基于CRF的入院记录中医院名称实体识别及应用
2019-12-10曹凯迪施识帆王忠民
曹凯迪,施识帆,王忠民
(南京医科大学第一附属医院 信息处,江苏 南京 210029)
0 研究背景
随着医疗信息化的快速发展,住院电子病历在临床中得到广泛应用,作为患者住院治疗全过程的原始记录,它包含有入院记录、病案首页、病程记录、检查检验结果、住院医嘱、手术记录等信息[1],这些数量庞大且完善的电子资料数据,给临床科研提供了很大便利,很多临床辅助决策系统(CDSS)将其当作重要的知识来源。入院记录是临床医生在患者入院之初的医疗记录,包含了患者的入院病因、简要病史等,常会包含患者在此次入院前的既往就诊信息。研究患者既往就诊历史医院,可以分析患者对就医机构选择的考虑因素。
自从机器学习方法中的命名实体识别广泛应用于英文电子病历的研究后,已经有越来越多的科研工作者将该技术用于中文电子病历的研究。当前使用较多的机器学习模型是条件随机场(CRF),该模型相对比其他模型比如支持向量机(SVM)、隐马尔可夫(HMM)等具有无标注偏见、可求得全局最优值、小规模数据可获得理想效果等优点。叶枫等[2]采用算法工具CRF++,提出了CRF特征选择和模板设计应用于中文病历中的一些基本规则,得到3类实体的最佳F值分别为92.67%、93.76%和95.06%。许源等[3]针对脑卒中患者入院记录中的医学实体构建了基于CRF和RUTA规则的命名实体抽取模型,经五折交叉验证获得实体的抽取准确率0.960,召回率0.916,F-score 0.939。
目前对于患者就医医院选择的影响因素研究大多基于调查问卷进行,耗费人力物力,因此本研究采用机器学习的方法对入院记录信息进行分析挖掘,通过构建命名实体模型实现入院记录中的就诊医院名称的抽取,进而分析患者就医医院选择的影响因素。
1 研究方法
1.1 语料库来源
江苏省人民医院暨南京医科大学第一附属医院是江苏省综合实力最强的三级甲等综合性医院,担负着医疗、教学、科研、行风四项中心任务,实际开放床位4000张,每年有大量的住院患者,仅2018年一年出院人次就为16.8万,产生庞大的住院电子病历数据量。本文研究数据的原始语料是从2008-2018年间该院收治的住院患者的电子病历中随机抽取的1000份入院记录,因医生记录病历习惯不同以及患者就诊历史不同,其中330份语料中包含了患者既往在其他医院就诊的历史作为有效标注语料,另抽取26219份入院记录作为数据抽取模型验证的语料,所有语料均做了脱敏处理。
1.2 命名实体类别设计
本研究目的是通过命名实体识别的技术获取患者此次在江苏省人民医院住院前的历史就诊医院名称,包含此类信息的文本是患者的住院电子病历中的入院记录,语料来源类型单一,实体类别单一,综合考虑我国医院行政级别划分的情况并结合病历中实际描述情况,将待标注医院名称划分为5类实体:省级医院(ProvinceHSP)、市级医院(CityHSP)、县区级医院(CountyHSP)、社区医院(CommunityHSP)、以及无明确说明医院名称只概括提到的当地医院(LocalHSP),在实际标注过程中,遇到的军队所属医院全部归为ProvinceHSP一类。
1.3 语料标注工作与工具
语料标注工作由两个人完成,在统一命名实体标注标准并对标注工作人员进行培训后,从330份语料中抽取120,由两名研究人员各自对80份语料进行标注,其中有40份语料是完全相同的。两人标注完成后对这相同的40份语料进行一致性验证,第一次标注的一致性F值达到0.9以上才可以继续语料标注工作。
语料标注与后续的模型生成、数据抽取工具均是医学自然语言处理平台系统-PLATO,此系统集成了机器学习方法和深度学习方法,能实现对文本的标注以及自然语言实体抽取模型的快速构建,以及应用交叉验证等方法对模型的效果进行综合性能评估。通过该平台构建模型后,可以实现对非结构化医疗文本数据进行准确地识别和提取。
1.4 模型构建
本文采用PLATO系统中集成的CRF算法来构建抽取模型,然后使用五折交叉验证的方法对模型效果进行准确率验证。采用CRF的原因是它使用的概率图模型,能够表达长距离依赖性和交叠性特征,从而更优地解决标注(分类)偏置等问题,并且所有特征可以进行全局归一化,以求得全局的最优解[4]。
2 结果与讨论
因本文研究的实体只涉及到医院名称,不存在主观判断,对标注人员的医学知识没有要求,所以两名标注人员对40份相同的语料标注的第一次的F值达到0.950,满足多人标注的一致性要求,继续完成剩下290份语料的标注。之后采用PLATO平台集成的CRF算法作为构建自然语言模型的核心算法,此算法获得的5类实体的准确率、召回率、F-score平均值分别为0.946、0.896、0.917(表1)。其中F-score较高的前4个实体均超过了0.9,表现良好。CommunityHSP的F-score较低,原因是社区医院在患者的就诊历史中出现次数非常少,训练样本数量太少导致模型的F-score较低,这一现象在语料标注时已显现。
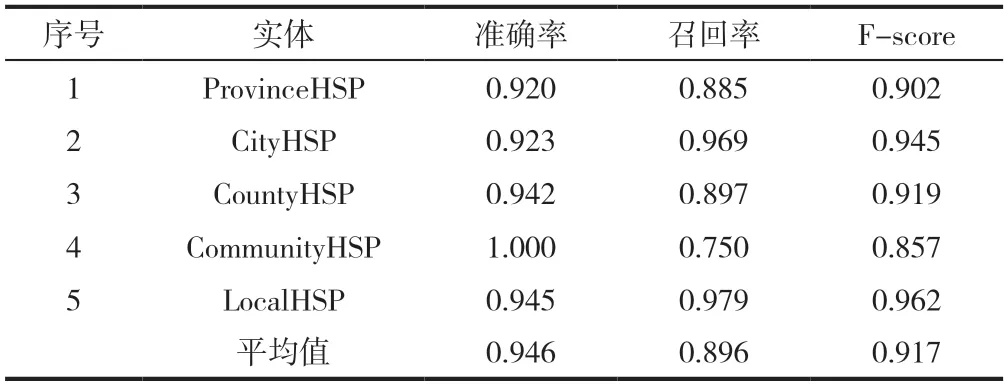
表1 330份入院记录中5类命名实体抽取的交叉验证准确率
将此模型用于江苏省人民医院入院记录中随机抽取的26219份语料进行实体抽取,共获取命名实体数据11254条,实体数据小于语料数量的原因有二:1)医生书写病历中未涉及到患者既往就诊医院;2)患者在此次入院前无其他医院就诊历史。在实体数据中,以LocalHSP数量最多(图1),占总数的51.3%,这与医生的书写习惯和患者所述病史是否清晰有关系。另外4类实体中,我们发现,数据量按省-市-县区-社区依次减少,这与我国卫生资源的倒三角配置有关系,技术水平优秀的医务人员、先进的医疗资源都集中在大城市的大医院,基层医疗机构卫生资源薄弱[5],所以患者更愿意到省市级大医院就诊。
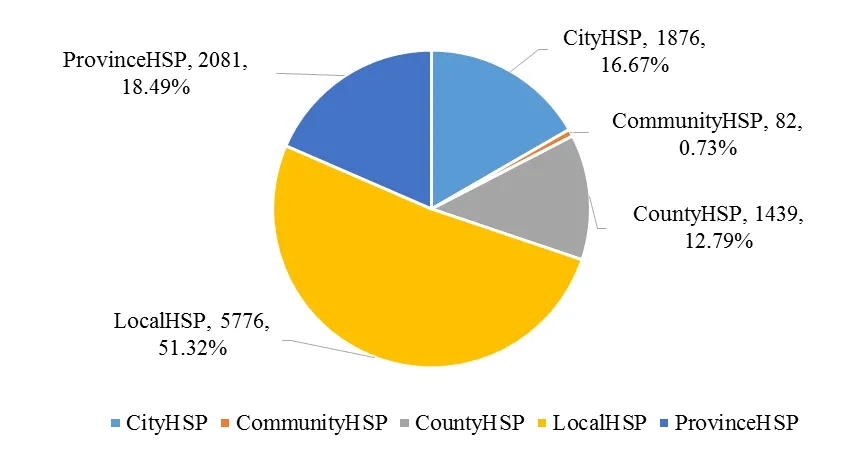
图1 26219份入院记录中命名实体抽取数量与占比统计
针对这4类实体进行详细分析,将医院按照所属省份分类(表2),5478个实体中江苏省的医院占大部分,其次是军队、安徽省和上海市的医院。从地理位置上看,安徽省和上海市紧挨江苏,两地患者到江苏省人民医院就诊距离近而且交通便利,这符合患者倾向于就近就医的心理。
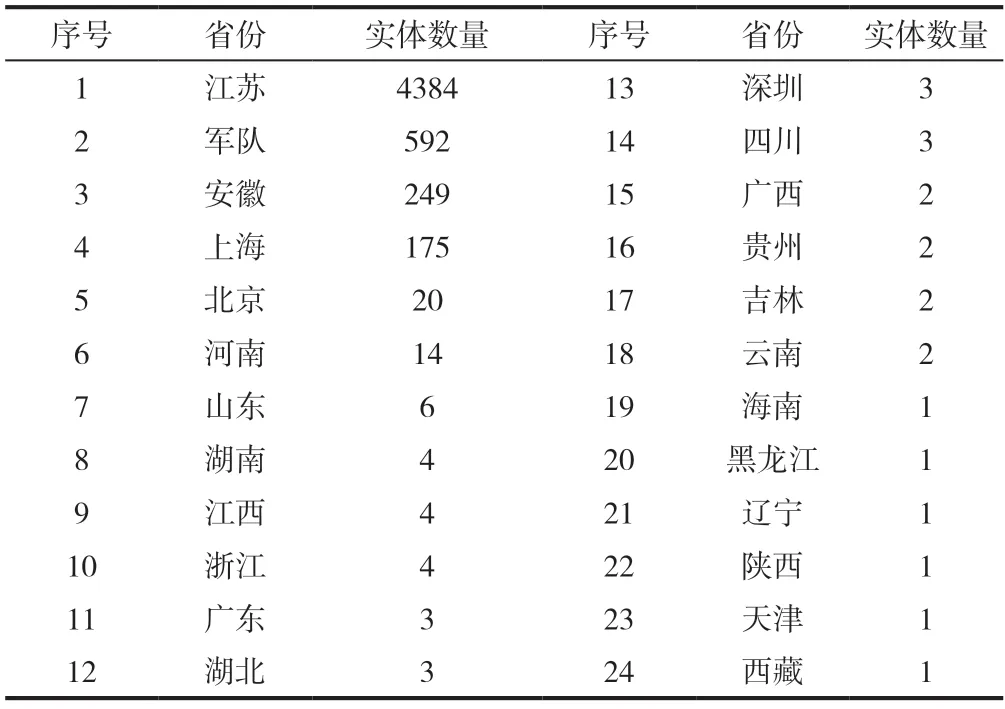
表2 患者就诊历史医院数据按省份分布统计
具体到江苏省内的医院(表3),南京市医院数量最多,因江苏省人民医院位于省会南京,在本市有高水平的大医院的情况下,南京市患者去外地就医的意愿会降低。进一步分析南京之外的医院(图2),扬州、常州和盐城的医院排在前三,这三个城市在地域上靠近南京,且市内没有高水平省级医院,从患者就诊医院选择倾向于技术水平高和距离近两个原因分析,符合患者心理。排在后三位的是徐州、南通和苏州,南通与苏州到上海的距离要近于南京,且上海有更多的高水平三甲医院,从上述两个原因考虑,比南京对这两个城市的患者更有吸引力。

表3 患者就诊历史医院在江苏省内按城市分布统计
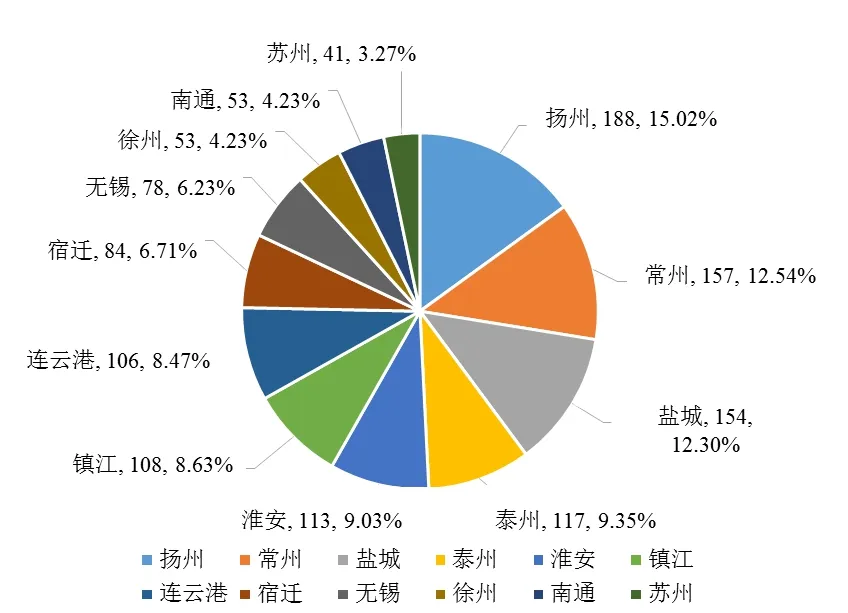
图2 患者就诊历史医院在江苏省南京市之外的城市分布示意图
3 结论
本文建立了统一的命名实体标注体系,对330份江苏省人民医院住院电子病历的入院记录进行了标注,标注一致性F值为0.95。基于标注好的语料库,结合CRF算法,构建了入院记录中医院名称的命名实体抽取模型,获得5类实体的平均准确率、召回率、F-score分别为0.946、0.896、0.917。之后使用该模型对该院入院记录中随机抽取的26219份语料进行结构化抽取,共获取命名实体11254条。通过对实体的进一步分析,得到了江苏省人民医院住院患者的来源分布数据,患者在就诊医院的选择上具有技术水平高、医疗资源好、就近就医的偏好,此结论与既有文献相关发现一致[6]。由此可见完善分级诊疗政策体系,优质医疗资源有效下沉,提高基层医疗卫生服务能力的工作任重道远[7]。
