基于相关信息熵和CNN-BiLSTM的工业控制系统入侵检测
2019-11-15石乐义朱红强刘祎豪
石乐义 朱红强 刘祎豪 刘 佳
(中国石油大学(华东)计算机科学与技术学院 山东青岛 266580)
工业控制系统(industrial control system, ICS)是对工业生产中的各种控制系统的统称[1].随着工业化和信息化融合发展的不断深入,工业控制系统面临更为严峻的威胁.2011年的“震网”病毒、2013年的Black Energy病毒和2017年的“永恒之蓝”病毒[2]均给工业控制系统造成严重的损害.在工业控制环境中,连续运行的生产设备会产生大量非线性的、高维度的数据,对于系统安全人员来说,面临数据处理效率低下、攻击发现迟缓的问题.
入侵检测技术作为一种有效的安全防护技术,在传统网络环境中得到了广泛的应用.入侵检测技术与传统的数据加密、防火墙等技术相比更具有优势,目前已经成为工控系统安全的研究热点.入侵检测技术通过分析工控系统中的各种通信行为,提取其中的数据特征,并利用设计的检测算法判断是否存在攻击.
传统的机器学习算法在工控系统入侵检测中取得了一定效果.Dong等人[3]将单类SVM算法应用到Modbus TCPIP协议下的异常检测中,但是对于大数据样本实施难度大,难以解决多分类问题;Eigner等人[4]将具有Bregman散度的KNN算法应用于工控系统中间人攻击检测中,但是在特征数较多时计算量大,并且样本不平衡时对稀有类别的分类精度低;Singh等人[5]将决策树应用到智能电网系统的异常检测中,但是对于样本中各属性间关联性不敏感,同时容易出现过拟合的问题.传统的机器学习方法属于浅层学习,通常需要复杂的特征工程,处理工控系统数据具有很大的局限性.因此,传统的入侵检测方法难以有效地对工业控制系统的恶意流量进行分类检测.
深度学习不同于传统的机器学习技术,通过深度的隐藏层能够对数据特征进行充分的学习.深度学习已经广泛应用于语音处理[6]、计算机视觉[7]、自然语言处理[8]等领域.近几年来,研究人员开始将深度学习应用于入侵检测领域.Tang等人[9]提出深度神经网络(deep neural network, DNN),在传统网络下利用较少的特征,取得了很好的检测效果;於帮兵等人[10]将长短期记忆(long short-term memory, LSTM)神经网络用于工业控制系统入侵检测中,对网络数据集进行多分类,分类准确率达到98.30%,但是对某些攻击类别的检测精度有待提高;Vinayakumar等人[11]将卷积神经网络(convolutional neural network, CNN)与LSTM结合用于传统网络下的入侵检测,利用KDD Cup99数据集进行验证,取得了较好的准确率;Raff等人[12]将LSTM和注意力机制(attention mechanism)[13]结合用于恶意软件的检测中,取得了较好的效果.
特征选择作为特征降维的手段,近年来在许多领域得到了广泛的应用.特征选择通过从原始特征集合中筛选出对分类作用最大的特征子集,从而有效降低计算量、提高分类精度.Hall[14]提出CFS算法,利用特征间的相关性实现特征选择,但是只能衡量2个特征的相关性;Peng等人[15]提出基于信息论的mRMR算法,充分兼顾特征和类别之间的相关性,但是没有考虑到新特征加入后特征子集的整体变化;董红斌等人[16]提出基于关联信息熵的特征选择算法,充分考虑了特征子集前后的整体变化,但是对于高维数据的算法时间复杂度较高.
通过上述分析可知,深度学习在工控系统入侵检测方面具有优势,同时特征选择对于数据降维具有很好的效果.针对工控系统数据维度较高、噪声冗余严重、传统的入侵检测方法对工控系统数据特征提取不足等问题,本文提出基于相关信息熵和CNN-BiLSTM的工控系统入侵检测模型,对工控数据进行基于相关信息熵的特征选择,然后采用融合的神经网络进行训练检测,增强工控系统入侵检测的效果.
1 工业控制系统入侵检测模型
为了降低原始数据的噪声冗余、增强工控系统入侵检测的效果,建立了工控系统入侵检测模型,模型的整体流程如图1所示.图1主要包含5个部分:1)原始的工控系统通信数据;2)预处理,包括处理样本不平衡问题、数据的归一化等操作;3)特征选择,包括基于相关信息熵的特征排序和特征子集筛选;4)核心检测,包括基于CNN和BiLSTM网络特征提取、多头注意力机制融合;5)入侵检测结果.

Fig. 1 The entire flow of the proposed model图1 本文模型的整体流程
1.1 数据预处理
本文原始的工控系统数据中存在某些攻击类别的样本数量较少从而导致不平衡样本的问题.在工控系统入侵检测中,少数类样本相对较少是影响最终检测精度的重要原因之一.本文采用基于边界的SMOTE方法(borderline-SMOTE)[17],仅对少数类的边界样本进行过采样操作,使得合成后的样本分布更加合理.
Borderline-SMOTE的过程为:1)计算少数类在训练集中各个样本Vi的K近邻样本集.2)分析该样本集中多数类的比例,进而判断Vi是否为边界样本,若是则加入边界样本集;反之,则重新放回少数类样本集.3)对边界样本Vi进行过采样操作,生成新的少数类样本Vnew:
Vnew=Vi+rand(0,1)×|Vj-Vi|,
(1)
其中,j=1,2,…,n,n表示根据采样倍率随机选取的样本数,rand(0,1)表示[0,1]的随机数.
对原始的工控系统数据采用MinMax归一化方法:

(2)
其中,xmin和xmax分别表示样本数据最小值和最大值.式(2)将结果映射到[0,1]之间.归一化有助于消除奇异数据,加快神经网络梯度下降的速度,提高分类检测精度.
1.2 基于相关信息熵的特征选择
本节采用基于相关信息熵的算法对工控系统数据按照相关度进行特征选择,充分考虑流量特征之间的相关性,以及流量特征与所属类别的相关性.相关信息熵(correlation information entropy, CIE)[18],作为信息论中信息熵的变体,常用于多传感器数据融合领域,度量多个变量之间的相关性.
根据相关信息熵理论,将原始流量特征集合X={x1,x2,…,xn}描述为n个变量的多变量系统;所属类别集合L={l1,l2,…,lm}描述为该系统的时间序列,则对应的多变量时间矩阵的转置F为

(3)
其中,每个元素为系统变量(流量特征)xi与相应的时间点(所属类别)lj的互信息Iij.
Iij=I(xi;lj)=H(xi)+H(lj)-H(xi,lj).
(4)
将矩阵F进行相应的规范化处理得到矩阵P.基于各个系统变量(流量特征)与相应时间序列(所属类别)之间的相关性构造出相关矩阵:

(5)
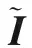
设原始特征集合为X,已排序的特征集合为S,未排序特征为X-S.从后者取出特征xi添加至前者,相关矩阵记为RS∪{xi},依据信息论原理和矩阵变换,集合S对应的相关信息熵为
(6)
其中,λRS∪{xi}表示添加xi后相关矩阵的特征值.流量特征冗余性越低,流量特征与所属类别的相关性越高,对应的相关信息熵越大.
基于相关信息熵的特征选择算法包含2个部分:特征排序部分和特征子集筛选部分.特征排序部分利用流量特征与所属类别的互信息、流量特征与已排序特征的相关信息熵进行特征排序;特征子集筛选部分运用C-SVM分类器,计算衡量值fitness,将最大衡量值对应的特征子集作为筛选出的特征子集,详细步骤如算法1所示:
算法1.基于相关信息熵的特征选择算法.
输入:数据集Draw、流量特征集合X、所属类别集合L;
输出:最大fitness对应的特征子集T.
①S=∅,T=∅;*初始化变量S用于存储已排序特征集,T用于存储选择后的特征集*
② For eachxi∈X, eachlj∈L
③ 根据式(4)计算Iij,得到矩阵F;
④ End For
⑤ 对F进行规范化处理得到矩阵P;
⑥ 根据式(5)得到相关矩阵R;
⑦S(1)=arg max(Iij),X=X-S;*取互信息最大特征作为特征子集的第1个元素,放入S集合*
⑧ Forj≤|X|
⑨ For eachxi∈X
⑩ 根据式(6)计算HS∪{xi};
1.3 CNN-BiLSTM模型
CNN和BiLSTM都是深度学习中具有代表性的算法.CNN能够逐层抽象数据局部特征,实现空间维度上提取数据特征.BiLSTM具有长期保留上下文历史信息的特性,实现时间维度上提取数据特征.在工业控制系统数据的特征提取中,不仅需要在时间层面上衡量变化规律,而且有必要考虑空间层面的特征联系.因此,本文利用CNN和BiLSTM分别提取特征,以多头注意力机制融合为一体,构建CNN-BiLSTM融合神经网络模型.模型结构如图2所示.

Fig. 2 CNN-BiLSTM fusion model图2 CNN-BiLSTM融合模型
将预处理和特征选择的样本作为输入数据,分别进入CNN和BiLSTM两种神经网络进行特征提取.
1) CNN层
卷积神经网络CNN[19]有效地解决了神经网络参数爆炸问题,本质上利用多个滤波器对输入数据进行逐层卷积、池化操作,提取其中的数据特征.一般而言,CNN结构如图3所示.

Fig. 3 CNN structure diagram图3 CNN结构图
经过CNN网络进行特征提取后,得到一个1×n维度的数据特征co:

(7)
2) BiLSTM层
长短期记忆神经网络LSTM[20]是循环神经网络RNN的改进变体,LSTM与RNN的整体结构基本相同,但隐藏层设计不同,通过记忆单元中的3个逻辑门,即输入门i、遗忘门f、输出门o,避免了反向传播过程中的梯度消失和梯度爆炸问题.LSTM单元结构如图4所示:

Fig. 4 LSTM unit图4 LSTM单元
双向长短期记忆神经网络(bi-directional LSTM, BiLSTM)是由2个方向上的LSTM模块连接而成,具有多个共享权值.与LSTM相比,BiLSTM能够兼顾前后内容对当前内容的影响,从而得到更加全面的特征信息.
经过BiLSTM网络双向操作后叠加,最终提取到的n×m维的数据特征lo:
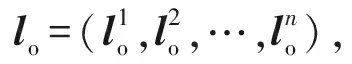
(8)

3) 多头注意力(multi-head attention)层
CNN和BiLSTM神经网络分别提取到数据特征之后,使用多头注意力机制得到融合特征MA.
注意力机制(attention mechanism)的核心思想是将有限的注意力资源集中于众多信息的少数关键信息点上,而不是将注意力平均到所有信息上.从本质上来看,注意力机制是对输入内容的加权求和.注意力机制的过程如图5所示:

Fig. 5 Attention mechanism structure diagram图5 注意力机制结构图


(9)
其中,wf表示偏置矩阵,bf表示偏置项.
(10)
多头注意力机制(multi-head attention mechanism)是注意力机制的变体,利用多个查询,平行地从输入数据中获取多个焦点信息,并将多次结果拼接起来作为最终结果,从而更加全面地把握输入内容的核心.
MA=Concat(A1,A2,…,Ahead),
(11)
其中,head表示执行多头注意力的次数.
经过多头注意力层得到融合特征MA;再经BiLSTM网络,对融合特征进行提取;最后由softmax分类器得出最终的分类结果.
2 实验与结果
2.1 数据集与评价标准
本文采用密西西比州立大学公开的工控系统入侵检测数据集[21],数据源于天然气管道控制系统的网络层数据.数据集包括1类正常数据和7类不同的攻击数据.每条记录包含26个流量特征和所属类别标签。数据描述如表1所示:
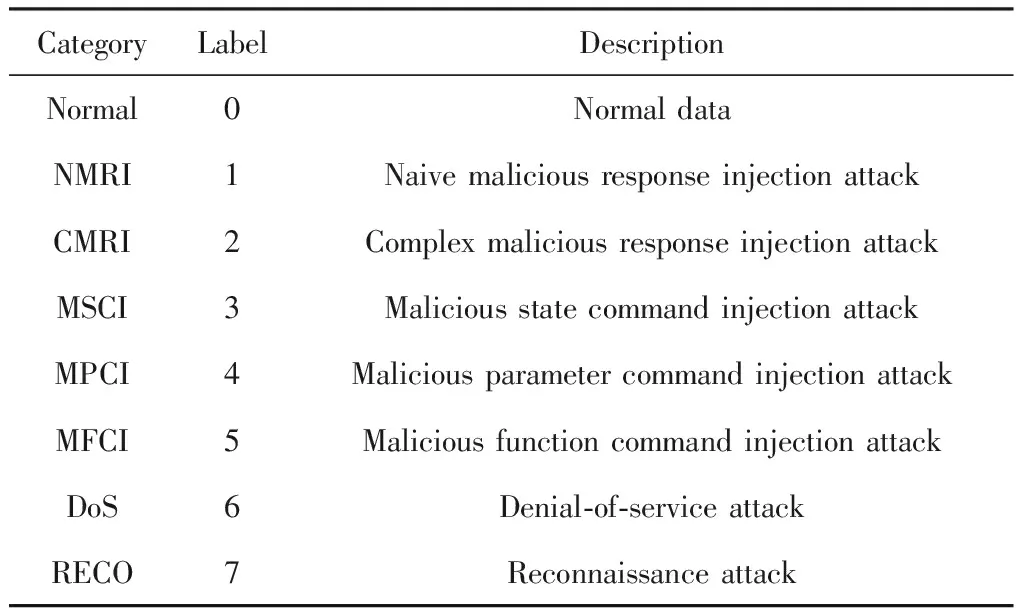
Table 1 Data Description表1 数据描述
本文选取6 000条样本,包括4 800条训练样本和1 200条测试样本,通过5折交叉验证进行实验.预处理和特征选择部分的实验环境是Matlab 2015 b和LibSVM,神经网络部分的实验环境是基于TensorFlow的Keras深度学习平台,配置包括:Intel i5-8300H CPU 2.3 GHz、NVIDIA GeForce GTX 1050Ti、8 GB内存、Win64位操作系统.
本文特征选择的目的是筛选出对分类影响较大的特征子集,针对工控系统入侵检测需要较高的准确率和较小的特征子集,衡量指标为
fitness=α×ACCi+β×dD,
(12)
其中,α和β表示调节参数,d表示特征子集的维度,D表示原始特征集的维度.
同时为了衡量模型的检测性能,根据混淆矩阵的定义,得出准确率(ACC)、漏报率(FNR)和误报率(FPR):
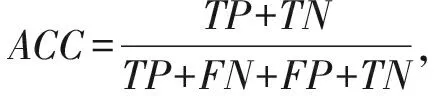
(13)
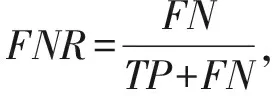
(14)

(15)
其中,TP,FP,TN,FN分别表示正确分类的正常样本数、错误分类的正常样本数、正确分类的异常样本数、错误分类的异常样本数.
2.2 模型实现与参数优化
为了验证本模型的有效性,本文进行了多组对比实验.包括采用Borderline-SMOTE合成少数类前后的效果对比;采用基于相关信息熵的特征选择前后的效果对比;通过调节参数对比CNN-BiLSTM模型的性能.
1) Borderline-SMOTE合成少数类前后效果对比
本文采用的天然气管道数据集,MFCI类的样本数量极少,使得数据集存在不平衡的问题.采用Borderline-SMOTE方法进行相应合成,选取参数近邻k=8,采样倍率n=4.实验结果如表2所示:

Table 2 Experimental Results Before and After Borderline-SMOTE
Borderline-SMOTE算法有效提高了MFCI类样本的检测率,同时有效地降低了分类的漏报率、提高了准确率.
2) 基于相关信息熵的特征选择前后效果对比

Fig. 6 Curve of fitness图6 特征衡量值变化曲线
本文采用基于相关信息熵的算法对数据集进行特征选择,采用C-SVM作为分类器,RBF作为核函数,核半径g=2.4,惩罚系数c=1.2,式(12)作为特征衡量值fitness计算函数.
如图6所示,从特征衡量值的变化曲线可以看出当特征子集小于14时,特征衡量值一直处于增长趋势,分类性能逐步提高;当特征子集为14时,特征衡量值达到最大,分类效果最佳;当特征子集大于14时,特征衡量值呈现下降趋势,分类性能逐步降低.因此,选取特征个数为14时,对应的特征子集为最终筛选的特征子集.特征选择前后的入侵检测性能对比如表3所示,可以看出检测的准确率明显提高,平均检测时间降低.

Table 3 Experimental Results Before and AfterFeature Selection
3) CNN-BiLSTM融合模型参数调优
CNN-BiLSTM模型主要参数包括:BiLSTM隐藏层节点个数units、卷积核大小ks、多头注意力head个数等.因此,选择BiLSTM隐藏层节点个数为20,50,80;卷积核大小为1,3,5.其他参数为默认值,损失函数采用categorical_crossentropy.经过实验对比,实验结果如表4所示:

Table 4 Effect of Different Parameters表4 不同参数的效果
为确定多头注意力head个数对实验效果的影响,在上述参数配置条件下,选取head个数为1~9进行实验.结果如表5所示,head=6时检测效果最佳.

Table 5 Effect of Different head Numbers表5 不同head个数的效果
具体的模型结构和参数如图7所示:
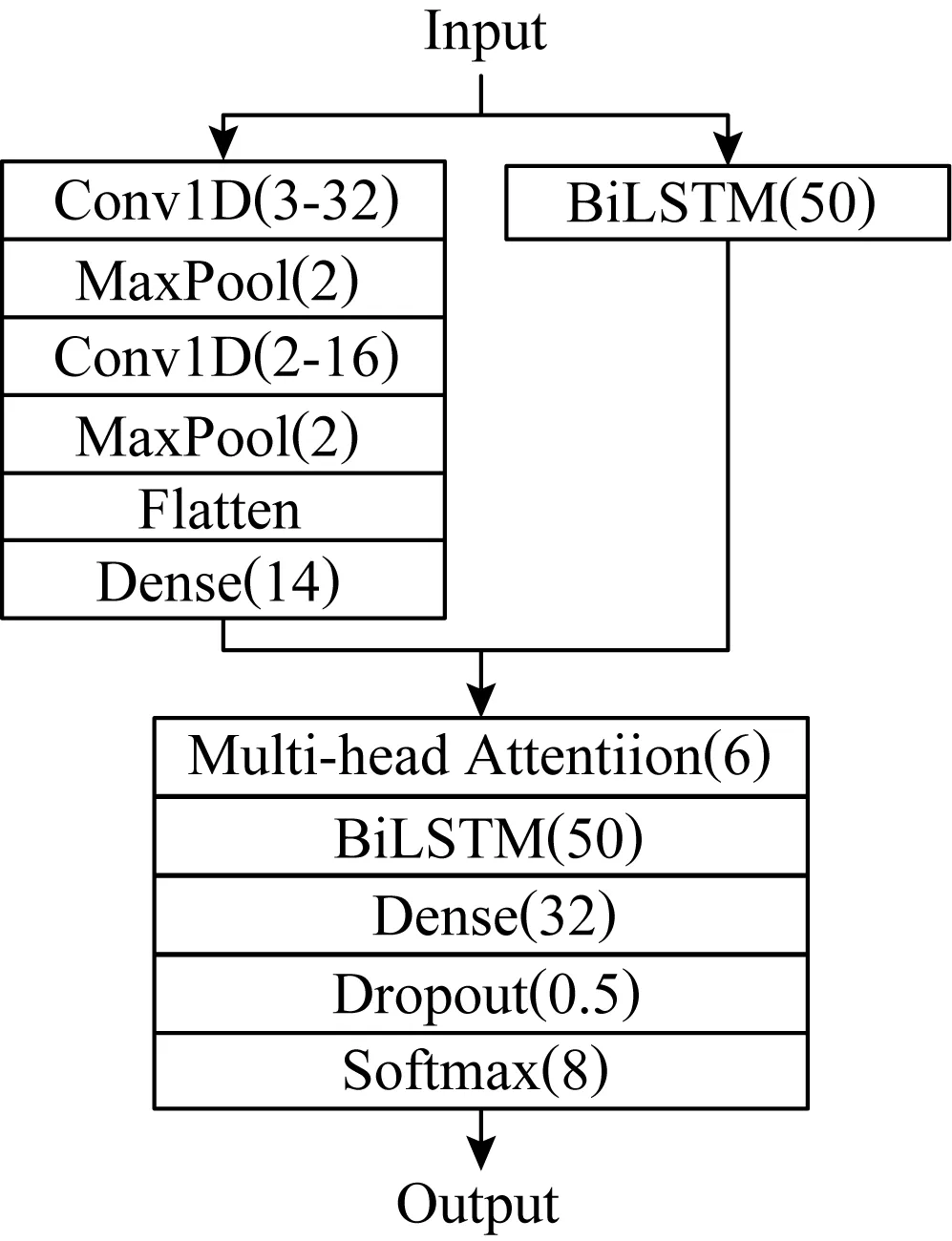
Fig. 7 Structure and parameters of CNN-BiLSTM fusion model图7 CNN-BiLSTM融合模型的结构和参数
图7中输入样本表示为张量(?,14,14),其中?表示批处理的样本数量;卷积层表示为(卷积核大小-通道数).
在CNN-BiLSTM模型中,我们将输入样本分别通过CNN和BiLSTM网络提取特征.在CNN网络中,首先输入样本分别进行2次一维卷积操作和下采样操作,第1个Conv1D层采用32个尺寸为3的卷积核提取特征,激活函数为relu;第2个Conv1D层采用16个尺寸为2的卷积核.2次下采样操作均利用MaxPool层,池化窗口尺寸为2.然后,经过Flatten层压缩为一维张量,输入Dense层,最终CNN提取的数据特征维度为(?,14).在BiLSTM网络中,输入样本经过BiLSTM的隐藏层输出,得到BiLSTM提取的数据特征维度为(?,14,50).
上述2个网络提取的数据特征经过Multi-head Attention层6次提取融合,得到融合特征.然后输入BiLSTM网络层,最后通过一个输出维度为32的Dense层,丢失率为0.5的Dropout层,使用激活函数为softmax的全连接层输出最终的分类结果,张量维度为(?,8).
2.3 结果分析
为了验证本文提出的方法在工业控制系统入侵检测领域的优势,首先将融合模型CNN-BiLSTM与单CNN、单BiLSTM的方法进行实验比较检测精度,3种深度算法的迭代训练效果如图8所示;然后将本文方法与CNN,BiLSTM,GRU,SVM,KNN算法的准确率、漏报率和误报率进行实验比较,如表6所示;最后将本文方法与上述算法对各类样本的分类正确率的进行实验比较,如图9所示.

Fig. 8 Training curves of the deep learning algorithm图8 深度学习算法训练曲线

MethodACC∕%FNR∕%FPR∕%Running Time∕sSVM91.728.703.573.90KNN93.114.122.112.78CNN98.232.122.6011.05GRU98.332.532.1810.84BiLSTM98.502.402.1611.29Our Method99.210.771.0211.75
从图8可以看出,CNN-BiLSTM,CNN和BiLSTM算法在第8次迭代之后训练精度趋于稳定,总体上来看,三者的训练精度都稳定在98.4%以上,CNN-BiLSTM的融合设计提升了工控系统入侵检测的效果,明显好于单BiLSTM、单CNN的方法.另外BiLSTM的训练精度整体稍高于CNN,而CNN的训练稳定性稍好于BiLSTM.
从表6看出,本文方法的分类准确率最高,达到99.21%,同时漏报率明显降低,更加符合工控系统安全需求.虽然深度学习算法的检测用时相比于传统机器学习算法长,但是检测效果明显好于后者.其中GRU检测精度低于BiLSTM和本文方法,SVM,KNN算法的漏报率非常高,对正常样本不能有效识别,SVM算法的误报率较高,对攻击样本的检测效果较差.
图9是上述方法对各类样本数据的分类效果图,由图可知,本文方法对于各种类型样本的检测正确率都高于其他算法,特别是对于Normal,MPCI和RECO的分类效果最好;对于MFCI类样本,各种算法的效果均欠佳;对于RECO类样本,各种算法的效果最佳.
3 总 结
本文提出一种基于相关信息熵和CNN-BiLSTM的工业控制系统入侵检测模型,将基于相关信息熵的特征选择算法用于工业控制系统入侵检测中,去除原始工控系统数据中的噪声信息、冗余特征等;将处理之后的数据输入CNN-BiLSTM融合模型,分别利用CNN和BiLSTM从空间和时间维度提取数据特征,并运用多头注意力机制进行特征融合,取得了较好的检测效果.
通过将本文方法与深度算法CNN,BiLSTM,GRU以及传统的机器学习算法SVM,KNN进行实验对比,从整体的检测效果和不同类别样本的检测效果方面进行分析,结果表明本文提出的模型有效提高了工控入侵检测的准确率(99.21%),大幅降低了漏报率(0.77%),为工业控制系统入侵检测提供了一种新的思路.
