基于支持向量机的酗酒脑电信号分类研究
2019-12-04丁尚文王纯贤
丁尚文,王纯贤
(1.合肥工业大学基础部,安徽 宣城 242000; 2.合肥工业大学机械工程系,安徽 宣城 242000)
0 引言
饮酒作为一种社会习俗和文化已经流传了几千年。酒文化的巨大作用和影响推动了社会的发展,同时也给社会带来了巨大损失。长期过量饮酒会产生高血压、糖尿病及心脑血管等疾病。高剂量摄入酒精会引发脑细胞毒性水肿,并且长期酗酒会导致脑部形态在额叶、胼胝体等部位发生特异性损伤[1]。
对于过量饮酒危害是否对脑认知功能产生损伤,国内外学者开展了相关研究工作。Michael等采用威斯康星卡片分类对急性饮酒志愿者进行测验,结果表明急性酒精中毒可导致大脑执行控制能力下降,其相应的持续语言功能由于受到酒精抑制而导致语言表达不连贯[2]。谢成娟等对酒精依赖患者进行爱荷华博弈测试(Iowa gambling test,IGT)。试验结果表明,对照组的IGT净得分显著高于酒精依赖组,并推测认为患者的IGT表现受损,可能与眶额叶皮质、杏仁核受损等有关[3]。Ehler等采用脑电(electroencephalogram,EEG)技术研究发现酒精依赖患者在静息态下额叶部位β功率明显高于对照组[4]。刘桂青等[5]对酗酒者脑皮层EEG信号的同步性开展研究,结果发现酗酒者大脑不同区域间的功能连接强度受到一定程度的损伤。Korucuoglu等采用EEG方法研究急性饮酒对脑认知功能的影响,结果发现与安慰剂组相比急性饮酒志愿组的额叶处EEG信号α功率有明显的增强[6]。文献[7]采用的Flanker范式考察被试者在清醒状态和饮酒状态下的事件相关电位(event-related potentials,ERP)的差异性,研究结果发现饮酒会导致前扣带回处的神经活动兴奋,进而使得觉察、认知功能和控制能力下降。
综上分析可以发现,国内外研究人员采用认知量表、EEG技术等研究了酗酒成瘾者脑认知功能损伤问题,研究结果给出了饮酒对脑认知功能产生影响的定性结论。进一步研究期望获得研究个体EEG信号评估特征参数;利用已经获得的评估参数对酗酒者EEG信号识别与分类。
1 支持向量机原理
支持向量机(support vector machine,SVM)是以统计学理论为基础的一种模式分类识别技术[8]。为了对训练数据进行分类,SVM的基本原理就是要寻找一个最优分类面,尽可能使得训练数据中样本间距最大,从而将训练数据分类。最优分类面如图1所示。图1中的虚线表示分类的边界线,在边界线上的向量称之为支持向量。边界线之间的距离称之为分类间隔。

图1 最优分类面示意图
wx+b=0为分类线方程。该方程满足条件:
yi[(wxi)+b]-1≥0

(1)
采用Lagrange求极值方法,利用对偶理论将式(1)中目标函数最值求解问题转化为求下列目标函数最值问题[8]:
(2)
求解式(2)中对偶问题,得到最优分类面的权系数向量以及分类域值为:
(3)
x(1)为式(3)中的训练数据中第一类样本点,x(-1)为第二类样本点。式(4)中的最优分类函数称之为支持向量机,又称之为最优分类函数。
(4)
(xi·x)在式(4)中表示为内积,且(xix)可选用核函数K(xix)替换,核函数的选取满足Merce条件即可,但核函数表达式的不同对SVM分类结果有不同影响。另外,对于训练样本不可分情况,SVM借助松弛变量ξ以判断对训练数据xi的分类程度,惩罚因子C用来判断最小错分样本点个数和分类间隔,最终获得最优分类面。式(4)中的(x1,y1),(x2,y2),…,(xn,yn)为已知训练样本。其中,xi∈Rl,yi∈{+1,-1},i=1,2,…,n。支持向量算法优化的目标函数为:
(5)
s.t.yi(w·xi+b)≥1-ξi,ξi≥0
常用的核函数形式主要有线性核函数、内积核函数、径向基核函数等[8]。
2 数据获取来源
本文分析采用的数据均来自于纽约大学HenriB教授在互联网上公开的EEG数据库。该数据主要涉及的是酒精中毒病人的相关脑电信号数据。试验记录了两组试验对象,即酗酒者和对照组在3种视觉刺激条件下的EEG信号。试验时,按照国际标准在受试者头部放置64导电极,设备采样频率为256 Hz,每次试验记录1 s的数据。试验过程施加单一刺激或者复合刺激。数据采集存放在两个数据集SMNI_CMI_TRAIN和SMNI_CMI_TEST。数据选择:本文数据选择来源于该试验的大数据集(The Large Data Set),受试者包括酗酒者和正常人。各选择10例受试者数据用来测试。从酗酒者和对照组的EEG数据中分别随机选择6段数据作为分析样本,每组试验数据作为训练样本或者测试样本,共计三组数据,分别简称数据1、数据2和数据3。
3 面向酗酒脑电信号的分类技术研究
本文将酗酒者和健康者EEG信号相关参数作为标准,采用SVM方法期望借助评估参数对酗酒者和健康者EEG信号进行分类识别,同时优选出用于识别两类不同EEG信号的最佳评估因子。
3.1 酗酒脑电信号参数选择
能量参数:在EEG节律特征研究中,大多选择特征波的能量这一特征值对信号进行特征识别。EEG信号的低频率节律相关能量E可用式(6)计算得到:
(6)
式中:x(n)为EEG信号的幅值;N为采集到数据点个数。
通过式(6),能够计算出低频率节律波EEG中相关的α、β和θ节律波段的能量[9]。
EEG信号功率谱AR参数:在信号频谱分析方法中,AR谱估计(简称AR模型)由于可用较短时长数据获得较高频率分辨的优点而被研究者广泛使用。AR算法详见文献[10]。该算法是建立在数据基础上的基于自回归系数求解的有效算法。
EEG信号近似熵:Pincus等在研究混沌现象课题时发现熵可以用来描述混沌现象[11],他们利用信号的时间序列复杂度提出了近似熵模型。通过近似熵判断时间序列中新信息发生的可能性,以此判断混沌现象中产生新模式的可能性。近似熵具体算法详见文献[11-12]。
3.2 酗酒脑电信号分类识别结果
将酗酒者和健康者的EEG信号的特征参数集合{‘EEG信号能量参数’,‘EEG信号功率谱AR参数’,‘EEG信号近似熵’}中任意元素作为EEG信号评估参数,将该参数对应的信号数据作为支持向量的训练样本。例如将EEG信号能量值作为训练样本(x1,y1),(x2,y2),…,(xn,yn),xi∈R2,yi∈{+1,-1},i=1,2,…,n。酗酒者的EEG信号能量值标签对应设定为1,健康者的EEG信号能量值标签对应设定为-1。将10例酗酒者和10例健康者的EEG信号能量值数据作为训练样本,对SVM模型参数进行训练和估计。将对应的两类EEG信号能量值各10例为测试样本,分别对应的标签设置为1和-1,具体流程见图2。根据图2算法流程,对EEG数据采用SVM方法(使用libsvm软件包)进行训练和测试。本文选择线性核函数作为SVM的核函数,借助EEG信号不同频率段对应的能量值,将酗酒者和健康者EEG信号分类。

图2 基于SVM的酗酒者和健康者的EEG信号分类流程图
基于不同数据组的测试效果对比如表1所示。
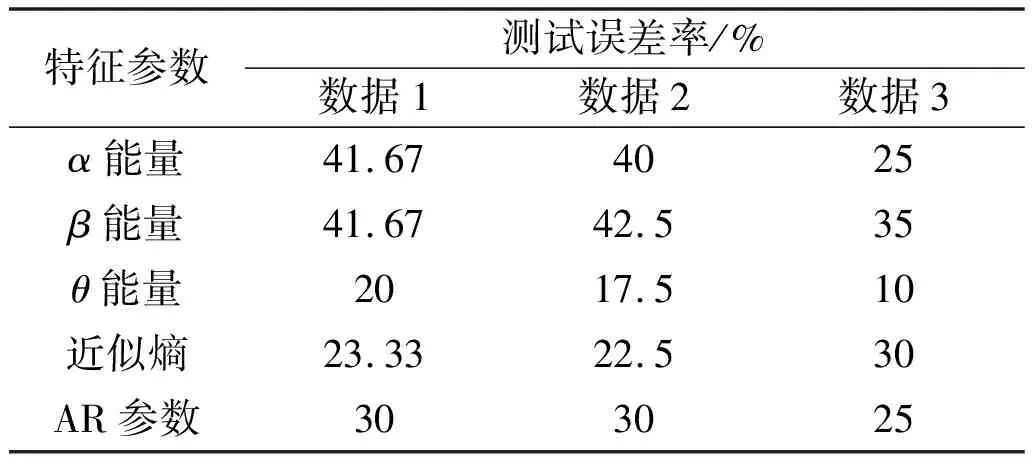
表1 基于不同数据组的测试效果对比
从表1可以发现,采用近似熵、AR参数作为训练样本,能够对酗酒者EEG信号和健康者EEG信号分类识别,测试误差率最小值分别为22.5%和25%。采用α、β和θ能量值作为训练样本,能够对酗酒者EEG信号和健康者EEG信号分类识别,测试误差率最小值分别为25%、35%和10%。对应的基于θ能量评估参数的酗酒者和健康者EEG信号分类结果见图3。通过以上的分类结果比较,可以发现最佳的评估因子为θ能量评估参数,且使用θ能量评估参数采用SVM方法能够对两类不同EEG信号分类识别,识别精度最高达到90%。

图3 第十通道EEG信号θ能量评估参数分类结果图(分类误差10%)
4 结束语
酗酒会对脑认知功能产生严重损伤,国内外研究者采用认知量表、EEG等技术已进行大量的研究,并给出较为可靠的脑认知损伤报告。本文提出基于支持SVM方法的EEG信号自动分类检测技术。本文的工作能够为当前国内外研究机构对酗酒成瘾者评估检测提供技术参考,能够对健康饮酒者是否有酗酒倾向提供辅助检测。
