有限感知条件下的停车数据批量式修复研究①
2019-11-15张华成刘建明钟晓雄
张华成,邹 万,刘建明,钟晓雄,杨 兵
(桂林电子科技大学 计算机与信息完全学院,桂林 541004)
1 引言
伴随着汽车保有量的迅速增加,停车难问题已成为无法忽视的城市通病,因停车问题引发的纠纷屡见不鲜.无论是超大型城市,还是特大城市,甚至只有几十万、十几万人口的中小型城市,车辆迫切的停车需求与可用停车位不充足的矛盾都日益突出.因此,如何对城市中有停车需求的车辆进行宏观的停车诱导,成为地方政府面临的一大难题.为解决这个问题,降低停车时间成和经济成本,智能停车系统[1]是最有效的办法之一.而城市中所有停车场当前可用停车位都已知是智能停车系统能正常运行的前提.目前停车数据主要通过传感器采集和与停车场直接合作的方式获得,但因为停车场类型、产权的多样性、经济成本及安装施工等原因的限制导致大范围的停车场数据处于缺失状态.其次,不同停车场以及不同辖区的系统以往都是独立运行,必然存在数据兼容问题,而且由于缺乏统一标准,也不能实现数据共享,多种原因导致难以将所有停车数据加入到大系统中形成规模.因此,城市中相同数据形式的停车数据往往是非充分的[2].
考虑到直接获得充分的停车场数据有足够的挑战性,本文希望在经济时间成本可控范围内对缺失数据的停车场进行数据修复.停车数据受时空两个维度的综合影响,不同停车场间的数据可能差异极大,如果直接将数据特征明显不同的停车数据当成一个样本集进行学习训练,会得到无法解释的生成数据.针对这个问题,本文使用K-means 聚类的方法按空间特征相似性将停车场划分为多个簇,对每个簇单独进行数据修补.通过可获得的停车场公开数据量化各个停车场的影响力,对影响力高的停车场安装传感器以获得真实数据,在此基础上修复其余停车场的停车数据.因为不同地理位置、规模、收费标准等多种状况对停车场的影响,不能简单的用一般插值法的方式修复.因此本文采用数据增强技术,也就是通俗意义上的数据生成/修补技术.通过这种方法,能在有限感知条件下下获取大量高仿真的停车数据.
2 相关工作
本文的停车数据为时序数据,目前时序数据修补领域的研究主要是一些插值法[3],主要为3 类,基于拉格朗日插值法的数据修补方法、基于牛顿插值法的数据修补方法、基于分段线性插值法的数据修补方法[4],其中基于分段线性插值法的数据修补方法效果较好.上述方法的特点是需要一定的先验知识,常常被用于有一定历史数据的修补领域中,然而由于经济成本、安装施工、经济产权等原因,多数停车场历史数据难以获得,因此是用插值法在对停车场数据修补时会有较大局限性.
在机器学习中,处理数据缺失问题一般采用数据增强技术,也就是传统意义上的数据生成或数据修复技术.数据生成目前已成为机器学习领域的研究热点,其中优秀的生成模型有生成对抗网络(Generative Adversarial Nets,GAN)[5],该模型由一个生成网络和判别网络组成,在每一次迭代中,判别器的目的是区分真实数据和生成数据,而生成器则期望生成以假乱真的数据,在零和博弈的思想下,最终达到一个两者都可接收的结果.由于GAN 在时序数据中训练起来非常不稳定,因此直接使用GAN 可能会生成无意义的数据.目前一种高效的的生成方式是将在时序数据表现良好的LSTM 网络与GAN 结合得到的循环生成式对抗网络(Recurrent Generative Adversarial Networks,RGAN)[6],该方法虽然能快速生成时序数据,但缺点是生成结果伴有明显的抖动和相位差,针对生成数据震动较大这个不足,本文的解决思路是将时间序列升维,使用在二维数据有强大特征提取能力的深度卷积对抗生成网络(Deep Convolution Generative Adversarial Networks,DCGAN)[7]提高生成数据的稳定性,实验表明该方法使生成结果更加稳定,抖动减少.
3 系统模型
3.1 模型搭建
本文的停车数据指的是关于停车场的空车位的时间序列,考虑到不同停车场同一时刻可用停车位数量差异较大引起的数据难以训练问题,本文将空车位的时间序列除以停车场的规模,转换成空车率的时间序列.对于区域O中的n个停车场,表示为P={p1,p2,···,pi,···|i=1,2,···,n}则 停车场pi的空车率数据可表示为U=s为时间序列的长度.实验将样本点的停车数据作为训练集,使用改进后的DCGAN 模型生成其余停车场的停车数据.改进后的生成器如图1所示.
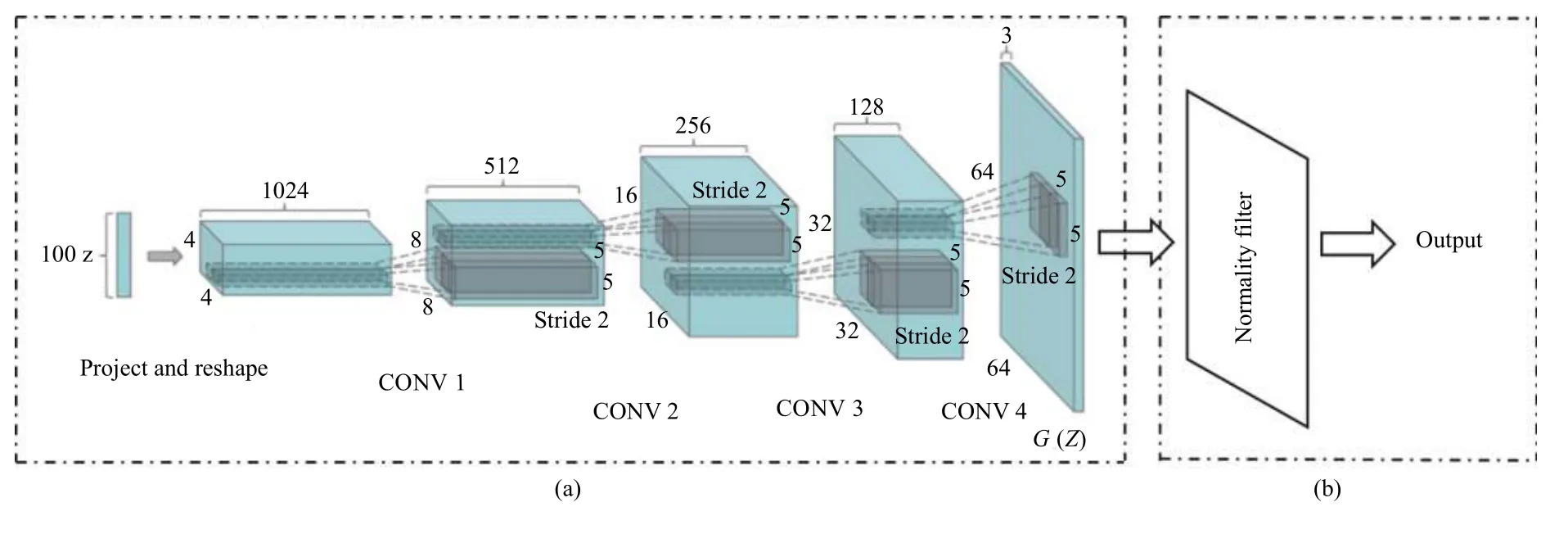
图1 改进后的DCGAN 生成模型
图1(a)描述的是,将100 维均匀分布的z投影到一个具有多个特征图的小空间范围的卷积中表示,用一系列步长为4 的卷积将这种高维的表示方式转换为64×64 像素的图像,注意不适用全连接层和池化层.另外,在生成器中引入正态性检验的过滤器,用来保证生成的曲线效果可以接受,如图1(b)所示.其中,正态性过滤器使用的算法为D’Agostino-Pearson 检验,该方法是一种对分布的偏度和峰度进行综合评定的方法[8].D值的公式如下:
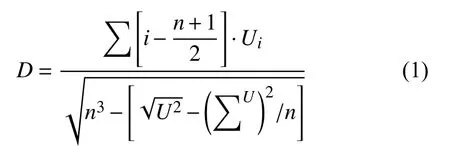
在式(1)中,n为样本总数,ri为停车场pi的的停车数据.得到D值后,通过D界值表确定P′的值,按照P′值判断这组样本是否符合正太性分布.如果P′小于设定的阈值∂,则这组生成样本不符合正态性检验,反之符合正态性检验,并保留这组生成样本.
3.2 停车场的高维聚类
不同停车场的停车数据差异较大,这是因为停车场不可能单独存在于地理空间中,一定会受周围空间信息的影响,地理空间信息其实也就是地理兴趣点(Point Of Interest,POI),包括住宅、商场、学校、公交站等,不同POI 对停车场有不同的影响.比如某景区附近的停车场,其停车位在节假日使用率明显高过工作日;住宅区附近的停车场车位占用率在下班时段明显高于上班时段;商场周围停车场的车位使用率在周末显著上升.换句话说,附近空间信息相似的两停车场其数据一定具有相似性,如图2所示.
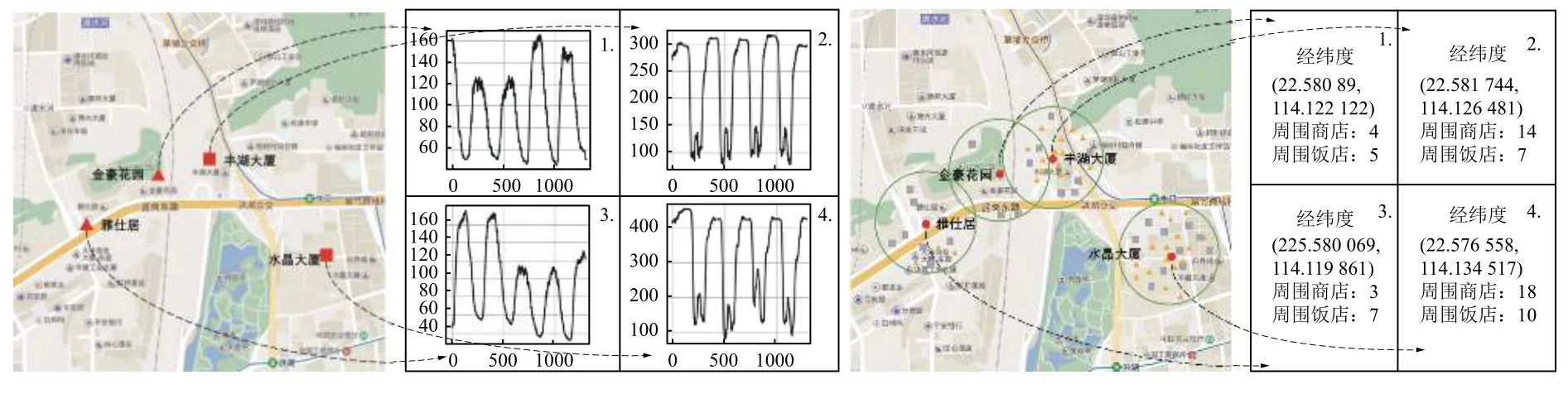
图2 停车场间的拓扑关系
可以看到两对停车场停车数据差异明显;而对于两对中的任何一对,对内停车数据却很接近.因此本文根据停车场的各POI 数量,对每个停车场转成高维向量的形式,通过对停车场高维向量的聚类实现将停车场按数据差异分类的目的.
以停车场为圆心、Rt为容忍度半径的圆用Op表示.圆内的POI 会对停车场产生影响,圆外的POI 对停车场的影响不考虑.假设在区域Ω 内有n个停车场,如果城市中主要的POI 有h种,那么,对于任意一个停车场pi统计Rt内h种主要POI 的数量可构建一个h维的向量作其特征向量,记为vi,表示为用来表示停车场受地理空间的影响.考虑到停车场的经纬度也会对停车数据产生影响,将停车场pi的经纬度信息用一个2 维向量,记为μi.对于停车场pi的地理空间信息用(2+h)维向量esi=(ui,vi)唯一标定,则n个停车场的高维向量记为ES={es1,es2,···,esi,···|i=1,2,···,n}.基于K-means 的聚类算法更适合对高维向量进行聚类,在本文中,将对停车场高维聚类的公式为:
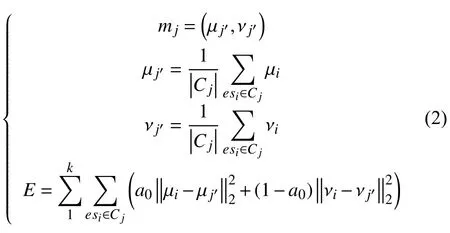
其中,C={C1,C2,···Cj,···|j=1,2,···,k}为聚类产生的k个簇,mj为簇Cj的质心,E为成簇Cj内样本与簇均值向量mj的靠近程度,a0是经纬度2 维向量和POI 高维向量的权重.
3.3 一种停车场影响力评价算法
区域内的停车场间相互影响,具体表现为影响力越强的停车场吸引车辆停车的能力越强,当一个影响力强的停车场因为无空闲停车位而无法继续停车时,车辆会向周围影响力较弱的停车场进行疏散.换句话说,在一个区域内某个停车场的影响力越强的,则这个停车场越能代表这个区域的停车场.因此,如果对停车场按影响力进行排序,那么只要知道影响力较高的停车场的停车数据,就可以通过某种方式对其余停车场的数据进行修复.本节的目的是筛选出影响力较强的停车场.
基于一般的认知标准,与周围其它停车场连通度越高的停车场往往表现出更高的影响力,因为人们更倾向于前往停车场较密集的区域,这样会增加停车的成功率,当一个停车场由于某种原因无法停车时,可以轻松的向与之连通的停车场疏散.此外,相邻停车场也会互相影响,具体表现在一个区域内影响力最强的停车场附近停车场评分会稍低,但明显高于更远处的停车场(类似于地理上的等高线).因此,实验需要将停车场的拓扑关系用数学方式描述.假设有6 个停车场,它们的拓扑关系可用无向图表示,如图3所示.
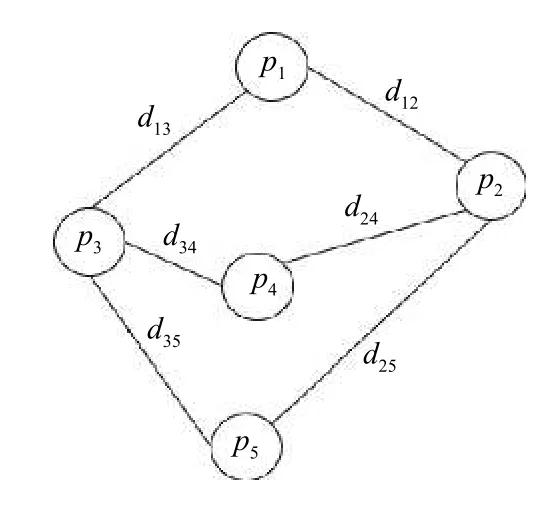
图3 停车场间的拓扑关系
对于图3中任意两个停车场pi和pj,如果存在连通关系,那么它们间的距离设为dij.上图中的拓扑关系也可用矩阵的形式表示:
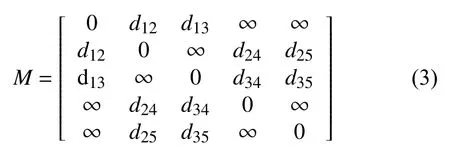
考虑到距离的数值差异较大难以计算,将pi和pj距离dij换成pi和pj的连通度,并做归一化处理,用sij表示pi和pj的转移概率,则新的矩阵也就是概率转移矩阵如下:
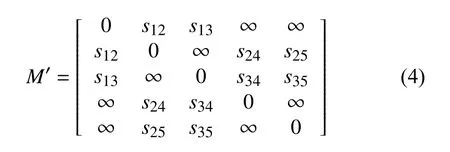
一个连通度很高的停车场会存在多种无法停车的情况,比如私有停车场、收费过高的停车场.因此,除了考虑停车场的连通度之外,还需量化停车场的静态信息.
根据我国相关的法律法规,任何一个合法经营的停车场都必须以公示牌的形式公开的展示该停车场的类型、收费标准、规模等信息,这些信息一定程度上代表了停车场相对于其它停车场的影响力.不难发现,不同的信息有着不同的深层含义,具体如下:
(1) 停车场类型:主要分为4 种,住宅、办公、政府、商场.其中,住宅类型和政府类型的停车场开放程度最低,外来车辆很难进入,商场类型停车场开放程度最高.用1≥x≥0 来表示不同类型停车场的开放程度,当x=0 时不对外开放.
(2) 收费标准:不同收入阶层能接受的收费区间不同,低收费的停车场能被大多数收入阶层的人接受,而收费较高的停车场只吸引高收入阶层的人.因此,收费标准可以表示停车场的受欢迎程度,用y≥0 表示停车场的收费标准,当y=0 时,停车场最受欢迎.
(3) 停车场规模:停车场的规模可以表示停车场的服务能力,显然,规模越大的停车场无疑影响力越强,用z>0 表示停车场的服务能力
通过式(5)来量化静态信息对停车场影响力的影响,也就是对其评分[2]:
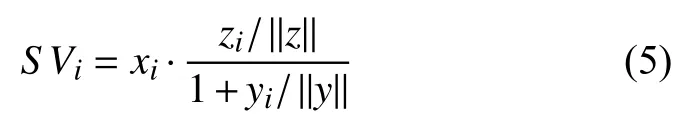
其中,SV表示停车场的评分值.i为停车场pi的编号,zi/||z||和yi/||y||的目的是对收费标准和停车场规模归一化处理.用SV={SV1,SV2,…,SVi,…|i=1,2,…,n}表示区域O中的n个停车场的评分向量.
考虑到停车场的静态信息和拓扑关系都对停车场的影响力有显著影响,因此如何合理的统筹这两部分,成为必须要解决的问题.本文的方法是在已知概率转移矩阵M′的条件下,求解平稳状态下向量SV的值,可表示为SV=M′.SV,显然,SV是循环定义的,所以引入著名的幂迭代法求解平稳状态下向量SV.将式(1)得到的评分向量作为初始评分向量SV0,与转移概率矩阵M’作为幂迭代法的输入,多次迭代不断修正评分值SV,直到SVi和SVi+1的差值小于一个阈值θ时,迭代终止,并取SVi作为最终的评分向量.迭代公式如下:

实验选取影响力较大的部分停车场为样本点,来修复其余停车场的停车数据.由于停车数据受到人类社会的活动的影响,一定程度上停车数据是满足正态分布的,可用式(1)中的D值检验证真实停车数据是否存在正态性,当数据存在明显正态性时,则可根据二八定律[9],也就是影响力最大的前20%的停车场基本包括该簇停车场全部的特征,停车数据因受多种复杂因素的影响,在服从同一分布的前提下必然含有一定的多样性.一般数学方法生成的同分布数据极为相似,不满足停车数据的特点,而这正是GAN 的优势所在,因此本文基于GAN 的思想学习样本数据分布并生成新的停车数据.与传统大量部署传感器获得数据的方式相比,显著降低了时间和经济成本.
3.4 修复缺失停车数据
考虑到直接使用一维时间序列生成同簇数据时,其结果难免伴随有明显抖动[6].为了使生成数据的效果更平滑,需要对一维时间序列升维.本文解决方式是将其转为二维曲线,并以图像方式保存,如图4所示.
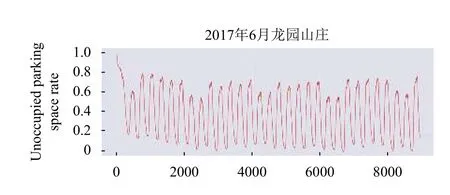
图4 一条真实的空车率曲线
将筛选出的二维曲线集做为学习样本,采用基于图1的DCGAN 模型中训练.一条生成曲线如图5所示.
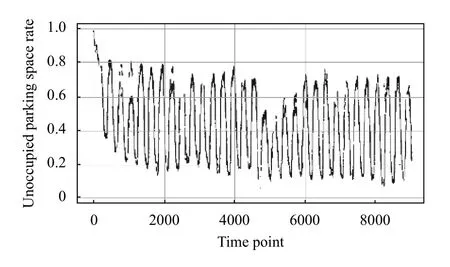
图5 一条生成的空车率曲线
从图5可以看到,生成图像伴随有明显的噪声,因此需要对生成数据进行降噪处理.本文试验中对生成图像的处理包括如下3 步.
第一步,需要把产生的图片灰度化.即将灰度化之前的RGB 值分别设为R1、G1和B1,相应的,灰度化后的值设为R2、G2和B2.用公式表示为:
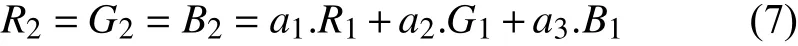
第二步,将灰度化的做二值化处理.二值化处理方法为设定一个阈值γ,遍历矩阵中每一个数值,如果该数值大于γ则设为255,若像素点值小于该阈值则设为0.
第三步,将异常值处理.下一节将提到.
3.5 异常值处理
图5中异常值分为两类,在曲线峰值处像素点过于密集,称为毛刺点;在曲线外零星的像素点,称为离群点.
对于毛刺点,实验采用均值滤波的方法[10],降低毛刺点处像素点的密度.均值滤波的公式如下所示.
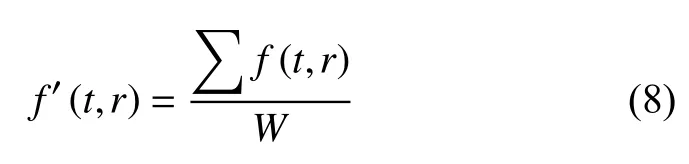
其中,t代表时间轴和r为空车率;W表示滤波窗口,大小取默认的3×3;表示遍历原图像所有像素点;最后f′(t,r)表示滤波之后的新图像.
对于离群点,实验采用局部异常因子LOF 算法(Local Outlier Factor)[11]来寻找.思想是通过比较每个点q和其邻域点的密度来判断该点是否为离群点.设Nq(k) 表示以q为圆心,dk(q) 为半径的圆,其中dk(q)为点q到第k远点的距离.实验中选k为3.寻找离群点用到的公式如下:
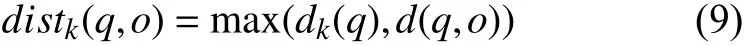
式(9)中,distk(q,o)表示可达距离,d(q,o)表示点q到点o的距离.当点o在Nq(k)圆内,则distk(q,o)等于dk(q),当点o在圆Nq(k) 外,则distk(q,o) 等于d(q,o).
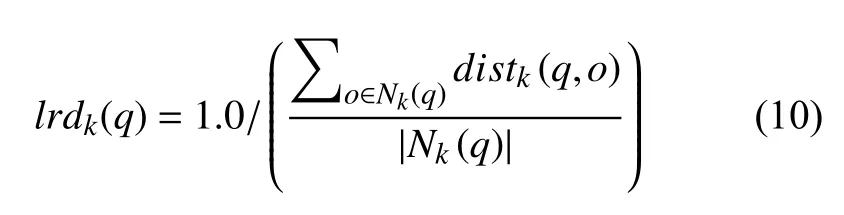
式(10)定义了局部可达密度lrdk(q),可以理解为一个密度,密度越高,则认为越可能属于同一簇,反之,越可能是离群点.其中|Nk(q)|描述的是q为圆心,邻域为dk(o)点的个数.
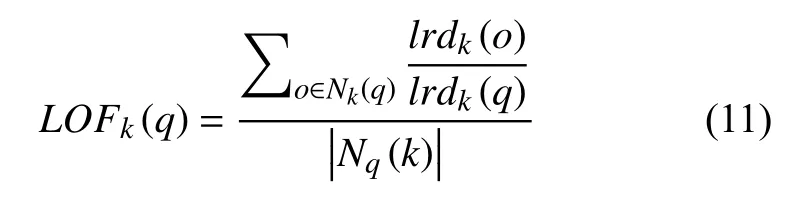
因为密度的阈值难以选定,实验引入局部离群因子来判定每个点q是否为离群点,如式(11)所示.其中,LOFk(q)描述的是点q在圆Nq(k)的局部可达密度lrdk(q)与点q的局部可达密度之比的平均数.如果这个比值越接近1,说明点q的邻域点密度越接近,q和邻域同属一簇;如果这个比值越小于1,说明q的密度高于其邻域点密度,q为正常点;如果这个比值越大于1,说明q的密度小于其邻域点密度,q越可能是离群点.
4 仿真实验
本实验的目的是在有限感知的前提下,获得足够多的停车数据,为基于机器学习的停车诱导系统提供充足的数据支撑.目标区域停车场的静态信息,通过百度地图拓展包BMap 得到.本文的思路是筛选出样本点,通过对样本点安装传感器可以得到实时停车数据,基于这些样本点来修复剩余的实时停车数据,达到实验目的.而现实情况是没有条件安装这些传感器,因此选择已知2017年6月停车数据的深圳市罗湖区的392 个停车场来进行仿真实验(实验收据为采购获得),最后将修复的数据与测试数据对比来筛选出合理的生成数据.
4.1 样本停车场的筛选
目标区域主要POI 分布如图6所示.
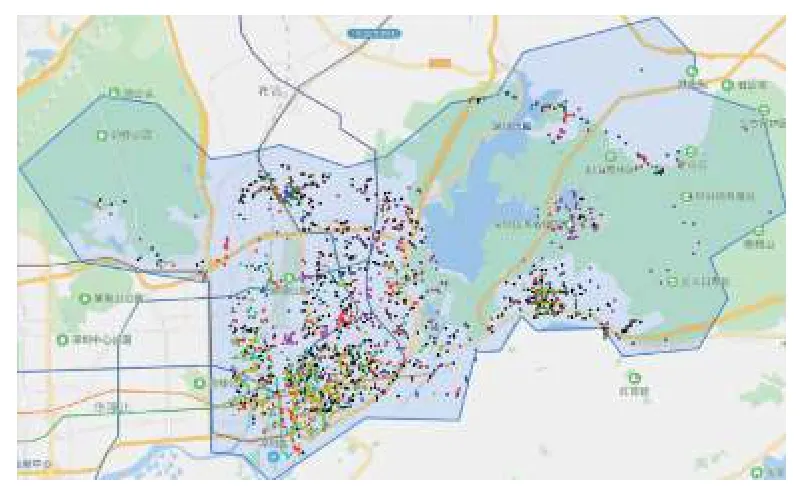
图6 深圳市罗湖区主要POI 分布
考虑到空间信息差异大的停车场间停车数据同样差异过大,在筛选样本停车场前需要将停车场进行聚类.实验中,为方便计算,取容忍度Rt为310 米,在地图中恰好约等于1′,对每个停车场统计其半径310 米方位内POI 的7 维向量.结合其位置得到9 维向量.部分停车场的9 维向量如表1所示.
对392 个停车场进行高维聚类,结果如图7所示.
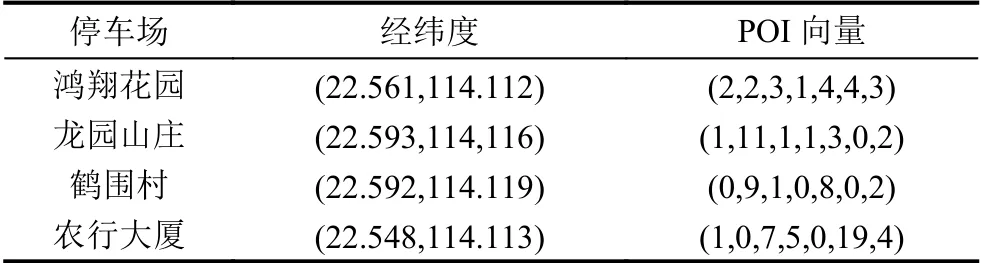
表1 部分停车场的9 维向量
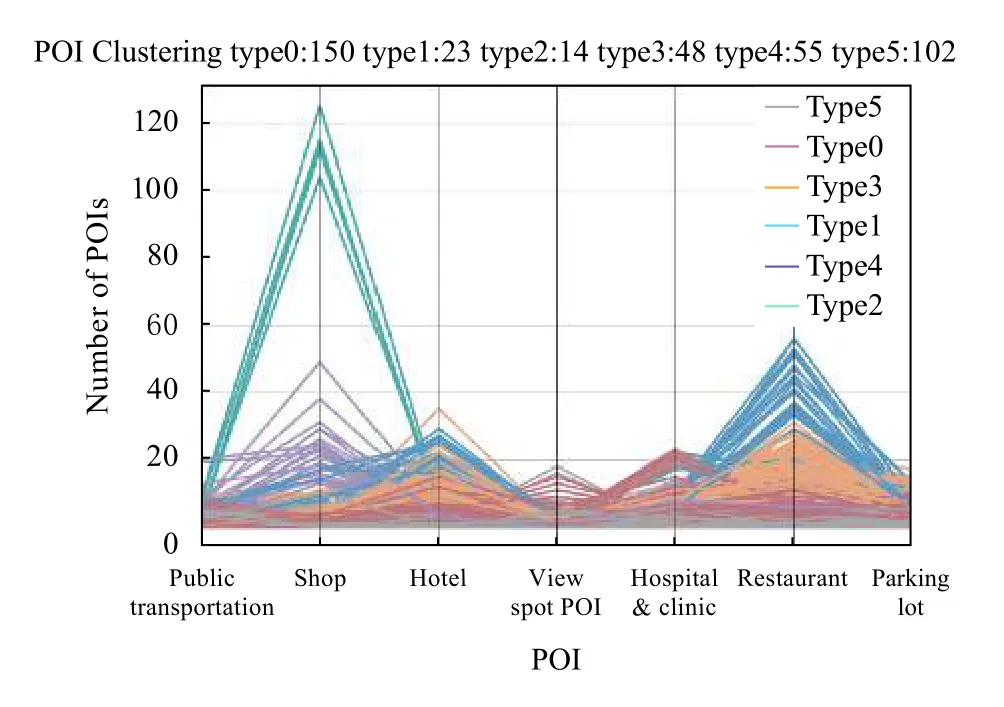
图7 对停车场的聚类结果
可以看到停车场数量最多的簇为‘type0’,因此仿真实验选取簇‘type0’的150 个停车场进行后续实验.
‘type0’的150 个的停车曲线和正态性检验结果如图8和表2所示.从图8可以看到,有3 条数据明显异常的噪声数据,做剔除处理.对其余147 条数据在8928 个时刻检验使用式(1)其正态性,设阈值∂为0.05.结果如表2所示.不满足正态性的组数不足25%,可以认为整体是符合正态性的,因此停车数据适用于二八定律.
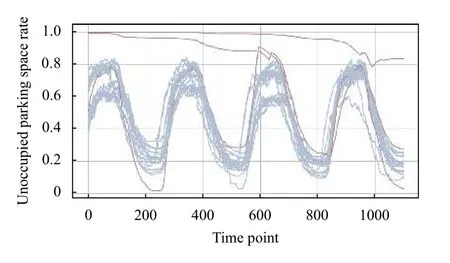
图8 簇“type0”停车场的空车率数据

表2 样本数据的正态性检验
第二步对150 个停车场进行编号,根据式(3)-式(6)及停车场间的空间拓扑关系,计算所有停车场的评分,并排序.如表3所示.
取θ为0.01,当迭代次数达到105 时,评分值趋于稳定,并全部保存.可以看到序号为74 和73 的停车场存在约等于,而最终的却远远大于的情况.导致这种情况的原因是两停车场的拓扑关系也就是连通度差异较大.具体来说,序号为74 的停车场与周围停车场的连通度远远大于序号为73 的停车场,当车辆在74 号或73 号停车场无法停车时,处于74 号停车场的车辆更容易疏散到附近停车场.序号为39 和74 的停车场,存在和差异较大,而和却比较接近,这还是由连通度差异较大导致的.74 号停车场连通度大于39 号停车场,一定程度上弥补了74 号停车场先天条件的不足.评分结果符合 公众认知,可被接受.
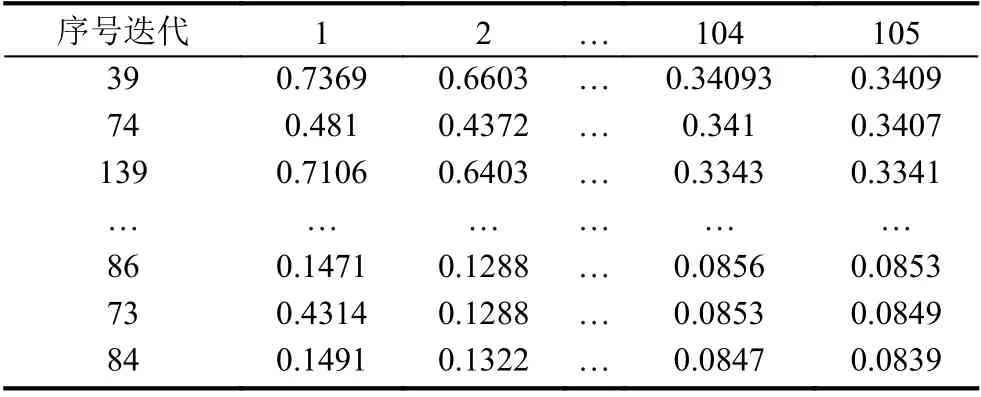
表3 停车场评分的迭代过程
4.2 数据生成和处理
在深圳市罗湖区,对应簇‘type0’中147 个有数据的停车场,筛选出30 个样本点,在此基础上修复其余停车场的停车数据.实验以2017年6月整月为时间跨度,每5 分钟为时间间隔,可划分出8928 个时间节点,并绘制空车率线图像.一条真实的停车曲线如图4所示.
使用DCGAN 为生成模型,设置隐层神经元为600个,批处理大小为1,学习率为0.004.在生成过程中,每一次迭代生成器都会学习样本点在2017年6月的空车率数据,并尽可能生成与样本点相似的数据.由于在DCGAN 生成模型中加了正态性检验过滤器,所以生成的数据一定是符合正态性的.DCGAN 的生成过程如图9所示.
从图9中可以看到随着迭代次数的增加,生成图像从模糊逐渐变得清晰,实验取第800 次迭代的结果.图5为最终得到的一条生成结果,从中可以看到生成的数据存在较多的噪声,需要进行降噪处理.降噪的第一步是要进行灰度化处理,灰度化公式中的系数如表4所示.
具体二值化的做法是从图5左上角遍历每一个数值点,设定阈值γ为140,当像素点的像素值大于该阈值将该值重新设为255,当像素值小于该阈值时则设为0.最后对二值化后的图像删除毛刺点和离群点.图10为图5经过去噪的效果.

图9 DCGAN 生成数据的过程.
图10 图5经过去噪处理的效果
从图10中可以看到,生成数据一定程度的保留了原始空车率数据的概率分布信息,即可表示出时间和空车率的关系.另一方面,由于DCGAN 本身的特性,生成结果不仅和真实数据有相似的概率分布,且有一定的多样性.因此,只要生成结果集足够大,就会包含该簇所有停车场的空车率数据.

表4 式(7)的系数设置.
为了对比生成数据的效果,本文还复现了RGAN生成停车数据的实验.设置隐层神经元50,批处理大小为1,学习率为0.03.使用与上文实验相同的训练集进行学习,生成过程如图11所示.
在图11中,Iteration 表示迭代次数.在迭代100 次时曲线无规律,随着学习的进行,曲线渐渐变得平滑,当迭代次数达到4000 时,曲线趋于平稳,但仍有数据跳变的情况.本文实验选取第4000 次迭代结果.
考虑到 GAN 网络本身的缺陷,无论是本文基于 DCGAN的生成模型还是已有的基于RGAN 的生成模型,都难免会生成十分异常的输出,因此需要对生成的数据进行评估,及时剔除明显错误的生成数据.具体做法是在每一个时间节点计算生成数据与117 条真实数据误差,当一条生成数据在85%的时间节点上与真实数据集的误差都小于0.05,则保留这条数据,反之则丢弃.两种方法耗时对比和生成数据结果对比如表5和图12所示.
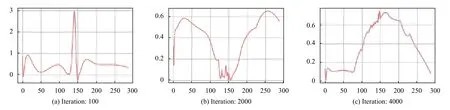
图11 RGAN 生成数据的过程.

表5 两种数据修补方法耗时对比.
从表5中,可以看到基于DCGAN 的停车场数据修补方法相较基于RGAN 的停车场数据修补方法耗时显著降低.从图12可以看出,一方面无论RGAN 生成模型还是DCGAN 生成模型,其生成数据和真实数据视觉上大致相似,因此两种方法均存在一定合理性.另一方面RGAN 生成的数据出现了异常偏移和明显抖动,而DCGAN 生成数据较RGAN 生成数据更为平滑.这可能是RGAN 网络对样本集学习过于充分而导致的泛化性能不强,且DCGAN 面向的二维数据比RGAN 处理的一维数据有更多的特征.考虑到停车数据受人类社会活动的影响,一般情况下其数据变化是一个循序渐进的过程(如图12中的真实数据),特殊情况下有出现短期大幅跳变的可能,比如体育场周边的停车场,在有球赛的时其空车率会急促降低,但如果多数生成曲线均存在急剧抖动现象,会导致其与真实数据间的方差变大,因此需要曲线平滑.两种生成数据与真实数据方差如表6所示.
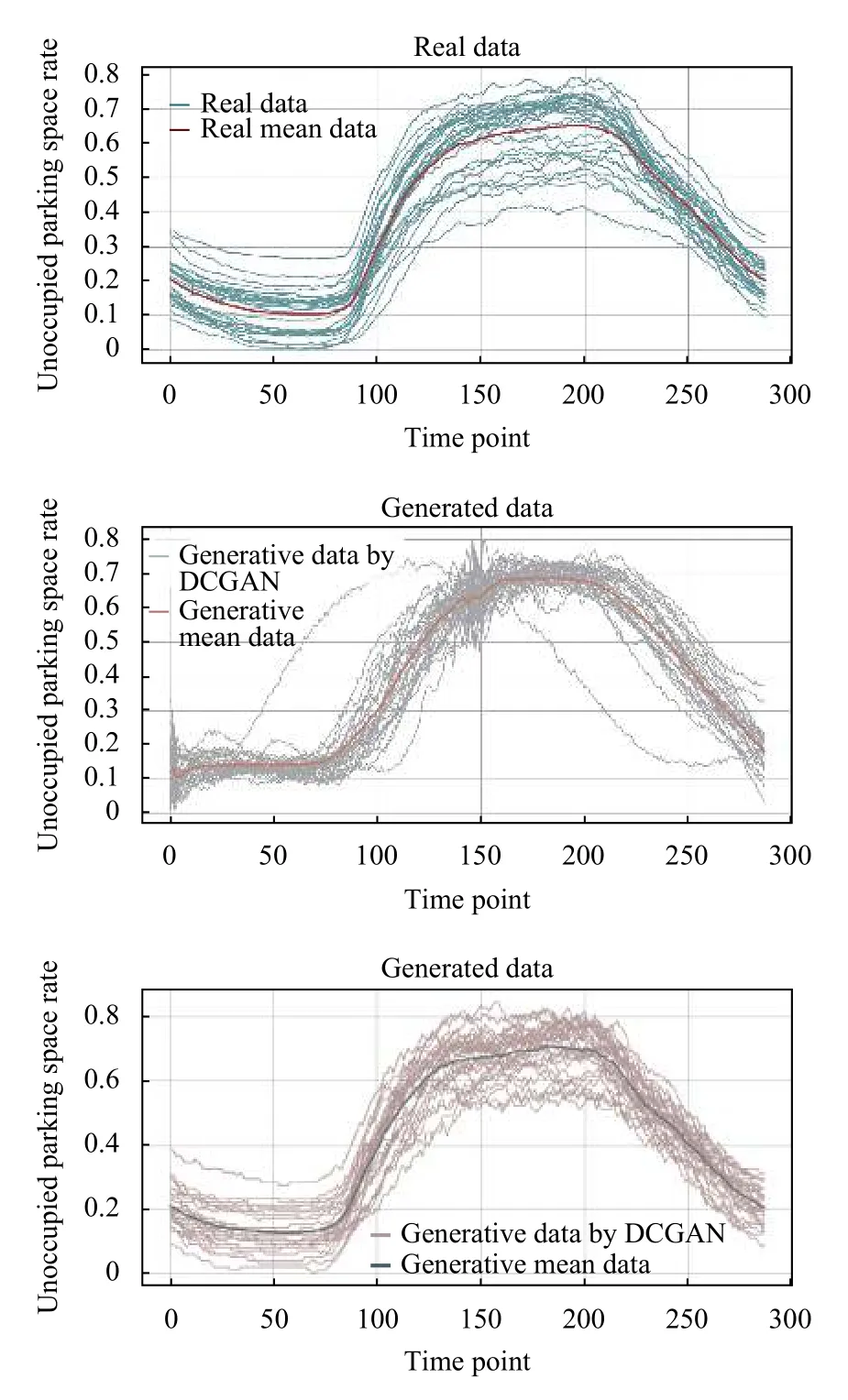
图12 真实数据和生成数据对比效果

表6 两种修补方法生成数据的离散程度
因此就修补速度和生成数据直观效果,基于DCGAN模型的修补方法均明显优于基于RGAN 模型的修补方法,更符合公众认知.
为了进一步比较两种生成数据的质量,还需衡量生成数据与非样本点的真实数据之间的误差.本文引入均方根值(RMS)、均方根分误差(RMSE)、平均绝对误差(MAE)来描述这种误差,并用卡方检验(Chisquare test)计算两种生成数据和真实数据同分布的比例,设置卡方检验显著性水平为0.05,在8928 个时间点上判断生成数据和真实数据是否属于同一分布,如果卡方检验的P值大于0.05,则此时刻的生成数据与真实数据属于同一分布.两种方法修复数据对比如表7所示.
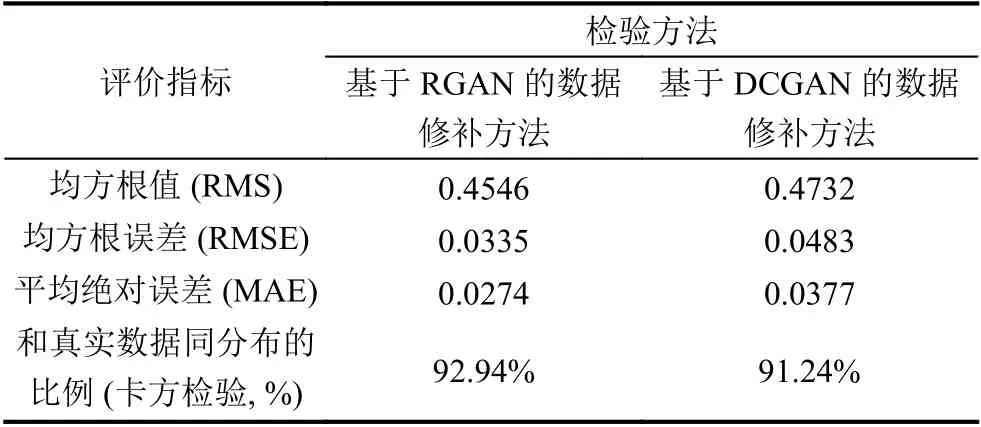
表7 两种数据修补方法效果对比
从表7可以看出,基于RGAN 的数据修补方法的误差分析和正确率均稍好于基于DCGAN 的数据修补方法,这是因为RGAN 中的LSTM 对文本数据解释性较好.因此,总结两种方法的优缺点如表8所示.
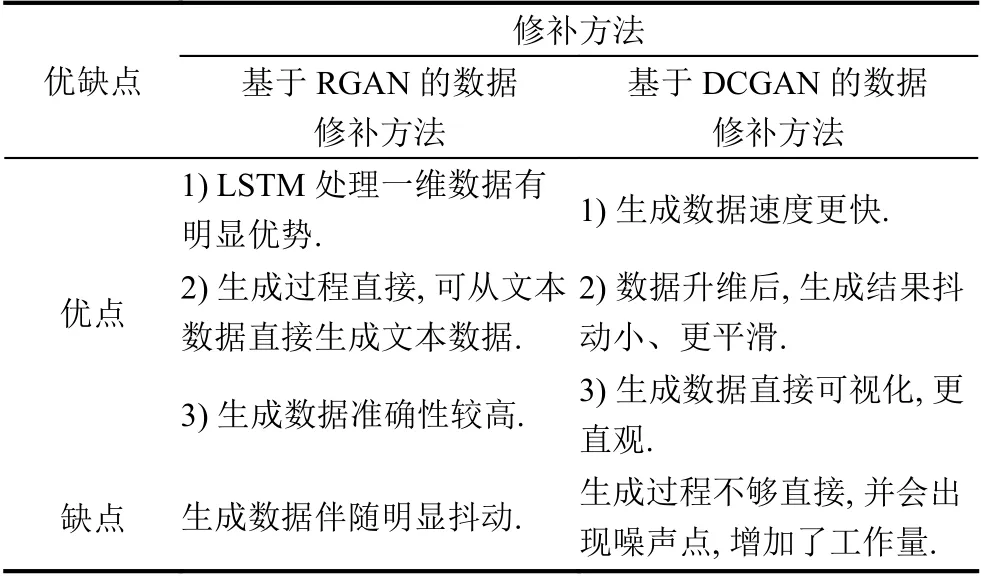
表8 两种生成方法的优缺点
5 结论
为了在降低经济时间成本的前提下,获得城市中的所有停车场的停车数据,本文提出了一种基于DCGAN生成模型来修复缺失数据的全新技术,可通过对样本停车数据的学习训练生成与之同分布的新数据,由于GAN 网络生成数据多样的特征,理论上只要新数据数量足够大,就一定会包含该簇所有停车场的停车数据.其中要解决的细节问题主要由两点组成.首先,不同地理信息的停车场数据差异巨大,这样会导致生成数据可解释性差.本文的方法是统计停车场周围POI 的类型和数量将停车场映射为高维向量,使用K-means 算法将数据特征相似的停车场归为一个簇,针对各个簇分别进行数据修复实验;其次,为了降低成本,本文希望仅通过少量数据就能学习到足够特征来生成同分布的新数据.对于任意一个簇,本文做法是利用PageRank算法的思想通过对停车场的公开信息和停车场间的连通度的迭代计算,算出各个停车场的影响力评分值,在验证停车数据遵循二八定律的后,将影响力最大的20%停车场作为样本停车场,通过安装传感器等方式获取样本停车场数据,以此为样本修复该簇其余的停车场停车数据.
本文的方法目前还不能针对具体停车场进行点对点的修复.下一步主要研究方向是对特定停车场的数据进行修复.
