某汽车销售公司数据仓库项目的构建及应用研究
2019-12-06官维
官维
摘 要:为了辅助某汽车销售公司在管理上的科学决策,本文通过需求分析、源数据准备、建模、抽取等步骤构建了一个数据仓库,并开展了多维分析、报表可视化等应用。结果表明,该数据仓库能有效支持该公司的销售分析与决策,也为其他企业同类项目的实施提供了一定的经验参考。
关键词:数据仓库构建;数据抽取;多维分析;报表可视化
中图分类号:TP311.13 文献标识码:A
Research on Construction and Application of Data Warehouse
Project in an Auto Sales Company
GUAN Wei
(Experimental Center,Dalian Neusoft University of Information,Dalian 116023,China)
Abstract:In order to assist the scientific decision on the management of a certain automobiles sales company,a data warehouse is constructed in this paper after a series of steps,such as requirement analysis,source data preparations,modeling and extraction.And the applications of multidimensional analysis and report visualization are performed as well.The result shows that the data warehouse can support this company's sales analysis and decision-making effectively,and the experience can also be referred for the implementation of similar projects by other companies.
Keywords:construction of data warehouse;data extraction;multidimensional analysis;report visualization
1 引言(Introduction)
某汽車销售公司是一家以整车销售为主营业务的贸易公司,在国内外都占有重要的市场份额。随着公司规模的不断扩大,公司的业务量也逐渐增长,并积累了大量的历史销售数据,如何从这些数据中挖掘有价值的规律以更好地辅助企业高层的科学决策已经成为该公司战略规划中的一个重要内容。
商务智能可以使分散在各业务系统中的信息进行有机集成[1],为企业的未来发展和市场竞争提供参考。而数据仓库作为商务智能的核心技术是一种为企业管理服务的重要手段[2]。目前,数据仓库技术已广泛地应用于各个行业,包括:姜兆龙等研究了数据仓库的测试特征并之应用于建设银行的实践[3];冯强等探索了商务智能技术在物流企业的数据仓库构建中的具体应用[4];余媛等立足于交通领域,研究了数据仓库在公交运营信息管理中的构建步骤及实现细节[5]、樊持杰等将数据仓库技术应用在高校突发公共卫生事件的预警和控制中,取得了良好的效果[6]。数据仓库能够对企业的业务数据开展深层次的挖掘与分析,以快速获取其中有用的决策信息,进而提升企业的效益和竞争力。
因此,本文将从某汽车销售公司的实际业务需求和管理目标出发,借助微软公司的SQL Server商务智能工具构建一个汽车销售的数据仓库,在此基础上开展多维分析和报表可视化等应用,以满足该公司规模化发展中的管理与决策需要,同时,也为其他同类企业甚至其他领域提供可借鉴的经验。
2 需求分析与源数据准备(Requirement analysis and source data preparations)
该汽车销售公司的管理人员需要将企业销售部门近些年来的业务数据转换为统计数据,并以直观的可视化报表加以展示,以帮助高层做出正确的管理决策。因此,在项目开始前,要通过与客户的反复沟通明确用户的需求,详细了解销售部门的业务运行流程;按照业务主线,抽取关键的业务概念,将其抽象化并分组;理清分组内每个步骤的具体实现细节并进一步细化与抽象,同时理清分组间的关联关系,进而形成完整的数据模型[7]。
通过分析,该公司需要的是与销售相关的统计型报表,支持可视化分析与浏览。因此,本步骤首先要确定和建立源数据。源数据是数据仓库构建的关键步骤和来源基础,确定源数据就是根据相关的数据源主题构建源数据表,并从企业的业务系统(如ERP)中抽取所需数据至源数据表的过程。
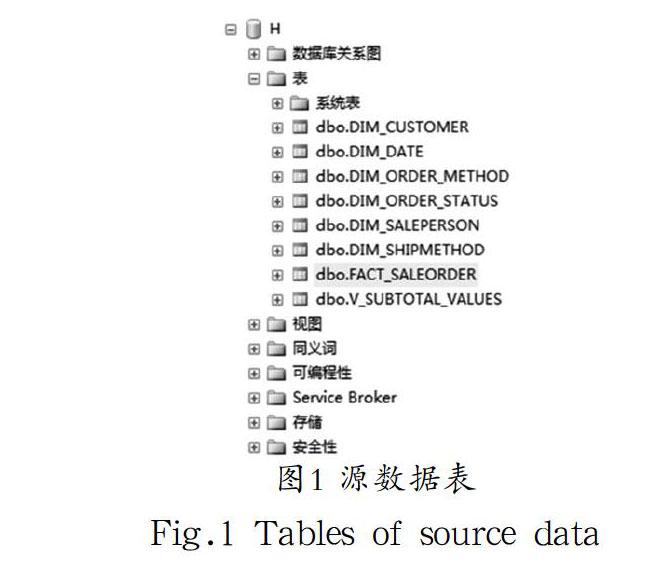
根据本项目的实施目标,确定七个源数据主题,包括:下订单方式、销售人员、发货方式、订单日期、客户、订单状态、订单价值。基于上述源业务主题,通过调用SQL语句建立相应的数据库表,包括:下订单方式表、销售人员表、发货方式表、订单日期表、客户表、订单状态表、订单价值段表、订单分析表。其中,前七个表作为后续数据仓库中的维度表,订单分析表作为事实表。上述源数据表的创建结果见图1。
图1 源数据表
Fig.1 Tables of source data
3 数据仓库建模与数据抽取(Data warehouse modeling and extraction)
3.1 数据仓库建模
常见数据仓库的模型包括两种:星型模型和雪花型模型。两种模型各具特色,在许多的应用场景中往往都是配合使用,以发挥各自的优势[8]。其中:星型模型是由事实表和维度表组成,事实表处于整个模型的核心位置,其他的维度表以事实表为中心呈星型排列。维度表只与事实表相关联,维度表之间没有任何关系。每个维度表中的主键都是单列的,且该主键同时被放置在事实表中,作为连接事实表与维度表的外键;雪花模型是对星型模型的扩展。通过对某些维度进行“层次化”操作,使原有的维度表被扩展为更小的事实表,进而形成局部的层次关系,即某个维度表不是与事实表直接相联,而是依附于另一个层级较高的维度表,维度表与其他的维度表也是靠主外键关联的。通过维表层次关系的下钻操作可以进一步查看更细粒度的数据。星型模型与雪花模型的对比见表1。
表1 雪花模型与星型模型对比
Tab.1 Star model vs.snowflake model
比较标准 星型模型 雪花模型
数据优化 使用反规范化数据,维度表直接与事实表相关,冗余大 使用规范化设计,数据组织合理,冗余少,数据量小
业务模型 所有必要的维度表在事实表中都只拥有外键 由一个不同维度表主键-外键的关系来表示
查询性能 维度表与事实表间的连接较少,性能较高 维度表与事实表间的连接很多,性能较低
ETL操作 加载维度表,不需要额外的附属模型,操作简单,可并行 加载数据集市,受附属模型限制,操作复杂,不能并行化
通过对本公司汽车销售业务的分析,本文采用星型模型,并使用SQL SERVER工具完成数据仓库的构建。具体过程如下:
第一,建立数据源。数据源是特定数据的集合,是为了访问数据所需要的额外信息。在创建数据源时,选择绑定了名称为“H”数据库的本地连接,下一步后的模拟信息选择“默认值”,之后点击“完成”按钮。
第二,建立数据源视图。数据源视图由数据源生成,它可以直接展示数据源中表与表间的联系及层次结构。通过数据源视图提供的可视化平台,能够方便地添加、删除多维数据集的表并建立、维护表与表间的关系。在此处,将所有数据源中的表都选中至数据源视图中,作为数据源视图包含的对象。
第三,建立维度。所有维度都是基于数据源视图中的表列或视图列的属性组。独立于多维数据集存在的维度称为数据库维度,多维数据集中的数据库维度实例称为多维数据集维度。此处选择主表并创建所需维度,同时指定每个维度的属性。
第四,创建多维數据集。多维数据集是一个数据集合,也称为多维立方体。多维数据集由一个事实表和多个维度表构成,事实表是核心,由维度外键和度量值组成;维度表是包围事实表的立体表面,对立方体的切面操作实际是从不同的角度看事实。通过向导选择事实表和所需的维度表,完成多维数据集的创建。
本文数据仓库的建模结果见图2。
图2 数据仓库模型
Fig.2 Model of data warehouse
3.2 数据抽取
数据抽取(也称为ETL)是数据仓库构建的核心环节之一,就是将原始数据从业务系统中抽取出来,经过转换、清洗和装载的过程,形成新的数据仓库。本项目的数据抽取包括对维度的抽取和对多维数据集的抽取。
以对“订单价值段”维度的数据抽取为例,说明抽取过程。选中相应的维度,点击“处理”按钮,进入处理维度界面,再点击“运行”按钮执行处理过程。“处理”就是将相应的维度激活,只有在处理后数据才会显示,即实现了数据抽取过程。需要注意的是,在查看维度中的数据或维度发生改变时,都需要对维度进行处理,否则维度信息会不准确。完成处理之后,为该维度添加层次结构,以保证其值是按从小到大排序,点击“浏览器”,可以显示当前的维度值,见图3。
图3 抽取的维度值
Fig.3 Dimension value after extraction
4 应用实例(Examples of application)
4.1 多维分析
多维数据分析可以对以多维形式堆积起来的数据进行切片、切块、钻取、旋转等各种分析操作,方便解析数据,使分析者、决策者能从多个角度、多个方面观察系统中的数据,从而更加深入了解隐含在数据中的重要信息。具体过程如下:
(1)切片
切片是在给定的数据立方体的一个维度上进行选择操作,其结果是一个二维的平面数据。此处执行“订单价值—订单数量”的切片操作。其执行结果见图4。
图4 切片操作结果
Fig.4 Result of slice operation
图4中,通过切片操作,可看到在0—100价值段的销售数量最多,达到1万笔以上,2000—5000价值段的销售数量排名第二,也接近1万笔,而100—500价值段的销售量最少,仅1409笔。因此,应继续保持0—100和2000—5000两个价值段的销售优势,同时应加强100—500价值段的宣传,扩大其影响进而提升其销售量。
(2)切块
切块是在给定的数据立方体两个或多个维度进行选择操作,其结果是子立体。此处执行“订单价值—订单数量—客户受教育程度”的切块操作。其执行结果见图5。
图5 切块操作结果
Fig.5 Result of dice operation
图5中,通过切块操作,可看到在0—100价值段且面向受教育程度为Partial College的销售数量最多,为3041笔,而100—500价值段且面向受教育程度为Partial High School的销售数量最少。因此,应深入分析受教育程度为Partial College人群的消费习惯和特点,总结其规律,并将之应用于覆盖不同价值段的消费群体,从总体上提升该公司的销售总量,以获取更多的利润和价值。
(3)旋转
旋转是改变维度的方向。此处执行“订单价值—订单数量—客户受教育程度”向“客户受教育程度—订单数量—订单价值”的旋转操作。其执行结果见图6。
图6 旋转操作结果
Fig.6 Result of rotate operation
图6中,通过旋转操作,通过横向维度,可观察到针对不同类别受教育程度的消费者在不同价值段的销售量分布情況;通过纵向维度,可观察到某个价值对应不同受教育程度的消费者的销售分布情况。可见,旋转可以通过一个全新的视角观察到同一数据立方体的不同显示效果,进而获得新的发现与结论,以更好地辅助企业的科学决策。
(4)钻取
钻取是在维度级别的基础上继续深入的了解观察数据。此处针对订单数量执行“客户所在地区:国家”向“省”再向“市”的钻取操作,其执行结果见图7。
图7 钻取操作结果
Fig.7 Result of drill down operation
图7中,加拿大(Canada)的不列颠哥伦比亚省(British Columbia)的销售数量最多(3359),通过进一步的下钻,可以查看该省下属不同城市的销售数量。可见,钻取操作可在不同层次的行政区域间快速切换,即时浏览任一粒度层的销售数量,从而为面向不同区域的销售情况分析提供了全面而灵活的数据支持。
4.2 报表可视化
报表能够以客制化的样式直观展示数据分析的结果,是数据仓库最典型的应用形式之一,本节基于SQL Server的报表设计器实现数据的可视化分析。具体过程如下:
第一,依据报表服务向导创建报表实例。
第二,针对此报表实例,建立共享数据源,用于连接到目标数据库。
第三,定制报表结构,并选择报表类型为“表格格式”。
第四,形成并浏览报表结果。
基于上述步骤,创建的各类报告结果如下:
(1)各个地区的销售统计报表
该报表展示各个地区的销售统计结果,见图8。
图8 各个地区的销售统计报表
Fig.8 Sales statistics report for each region
由图8可见,在澳大利亚新南威尔士州的科夫斯港订单价值在100万以内的销售记录有77条、100—500万的销售记录有6条、500—1000万的销售记录有24条、1000—2000万的销售记录有22条。
(2)订单价值及数量报表
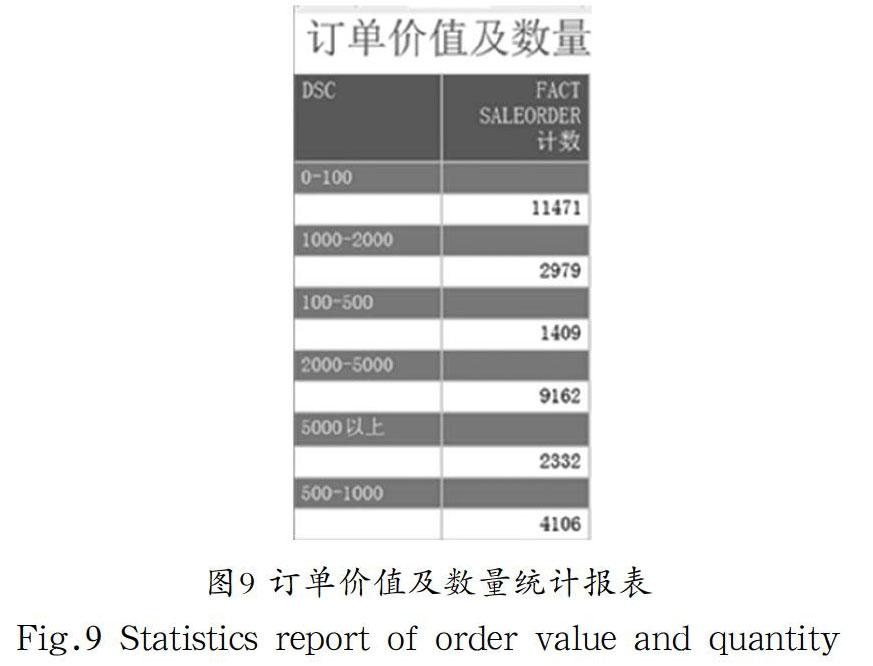
报表展示的是订单价值及数量,见图9。
图9 订单价值及数量统计报表
Fig.9 Statistics report of order value and quantity
由图9可见,订单价值在100万以内的销售记录统计11471条。
(3)订单价值与数量及受教育程度报表
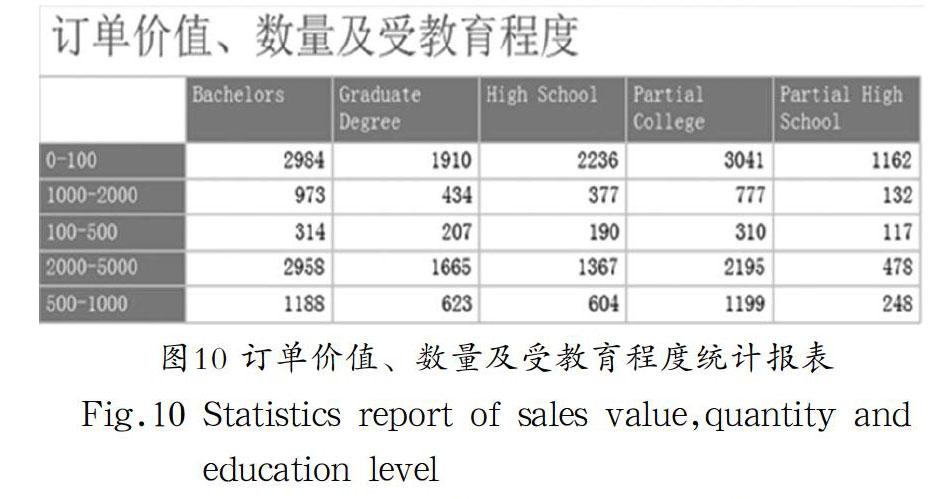
报表展示的是订单价值、数量及受教育程度间的关系,见图10。
图10 订单价值、数量及受教育程度统计报表
Fig.10 Statistics report of sales value,quantity and education level
由图10可见,订单价值在100万以内,顾客受教育程度是高中,订单统计为1162条。
(4)受教育程度与订单数量及价值报表
此报表展示的是受教育程度、订单数量及价值之间的关系,结果见图11。
图11 受教育程度、订单数量及价值统计报表
Fig.11 Statistics report of education level,order quantity and value
由11图可见,从总体上看,在0—100万元价值的订单数量是最多的,100—500万价值的订单数量是最少的。受教育程度为Bachelors和Partial College两类人群的订单数量在所有价值区间中都比较靠前,其中,受教育程度为Partial的人群在0—100万价值的订单数量最多,超了3000笔。
5 结论(Conclusion)
本文阐述了某汽车销售公司数据仓库项目的构建过程,包括源数据准备、建模、抽取等步骤,并从多维分析及可视化报表两个角度展示了该数据仓库能为该公司在管理决策上提供的支持。研究结果表明:数据仓库项目的实施可以有效解决该公司数据海量增长背景下快速提高管理决策水平的需求,为“数据驱动决策”提供了强大、科学的数据支撑。可以预见,数据仓库技术在该公司的发展前景巨大,能给企业带来不可估量的价值与优势,提升企业在市场环境下的综合竞争实力。本文的后续工作将根据企业的需求进一步完善数据仓库的高级技术应用,并在此基础上,探索数据挖掘相关技术在该项目上的运用。
参考文献(References)
[1] 李娜.基于数据仓库的商务智能经营系统设计与实现[J].现代电子技术,2016,39(15):140-144.
[2] 李晓琳.互联网+信息技术应用浅谈[J].农村经济与科技,2016(24):297.
[3] 姜兆龙,金妍,李冬晓.数据仓库测试特性及中国建设银行测试实践[J].中国金融电脑,2018(4):55-62.
[4] 冯强,郑垂勇.商业智能技术在物流企业数据仓库设计中的应用[J].物流技术,2015,34(14):192-194.
[5] 余媛.公交公司运营信息数据仓库的构建[J].汉江师范学院学报,2017,37(6):111-113.
[6] 樊持杰,司巧梅,刘文,等.数据仓库技术在高校突发公共卫生事件预警和控制中的应用[J].信息技术与信息化,2018,218(05):98-100.
[7] 胡馗.基于数据仓库技术的企业信息化管理[J].科技与企业,2016(5):15.
[8] 雷启明.超市数据仓库雪花模型的设计与应用[J].商场现代化,2008(25):40-41.
作者简介:
官 维(1976-),男,本科,讲师.研究领域:计算机网络.
