有限资源条件下的软件漏洞自动挖掘与利用
2019-11-15黄桦烽王嘉捷苏璞睿聂楚江
黄桦烽 王嘉捷 杨 轶 苏璞睿 聂楚江 辛 伟
1(中国科学院软件研究所可信计算与信息保障实验室 北京 100190) 2(中国科学院大学计算机科学与技术学院 北京 100190) 3(中国信息安全测评中心 北京 100085)
软件漏洞是指存在于操作系统或者应用程序中,可导致攻击者在未授权情况下获取或破坏系统数据的安全缺陷.软件漏洞的成因主要包括软件开发人员疏忽及水平受限、编译器引擎存在缺陷、程序功能逻辑复杂、代码模块测试不充分等因素.鉴于软件的代码规模、功能组成、多线程并发、数据资源共享等高度复杂的机制,即使经过严格的代码审查与测试也难以消除软件中的安全漏洞.知名压缩软件Winrar被爆出的CVE-2018-20250等一系列漏洞已潜伏长达19年,通过该漏洞可以实现任意代码执行,实现信息数据窃取、系统破坏、敲诈勒索等恶意攻击,严重威胁到信息系统的安全.
软件漏洞是网络安全的主要威胁,国家计算机网络应急技术处理协调中心(CNCERT)联合国内多家单位建立了国家信息安全漏洞共享平台(China National Vulnerability Database, CNVD),建立软件安全漏洞统一收集验证、预警发布及应急处置体系.漏洞利用是系统入侵渗透的主要手段,如何提高软件漏洞的自动化挖掘与利用能力是攻防双方共同关注的焦点.在有限资源条件下实现软件漏洞的自动利用是未来的现实需求和技术发展方向,2014—2016年美国DARPA组织的CGC[1](Cyber Grand Challenge)比赛在该方向作了初步的尝试,并受到业界的广泛关注.
软件漏洞的自动挖掘与利用实际已有长久的研究历史.在软件漏洞挖掘方面,微软的Cui等人[2]提出了基于符号执行反馈的并行化Fuzzing方法;Zalewski等人[3]提出了AFL Fuzzing系统,实现了基于遗传算法的路径快速触发,有效提高了漏洞挖掘能力.在软件漏洞分析方面,加州伯克利的Song等人[4]提出了基于动态污点传播分析的漏洞分析平台BitBlaze,之后该团队又提出了比特粒度的DECAF[5]污点传播分析系统.漏洞利用方面代表工作包括AEG[6],APEG[7]漏洞利用自动生成系统等.近年来,人工智能方法被引入到漏洞挖掘研究中,代表性工作包括Xu等人[8]提出的Gemini,通过对代码进行深度学习建模的方式,检测程序中存在的漏洞函数.相关方法和系统有效提高了漏洞挖掘与利用能力,但仍存在较大的局限性.主要包括:1)缺少统一的模型和框架,漏洞挖掘、漏洞分析、漏洞利用环节的方法难以形成一体化的能力,各环节的结果难以互相支撑;2)资源消耗大,难以支撑实际需求,现有的漏洞挖掘采取并行集群,需要大量计算资源;3)漏洞分析和漏洞利用基于传统污点传播、符号执行,时间及空间复杂度高,分析效率低,常因计算资源不足失效;4)漏洞自动利用生成只支持控制流劫持等有限的类型,扩展类型支持工作量大.
CGC是实现漏洞挖掘、分析、利用完全自动化的一次尝试,参赛团队通过建立“自动攻击防御系统”,在无人干预的条件下,自动寻找程序漏洞、生成利用攻击敌方、以及部署补丁抵御敌方的攻击,目的在于探索完全无人干预条件下的网络入侵、网络防御方面的可行性方案,构建出一套具备自主攻击及自我防御的软件.该比赛是软件漏洞挖掘与自动化利用的里程碑,从系统实现的角度证明了智能化自动攻防的可行性.但是,CGC比赛中采用了裁剪后的操作系统,程序的可执行文件格式等均进行了一定的修改,距离实际应用系统仍有较大的差异,难以应用于实际问题的分析.
漏洞自动挖掘与利用涉及多个环节,需要将各环节有效结合才能发挥作用,本文提出了基于程序运行时信息的Weak-Tainted漏洞描述模型,在该模型下优化污点传播方法和输入求解方法,基于2种优化方法指导模糊测试数据生成、漏洞自动分析及漏洞利用自动构造,构建了一套自动化的有限资源条件下的漏洞挖掘与利用框架,实现了轻量级的漏洞挖掘和利用,有效提高漏洞挖掘与利用的效率和准确性,并基于Ubuntu现实系统下的系列实验,验证了本文方法的有效性.
本文主要贡献和创新点有4个方面:
1) 提出了基于程序运行时信息的Weak -Tainted漏洞描述模型,通过脆弱性和污点属性对漏洞进行定义和描述,该模型支持漏洞挖掘、分析、利用过程中对漏洞进行统一描述,解决当前漏洞研究各环节的结果难以互相支撑的问题,形成了一体化的描述规范;
2) 提出了字节级标签的高效动态污点传播分析优化方法,基于多级页表存储污点结构属性信息,通过值校验消除传播误标记,解决了现有污点传播分析方法时间与空间复杂度高,难以应用于有限资源环境的问题,同时提高了污点传播准确度;
3) 提出了基于输出特征反馈的输入求解方法,基于输入点和输出点的关系统计分析预判进行输入求解和验证,解决了字符表映射运算的符号表达式难以构建导致符号执行求解失败的问题,降低了计算资源消耗,同时提高了输入求解的成功率,支撑漏洞挖掘与漏洞利用生成所需的输入求解能力;
4) 实现了漏洞自动挖掘与利用生成原型系统,支持漏洞描述模型规则的定义和扩展,针对真实系统中的漏洞程序,验证了字节级标签动态污点传播方法、基于输出特征反馈的输入求解方法、程序动态运行时Weak-Tainted漏洞描述模型的有效性.
1 相关工作
软件漏洞自动挖掘目前主要基于模糊测试方法,其基本思想是通过变异算法提供各种非预期输入,启发程序执行更多的代码模块和路径,监视目标程序在处理该输入是否出现异常的动态测试方法.经过多年的发展,模糊测试可分为四大类型,包括:1)测试用例随机生成,如zzuf[9];2)基于目标静态数据结构信息生成测试用例,如基于已知文件格式和网络协议规范,代表性研究工作有Peach,Sulley[10]等;3)基于遗传迭代的代码覆盖率反馈变异,代表工作有honggfuzz[11]和AFL[3]等;4)基于符号执行和求解生成用例,遍历程序执行路径,代表工作有KLEE[12],SAGE[13]以及商用版本SpringField等.这些代表的模糊测试工作仅具有单独的漏洞挖掘能力,形成的数据难以有效支撑后续的漏洞分析与漏洞利用自动生成工作.
软件漏洞自动利用目前主要基于模糊测试技术和数据流分析方法求解生成使程序陷入可利用状态的输入数据,再根据该输入和状态自动求解生成漏洞利用代码.而可利用状态通常会伴随着内存访问越界、格式化字符串受恶意操作、系统调用接口参数受恶意操作等异常情况出现,基于这些异常信息进行利用构造,最终实现控制流劫持等方式的任意代码执行.漏洞自动利用的代表性工作有2011年Avgerinos等人[6]提出的AEG,该工作使用了指令动态插桩技术和符号执行进行漏洞利用样本自动生成,验证了漏洞自动利用生成的可行性.但是,该方案依赖于程序源代码进行程序错误静态搜索,即可利用状态的搜索,不适用于非开源的二进制程序.
2012年Cha等人[14]针对二进制程序提出了构建基于索引的内存优化模型,优化符号化内存的加载问题,提高符号执行的效率,形成漏洞自动挖掘与利用代码自动生成的方案Mayhem.该方案在检测可利用状态方面,主要包括缓冲区溢出和格式化字符串2方面,针对指令指针符号化检测和构造控制流劫持的漏洞利用.但是Mayhem只对30个Linux系统调用和12个Windows库函数进行建模分析,无法高效处理复杂的程序,无法处理未建模系统调用函数引起的符号执行计算错误问题.
在漏洞利用样本多样化生成方面,2013年Wang等人[15]提出了一套针对控制流劫持类漏洞的利用样本多样性自动生成方法PolyAEG.该方法的基本思想是基于动态污点分析发现所有的程序控制流劫持点,然后基于等效指令替换构建不同的控制流转移模式,实现漏洞利用样本的多样性生成.PolyAEG针对控制流劫持类漏洞实现了一套完整的漏洞利用样本多样化生成的自动化构造方案,测试验证了8个现实漏洞程序,其中针对单个控制流劫持漏洞最多生成了4 724个利用样本变种.该方案是一种较为有效的控制流劫持类漏洞自动利用生成方法,但对于尚未触发控制流劫持点的POC样本难以生成有效的利用,而当前模糊测试生成的POC大多未触发控制流劫持.
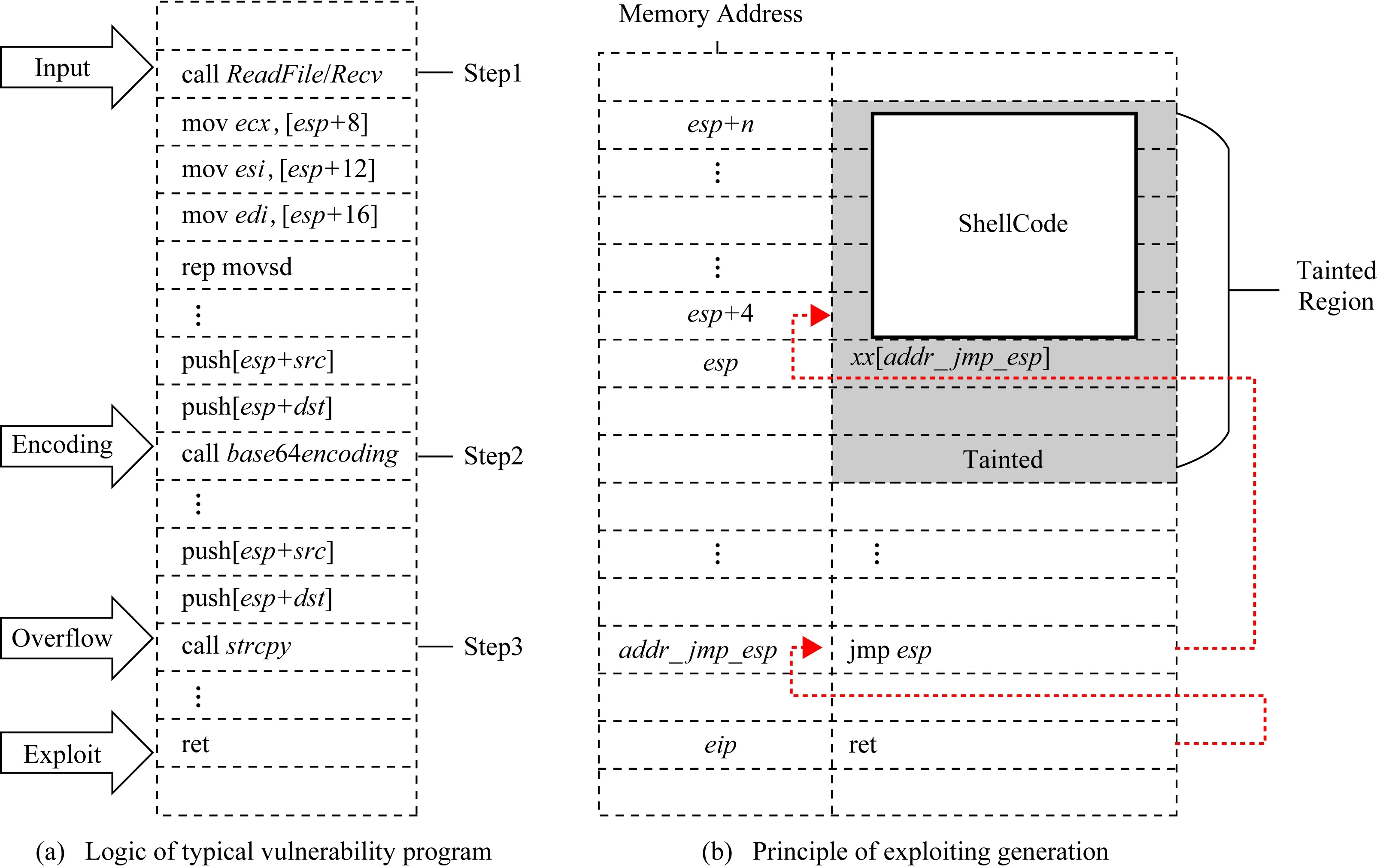
Fig. 1 Control flow hijacking vulnerability logic and exploit principle图1 控制流劫持漏洞逻辑与利用原理
在堆漏洞利用方面,He等人[16]提出了基于堆溢出崩溃和溢出修复的堆漏洞可利用性评估方法HCS IFTER,该方法首次提出了通过修复被破坏的内存,使得程序能够继续执行,并检测被破坏的内存数据后续使用情况,进而分析判定内存破坏点是否潜在利用条件,虽然该方法能够检测出触发崩溃样本本身是否潜在可利用性,但还不具备内存数据重新布局和构造的能力,即使检测出当前条件不可利用也不能得出该漏洞不可利用的结论.针对堆溢出内存数据的重新布局和构造,Wang等人[17]在2018年提出了一种基于现有崩溃路径,结合导向性模糊测试的技术,触发堆漏洞程序更多可利用状态的方法Revery.Wu等人[18]在2018年提出了针对内核堆释放后使用漏洞的自动利用框架FUZE,该框架利用内核模糊测试技术提供更多的内核崩溃上下文环境作为漏洞利用的依据,并利用符号执行在不同的上下文环境中去尝试利用目标漏洞.
CGC获奖团队之一的加州大学圣塔芭芭拉分校的Shoshitaishvili等人[19-20]提出了面向二进制软件攻防的基础分析平台ANGR.该工作主要是将已有基础性软件分析方法进行模块化实现,形成一套功能完整的分析框架,包括:控制流图生成、动态分析执行、符号执行、逆向切片等内容.在ANGR基本框架的基础上,可以实现针对二进制程序的漏洞挖掘、分析与利用等具体应用场景,并进行自动化系统功能构建.ANGR的作者将该系统应用到了CGC比赛中,将多种程序分析方法集成到同一个系统中,并实现了自动化,通过组合不同的分析技术进而构建面向二进制软件的自动攻防系统.但是ANGR系统在分析现实程序及静态链接的BCTF样本时却因为性能和兼容性等因素显得捉襟见肘,难以直接支撑实际工作.
与以上方法不同的是,本文提出了有限资源条件下基于动态模型的漏洞自动利用方案,在分析了不同类型漏洞利用方法的差异基础上,提取共性特征建立程序动态运行时的漏洞描述模型,基于漏洞的动态Weak-Tainted模型和优化的污点分析技术检测和判断漏洞类型,并提取利用约束条件,最后基于输入求解技术自动生成利用样本.
2 软件漏洞自动挖掘与利用问题分析
当前软件漏洞自动挖掘与利用的现实场景大多是在给定的二进制条件下,基于大规模分布式资源对目标软件进行模糊测试,对产生的程序异常点进行分析,筛选出存在控制流劫持等可利用条件的输入,对其进行数据流分析和内存布局分析,通过ShellCode布局和攻击链构造实现利用代码自动生成.
以典型的控制流劫持类漏洞为例,所针对的目标和利用过程如图1所示.其中,图1(a)表示一个典型的漏洞程序的基本逻辑,图1(b)表示针对该程序的利用代码生成原理.图1(a)的目标程序包括输入接口(图1(a)中的ReadFileRecv函数),处理输入数据的指令序列(图1(a)中的阶段1),通常情况下有数据的转移复制,甚至是编码与解码的运算(图1(a)中的阶段2),在对输入数据进行编码或解码运算后,程序执行至脆弱点(图1(a)中的阶段3).图1(b)的漏洞利用代码生成主要分为控制流劫持检测、内存布局构造、约束条件求解等步骤:①基于模糊测试得到异常样本,所谓的异常样本在传统漏洞挖掘方法里大多是指造成程序崩溃的输入;②使用数据流分析检测异常点是否为可利用的控制流劫持;③分析控制流劫持过程发生时的ShellCode内存布局,设计转移到ShellCode的攻击链,如图1(b)利用中间跳板指令jmpesp来触发栈空间ShellCode代码的执行;④基于ShellCode和攻击链部署条件提取约束,基于符号执行等方式求解生成利用代码.
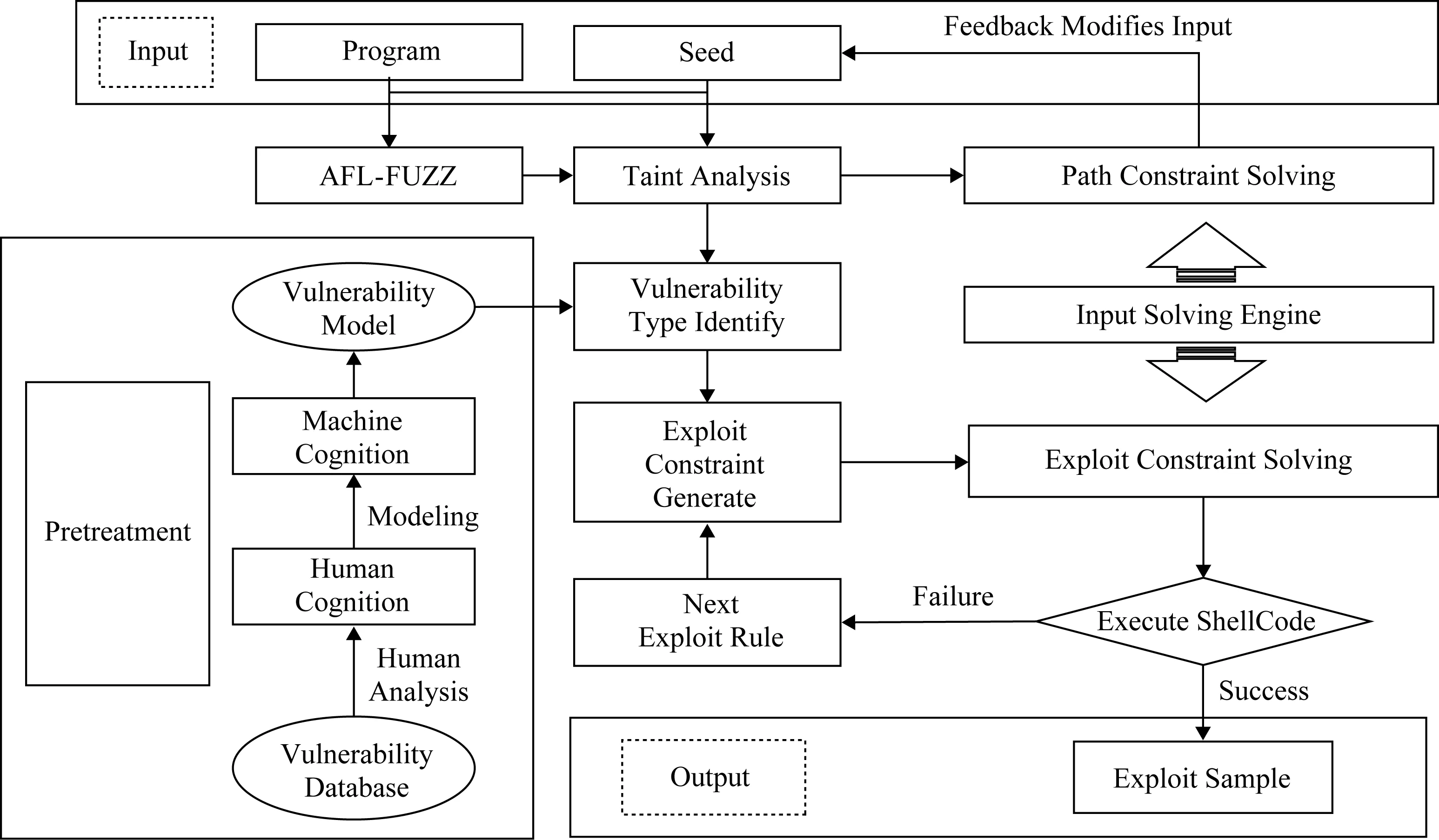
Fig. 2 Vulnerability automatic discovery and exploit based on vulnerability description model图2 基于漏洞描述模型的漏洞自动挖掘与利用方法
以上是当前漏洞自动挖掘与利用的典型过程,可总结为挖掘、分析、利用构造3个部分,而在前期的研究中我们注意到现有研究主要存在3个方面的难点与挑战:
1) 在漏洞自动挖掘方面,基于大规模计算实现并行化的模糊测试,Peach,Sulley等Fuzzing工具通常会生成大量的冗余样本,缺乏分析数据的反馈,漏洞挖掘与利用缺乏统一描述模型,生成的数据难以相互支撑,造成漏洞挖掘与漏洞分析利用流程脱节;
2) 在漏洞自动分析方面,以BitBlaze和Decaf为代表的基于污点传播的分析方法为主,以qemu虚拟机全系统模拟为基础,其污点传播算法消耗大量计算资源,在面对复杂的大型目标程序时,其性能难以满足有限资源条件下的漏洞自动分析需求;
3) 在利用代码自动生成方面,大多数自动利用基于已有的漏洞知识构造自动利用专家系统,只能针对特定类型的漏洞,针对不同类型的漏洞需重新编写自动利用系统;另外,逻辑公式求解受到程序自身数据处理过程复杂性与路径约束条件规模的影响,求解准确性和效率堪忧;同时,当前的符号执行求解在应对base64等存在映射表运算的编解码情况难以求解,很难有效支撑漏洞利用代码的自动生成.
3 软件漏洞自动挖掘与利用方法
针对当前漏洞自动挖掘与利用存在的难点与挑战,本文提出了有限资源条件下的漏洞自动挖掘与利用方法,总体框架如图2所示.首先,针对不同类型漏洞在触发时的关键属性,对漏洞进行归类和建模,形成可被机器识别的、贯穿漏洞挖掘与利用全流程的程序运行时漏洞统一描述模型,该模型基于程序脆弱性特征和数据污点属性进行描述和定义,本文称之为Weak-Tainted漏洞描述模型;然后,基于动态污点传播分析方法,结合漏洞描述模型给出的描述,在模糊测试过程中提取分支路径对应输入,并求解执行分支另一条路径的输入约束条件,得到下一轮模糊测试的新种子,用于提高漏洞发现的能力和效率;之后,根据漏洞描述模型和动态污点分析判断模糊测试获得的漏洞是否可利用,在可利用条件下自动提取漏洞利用所依赖约束条件;最后由输入求解引擎进行利用约束条件的求解,生成漏洞利用样本.
本节从Weak-Tainted漏洞描述模型、基于页表标签值校验的动态污点分析方法、基于输出特征反馈的输入求解方法和原型系统设计与实现4个方面对本文提出的有限资源条件下的漏洞自动挖掘与利用方法展开介绍.
3.1 Weak-Tainted漏洞描述模型

Fig. 3 Weak-Tainted vulnerability discription model during program dynamic runtime图3 Weak-Tainted程序动态运行时漏洞描述模型
不同类型的漏洞,在运行过程中表现出来的特征具有差异性.控制流劫持类漏洞具有明显的指令特征,表现在控制流转移指令的目标位置受到输入数据的污染,或者转移目标位置的内容受到输入数据的污染;堆溢出漏洞表现在访问的内存空间超出了堆内存分配空间的范围;格式化字符串漏洞可能引发控制流劫持异常,但需要精心构造受输入控制的格式化参数,在触发控制流劫持异常触发之前,其具有自身的特征属性,具体表现在调用具有格式化操作函数API时,其格式化参数受到输入数据的污染控制;此外还有一些创建进程、管道调用命令行的API函数,如system,popen等,其关键参数受到输入污染控制也可触发任意代码执行的漏洞.
为了对多种不同类型的漏洞进行统一描述,便于机器自动识别和利用代码生成,同时也为了将漏洞挖掘、分析、利用各环节融合以相互支撑,本文提出了Weak-Tainted程序动态运行时漏洞描述模型,该模型包含脆弱点(weak)和污点属性2个部分.如图3所示,该模型定义了2个方面的内容:1)程序脆弱点集合,脆弱点集合包含Weak-INS和Weak-PC两种类型.Weak-INS是可能引起漏洞的指令,包括触发控制流劫持的指令call,ret,jmp以及通过执行系统调用执行任意代码的指令int 0x80,syscall,sysenter等;Weak-PC是指潜在漏洞的指令地址集合,主要通过静态分析敏感脆弱函数地址,比如memcpy,strcpy,scanf,system等容易产生漏洞的函数,获得模块信息和相对偏移地址,最后映射到动态运行时的函数指令地址,该地址通常是函数入口地址,当然也可以根据实际情况需求定义为函数中间某条指令的地址.2)检测点定义,需要给脆弱点集合的每个脆弱点定义检测点,检测其是否被输入污染(tainted),每种脆弱类型都有其对应的存储单元敏感点,存储单元可以是内存或者寄存器,可基于常量地址、指令操作数、寄存器或操作数作为指针索引等进行定义,当脆弱点定义的敏感点受到输入数据污染,可初步判定为存在漏洞.
一个脆弱点可以定义多个检测点,这些检测点可以是满足其一的关系或者同时满足的关系,比如call指令的检测点,包括3种情况:1)call指令op0操作数指向的内存为污点,这一类会导致指向的执行指令可以被输入改写;2)call指令的op0操作数为污点,这一类会导致call指令的地址可以被输入改写,使程序跳转去执行预设的攻击代码;3)op0的指针被污染,例如call [eax+8]中的eax被污染,这种类型会导致获取跳转地址的位置可被改写,同时引起跳转地址的位置可被改写.类似的jmp,ret指令也存在3种类型的脆弱类型.
当前漏洞利用的自动构造依赖于特定的漏洞类型,本文分析收集了常见的控制流劫持、格式化字符串、系统调用后门类型的漏洞利用要素和步骤,基于Weak-Tainted程序动态运行时的漏洞描述模型,实现了相应的漏洞模型库及模型库的解析引擎,形成基于Weak-Tainted漏洞描述模型的漏洞利用样本自动生成框架.
在漏洞描述模型库的表示方面,以常见的控制流劫持漏洞为例,call指令的劫持与ret指令的劫持在利用构造的具体实现上存在差异,并且call指令的劫持还分为call *Taint,call Taint和call [Taint]三种情况,这些差异导致漏洞利用的构造步骤存在一定差异.本文分析总结了这类漏洞的利用构造步骤,在此基础上形成漏洞判断条件和利用要素描述模型库.系统实现的模型库对call指令的多种情况分别给出了不同的模型描述,其中call参数为寄存器的情况给出了2种模型,例如calleax,包括eax为污点和eax指向的内存为污点2种状态;另外call参数为内存的情况给出了3种模型,例如call [eax],包括eax为污点、[eax]为污点和[eax]指向的内存为污点的3种状态.针对jmp指令,与call指令的描述模型一致,针对ret指令,描述了esp为污点和[esp]为污点的2种状态.如图4所示,是针对call参数为内存情况的一种描述.

Fig. 4 Case of vulnerability description model图4 漏洞描述模型样例
图4的样例给出的Weak_Type:INS是通过特定敏感指令进行判别,Weak_Value:call给出的敏感指令是call,此外还有jmp,ret等指令.而本方案还支持通过指令地址进行判别的方式,表示方式为 Weak_Type:ADDRESS,如针对格式化字符串漏洞或者敏感系统调用API,通过函数入口检测相应参数是否受到控制,函数的入口地址则是通过静态分析结合动态库基地址计算得到,表示方式为Weak_Value:0x80888888.
程序执行到脆弱位置时需要检测相应条件再判断是否存在可利用点,不同的情形检测不同的参数,因此设计了图4所示的OpCondition域,用于区分检测指令(如call)的参数是寄存器还是内存,针对不同情况需要检测不同的位置并使用不同的步骤进行构造,因此也需要分别给出不同的模式配置,针对无需区分的情况OpCondition项为空.
另外配置的污点检测Tainted_Conditions存储单元可能是指令参数或者函数参数,这些参数都可以通过寄存器、指令操作数及偏移,多次指针索引进行描述和表示,如图4中的storagetype域和type_index域.系统设计并实现的storagetype包括reg,memory,point三种类型,用于表示需要通过多少级索引获取存储单元地址,type_index包括eax,ecx,esp,op0,op1等通用寄存器和指令操作数,作为存储单元的索引.图4的reg和op0组合表示检测call指令的op0本身是否被污染,如果是memory和op0组合,表示检测op0指向的内存是否被污染;如果是reg与esp组合,表示检测esp是否被污染;memory与esp组合,表示检测[esp]是否被污染;point与esp组合,表示检测*[esp]是否被污染.

Fig. 5 The page table structure of taint status图5 污点存储页表结构
系统实现了漏洞利用过程中所需步骤的子模块,包括但不限于:1)内存布局分析子模块,通过污点传播技术记录程序执行过程中存储单元污点状态,用于搜索内存中污点数据布局区域和对应的污点源关系,为ShellCode等注入代码提供存储空间;2)内存值搜索子模块,用于搜索内存中存储了特定数据的空间,返回相应的内存地址,在利用构造过程中提供跳板指令位置、函数指针、或者数据索引指针等特定数据结构位置;3)格式化字符串构造子模块,针对格式化字符串规则,构造任意地址的读或写的能力;4)约束表达式构建与求解子模块,基于模式库的约束模型,生成具体的利用构造约束条件,最后基于符号执行和输出特征反馈的求解方案进行利用样本生成.图4所示的Exploit_Steps 则是通过调用内存布局分析子模块搜索出连续的污点内存区域,通过内存值搜索子模块搜索特定值的地址,通过约束表达式构建求解子模块实现其2条约束条件的构建与求解.
本文的系统基于上述的子模块,在漏洞描述模型库中添加了针对calljmp指令各5种描述模型规则,ret指令2种描述模型规则的控制流劫持漏洞的自动分析判定与利用生成模型.同时添加了针对各类格式化字符串的漏洞分析判定与利用生成规则,包括基于格式化字符的栈溢出和基于格式化字符串的任意地址写2种利用构造方式.另外还添加了针对popensystem等敏感函数参数受污点控制的后门漏洞判定与利用构造模式.
本文通过构建Weak-Tainted的程序动态运行时漏洞描述模型,可配置漏洞描述模型的脆弱点和对应的敏感存储单元,结合动态污点分析技术,可以实现机器对漏洞的认知与识别.同时,本文提出的漏洞模型具有可扩展的能力,对于新型漏洞可基于该漏洞模型描述进行自定义扩展,提高了机器针对新型漏洞的自动识别与利用构造能力,免去了重新编写漏洞识别与利用代码生成算法的复杂工作.
3.2 基于页表标签值校验的动态污点分析方法
针对现有污点传播方法准确性和效率的缺陷问题,本文提出了基于页表标签的动态污点传播分析方法,通过优化污点状态记录方法、污点传播计算方法,实现低时间与空间复杂度的准确计算.在污点状态记录方面,我们解决了内存污点快速查询与记录、寄存器状态记录等问题;在污点传播计算方面,本文解决了因未监控内核指令导致的污点误标记导致的误报问题.
针对进程污点数据记录问题,本文借鉴操作系统内存管理的方法提出了基于多层页表的污点状态压缩记录方法.以32 b系统为例, 32 b系统进程的最大虚拟内存地址空间为4 GB,但是进程实际用到的内存空间远远不足4 GB,通过3级页表索引的方式,如图5所示,未被操作或未被污染的内存区域在污点状态页表内可以用空表项表示,而污点内存则由对应的页表项指针指向污点标签记录结构.查询和更新指定内存地址的污点状态的时间复杂度为O(1),记录程序污点状态所需内存空间最多与目标程序内存空间呈线性关系,即空间复杂度O(n).
针对寄存器状态记录问题,32 b系统的寄存器包括通用寄存器、标志寄存器、浮点寄存器等,考虑到通常情况下,进程的低地址0x0000~0x1000位置不会被使用,将CPU寄存器映射至页表中的低地址空间,并且为每一个线程维护了一套寄存器的污点状态信息.
污点标签结构记录了存储单元的污点源数量、污点源标签组、存储单元值、对应指令地址和序号等信息.污点源标签采用偏移量和字节数的压缩格式表示:{[offset1,size1],[offset2,size2],…,[offsetn,sizen]},标签之间通过求并集进行污点源的合并,标签求并集可将重叠的连续字节进行压缩合并,为了使标签合并高效进行,从初始化的单标签开始,合并标签按照升序进行排列,可以保障之后的多标签之间的合并只需按归并排序的策略依次合并,时间复杂度可控制在O(n),其中n为标签组的数量,且在实现当中限定了标签组最多支持127组,由于标签组是压缩存储,127组在实际案例测试过程中是足够用的,如果超出该数量多出的标签会被丢弃,但能保证消耗的空间复杂度不超过O(n).
在污点传播计算方面,本文解决了基于指令关系分析的字节粒度污点传播计算和因未监控内核指令引起的污点过标记误报问题.字节粒度污点传播计算为每个字节单独计算和维护污点状态信息,通过反汇编解析指令,提取指令操作数之间的关系,为了达到字节级粒度的精度,操作数间的关系并不再是简单的一对一或者一对多关系,而是复杂的多对多关系,本文用如下表达式模型表示一条指令派生出的操作数关系组,其中每个符号表示一个字节:
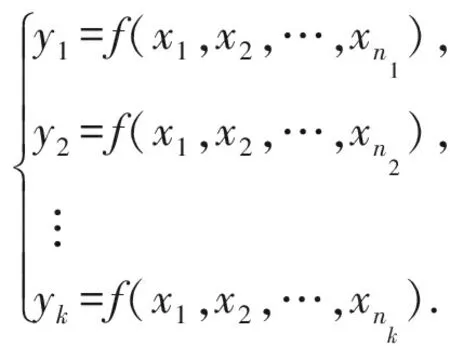
根据关系组,更新目标操作字节yi的污点状态,污点状态的更新首先是查询目标操作字节对应的所有源操作字节x1,x2,…,xni的污点状态,并计算这些污点标签的并集作为目标操作字节yi的污点标签,然后更新yi的污点标签,同时记录该字节的值以备后续使用.
通过分析发现,用户态的内存在释放回收后大多并未清除数据,并且其中有一部分被标记为污点,而当重新分配之后如果由内核模块对其初始化无法在用户态检测到存储单元被漂白的操作,因此导致了后续的传播误报问题.而本文不去监控内核指令是由于内核态指令执行占比大,初步测定是用户态指令数量的3倍,会导致性能的极度下降.针对上述问题,本文提出的动态污点传播方法带有值校验检测的能力,污点传播计算过程中,如果查询源操作字节的污点状态是污点,需要校验此时该字节的值是否与标记该字节为污点时的值是否一致,如果不一致将其漂白,从而解决了因未监控内核指令引起的污点过标记误报问题.另外,通过大量实验(包括office word,notepad++,kmplayer等常用软件)发现用户态污点数据经过内核,再传播到用户态的情况较为少见,在针对应用程序漏洞挖掘与利用构造这一应用场景下可以忽略不计,因此无需去监控内核态的指令.
3.3 基于输出特征反馈的输入求解方法
输入求解是为了获得满足某种条件的输入,比如执行某一条程序分支,或者使得某个时刻内存或寄存器的值满足某个约束条件.目前符号执行是理论可行的解决方案,但在实际应用中却面临计算关系难以用算术表达式或者逻辑表达式进行表示、符号表达式太多、约束条件太复杂等挑战.比如Base64编解码、AES加解密算法,其运算过程都存在基于映射表进行字符替换的过程,从输入到输出难以构造对应算术表达式,也就难以进行求解.
针对符号执行的缺陷,本文提出了基于输出特征反馈的输入求解方法,用于解决映射表运算等导致符号执行无法求解的问题.首先通过污点分析建立输入与目标输出之间存在关系的字节集合,此处的污点传播支持指针为污点的传播,因此污点状态不会因为映射表丢失,并且在传播过程中为指针标签增加了指针属性以便识别指针类型的污点数据.目标输出字节集表示为T={t1,t2,…,tk},输入字节集表示为X={x1,x2,…,xn},建立输入与输出字节级的污点关系,用如下函数模型表示它们之间的关系,其中函数g是一个未知的黑盒函数.求解的目标是找到一个输入集合X={x1,x2,…,xn}使得输出集合T刚好为T={t1,t2,…,tk}.
本文提出的输出特征反馈的输入求解基本思想是对输入字节逐个进行求解.图6给出了约束关系的样例,Conditions1中的0x0,4表示待求解目标偏移位置0的连续4 B,相关的输入字节为偏移0x1d的连续4 B;Conditions3中的0x8,4表示待求解目标偏移位置8的连续4 B,相关的输入字节为偏移0x1d的连续12 B,以此类推.本例中不难看出,Conditions1的输入字节是其他Condition输入字节的子集,这种情况应当优先求解Conditions1.目标字节集在各个Conditions中没有交集,而输入字节集中是可能存在交集的.

本文通过算法1实现条件求解顺序的排序.首先对约束条件输入字节进行排序,决定字节的求解顺序,如算法1所示,按照关联输入字节数少的约束优先原则进行排序,如果InputSet1∈InputSet2优先求解InputSet1对应的约束条件,再得到InputSet1之后对于约束中的部分变量将设置为常量,然后再求解剩余的输入集合{InputSet2-Inputset1}.
算法1.条件求解顺序的排序算法.
输入:多个待求解的约束集合中的输入集M={Set1,Set2,Set3,…,Setn};
输出:约束求解顺序.
①OrderSets={}
② WhileM!=OrderSets
③MinSet=one ofM-OrderSets;
④ For each set inM-OrderSets
⑤ Ifset∈MinSet
⑥MinSet=set;
⑦ End If
⑧ End For
⑨OrderSetsinsertMinSet;
⑩ End While
从算法1可知,如果这些约束的输入条件没有子集关系,它们的求解顺序不会进行调整,将按照原有约束条件的顺序进行求解.
针对单个约束,ti==f(x1,x2,…,xni) ,使用算法2进行处理,算法2通过反复修改ti对应的关系输入字节集{x1,x2,…,xni},动态运行监控对应的ti值变化,采用控制变量法,控制单个输入变量的变化,基于遗传迭代和贪心算法思想,保留最接近目标值结果的一组输入进行下一轮的变量修改.多次反馈迭代调整改变输入,直到输出的ti满足求解条件或者求解失败.这种方法能够有效应对大多数编解码算法.
算法2.单约束条件输出反馈求解算法.
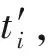
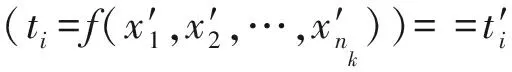
①BestInput=Init(x1,x2,…,xnk)*初始输入为约束求解前的一个未满足的输入*
②BestTi=f(x1,x2,…,xnk)*所获得的离目标值最接近的结果*

④ ForxiInBestInput(x1,x2,…,xnk)
⑤xi1=xi+1;
⑥xi2=xi-1;
⑦Ti1=f(x1,x2,…,xi1,…,xnk);
⑧Ti2=f(x1,x2,…,xi2,…,xnk);

⑩BestTi=Ti1;
3.4 原型系统设计与实现
本文实现了漏洞自动挖掘与利用原型系统AOTA,该系统框架流程如图7所示,包含污点分析、输入求解2个基本引擎和一个漏洞描述模型,基于漏洞描述模型辅助实现漏洞挖掘、分析、利用全流程系统.漏洞挖掘主要基于模糊测试基础方法,结合漏洞描述模型及其污点分析和输入求解技术,反馈获得额外的变异样本辅助漏洞挖掘,提高漏洞挖掘的效率;漏洞分析目的是分析漏洞类型,判定漏洞是否为可利用,主要基于污点分析引擎和漏洞描述模型来完成;漏洞利用自动生成是针对可利用的漏洞及样本,结合分析获得的约束条件、关联的输入字节,及其对应的漏洞模型和输入求解引擎实现利用样本的自动生成.AOTA系统的污点分析引擎基于QEMU的指令插桩实现,基于udis86反汇编结果编写传播规则,污点源是通过监控获取外部输入的系统调用标记,每个字节采用不同标签进行区分.输入求解引擎所需的数据采集基于Python框架,迭代调用QEMU引擎监测求解点的输出结果,从而进行遗传迭代反馈预测求解,约束关系式是在漏洞分析过程结合漏洞模型描述提取的,求解引擎除了使用本文提出的优化方法,还结合了符号执行求解引擎Z3.漏洞描述模型以JSON格式数据形成漏洞模型配置文件,模型库包含了calljmpret等控制流劫持漏洞,格式化字符串漏洞,systempopen等敏感命令行执行后门漏洞;可由系统导入进行配置;模型的解析主要用来根据配置执行对应的检测操作和求解操作,在QEMU动态运行目标程序过程中进行;另外,模型库内置了2个不同版本的执行shell的ShellCode.
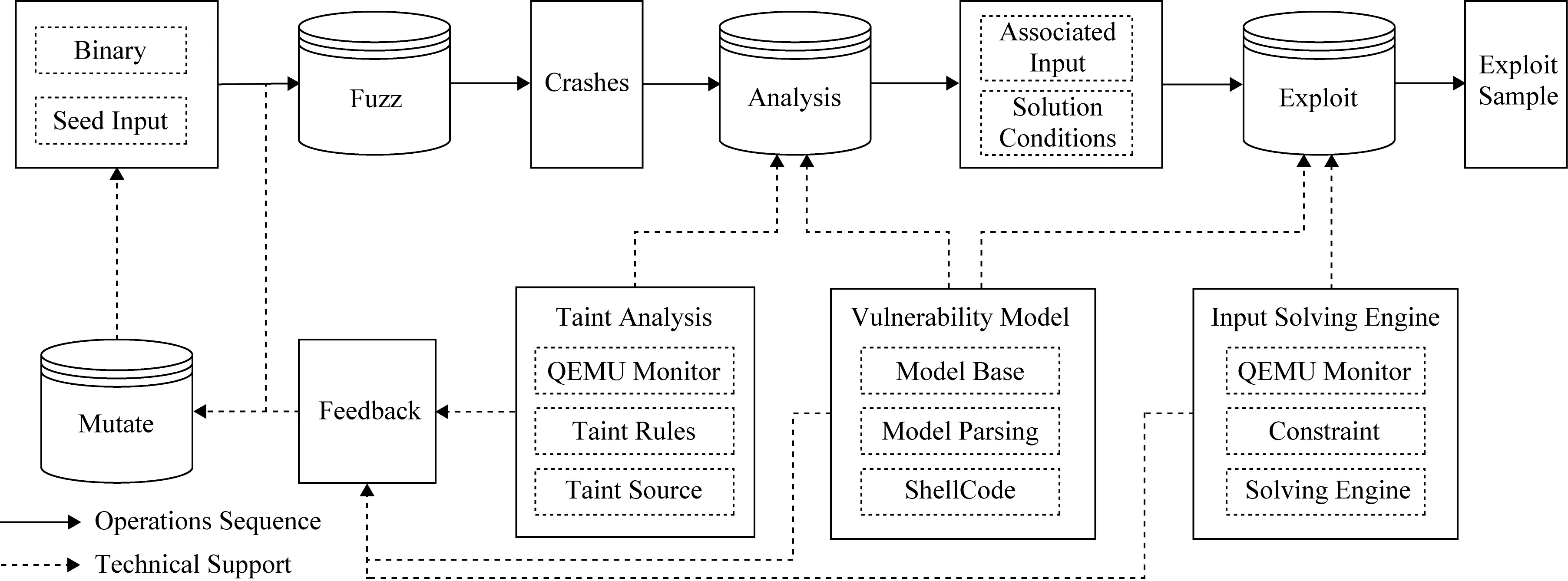
Fig. 7 Framework of prototype system图7 原型系统框架流程
4 实验验证与结果分析
参照国际同行选择实验测试对象的情况,如Driller[20]以2016年CGC自动攻防比赛的样本作为测试用例,本文以2018年DEFCON和百度安全联合举办的DEFCON China大会上的BCTF比赛样本[21]作为测试集,其中共有50个含有漏洞的Linux二进制程序,测试漏洞自动挖掘与利用能力.本文的测试环境均为Intel Xeon®CPU E5-2630 v3 @2.4 GHz × 16, 内存64 GB,硬盘2 T的联想RD650服务器,操作系统Ubuntu 16.04.5 64 b.
本文的原型系统也直接应用于2018年BCTF比赛,在99 s内完成第1个漏洞的自动挖掘和利用,在2 min48 s内完成了4个样本的自动利用生成,而人类战队完成第1个漏洞利用花了17 min,与国内外知名CTF战队同台竞技,获得了机器人自动攻防单项排名第1的成绩.
4.1 污点传播功能测试
本文实现的污点传播模块包括污点源标记、污点传播计算、污点异常检测3个部分.污点源标记通过监测外部输入实现,当检测到外部设备、文件或网络数据读入内存时,将对应的内存字节标记为污点,并使用对应的输入字节偏移量为标签进行标记.污点传播计算通过代码插桩提取目标程序执行的指令,针对Linux的目标程序,实验采用qemu的用户态模式进行代码插桩,然后反汇编指令,解析指令语义更新内存和寄存器的污点状态,记录对应污点源标签.污点异常检测根据配置的漏洞模型规则获得检测点和检测内容,查询对应内存或寄存器操作数是否为污染状态,如果是污染状态取出污点源.
实验从测试集选取了12个栈溢出和格式化字符串漏洞样本,使用对应的POC样本单独测试AOTA系统的污点传播模块,实验均能基于漏洞模型通过污点分析检测到漏洞点,并且未发现误报和漏报.实验表明:本文改进后的污点传播方法其准确度能够满足漏洞分析与判定的需求.
性能方面,测试的12个样本中,污点分析消耗的时间最多的是357 ms,最少的是19 ms,平均值为174.25 ms.消耗的内存最多的为25.73 MB,最少的为12.6 MB,平均消耗22.2 MB.另外,实验统计了1 000组指令数量与污点分析时间消耗关系数据,如图8所示,横轴是指令数量,纵轴是消耗的毫秒时间.由于程序开始执行时自身需消耗较多的时间用于IO加载,对污点分析速度的测算影响较大,实验筛除指令数量少于20 000条的测算数据,对剩下的速度数据求平均值,得到的污点传播速度为每秒57.34万条指令.
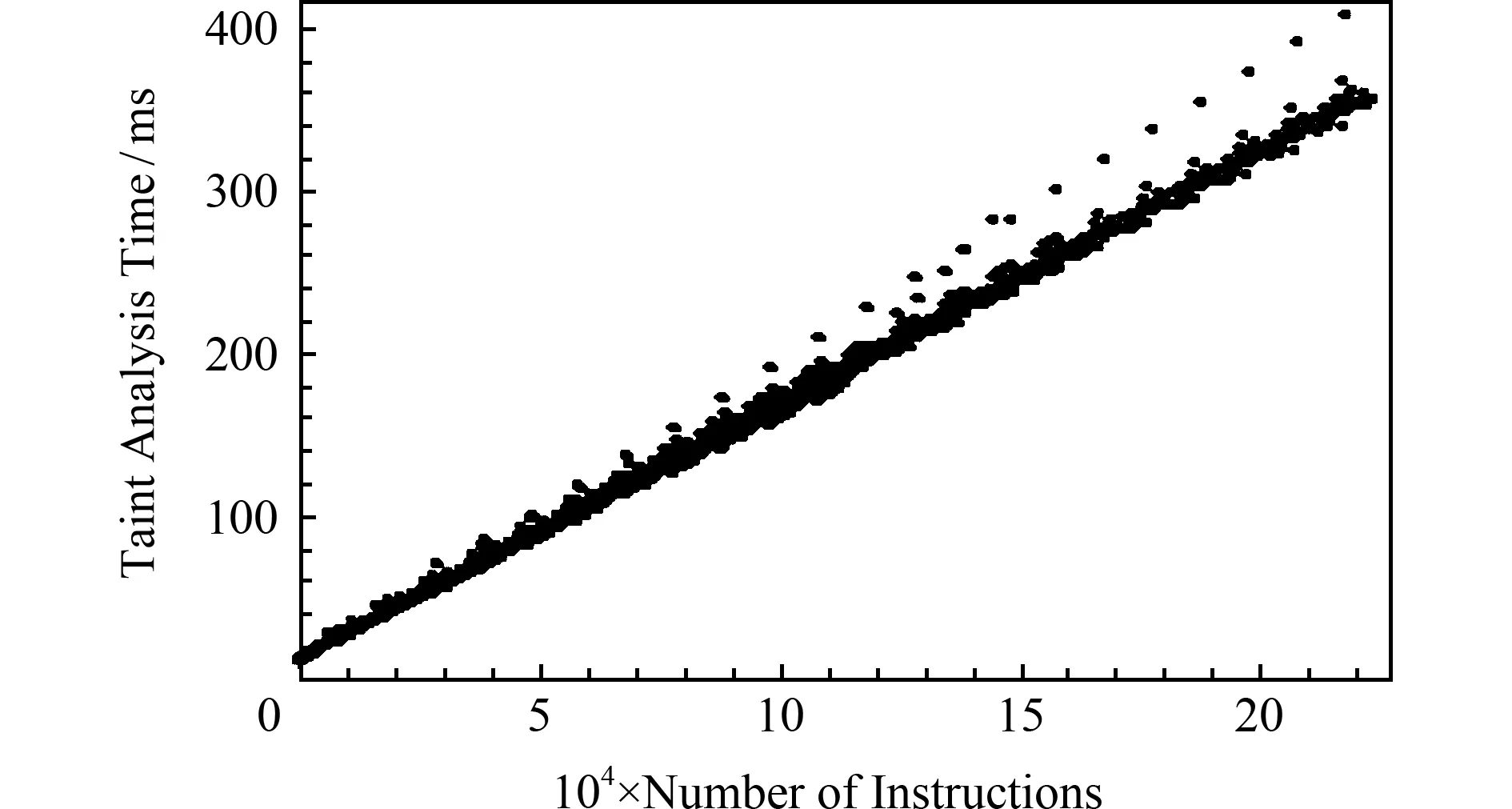
Fig. 8 Velocity curve of taint analysis图8 污点分析速度曲线
4.2 基于输出特征反馈的输入求解测试
本文提出的基于输出特征反馈的输入求解方法在原型系统AOTA中进行了实现,与ANGR中的符号执行模块进行了实验对比,测试输入数据分别经过atoi转换、base64编码、hex编码处理的求解能力,从求解能力和求解效率的角度进行评估.通过学习ANGR符号执行的用例,发现其主要应用在路径求解,并且其约束条件是用输出含有指定字符进行描述.为了适应ANGR的应用场景,实验构造了符合ANGR应用场景的测试用例,由标准输入经过编码转换,然后将结果与预设值匹配,匹配成功则使用标准输出打印出Success字段.
实验分别使用ANGR和AOTA对atoi,base64,hex编码进行求解,求解成功与否如表1所示.其中对于atoi的转化均能求解成功;ANGR对base64编码的求解失败,但AOTA能够求解成功,这是因为base64中有映射表转换的操作,ANGR的符号执行无法支持该转换的求解,导致求解出来的结果是错误的;对于hex编码的求解ANGR只能求解少量字符,当字符串长度不少于3个时,内存消耗超过64 GB求解失败,而AOTA的求解不受长度限制.总体而言,AOTA的求解能力要优于ANGR.
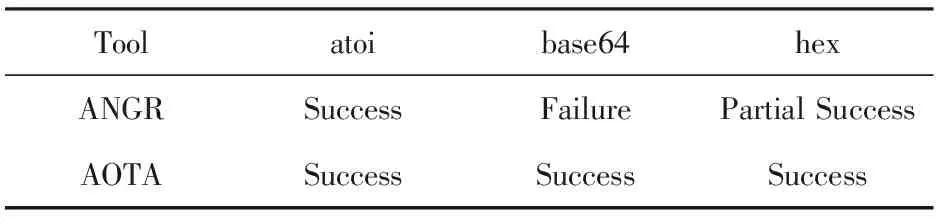
Table 1 Results of Input Solving Ability

Fig. 9 Comparison of time and memory consuming to solve atoi图9 求解atoi时间与内存消耗对比图
实验对比分析了AOTA和ANGR分别求解atoi和hex编码的资源消耗.图9(a)是ANGR和AOTA求解atoi转换的时间消耗对比,横轴是字符个数,纵轴是消耗时间的秒数.ANGR仅在字符数少于3时有求解速度上的优势,当字符数达到6以上时求解时间维持在15 s左右,而AOTA的求解时间稳定在10 s左右.图9(b)是ANGR和AOTA求解atoi转换的内存消耗对比,横轴是字符个数,纵轴是内存消耗,单位MB.ANGR在求解6字符以内的atoi时内存消耗从130 MB随字符数增多而增加,之后稳定在145 MB左右,而AOTA一直维持在60 MB左右的内存消耗.
另外,求解出的atoi输入存在非预期解,这是由于计算过程中存在整数溢出导致,如求解atoi(x)值为87654321,ANGR给出的结果是字符串“8677588913”,而并非字符串“87654321”,此处预设的字符长度并非求解出来的真实长度,求解提前到达了有解情况的最大输入长度,这也导致了ANGR后续求解时间和内存消耗不再随着预设的字符数增加而增加,而是保持在稳定的范围内.而AOTA的求解更多的时间消耗在输入输出关系的建立和收集,另外atoi的输出目标都是一个整型数,恒定为4个字符,关系建立受输入长度的影响较小,因此求解时间较为稳定.
在求解hex编码能力方面,ANGR仅在字符数少于3时能够求解成功,单字符所需的求解时间10 s左右,内存消耗400 MB以上;2字符所需时间将近300 s,内存消耗8 GB以上;当字符数达到3及以上时所需内存超过64 GB求解失败.而AOTA的求解时间随着字符数在1~10之间的增加,时间消耗在20~100 s的区间内递增,所消耗内存维持在60 MB左右,并且均能求解成功.总体而言,AOTA的求解性能优于ANGR.
与ANGR相比,本文的求解方法建立在优化的基于页表标签的动态污点分析,通过页表的多级索引提高了检索计算的效率,通过值校验的方式消除了污点数据的误标记扩散,避免了污点爆炸引起的内存额外消耗,通过污点相关性筛选出需要求解的输入字节,降低了直接使用符号执行求解的复杂度,一定程度消除了传统符号执行求解中的路径爆炸问题.实验也表明,在针对atoi,base64,hex编码的反向求解方面,本文的求解能力要优于ANGR,其中对atoi的求解效率提升了33%左右,而hex和base64编码ANGR无法成功求解.
4.3 漏洞自动挖掘能力测试
本文提出的漏洞描述模型与污点分析、输入求解结合,优化了程序漏洞的自动挖掘,在AOTA原型系统中进行了实现,与AFL-Fuzz进行了实验对比.实验以BCTF2018的50个样本作为样例测试程序,使用相同的种子文件,分成2组,每组25个测试用例,同时对50个测试用例程序进行了24 h的漏洞挖掘测试.使用4台配置型号相同的RD650服务器并行测试,配置说明见本节开头,其中2台服务器测试AFL的漏洞挖掘能力,另外2台服务器测试AOTA系统的漏洞挖掘能力.测试每隔10 min统计1次AOTA和AFL挖掘出漏洞的样本数,24 h的统计结果曲线如图10所示.

Fig. 10 Comparison of vulnerabilities sequence diagram between AOTA and AFL图10 挖掘漏洞样本数时序对比图
实验表明:相同种子输入、时间和测试用例,AOTA能挖掘出41个样本的漏洞,而AFL只挖掘出了39个样本的漏洞,并且这39个样本的漏洞包含在AOTA的41个样本范围内,同时对比这39个样本的挖掘时间发现,AOTA比AFL先挖掘出漏洞的样本有12个,AFL比AOTA先挖掘出漏洞的也有9个,其中4个是由于样本有大量的模型约束需要求解,消耗了30~60 min的时间用于约束求解,另外5个在误差允许的范围之内,但是AOTA挖掘出这39个样本的平均时间为65.72 min,而AFL挖掘出这39个样本的平均时间为121.03 min,总体上AOTA挖掘漏洞的能力与AFL相当,挖掘出漏洞的平均时间缩短了55 min,平均效率提升45.7%.
AOTA的模糊测试优化功能为18个测试样本生成了新的测试用例,将这些用例作为AOTA新增的种子集合,与AFL在相同硬件配置环境下进行模糊测试路径覆盖对比测试,得到的路径覆盖数量如图11所示,其中AOTA的平均覆盖路径数量为1 000,而AFL的平均覆盖路径数量为992,相比之下,AOTA的覆盖路径数量比AFL增加了0.8%.

Fig. 11 Comparison of paths coverage between AOTA and AFL图11 样本覆盖路径数量对比图
4.4 漏洞利用自动生成测试
本文实现的AOTA系统基于Weak-Tainted漏洞模型的漏洞识别和漏洞利用要素提取,并基于输出特征反馈对输入进行求解,实现漏洞利用自动生成,并以BCTF2018的50个样本作为测试用例进行了实验验证,实验统计结果如表2所示.
实验结果表明:本文提出的自动利用生成方法在AOTA系统中得到了实现和应用,在50个测试用例中成功发现了41个用例的漏洞,比例达到82%,其中26个判定为可利用,比例达到52%,并进行了自动利用生成的尝试,成功生成利用的有24个用例,比例达到48%.这些成功生成利用的漏洞中,包括栈溢出、格式化字符串和后门系统调用多种类型.
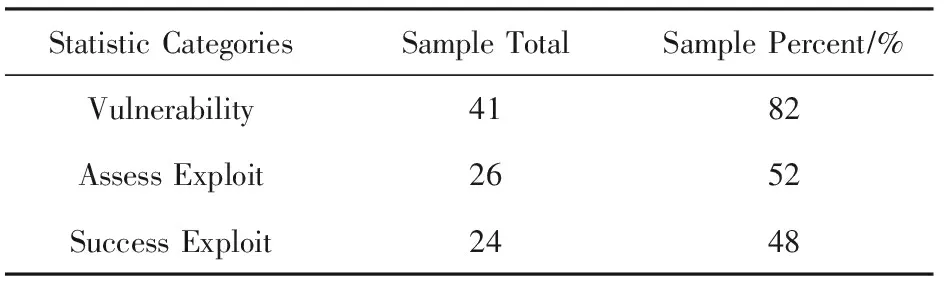
Table 2 Result of Vulnerability Automatic Discovery and Exploit
同时我们研究分析测试了ANGR的自动利用生成插件REX和AEG, 发现ANGR提供的测试用例是动态链接libc等动态库,主模块代码量较少,其本身进行了局部优化;对于BCTF这类静态链接libc等链接库,程序代码量较大(500 KB左右)的样例,ANGR的插件无法成功进行漏洞自动利用生成,并且针对单个测试用例内存消耗高达30 GB以上.
为了更充分地对比,本文重新选取了10个含原代码的测试用例,以动态链接库的方式编译出符合ANGR的AEG插件测试条件的二进制程序,同时用本文的漏洞自动利用生成模块进行对比测试,实验结果如表3所示.
表3第1个样本为ANGR项目中的测试样本,两者均能成功自动生成利用,其余9个样本为收集的BCTF比赛测试样本,ANGE的AEG插件只生成了一个exploit样本,但是测试运行时只是产生了段错误,并未能成功利用,分析原因是该漏洞是栈溢出,该AEG功能未考虑栈地址随机性.同时,实验中AEG每项失败的利用生成测试时间均超过12 h,内存消耗达到30 GB以上,单台设备每次只能运行2个任务.而本文的AOTA系统在这些测试用例中,成功生成并利用成功的样本数有6个,且能够在单台设备并发10个任务,在性能和能力方面具备明显的优势.

Table 3 Exploit Ability Comparison Between ANGR AEG and AOTA
5 讨 论
本文提出的有限资源条件下基于程序动态运行特征Weak-Tainted模型的漏洞自动挖掘与利用方法具备快速发现漏洞和生成可利用样本的能力,支持漏洞类型的自定义扩展描述,扩充了适用范围.而PolyAEG与Maythem等相关工作只能对控制流劫持等特定类型的漏洞自动生成利用,本文提出的漏洞模型支持对多种类型的漏洞自动生成利用,通过漏洞描述的配置实现多类型漏洞支持的扩展.
本文优化了污点传播算法和输入求解方法,国内对输入求解的优化研究[22]更侧重在漏洞挖掘方面提高路径覆盖率.当前的漏洞自动利用生成方案PolyAEG,Maythem,ANGR等均使用了污点传播和符号约束求解,PolyAEG在硬件虚拟化平台QEMU基础上进行指令插桩,构建指令级的数据传播流图iTPG和全局污点状态记录GTSR,其更侧重于漏洞利用样本的多样性生成,本文优化后的污点传播方法在内存消耗和效率上均优于它,同时PolyAEG未考虑因内核指令未监控导致的污点数据过标记问题,会导致控制流劫持的误报,消耗更多的资源用于无效的利用生成求解.同样,Maythem也具有同样的问题,其更侧重于符号执行求解的优化,未能消除内核未监控导致的误报问题.
另外,测试中我们发现部分的漏洞自动利用生成失败,其原因主要包括3种情况:1)输入无法满足特定字符,如通过scanf获取的输入字符串不可能有“ ”,“ ”以及空格等字符,对应的ASCII码值为0x0d和0x0a,而当求解的条件要求输入的字符为0x0d或0x0a时就会导致求解失败;2)修改后的输入改变了程序的原有逻辑,导致程序无法执行到我们设定的求解点,无法获得用于分析输入输出关系的更多数据,比如程序检测输入的数据必须全部为数字否则退出,当改变输入为非数字时就会导致程序执行不到预设的输出点;3)输入输出关系复杂度太高,如产生雪崩效应的加密算法在搜集了大量的输入输出关系之后仍然无法求解.
针对求解失败产生的原因,本节讨论可能的解决思路.针对原因1,本文的思路是修改等效的求解条件,在漏洞触发前题下,其利用输入的约束并非唯一的,比如栈溢出中所需要的跳板指令jmpesp可以用等效的callesp代替,并且在程序代码块中存在该指令的位置可能不止一处,我们在选取跳板指令时尽量避免导致输入为空格、回车等字符的约束.另外ShellCode可以进行变形,使用等效指令替换,以此规避一些导致无解的约束条件.针对原因2,我们在监测到输入导致无法执行到输出点后,只需舍弃该变异的输入,导致的结果仅仅是消耗更多的计算资源用于收集输入输出关系,但仍能继续求解.针对原因3,目前的研究尚无可行的解决方案,传统的符号执行方案也可能因为复杂度太高求解失败,毕竟对于高强度的RSA等公钥加密、SHA256等HASH算法也并非符号执行能够解决的问题,但毕竟这类问题很少出现在漏洞利用需要突破的范畴,需要将输入数据经过复杂加解密运算后作为ShellCode或者跳板指令地址的场景并不常见,但经过编码转换的情况则较为常见.
本文提出的Weak-Tainted程序动态运行时漏洞描述模型适用于控制流劫持类漏洞、格式化字符串漏洞、脆弱函数造成的缓冲区溢出漏洞、命令行执行API调用(疑似后门)漏洞等多种漏洞类型的漏洞识别和利用自动生成,但目前对UAF和Double Free仅能给出漏洞判定模型,尚未能给出适当的描述用于此类型漏洞的利用生成方案,这将作为后续的研究点.
6 总 结
本文介绍了一种有限资源条件下基于动态模型的漏洞自动利用方法,基于污点分析和输入求解优化模糊测试的数据生成,并建立了可贯穿应用于漏洞挖掘、分析、利用全流程的Weak-Tainted程序动态运行时漏洞描述模型,然后结合基于标签的污点传播方法用于漏洞判定和利用约束条件提取,最后基于输出特征反馈的输入求解方法进行利用样本自动生成.本文实现了原型系统,通过对2018年BCTF比赛样本进行了实验测试,在与AFL具备同等漏洞挖掘能力的前提下,平均效率提高45.7%,样本分析内存消耗维持在100 MB以内,为并行化提供了有利条件,在测试的50个样本中有24个能够自动生成利用代码,验证了有限资源条件下Weak-Tainted程序动态运行时漏洞描述模型用于漏洞自动挖掘与利用生成的有效性.
