机会移动社交网络中基于群组构造的数据分发机制
2019-11-15王兴伟
李 婕 洪 韬 王兴伟 黄 敏 郭 静
1(东北大学计算机科学与工程学院 沈阳 110819) 2(东北大学信息科学与工程学院 沈阳 110819)
随着移动互联网的迅速发展,人们通过移动智能终端获取大量各种形式的网络资源,而目前移动设备接入互联网的形式主要是通过基站,这样就大大增加了基站的流量负载,同时也增加了通信运营商对基站设备资金和技术的投入.在基础设施部署困难或者不完善的场景中,移动设备之间的通信就变得极为困难.针对以上问题,一些特殊的网络已被提出,如无线传感器网络、移动自组织网络[1]等.机会移动社交网络(opportunistic mobile social networks, OMSNs)[2]作为结合网络节点移动属性和社会属性的特殊移动自组织网络,能够很好地契合特殊场景下的网络环境,卸载部分基站的流量负载,近年来机会移动社交网络成为研究学者们关注的热点.
机会移动社交网络利用网络节点的移动性带来的接触机会实现近距离的无线数据传输,其具有非持续性连接、时延长、能耗大等网络传输特性,使机会移动社交网络的应用得到一定程度的限制,目前机会移动社交网络的研究面临的挑战性问题有:如何寻找到一条中断容忍、低时延、低能耗的数据传输路径;如何充分利用节点的移动性和社会性特征提高网络性能;如何避免节点自私性而增强网络整体性能.针对这些挑战性问题,本文提出了基于群组构造的数据分发机制(data dissemination mechanism based on group structure, DDMGS),该机制主要有4方面贡献:
1) 充分挖掘机会移动社交网络中节点的移动特性和社会关系特性,确定节点重要性、兴趣相似度和通信关系紧密度,构建节点关系度量模型;
2) 由于基于位置关系的拓扑结构具有周期稳定性,基于兴趣关系的拓扑结构具有长期稳定性,而基于通信关系的拓扑结构具有动态性,因此依据这3种行为属性关系构成的网络拓扑特征设计了3种群组构造算法;
3) 基于不同的行为属性关系构成的群组结构设计了数据分发机制,引入节点缓存区管理机制提高传输性能,引入合作博弈理论来规避节点的自私行为,降低传输能耗,促进节点协作,提高整体网络性能;
4) 验证并评估了DDMGS的性能,与机会移动社交网络中的主要数据传输算法在消息传输成功率、平均传输时延、平均跳数、数据分发开销比率等性能评价指标上进行了对比和分析,验证了DDMGS的有效性.
1 相关工作
目前,数据分发机制按照消息传输方式的不同大致分为四大类:基于洪泛的数据分发机制[3-6]、基于上下文感知的数据分发机制[7-9]、基于编码的数据分发机制[10]、基于群组的数据分发机制[11-14].由于机会移动社交网络的节点具有社会属性并且会自然地形成各种群组,所以充分利用节点的社会特性便成了机会移动社交网络的重要研究内容之一.文献[11-12]分别提出了经典的数据分发机制SimBet和Bubble Rap,这2种算法均考虑到节点的社会性.随后很多基于群组的数据分发机制相继被提出.文献[13]考虑到机会移动社交网络拓扑的动态性,提出在机会移动社交网络中存在一个嵌套的核心外围层次结构(nested core periphery hierarchy, NCPH),即加权度大的一些节点组成网络核心,同时网络周边由加权度小且不活跃的一些节点组成,当外围节点被迭代移除时,NCPH仍被保留,并利用网络的这种特征提出一种上下路由协议,即路由分为上传阶段和下载阶段,该路由协议在数据传送延迟和比率方面实现了优越的性能,并且具有较低的转发成本.文献[14]中作者提出一种基于社区和社交性的组播数据分发机制,引入动态社交特征的概念来捕获节点的动态连接行为,考虑了更多的节点之间的社会关系,采用社区结构来为每个节点选择最佳的中继节点从而提高多播机制的性能.该文中提出了2种基于社区和社交性的多播算法:第1种是基于社区及社会特征的组播算法Multi-CSDO(community and social feature-based multicast involving destination nodes only),它只涉及到社区发现中的目标节点;第2种被称为Multi-CSDR(community and social feature-based multicast involving destination nodes and relay candidates),它涉及社区发现中的目标节点和候选中继节点.文献[15]关注于群组的移动性和群组外形,提出一种算法可以根据若干移动设备的移动性以及它们所组成的外形高概率地判断这些移动设备是否是属于一个群组.文献[16]是有关D2D通信的研究,它通过判断某一设备进组是否会提升本组吞吐量来进行设备筛选,完成群组构造,提升了D2D通信的吞吐量等性能指标.文献[17] 考虑OMSNs 中节点间存在周期性相遇的特点设计了基于节点周期性相遇的数据分发机制,并通过实验对比验证了相对于传统DTN路由机制在数据分发成功率上的提升.
由此可以看出:在机会移动社交网络中考虑节点的社会属性和群组结构能够有效地提高数据分发效率.但目前的研究存在不足有:没有考虑节点的多方面社会属性,例如没有充分考虑节点的移动轨迹对数据传输的影响;并且未考虑由节点不同的社会关系构成的网络拓扑是有区别的,所以导致群组结构单一,群组划分与实际情况差距较大;未考虑由于节点自身的资源受限而出现的自私行为.因此,本文提出的基于群组构造的数据分发机制,根据节点的移动性特征、节点重要性、节点间兴趣相似度和节点间通信关系紧密度等多维社会属性设计了不同的群组构造机制,并引入合作博弈理论,加强节点之间的协作,通过与传统路由机制的对比实验论证了本文所提出的数据分发机制的可行性和有效性.
2 网络模型
由于机会移动社交网络的拓扑结构是动态变化的,所以每个时刻网络的拓扑都是不同的,为了对节点移动模型进行直观的描述,本文将机会移动社交网络某时刻的“快照”作为网络模型.将机会移动社交网络中的用户抽象为节点,其在网络中可以自由移动;节点可以选择和其通信范围内的任意节点进行通信,或者拒绝通信;由于节点的能量存储和缓存空间都是有限的,所以网络在某一时刻会存在拒绝转发数据的节点;节点之间采用Bluetooth,WiFi直连通信等近距离通信方式进行数据传输,节点只有处于相互通信范围内时才能进行通信,本文假设各节点通信半径相同.用户间的联系抽象为边,即将网络建模为图G(V,E),其中V={v1,v2,…,vn}表示用户的标识集合,E={e1,e2,…,el}表示用户间的关系.如图1所示,如果2节点间存在兴趣或者通信等关系,则2节点间存在1条无向边,边上的权重w(i,j)代表节点i和j之间某种关系的紧密程度.
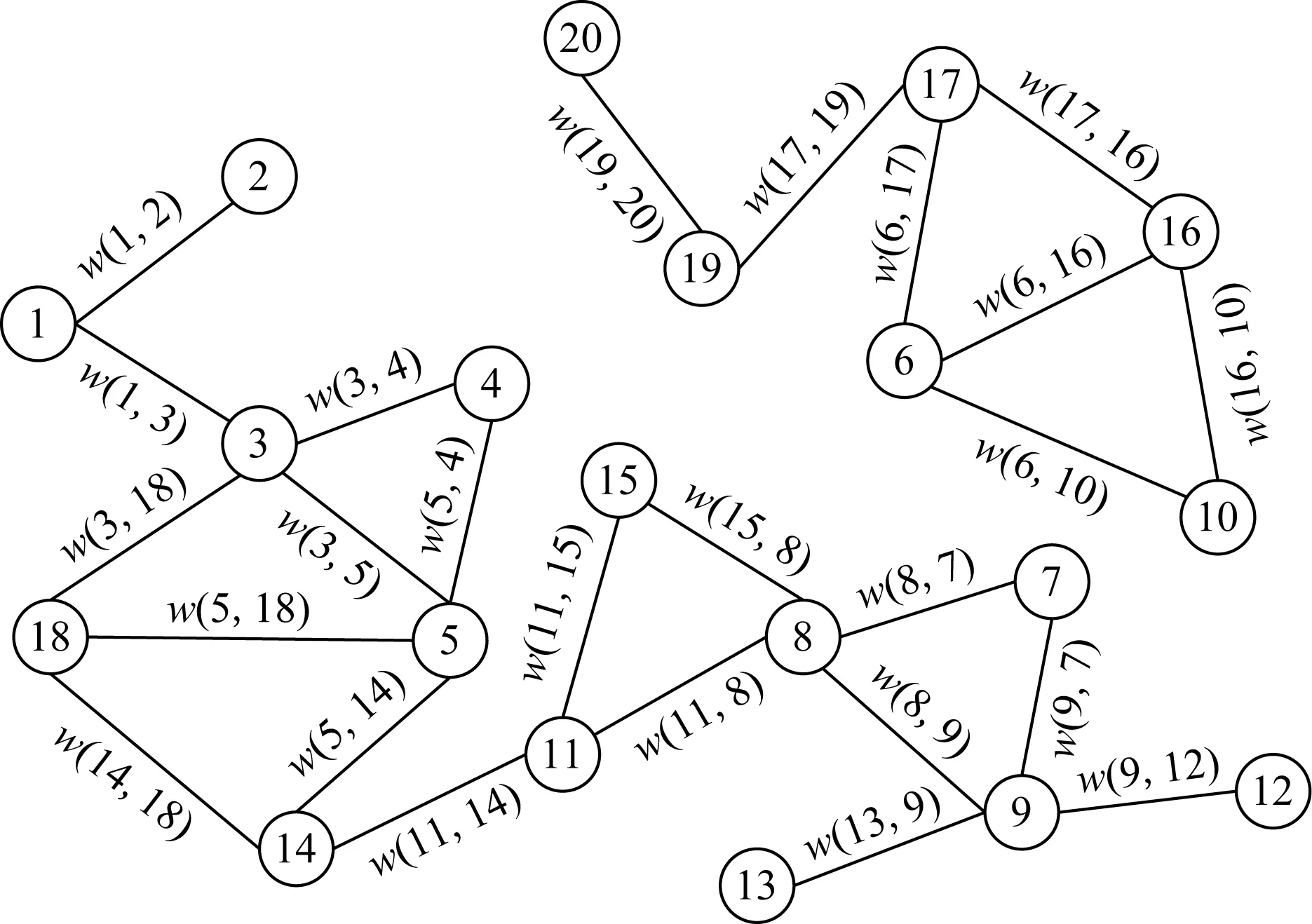
Fig. 1 Topology of the opportunistic mobile social network图1 机会移动社交网络拓扑
3 算法设计
本文根据户节点的位置关系、兴趣和通信关系等移动特征和社会特征对节点重要性、兴趣相似度和通信关系紧密度进行定义和建立度量模型,基于3种节点关系度量对节点进行群组构造.在构造群组基础上,利用节点的群组属性,对节点之间的合作博弈建模,引入缓存管理机制,设计基于群组结构的数据分发机制.
3.1 基于位置关系的群组构造方法
1) 移动模型
在OMSNs中,节点的移动模型影响节点在数据传输过程中的时延和成功率等性能.目前为止,经典的随机移动模型,由于其节点的速度和移动方向都是随机的,不太适用于机会移动社交网络.文献[18]提出了一种基于校园社区的移动模型(campus based mobility model, CBMM),该模型分析了用户的日常行为特征,重点关注节点之间的间隔联系时间和联系时长的分布,很好地呈现了节点的社会特征.本文将该移动模型与基于地图最短路径的移动模型(shortest-path map based movement, SPMBM)结合,给出基于地图的工作移动模型(map based working day movement, MBWDM).
2) 节点重要性度量
人们的移动不是随机的,而是有规律的,并且活动范围相对固定,例如上班族工作日规律地从家到公司,大学生在校园内按课程表作息活动,公交车每天总是在同一条路线上行驶,出租车司机总喜欢去客流量多的地方载客等.在机会移动社交网络中,我们将节点的相遇定义为2个节点移动至对方的通信范围内.只有相遇的节点才能进行通信,所以节点在机会网络中所处的位置决定了其承担通信任务的重要性.当用户节点处于聚集节点较多的位置时,能检测到较多节点发出的消息,那么该用户节点可以作为其他节点的中继节点进行数据的转发;反之,当其处于节点稀疏的位置时,能检测到的用户信息较少,能够承担通信任务的重要性减弱.因此,我们根据节点接收到的信号量来定义节点的重要性.
定义1.节点的重要性.节点在单位时间内接收到的检测信号量,表示为

(1)
其中,signal(τ,i)是节点i在时刻τ检测到的信号数量.
3) 基于位置因素的群组构造方法
在本群组构造发方法中,基于节点的移动轨迹,确定节点之间的位置关系,在同一时间片内处于相同或相近的地理位置时,节点相遇的机会大,从而更容易形成以地理位置为特征的群组结构,由于节点的移动具有周期性规律,因此基于位置属性的群组具有周期稳定性,其构造方法分为2个阶段:引导阶段和演化阶段.
算法1.基于节点位置关系的群组构造算法.
1) 引导阶段
输入:n个节点;
输出:m个群组.
① 选择节点重要性较大的前m个节点作为初始节点,每个节点有一个唯一的群组ID号,假设群组的ID号为1~m;
② 在所有节点的移动过程中,将没有群组归属节点加入到与其首次相遇的节点所属的群组中,直到每个节点都有其唯一的群组ID号.
2) 演化阶段
输入:n个节点、m个群组;
输出:每个节点所属的群组ID号.
① 在节点移动过程中,每个节点对自己与其他节点的相遇次数进行计数,将此信息保存在节点的隶属参数APS中,节点i的APS表示为
APS=(aps1i,aps2i,…,apsmi),
其中,apsji表示节点i和群组Cj中节点的相遇次数;
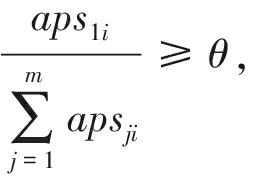
3.2 基于兴趣的群组构造方法
兴趣是节点具有的重要社会属性之一,也是相对稳定的行为属性之一,因此基于用户兴趣相似度的网络拓扑结构具有相对长期稳定性.本文设计了一种适用于静态拓扑结构的基于兴趣的群组构造算法,该算法将具有相同或相似的兴趣爱好的用户进行聚类,得到一种按兴趣划分的群组结构,当用户请求感兴趣的内容时,请求消息将在其所属群组内进行转发与传播,使请求成功率得到极大的提高.
1) 兴趣相似度度量
本文用兴趣相似度来度量用户之间在兴趣爱好方面的相似程度.移动节点的兴趣资源都会以文件的形式存储在移动设备,我们采用文档聚类技术对存储在节点中的数据进行聚类来模仿节点的兴趣.文档fi的文件向量即节点的兴趣矩阵表示为
其中,tk表示关键字,关键字可以是音乐、电影、体育、经济等等;witk表示关键字相应的权重,witk的计算过程为
witk=1+lnntk,
(2)
其中,ntk表示关键字tk出现的次数.为了将witk的范围控制在[0,1]之间,其标准化为
(3)
定义2.兴趣相似度.节点i和节点j兴趣向量中相同的关键字以及对应的权重为
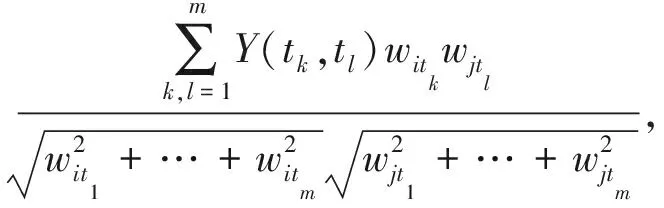
(4)
其中,Y(tk,tl)=1,仅当tk=tl时,否则为0,其中L为兴趣文档长度常量.
2) 基于兴趣的群组构造方法
团(clique)[19]的概念被引入到该群则构造算法中.
定义3.团. 团体的一个子集形成一个团,该团由3个或更多个成员组成,每个成员都与团的其他所有成员具有对称关系.
基于兴趣的群组构建算法分为3个步骤:团的构造、互相重合团的融合以及孤立节点的归属.
1) 团的构造.对于网络拓扑G,遍历所有的节点,对每一个节点V找出它对应的所有相连节点的集合Vn.判断该节点集合是否可以满足完全图的条件,如果可以,则将该节点集合连同节点V就可看作本网络拓扑中的一个团.
2) 团的融合.如果团K和团L拥有共同节点,则首先判断团K和团L的大小.如果团L较小,则判断去除团K和团L的共同节点,剩余节点是否仍然成团,如果仍然成团则将团L拆分为更小的团,如果不成团,则将团L直接加入到团K中;如果团K和团L节点数目相同,则根据先前提出的兴趣相似度判断共同节点应属于哪个团,而剩下节点的归属问题和团L较小时的情况相同.
3) 孤立节点的归属.在网络拓扑G中,经过团的构造和融合,如果还存在孤立的节点,则根据孤立节点与它相连的团的兴趣相似度的大小,把这些孤立节点归属到不同的团中.
算法2.基于兴趣的群组构造算法.
输入:具有n个节点、m条边的兴趣关系网络G(V,E,w),边权值的阈值γ;
输出:群组集合GS.
① 初始化群组集合GS←∅;
② FORV中每一个顶点vdo
③ 找到v的所有相邻顶点,记作集合Vn;
④ IFVn=∅
⑤ CONTINUE;
⑥ END IF
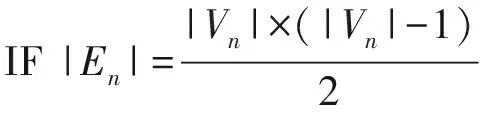
⑧ IF {{v}+Vn}⊄GS
⑨GS←{{v}+Vn};
⑩ CONTINUE;
3.3 基于通信关系的群组构造方法
在移动用户的通信行为中,通话时间和通话次数是最能直接表达通信关系紧密程度的度量指标.但是,通信关系紧密度又是一个随社会关系变化的量,因为人们在社会中的身份或地位发生了变化,会导致与其他人的通信关系发生变化,这种变化或增强或减弱人们之间的通信关系,所以本文考虑随时间变化的通信关系的衰减度.在计算通信关系紧密度时需要对时间进行周期划分,并且通过分析节点在网络中的重要程度,以及节点之间的周期通信关系和衰减函数计算得到通信关系紧密度.
1) 通信关系紧密度度量
定义4.社交中心性(social centrality).社交中心性代表了网络中节点的相对重要程度,我们采用Freeman[20]的度中心性来计算社交中心性.节点A的社交中心性可以定义为
(5)
其中,dAB(τ)=1当且仅当节点A和节点B在时刻τ有通信行为,N是网络中节点的个数.
定义5.衰减函数(decay).衰减函数取决于节点在社交网络中的重要程度以及与其他节点的社交时间,当2个节点才开始建立通信关系且2个节点的社交性强时,其关系衰减度较小.衰减函数的计算为

(6)
其中,τ是节点A和节点B有通信行为的时刻,T是周期.可以看出,当通信行为发生时刻越近,且社交中心性越大时,衰减函数的值越大.
定义6.通信关系(communication relationship).周期通信关系代表一个周期内节点之间通话时间和通话次数的关系,其计算公式为
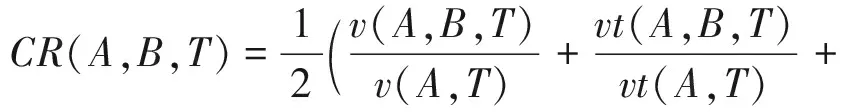
(7)
其中,v(A,B,T),vt(A,B,T)表示在周期T内用户A和B的通话时间、通话次数,v(A,T),vt(A,T)和v(B,T),vt(B,T)分别表示在周期T内用户A和用户B的总通话时间、总通话次数.
定义7.通信关系紧密度(communication tight-ness).综合衰减函数和周期通信关系得到通信关系紧密度,表示为
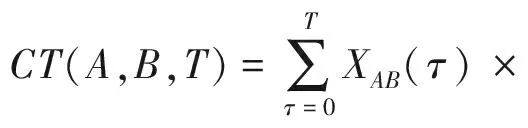
(8)
其中,XAB(τ)=1当且仅当节点A和节点B在时刻τ有通信行为,或τ=T时;否则XAB(τ)=0.CR(A,B,T)是上个周期的周期通信关系,这里我们使用上个周期的周期通信关系来计算本周期的通信关系紧密度.
本文采用增量式的动态群组构造算法,即计算本周期的群组结构时是基于上个周期的群组结构进行调整,避免重复计算.
2) 基于通信关系的群组构造算法
① 群组核.群组内部存在的稳定群组核心节点或群组核心节点的集合称为群组核,群组核之间没有重叠部分.
② 单独节点.度为0的节点集合.
③ 边缘节点.群组核以及单独节点外的节点或节点集合称为边缘节点.边缘节点之间可能存在一条或多条边,但是它们不能形成群组核或加入到已存在的其他群组核中.
④ 移动群组.移动网络中一组内部紧密联系的用户群称为移动群组.移动群组由群组核和满足条件的边缘节点组成.
⑤ 节点与群组的相似度.节点与群组的相似度是判断节点是否可以加入该群组的条件,本文对余弦相似度进行改进,可以计算有权网络中节点与群组的相似度,即:
(9)
其中,N(u)代表节点u的邻接节点集合,N(K)代表群组K的节点集合,N(u)∩N(K)是节点u的邻接节点集合与群组K的节点集合的交集.
⑥G(V,E,w).G表示有权无向图,V是G中节点的集合,E是G中边的集合,w(u,v)表示E中边(u,v)的权重.
Gt(Vt,Et,wt):时间片t的网络图快照.
C1,C2,…,Ct,…:随时间变化的群组结构.
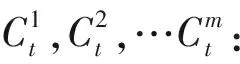
⑦ ΔG. ΔG表示图增量,有4种情况:节点加入、节点移除、边加入、边移除.
算法3.基于通信关系的群组构造算法.
1) 初始群组构造
输入:通信关系网络图G(V,E,w)、边介数阈值α、节点度阈值d;
① 对网络进行预处理,设定度为d的阈值,选出度高于d的节点;
② 采用设定边介数阈值的GN算法,将从②中得到的少量节点中挖掘出群组核;
③ 遍历网络中除群组核外的其他节点,计算这些节点与群组核的相似度,将该节点归入到与之相似度最大的群组核中,对没有与群组核直接相连的节点,则计算与其相连的移动群组的相似度,将其加入到与之相似度最大的群组中;
④ 进一步对③结果进行优化,遍历所有其他节点,计算节点与群组相似度,如果发现节点所归属的群组不是与其相似度最大的群组,则重新将其划分到正确的群组中,得到最终的群组结构.
2) 每个时间片群组的动态变化执行算法
输入:网络拓扑图快照Gt(Vt,Et,wt)、图增量ΔG.
输出:时间片t+1的网络群组结构Ct+1.
① 当新节点加入时,有2种情况:如果是单独节点,则将该节点单独划分为一个群组;如果是边缘节点,则根据该边缘节点与其相连移动群组的相似度,并将其加入到相似度值为最大的一个移动群组中.
② 当旧节点移除时,有2种情况:如果移除的节点是单独节点,则保持原有的群组结构;如果移除的节点是边缘节点,那么该节点的移除将影响其相邻节点的归属群组,这是个连锁反应,所以需要迭代计算其所影响到的节点,直到所有被影响的节点处于稳定的状态.
③ 当新的边加入时,有2种情况:如果新加入的边的2个顶点位于同一个群组,则保持原群组结构;如果新加入的边的2个顶点位于不同的群组,则重新计算这2个节点与其相连群组的相似度,将其划分到相似度最大的群组.
④ 当旧的边移除时,有2种情况:如果旧的边的2个顶点位于不同的群组,则保持原群组结构;如果旧的边的2个顶点位于同一个群组,则重新计算这2个节点与其相连群组的相似度,将其划分到相似度最大的群组.
3) 算法复杂性分析
本文设计3种群组构造算法:基于位置关系的群组构造算法采用动态的分布式群组构造算法、基于兴趣的群组构造算法采用静态社区划分方法、基于通信关系的群组构造算法采用增量式动态群组构造算法,前两种构造的群组相比基于通信关系的群组构造具有相对高的稳定性,算法复杂度低于增量式动态群组构造算法.
增量式动态群组构造算法认为网络拓扑的变化是平滑的,当计算当前网络的群组结构时,在上个时间片的群组结构上进行调整,所以计算速度加快,时间复杂度降低.该算法在同一个群组内增加边和删除不同群组之间的边时,算法复杂度为O(1);在不同群组之间增加边和在同一个群组内删除边时,算法较复杂,最坏的情况下时间复杂度是O(n),但群组的调整次数要小于节点个数n,所以一般情况下的时间复杂度小于O(n).
3.4 缓存区管理机制
在机会移动社交网络中,消息传输采用的是“存储-携带-转发”的方式,而移动终端设备的缓存空间是有限的,为了减少网路开销和缓存压力,保证消息的交付率,需要对节点的缓存空间进行管理.
节点缓存空间的管理主要依据消息的优先级和生存期(time to live,TTL).根据节点之间群组重合度,为每个节点分配转发消息的优先级,因为群组结构是动态变化的,所以在时段t群组重合度为

(10)

每个节点用一个队列存储消息列表,该列表记录消息的基本信息,如消息ID号、消息优先级和TTL.当节点u接收消息时,对优先级是0的消息不存储,对优先级不为0的消息,如果其缓存区足够则直接存储,如果其缓存区已满需要遍历消息列表删除优先级低的消息,如果消息的优先级相同则删除TTL较小的消息.节点每隔一段时间需要删除TTL为0的消息,完成缓冲区的清理工作.
3.5 基于群组构造的数据分发机制
本文设计的基于群组构造的数据分发机制(data distribution mechanism based on group structure, DDMGS)采用单副本模型,在选择下一跳节点时,不仅考虑节点所属的群组之间的关系,还引入博弈论,促使节点协作转发.
3.5.1 基于合作博弈的问题建模
1) 博弈模型的定义为
① 局中人N.N={1,2,…,n},表示机会移动社交网络中的所有节点.
② 策略集合S.S={D,F}表示每个节点可以采取的行动集合,Si表示节点i的决策,Si=D表示拒绝,Si=F表示转发.
③P.P={pij}表示节点i的支付函数.
2) 支付函数pij包含3部分:群组重合度、合作能力、声誉度.
① 群组重合度
群组重合度θij(t)是节点之间的所属群组的相似关系,重合度越高节点越相似,群组重合度θij(t)利用式(10)计算.
② 合作能力
合作能力φij(t)是关于电量的函数,定义为
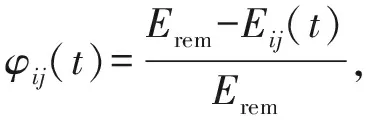
(11)
其中,Eij(t)表示节点i和节点j之间在时段t转发数据包所要花费的电量,Erem表示节点i或节点j的剩余电量.可以看出,电量随着时间的流逝越来越低,节点的合作能力也越来越低.
③ 声誉度
声誉度φij(t)是用节点在某时间间隔t内的转发消息数、产生消息数和接收消息数来度量,定义为
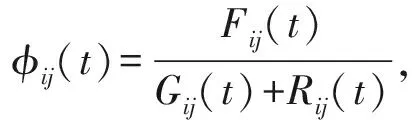
(12)
其中,Fij(t)表示节点i和节点j在时段t转发的消息数,Gij(t)表示节点i和节点j在时段t产生的消息数,Rij(t)表示节点i和节点j在时段t接受的消息数.
节点i在时段t支付的表达式为
pij(t)=αθij(t)+βφij(t)+γφij(t),
(13)
其中,α,β,γ是每部分的权系数,且α+β+γ=1,这些系数在实验时可以调整.
3) 模型策略
对于任一节点,s(θij(t))=0并且s(φij(t))=0代表拒绝合作,s(θij(t))>0并且s(φij(t))>0代表合作.
本文令Xij(t)代表其他节点转发本节点的消息给本节点带来的收益,Cij(t)代表本节点为其他节点转发消息所付出的代价,实质上Xij(t)来自节点合作后在声誉上的收益,Cij(t)来自节点合作后电量的损失.根据博弈理论,当节点选择合作时获得的收益为Xij(t)-Cij(t),节点拒绝合作时收益为-Xij(t),为激励节点选择合作,需要Xij(t)-Cij(t)>-Xij(t),为了简化实现,通过一次放缩,当Xij(t)-Cij(t)>0时能够对节点进行一定的激励.再一次放缩,当该节点此次合作的收益大于上次合作的收益时节点选择合作,如式(13)所示,我们假定2个时间间隔的组重合度一样,那么通过整理可以得到β,γ之间的关系以确保节点选择合作,如式(14)所示.并且我们定义一个信誉度的阈值,并在仿真过程中随时间提高该阈值的值,当上一跳节点的声誉值低于该阈值,本节点将拒绝转发上一跳的数据.这样使得那些拒绝合作的节点逐渐从网络中隔离出来,通过这样的过程达到激励节点合作的目的.
αθij(t)+βφij(t)+γφij(t)>
αθij(t-1)+βφij(t-1)+γφij(t-1) ,
(14)
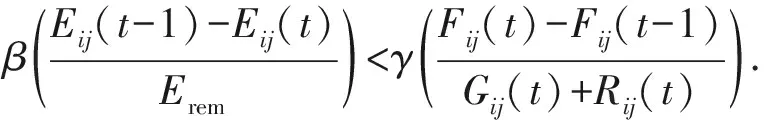
(15)
3.5.2 基于群组构造的数据分发算法
本文设计的基于群组构造的数据分发机制(data dissemination mechanism based on group structure, DDMGS)采用单副本模型,在选择下一跳节点时,不仅考虑节点所属群组之间的关系,而且引入博弈论,促使节点协作转发.具体的算法过程如算法4所示:
算法4.基于群组构造的数据分发机制.
输入:网络拓扑G(V,E)、节点i、声誉度阈值l;
输出:选择的下一跳节点.
① 新节点i的信息:完成对消息的处理,清理缓存;
② IF 节点i的缓冲区没有要转发的消息
③ RETURN;
④ END IF
⑤ 查找缓冲区,获得节点i中所有的消息列表messages;
⑥ FORmsg∈messages
⑦ IF 节点i的缓冲区中有能够直接投递给目的节点的消息
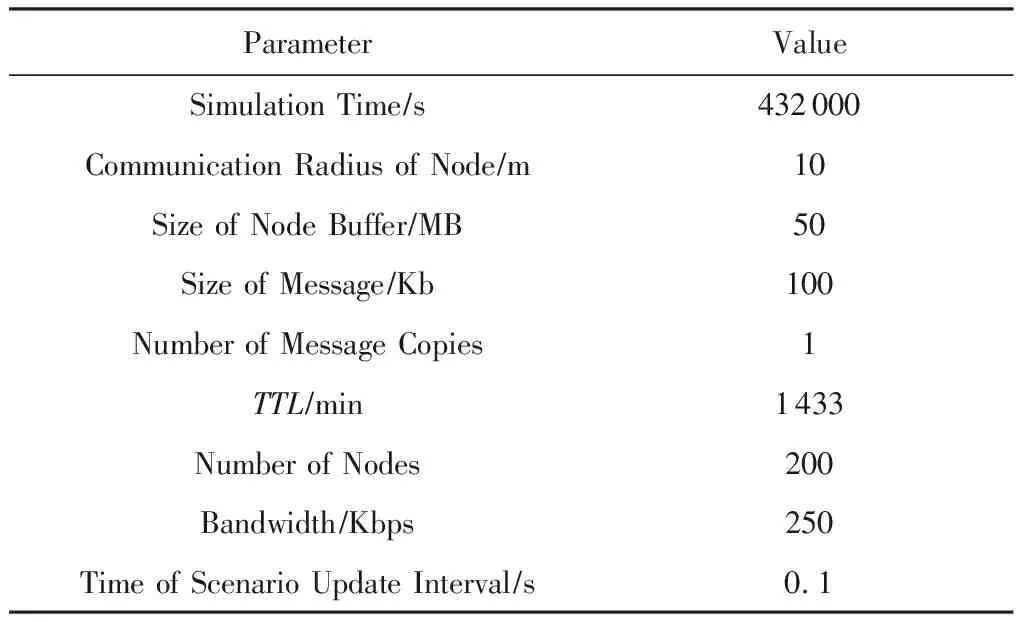
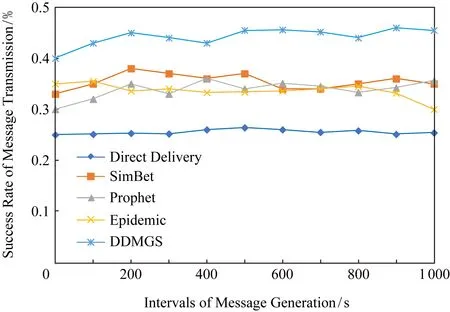
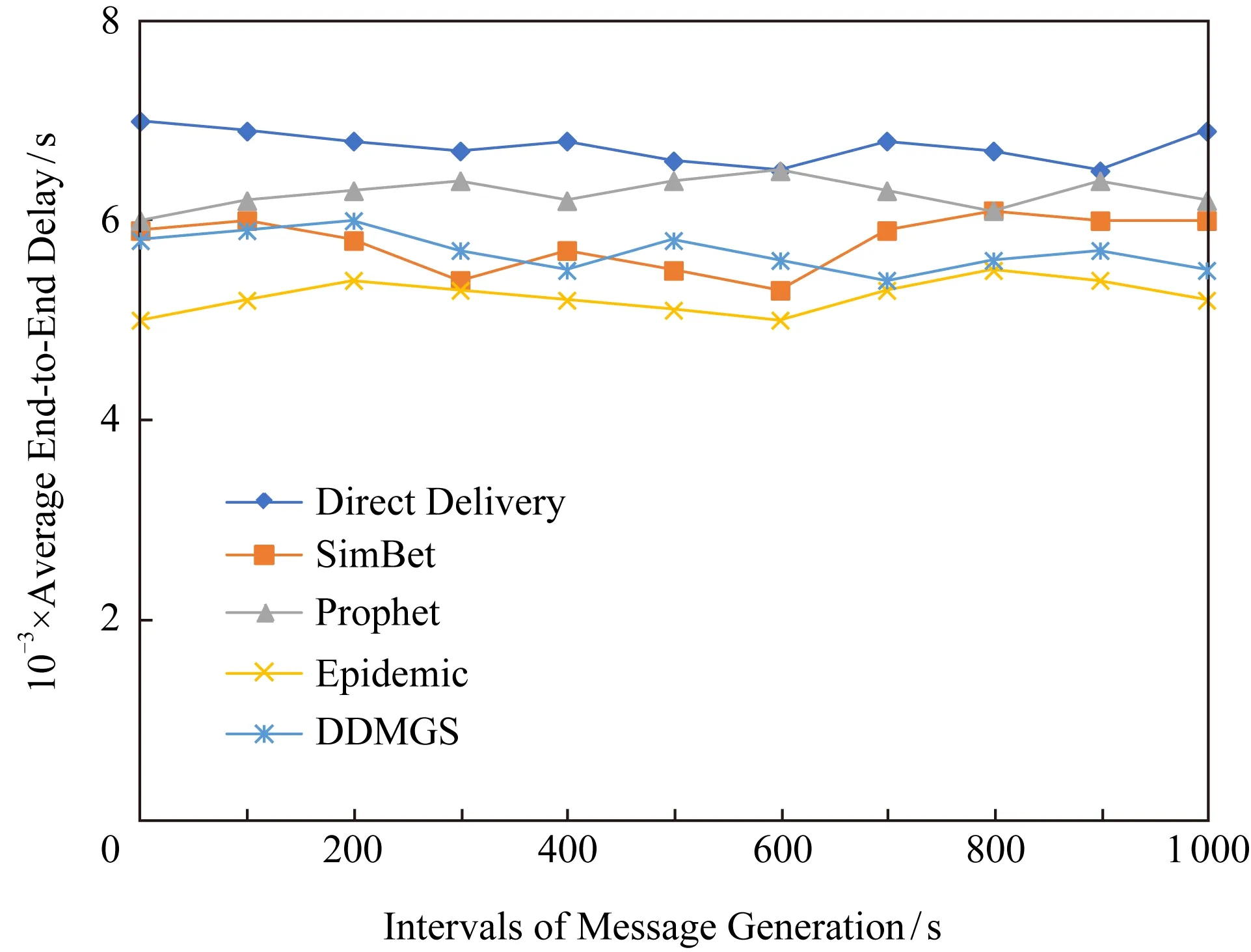
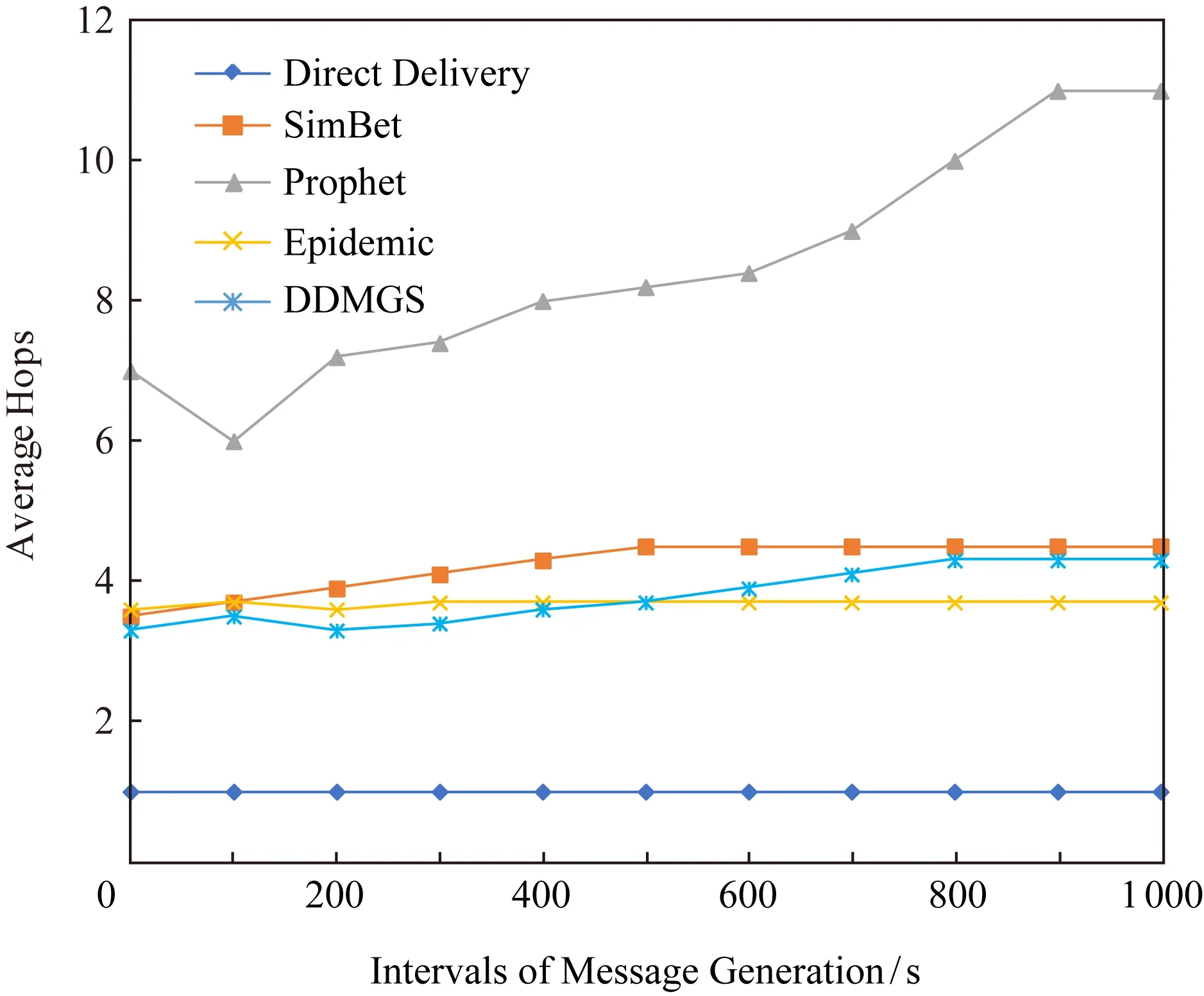
⑧ IF其上一跳节点j的声誉度φj ⑨ ELSE ⑩ 将消息直接发送给相遇节点; 本文仿真实现整个过程是基于机会网络(opportunistic network environment, ONE)模拟器,在Eclipse平台上采用Java语言编写实现. 本文使用的仿真场景是ONE模拟器中的Helsinki城市街道的场景,一共有200个移动节点,其中行人节点个数是120个,小汽车节点个数是60个,公共汽车节点个数是20个,并使用ONE自带的MBWDM和RWP移动模型去模拟这些节点的移动. 对ONE模拟器中的DTNHost类进行扩充,DTNHost类主要是对通信节点的描述,比如节点兴趣向量的定义和节点电量的定义等.比如电量的设置,我们使用整数类型表示,行人节点的最大电量为100,小汽车节点的最大电量为500,公共汽车节点的最大电量为1 000,在节点初始化时这些节点的电量随机取值,根据时间和数据的传输量更新节点的电量信息;而对于节点的兴趣向量,为了仿真方便,在节点初始化时,每个节点生成一个包括音乐、电影和体育兴趣点的兴趣向量,每个兴趣点的权值在0~1之间随机生成.具体的参数设置如表1所示: Table 1 The Setting of Simulation Parameter 本文在不同的消息产生时间间隔下,从消息传输成功率、平均传输时延、平均跳数和数据分发开销比率4种性能指标上,将本文提出的基于群组构造的数据分发机制(DDMGS)与4种基准算法:Direct Delivery Routing路由算法、SimBet Routing路由算法、Prophet Routing路由算法和Epidemic路由算法进行对比. 1) 消息传输成功率 消息传输成功率是机会移动社交网络性能评价中较为重要的一项指标,直接体现了数据分发机制性能的好坏.具体结果如图2所示: Fig. 2 Message transmission success rate under different intervals of message generation图2 不同消息产生间隔时间下的消息传输成功率 从图2可以看出,Direct Delivery的消息传输成功率最低.而本文设计的算法DDMGS分析了节点的3种行为,并将这3种行为构成的网络拓扑分别进行群组构造,当选择下一跳节点时,利用所属群组的重合度θij(t)来进行选择,并且引进合作博弈理论来避免节点发生自私行为,为了提高整个网络的收益促使节点之间合作从而极大提高消息交付率.SimBet,Prophet,Epidemic的消息传输成功率相差不大. 2) 平均端到端时延 由图3可以看出,各算法的平均端到端时延都比较长,大概在5 000~7 000 s之间.Direct Delivery的延迟最长,这也是由机会移动社交网络的特性和Direct Delivery的实现机制所导致的.Epidemic的路由时延最短,是因为其转发机制的特点是遇到节点便转发,所以数据包会比较快速地到达目的节点.Prophet的平均端到端时延略低于Direct Delivery的,但是也比其他算法要高,因为Prophet的平均跳数较高,所以时间主要消耗在节点对消息的处理上.本文设计的算法与SimBet算法的时延相差不大,两者都是基于节点之间的社会关系,充分考虑了节点的行为属性. Fig. 3 Average end-to-end delay under differentintervals of message generation图3 不同消息产生间隔时间下的平均端到端延迟 3) 平均跳数 通过平均跳数指标,可以直观地看到消息路由所利用的中间媒介数量,具体结果如图4所示: Fig. 4 Average hop count under different intervals ofmessage generation图4 不同消息产生间隔时间下的平均跳数 因为Direct Delivery的路由机制是消息生成节点遇到目的节点后直接交付,所以其跳数最少且始终为1,从图4可以明显看出. Prophet的平均跳数最高,是因为Prophet在选择下一跳节点时,根据其所有相遇节点为目的节点转发的概率值,如果相遇节点为目的节点转发的概率大于本节点,本节点就会选择此相遇节点作为其下一跳节. Epidemic跳数要小一些,这是因为Epidemic是通过消息副本的扩散进行消息交付的,它的传播速度更加迅速,其进行消息的扩散需要的跳数仅在2.7跳. SimBet在选择下一跳节点时,会选择节点中心度和相似度较高的节点作为下一跳,根据实验SimBet 路由机制的平均跳数为3.7跳. 本文设计的DDMGS算法充分考虑了节点的移动轨迹行为、兴趣行为和通信关系行为,所以在选择下一跳节点时更具有目的性和针对性,其平均跳数接近Epidemic,为4.0跳. 4) 数据分发开销比率 因为机会移动社交网络中节点资源的有限性,所以数据分发开销比率是机会移动社交网络中最重要的性能评价指标之一,具体结果如图5所示.在Direct Delivery中,消息的转发就意味着交付给目的节点,所以其数据分发开销比率恒为0.在Prophet中,从图4和图2可以看出:其平均跳数最高,而消息传输成功率与Epidemic和SimBet相比差不多,所以其数据分发开销比率要高于Epidemic和SimBet. Fig. 5 Data distribution overhead ratio under different intervals of message generation图5 不同消息产生间隔时间下的数据分发开销比率 本文在前人研究的基础上,分别由用户的移动轨迹、兴趣爱好和通信关系对用户进行群组构造,并在群组构造的基础上设计数据分发机制.并考虑到节点会因为自身资源受限而出现的自私行为,引入合作博弈理论,加强节点之间的协作. 本文对所设计的数据分发机制进行了仿真实现,并对其性能进行了验证.实验结果表明:所设计的数据分发机制具有较好的性能,是可行且有效的.更好地利用用户节点之间的社会关系来提高数据分发的性能,是我们下一步的研究和工作的重点.4 性能评价

5 结束语
