循环神经网络在端到端语音识别中的应用*
2019-12-04阎艺璇葛万成
阎艺璇,葛万成
(同济大学中德学院,上海 200092)
0 引 言
语音技术逐渐改变着人们的生活和工作方式。在移动设备、智能家居等方面,语音正在逐渐取代鼠标键盘等传统交互方式,极大地提升了人机交互的能力。语音识别是实现人机交互的关键技术。随着人工智能技术的发展,语音识别系统更加精准、强大,大词汇量连续语言识别取得了突破性进展。
20世纪90年代,语音识别的主要进展是引入了鉴别性训练标准和模型自适应方法,基于最大后验概率和最大似然线性回归,解决了HMM模型参数自适应的问题。2006年,Geoffrey Hinton等学者提出了深度置信网络[1](Deep Belief Network,DBN),促进了深度神经网络(Deep Neural Network,DNN)在语音识别中的研究。目前,DNN由于性能上的优势,已经在语音识别领域占据了主导地位。DNN主要有两类神经网络结构,分别是循环神经网络(Recurrent Neural Networks,RNN)[2]和卷积神经网络(Convolutional Neural Network,CNN)[3]。RNN 特别是具有长短期记忆(Long Short-term Memory,LSTM)[4]单元的网络,也开始应用于最先进的语音识别中,并且探索了双向与单向循环神经网络模型在语音识别中的应用。
本文基于TED-LIUM v2语料库[5]建立不同结构的循环神经网络来进行端到端音素识别。第1节阐述了基于连接时序分类(Connectionist Temporal Classification,CTC)的端到端语音识别方法;第,2节建立基于循环神经网络的模型;第3节则是循环神经网络基于TED-LIUM v2语料库的仿真与分析结果;最后是本文的总结部分。
1 基于连接时序分类的端到端语音识别方法
1.1 端到端语音识别方法
端到端方法被引入自动语音识别。在端到端语音识别模型中,不使用明确的语言模型、发音字典和HMM等,过程如图1所示。模型被简化为特征提取、端到端模型及解码器。使用CTC进行端到端语音识别的一个优点,是它能接受输入语音特征与输出字符在序列长度上的差异。

图1 端到端语音识别过程
1.2 连接时序分类
CTC使用单个神经网络对序列进行建模。网络具有一个softmax输出层,输出定义了所有可能的标签序列与输入序列的对齐方式的概率。CTC通过对所有可能的对齐概率求和来获得输出概率。
CTC解码的一种常见方法是前缀搜索解码。该方法通过标签树进行最佳搜索,具体过程如下:令γ(Pn,t)为时间t时网络输出前缀P的概率,使得在t处输出非空白标签;令γ(Pb,t)为时间t时使得输出为空白标签的网络输出前缀P的概率;令集合Y=π∈A´t:F(π)=p。于是,有:

因此,对于一个长度为T的输入序列x,p(p|x)=γ(Pn,t)+γ(Pb,t)。同样地,令p(p…|x)为所有不为p的标签的累计概率,其中p为前缀:

其中φ为空序列。给定足够的时间,前缀搜索解码总是能找到最可能的标签。
2 基于循环神经网络的模型
2.1 循环神经网络
循环神经网络(Recurrent Neural Networks,RNN)是一种神经序列模型,擅长处理序列到序列的问题。理论上,RNN可以把整个先前输入都映射到输出。循环连接允许“记住”先前输入,并将它保持网络的内部状态来影响网络的最终输出。一个包含单个自连接隐层的简单RNN如图2所示。

图2 包含单个自连接隐层的简单RNN
双向循环神经网络(Bi-directional Recurrent Neural Networks,BRNN)可以使用在特定时间帧内过去和将来的可得所有输入信息进行训练。将一般RNN的状态神经元分成两部分:一个为负责正时间方向(前向状态)部分,另一个负责逆时间方向(后向状态)部分。前后向状态的输出和输入互相不连接,形成了如图3所示的BRNN的一般结构,其中该BRNN在3个时间步中展开。通过在同一网络中同时处理两个时间方向,可以直接使用当前评估时间帧的过去和未来的输入信息最小化目标函数,而不需要在一般单向RNN中所述的包括未来信息的延迟。
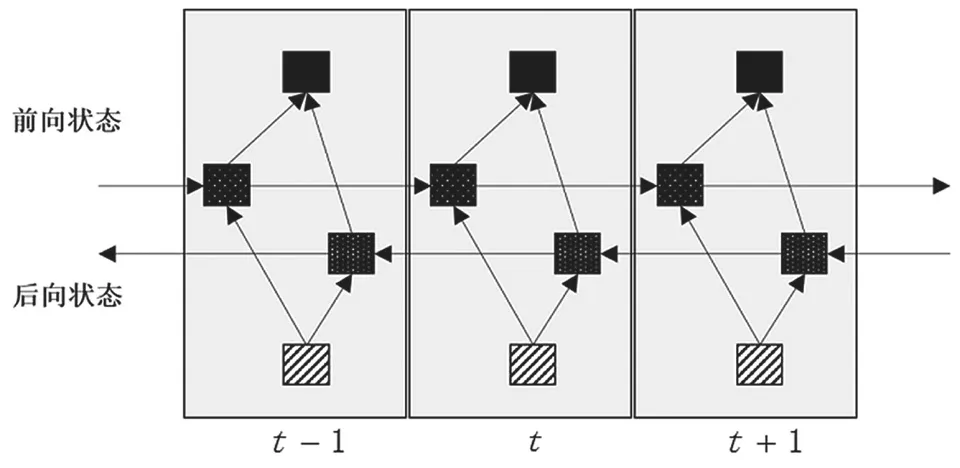
图3 双向循环神经网络的一般结构
2.2 LSTM的结构
长短期记忆(Long Short-term Memory,LSTM)是一种特殊的循环神经网络。具有一个单元的LSTM记忆模块如图4所示。LSTM网络与一般RNN相同,只是隐层中的求和单元被记忆模块所替代。
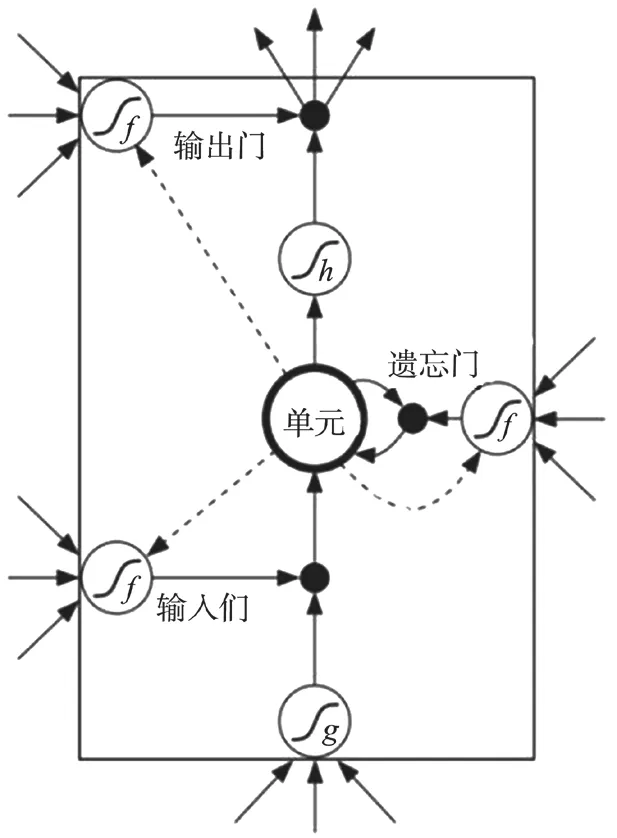
图4 具有单个单元的LSTM记忆块
由图4可知,LSTM由一组循环连接的子网组成,这些子网被称为记忆模块。LSTM的原始形式只包括输入门和输出门。遗忘门及窥视孔的权重被添加到LSTM的结构中,从而得到了扩展的LSTM。每个模块包含一个或多个自连接记忆单元以及3个乘法单元——输入门、输出门及遗忘门。
在双向循环神经网络中使用LSTM作为网络结构,就形成了双向LSTM(Bidirectional Long Shortterm Memory,BLSTM)。BLSTM可以在两个输入方向上访问远程上下文。展开的BLSTM层的结构包括一个前向LSTM层和一个后向LSTM层,如图5所示。前向层输出序列ht通过使用迭代从时间T-n到T-1的正序输入计算得到,后向层输出序列ht通过使用从时间T-n到T-1的反向输入计算得到。前向层和后向层输入都使用标准的LSTM更新公式计算得到。BLSTM层生成一个输入向量YT,其中每个元素都使用式(4)计算得到:

其中σ函数被用于连接两个输出序列。它可以是一个串联函数、求和函数、平均函数或乘法函数。
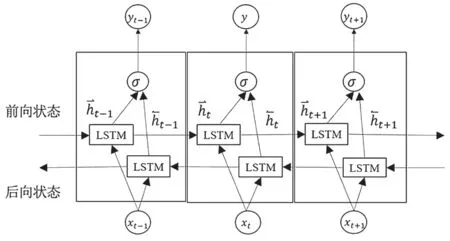
图5 有3个连续时间步的BLSTM展开结果
3 仿真与实验结果
3.1 不同结构的循环神经网络结合CTC
实验数据集使用TED-LIUM v2语料库。实验中,将84 719条语音作为训练集,505条语音作为开发集及1 144条语音作为测试集。用于评估音素识别中不同网络结构的性能指标,采用音素标签错误率(Phoneme Error Rate,PER)。PER越小,语音识别性能越好。实验中,使用如下4种循环神经网络结构结合CTC进行端到端音素识别模型的建模:单向RNN网络(URNN),有4层隐层;双向RNN网络(BRNN),有3层双向隐层,每层具有一个前向和后向层;单向LSTM网络(ULSTM),有4层LSTM隐层;双向LSTM网络,有3层双向LSTM隐层,每层具有一个前向和一个后向层。通过训练得到不同网络结构的学习曲线,如图6所示。
由图6可知,BLSTM网络除了训练周期需要的更少外,取得了相对更好的性能。开发集上的学习曲线不稳定,意味着随着训练周期的增加,训练的网络模型在开发集上并没有取得越来越好的性能。相对来说,BLSTM在开发集上的PER的整体趋势是下降的。
表1总结了不同网络结构在训练集和测试集上最终的PER。双向网络即BLSTM和BRNN在训练集上的识别结果较好,然而比起单向网络,双向网络在测试集上的识别性能远远不如在训练集上的识别性能。这意味着双向网络存在过拟合问题。与RNN相比,LSTM更容易过拟合。对于BLSTM,仅20个训练周期后,识别性能就会下降。从表1来看,BLSTM取得了这4种网络结构中最好的音素识别性能,其在训练集上的PER为33.8%,在测试集上的PER为41.3%。这可能是由于BLSTM能够利用额外的上下文信息而不必必须记住之前的输入。但是,BLSTM在训练集和测试集上的PER存在较大差异,意味着生成的模型存在过度拟合。
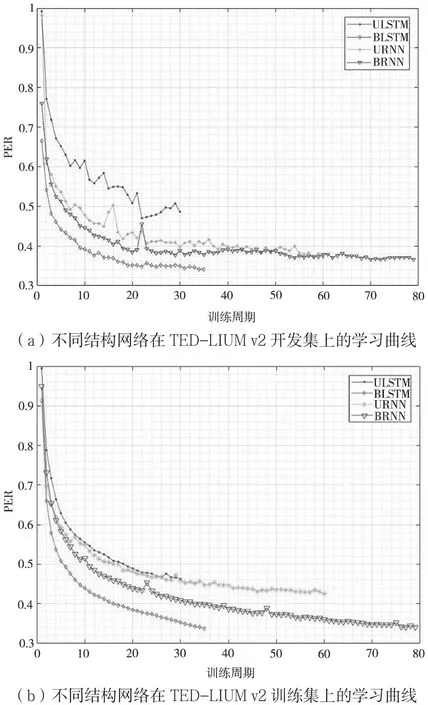
图6 不同结构网络在TED-LIUM v2开发集和训练集上的学习曲线
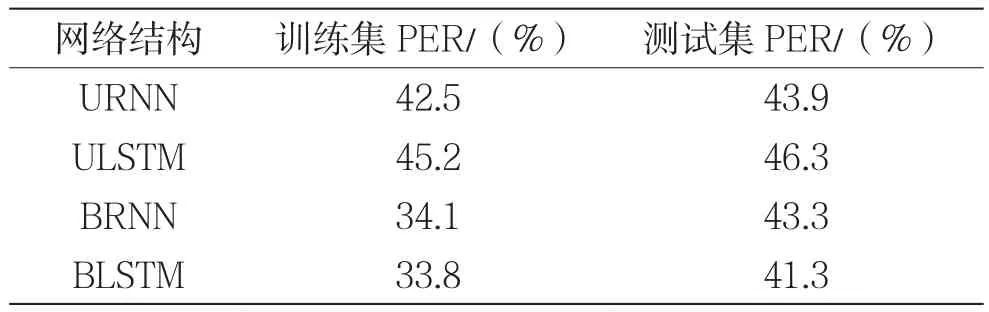
表1 不同结构的循环神经网络在训练集和测试集上的PER
3.2 采用dropout的双向LSTM
Dropout是指在深度学习网络的训练过程中,将一些输入层或者隐层节点的值置为0,防止节点之间的相互适应,有效防止大规模的神经网络的过拟合问题。由3.1节可知,BLSTM模型存在过度拟合。因此,实验将状态dropout应用于BLSTM网络训练。采用具有3个隐含层的BLSTM,每层都包括各有320个隐藏单元的前向层和后向层,将dropout率(dropout rate)设置为0.5、0.75、0.8,比较其对BLSTM-CTC在音素识别上性能的影响。
从图7可以得出,采用相同结构但采用不同dropout率的BLSTM网络,在音素识别上的性能不同。采用dropout率为0.75的BLSTM网络比采用dropout率为0.5和0.8的BLSTM网络学习更快,且在训练集上取得了更好的PER。从图7可以看出,在开发集上的学习曲线虽然有波动,但总体趋势趋于下降,且dropout率为0.75的BLSTM在开发集上取得了最好的PER。

图7 采用不同dropout率的BLSTM在TED-LIUM v2开发集和训练集上的学习曲线
表2总结了采用不同dropout率的BLSTM在训练集和测试集上的PER。dropout率为0.5的BLSTM网络学习最慢,且在测试集上的PER最大。可能的原因是更小的dropout率会减慢训练速度并导致欠拟合。因为dropout率的取值范围在0和1之间,若已经在过去很远的LSTM的求和单元乘以非常小的dropout率,那么它也将被有效地从求和单元中移除。这样即使BLSTM具有长期依赖性的学习能力,也无法在测试阶段利用学习到的长期依赖性。相较于dropout率为0.75的BLSTM网络,dropout率为0.8的BLSTM网络在测试集上的PER略高。出现这种结果的可能原因是,当dropout率较大时,并不能对足够多的单元进行dropout,从而改善BLSTM的过拟合问题。

表2 采用不同dropout率的BLSTM在训练集和测试集上的PER
4 结 语
本文的研究工作初步探讨了使用不同结构的循环神经网络对语音识别中的声学模型进行建模。通过音素错误率比较不同结构的循环神经网络在音素识别任务上的性能,分析可能的原因。本文的主要结论是,基于TED-LIUM v2语料库进行训练时,BLSTM作为一种循环神经网络结构,由于能够访问更多上下文信息,因此在音素识别中具有更好的性能,而采用dropout进行网络训练能有效改善过拟合问题,从而提高模型的泛化能力。
