查找差异数据子集的过滤规则建模方法
2019-12-06周鹏程何震瀛荆一楠王晓阳
周鹏程 何震瀛 荆一楠 王晓阳


摘 要:大数据分析和应用得到了各个行业的关注,人们试图从大量数据中发现蕴含的模式和规律,进而产生更多的价值,数据过滤作为数据分析过程中常用手段所起到的作用是无可替代的。基于方便用户快速筛选数据并找到差异性的数据子集的实际需求[1],需要分析与挖掘数据项之间联系,对数据过滤规则进行建模,以帮助用户快速定位到差异性的数据子集。在本篇论文中创新性地提出一种查找差异数据子集的过滤规则建模方法。该方法的目的是解决如何在数据分析中应用数据过滤规则建立分析过滤模型,然后利用模型分析过滤得到差异性的数据子集,最后利用模型完成结果集的自动可视化。利用该建模方法建立的数据分析系统能在真实数据集中快速找到差异性数据子集,并且自动完成对结果子集的可视化展示,展现了建模方法的实用性和高效性。
关键词:数据分析;差异性数据;过滤模型
中图分类号:TP18 文献标识码:A
A Filtering Rule Modeling Method for Finding Subset of Differential Data
ZHOU Pengcheng1,HE Zhenying2,JING Yinan2,WANG Xiaoyang2
(1.Software School,Fudan University,Shanghai 201203,China;
2.Computer Science and Technology School,Fudan University,Shanghai 201203,China)
Abstract:The analysis and application of big data have attracted the attention of various industries.People try to find the patterns and rules contained in a large amount of data so as to generate more values.Data filtering plays an irreplaceable role as a common approach in the process of data analysis.Based on the actual requirements of facilitating users to quickly filter data and find the differential data subsets,it is necessary to analyze and mine the connections between data items and conduct modeling of data filtering rules to help users quickly locate the differential data subsets.The purpose of this method is to solve the problem of how to apply data filtering rules in data analysis to establish an analytical filtering model,and then use the model to analyze and filter differential data subsets,and finally use the model to complete automatic visualization of result sets.The data analysis system established by this modeling method can quickly find out the differential data subsets in real data sets,and automatically complete the visualization of the result subsets,which shows the practicability and efficiency of the modeling method.
Keywords:data analysis;differential data;filtering model
1 引言(Introduction)
在數据无处不在的时代,用户的决策越来越受到数据分析的驱动[2]。通常,对于数据分析结果的不同往往能显著影响决策过程。选择不当数据,不管是有意的还是无意的,可能导致误导用户做出的不合适决策甚至导致错误的决策。差异化数据在数据分析中往往具有重要的分析意义,而非差异化的数据对于数据分析的贡献就比较小,甚至会降低数据分析的质量。所以提供用户优良的差异性数据过滤模型能引导用户进行质量更好的数据分析,从而提高用户的决策质量。
2 简介(Brief introduction)
大数据的快速发展引起了国内外的广泛关注和重视,如何对大数据进行科学有效地分析处理是大数据领域最核心的问题[3]。分析方法的优劣将决定分析结果的有效与否,将最终影响大数据分析成果的应用。根据国内外的研究将数据分析划分为描述性统计分析、探索性数据分析以及验证性数据分析[4];其中,探索性数据分析侧重于在数据之中发现新的特征,而验证性数据分析则侧重于已有假设的证实或证伪。本论文的研究方向属于探索性数据分析中的差异性数据查找方法。
2.1相关研究
在查找规律的方法中,粗糙集理论作为一种数据分析处理的理论引人注目[5]。粗糙集理论是处理不确定信息的一种方法。可以从不完备的信息中得出现有的规律,并从中提取出一些规则,这些规则代表原始数据集的数据分布。一般的在某些情况下有些信息在某些情况下是无用的或者说是无效的,这时候我们假设在不影响最终决策分类结果的情况下,对此属性进行约简去掉无用的属性并且对约简后的数据进行规则提取,分析提取出的规则。在属性简约的CEBARKCC算法中采用了基于信息熵的方法,去除冗余属性从而得到一个粗糙集,这个粗糙集是原始数据集的一个子集,相当于对原始数据集做一个抽样[6]。本文的过滤规则建模方法也是受到这种做法的启发,与属性简约的理念不同的是,本方法主要采用一系列的方法(包括信息熵)对原始数据集的过滤,最终的目的是提取具有最大差异数据的子数据集,这个数据子集不是原始数据集的抽样,而是原始数据集中具有最大差异性的数据的集合。
2.2 差异数据探索
数据分析的目的是把隐没在一大批看来杂乱无章的数据中的信息集中、萃取和提炼出来,以找出所研究对象的内在规律。数据分析是组织有目的地收集数据、分析数据,使之成为信息的过程。不同领域不同类型的大数据往往需要特定的分析方法来对数据进行分析,此类数据分析要求分析者对该领域数据有较为深入的理解,这就意味着分析者需要拥有专业领域的知识背景。本论文提出的目的就在于希望通过建立差异化数据分析过滤模型协助分析者对差异化的数据进行快速的分析探索。即使是没有分析经验的分析者,面对大数据时利用本论文提出的分析过滤模型都能使用适当的方法探索分析出数据集中的差异化的数据。
在大数据探索式场景中,面对大量数据时分析者很难找出差异化的数据。为了使用户能够尽可能消除容易出错的数据探索过程和烦琐的过滤条件设置,直截了当地得到差异化数据子集。毫无疑问的是我们需要一个标准化的流程来决定该如何进行数据的选择。为了实现这个目标,本论文提出一种差异数据子集的过滤规则识别方法,目的是通过合理的利用算法和设定相关的规则解决如何在数据分析中应用数据过滤规则建立分析过滤模型,并利用模型分析过滤数据,最后智能化的展示结果数据。
建立良好的数据过滤规则面临以下的这些问题亟待解决:
(1)维度:考虑从什么维度进行分析过滤才能产生更好的差异化分析结果。
(2)可解释性:过滤模型需要能分析出数据之间的潜在关联,产生能过滤出差异化数据的过滤条件。
(3)质量:如何判定分析的质量。
在接下来的章节中我们会详细地讨论如何利用我们的建模方法在来解决上述三个问题。
3 问题阐述及解决(Problem description and solution)
3.1 问题阐述
当用户打开数据集时,面对着成百上千的原始数据往往不知道该如何分析哪些数据子集。如果用户对原始数据没有一定的了解,也就不会知道数据之间的联系,更加不可能知道数据之间是否存在某种潜在联系。因此需要考虑如何选取差异化的维度,使得数据的分析能产生足够差异化的特征表现[7]。
选取了适合的维度以后,该如何分析选定维度中数据的相互联系,如何定义在该维度数据下的差异化数据,进而选定适合的过滤条件并通过过滤找到其中的差异化数据。这个问题我们在之后会详细讨论如何解决。
在常用的数据分析工具中常用可视化作为直观地展示数据分析结果的手段,可视化同时作为评判数据分析结果的质量。但是在常用的数据分析工具中需要用户自己选择如何对结果数据集可视化。有经验的分析师能凭借经验知道该如何选择,对于新手来说那就要经过多次的试错才能达到理想的数据展示效果。如果能自动的判定用户选定的数据该如何生成可视化图表,就能大大的帮助到用户检验数据分析的质量。事实上,我们的差异化数据分析过滤模型面对着该如何采用智能化的方法为用户可视化的问题,即如何使用可视化直观的呈现用户数据分析的结果。
3.2 解决方案
关于维度的选择和差异化数据过滤条件,本论文基于传统数据库的表结构,从行和列两个维度分析差异化数据。首先通过列数据的分析过滤,查找可能具有差异化信息的数据列,之后通过一系列的关于差异数据的信息计算算法,找到具有差异性特征的数据子集,最后通过可视化展示差异性数据查找的质量。
总结来说就是在差异性数据过滤模型中有三个过滤规则:差异性数据列的过滤、差异数据范围的过滤、结果可视化的过滤。使用过滤模型进行差异化数据查找流程如图1所示。
图1 差异化数据过滤模型过滤流程
Fig.1 The filtering process of differentiated data
filtering model
實践证明通过以上过滤规则引导用户进行差异性数据分析,能明显提升用户分析差异性数据的质量。在接下来的章节4.1介绍数据列的过滤规则建模方法;4.2中介绍数据范围的过滤规则建模方法;4.3中介绍结果数据可视化的过滤规则建模方法。
4 建模方法(Modeling approach)
接着具体介绍一下如何根据数据集本身特征,以及用户的真实需求产生适当的数据列差异性分析过滤。
4.1 差异数据列的过滤
数据集D里面有很多数据列等待差异性分析,对于没有分析经验的普通用户来说,并不知道哪些数据列具有差异性数据。而数据列的差异性分析过滤不仅能帮助用户方便的分析数据列之间的联系,更能帮助用户挖掘数据列之间的潜在联系,用户通过分析过滤模型得到最有可能具有差异性数据子集的数据列。
4.1.1 对于指定关键列差异性分析的列过滤
当用户指定关键列时,一般来说,用户希望得到相关数据列对于关键列的差异性是否具有影响,并希望知道这些相关列对于关键列差异性的影响因子。因此,指定的关键列的差异性分析过滤核心思想就是在数据集D中计算相关列对于关键列所产生影响的影响因子,然后根据影响因子大小排序进行过滤。本部分过滤模型采用随机森林的方法完成相关列的过滤。随机森林[8]计算影响因子的核心思想就是计算每个特征列在随机森林中的每颗CART树(最小二乘回归树)上做了多大的贡献,然后取个平均值,比较特征之间的贡献大小。贡献度通常用基尼指数(Gini index)或者袋外数据(OOB)错误率作为评价指标来衡量。本论文采用的是袋外数据(OOB)错误率作为评价指标来衡量贡献度。方法的伪代码如下Algorithm 1所示。
之所以可以用∑(err00B2-errOOB1)/Ntree这个表达式作为相应特征列影响因子的度量值是因为若给某个特征列随机加入噪声之后,袋外的准确率大幅度下降,则说明这个特征列对于关键列的分类结果影响很大,也就是说它对于关键列的差异性影响程度比较高。
4.1.2 无指定关键列的差异列过滤
当用户没有指定关键列的时候,很大程度上说明用户不清楚在这个数据集里面的关键列是什么,或者用户不清楚数据集里面有什么。那么此时过滤规则就需要分析出此数据集里面有哪些部分是“主要成分”,这些“主要成分”影响着数据的差异性,是影响数据集中数据特征分布的重要成分。因此,本论文面对这种情况时分析过滤模型采用PCA[7](Principal Component Analysis,主成分分析)来提取数据的主要特征列,这些特征列的影响因子也就是造成数据集中差异性数据分布的重要性指数。
PCA本身的核心思想就是将高维数据降维到低纬度空间里,并期望在所投影的维度上数据的方差最大。因此可以使用较少的数据维度,同时保留住较多的原数据点的特性。同时PCA可以压缩数据空间提升整体算法效率,进一步的消除冗余数据和噪音数据。PCA作为一个非监督学习的方法,仅仅需要以方差衡量信息量,不受数据集以外的因素影响。PCA各主成分之间正交,可消除原始数据成分间的相互影响的因素。而且PCA计算方法简单,主要运算是特征值分解,易于实现。方法的伪代码如下Algorithm 2所示。
根据PCA得到的数据的主成分(即特征向量)与它们的权值(即特征值)。根据权值的大小排序将最大的三列提供给用户,即得到这些特征列对于数据差异性的影响因子的排行。
4.2 差异数据区间过滤
4.2.1 差异数据区间
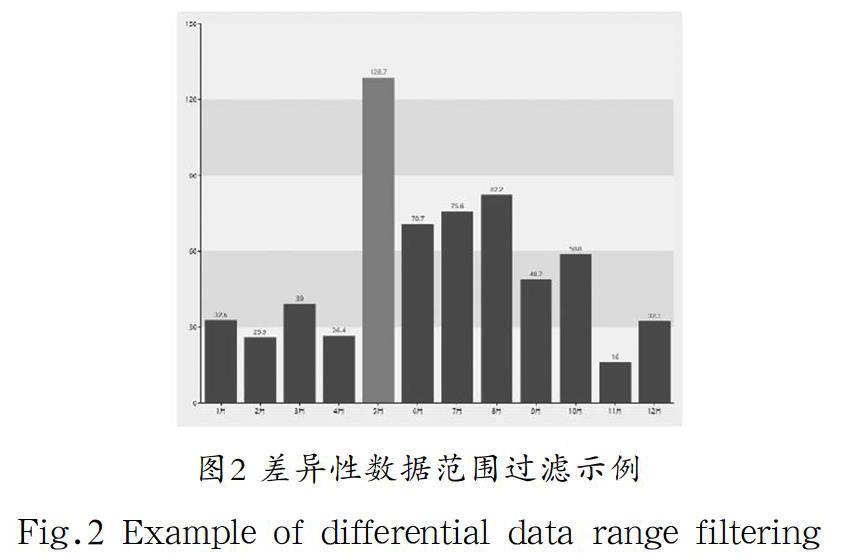
本论文提出过差异性数据分析过滤模型会帮助用户对差异性数据区间进行过滤,以便用户对差异性的数据进行筛选与分析。如图2所示,应用该模型的一个系统过滤分析示例,其中5月—10月为差异性数据区间,5月为其中的异常区间。
图2 差异性数据范围过滤示例
Fig.2 Example of differential data range filtering
因为此时选取一列数据进行过滤会对数据集产生一次数据的筛选,从而产生不同区间的数据子集。考虑到这种会影响到其余所有列的数据范围。因此,本论文介绍的过滤规则首先通过剪切减少计算,然后通过并行计算提高差异性数据子集的寻找。
4.2.2 数据剪切
数据集中的数据,绝大部分都是非差异化的数据,差异化的数据只占有数据中的很小一部分。为了减少计算的开销,通过剪切能及其有效地过滤掉非差异化的数据。本论文采用的是孤立森林对差异化数据区间进行过滤。孤立森林[9]是一个基于Ensemble的快速异常检测方法,具有线性时间复杂度和高精准度。方法的伪代码如下Algorithm 3所示。
看似要计算m列数据,实则不然,在4.1节中我们已经得到对数据差异性影响因子最大的几个列。因此,我们在此处只需要计算这几列的差异区间即可。
4.2.3 并行计算
在选择哪个差异性数据区间作为数据集的过滤条件时,本论文采用相对熵,也就是K-L散度作为计算数据差异度的方法。假设有差异性区间分布P,特征数据列的分布Q。他们之间的差异性计算如下:
对于差异性区间P我们也会枚举出P的数据子集与特征数据列计算K-L散度,考虑其中的计算量。本论文采用并行计算[10]加快差异度的计算。最终由差异性最大的区间作为数据集的过滤条件。
4.3 结果集可视化过滤
为了将差异化分析的结果数据集更加直观地展示给用户,我们采用可视化的形式将结果数据展示出来[11]。
4.3.1 结果集
在结果集D中的某一列X有许多差异性区间记做X1,X2,…,
Xn,某个差异性区间中可以得到一些基本的统计信息,以及通过计算得到的信息合称为一个信息节点,记作V(Xn)[12,13]。其中V(Xn)包含的信息如下所示。
①区间Xn的基数值,d(xn)
②区间Xn的最值,max(xn)、min(xn)
③区间Xn的元组值,|xn|
④区间Xn的数据类型,评论型(LongStr)、数值型(Num)、分类型(Cat)、时序型(Tem)
⑤区间Xn分完箱后,每个箱数据xn'与其对应的CNT(x')
⑥区间Xn分完箱后,每个箱数据xn'与其对应的CNT(xn')的相关系数,correlation (x,CNT(xn'))
⑦区间Xn推荐展示图标类型,饼状图(Pie)、柱状图(Bar)、词云图(WordCloud)、折线图(Line)、散点图(Scatter)
Xn提前计算出可视化节点V(Xn)的目的是为了减少计算相对信息熵时的计算开销,因为在计算相对信息熵的时候会反复使用信息节点中的特征信息和统计信息。
4.3.2 相对信息熵排序
本套建模方法采用一種方法对结果集可视化进行一定的过滤,按照结果集中的数据列维度展现每一列的差异性数据区间。我们称之为“相对信息熵排序”。注意,这里的相对信息熵和相对熵不是一个概念,这里的相对信息熵是指每一个不同的可视化方式的信息熵相对于“标准”的可视化方式计算得到的信息熵值的比值[14,15]。相对信息熵越高,使用该可视化方式得到的可视化图表越接近“标准的”可视化。
其中,该方法的核心思想就是:
(1)首先为每一种可视化方式规定一个“标准的”可视化。
(2)根据剪切规则过滤。
(3)计算结果集中的差异性区间在每一个可视化方式下的信息熵与“标准”可视化的比值。
(4)根据比值选取最优的可视化方式。
4.3.2.1 剪切规则
当我们拿到已经分箱的xn'数据时,根据xn'数据的类型,定义了一套規则如下。
(1)当xn'的数据类型为时序型:可视化图表可为柱状图、折线图。
(2)当xn'的数据类型为离散型或数值型:可视化图表可为柱状图、饼状图、散点图。
通过对数据类型的判断,能直接过滤掉那些从理论上来讲就不能很好的表现差异化数据的信息节点的可视化过程。这样能大大地减少我们在可视化过程中的计算节点次数[16]。
4.3.2.2 相对信息熵
现在,我们正式地介绍一下如何采用相对信息熵排序的方法[17,18]选择差异性区间Xn适合的可视化图表。信息熵(Comentropy)记作C。
(1)柱状图
柱形图是分析师最常用到的图表之一,适用于各个场景。当xn'元素过多的时候能更好地展示数据的详细情况以及利用柱子的高度差提高用户对于数据差异的辨识度,展现数据的差异化程度。
(2)饼状图
饼状图可展示多组数据,表现各组数据占总比情况。当差异性区间Xn的基数为1时,|d(Xn)|=1,饼状图没有什么意义。设置信息熵为0。同理当Xn的最小值小于0的时候,饼状图无法展现负数,信息熵也设置为0。设定一个标准的饼图,饼图元素的量不超过20,因此设置权重为1。当饼图元素超过20,饼图所包含的信息反而减少,因此,我们将权重设置。由于人的肉眼对于面积的感知不敏感。在饼状图中我们需要有区分度的CNT(xn')来凸显各部分的占比,为此引入熵作为判定差异性数据标准[19]。
(3)折线图
折线图的优势可以反映同一事物在不同时间里的发展变化的情况,也就是能够显示数据的变化趋势,反映事物的变化情况。
当数据CNT(xn')与x'符合某种分布(e.g.线性分布、指数分布、对数分布、低次幂分布)时,我们规定此信息节点v的信息熵C(V(Xn))为1。否则,信息熵为0。
(4)散点图
散点图通过坐标轴,表示两个变量之间的关系。绘制它依赖大量数据点的分布。其优势是揭示数据间的关系,发觉变量与变量之间的关联。
我们使用相关系数可作为散点图类型的信息熵[20]。
当所有种类可视化图表信息熵计算出来以后,算出的C(V(Xn))值越大,表示此信息节点采用该种类图表可视化能更好的展现差异化的数据给用户,即Xn的差异化数据所对应的节点V适合该种可视化图表。特别的情况,当|d(Xn)|=1时,所有的C(V(Xn))=0,默认柱状图作为节点V的可视化图表。
相对信息熵排序的伪代码如下Algorithm 4所示。
5 相关实验(Experiment)
5.1 性能实验
(1)列分析运行时间
本套差异性数据分析过滤规则建模方法在数据列筛选环节采用两种不同的筛选方法随着数据列数量的增多,两个方法显示了一定的性能差异。“指定关键列”分析方法在相同规模下运行时间总是小于“无关键列”的分析方法。因此,本建模方法默认采用了性能表现更好的“关键列差异性分析的列过滤”的方法。
图3 列分析的时间对比
Fig.3 Time comparison of column analysis
(2)数据分析运行时间
本套差异性数据分析过滤规则建模方法在差异数据筛选环节采用并行计算来减少计算差异数据的时间。通过并行和非并行两种计算时间的对比。从中看出如果不采用并行计算,计算的开销时间再交互式的系统中使不可被接受的。在相同数据规模的表现如图4所示。
图4 数据分析的时间对比
Fig.4 Time comparison of data analysis
(3)准确度
本套差异性数据分析过滤规则建模方法在分析差异性数据的时候采用异常值加信息熵,也就是K-L散度计算差异性数据。在选取异常值计算信息熵的过程中会有一些数据被抛弃,那么本套差异性数据分析过滤规则建模方法的差异性数据选取的准确度怎么样呢?通过实际的数据集测试,我们选取了100个数据集进行测试。结果如图5所示,可以看出准确度处于一个非常高的水平。有90%以上的数据集准确率都在90%及以上。
图5 准确度
Fig.5 Accuracy
5.2 专家评判
本套差异性数据分析过滤规则经过五位专业数据分析专家的评测,从准确度指标、多样性和新颖性三个指标来评价本套差异性数据分析过滤规则建模方法(评价为五分制)。
(1)准确性
准确性评价数据分析过滤规则推选出来的数据以及分析出来的可视化图表是否真正的表达出数据的差异性。如图6所示,多数专家认为本数据分析过滤规则能准确地过滤差异化的数据给用户的。
图6 准确度评价
Fig.6 Accuracy assessment
(2)多样性
多样性衡量数据分析过滤规则面对不同的数据能否分析过滤出差异化的数据。如图7所示,多数专家认为本数据分析过滤规则面对不同的数据能提供良好的差异化数据过滤推荐。
图7 多样性评价
Fig.7 Diversity assessment
(3)新颖性
新颖性度量差异化数据分析过滤规则相对于现存的一些基于相似度数据分析方法是否有改进。如图8所示,专家一致认为本套数据分析过滤规则相对于现有的分析系统有较多的改进,能更加智能化的将差异化数据分析过滤并可视化提供给用户。通过对差异化数据分析建立过滤规则模型为用户提供一套完整差异化数据分析解决方案。
图8 新颖性评价
Fig.8 Novelty assessment
通过上述几项评测可以看出,本论文提出的这套寻找差异数据子集的过滤规则建模方法总体表现優异,能很好地引导用户查找到差异化数据子集。
6 结论(Conclusion)
我们已经介绍了我们新颖的数据过滤规则建模方法。我们利用机器学习的算法,以及启发式的规则作为基础解决本文开头提出的面临的两个挑战性问题,并且结合自动化的可视化规则展现差异化数据过滤规则模型的分析过滤结果。在使用真实数据和用例进行的测试中展现了令人欣喜的结果。
未来将挑战更大规模的数据分析过滤,并考虑加入深度学习的相关技术用于改进和完善数据分析过滤规则[21],比如通过深度学习的方法可以不预先训练相关特征;网络在对一组数据进行训练时学习相关特征。
参考文献(References)
[1] Richard Chow,Hongxia Jin,San Joseg,et al.Differential data analysis for recommender systems[C].RecSys '13 Proceedings of the 7th ACM conference on Recommender systems,2013:323-326.
[2] Quoc Viet Hung Nguyen,Kai Zheng,Matthias Weidlich,et al.
What-If Analysis with Conflicting Goals:Recommending Data Ranges for Exploration[C].ICDE,2018:89-100.
[3] Jiahao Wang,Peng Cai,Jinwei Guo,et al.Range Optimistic Concurrency Control for a Composite OLTP and Bulk Processing Workload[C].ICDE,2018:605-616.
[4] Li Guo,Wenyuan Xu,Hao Li,et al.Research and Implementation of Interactive Analysis and Mining Technology for Big Data[C].HCC,2018:359-364.
[5] Lindsay I Smith.A tutorial on Principal Components Analysis[J].International Journal of Remote Sensing,2002,51(2):1100-1127.
[6] Asma Hassani,Sonia Ayachi Ghannouchi.Analysis of Massive E-learning Processes:An Approach Based on Big Association Rules Mining[C].PDCAT,2018:188-199.
[7] Brett Walenz,Jun Yang.Perturbation analysis of database queries.Proceedings of the VLDB Endowment,2016,9(14):1635-1646.
[8] Leo Breiman.Random Forests[J].Machine Learning,2001,45(1):5-32.
[9] Fei Tony Liu,Kai Ming Ting,Zhi-Hua Zhou.Isolation-based Anomaly Detection[J].TKDD,2011,6(1):3:1-3;39.
[10] Xudong Zhang,Zhongwen Qian,Siqi Shen,et al.Streaming Massive Electric Power Data Analysis Based on Spark Streaming[C].DASFAA Workshops 2019:200-212.
[11] E.Wu,F.Psallidas.Combining design and performance in a data visualization management system[C].CIDR,2017:111-132.
[12] T.Siddiqui,A.Kim,J.Lee,et al.Effortless data exploration with zenvisage:An expressive and interactive visual analytics system[J].PVLDB,2016,10(4):457-468.
[13] Xin Guo,Mingshu He.Research on Data Visualization in Different Scenarios[C].HCC,2018:232-243.
[14] M.Vartak,S.Madden,A.Parameswaran,et al.Seedb:automatically generating query visualizations[J].PVLDB.2014,7(13):1581-1584.
[15] M.Vartak,S.Rahman,S.Madden,et al.SEEDB:efficient data-driven visualization recommendations to support visual analytics[J].PVLDB,2015,8(13):2182-2193.
[16] Kwan Hui Lim,Sachini Jayasekara.RAPID:Real-time Analytics Platform for Interactive Data Mining[C].ECML/PKDD,2018:649-653.
[17] Yuyu Luo,Xuedi Qin,Nan Tang,et al.DeepEye:Towards Automatic Data Visualization[C].ICDE,2018:101-112.
[18] Xuedi Qin,Yuyu Luo,Nan Tang,et al.DeepEye:An automatic big data visualization framework[C].SIGMOD Conference,2018:1733-1736.
[19] K.Wongsuphasawat,D.Moritz,A.Anand,et al.Voyager:Exploratory analysis via faceted browsing of visualization recommendations[J].IEEE Trans.Vis.Comput.Graph,2016,22(1):649-658.
[20] Satyanarayan,J.Heer.Lyra:An interactive visualization design environment [J].Comput.Graph.Forum,2014,33(3):351-360.
[21] S.Kandel,R.Parikh,A.Paepcke,et al.Profiler:integrated statistical analysis and visualization for data quality assessment[C].AVI,2012:547-554.
作者簡介:
周鹏程(1995-),男,硕士生.研究领域:数据分析.
何震瀛(1978-),男,博士,副教授.研究领域:海量数据管理,数据分析,面向机器学习的效率优化.
荆一楠(1979-),男,博士,副教授.研究领域:大数据分析,时空数据管理,移动计算.
王晓阳(1964-),男,博士,教授.研究领域:时空移动数据分析,数据系统安全及私密,大数据并行式分析.
