基于微局部特征的时序数据二分类算法①
2019-11-15舒伟博
舒伟博
(中国科学技术大学 计算机科学与技术学院,合肥 230027)
1 引言
时间序列是一种重要且特殊的高维数据,它的各个维度之间存在固定的先后次序,这些次序中隐藏大量的有利于分类的特征信息.在现实生活中,时间序列有着广泛的应用.例如天气预报中的气象数据、对外贸易中浮动的货币汇率、医疗器械捕获的电波图像,工程应用中的连续信号等,这些数据都可以看成是时间序列.
时间序列分类是时序数据分析中的主要任务之一.当前的时序数据分类算法可大致分为两类,一类是将整个时间序列看成一个整体,即距离空间中的一个点,通过构造合适的距离度量方式,在距离空间中寻找分类边界.
第二类是采用滑动窗口的方式捕捉时间序列的子序列,即所谓的“捕捉局部特征”.在通过某些方式选择具有良好分类性能的局部特征后,通过这些局部特征来构造各式各样的分类器,进而完成分类.
通过一些综合的比较,基于局部特征的分类方法整体性能优于第一类算法,尤其体现在更好的分类性能上[1].因而基于局部特征的分类方法也是现在研究的主要方向.
本文针对现阶段在基于局部特征进行时序数据分类的研究领域内存在的一些问题,设计了一个新的算法,该算法着重解决现阶段存在于该领域内的如下两个问题:
(1)基于局部特征的分类算法在分类精度上依旧存在可以提升的空间.该问题尤其体现在一些二分类问题上.
(2)基于局部特征的分类算法在现阶段存在太多的冗余局部特征,使得时间复杂度相对较高.
针对这两个问题,本文提出的算法分别采用如下的策略进行改进:
(1)本算法针对二分类问题,采用一种新的指标来评价局部特征,使得原数据在转换到特征空间后,具备更高的线性可分性.
(2)本算法在选择局部特征前,首先抛弃大量局部特征,仅保留长度非常短的局部特征,使得局部特征数量大幅减小,因而在评估并选择局部特征时,时间会被大幅减少.
对于这两处创新,本文也会给出理论依据以证明其可行性,同时,实验结果也证明了其带来的时间优势和分类性能上的优势.
2 相关工作
2.1 几个术语的定义
定义1.时间序列及其分类器:时序数据的一个样本点是一个序对(x,y),x是一个m维的有序观测值(x1,x2,…,xm),y为该样本点的类标,在不需要讨论其类别信息时,我们也会在文中将其简写为x.整个样本集表示为T=(X,Y)=((x1,y1),(x2,y2),…,(xn,yn)),在不需要讨论其类别信息时,我们也会在文中将其简写为X.
定义2.局部特征(shapelet):局部特征又叫 shapelet,本质上是时间序列的连续子序列,其具有一定的判别性能[2].所以一个局部特征由一段连续子序列以及一个类标组成,该类标即为该子序列的父序列(即某一原始时间序列)的类标.我们在文中用(s,z)来表示一个局部特征,其中s表示其代表的连续子序列,z为其类标,在不需要讨论其类别信息时,我们也会在文中直接用s指代.为了尊重提出shapelet 的原作者,从此处开始,下文中的“局部特征”皆用“shapelet”替代.
2.2 基于shapelet 的时序数据分类算法
一个m维的数据,它的shapelet 的长度可以是1 到m,所以其一共产生m(m+1)/2 个shapelet.如果数据集里面有n个时间序列,那整个数据集一共拥有nm(m+1)/2 个shapelet.Ye LX 和Keogh E 首次提出用shapelet 进行时间序列分类.其使用方法是选择具有判别性的shapelet 来构造一棵决策树[2].该决策树的判定节点为一个shapelet,而属性即为时间序列与该判定节点中的shapelet 的距离,通过距离所处的区间来将时间序列选择递交给某下一个节点处理[2].
因为shapelet 是从原始数据上截取下来的子序列,所以与原始数据并不等长,这里特别说明一下如何计算shapelet 与原始数据之间的距离.
设原始数据的一个样本点x=(x1,x2,…,xm),某个shapelets=(s1,s2,…,sj),其中j≤m,那么它们之间的距离用如下函数D(.,.)计算:

其中,d(·,·) 是欧式距离度量函数.
该算法较好地利用了数据的局部特征进行分类,具有不错的分类精度和可扩展性,但其缺点在于时间复杂性高.算法拥有O(n2m4)的计算复杂性,n是数据个数,m是数据维数,即时间序列数据的长度[2].
针对该方法时间复杂度高的问题,领域内的研究者提出了种种解决方案[3-6],这里介绍其中几种比较有代表性的方案.该算法时间复杂度高的第一大原因在于候选shapelet 太多了,对每一个shapelet 进行评估的单位时间,被候选shapelet 的数量极大规模地放大.所以有一类叫做“快速shapelet”的方法针对候选shapelet的数量进行改进,它们牺牲掉一些shapelet 的覆盖率,大幅减少shapelet 的候选数量,换取运行速率上的提升,但是精度上也有明显退化[7].而另一类叫做“learning shapelet”的算法,它并不从原始数据直接获取shapelet,而是通过学习的方式习得最佳的shapelet.该shapelet可能与原始数据中的任意一个数据段都不匹配,因为它是通过feedback 的学习方式创造出的用于分类的shapelet.该方法开辟了另一条道路,然而其也存在过拟合的问题,时至今日尚无可观的突破[8,9].
2.3 Shapelet 转换算法与shapelet 集成算法
Ye LX 和Keogh E 使用shapelet 构造决策树,该算法时间复杂度高的另一个原因在于,shapelet 的评估需要在每个节点的特征选择阶段进行一次.这是因为在构造完一个节点之后,数据集会被该节点划分为若干新子集,而新子数据集与原来的数据集不相同了,所以shapelet 的判别性能需要在新子集上做重新的评估.同样地,每一轮评估的时间被评估的轮数——即决策树上的节点数——放大后,时间复杂度变得相当高.
于是有一类叫做“shapelet 转换”的方法,它通过解决该问题来降低时间复杂度.该类方法通过一次性选取若干shapelet 来构建分类器,所以只需要对所有的shapelet 进行一轮评估,在评估并选取了合适的shapelet之后,则基于它们将原始数据转换到一个特征空间中,转换的方式是通过计算原始数据与第i个shapelet 的距离来作为原始数据在特征空间中的第i个坐标[10].当这些原始时序数据被转换到特征空间中之后,它再使用kNN 算法来完成分类[10].该算法有效地避免了多轮shapelet 评估,但是其时间开销依然不容小觑,主要原因还是上节中提到的候选的shapelet 数量太多.如果要减少候选shapelet 的数量,势必会引起精度的下降,但是其相较于原来经典的shapelet 算法已有了革命性的突破,使得后续的研究者工作开始围绕如何快速地找到用来构建特征空间的若干shapelet 来进行[11].
“shapelet 转换”的方法会有不稳定的特性,因为数据在被转换到特征空间之后,很难准确预料它们的分布特性,如果使用单一分类器,必须承担错误估计它们分布特性的风险,所以很多时候特征空间中的单一分类器会带来低分类性能的后果.为了解决这一问题,有人提出了“集成shapelet 转换”的方法,即在特征空间中集成若干经典分类器来完成分类[12].该方法能让分类精度得到大幅提升,但是训练集成分类器带来的时间开销也是很可观的.
3 算法理论分析
该节对当前已有的基于局部特征的分类算法上存在的缺陷进行分析,探讨如何能够有效地改进它们.
3.1 时间序列与shapelet 的距离计算
从式(1)可以看到,计算一个shapelet 与一个时间序列的距离需要计算该shapelet 与该时间序列的所有与该shapelet 等长的连续子序列的距离,然后选择其中最小的距离.如果假设一个时间序列的长度为m,一个shapelet 的长度为k,那么计算它们之间的距离需要O(k(m-k))的时间复杂度,当m>>k时,该复杂度接近O(km).
显而易见,该距离度量方式的时间复杂度比较高,而且此种度量方式只关心该shapelet 代表的局部特征是否明显出现在与其计算距离的时间序列中,而并不关心其出现的位置,这是因为最终的距离是取所有子序列与该shapelet 距离中的最小值.而对于不同的时间序列,取得最小距离的子序列的位置并不是固定的.由于shapelet 本身来自于时间序列,所以其本身就携带了位置信息,所以我们认为这种忽略位置信息的距离计算方式存在一定缺陷.
针对以上问题,我们设计了固定位置的距离度量方式,如下式所示:

其中,x,s,j和d(·,·)的含义同式(1),由于s本身是某个时间序列的子序列,所以它拥有自己在原始时间序列数据中的起始位置,所以式(2)所表达的即是用x中与s位置对齐的子序列与s计算欧氏距离来作为x与s的距离.我们把这个距离称作“定点距离”.
式(2)的计算加入了位置信息,既关注该时间序列是否具备shapelet 所代表的局部特征,还关注了其是否在对应的位置上与该局部特征有很好的近似性,同时,其时间开销从O(km)降低至O(k),其中k是shapelet的长度,m是原始时间序列的长度.所以,式(2)无论从最后的预测精度这一角度还是从时间开销这一角度来说,都要优于式(1).
考虑到时间序列数据经常会发生迟滞,噪音等情况,我们对式(2)加入适当的松弛,得到如下式(3)的距离计算公式:
上式中的x,s,m,j和d(·,·)的含义同式(2),而l是左松弛因子,r是右松弛因子,都是超参数.我们把这个距离称作“定点浮动距离”.
3.2 固定候选shapelet 集中shapelet 的长度
基于shapelet 的算法因候选的shapelet 数量太大而具有很高的时间复杂度,而之所以需要如此庞大的候选shapelet 集,是为了保证局部特征的全覆盖,因为你无法判定理想的局部特征所对应的shapelet 的长度应该是多少,所以只能选取所有长度的shapelet 来评估.这样的话,我们时序数据的个数为n,长度为m,则根据2.2 节中的分析,整个数据集产生的shapelet 个数达到O(nm2)的量级,非常庞大,由于评估一个shapelet的时间开销也不容小觑,所以单位评估时间被这个数量放大之后,时间开销爆炸性增长.
然而,我们发现,如果我们使用“shapelet 转换”的方式配合定点浮动距离(式(3))来构造分类器的话,我们可以通过固定shapelet 的长度来大幅缩减shapelet候选集的规模,接下来我们就来说明这件事.
我们看到“shapelet 转换”的第一步是从候选shapelet中选择判别性强的若干个shapelet 出来,第二步是基于这些选择出来的shapelet 构造特征空间,将原始数据转换至特征空间,第三步是在特征空间中对转换后的数据进行分类.
在这个过程中,我们能够发现最后对数据分类所倚赖的关键是构建特征空间的shapelet 的判别性.而shapelet 的判别性体现在,和该shapelet 同类的时间序列,与该shapelet 的距离要足够小,而反之则要与该shapelet 的距离足够大.而根据转换的方式(参见2.3 节),当原始数据被转换到特征空间之后,这就体现在和shapelet 同类的时间序列,转换后在该shapelet 对应的坐标轴上的范数要比较小,而反之则对应的范数要比较大.
所以我们看到,在特征空间中分类的关键依据,其实质是原始数据被转换到特征空间之后的范数.如果有两个不同的特征空间,原始数据被转换到它们之中后拥有相同的空间范数,那最终两个特征空间中的分类依据就是相同的,分类效果也会大同小异,在某种程度上,我们可以认为这两个特征空间是等价的.
现在假设原来的shapelet 候选集是A,如果我们找到一个A的很小的子集B,使得:从A里面找出的任意一组shapeletP,任意原始数据x被转换到P构造的特征空间中的范数记录为||x||P,B中都存在对应的一组shapeletQ,原始数据x被转换到Q构造的特征空间中的范数记录为||x||Q,且任意x,都有||x||P≈||x||Q,即这两个特征空间是等价的.那么这样的B显然具备构造等价特征空间的能力.而如此一来,我们就能够抛弃原来巨大的候选shapelet 集A,而只选用它的很小的子集B,这样时间开销会得到大幅降低.
我们现在就来证明这件事,即存在上述那样一个小子集B,其具备构造同等特征空间的shapelet.此事关键在于证明如下的定理:
定理1.将一个shapelets分割成若干段C={s1,s2,…,sn},使得它们按序拼接起来构成完整的s,我们称这样的C为s的一个划分集.对任意时间序列x,其通过定点距离(式(2))转换至s构造的特征空间中的欧氏范数记录为||x||s,而其通过定点距离转换至C构造的特征空间中的欧氏范数记录为||x||C,则我们有||x||s=||x||C.
证明:不妨设s=(si,si+1,…,si+k),其中i是s在原始时间序列中的起始位置,k+1 为其长度.令tj为C中sj的终止位置,且规定t0=i-1,tn=i+k,那么我们有sj=(stj-1+1,stj-1+1,···,stj).对于任意时间序列x,我们设x=(x1,x2,…,xm),显然m>i+k.
则根据shapelet 转换的规则,我们有:
证毕.
根据上述定理我们发现,在当前叙述背景下,一个shapelet 构造的特征空间,和它的划分集构造的特征空间可以看成是等价的.尽管最后我们用作转换的距离度量方式是定点浮动距离(式(3)) 而不是定点距离(式(2)),但是定点浮动距离只是定点距离的松弛版本,所以最后转换后的数据的范数与定理1 中的范数并不会相差太远,这样我们依旧有||x||C≈||x||s.所以在定点浮动距离作为转换坐标的计算公式的前提下,我们得到shapelet 构造的特征空间和它们的划分集构造的特征空间是近似的.
而另一方面,每一个shapelet 都可以划分为若干短的shapelet,所以我们只需要保留shapelet 候选集里足够短的shapelet,就足够我们找到好的shapelet 来构造好的特征空间了.如此一来,我们只需要选取长度为某个固定小数值的所有shapelet 来作为shapelet 候选集即可,这个数值一般取3 或者4 即可,我们把这样的shapelet 称作为“微局部特征”.我们将长度设置为3 或者4 是一种折衷,当长度设置比3 更小的时候,这些短shapelet 将失去统计意义,因为时序数据是连续的数据,在某个时间点的值并不能构成统计意义上的特征,它们提供的分类信息也因而不具备高可信度.而当长度比4 还大时,将无法覆盖某些短shapelet,比如长度为4 的shapele,失去这些shapelet 会对分类结果造成影响.由这些微局部特征构成的集合正是我们需要寻找的原候选集的小子集.对于n个长度为m的时间序列构建的数据集,我们构建的shapelet 候选集只有O(nm)的规模,而不再是O(nm2)的量级.
3.3 shapelet 判别性的评价指标
在具备shapelet 候选集后,需要从中选取判别性强的shapelet 来作为构建特征空间的一组基底.
容易知道,选取shapelet 需要量化shapelet 的判别性能,目前普遍采用的做法是用最佳信息增益来量化shapelet 的判别性能.该做法如算法1 所示.

算法1.计算shapelet 的信息增益输入:shapelet s,data set T=(X,Y)输出:prime information gain of s 1) For each time series (x,y) in T 2) Calculate Ds,x),namely distance between s and x;3) Depict D(s,x) with its label y in a real line r;4) End for 5) Find each possible segmentation in real line r to build C;6) Set prime_information_gain=0;7) For each segmentation c in C 8) Calculate information gain of c as g;9) If g>prime_information_gain 10) Prime_information_gain=g;11) End if 12) End for 13) Return prime_information_gain;
从该算法中可以看到,如果要计算一个shapelet 的最佳信息增益,则需要计算所有“分割”的信息增益再挑出里面最大的.这样做非常耗时,尤其当数据集里面数据比较多时,则可能的“分割”的数目指数增长,评价一个shapelet 的代价变得相当大.
为了避免这个问题,我们决定采用广义雷利熵来作为shapelet 的判别性能的评价指标.对于一个实数轴上的二分类问题,我们假设两类数据的集合分别为P和Q,则广义雷利熵的计算公式如下式所示:

式中,µ(.)是均值函数,σ2(.)是方差函数.
利用广义雷利熵来作为判别指标后,我们有效避开了寻找最佳分割的过程,不再需要计算每种分割的信息增益来寻找最佳信息增益了,这种耗时的操作因此也被去除掉了.因为shapelet 的评估是一个单位操作,所以在单位操作上带来的时间节省,被操作次数放大后,会得到非常可观的优化效果.如此一来,评估一个shapelet 的算法如下所示.

算法2.计算shapelet 的判别性能(广义雷利熵)输入:shapelet s,data set T=(X,Y)输出:prime information gain of s 1) For each time series (x,y) in T 2) Calculate D(s,x) by formula (3);3) Depict D(s,x) with its label y in a real line r;4) End for 5) Calculate general Rayleigh quotient grq of points in r;6) Return grq;
3.4 特征空间中的分类器
正如我们2.3 节中所述,使用“shapelet 转换”的方式必须承担转换后的数据在特征空间中的分布不定性这一代价,所以要想保证分类精度,需要在转换后的特征空间中训练多个类型不同的分类器,保证不遗漏可能的数据分布.但是这样做的时间代价相当高.
自然地,我们想要避免这种操作来降低时间开销.由于我们无法保证特征空间中的数据具有某种特定的分布特性,所以我们只能用不同类型的分类器把所有可能的分布特性都考虑进去.而造成这种现象的根源在于选择shapelet 的环节.我们确实选择了最具判别性的shapelet 来作为特征空间的基底,但是却忽略了它们的组合效应.在经典的基于shapelet 的算法中,他们选择最佳信息增益作为判别指标,这使得在“shapelet 转换”后,特征空间的数据在每个坐标轴上的投影具有非常好的线性可分性,但是在每个坐标上的分量具有很好的线性可分性,并不能保证在整个空间上具备很好的线性可分性,这是问题的关键所在.
所以若我们可以保证原始数据被转换到相应的特征空间之后,具备线性可分性这一分布特性.我们就能使用单个的SVM 去替代集成的分类器而避免训练集成分类器这一耗时操作.
我们现在断言,如果我们使用广义雷利熵作为shapelet 的评价指标,那么高得分的shapelet 能够保证特征空间中数据的线性可分性,这倚赖于如下的定理:
定理2.对于一个时序数据的二分类问题,shapelet的广义雷利熵与特征空间中数据的线性可分性存在正相关.
证明:我们假设选择了k个shapelet 构造好了一个特征空间,那我们要证明的是,将其中某个shapelets1替换为拥有更大广义雷利熵的shapelets2,数据的线性可分性会提高.我们假设原始数据中有两个类的时间序列,根据中心极限定理,它们通过这k个shapelet转换到特征空间之后实际上形成了两个随机向量A,B,且A和B服从球形正态分布.
我们自然地按如下方式来定义这两类数据的线性可分性:

式中,LS是线性可分性,P(·)是概率函数.我们现规定µ(·)是均值函数,返回随机向量的均值向量;σ2(·)为随机向量的协方差矩阵的对角线函数,它返回由协方差矩阵的对角线构成的向量;[·]2是平方函数,对向量中每一维度的数据取平方来得到一新向量.根据A,B服从球形高斯分布,我们有:
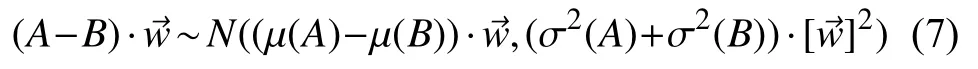
式中,N(·,·)为正态分布的符号.结合式(7),根据线性可分性的定义以及的取值范围(式(6)),对于最佳的,我们显然可以得到如下关系:
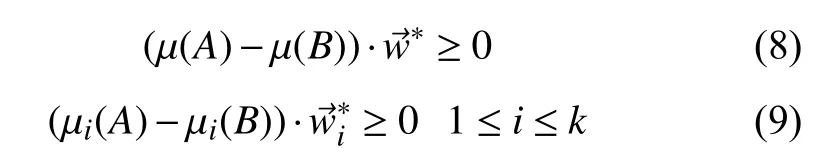
根据广义雷利熵的计算式(式(5)),我们若证明任意0<i<k+1,|µi(A)-µi(B)|与式(6)中的线性可分性成正相关以及 σ2i(A)+σ2i(B)与其成负相关,则可完成定理的证明.
但这件事并不难,假设我们已经拥有最佳的LS值(式(6)),现在将某个特定的µi(A)-µi(B)替换为拥有更大绝对值的 µi(A′)-µi(B′),保持其它数值不变.我们不妨假设( µi(A′)-µi(B′))·>0,因为若其小于0,我们只需将相应的取成相反数即可.由于(µi(A′)-µi(B′))·>(µi(A)-µi(B))·→ ≥0,其他项不变,所以(µ(A′)-µ(B′))·>(µ(A)-µ(B))·≥0.再根据正态分布的特性及式(8),我们有:

这样即证明了| µi(A)-µi(B)|与式(6)中的线性可分性成正相关,同样地方法可以证明与 σ2i(A)+σ2i(B)式(6)中的线性可分性成负相关,此处不再赘述.
证毕.
定理2 为特征空间中的转换后的数据的线性可分性这一分布特性提供了理论支撑,所以在我们提出的新算法中,当原始时间序列被转换到特征空间之后,我们可以放心地使用单个的SVM 来执行分类,而不再需要训练集成分类器,这一结果极大优化了时间性能.
4 算法框架与实验结果
4.1 主体算法
我们在此节给出最终的算法框架,如算法3 和算法4 所示.

算法4.基于微局部特征的时序数据二分类算法(数据分类)输入:shapelet queue Q,SVM classifier svm,data x输出:class label of x 1) Transform x to the N-dimensional vector v by calculate distance with shapelet in Q by formula (3);2) Use svm to classify v,get a label y;3) Return y.
4.2 实验数据集
为了公平起见,我们选择Bagnall 等人在其工作中所使用的数据集[1].他们在相关研究工作中精心筛选数据集以及各种算法,并做出了比较公平公正的对比,他们所使用的数据集也被选作时序数据分类算法社区的标准数据集[10].先对数据集做如下介绍:
Ham,火腿光谱图数据,通过对光谱图进行分类来判断火腿的种类,训练集109 个数据,测试集105 个数据,数据长度431.
MPOC,全称Middle Phalanx Outline Correct,手指中部骨节的X 光投影轮廓图.科学家根据该数据来判断人们所处的年龄阶段,训练集600 个数据,测试集291 个数据,数据长度80.
Eq,全称Earthquakes,用传感器捕捉的地震波数据,用来判断近期内是否会有地震发生,数据来自于北加利福利亚地震研究中心.训练集322 个数据,测试集139 个数据,数据长度512.
Herring,鲱鱼的耳石轮廓,该数据用于生物多样性研究,通过耳石轮廓对应的时序数据来判定鲱鱼生活的地区.训练集64 个数据,测试集64 个数据,数据长度512.
IPD,即Italy Power Demand,意大利人民不同季度生活用电时序数据,不同类别的时序数据对应不同季度的用电水平.训练集67 个,测试集1029 个,数据长度24.
Wine,葡萄酒的光谱图,光谱图上不同种类的时序数据对应不同种类的葡萄酒.训练集57 个数据,测试集54 个数据,数据长度234.
用于做实验的数据集来自于实际应用的各方各面,包括天文地理,衣食住行等多个领域,也从侧面反映了时序数据有着广泛的应用.
4.3 对比算法与算法超参
本文针对基于shapelet 的时序分类算法进行分析与改进,旨在提升算法的分类精度和降低算法的时间开销,所选对比算法为基于shapelet 的时序分类算法中的优秀算法,介绍如下:
FS,该算法专注于时间开销,是现有的基于shapelet的算法中平均时间开销比较低的,但是其牺牲了部分精度,采用近似的方法选取shapelet[7].
LS,是用学习的方式获取shapelet 的代表算法,通过把获取判别性shapelet 这一难题转换为优化问题,并用梯度下降来习得最优shapelet,具有非常不错的时间开销和分类精度[8].
ST,是当今主流的基于shapelet 的时序数据分类算法,它通过shapelet 将原始数据转换至特征空间,在特征空间里训练集成分类器进行分类,拥有较高的时间复杂度,但是分类精度属于领域内的顶尖[12].
COTE,是基于shapelet 的集成算法中的集大成者,除了集成基于shapelet 的时序数据分类算法,也集成了其它类型的时序数据分类算法,因此是四个对比算法中时间复杂度最高的,同时也是分类精度最好的[13].
值得一提的是,在Bagnall 等人的工作中,ST 和COTE 不仅是基于shapelet (局部特征)的时序数据分类算法中的最好的,也是所有时序数据分类算法中分类精度最好的[1].详情请见图1[1].
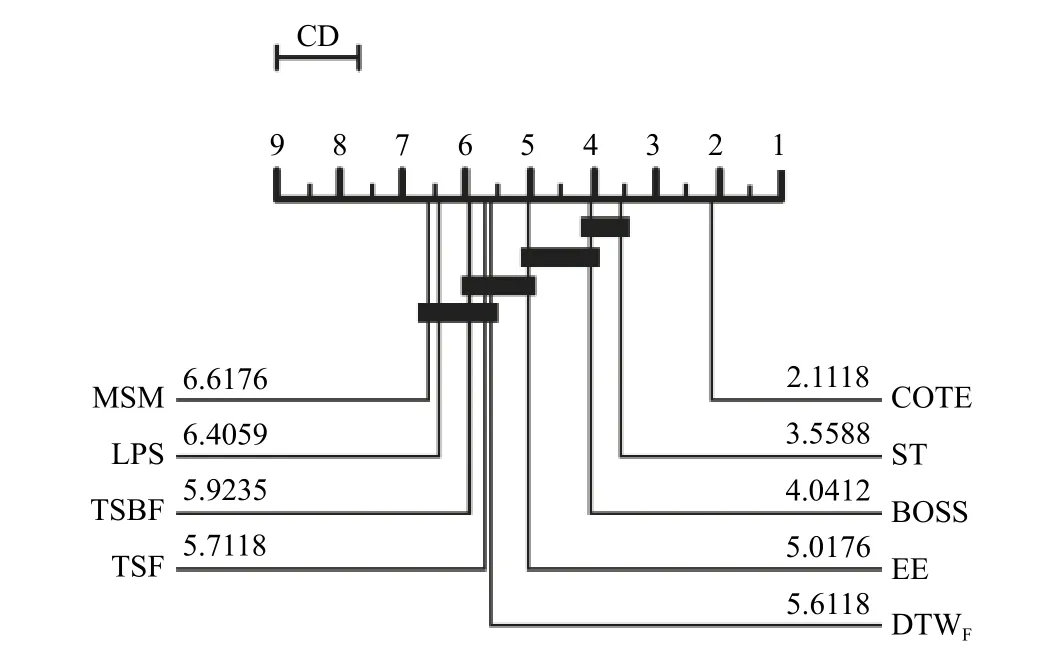
图1 最佳算法在UCI 数据集上的分类精度平均排名[1]
另外,我们提出的基于微局部特征的时序数据二分类算法,它的英文名称为“mini-shapelet based algorithm”,简写为“MS”.MS 的超参选择集如表1所示.

表1 MS 的超参取值
4.4 分类性能对比
关于分类性能,我们延用时序分类算法社区里面的硬指标,即分类精度对比以及分类精度的排名对比,具体的对比数据如表2,表3以及图2所示.
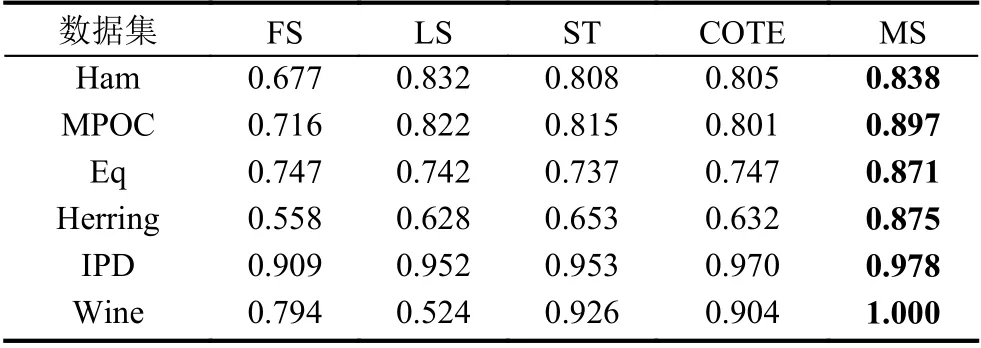
表2 分类精度对比
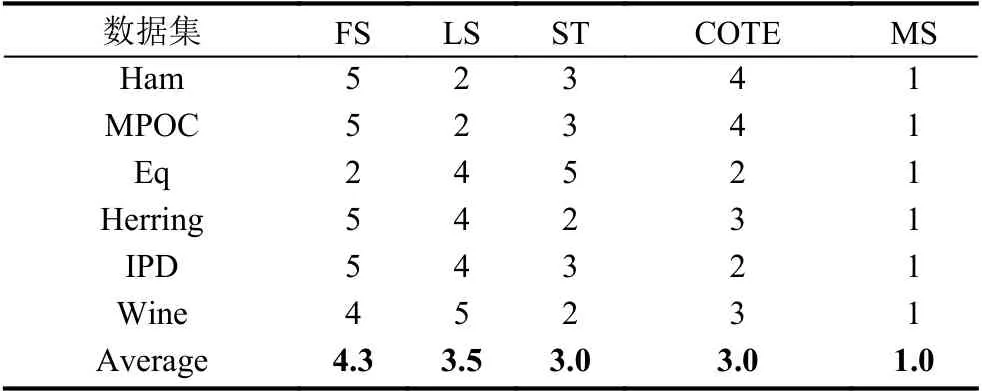
表3 分类精度排名对比

图2 算法分类精度点线对比图
从表2以及表3中可以看出,在所有测试数据集上面,基于微局部特征的分类算法(MS)都取得了最优的分类精度,并且在某些数据集上还具有非常明显的分类精度优势,比如Herring 和Eq 这两个数据集.综合来看,相对于其它4 种经典的基于shapelet 的分类算法,基于微局部特征的分类算法显而易见地具有最佳的分类能力.而在Wine 这个数据集上,它甚至取得了无任何错误的分类结果,体现了其极强的分类能力.因而综上所述,基于微局部特征的时序数据分类算法相较于4 种对比算法有明显的分类精度优势.
从图2中我们可以观察出四种对比算法分类性能不太稳定,都有大幅度的波动.而相比之下,基于微局部特征的分类算法(MS)具有较为稳定的分类性能,其折线波动较小,相对来说比较平稳.所以基于微局部特征的时序数据分类算法在分类表现上稳定性更好,且具有稳定的分类性能优势.
4.5 时间开销对比
关于时间开销,因为5 个算法都是使用eager learning 的方式进行分类,而且其主要的时间都用在构造分类器上,所以我们主要比较它们的构建分类器的时间.我们在同样的硬件条件(内存:8 GB;CPU:2.5 GHz)及软件条件下(OS:Win 10;platform:JAVA)进行实验,具体数据如表4及表5所示.
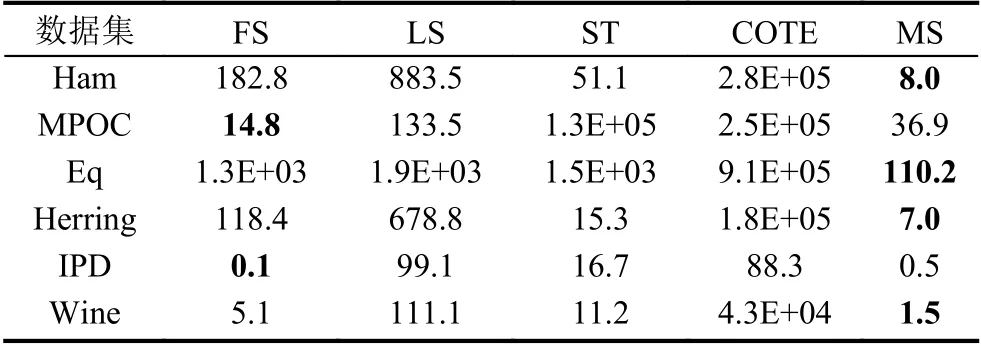
表4 时间消耗对比(单位:秒)

表5 时间消耗排名对比(升序)
从表4和表5中可以观察到,除了MPOC 和IPD这两个数据集外,基于微局部特征的分类算法(MS)在剩余数据集上都具有最小的时间开销,而在MPOC 和IPD 这两个数据集上,也仅次于FS 这一算法,但是FS在MPOC 和IPD 上的精度远不如基于微局部特征的时序数据分类算法.再结合表5中的平均排名,我们可以认为相对于其它4 个对比算法,在保持最高分类精度的同时,基于微局部特征的时序数据分类算法具有最佳的时间性能.
5 结语
本文针对当前基于局部特征的时序数据分类算法中存在的问题与挑战,在充分的理论依据的支撑下,使用缩减候选集,调整判别性评定指标,修改距离度量以及替换集成分类器4 项技术设计了高效实用的新型算法.该基于微局部特征的时序数据分类算法在实验数据集上表现出良好的分类性能和时间性能.通过实验对比,也证明了其对当前研究领域内存在的分类精度不足以及时间开销过高等问题有不错的改进.
