基于气相色谱技术分析滩羊肉风味物质的研究
——飞行时间质谱联用
2019-12-11马小明12
马小明12
1.甘肃农业大学动物科学技术学院 甘肃兰州 730070 2.宁夏农林科学院动物科学研究所 宁夏银川 750002
滩羊是宁夏自治区发展羊产业的主要羊品种之一,也是宁夏农业战略主导产业和优质牛羊肉产业发展中的重要品种资源。宁夏回族自治区滩羊这一品种优势明显,品牌美誉度较高,具有形成地缘优势农产品的基础条件,产品市场竞争潜力较大。滩羊以宁夏自治区为中心产区,具有鲜明的地域分布特色,近年来在自治区农业特色优势产业政策扶持下,滩羊产业提质扩量成效显著,“盐池滩羊”及“盐池滩羊肉”商标品牌价值凸显,滩羊胴体精细化分割加工工艺及产品日趋成熟,以滩羊为重要支柱的优质牛羊肉产业已成为宁夏回族自治区农业战略主导产业。不断发掘滩羊及滩羊肉的优势,做精、做强宁夏羊产业,对增加农民收入、助力精准扶贫工作也具有十分重要的意义。
滩羊公羊肉质较膻,导致大多数人不喜食用。针对滩羊、羯羊肉香味美等特点,开展相关研究,以期探究滩羊公羊与羯羊差异代谢物的种类和物质,助力滩羊产业发展[1]。
1 材料与方法
1.1 材料
选择盐池县农户饲养的成年滩羊羯羊、公羊各3只,共6只组织样本。并于早晨空腹屠宰后采集背最长肌100g,切成肉丁,分别装入玻璃瓶中密封并贴标,然后冷冻保存,待测。
1.2 试验方法
将样本低温研碎,称取样本2.5g于20mL顶空瓶中,再加入1μL 2-辛醇为内标;随机顺序GC-MS检测。
1.3 实验试剂
2-辛醇(2-Octanol),6169-06-8,≥99.5%,TCI。
1.4 试验仪器
气相色谱,型号 7890A,Agilent;
质谱仪,型号5975C,Agilent;
色谱柱,型号DB-Wax(30m×250μm×0.25μm),Agilent。
1.5 上机检测
Agilent 7890气相色谱-质谱联用仪配有Agilent DB-Wax毛细管柱(30m×250μm×0.25μm,J&W Scientific,Folsom,CA,USA),GC-MS具体分析条件如下。
萃取温度(Incubate Temperature),65℃;
预热时间(Preheat Time),20min;
萃取时间(Incubate Time),40min;
解析时间(Desorption time),4min;
分流模式(Front Inlet Mode),Splitless Mode;
隔垫吹扫流速(Front Inlet Septum Purge Flow),3mL/min;
载气(Carrier Gas),Helium;
色谱柱(Column),DB-Wax(30m×250μm×0.25μm);
柱流速(Column Flow),1mL/min;
柱箱升温程序(Oven Temperature Ramp),40℃ hold on 5min, raised to 250℃ at a rate of 5℃/min, hold on 5min;
前进样口温度(Front Injection Temperature),260℃;
传输线温度(Transfer Line Temperature),260℃;
离子源温度(Ion Source Temperature),230℃;
四级杆温度(Quad Temperature),150℃;
电离电压(Electron Energy),-70eV;
质量范围(Mass Range),m/z 20~500;
扫描模式(Scan Mode),Scan;
溶剂延迟(Solvent Delay),0min。
1.6 数据处理
使用Chroma TOF软件(V4.3x,LECO)和NIST数据库对质谱数据进行了峰提取、基线矫正、解卷积、峰积分、峰对齐、质谱匹配等分析[2]。
2 试验结果
本次实验中共检出了108个峰,详见图1。
3 数据分析
3.1 原始数据预处理
原始数据包含0个质控(quality control,QC)样本和6个实验样本,从中提取108个Peak,为了更好地分析数据,我们对原始数据进行一系列的准备和整理(data management)。主要包括以下步骤:对单个Peak进行过滤以便能去除噪音。基于四分位数距(interquartile range)对偏离值进行过滤。对单个Peak进行过滤。只保留单组空值不多于50%或所有组中空值不多于50%的峰面积数据。对原始数据中的缺失值进行模拟(missing value recoding)。数值模拟方法为最小值二分之一法进行填补。数据标准化处理(normalization)。利用内标(internal standard,IS)进行归一化。经过预处理后107个Peak被保留。
3.2 主成分分析(PCA)
在获得整理好的数据之后,我们对其进行一系列的多元变量模式识别分析,首先是主成分分析。主成分分析(principalcomponent analysis, PCA)是将一组观测的可能相关变量,通过正交变换转换为线性不相关变量(即主成分)的统计方法。
PCA可以揭示数据的内部结构,从而更好的解释数据变量。代谢组数据可以被认为是一个多元数据集,能够在一个高维数据空间坐标系中被显现出来,那么PCA就能够提供一幅比较低维度的图像(二维或三维),展示即为在包含信息最多的点上对原对象的“投影”,有效地利用少量的主成分使得数据的维度降低[2~7]。
使用SIMCA软件(V14.1,Sartorius Stedim Data Analytics AB, Umea,Sweden),对数据进行对数(LOG)转换加中心化(CTR)格式化处理,然后进行自动建模分析。PCA模型的相关参数见表1“PCA模型参数表”。

表1 PCA模型参数表
表1内各列内容解释如下。
Model:SIMCA软件建模的模型编号,该编号会对应到结果文件。
Type:SIMCA的模型类型,PCA-X表示对样本建立PCA模型。
A:模型的主成分个数。
N:模型的观测个数(此处即为样本数)。
R X(cum):代表模型对X变量的解释性。
Title:该模型对应的数据对象。
全部样本的PCA得分散点图(score scatter plot)如图2所示。
图2中横坐标PC[1]和纵坐标PC[2]分别表示排名第一和第二的主成分的得分,散点颜色和形状表示样本的实验分组。样本全部处于95%置信区间(Hotelling’s T-squared ellipse)内。样本间的对比分析以Class2组对Class1组为例:Class2组对Class1组的PCA得分散点图如图3所示。
从PCA得分图3的结果可以看出,样本全部处于95%置信区间(Hotelling’s T-squared ellipse)内。
交叉验证后得到的R Y(模型对分类变量Y的可解释性)和Q(模型的可预测性)对模型有效性进行评判;最后通过置换检验(permutation test),随机多次改变分类变量Y的排列顺序得到不同的随机Q 值,对模型有效性做进一步的检验。各组对比OPLS-DA模型的模型累积解释率见“OPLS-DA模型参数表”。
3.3 正交偏最小二乘法-判别分析(OPLS-DA)
基于GC-MS的代谢组学数据具有高维(检测出代谢物种类多),小样本(检测样本量偏少)的特性,在这些变量中既包含与分类变量相关的差异变量,也包含大量互相之间可能存在关联的无差异变量。这导致如果我们使用PCA模型或PLS模型进行分析,由于相关变量的影响,差异变量会分散到更多的主成分上,无法进行更好的可视化和后续分析[8]。所以我们采用正交偏最小二乘法-判别分析(orthogonal projections to latent structures- discriminant analysis, OPLS-DA)的统计方法对结果进行分析。通过OPLS-DA分析,我们可以过滤掉代谢物中,与分类变量不相关的正交变量,并对非正交变量和正交变量分别分析,从而获取更加可靠的代谢物的组间差异与实验组的相关程度信息。使用SIMCA软件(V14.1,Sartorius Stedim Data Analytics AB, Umea,Sweden对数据进行对数(LOG)转换加UV格式化处理,首先对第一主成分进行OPLS-DA建模分析,模型的质量用7折交叉验证(7-fold cross validation)进行检验;然后用交叉验证后得到的R Y(模型对分类变量Y的可解释性)和Q(模型的可预测性)对模型有效性进行评判;最后通过置换检验(permutation test),随机多次改变分类变量Y的排列顺序得到不同的随机Q值,对模型有效性做进一步的检验。各组对比OPLS-DA模型的模型累积解释率见表2“OPLS-DA模型参数表”。

表2 OPLS-DA模型参数表
Model:SIMCA软件建模的模型编号,该编号会对应到结果文件。
Type:SIMCA的模型类型,OPLS-DA表示建立OPLS-DA模型。
A:模型的主成分个数。
N:模型的观测个数(此处即为样本数)。
R X(cum):代表模型对X变量的解释性。
R Y(cum):代表模型对Y变量的解释性。
Q (cum):模型的可预测性。
Title:该模型对应的数据对象。
样本间的对比分析以Class2组对Class1组为例,对OPLS-DA结果进行解释。
3.3.1 OPLS-DA得分散点图
Class2组对Class1组的OPLS-DA模型得分散点图如图4所示。
图中横坐标t[1]P表示第一主成分的预测主成分得分,纵坐标t[1]O表示正交主成分得分,散点形状和颜色表示不同的实验分组。从OPLS-DA得分图的结果可以看出,两组样本区分非常显著,样本全部处于95%置信区间(Hotelling’s T-squaredellipse)内。
3.3.2 OPLS-DA置换检验
置换检验通过随机改变分类变量Y的排列顺序,多次(次数n=200)建立对应的OPLS-DA模型以获取随机模型的R Y和Q值,在避免检验模型的过拟合以及评估模型的统计显著性上有重要作用[9]。Class2组对Class1组OPLS-DA模型的置换检验结果如图5所示。
图5中横坐标表示置换检验的置换保留度(与原模型Y变量顺序一致的比例,置换保留度等于1处的点即为原模型的R Y和Q值),纵坐标表示R Y或Q的取值,绿色圆点表示置换检验得到的R Y值,蓝色方点表示置换检验得到的Q值,两条虚线分别表示R Y和Q的回归线。原模型R Y非常接近1,说明建立的模型符合样本数据的真实情况;原模型Q比较接近1,说明如果有新样本加入模型,会得到比较近似的分布情况,总的来说原模型可以比较好地解释两组样本之间的差异。同时随着置换保留度逐渐降低,置换的Y变量比例增大,随机模型的Q逐渐下降。说明原模型具有良好的稳健性,不存在过拟合现象。
3.4 单变量统计分析(UVA),差异代谢物的筛选和火山图
基于GC-MS的代谢组数据的固有特性要求我们使用多元变量统计分析方法对数据进行分析。相比与传统的单变量统计分析方法(univariate analysis, UVA)如学生氏t检验、方差分析(analysis of variance, ANOVA)等更加注重代谢物水平的独立变化,多元变量统计分析更加注重代谢物之间的关系以及它们在生物过程中的促进/拮抗关系。同时考量两类统计分析方法的结果,有助于我们从不同角度观察数据,得出结论,也可以帮助我们避免只使用一类统计分析方法带来的假阳性错误或模型过拟合[10]。本研究使用的卡值标准为学生t检验(Student’s t-test)的P值(P-value)小于0.05,同时OPLS-DA模型第一主成分的变量投影重要度(Variable Importance in the Projection, VIP)大于1。差异代谢物筛选的结果以Class2组对Class1组为例进行说明,差异代谢物筛选结果示例如下表3。
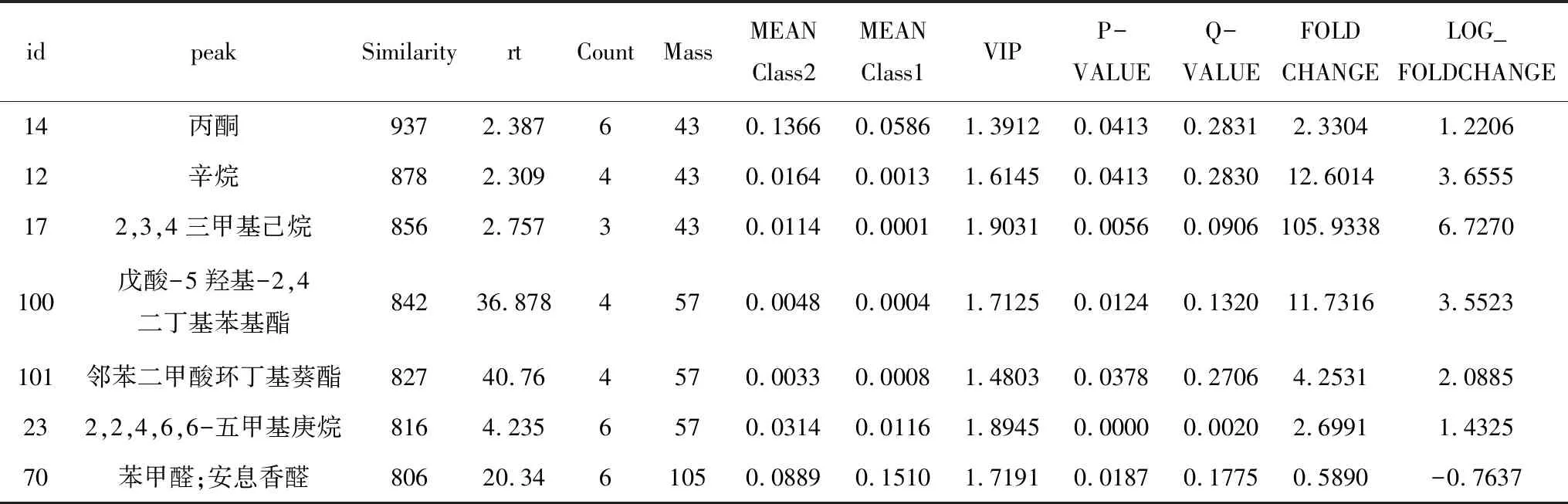
表3 差异代谢物筛选表(前7行,digits=2)
差异代谢物筛选表的主要内容包括下列内容。Id,代谢物在本数据库中的序号;Peak,物质在Fiehn数据库中的名称;Similarity,该物质与质谱检测峰的匹配度打分;VIP,来自OPLS-DA模型的VIP值;P-VALUE,来自t-test的P值;FOLD-CHANGE,两组实验物质定量的比值;LOG-FOLDCHANGE,FOLD CHANGE取以2为底的对数。表中Similarity打分的取值范围为[0,1 000],分数越高匹配度越好,依据Similarity及其他信息,我们将一些物质进行删减和合并,并以analyte和unknown代替。我们将筛选差异代谢物的结果以火山图(volcano plot)的形式进行可视化,Class2组对Class1组的结果如图6所示。
火山图中每个点代表一个代谢物,横坐标代表该组对比各物质的倍数变化(取以2为底的对数),纵坐标表示学生t检验的P-value(取以10为底对数的负数),散点大小代表OPLS-DA模型的VIP值,散点越大VIP值越大。散点颜色代表最终的筛选结果,显著上调的代谢物以红色表示,显著下调的代谢物以蓝色表示,非显著差异的代谢物为灰色。
4 讨论
本次实验中共检出108个峰,经过我们对原始数据进行一系列的处理后,107个峰值被保留,经两组样品对比分析,我们共得到显著上调的代谢物12种,显著下调的代谢物2种,主要的差异代谢物有:丙酮、辛烷、2,3,4三甲基己烷、戊酸-5羟基-2,双丁基苯基酯、邻苯二甲酸环丁基葵旨、2,2,4,6,6-五甲基庚烷。
随着我国经济社会的快速发展,居民生活水平显著提高,食品消费结构的进一步优化调整,使得畜产品越来越受到消费者的青睐,特别是以低胆固醇、高蛋白含量为代表的羊肉产品需求不断加大,羊肉、羊肉卷等特色产品早已成为人们餐桌上的美食,特别是北方人,吃火锅的时候少不了来一盘羊肉(卷),这也为我国肉羊等草食性畜牧产业的繁荣发展提供了强劲的外源动力,也促使肉羊产业成为畜牧产业中迅速发展的新兴产业。羊肉不仅是部分民族地区居民的重要肉类食品,其在改善我国城乡居民膳食结构、提高国人身体素质、优化生活品质等诸多方面发挥作用。羊肉除了作为居民的重要肉类食物以外,在西北,其所带动的养羊业同样肩负着带动县域经济的发展,增加农牧民收入,脱贫攻坚的重要抓手。
膻味物质一直是影响人们是否喜食羊肉的主要原因之一,膻味绝大多数情况下是指来自绵羊或山羊肉所散发出的使人不愉快的异味。羊肉风味中较难接受的味道分别为“mutton flavor”和“pastoral”2种风味。Watkins等研究发现,产生“mutton flavor”风味的物质目前比较确定的为支链脂肪酸,主要为4-甲基辛酸(4-methyl octylic acid,MOA)、4-乙基辛酸(4-ethyl octylic acid,EOA)和4-甲基壬酸(4-methyl nonyl acid,MNA),3种支链脂肪酸产生“mutton flavor”的阈值分别为20、6、650μg/kg;而产生“pastoral”风味的物质主要为3-甲基吲哚(3-methylindole,MI)和4-甲基苯酚(4-methyl phenol,MP),MI和MP产生“pastoral”风味的阈值分别为50.0、0.2 μg/kg[11]。而本研究并未检测出这几种物质,据报道,羊肉膻味的几类物质主要存在与羊肉的脂肪组织中,脂肪组织是最明显的风味物质的来源,特别是其中的4-辛烷和4-甲基九烷。某些脂溶性物质在风味和膻味形成中发挥着重要作用,但在肌肉中这类含量相对较少[12~18]。因此,本研究正好也印证了相关研究结果。
羊肉具有高蛋白、低脂肪和低胆固醇等特点,是中国传统的肉类食品,盐池滩羊肉,因其肉质细嫩、膻味轻、味美,受到广大消费者的喜爱,气谱-质谱方法已普遍应用到了羊肉风味物质的研究中[19~21],虽然影响羊肉风味的因素是多样的,但对于阐明其主要的代谢物质对进一步提高和改善滩羊肉品质具有一定的意义,因此,因进一步开展相关研究,助推滩羊产业发展。
