基于跨视角判别词典嵌入的行人再识别
2019-11-15董虎胜龚声蓉
陆 萍 董虎胜 钟 珊 龚声蓉
1(苏州经贸学院信息技术学院 江苏苏州 215009) 2(浙江大学计算机科学与技术学院 杭州 310027) 3(常熟理工学院 江苏常熟 215500)
在具有不重叠视域的摄像机监控网络中,根据行人表观信息进行跨摄像机身份关联的工作也被称为行人再识别[1],它是实现对特定目标的检索[2]、持续跟踪[3]和行为分析等智能视频监控应用的一项关键技术.由于受到光照、视角、姿态与遮挡等因素的影响,同一行人在不同摄像机拍摄的画面中可能会呈现出很大的外观差异,这给行人再识别带来了相当大的困难.由于在智能视频监控中具有广阔的应用前景,行人再识别引起了计算机视觉与机器学习领域广泛的关注并开展了大量的研究[4-6].
目前对行人再识别的研究可分为传统方法与基于深度学习的方法两大类.其中深度学习方法需要有大量标注的训练数据,因此在大型数据集上通常能够取得比较优秀的性能[7-8].但在较小的数据集上,深度学习模型极易发生过拟合问题,在性能上仍弱于传统的方法.本文工作主要关注小数据集上的行人再识别问题,且归属于传统方法类别.应用传统方法的行人再识别工作主要从特征描述子设计与度量学习算法两个方面来开展.
为了从行人图像中获取具有判别性的表观信息,研究人员设计了一系列用于行人图像匹配的特征描述子,如局部最大出现特征[6](local maximal occurrence, LOMO)、显著颜色名称[9](salient color names, SCN)、条状加权直方图[10](weighted histograms of overlapping stripes, WHOS)等,它们有力地促进了行人再识别研究的进展.但是由于不同摄像机下行人外观常常会存在很大的差异,同一摄像机下还会有行人外观相近的情况,以及特征描述子在语意上的模糊性等原因,使得特征描述子的表达能力受到了一定的限制.
直接在原始特征表达空间中进行行人再识别的准确率通常都比较低,通过学习度量矩阵将它们投影到更具判别性的子空间中通常能够带来比较显著的性能提升[11].度量学习旨在从训练数据中学习到某一特定的投影空间,使得具有相同标签的行人图像在该嵌入子空间中距离被收缩,而具有不同标签的图像之间的距离被拉大[12-13].尽管度量学习方法能够获得更为优秀的匹配效果,它们仍然会受到特征表达能力的影响.
针对行人外观描述子与距离度量表达能力受限的问题,本文提出了一种基于跨视角判别词典嵌入(cross-view discriminative dictionary learning with metric embedding, CDDM)的行人再识别匹配模型.在该模型中通过学习跨视角的判别词典将原始特征表达为过完备基(over-complete basis)的组合系数向量,从而获得比原始特征描述子更为鲁棒的表达.但与文献[14-15]等仅学习词典表达的方法不同,本文方法还利用了训练样本及标签中蕴含的距离约束信息,在学习判别词典的同时联合学习了一个度量矩阵来进行子空间嵌入,这样就可以在更具判别性的子空间中进行行人相似度的匹配.针对不同摄像机下行人图像正负样本对数量严重不均衡引起的度量偏差问题,本文还设计了样本对自适应权重分配策略.在VIPeR,GRID,3DPeS数据集上的实验结果验证了本文算法的有效性.
1 相关工作
在行人再识别的研究工作中,特征设计受到关注相对较早.为了抑制各种引起行人外观变化的因素,在行人再识别特征描述子的设计中大多使用了颜色、纹理与形状等信息.在Liao等人[6]设计的LOMO描述子中,从滑动窗口中提取了联合HSV直方图和尺度不变局部三值模式(scale invariant local ternary pattern, SILTP),并运用最大池化(max pooling)操作来增强描述子的抗视角变化能力.Matsukawa等人[16]使用层次化的高斯模型来表达图像的颜色信息,设计了高斯化高斯(Gaussian of Gaussian, GOG)描述子.Yang等人[9]从像素概率分布的角度提出了显著颜色名称SCN特征.Zhao等人[17]通过学习最具有判别性的中层滤波器特征来表达行人图像外观.Ma等人[18]设计了使用协方差描述的生物启发特征(bio-inspired features, BIF).
在获得行人图像的特征描述子之后,度量学习能够利用训练数据的标签信息,根据特定的距离约束来学习获得更有效的距离计算模型,取得更高的行人再识别准确率.Mignon等人[19]设计了成对约束元件分析(pairwise constrained component analysis, PCCA)算法从高维样本中学习投影子空间;Liao等人[20]提出了对训练样本采用不对称加权策略的度量学习方法.Zheng等人[21]提出了概率相对距离比较模型(probabilistic relative distance comparison, PRDC),You等人[22]在引入更严格的最近负样本约束后设计了“顶推”(top push)学习模型.利用贝叶斯准则,Köestinger等人[23]提出了具有闭合形式解的简单直接度量(keep it simple and straightforward metric, KISSME)学习方法.Liao等人[6]对KISSME加以改进后提出了联合学习度量矩阵与投影子空间的跨视角二次判别分析(cross-view quadratic discriminant analysis, XQDA)方法.
从训练数据中学习判别性词典能够将原始特征表达为更鲁棒的组合系数向量,实现对原始特征的变换[24].在文献[25]中,Liu等人通过学习跨视角的半监督耦合词典来匹配行人图像.Prates等人[26]通过学习核化的跨视角词典,使用协同表达向量来对行人图像进行匹配.Zhang等人[27]为每个行人学习了支持向量机(support vector machine, SVM)的判别向量,并进一步创建最小二乘半耦合词典.Srikrishna等人[14]通过对相互关联的稀疏编码施加判别约束来解决行人图像因视角变化引起的差异.Kodirov等人[28]通过引入L1范数的拉普拉斯图正则项来进行无监督的行人再识别.
与上述工作不同,本文方法采用了联合学习度量矩阵与判别词典的策略.在学习模型中充分挖掘了不同视角下词典表达的内在联系与距离约束,把度量学习与词典学习的优势结合起来进行行人再识别.
2 跨视角判别词典嵌入
2.1 词典学习

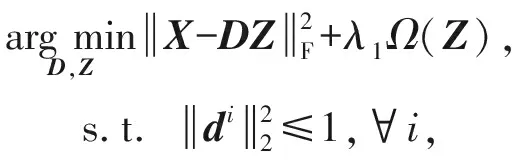
(1)

2.2 跨视角判别词典嵌入模型
在行人再识别中,需要对不同摄像机下捕捉到的行人图像进行相似度匹配.但采用式(1)学习到的词典无法捕捉不同视角下数据的内在结构,针对该问题,在本文方法中为每个摄像机视角分别学习了词典表达.设Xp∈Rd×n与Xg∈Rd×n分别为训练集中检测集(probe set)与匹配集(gallery set)的特征矩阵;Y∈Rn×n为它们之间的匹配标签矩阵;D∈Rd×m为对应的判别词典;可以建立的跨视角判别词典学习模型为

(2)
其中,λ1为调节系数;Zp∈Rm×n和Zg∈Rm×n分别指代Xp与Xg在使用词典D表达时的组合系数向量,也就是变换后的特征表达.式(2)的前2项表达了学习词典对原始特征数据的重建误差,后2项为正则项,用来抑制模型的过拟合风险.
尽管式(2)能够描述跨视角行人图像数据的内在结构,但是对训练数据与标签中蕴含的距离约束信息却未能有效利用.在行人再识别中,我们希望不同摄像机视角下正确匹配图像(正样本对)之间距离应尽可能的小,而错误匹配图像(负样本对)间的距离要尽可能的大,从而在正、负样本之间建立起一个距离间隔.这样就可以在给定某一检索图像后,达到将正确匹配图像从所有待匹配图像中识别出来的目标.为此,本文引入的约束损失函数为

(3)


(4)
其中M为待求解的距离度量矩阵,其半正定性(M0)保证了dM能够满足距离所需的三角不等式与非负性.对M可进一步作Cholesky分解得M=WTW,因此式(3)等价于:
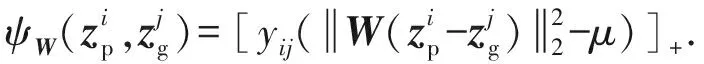
(5)
在行人再识别中,由于不同摄像机下错误匹配行人图像的数量远多于正确匹配图像,这会使得学习到的度量矩阵倾向于将所有行人图像对判定为错误匹配,引起度量偏差问题[20].为了解决该问题,可以采用从训练样本邻域学习度量矩阵的方案[29],通过减少容易识别的负样本对在模型中的贡献度来抑制数据不平衡问题.由此可以把整个训练集上的损失函数表达为
(6)

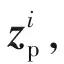

(7)

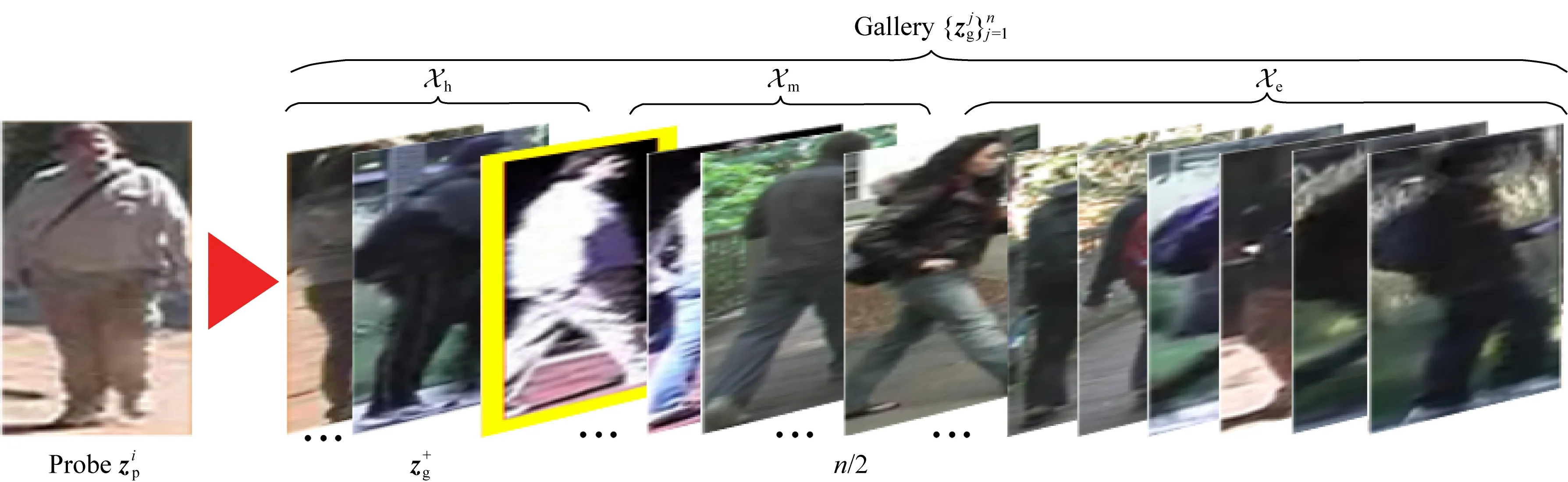
Fig. 1 Partition of the hardmediumeasy sets图1 困难中等容易匹配集划分示意
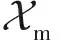
根据分析,本文采用的训练样本对自适应加权方案为:若yij=1即为正确匹配时,取βij=1N+,这里N+为训练集中正样本对的数量;若yij=-1,βij取值为

(8)

根据式(2)与式(6),可以将本文提出的联合学习跨视角判别词典与度量嵌入的模型表达为
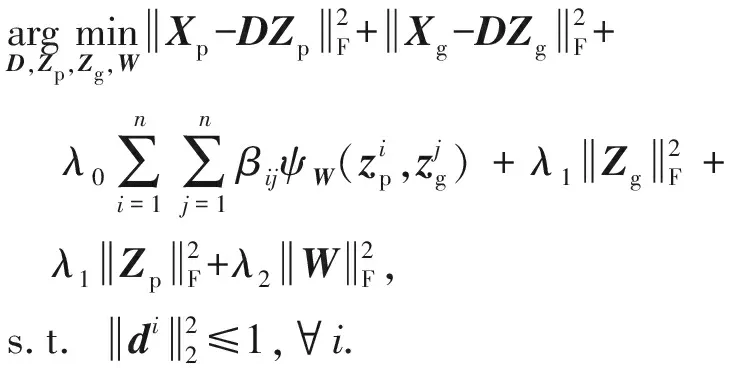
(9)
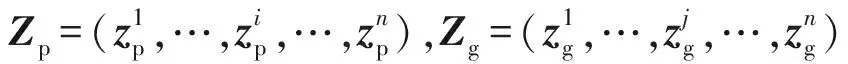

Fig. 2 Illustration of the adaptive weight assignment in 2-dimensional space图2 二维空间中样本自适应权重分配示例
2.3 模型优化
在式(9)所示的模型中需要同时优化D,Zp,Zg,W这4个相互耦合的参数,模型并非关于所有参数联合凸,因此无法对它们同时进行优化.但该模型中各项均为二次项或max函数,在固定其他参数仅优化某一变量时为凸模型,故本文采用交替优化的方法来求解各模型参数.
1) 更新Zp
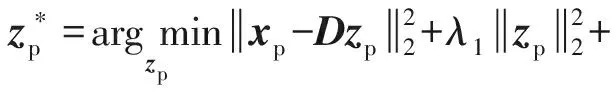
(10)

(11)

2) 更新Zg
与优化Zp类似,在对式(9)固定D,Zp,W,对Zg进行优化时也需要采取逐列优化zg的方式,最终可以获得的解表达式为
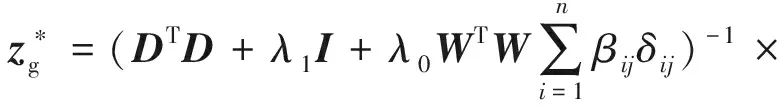
(12)
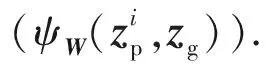
3) 更新D
在固定Zp,Zg,W对式(9)仅考虑D的优化时,等价于二次规划问题:

聚焦精准施策。强化因村因户因人施策,在全面实施脱贫攻坚“十大工程”的基础上,结合实际,突出重点,分类施策,实施产业扶贫全覆盖,推广“选准一项优势主导产业、组建一个合作组织、设立一笔贷款风险补偿金、落实一个部门帮扶机制”四位一体的产业扶贫模式,因地制宜扶持贫困户发展特色种养业及乡村旅游、光伏、电商等新兴产业实现增收脱贫。实施健康扶贫再提升,在全面筑牢基本医保、大病保险、补充保险、医疗救助四道防线基础上,探索“爱心”救助的第五道保障线。同时,推进教育扶贫再对接、易地扶贫搬迁再精准、贫困村村庄整治再推进重点工程,确保扶到点上、帮到根上。
(13)
为简化求解,这里令X=(Xp,Xg)表示检索集特征矩阵与匹配集特征矩阵的拼合矩阵;类似地,令Z=(Zp,Zg)为学习到的系数矩阵的拼合.对式(13)应用拉格朗日对偶方法可以解得:
D=XZT(ZZT+Λ*)-1,
(14)
其中,Λ*为由最优对偶变量组成的一个对角矩阵.在实际运算时ZZT+Λ*可能会出现奇异的情况,此时可以进行适当的正则平滑或取伪逆.
4) 更新W
在固定Zp,Zg,D时,式(6)关于W的优化目标等价于:
(15)
对式(15)计算关于W的导数:
(16)


(17)
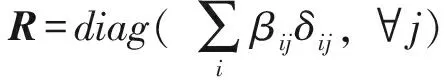
最终,本文提出的联合学习跨视角判别词典与嵌入矩阵的算法模型可以被描述为算法1所示的流程框架,本文将其称为跨视角判别词典嵌入(cross-view discriminative dictionary learning with metric embedding, CDDM)算法.
算法1.跨视角判别词典嵌入(CDDM)算法.
输入:训练集特征矩阵Xp,Xg,标签矩阵Y,参数λ0,λ1,λ2;
初始化:根据式(2)获得初始的D,Zp,Zg,W=I,μ=E[dI(zp,zg)];
① fort=1,2,…,Tdo
② 根据式(4)(7)(8)计算βij;
③ 根据式(11)更新Zp;
④ 根据式(12)更新Zg;
⑤ 根据式(14)更新D;
⑥ while不收敛do
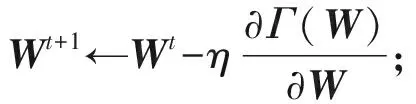
⑨ end while
⑩ end for
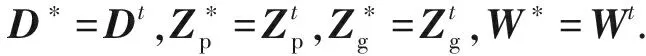
2.4 在行人再识别中的应用


(18)
2) 采用类似过程1)的方法根据式(18)获得xpt的系数表达zpt.
4) 对距离向量d排序,获得各匹配图像按距离升序排序的列表.
3 实 验
本节对提出的跨视角判别词典嵌入算法CDDM在VIPeR,GRID,3DPeS这3个常用的行人识别数据集上进行了性能测试,并对实验结果进行了比较和分析.
3.1 实验设置
1) 数据集
实验使用3个数据集:
① VIPeR[30]是最早公开的专门用于检测行人再识别算法性能的数据集,在行人再识别的研究中应用最为广泛.该数据集中包含有从2个不重叠摄像机视角下拍摄的632个行人,每个行人在各摄像机下均只有1张图像,因此该数据集共有1 264张图像.这些行人图像已经被统一为128×48的像素大小,他们在不同视角下的外观差异主要来自于强烈的光照变化、姿态与视角差异.
② GRID数据集[3]由安装在地铁站中的8台摄像机拍摄获得,行人图像被组织到了检索集Probe与匹配集Gallery 2个目录下.其中有250个行人在2个目录下各有1张图片,Gallery目录下还有775个行人在Probe下没有正确匹配的图像.由于存在干扰图像和强烈的光照视角变化,以及摄像机视角数多达8个,在GRID数据集上的行人再识别工作相当困难.
③ 3DPeS数据集[31]中包含有从8个摄像机视角下拍摄的192个行人,每个行人的图像数为2~26张不等.由于3DPeS在采集时持续了数天中不同的时间段,因此该数据集中的图像存在强烈的光照变化,另外行人在不同摄像机下的姿态差异也比较大.
图3给出了从上述3个数据集中随机选取的部分行人图像示例,每一列的2张图像取自于同一行人在不同摄像机下的视频画面.

Fig. 3 Example images from VIPeR, GRID, and 3DPeS图3 VIPeR,GRID,3DPeS数据集中部分行人图像
2) 特征提取
实验中采用了文献[32]中改进后的局部最大出现特征和使用深度残差网络[33](deep residual net, ResNet)提取的深度特征来表达行人图像.在文献[32]设计的特征描述子中融合了从密集网格提取的LOMO[6]描述子与从图像前景两层水平条空间中提取的LOMO变体,其中使用的基本特征有联合HSV与RGB颜色直方图、局部三值模式(local ternary pattern, LTP)和显著颜色名称SCN特征.该描述子中从密集网格提取的特征能够比较好地捕捉图像的细节,从水平条中提取的特征能够更好地刻画图像的整体外观,两者的融合赋予了描述子“由粗到细”的行人外观表达能力.在使用深度残差网络提取图像特征时,使用了在ImageNet上训练好的152层的ResNet-152网络,提取的特征为2 048维.
3) 参数设置
实验中模型的超参数通过交叉验证获得,具体设置为λ0=1,λ1=0.2,λ2=0.1.在使用梯度下降更新W时,学习率η的初始值设为0.01;在迭代中若目标函数值下降则对η扩大1.2倍,否则对η乘上0.9的收缩因子.在选择词典基的数量时取m=200,关于基数量的选择将在3.4节中作进一步的讨论.
4) 评价方案与指标
实验中对各数据集均采用了单张-单张(single-shot vs single-shot)的匹配测试方案,由于在3DPeS中每个行人的图像数不等,因此与文献[34]中的方法相同,对每个行人随机选择一张图像用于检索,剩余图像均作为匹配集.在评价指标上选择了在行人再识别研究中应用最为广泛的累积匹配特征(cumulative matching characteristic, CMC)曲线,它反映了在前个匹配集图像中发现正确匹配的概率.为了便于和文献公开的方法作性能对比,在表格中仅选择了CMC曲线部分排序位置(rank)上的匹配精度.为了获得更具有鲁棒性的实验结果,在每个数据集上都进行了10次随机的训练集测试集划分,取它们的平均CMC作为最终实验数据.
3.2 与文献公开的结果对比
实验中首先把本文CDDM算法在各个数据集上取得的行人再识别结果与文献中公开的数值进行了对比.
在VIPeR数据集上进行行人再识别时采用了当前应用最为广泛的等量划分方案,数据集中632个行人被划分为2组,每组316个行人.其中一组作为训练集,另一组作为测试集.实验对比的方法包含有监督平滑流形[35](supervised smoothed mani-fold, SSM)方法、空间约束相似度学习34](spatial constrained similarity learning on polynomial feature map, SCSP)算法、零空间Foley-Sammon变换[11](null Foley-Sammon transform, NFST)、度量组合[13](metric ensemble, ME)、摄像机相关性已知的特征扩增[36](camera correlation aware feature augmentation, CRAFT)、加权线性编码[37](weighted linear coding, WLC)、基于核化跨视角协同表达分类[26](kernel cross-view collaborative representation based classification, KX-CRC)、基于加速近邻梯度的度量学习[20](metric learning by accelerated proximal gradient, MLAPG)、XQDA[6]、GOG[16]、深度多层相似度[5](deep multi-level similarity, DMS)和SpindleNet[7]等.
表1与图4(1)由于表1中部分方法未公开代码或CMC,因此未能全部绘制.给出了CDDM算法及其他算法在VIPeR数据集上的行人再识别结果对比.从对比结果可以看出CDDM在性能上明显优于其他方法.特别是在rank-1上,CDDM取得了60.93%的正确匹配率,也是唯一达到60%匹配率的方法.和此前SpindelNet取得的最优结果53.80%相比,CDDM比其高出了7.13%,这充分展现了CDDM优异的性能.在其他的各个rank上,CDDM也表现出显著的性能优势.在对比方法中,SpindelNet,CRAFT,DMS都是基于深度学习模型的方法,但是在VIPeR数据集上由于样本相对较少,无法完全发挥它们的性能,虽然它们在rank-1上都达到50%以上的匹配率,但整体性能仍相对较弱.在对比方法中SSM,SCSP,NFST,MLAPG,XQDA等均为度量学习算法,KX-CRC与WLC为基于词典学习的方法,与它们相比,CDDM联合学习了判别词典与度量矩阵,能够同时利用两者的优势,因此具有更强的匹配性能.
在GRID数据集上,实验中将在Probe与Gallery目录下都有图像的250人均分为2组.其中一组作为训练集,另一组和Gallery目录下的775张干扰图像作为测试集.在该数据集上本文CDDM算法与样本独立的SVM[27](sample specific SVM, SSSVM),NK3ML[38](nullspace kernel maximum margin metric learning)等其他文献中公开的结果对比如表2和图5所示.从表2可知,CDDM再次取得了最优的结果.在rank-1上CDDM取得的正确匹配率达到了28.20%,比此前最优的NK3ML和SSM高出了1%,在其他rank上CDDM也取得了更为优秀的再识别性能.这说明CDDM能够较好地应对GRID数据集中复杂的视角变化与光照等干扰.
Table 1Performance Comparison of CDDM with State-of-the-Art Algorithms on VIPeR
表1 CDDM与其他算法在VIPeR数据集上匹配率对比%

Methodrank-1rank-5rank-10rank-20ReferenceCDDM60.9386.6893.8998.35OursSpindelNet53.8074.1083.2092.10Ref[7]SSM53.7391.49 96.08Ref[35]SCSP53.5482.5991.4996.65Ref[34]KX-CRC51.4081.2089.7095.60Ref[26]WLC51.4076.4084.80Ref[37]NFST51.1782.0990.5195.52Ref[11]CRAFT50.2879.9789.5695.51Ref[36]DMS50.1073.1084.35Ref[5]GOG49.7279.7288.6794.53Ref[16]ME45.9077.5088.9095.80Ref[13]MLAPG40.7369.9682.3492.37Ref[20]XQDA40.0068.1380.5191.08Ref[6]

Fig. 4 CMC curves of different algorithms on VIPeR dataset图4 不同算法在VIPeR数据集上的CMC曲线
在3DPeS数据集上实验时采用了与文献[34]相同的数据集分割方案,从该数据集随机选择96人作为训练集,剩余96人作为测试集.对于每个行人,随机选择一张图像来创建匹配集,剩余图像均用于检索.在该数据集上与本文CDDM算法进行对比的方法有核化局部Fisher线性判别[39](kernel local Fisher discriminant analysis, KLFDA)、深度排序大间隔度量学习[40](deep ranking by large adaptive margin learning, DRLAML)、域引导丢弃方法[41](domain guided dropout, DGD)、SpindelNet、SCSP和ME.表3列出了这些算法在rank1,5,10,20上取得的累积匹配正确率.
Table 2Performance Comparison of CDDM with State-of-the-Art Algorithms on GRID
表2 CDDM与其他算法在GRID数据集上匹配率对比%

Methodrank-1rank-5rank-10rank-20ReferenceCDDM28.2052.4064.0074.10OursNK3ML27.2060.9671.04Ref[38]SSM27.2061.1270.56Ref[35]KX-CRC26.9045.7057.5070.20Ref[26]CRAFT26.0050.6062.5073.30Ref[36]GOG24.7246.9658.4068.96Ref[16]SCSP24.2444.5654.0865.20Ref[34]SSSVM22.4040.4051.2861.20Ref[35]MLAPG16.6433.1241.2052.96Ref[20]XQDA16.5633.8441.8452.40Ref[6]
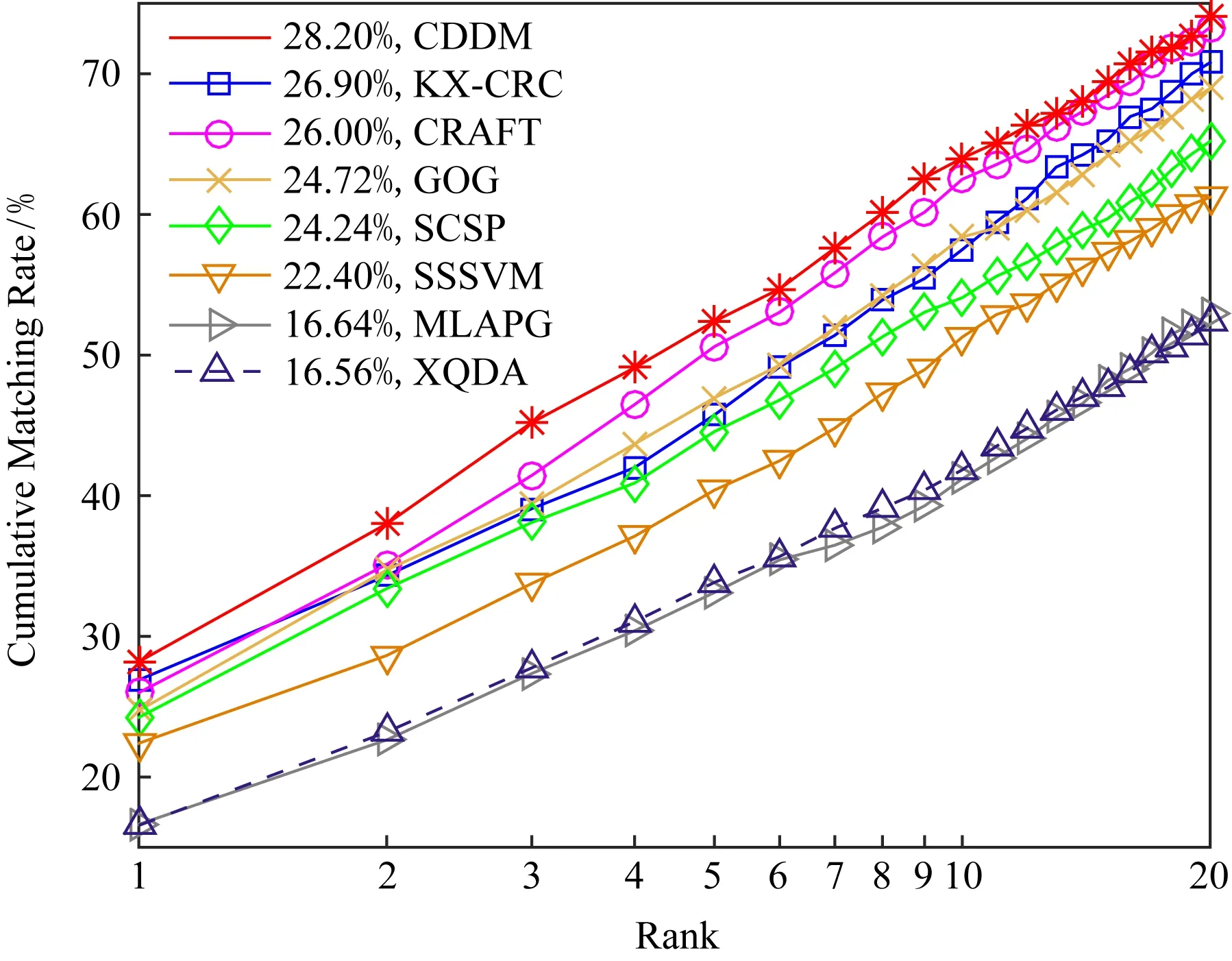
Fig. 5 CMC curves of different algorithms on GRID dataset图5 不同算法在GRID数据集上的CMC曲线
从表3中的数据可以看出与其他方法相比,本文CDDM算法取得的匹配结果依然领先于其他方法.在rank-1上CDDM的匹配率为65.57%,比排在第2名的SpindelNet高出了3.47%,在其他rank上也均优于各对比方法.尽管基于深度学习方法的SpindelNet,DGD,DRLAML在该数据集上的识别性能比其他方法有所提升,但仍弱于本文CDDM算法.与SCSP,ME,KLFDA等度量学习方法相比,CDDM也具有明显的性能优势.
Table 3Performance Comparison of CDDM with State-of-the-Art Algorithms on 3DPeS
表3 CDDM与其他算法在3DPeS数据集上匹配率对比%
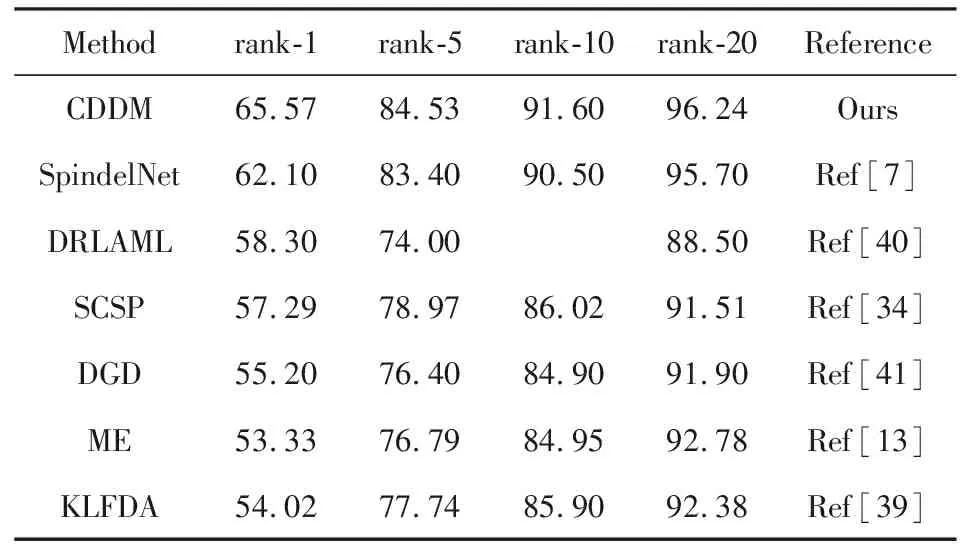
Methodrank-1rank-5rank-10rank-20ReferenceCDDM65.5784.5391.6096.24OursSpindelNet62.1083.4090.5095.70Ref[7]DRLAML58.3074.0088.50Ref[40]SCSP57.2978.9786.0291.51Ref[34]DGD55.2076.4084.9091.90Ref[41]ME53.3376.7984.9592.78Ref[13]KLFDA54.0277.7485.9092.38Ref[39]
3.3 采用相同特征描述子时算法性能比较
在3.2节的行人再识别结果数据对比中,尽管各算法模型均采用了相同的数据集划分方案,但是各模型的结构与使用的特征描述子各不相同,因此性能对比中必然存在一定的不公平性.特别是对于SpindelNet[7]等基于深度学习的方法,尽管已经取得比较优异的性能,但是受到数据集中样本数量较少的限制,它们的性能难以得到完全发挥.为了进一步对CDDM算法的性能进行分析,本节对CDDM与其他可获得源码的算法在采用相同特征时的再识别性能进行了测试.实验中对比的方法有SSSVM,MLAPG,XQDA,KLFDA,NFST,KX-CRC,其中SSSVM和KX-CRC为学习判别词典的方法,其余为度量学习方法.
采用本文使用的特征描述子,在3个数据集上各算法取得的CMC曲线及rank-1匹配率如图6所示.从图6可以看出本文CDDM算法在3个数据集上均取得了优于其他算法的匹配性能.在VIPeR数据集上,CDDM的rank-1匹配率为60.93%,排在第2名的是XQDA,其正确匹配率为58.72%,比CDDM弱了2.21%.在GRID与3DPeS数据集上,排在第2名的方法分别是NFST和XQDA.与它们相比,CDDM分别具有1.08%和3.33%的rank-1性能优势.综合各方法在3个数据集上的再识别性能可以发现,在使用相同特征描述子时,尽管各方法在不同数据集上的性能会存在差异,但是本文CDDM由于同时学习了判别词典与度量矩阵,始终表现出最优的行人再识别性能.该实验充分说明了联合学习判别词典与度量矩阵所带来的优势.

Fig. 6 Performance comparison of CDDM with other algorithms using the same feature representation图6 采用相同特征描述子时CDDM与其他算法的性能对比
3.4 算法分析
在本文提出的CDDM算法中,学习的判别词典中基向量的数量、样本对权重的分配、使用的特征描述子等均会给算法的最终性能带来很大的影响,在本节实验中对它们分别进行了分析.
1) 词典基向量数量对算法性能的影响
图7给出了在VIPeR,GRID,3DPeS数据集上,采用本文CDDM算法进行行人再识别时不同的词典基向量数量对rank-1正确匹配率的影响.从图7可以看出,随着词典基向量数量的增长,各数据集上的rank-1匹配率均呈上升趋势;但在词典数达到200后,各匹配率基本上保持稳定.因此,本文选择了200作为词典基向量数.
2) 联合学习判别词典与距离度量的作用
在本文CDDM算法中联合学习了判别词典与度量矩阵,为了验证联合学习度量矩阵所带来的性能提升,实验中将算法1中的投影矩阵设置为单位矩阵进行了实验(下面标记为CDDI),并与CDDM作了对比.表4给出了它们在不同数据集上的实验结果,从表4数据可知联合学习判别词典与度量矩阵时,CDDM的匹配性能显著优于CDDI.在VIPeR,GRID,3DPeS上,CDDM的rank-1匹配率比CDDI分别高出了7.13%,4.88%,5.15%,说明联合学习度量矩阵更有助于发现数据的内在结构,获得的投影子空间比使用欧氏距离具有更优的判别性.
3) 融合深度特征与手工特征带来的性能提升
本文实验中使用了手工设计的特征描述子(标记为HCFeat)与ResNet152学习到的深度特征表达(标记为DeepFeat),图8给出了它们在融合使用(标记为ConFeat)与独立使用时获得的CMC曲线.从图8可以发现2种特征融合后取得的匹配性能显著优于分开独立使用时的结果,本文认为这主要是因为它们捕获了具有互补性的图像低层外观与高层语意信息.
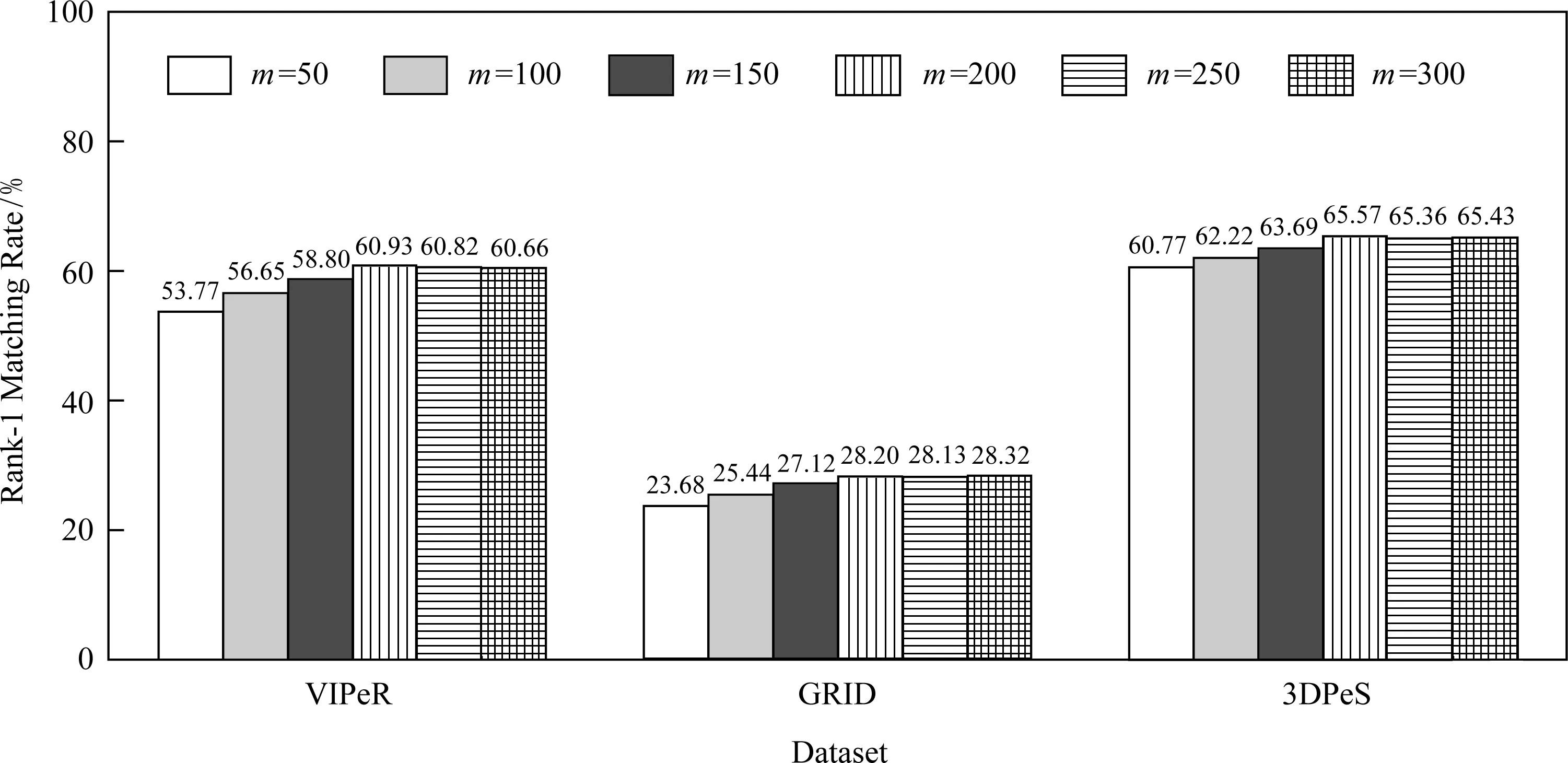
Fig. 7 Influence of the number of bases for dictionary learning on rank-1 matching rate图7 词典基向量数m对rank-1匹配率的影响

Fig. 8 Performance comparison of feature descriptors图8 特征描述子性能对比
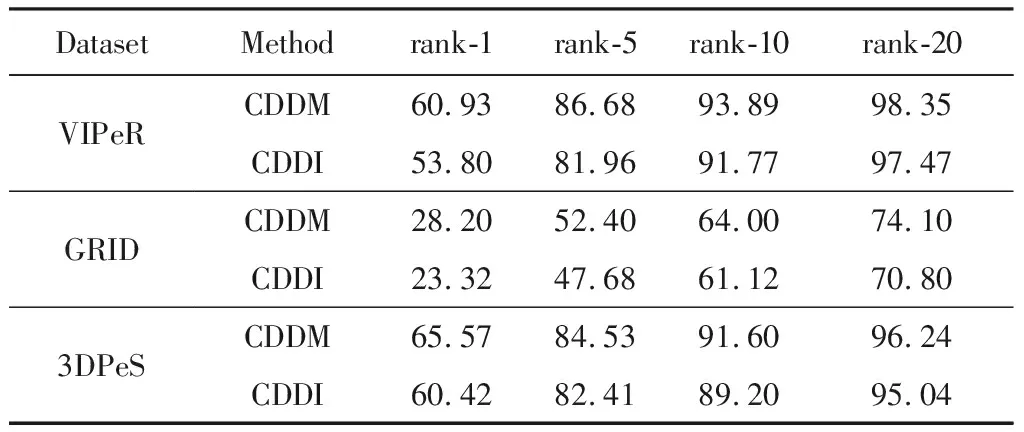
Table 4 Matching Rate Comparison of CDDM with CDDI表4 CDDM与CDDI匹配率对比 %
4) 样本对的权重分配对算法性能的影响
为了降低不均衡训练样本带来的度量偏差问题,本文采用了自适应的样本对权重分配策略.为了考查样本对权重分配对算法性能的影响,实验中对所有样本对在不考虑权重(设置式(8)中βij=1)时的匹配性能与使用式(8)权重分配方案取得的结果进行性能对比.图9给出了这2种情况下在各数据集上的rank-1匹配率.从图9可以发现,使用了自动权重分配策略比不考虑权重分别带来了7.07%,3.68%,8.66%的性能提升,说明本文权重分配策略对训练样本数量不平衡引起的度量偏差问题具有良好的抑制作用.

Fig. 9 Comparison of rank-1 matching rate图9 rank-1匹配率对比
4 结束语
本文提出了一种跨视角判别词典嵌入的行人再识别算法,该算法中通过交替迭代优化的方式联合学习了跨视角的判别性词典和嵌入子空间,从而将词典表达与度量学习的优势结合了起来.为了降低在学习距离度量时由于正负样本对数量不均衡带来的度量偏差问题,在算法中还引入了对训练样本自适应赋予权重的策略.在3个广泛使用的行人再识别数据集上的实验结果表明,本文方法取得了优秀的跨视角行人再识别性能.由于当前的工作主要关注于小数集上的行人再识别,在后续的工作中将尝试基于深度学习模型学习判别词典,并应用到更接近现实场景的大型数据集上.
