基于多分类支持向量机和主体延伸法的基音检测算法
2019-11-20冯起斌李鸿燕
冯起斌,李鸿燕
(太原理工大学 信息与计算机学院,山西 晋中 030600)
0 引 言
基音周期是语音信号的一个重要特征参数,能否准确地估计基音周期的大小在语音识别和分离、说话人识别及跟踪等语音处理应用中有着至关重要的作用。基因检测的典型方法包括自相关函数法、倒谱法、小波变换法、线性预测法,以及在此基础上衍生的多种算法[1-3],这些算法可以在无噪声或高信噪比环境下检测出被测语音的基音周期。但是,随着信噪比的降低,基音的线索会受到极大的干扰,导致算法在低信噪比境下不再适用。因此,低信噪比环境下的基音估计问题成为近年来该领域的热点研究课题。
为在低信噪比环境下获得较好的基音检测效果,很多算法都采取了相应的措施,例如近几年提出的PEFAC 法[4-5],该算法可以压缩抑制部分噪声,因此在低信噪比环境下能保持一定的基音检测率,但是随着噪声强度的增加,语音信号的谐波结构遭到破坏[6],完整的基音周期变得难以分辨,使得检测效果变得不尽人意。
分类算法相较于回归预测在基音周期的估计中对语音要求少,使用更加灵活。支持向量机(Support Vector Machine,SVM)追求在有限的信息条件下获得最优的结果,有着很强的非线性分类能力。在解决小样本、非线性及高维模式识别中表现出许多特有的优势[7],非常适用于语音的处理。
针对低信噪比环境下的基音检测问题,本文提出一种基于多分类支持向量机的基音检测算法,该算法提取语音信号的对数频域信息作为特征,通过支持向量机多分类器对带噪语音的频域信息与对应基音周期之间的非线性映射关系进行建模;通过优化参数对其进行训练,从而减少噪声的影响,并利用主体延伸法选取出最合适的基音曲线,完成基音检测。
1 算法描述
本文提出的基于多分类支持向量机的基音检测算法,可以分为模型训练、获取基音候选值和产生基音估计曲线三个部分。图1为该算法的原理框图。

图1 基于多分类支持向量机的基音检测算法原理框图Fig.1 Principle diagram of pitch detection algorithm based on multi-class support vector machine
1.1 特征提取
当读取一段语音文件时,最初常常获得的是语音信号的波形图,这种时域特征所含信息冗余巨大,且并不能直接反映该语音基音的本质特征,将其直接用作分类特征时,不但耗时,而且会影响分类效果。因此,本文选取信号的频域特征作为分类依据[8]。
将待处理的语音信号通过短时傅里叶变换到频域,第t帧信号在频率f处的功率谱密度为Xt(f),表达式如下:
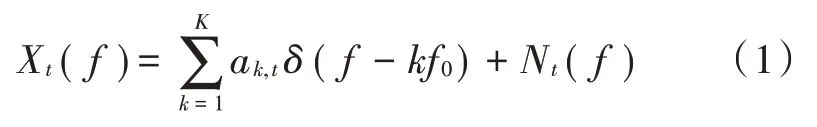
式中:ak,t代表第t帧信号的K个谐波中第k个谐波的能量;f0为该帧信号的基音频率;Nt(f)表示该帧信号所含噪声的功率谱密度。将得到的功率谱密度函数转换到对数域,表示为Xt(q),其中q=logf,按式(2)进行规整化处理:

式中:L(q)表示长时平均语音谱为第t帧经过平滑后的平均语音谱;而为规整化处理后的对数域功率谱密度。为了增强其谐波特性,将规整化后的功率谱密度通过一个扩展峰值的滤波器,滤波器定义为:

式中:α用于控制峰值宽度;选取β使得K为滤波器捕获的谐波数。

式中,Yt(q)包含基音的相关信息,可以根据峰值的大小及其位置来估计基音周期的大小,若被测语音信号信噪比较高,则Yt(q)会在q=logf0处产生最大值。
然而,在低信噪比环境下,很难在噪音的干扰下寻找出代表基音的峰值。针对此问题,本文以卷积结果Yt(q)为基础,使用多分类支持向量机从中计算出该帧语音可能的基音大小作为对应的基音候选值。
由于语音信号在短时间内有一定的相关性,为了提高检测准确率,将第t帧结果与附近两帧合并,所得结果即为最终提取到的特征:

1.2 模型训练
1.2.1 SVM 模型构造
最基本的SVM 是为寻求两类线性可分样本间的最优分类面而提出的,本文选择的SVM 分类器是在其基础上发展来的C-SVM 分类器[9]。该分类器用核函数K(xi,x)将线性不可分的样本映射到高维空间,并在这个新空间中寻找样本的分类超平面,而对无法用直线完全正确划分的近似可分问题,C-SVM 用惩罚参数C表示对错误分类的惩罚程度。用有l个样本的集合T=训练 C-SVM,其中xi∈Rn,代表第i个样本的数据值,yi是第i个样本的标签,训练公式如下:

式中,ai为第i个样本的 Lagrange 乘子,对式(6)求得最优解从中选取一个分量使得:
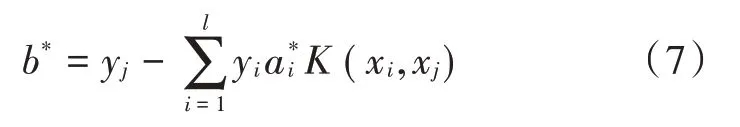

最后得到决策函数:

对C-SVM 分类器来说,惩罚参数C和核函数中参数γ的选择是能否取得满意分类效果的关键。γ过大会造成过学习问题,过小则会产生欠学习问题,C的大小则会影响SVM 的经验风险和置信区间之间的平衡。
本文使用网格寻优方法在有限的范围内寻找到合适的参数C以及γ的大小,主要过程是参数C以及γ以一定的间隔进行取值然后各选一值进行组合,在n×m种组合结果中取令分类结果最佳的一组为最终的参数寻优结果。
单个的SVM 分类器只能解决二分类问题,在解决多分类问题时,需要将多个二值SVM 分类器按一定方法组合构成多类分类器。在本文中,将多个C-SVM 分类器以一对一的形式进行组合,构成SVM 多分类器,如图2所示。
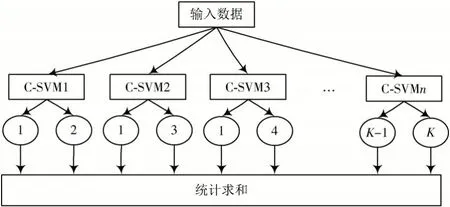
图2 一对一SVM 多分类器构成示意图Fig.2 Structure diagram of one-to-one SVM multi-classifier
对于一个K分类的问题,需要个二值SVM 分类器,每个分类器对两种类型进行投票,最后得票数最多的种类即为输入样本所属的种类。
1.2.2 C-SVM 多分类器的模型构造及训练
首先确定分类范围及类型。人类说话的基音可信范围60~400 Hz,是一个连续的范围,故在作为分类结果时要先进行量化处理。误差在大小相同的情况下,对低频区的影响要远远高于高频区,因此在低频区量化点数比较稠密,而在高频区则相对稀疏。现用每8 度24 个频点[10]将整个基音可信范围量化为67 个状态,即s1,s2,…,s67。其中第m个状态对应的基音频率是Hz,加上清音状态,记作s0,共计 68 个状态作为SVM 分类器的分类结果。
在实验的训练阶段,将提取到的特征值作为输入数据,每帧所对应的标准基音频率作为输出进行训练,得到训练好的SVM 多分类器模型。
1.2.3 获取基音候选值
对于一个待估计的语音信号,进行分帧处理后通过特征提取模块以降低其与基音无关的冗余。将每帧信息所对应的特征输入到已构造并训练好的C-SVM 多分类器模型中,这种一对一多分类器将会对所有可能的基音状态进行投票,取得票数最多的三个状态作为该帧信号基音的候选值,即第t帧所对应的基音候选值是这三个基音候选值所获得的票数由大到小排列,即该帧信号基音状态是Z1(t)的可能性最大,其余两个的可能性依次减少。
1.3 主体延伸法
获得基音候选值后,本文采用一种主体延伸的方法,结合帧与帧之间的时序信息,在候选基音中选取合适值连接起来作为被测信号的基音状态估计曲线。
由于语音在短时间内可以看作是稳定的,即语音的清浊交替不会在很短的时间内完成多次,因此当判断的清音段和浊音段比较短时,可以认为这段时间内,基音的判断并不准确。因此,以可能性最大的Z1(t)为基础,进行基音状态曲线的勾画。首先从整条测试语音的第1 帧开始向后寻找连续的清音段或是浊音段,如图3中的段 1 到段 5 所示。

图3 主体延伸法示意图Fig.3 Schematic diagram of main body extension method
选取长度大于40 ms 的浊音段和长度大于70 ms 的清音段作为主体。设段1、段3 和段5 满足上述条件,被认为是主体。然后依照主体向后延伸,直到下一个主体,第一个主体(即段1)还需要向前延伸,延伸部分应与主体性质保持一致。
当主体为一段清音序列时,在延伸过程中将遇到的浊音序列认为是被误判作浊音帧的清音帧,予以修正。而当主体是一段浊音帧时,在延伸过程中遇到的清音序列需要通过其余基音候选值进行修正。若从第t帧开始需要修正,则修正方法如下:

式中:A(t)为第t帧的基音估计状态;而A(t-1)则为前一帧的基音估计状态。通过上述步骤可以将零散的基音候选值连接成基音状态估计曲线,经过反量化处理后获得基音估计曲线,反量化公式为:

式中,B(t)为第t帧信号的基音估计值,单位为Hz。随后通过三点平滑处理,使得每帧之间过渡更加合理,最终得到被测信号的基音估计曲线。
2 实验结果与分析
本文训练及测试时所使用的纯净语音来自于TIMIT 标准语音库(http://www.fon.hum.uva.nl/david/ma_ssp/2007/TIMIT/),从中选取一条语音,将其与人声babble 噪声、机械噪声和粉红噪声分别按-5 dB,0 dB,5 dB 三种信噪比进行混合,将这些带噪语音及纯净语音共10 条语音作为训练组进行特征提取,训练模型。另选取三条语音,按照按20 dB,10 dB,5 dB,0 dB,-5 dB,-10 dB 这六种信噪比与上述三种噪音进行混合,所得的18 条语音信号作为测试组对算法进行检验。使用Praat 语音学软件提取出纯净语音的基音频率作为标准,将其进行量化处理,分别与上述10 条语音的特征一一对应作为SVM 分类器的输出进行监督学习。
本实验使用网格寻优算法寻找合适的C和γ的大小,使得被训练数据在三折交叉检验下获得最高的分类准确率。为了提高寻找效率,网格以指数形式设计,在2-12~20之间寻找合适的γ,在 20~210之间寻找合适的C,两参数步进大小都为指数增长,例如C在网格中的取值是20,21,…,210。以此网格进行参数寻优,所得的交叉检验准确率如图4所示。

图4 交叉检验准确率Fig.4 Accuracy rate of cross check
实验结果表明,在C=29,γ=2-11处获得最高的分类准确率为96.13%,且在附近网点处变化平缓,故可作为取得的最佳参数。
完成多分类SVM 模型的构造后,利用所得的模型以及被测语音的特征值罗列出可能的基音候选值,使用主体延伸的方法从中选出最终的基音估计值,图5为使用本文算法对测试组中的一条纯净测试语音进行基音估计的结果。

图5 本文算法的基音检测结果Fig.5 Pitch detection results of the proposed algorithm
为了检验本文算法的有效性,采用两个评价指标:基音频率检测正确率R1和浊音判断错误率R2,作为客观评价标准。对于某一帧信号估计的基音频率与真实基音相差小于5%,则认为该帧的基音估计正确,反之错误。
基音频率检测的正确率R1表示为:

式中:N表示基音判断正确的帧数;M表示总帧数。R1越大,表示算法性能越好。
浊音判断的错误率R2为被错误判断的语音帧占语音总帧数的百分比,表示为:

式中:W1表示被错判为非浊音帧的帧数;W2表示被错判为浊音帧的帧数。R2越小表示清浊音判断的准确性越好。
将本文算法与PEFAC 算法以及主体延伸法这两种基音估计算法进行比较。主体延伸法先用语音信号的能熵比检测元音主体,再从自相关函数的峰值中动态规划出基音曲线。PEFAC 算法利用滤波器压缩抑制噪声,并从信号的频域信息中计算基音周期的大小。表1列出了三种算法在不同信噪比下的基音频率检测正确率。实验结果表明,R1的大小与信噪比成正比例关系。主体延伸法在高信噪比环境下检测结果良好,但无法在低信噪比状态下正常工作;而本文算法和PEFAC 算法在低信噪比甚至是负信噪比环境下仍能取得较好的检测结果,且相比于PEFAC 算法,本文算法提高了约5%的正确率。在训练SVM 多分类器时,虽然只在-5 dB,0 dB,5 dB 三种信噪比的环境下完成了对模型的构造;但测试结果表明,本文所提的算法在-10 dB 的环境下仍优于其他算法,同时在高信噪比环境下也有较好的检测效果。
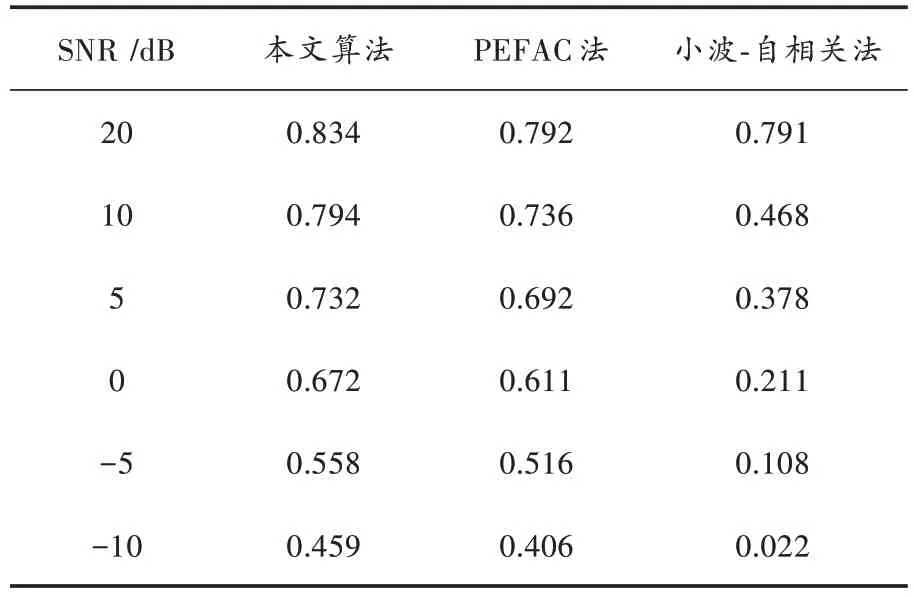
表1 不同算法的基音频率检测的正确率Table 1 Accuracy of pitch frequency detection of different algorithms
一个优秀的基音检测算法不仅可以达到较高的基音检测正确率,同时也能很好地区分清浊音片段,为进一步验证本文算法对语音清浊音判断的准确性,将本文算法与PEFAC 算法以及主体延伸法进行比较。
表2表示三种算法在不同信噪比环境下的浊音判断的错误率。可以看出,相比其他两种算法,本文算法的浊音判断错误率最低,这意味着它能够更好地区分清音片段与浊音片段。

表2 不同算法的浊音判断的错误率Table 2 Error rate of dull resonance judgment of different algorithms
实验结果表明,相比PEFAC 算法和主体延伸法,本文所提的基于多分类支持向量机和主体延伸法的基音检测算法具有更好的效果。
3 结 语
在低信噪比环境下对语音信号进行基音估计一直以来都是一个实用却颇具难度的问题。本文提出一种基于多分类支持向量机的基音检测算法,将被测信号的功率谱密度函数转化到对数域后,通过一个扩展峰值的滤波器,所得结果作为特征参数,然后利用该语音信号的特征以及其标准基音周期对SVM 多分类器进行监督训练。利用训练后的分类器模型对含有不同强度、噪声的语音信号进行基音检测,获得的基音候选值使用主体延伸法进行处理,并经过平滑处理后最终完成基音检测。
仿真结果表明,本文所提算法可以适用于多种信噪比环境下的基音检测,其基音检测率以及浊音判断率都有一定的提高,系统的稳定性也得到了提高。
