基于全局K-means算法的高校学生成绩分析
2019-11-23谷欣超徐福祥杨勇曲福恒
谷欣超,徐福祥,杨勇,曲福恒
(1.长春理工大学 计算机科学技术学院,长春 130022;2.长春师范大学,长春 130032)
在当代大学中,成绩对于学生非常重要,分数高可以为评选奖学金评选加分,也可以在找工作时,比其他人更加容易吸引招聘公司的注意力,所以,为了提高高校学生学习成绩,应该对学生成绩进行分析,从中挖掘出影响学生成绩的主要因素,针对学生的缺点培养学生,为学生构建一套合理且高效的教学方法。常用的成绩分析方法包括聚类分析[1-2]方法、决策树算法、关联规则等。聚类分析方法是目前最具应用前景的成绩分析方法之一,该方法的优点在于其结论形式简明、直观,容易从中发现隐含的规律。K-means[3-4]算法是一种重要的聚类算法,由McQueen在1976年提出。K-means算法的目标是将N维的M个点划分为K个簇,使准确率和召回率达到最大值。K-means算法主要有两个缺点:(1)对簇的数目进行先验固定;(2)随机选择初始聚类中心。本文将全局K-means算法应用于成绩分析中,全局K-means算法改进了初始类簇中心的确定过程,减少了初始聚类中心的筛选对于K-means算法产生的负面影响。应用于学生成绩分析中,能够得到更加准确的聚类效果。
1 聚类分析方法
在学生成绩分析[1]中主要应用聚类分析[5]方法。常用的聚类分析方法包括K-means[6]算法、K-中心点[7]、OPTICS[8]、FCM[9]算法和 SOM[10]算法等。聚类分析是将大量的数据对象,按照数据之间性质的差异,分成多个类或簇,每一个类簇中的数据具有较高的相似度,不同类簇之间,存在一定的差别。聚类分析方法主要分为四种方法,在文中简单介绍基于划分和基于层次的两种聚类方法。
基于划分[11]的聚类方法,能够实现同一类的数据点之间的距离足够近,不同类的数据点之间的距离足够远的聚类效果。首先确定要划分的数据种类K,然后选择几个聚类中心,作为初始划分;在此基础上,依据预先确定的启发式算法对数据进行迭代重置,最后获得K类数据以实现算法预计的聚类效果。该方法中常用于成绩分析的算法包括K-means算法、K-medoids[12]算法等。
基于层次[13]的聚类方法,其主要原理是先将每个对象看作一个簇或类,然后将这些簇或类进行合并,得到较大的簇或类,所合成的类簇达到算法设定的结束条件后停止。通常,层次聚类属于凝聚型层次聚类,簇间相似度的定义决定了类与类之间的差异。层次聚类的主要优点在于不需要预先定义聚类数,在聚类时,能够发现数据之间的层次关系。这一聚类方法的缺点在于计算量太大,而且在聚类的过程中会聚类成链状。
2 全局K-means聚类
K-means算法是目前最常用的聚类算法之一。该算法主要的优点在于容易实现且高效,能够得到局部最优解;但缺点也很明显,需要聚类的对象数目越多,收敛速度越慢,而且传统的K-means算法在聚类过程中,使用随机选择的初始聚类中心,随着迭代过程的进行,会产生明显的聚类偏差。K-means算法可以将数据中相似的对象归到同一集群中,且K-means算法不受集群对象的限制。对象的性质相似性越高,算法的聚类效果越好。在使用K-means算法进行聚类分析时,先随机选择K个点,作为初始聚类中心;然后将其他数据点划分到距离K个初始聚类中心最近的簇中,完成一次迭代过程;每次迭代后,计算每一类数据点的均值,更新类簇中心。重复前两步操作,直至得到的聚类中心点不再变化,则完成聚类过程。
本文使用一种全局K-means算法分析学生成绩。全局K-means算法是在K-means算法的基础上,改进了初始聚类中心的选择过程,优化传统的K-means算法。全局K-means算法的主要原理是基于递增来实现全局最优化。该算法选取的聚类中心点不需要依赖于初始值,而是计算已知聚类中心点与其他数据点的聚类平方误差函数值,然后选择函数值最小的数据点,作为下一簇最佳初始聚类中心。在全局K-means算法中,一次迭代过程需要运行N次(N表示数据量)K-means算法搜索数据集,以找到一个数据点使聚类平方误差函数值最小,并将此数据点作为下一个簇的初始聚类中心。而K-means算法使用随机选取的初始聚类中心点,随着迭代过程的进行,聚类结果中产生的聚类误差会越来越大。全局K-means算法以牺牲时间为代价,为每一个簇选择最佳的初始聚类中心点,减少了迭代过程中产生的聚类误差。
全局K-means聚类算法,简化了聚类过程,将一个问题,划分成多个子问题。该算法使用一种增量的方法,在每一次迭代过程中计算下一个簇的初始聚类中心点。其算法描述如下:
Step1[初始化]计算出样本集的质心,将其作为第一个最佳聚簇中心,设置i=1;
Step2[结束条件]i=i+1,当i> K 时,算法终止;
Step3[查找下一簇最佳初始聚类中心]当前已知 i-1个最佳聚类中心,为m1,m2,…,mi-1,可以将剩余样本作为最佳聚簇中心,然后计算它们与已知的i-1个最优聚类中心的误差平方准则函数。使此函数最小的样本点,被选为第i个最佳聚簇中心,即 K=i的最佳聚类中心为b1,b2,…,bi-1,运行K-means算法。误差平方准则函数如下:
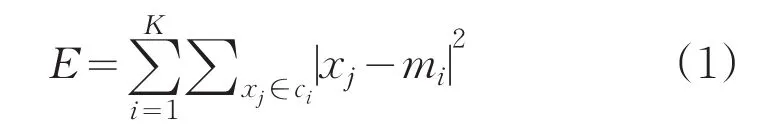
Step4 让 mj=bj,j=1,2,…,i,转到Step2;
全局K-means算法的流程图如图1所示。

图1 全局K-means算法流程图
3 聚类有效性
聚类有效性[14],是指使用聚类有效性评价函数评估每次迭代过程中聚类效果的方法,来衡量算法的聚类效果的优劣。本文使用I Index[15]聚类有效性验证指标作为聚类有效性函数,来衡量全局K-means算法在高校学生成绩中的聚类效果。I Index指标通过计算各聚类中心距离的最大值,来度量组间的分离度;使用聚类中各成员与聚类中心点的距离之和度量组内的分离度,且I Index取值愈大,则分组效果愈佳。I Index主要原理可以由公式(2)表示:

式中,M表示聚类数;s表示第i聚类组的法向单位向量;CMi表示第i聚类的中心向量;d(s,CMi)表示向量s和CMi的欧几里得距离。
4 基于全局K-means的学生成绩分析
全局K-means算法是在K-means算法的基础上,改进了K-means算法选择初始类簇中心的过程,减小了算法聚类的偏差,能够得到更加准确的聚类结果。鉴于全局K-means算法的原理和特点,采用全局K-means算法分析学生的表现,从而获得简洁、直观、准确的聚类结果。此外,在全局K-means算法的聚类分析过程中,聚类个数需要提前确定,为解决此问题,本文使用I Index有效性函数,衡量算法在不同聚类数情况下聚类效果的优劣,选择对应于最优聚类结果的聚类数来对学生成绩进行分析。
基于全局K-means算法进行学生成绩分析的具体流程如下:
算法输入:待聚类数据集X={x1,x2,…,xn},xi∈RD(1,2,…,N)
算法输出:最佳聚类数M及聚类中心(k1,k2,…,kbest)。
(1)初始参数:生成聚类数的搜索范围[1,Mmax],令M=1;
(2)设置终止条件:令M=M+1,若M>Mmax,则完成迭代过程;
(3)使用基于全局K-means算法将X聚类为M类,并得到聚类中心点(k1,k2,…,kbest);
(4)利用聚类中心点(k1,k2,…,kbest)求出聚类数M对应的(2)式中的有效性指标I(M)的值。
(5)选择最大的有效性指标对应的聚类数M,作为最佳聚类数。
本文选择处理的数据为某校学生四个学科的期末成绩,人数100人,其中部分数据如表1所示。

表1 100名学生四个学科期末成绩
将所有学生数据以csv文件存储,在程序中读入csv文件,使用基于全局K-means算法对数据进行聚类分析,得到聚类数、聚类中心以及聚类中的样例数,如表2所示。
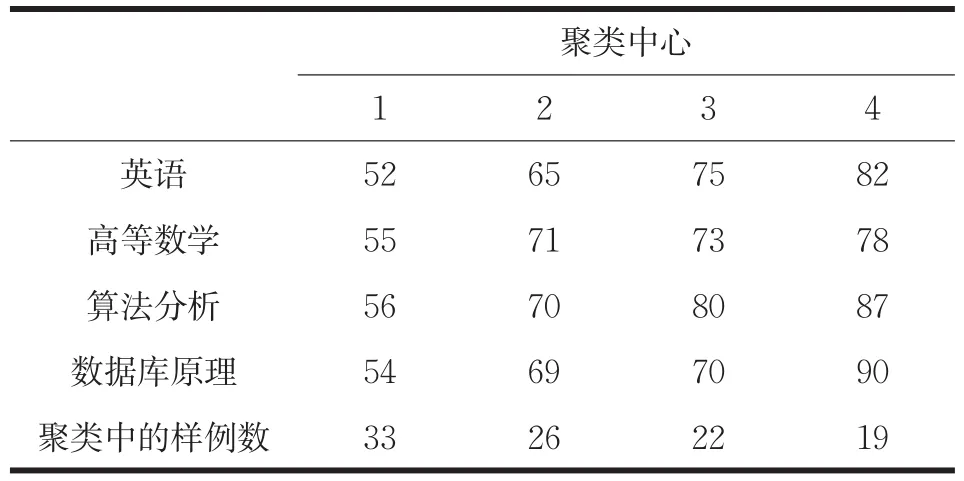
表2 100名学生四科期末成绩初始聚类中心(保留整数)及样例数

图2 聚类分析结果柱状图
根据表2和图2可以看出,算法将100名学生的四门课程成绩分成四类。四类结果在分数上表现出了很明显的层次感。在聚类中心1中,课程成绩均偏低,且低于其它三类,但与同组数据相比,差异相对较小。聚类中心2、3处,课程成绩属于中等及偏上层次,每一聚类中,课程成绩相近。聚类中心四中,总体成绩高于其他三个聚类中心。所以,根据上表结论,针对聚类中心1中的学生,应该修改教学方法,并可借鉴聚类四中学生的学习方法,培养学生,让其在自己成绩较差学科中找到更加适合自己学习方法。并且,针对有些同学部分课程成绩较高,但存在成绩非常低的课程,学校应该针对这类偏科的同学,设计针对性的培养方案,让其能在偏科的科目中发现感兴趣的知识,以此引导该学生主动去发现、去学习。
为了对比全局K-means算法与传统的K-means算法的聚类效果,对两种算法在进行学生成绩聚类分析时的聚类中心坐标和簇内平均距离进行对比,如表3所示。
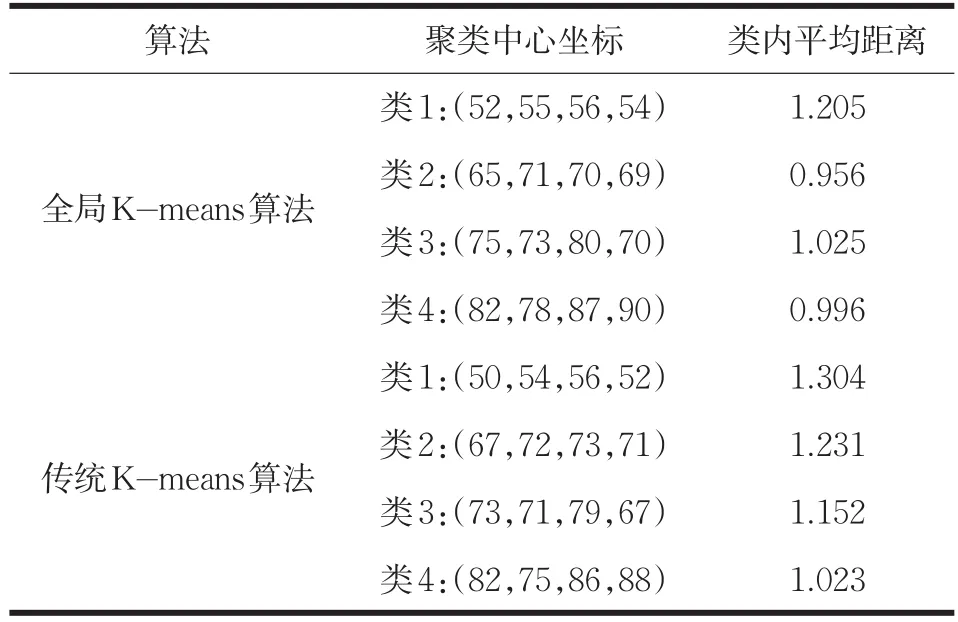
表3 算法参数对比
对比试验主要比较两种算法的类内平均距离,以达到对比聚类效果的目的。两种算法进行对比试验使用的数据为某校学生四个学科的期末成绩,人数100人。通过表3能够知道,使用全局K-means算法对学生成绩进行聚类分析时,类内数据的平均距离要小于传统K-means算法的类内数据的平均距离,说明利用全局K-means算法进行聚类分析得到的聚类结果中,数据之间的距离更近,数据的分布更加紧密。所以全局K-means算法的聚类效果要优于传统的K-means算法。
5 结论
学生成绩分析作为评价学生学习方法、学习态度的一个重要过程,衡量学校教学质量的主要方法,随着教育信息化的发展,实现高效、准确的学生成绩分析,对于学生成绩评价,具有非常重要的应用价值。本文使用全局K-means算法与I Index算法相结合,来执行无监督的学生成绩分析,且聚类个数由聚类有效性指标自动确定。在实验中,通过对100名学生的四门期末成绩进行实验,验证了算法的可行性,得到了简明直观的聚类效果,并且聚类算法对学生成绩的分析结果反应出学生当前的学习计划以及学习方法不当。可以通过对学生成绩的分析,为了提升学生成绩,制定更加合理的学习计划和教学方案。
