个部分中偏置项对该模型的性能提升最大.偏置项通过影响模型的目标函数,使其对关系标签更加敏感,提升了模型组合相关联实体的能力.因此删除偏置项后,模型准确率虽有提升,但召回率和总体F1值均大为降低.
对于变种2,去掉了对抗训练,该变种使模型F1值降低了1.7%,影响也非常大.原因是原始输入集合中本身就存在一些影响模型效果的扰动,对抗训练以及对抗样本的加入使得模型对输入扰动的分辨能力提升.因此删除对抗训练后,模型准确率降低,虽然召回率略有提升,但总体F1值也降低.
对于变种3,由于缺少自注意力层,模型对输入文本的表示能力下降,一定程度上影响了模型性能.自注意力机制能帮助模型有效地捕获有重要作用的分词(在本任务中即为被标记为实体标签的分词),能够提升模型标记的准确率.因此删除自注意力层后,模型准确率降低,虽然召回率有提升,但总体F1值仍下降.
对于本文模型而言,偏置项的加入作用大于对抗训练的加入,大于自注意力机制的加入,但三者对模型在知识三元组抽取任务上F1值的提升都有较大贡献,因此这些部分的加入是必要的.
3.4 知识三元组抽取结果的误差分析
本文要解决的任务是抽取由2个实体和它们之间的1个关系组成的知识三元组.表3展示了此任务上各种模型的抽取结果.在判断三元组抽取结果正确与否时,只有当2个实体和对应关系类型均正确的三元组才被认定为正确.

Table 3 The Predicted Results of Triplet’s Elements Based on Our Tagging Scheme表3 不同端到端模型基于本文标注策略对三元组元素的预测结果
Note:The bold numbers represent the highest performance among all models.
为了找出影响端到端模型表现效果的因素,本节分析了端到端模型对三元组所含元素的抽取表现,表3展示了结果.E1和E2分别代表模型抽取的第1、第2个实体实例,(E1,E2)则表示实体对实例.
从表3可以看出,与元素E1和E2相比,模型对(E1,E2)实体对抽取的准确率更高,但召回率略有降低,这意味着一些抽取出的实体没有组成实体对.原因可能是模型只抽取出了实体E1或E2而没有找出其对应的实体E2或E1,因此导致抽取出较多单实体E和较少实体对(E1,E2).实体对因此比单实体准确率更高而召回率更低.
另外,表3中实体对(E1,E2)的抽取结果相比表1,LSTM-LSTM-2AT-Bias的三元组抽取结果有了2.7%的F1值提升,这也意味着抽取结果中有部分三元组是因为关系类型分类错误而导致被错误抽取.
3.5 对知识三元组抽取实例的分析
通过上述实验及分析,发现本文模型针对知识三元组抽取问题具有更好的性能.接着,本节观察了几种端到端模型对三元组的抽取结果,然后挑选了3个代表性的例句来进一步说明模型优缺点,如表4所示.
表4中,黑体字为正确输出结果,下划线标记出的是模型抽取错误的结果.句中实体的下标表示实体角色(头实体/尾实体)以及实体构成三元组所属的关系,例如例句S1抽取出三元组(New York City,contain,Brooklyn),其中“[New York City]E1Contain”表明“New York City”属于三元组中头实体,且三元组关系类型为“Contain”.例句S3中E1CF则是E1Company-Founder的缩写.
观察分析表4中的例句以及抽取结果:
例句S1的抽取结果是本文模型的正例,同时它也代表一种源文本类型:文本中的2个相关实体彼此之间相距较远,从而增大了检测它们之间关系的难度.从抽取结果看,LSTM-LSTM-Bias与LSTM-LSTM-2AT-Bias模型均正确抽取出了结果,而LSTM-LSTM模型则因实体间距离过长,未能关联起相关实体,仅仅抽取出了1个实体“New York City”,未能检测出“Brooklyn”.这反映了本文模型增加偏置目标函数的有效性.
例句S2的抽取结果是另一个正例,它代表另一种情况:文本中存在多个扰动实体,加大模型分辨组合实体对的难度.例句中,实体“Silicon Valley”和“USA”之间并没有指示性词暗示2个实体的关系.另外,实体“USA”和“industry”的模式“the*of*”很容易误导模型,使之认为2个实体之间存在关系“Contain”,导致模型LSTM-LSTM与LSTM-LSTM-Bias均抽取错误;而本文的模型由于加入了对抗训练,使其能够分辨这种模式,从而抽取正确.
例句S3的抽取结果是1个负例,它代表一种情况:模型能够正确抽取出实体,但实体的关系角色预测错误.LSTM-LSTM和LSTM-LSTM-Bias模型抽取出实体“Jerry Moss”和“A&M Records”均为头实体E1,未能抽取出对应的尾实体E2.而LSTM-LSTM-2AT-Bias模型能够发现实体对(E1,E2)存在,但实体“Jerry Moss”和“A&M Records”的实体角色被抽取反了.与LSTM-LSTM-Bias相比,本文模型由于加入了注意力机制,对文本语义把握更充分,检测出相关联实体对的能力更强,但在区分两实体具体关系上有待提升.
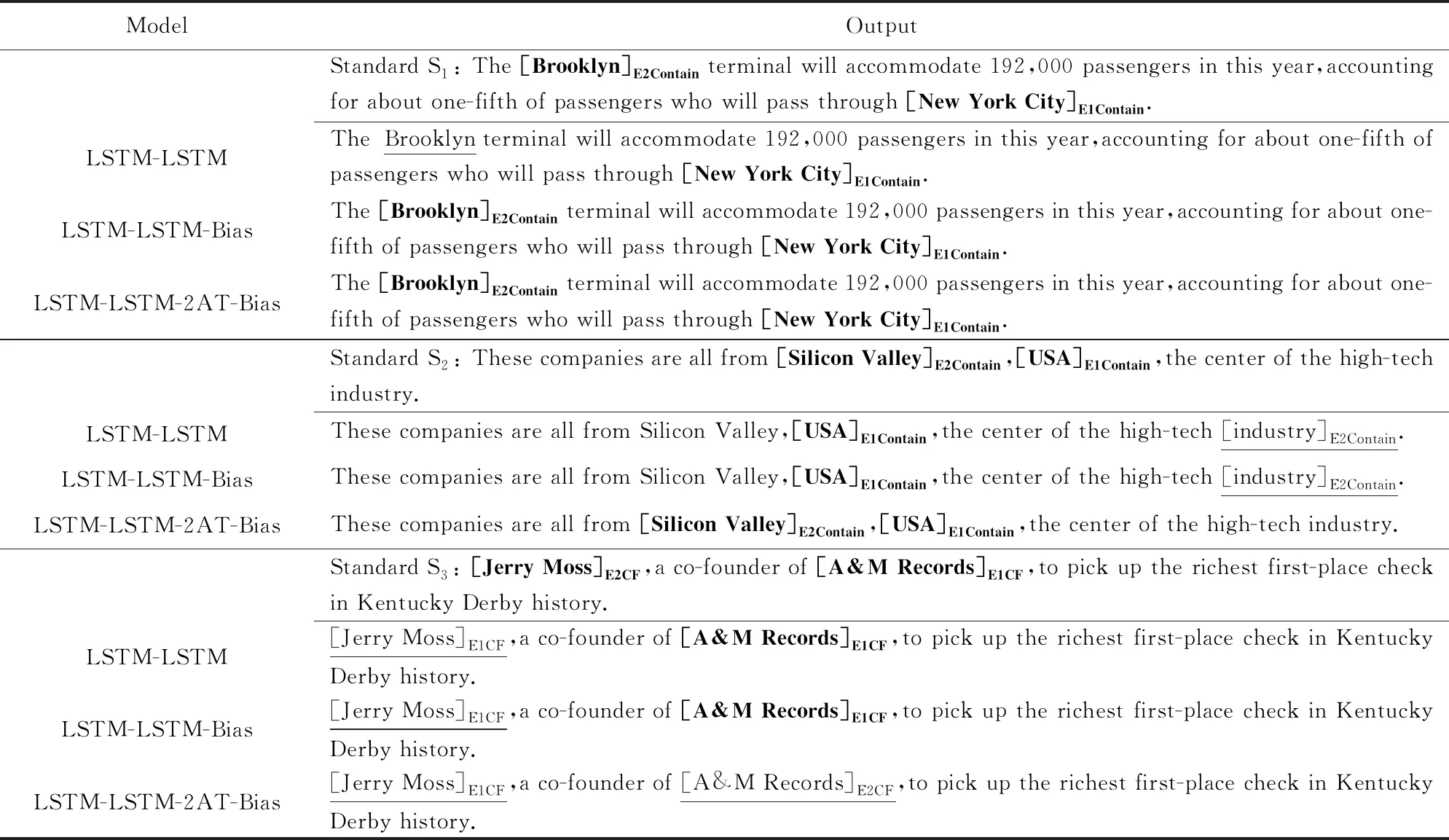
Table 4 Output from Different Models表4 不同端到端模型的输出结果
Note:Standard Sirepresents the gold standard annotation of sentencei.The bold parts are the correct outputs,and the underlined parts are the wrong outputs.
4 结论和进一步工作
本文主要提出了一种融合对抗训练的端到端知识三元组联合抽取方法.传统的流水线式抽取方法会导致误差传递,而现有的联合抽取没有充分发掘实体识别与关系抽取2个子任务的联系.针对现有方法的问题,本文模型提出一种标注策略,能够通过端到端标注将知识三元组抽取问题完全转化为序列标注问题;然后设计了端到端的标注网络,并加入自注意力层来充分表示文本,通过带偏置项的损失函数提高模型组合实体对的能力,加入对抗训练以增强模型鲁棒性.为验证方法有效性,在普遍使用的数据集上将模型与目前较先进的模型以及一些变种在知识三元组抽取任务上的效果进行对比,结果表明本文模型取得最优性能;然后进行消融分析,证实了模型各个部分的必要性;之后进行了误差分析,最后通过实例说明模型优缺点.
下一步,计划对所提方法以及模型进行进一步改进,寻求模型的性能提升.注意到模型最后1层采用softmax进行单分类,1个词只能有1个标签.可考虑用多分类器替换softmax,1个词可以有多个标签,能够出现在多个三元组中从而使模型能够识别重叠关系.
