一种基于机器学习的P2P 网络流量识别算法研究∗
2019-11-12袁华兵
袁华兵
(西安医学院信息技术处 西安 710021)
1 引言
对等网络(Peer to Peer Networks,P2P)是计算机网络和分布式系统结合的产物,其被广泛地应用于即时通信、流媒体、文件存储和文件共享等领域[1]。目前,P2P 流量占到国内网络流量的70%以上,由此可见P2P 网络流量严重影响整个互联网的服务质量,因此进行P2P 流量识别对给用户提供可管可控的高质量网络服务具有重要意义。
为提高P2P 网络流量识别的准确率,针对Elman 神经网络预测精度受其权值和阈值选择的影响,本文运用蜻蜓算法[2](Dragonfly Algorithm,DA)对Elman 神经网络的权值和阈值进行优化选择,提出一种基于DA-Elman的机器学习的P2P网络流量识别模型。研究结果表明,DA-Elman 可以有效提高P2P 网络流量识别的准确率,其准确率高达98.4252%,为P2P网络流量的识别提供新的方法和途径。
2 蜻蜓算法
DA 算法中,蜻蜓个体通过避撞行为、结对行为、聚集行为、觅食行为和避敌行为等5种行为方式进行觅食和寻优,这些个体行为详细描述如下[2]:
避撞行为的位置向量更新策略:

式中,X 为当前蜻蜓个体的位置;Xj为第j 个邻近蜻蜓个体位置;N为相邻蜻蜓个体的数量。
结对行为的位置向量更新策略:
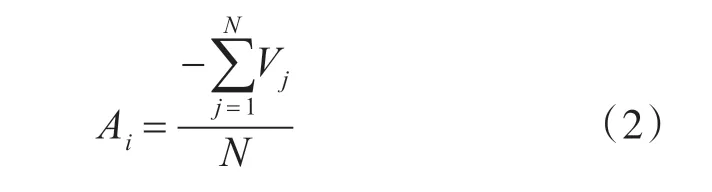
式中,Vj为第j个邻近蜻蜓个体速度。
聚集行为的位置向量更新策略:
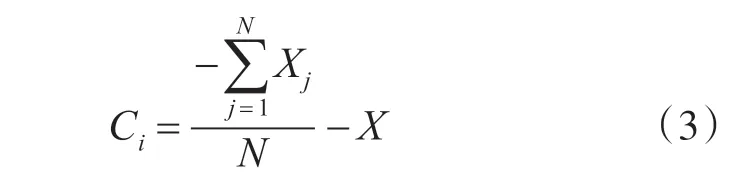
觅食行为的位置向量更新策略:

式中,X+为食物源位置(当前最优解)。
避敌行为的位置向量更新策略:

式中,天敌位置X-(当前最差解)。综合5 种蜻蜓群体行为,蜻蜓个体的步长向量更新策略为

式中,s、a、c、f、e 分别为5 种蜻蜓群体行为的权重;w 表示惯性权重;t 为当前迭代次数。
蜻蜓位置更新策略为

3 Elman神经网络
Elman 神 经 网 络[3~5](Elman Neural Network,ENN)是一种具有局部反馈连接的前向神经网络,其由输入层(Input Layer)、隐含层(Hidden Layer)、关联层(Association Layer)和输出层(Output Layer)组成,其结果示意图如图1所示。
与传统的静态前向神经网络相比,ENN网络增加了一个关联层,也叫连接层,该层从隐含层接受反馈信号,隐含层节点数与关联层节点数相等,两者一一对应进行连接。图1中,W1、W2、W3分别为输入层到隐含层的权值矩阵、关联层到隐含层的权值矩阵和隐含层到输出层的权值矩阵;U(k-1)、X(k)、Y(k)和Xc(k)分别为ENN 的输入向量、隐含层输出向量、ENN 的输出向量和关联层的输出向量,其数学模型为[6~7]

其中,f(x)、g(x)分别为隐含层和输出层的传递函数;b1、b2分别为隐含层和输出层的阈值。

图1 Elman神经结构示意图
4 基于DA-Elman 的P2P 网络流量识别
4.1 适应度函数
针对ENN 预测精度受其权值和阈值选择的影响,本文运用DA 对ENN 网络的权值和阈值进行优化选择,DA-Elman模型的适应度函数为

4.2 算法流程
基于DA-Elman的P2P网络流量识别算法流程具体描述如下。
Step1:输入P2P 网络数据,产生Elman 训练集和测试集,并进行数据归一化,归一化公式为
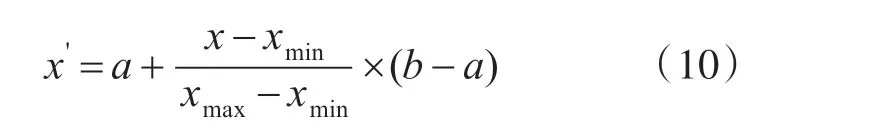
其中,x'为归一化之后的数据;x,xmax,xmin分别原始数据、原始数据中的最大值和最小值;a、b为归一化之后的最小值和最大值。本文取a=-1,b=1。
Step2:DA 算法参数初始化:种群规模N,最大迭代次数T,若Elman 神经网络的输入层神经元个数为N1,隐含层神经元个数为N2,关联层神经元个数为N2,输出层神经元个数为N3,则DA 优化变量的个数为Num=N2×(N1+N2+N3)+(N2+N3);
Step3:随机初始化步长向量DX 和随机产生蜻蜓个体的初始位置X ;
Step4:令当前迭代次数t=1,将训练集输入Elman,根据适应度函数式(9)计算所有蜻蜓个体的适应度,并进行排序记录当前最优解;
Step5:更新食物源位置X+(当前最优解)和天敌位置X-(当前最差解),更新5 种行为权重s、a、c、f、e和惯性权重w;
Step6:根据式(1)~式(5)更新S、A、C、E和F;
Step7:根据式(6)~式(7)更新步长向量和位置向量;
Step8:若迭代次数t>T,保存ENN 的最佳参数W*1,W*2,W*3,b*1,b*2;否则,t=t+1,返回Step4;
Step9:将最ENN 的最佳参数W*1,W*2,W*3,b*2代入Elman进行P2P网络流量识别。
5 实证分析
5.1 数据来源
选择Wireshark 软件抓取网络流量数据,包括PPStream、eMule、BitTorrent 和PPLive 4 个网络流量数据类型[8~9],每个类型的样本各159 个,一共636个数据样本。数据特征包括TCP 流量比例、连接数与不同IP 数目的比值、平均数据包长度、上行流量比例、数据包总数5个特征属性[10~11]。
5.2 评价指标
为了评价不同方法进行P2P 网络流量识别的优劣,选择准确率作为流量识别的评价指标[12]:

式中,AC 为准确率;N 为样本总数;TN 为正确分类的样本数量。
5.3 结果分析
为验证本文DA-Elman 算法的优劣,将DA-Elman 与PSO-Elman、GA-Elman 和Elman 进行对比,Elman 网络参数[13]为N1=5,N2=11,N3=1,最大迭代次数Tmax=1000,训练误差goal=0.001。通用参数设置:种群规模N=10,最大迭代次数T=100,PSO 算法[14]学习因子c1=c2=2;GA 算法[15]交叉概率pc=0.7,变异概率pm=0.1,训练集占比ratio=0.8,每个算法独立运行10次,识别结果取平均值,识别结果如图2~图5所示和表1所示。

图2 DA-Elman识别结果

图3 PSO-Elman识别结果

图4 GA-Elman识别结果
“○”为实际网络流量类型,“*”为预测识别的网络流量类型。由图2~图5 和表1 可知,与PSO-Elman、GA-Elman 和Elman 相比,DA-Elman可以有效提高P2P网络流量识别的准确率,其准确率高达98.4252%,分别比PSO-Elman、GA-Elman和Elman 提高4.7244%、6.2992%和9.5118%。智能算法优化Elman 的网络流量识别准确率均得到了较大提高,主要是因为智能算法对Elman 的权值和阈值进行了参数选择,提高了识别准确率。
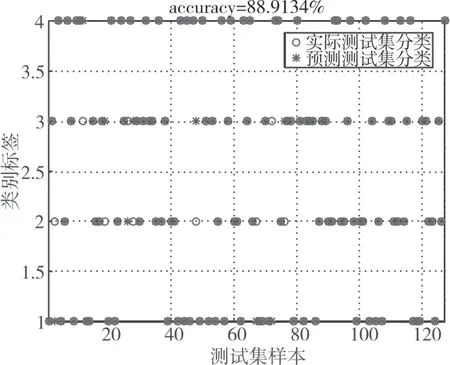
图5 Elman识别结果

表1 不同算法识别准确率
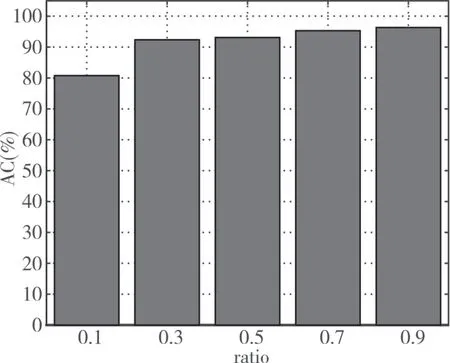
图6 不同训练集占比识别正确率
由图6 可知,随着训练集占比的提高,DA-Elman的P2P网络流量识别的正确率不断提高,当ratio=0.1 时,识别准确率AC=80.7692%;当ratio=0.9时,识别准确率AC=96.3351%。综合分析可知,与PSO-Elman、GA-Elman 和Elman 相比,DA-Elman可以有效提高P2P 网络流量识别的准确率,其准确率高达98.4252%,为P2P网络流量的识别提供新的方法和途径。
6 结语
针对Elman 神经网络预测精度受其权值和阈值选择的影响,运用蜻蜓算法对Elman 神经网络的权值和阈值进行优化选择,提出一种基于DA-Elman 的机器学习的P2P 网络流量识别模型。研究结果表明,DA-Elman 可以有效提高P2P 网络流量识别的准确率,其准确率高达98.4252%,为P2P 网络流量的识别提供新的方法和途径。
