基于信息扩散与聚集的脱机手写字符重心定位方法
2019-11-21王寅同王燕清肖文洁
王寅同,王燕清,肖文洁
(南京晓庄学院 智能信息处理重点实验室,江苏 南京 211171)
0 引言
脱机手写体文本识别是目前文字识别领域的最困难问题之一[1-4],与联机手写识别相比,缺少必要的字符位置和轨迹信息,其中后者可以根据字符位置和书写经验来近似获得,因此字符位置的判定对脱机手写体文本识别效率的影响甚大。脱机手写字符书写随意性导致相邻字符之间的位置关系复杂性,造成脱机手写体文本中的字符位置定位要比印刷体字符定位难得很多,尤其是行倾斜、不规则行片段以及粘连字符的文本中的字符位置判定[5-7]。
目前脱机手写文本的字符位置判定主要是由字符切分来实现,常用的切分技术有基于统计的切分方法、基于字形结构切分和基于识别的汉字切分方法等。其中,基于统计的切分方法是根据字符的总体统计分布特征,确定字符之间的界线,判别时以字符的平均字符宽度作辅助判别,统计分布特征的代表性和稳定性对切分的正确性及收敛性起很重要作用,如投影法(Project Methods,Pros)和连通域法(Connected Components Method,CCs)[8-9],这些方法适合汉字字符间距较宽,无粘连字符的切分,尽管算法效率高,但不能适用于粘连或交叉字符串的切分。基于笔划结构切分是一种很有潜力的切分方法,可以从另一个角度解决笔画粘连问题。常见的笔画分割方法有笔画连接盒的动态算法和黑游程跟踪提取笔画算法两种[10-13]。有学者提出采用先提取笔画再合并的方法,但该方法对汉字切分的好坏很大程度上依赖于笔画提取的好坏,其主要应用障碍就在于准确提取笔划难度较大。如何有效地提取笔划信息仍有待进一步研究。此外笔画先提取后合并使算法过于复杂。基于识别的字符统计切分方法是将字符切分和识别视为整体,切分后的字符送入相应分类器并获得一个分类结果,再由分类结果反作用于字符切分,从而获得更有效的字符切分效果,这一过程不断地迭代,直至满足某一终止条件[12,14-15]。该方法结合了前两类方法的优点,能获得更好的字符切分效果,但对于有限的时间和空间资源下获得字符切分结果的情况却是不适用,时间复杂度和空间复杂度远超过前两类方法。
与上述字符切分相比,脱机手写字符重心定位方法具有自身的独特之处,即将字符轨迹上的像素点视为信息源,每个信息源以某种方式进行信息扩散与聚集以形成文本图像的信息矩阵,再由信息矩阵的局部峰值分析获得字符重心定位。该方法既可以准确地得到单个字符在文本图像中的位置,又可以由字符重心来区分单体、左右或上下结构的字符。对于倾斜文本行、不规则文本片段以及粘连字符的脱机手写体文本,字符重心定位方法能够快速准确地区分不同字符,进而为后续的单或多字符识别以及非显著切分式文本识别提供有力的支持。为此,本文做了如下三个方面的工作:(1)基于连通域分析法进行文字高度估计,多个离散位置的像素点进行连通域分析以获得对应文字或部首的连通区域,能够避免单一像素点所产生的连通导致字符高度估值偏差;(2)基于信息扩散的文本图像信息量矩阵,该矩阵的局部峰值对应汉字重心位置,而信息量低谷区分不同字符。(3)信息量矩阵的局部峰值分析,将信息量的局部峰值位置或区域的中心设置为对应字符的重心以完成字符重心定位这一目标。
1 脱机手写字符重心定位方法
对于脱机手写体文本图像而言,图像的二维数组表示形式为X={xij}a×b,其中i和j分别代表图像的第i行和第j列;xij代表图像的第i行j列上的像素值,二值化处理后的像素取值为0或1;a和b分别代表脱机手写文本图像的高和宽。
1.1 实现原理
重心是在重力场中物体处于任何方位时所有各组成质点的重力的合力都通过的那一点。在脱机手写体字符重心定位研究中,字符重心可以理解为字符中所有像素点合力作用下的点[16]。字形对称的字符重心是其所在区域的中心位置。反之,字形不对称的字符重心将偏向于笔迹像素点密集的一侧。与真实物体重心性质不同,真实物体的重心不一定在物体上,如一根弯曲的竹子重心往往偏向于内弧侧,而单个字符重心则处于字符所占区域中,该区域是由字符的最左、最右、最上和最下四个极值位置的像素点共同确定的。因此,脱机手写体字符重心可以用于定位不同字符在文本图像中所对应的位置。
图1给出了脱机手写体文本的字符重心定位流程图,主要包括脱机手写文本图像预处理、字符高度估计、信息量矩阵构造和信息量局部峰值分析四个方面。对待识别的脱机手写体文本图像进行预处理能够减少噪声信息对后续识别效率的影响;运用连通域分析法进行字符高度估计,并将其作为一个自适应变量,它与文本图像的字符大小直接关联;运用信息量传递方式构造脱机手写体文本的信息量矩阵,形成笔迹像素点的信息聚集;运用信息量矩阵的局部峰值分析以完成字符重心定位。
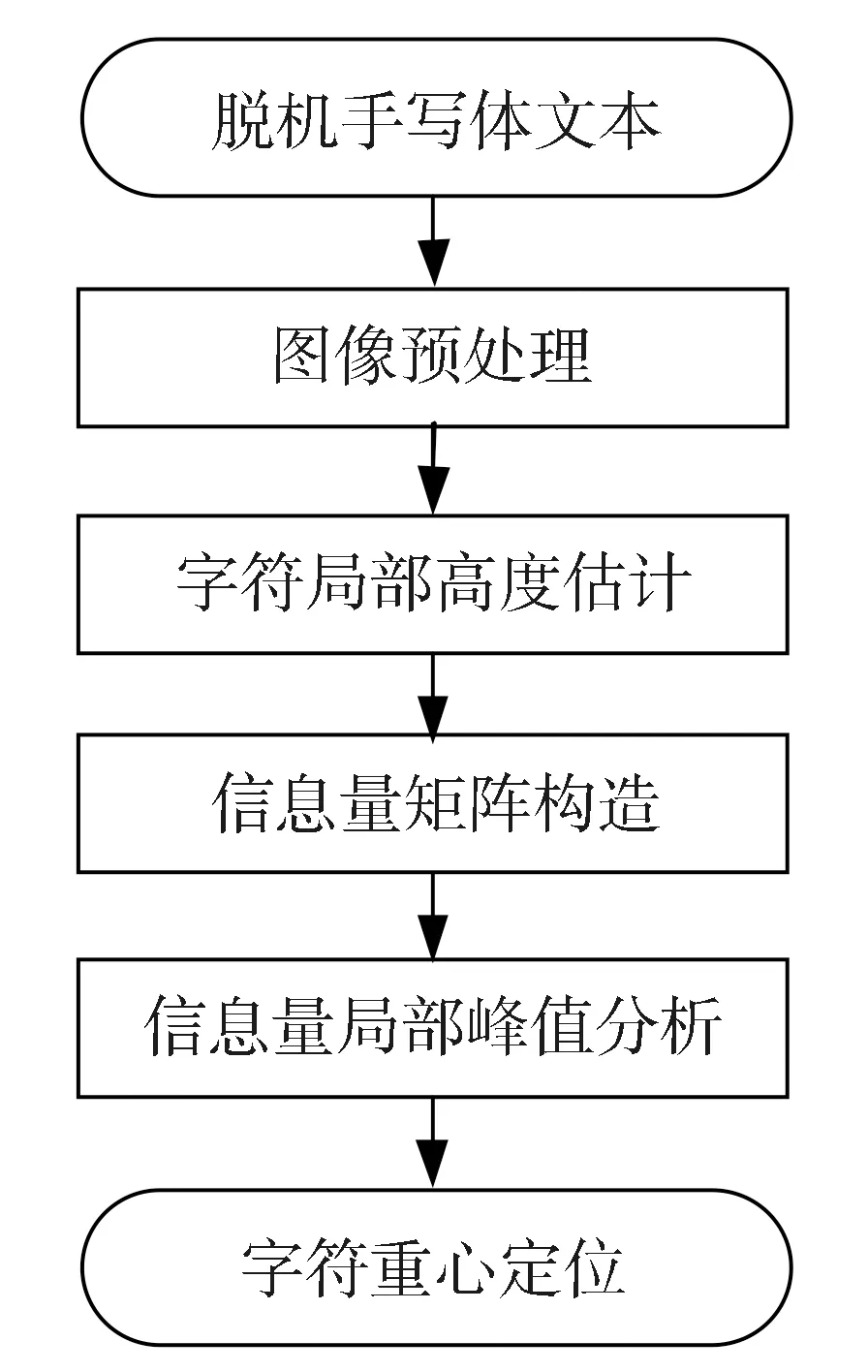
Fig.1 Flow chart of the offline handwritten character centroid localization图1 脱机手写字符重心定位流程图
本文的研究重点在脱机手写文本字符重心定位问题,即对待识别的脱机手写体文本图像进行预处理能够减少噪声信息对后续识别效率的影响。考虑到脱机手写体文本图像来源的多样化,如扫描仪、照相机、手持移动等设备,对这些设备获得的彩色或灰度图像进行图像灰度化、背景色移除和图像二值化等操作,完成字符与背景分离。进一步地,可以对二值化图像进行滤波去噪声信息处理,以降低噪声信息对字符重心定位的影响。
1.2 基于连通域的文字高度估计
基于连通域的文字高度估计能够自适应不同文本的字符高度或同一文本不同区域的字符高度,避免固定字符高度对脱机手写字符重心定位的不利影响。字符高度h作为一个自适应量,与脱机手写文本图像的字符大小存在直接关联。为了更好地运用连通域分析法进行字符高度估计,给出相邻像素点和连通域概念,其中前者中每个像素点存在八个相邻像素点(除边缘位置),分别处于该像素点的左、右、上、下、左上、右上、左下和右下八个位置;后者中每个连通域是由若干个笔迹像素点组成的序列,该连通域的高度是由最上方的笔迹像素点位置与最下方的笔迹像素点的位置之差。
运用连通域分析法进行文字高度估计,具体步骤如下:步骤一:以文本图像的左上角和右下角为极限位置,随机选择k个位置点,即{(x1,y1),(x2,y2),…,(xk,yk)},其中k≥10;步骤二:获取每一个随机位置点的最邻近笔迹像素点,当该位置点的像素值为1,则最邻近像素点为自身。对第i个随机位置点(xi,yi)而言,最邻近笔迹像素点(xi,yi)应满足如下条件:
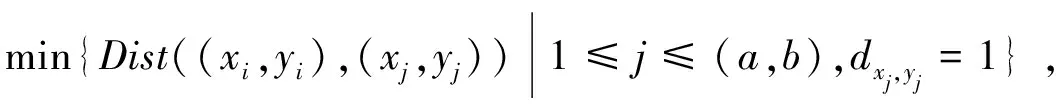
(1)
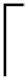
1.3 基于信息扩散与聚集的信息量矩阵构造
信息量扩散与聚集方式构造脱机手写体文本的信息量矩阵,设第i行j列非零值的像素点xij含有的信息量为1个单位,对近邻像素点的信息传递量info与它们的距离dist成反比,其中信息传递量与距离的函数关系info=fun(dist)可以采用一次函数、二次函数和对数函数等,本文实验的信息传递量与距离设定为二次函数关系。像素点xij信息传递影响的最远像素距离为k,即该像素点收到像素点xij信息传播量为0或无穷等于0。为此,对像素点xij构造大小(2k+1)×(2k+1)的影响力矩阵info(2k+1)×(2k+1),其中infok+1,k+1=1代表像素点xij对自身信息传播量为1个单位,而对其邻近k范围内的像素点xi′j′的信息传递量infoi′,j′=fun(disti′j′)。
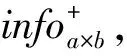
(2)
其中infoi,j表示2k+1行2k+1列矩阵,info+(i±k,i±k)表示矩阵info+的第i-k到i+k行、第j-k到j+k列的子矩阵,将信息量矩阵info+对应位置的值加上infoi,j并更新。另外,图像X边缘像素点的信息量化需要特别处理,如第1行1列的像素点x1,1仅对处于其第四象限的像素点发挥作用,以及第a行b列的像素点xa,b仅对处于其第二象限的像素点发挥作用。
1.4 信息量矩阵的局部峰值分析
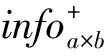
(3)
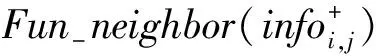
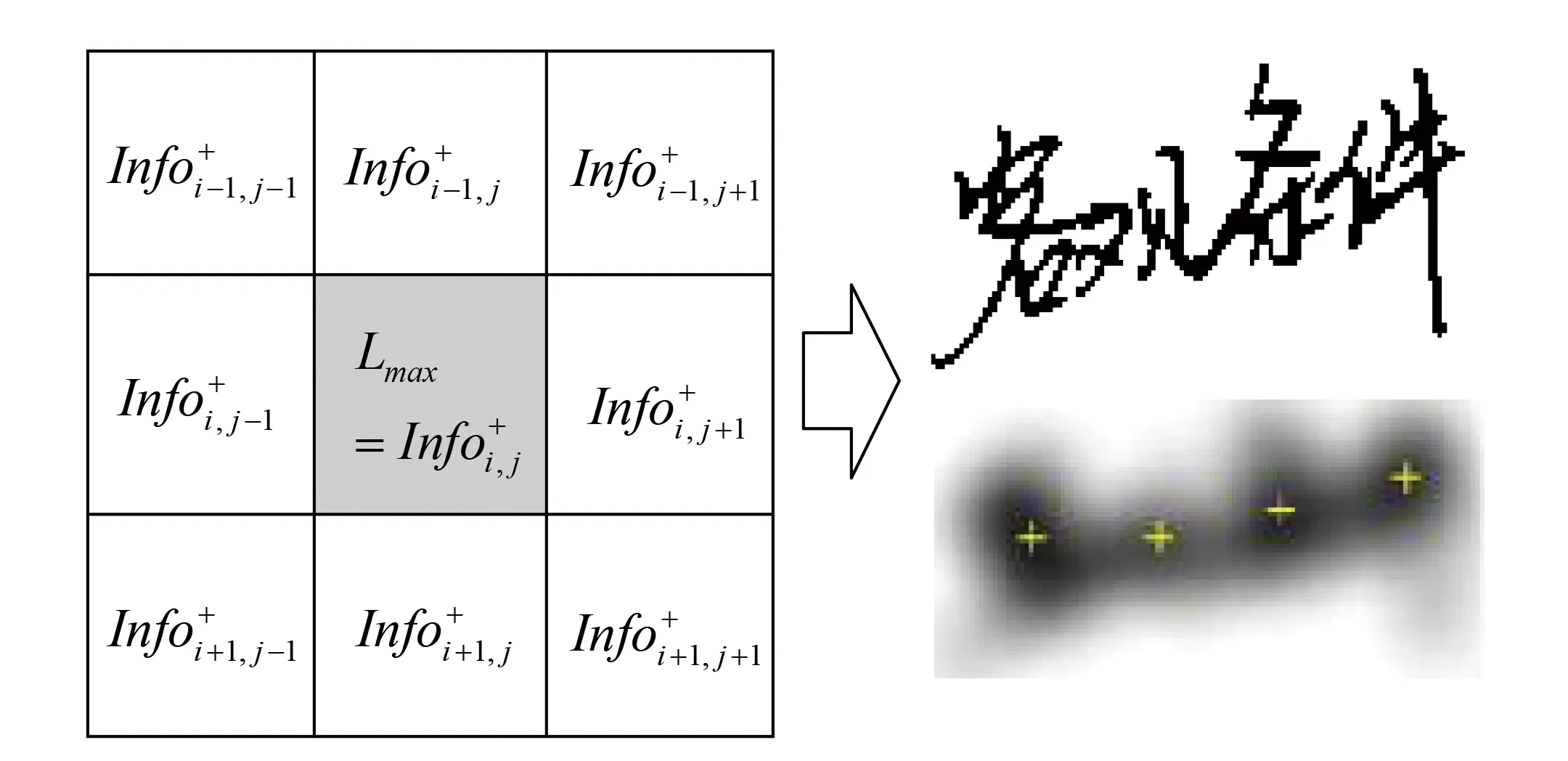
Fig.2 Information quantity relation between local peak and nearest neighbor pixels图2 局部峰值与最近邻像素点的信息量关系
1.5 算法实现
基于信息传递与聚集的脱机手写字符重心定位的算法实现主要包括脱机手写文本图像预处理、基于连通域的字符高度估计、基于信息扩散与聚集的信息量矩阵构造和信息量矩阵的局部峰值分析四个部分。OHCCL算法的输入是待处理的脱机手写文本图像X,字符高度估计的随机数k;输出是字符重心定位数据Y。具体实现内容如下:
算法1 基于信息扩散与聚集的脱机手写字符重心定位方法
输入:脱机手写文本图像数据X={xij}a×b,字符高度估计的随机数k
输出:字符重心数据Ya×b
Step 1 脱机手写文本图像预处理,对脱机手写文本图像X进行灰度化、背景色移除和二值化等预处理,降低噪声信息对字符重心定位的影响。
图3脱机手写字符重心定位执行效果图,从图中可知,这份学生纸质答题试卷的书写工整、字迹清晰,但是存在字符粘连、文本行倾斜和零散等问题。图3(a)脱机手写文本原始图,存在深色背景色;图3(b)已完成预处理之后的脱机手写文本图像,字符笔迹与文本背景的颜色分别为黑色和白色;图3(c)运用了信息扩散与聚集的脱机手写文本图像的信息量矩阵,图中颜色由白色至黑色代表了对应位置的信息量由少到多的对应关系,其中字符重心偏向于图中颜色最深的位置;图3(d)运用了信息量矩阵的局部峰值分析所得到的字符重心,实心圆点代表了字符重心位置。

Fig.3 Offline handwritten character centroid localization demonstration图3 脱机手写字符重心定位的执行效果图
2 实验结果及分析
2.1 实验数据集
HIT-MW数据库由哈尔滨工业大学计算机学院开发,该数据库由780多名书写者在无监督的情况下书写完成,优化出合格的手写样本853份,其中无监督情况是指在书写参与者与数据库收集者并不发生正面接触,通过邮寄等方式将数据库页面交与书写者,书写者按照自己习惯的书写规则在一块未经分格的区域书写题签上标注的内容,允许出现涂改、文本行倾斜和交叠等复杂手写现象[17]。HIT-MW数据库中的手写体样本不是按照孤立的汉字书写,而是按照一定的规则从《人民日报》上随机抽取的一段200字左右具有一定含义的文字。
2.2 实验设置
脱机手写字符重心定位方法通过字符笔迹像素点的信息量扩散与聚集以获取脱机手写文本中的字符重心,投影法(Pros)[7]和连通域法(CCs)[8]作为两种参与比较的经典字符重心定位方法,其中投影法实现字符重心定位的前提是文本的行信息已知。由于手写风格、文本排版和字符结构等差异,导致OHCCL方法获得单字符的重心数目存在不确定性,大体上可以归为四类,即“0重心”“1重心”“2重心”和其他。“0重心”代表字符重心定位失败,未能准确获得对应字符重心;“1重心”代表获得对应字符重心且唯一;“2重心”代表获得对应字符重心的数目等于2;其他代表获得对应字符重心的数目大于等于3。考虑到中文字符的单一结构、上下或左右结构,脱机手写字符重心定位的准确率由“1重心”和“2重心”共同决定。对于给定的脱机手写体文本而言,“0重心”的字符数为m0,“1重心”和“2重心”所对应的字符数为m1,其他情况所对应的字符数为m2,那么脱机手写文本的字符总数目n=m0+m1+m2,字符重心定位的准确率定义为:
(4)
字符重心定位的丢失率定义为:
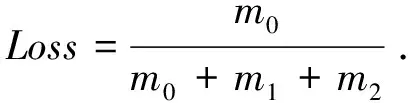
(5)
2.3 实验结果
从表1可知,Pros和CCs的中文字符重心的定位准确率分别为85.31%和91.55%,而OHCCL方法对中文字符重心的定位准确率达到98.70%,丢失率率仅为0.32%,定位准确率提升了15.70%和7.81%。在数字字符的定位准确率上,Pros和CCs准确率分别为87.80%和94.23%,OHCCL方法在数字定位的准确率为94.82%。由于各个标点符号在不同行的相对位置及与字符或数字的间隙差异,CCs取得了最优标点符号的定位准确率,其值为95.58%,Pros和OHCCL标点符号的定位准确率分别为81.04%和95.14%。
中文字符具有“外圆内方”的特征,有利于字符笔迹像素点的信息量聚集以获得对应字符的重心,但也存在部分结构复杂的中文字符获得了过多的字符重心,即其他情况为0.98%。数字字符和标点符号的笔迹信息量少和非规范的书写风格也放大他们的字符重心定位的丢失率,对应的丢失率分别为5.18%和4.86%。

表1 HIT-MW字符重心定位结果(%)
3 总结与展望
针对脱机手写文本的倾斜文本行、不规则行片段和粘连字符等问题,提出了一种基于信息扩散与聚集的脱机手写体字符重心定位方法,该方法通过字符笔迹像素点的信息传播方式实现信息聚集形成局部峰值而相邻字符之间产生信息量低谷,字符重心设为信息量的局部峰值位置或区域的中心。该方法的优点是在字符重心定位过程中摆脱了文本行概念的束缚,减少了倾斜文本行的纠正、不规则文本行片段的规整以及连笔字符的过切分等操作,使得脱机手写字符重心定位的步骤更简洁且贴近实际应用。本文所实验的数据集规模还较小,下一步工作是扩大真实数据集的规模、形成公开学生答题试卷数据集并深入研究脱机文本结构分析与识别。
